Что такое директива DB в ассемблере. Как работает оператор DUP. Какие есть особенности использования DB и DUP в ассемблерных программах. Как правильно объявлять массивы и инициализировать данные с помощью этих директив.
Директива DB в ассемблере: определение и использование
Директива DB (Define Byte) является одной из базовых директив в ассемблере для определения данных. Она используется для резервирования памяти под байтовые значения.
Основные способы использования DB:
- Определение отдельных байтовых значений:
NUM DB 34— создает переменную NUM и присваивает ей значение 34 - Определение строк:
MSG DB 'Hello'— создает строку из 5 байт - Определение массивов:
ARR DB 1, 2, 3, 4, 5— создает массив из 5 байт
Важно понимать, что DB всегда резервирует память под байты, даже если записываются числа больше 255. Например:
VAL DB 1000
Это создаст 2 байта — 232 и 3, так как 1000 в двоичном виде это 11 1110 1000.
Оператор DUP: дублирование данных
DUP (Duplicate) — это оператор, который позволяет повторить определение данных заданное количество раз. Он часто используется вместе с DB для создания массивов.
Синтаксис DUP:
количество DUP (значение)
Примеры использования DUP:
ARR DB 5 DUP (0)— создает массив из 5 нулевых байтSTR DB 10 DUP ('A')— создает строку из 10 символов ‘A’BUF DB 100 DUP (?)— резервирует 100 неинициализированных байт
Особенности использования DB и DUP
При работе с DB и DUP важно учитывать несколько моментов:
- DB всегда оперирует байтами. Для определения слов (2 байта) используется DW, для двойных слов — DD.
- DUP может использоваться с любыми директивами определения данных (DB, DW, DD и т.д.).
- Внутри DUP можно использовать выражения:
ARR DB 10 DUP (1, 2, 3)— создаст массив из 30 байт - Символ ? в DUP означает неинициализированные данные.
Правильное объявление массивов с помощью DB и DUP
При объявлении массивов с помощью DB и DUP следует придерживаться нескольких правил:

- Используйте DUP для создания больших массивов с повторяющимися значениями
- Для небольших массивов с разными значениями используйте просто DB с перечислением элементов
- Используйте ? внутри DUP, если начальные значения не важны
- Помните о размере элементов — DB для байт, DW для слов и т.д.
Примеры правильного объявления массивов:
SMALL_ARR DB 1, 2, 3, 4, 5 ; Маленький массив с разными значениями
BIG_ARR DB 1000 DUP (0) ; Большой массив, заполненный нулями
MATRIX DB 10 DUP (10 DUP (0)) ; Двумерный массив 10x10
BUFFER DB 512 DUP (?) ; Буфер без начальной инициализации
Инициализация данных с использованием DB и DUP
DB и DUP предоставляют гибкие возможности для инициализации данных в ассемблерных программах. Рассмотрим некоторые типичные сценарии:
Инициализация строк
Для инициализации строк обычно используется DB без DUP:
MESSAGE DB 'Hello, World!', 0 ; Строка, завершающаяся нулем
NAME DB 'John Doe' ; Строка фиксированной длины
Инициализация числовых массивов
Для числовых массивов можно использовать как DB, так и DUP:

NUMBERS DB 1, 2, 3, 4, 5 ; Массив из 5 чисел
HUNDREDS DB 100 DUP (100) ; 100 элементов со значением 100
SEQUENCE DB 10 DUP (1, 2, 3, 4, 5) ; Повторяющаяся последовательность
Инициализация структур данных
DB и DUP можно комбинировать для инициализации сложных структур данных:
PERSON DB 'John Doe', 0, 30, 5 DUP (0) ; Имя, возраст и 5 байт дополнительных данных
TEAM DB 10 DUP ('Player', 0, 25, 0) ; Массив из 10 записей игроков
Типичные ошибки при использовании DB и DUP
При работе с DB и DUP новички часто допускают следующие ошибки:
- Использование DB для значений больше 255 без учета переполнения
- Забывание о том, что DUP создает непрерывный блок данных
- Неправильное использование кавычек при определении строк
- Путаница между DB, DW и DD при определении данных разного размера
Пример некорректного кода:
WRONG_VAL DB 1000 ; Будет интерпретировано как два байта: 232 и 3
BAD_STR DB "Hello' ; Неправильные кавычки
MIXED_ARR DB 5 DUP (1, 2) ; Создаст массив из 10 байт, а не 5
Оптимизация использования памяти с помощью DB и DUP
- Используйте DUP для больших блоков с одинаковыми значениями вместо их явного перечисления
- Группируйте связанные данные для лучшей локальности кэша
- Используйте ? для неинициализированных данных, чтобы уменьшить размер исполняемого файла
- Выравнивайте данные по границам слов или двойных слов для оптимизации доступа
Пример оптимизированного кода:
ALIGN 4 ; Выравнивание по границе двойного слова
DATA_START:
COUNTER DD 0 ; Счетчик (4 байта)
FLAGS DB 16 DUP (0) ; Флаги (16 байт)
BUFFER DB 1024 DUP (?) ; Большой неинициализированный буфер
DATA_END:
Заключение: важность понимания DB и DUP в ассемблере
Директива DB и оператор DUP являются фундаментальными инструментами в ассемблерном программировании для работы с данными. Их правильное использование позволяет эффективно управлять памятью, создавать сложные структуры данных и оптимизировать производительность программ.
Ключевые моменты для запоминания:
- DB всегда работает с байтами
- DUP позволяет эффективно создавать большие массивы
- Комбинация DB и DUP предоставляет гибкие возможности для инициализации данных
- Внимательно следите за размером данных и возможным переполнением
- Используйте DB и DUP для оптимизации использования памяти
Глубокое понимание этих концепций является важным шагом на пути к мастерству в ассемблерном программировании.

Типы данных в ассемблере
Данные – числа и закодированные символы, используемые в качестве операндов команд.
Основные типы данных в ассемблере
| Тип | Директива | Количество байт |
| Байт | DB | 1 |
| Слово | DW | 2 |
| Двойное слово | DD | 4 |
| 8 байт | DQ | 8 |
| 10 байт | DT | 10 |
Данные, обрабатываемые вычислительной машиной, можно разделить на 4 группы:
- целочисленные;
- вещественные.
- символьные;
- логические;
Целочисленные данные
Целые числа в ассемблере могут быть представлены в 1-байтной, 2-байтной, 4-байтной или 8-байтной форме. Целочисленные данные могут представляться в знаковой и беззнаковой форме.
Беззнаковые целые числа представляются в виде последовательности битов в диапазоне от 0 до 2n-1, где n- количество занимаемых битов.
Знаковые целые числа представляются в диапазоне -2n-1 … +2n-1-1. При этом старший бит данного отводится под знак числа (0 соответствует положительному числу, 1 – отрицательному).
Вещественные данные
Вещественные данные могут быть 4, 8 или 10-байтными и обрабатываются математическим сопроцессором.
Логические данные
Логические данные представляют собой бит информации и могут записываться в виде последовательности битов. Каждый бит может принимать значение 0 (ЛОЖЬ) или 1 (ИСТИНА). Логические данные могут начинаться с любой позиции в байте.
Символьные данные
Символьные данные задаются в кодах и имеют длину, как правило, 1 байт (для кодировки ASCII) или 2 байта (для кодировки Unicode) .
Числа в двоично-десятичном формате
В двоично-десятичном коде представляются беззнаковые целые числа, кодирующие цифры от 0 до 9. Числа в двоично-десятичном формате могут использоваться в одном из двух видов:
- упакованном;
- неупакованном.

В неупакованном виде в каждом байте хранится одна цифра, размещенная в младшей половине байта (биты 3…0).
Упакованный вид допускает хранение двух десятичных цифр в одном байте, причем старшая половина байта отводится под старший разряд.
Числовые константы
Числовые константы используются для обозначения арифметических операндов и адресов памяти. Для числовых констант в Ассемблере могут использоваться следующие числовые форматы.
Десятичный формат – допускает использование десятичных цифр от 0 до 9 и обозначается последней буквой d, которую можно не указывать, например, 125 или 125d. Ассемблер сам преобразует значения в десятичном формате в объектный шестнадцатеричный код и записывает байты в обратной последовательности для реализации прямой адресации.
a DB 12
Шестнадцатеричный формат – допускает использование шестнадцатеричных цифр от 0 до F и обозначается последней буквой h, например 7Dh. Так как ассемблер полагает, что с буквы начинаются идентификаторы, то первым символом шестнадцатеричной константы должна быть цифра от 0 до 9. Например, 0Eh.
Например, 0Eh.
a DB 0Ch
Двоичный формат – допускает использование цифр 0 и 1 и обозначается последней буквой b. Двоичный формат обычно используется для более четкого представления битовых значений в логических командах (AND, OR, XOR).
a DB 00001100b
Восьмеричный формат – допускает использование цифр от 0 до 7 и обозначается последней буквой q или o, например, 253q.
a DB 14q
Массивы и цепочки
Массивом называется последовательный набор однотипных данных, именованный одним идентификатором.
Цепочка — массив, имеющий фиксированный набор начальных значений.
Примеры инициализации цепочек
M1 DD 0,1,2,3,4,5,6,7,8,9
M2 DD 0,1,2,3
DD 4,5,6,7
DD 8,9
Каждая из записей выделяет десять последовательных 4-байтных ячеек памяти и записывает в них значения 0, 1, 2, 3, 4, 5, 6, 7, 8, 9.
Идентификатор M1 определяет смещение начала этой области в сегменте данных .DATA.
Для инициализации всех элементов массива одинаковыми значениями используется оператор DUP:
Идентификатор Тип Размер DUP (Значение)
Идентификатор — имя массива;
Тип — определяет количество байт, занимаемое одним элементом;
Размер — константа, характеризующая количество элементов в массиве
Значение — начальное значение элементов.
Например
a DD 20 DUP (0)
описывает массив a из 20 элементов, начальные значения которых равны 0.
Если необходимо выделить память, но не инициализировать ее, в качестве поля Значение используется знак ?. Например,
b DD 20 DUP(?)
Символьные строки
Символьные строки представляют собой набор символов для вывода на экран. Содержимое строки отмечается
- одиночными кавычками », например, ‘строка’
- двойными кавычками «», например «строка»
Символьная строка определяется только директивой DB, в которой указывается более одного символа в последовательности слева направо.
Символьная строка, предназначенная для корректного вывода, должна заканчиваться нуль-символом ‘\0’ с кодом, равным 0.
Str DB ‘Привет всем!’, 0
Для перевода строки могут использоваться символы
- возврат каретки с кодом 13 (0Dh)
- перевод строки с кодом 10 (0Ah).
Stroka DB «Привет», 13, 10, 0
Назад
Назад: Язык ассемблера
Описание типов данных в Ассемблере Intel
Для описания типов данных используются директивы резервирования и инициализации памяти:
DB – 1 байт – 8 бит,
DW – 2 байта – 16 бит,
DD – 4 байта – 32 бита,
DQ – 8 байт – 64 бита,
DT – 10 байт – 80 бит.

Примечание. Дополнительными директивами являются директивы, описывающие данные длиной 6 байт (для дальнего указателя – 2 байта селектор и 4 байта смещение):
DF – 6 байт – 48 бит,
DP – 6 байт – 48 бит,
Примеры:
The_byte DB 5 ; 0 … 255 (28-1)
The_word DW 3000 ; 0 … 65 535 (216-1)
The_dword DD 12345678 ; 0 … 4 294 967 295 (2 32-1)
The_qword DQ 1122334455667788 ; 0 … (264-1)
The_ptr DP 112233445566 ; 0 … (248-1)
При резервировании
памяти можно задавать различное
количество элементов данных, инициализируя
их значения или не инициализируя,
присваивая имя или не присваивая.
Для описания символов в коде ASCII
Ассемблер допускает записывать значения
байт в кавычках.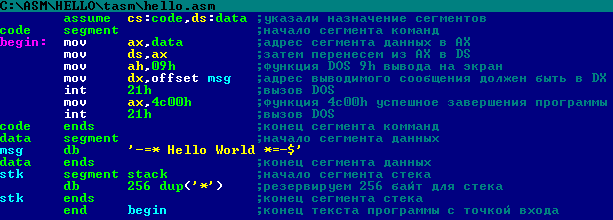
Примеры:
DB ? ; один байт без инициализации и имени
DB 5, 0Fh ; два байта без имени с инициализацией
DB 5,?,7 ; три байта, два с инициализацией, один – без
Five_bytes DB 0,0,0,0,0 ; область 5 байт, значения всех нулевые
The_ptr DB 1122334455 ;
0 … (2
Str DB ‘Строка текста’ ; 13 байт
DB ‘5’ ; один байт, равный 53 или 35h или ‘5’
DB 5 ; один байт, равный 5
При заполнении памяти повторяющимися значениями используется оператор dup:
Примеры:
Buffer DB 200h dup (0) ; буфер 512 байт инициализирован нулями.
String_buf DB 78 dup (‘ ‘) ; буфер приема строки заполнен пробелами.
К одним и тем же
ячейкам памяти можно обращаться как к
данным различных типов. Один из способов
описания таких ячеек памяти предполагает
использование директивы LABEL.
Один из способов
описания таких ячеек памяти предполагает
использование директивы LABEL.
Примеры:
Bytes label byte
Words label word
DB 0,1,2,3,4,5 ; определены шесть байт или три слова
; слова равны: 0100h, 0302h, 0504h
Обращение к ячейкам как к данным нужного типа можно выполнять и без описания их в директиве LABEL, если явно указать тип данных в команде, используя оператор PTR.
Примеры:
b_or_w db 1,2,3,4 ; данные
…
mov al, byte ptr b_or_w ; al := 01
mov ax, word ptr b_or_w ; ax := 0201h
mov al, byte ptr b_or_w+3 ; al := 04
mov ax, word ptr b_or_w+2 ; ax := 0403h
w_or_b dw 0201h,0403h ; те же данные
…
mov al,byte ptr w_or_b+3 ; al := 04
mov ax,w_or_b+2 ; ax := 0403h
Ниже приведен
пример программы на языке Ассемблер с
различными типами данных, описанными
в сегменте данных. Сегмент данных выделен
полужирным шрифтом.
Сегмент данных выделен
полужирным шрифтом.
На первой странице листинга программы, приведенной ниже, можно увидеть результаты трансляции рассматриваемой программы. Описанные в исходном модуле данные выделены.
Turbo Assembler Version 2.51 03/07/00 12:25:41 Page 1
prog.ASM
1 name prog
2
3 0000 .model small
4
5 0000 .data
6 ;———————
7 0000 42 65 67 69 6E 20 6F+ db ‘Begin of DATAseg’
8 66 20 44 41 54 41 73+
9 65 67
10
11 0010 12 x1 db 12h
12 0011 1234 x2 dw 1234h
13 0013 12345678 x3 dd 12345678h
14 0017 0123456789ABCDEF x4 dq 0123456789ABCDEFh
15 001F 112233445566778899AA x5 dt 112233445566778899AAh
16 0029 112233445566 x6 dp 112233445566h
17 002F AABBCCDDEEFF x7 df 0AABBCCDDEEFFh
18
19 0035 53 74 72 69 6E 67 20+ s1 db ‘String 1’
20 31
21 003D 2A db ‘*’
22 003E ?? db ?
23 003F ?? db ?
24
25 0040 10*(02 03) b1 db 10h dup (2,3)
26
27 0060 . code
code
28 ;———————
29 0000 main proc far
30 0000 start:
31 0000 B8 0000s mov ax,@data
32 0003 8E D8 mov ds,ax
33
34 0005 exit:
35 0005 B8 4C00 mov ax,4C00h ; exit
36 0008 CD 21 int 21h
37
38 000A main endp
39 ;———————
40 end start
На второй странице листинга приведена таблица символических имен с указанием их адресов. Так, адрес переменной x4 равен 0017h, т. е. находится в 23-ей ячейке относительно начала сегмента данных, который находится в группе DGROUP.
Turbo Assembler Version 2.51 03/07/00 12:25:41 Page 2
Symbol Table
Symbol Name Type Value
??DATE Text «03/07/00»
??FILENAME Text «prog «
??TIME Text «12:25:41»
??VERSION Number 0205
@CODE Text _TEXT
@CODESIZE Text 0
@CPU Text 0101H
@CURSEG Text _TEXT
@DATA Text DGROUP
@DATASIZE Text 0
@FILENAME Text PROG
@MODEL Text 2
@WORDSIZE Text 2
B1 Byte DGROUP:0040
EXIT Near _TEXT:0005
MAIN Far _TEXT:0000
S1 Byte DGROUP:0035
START Near _TEXT:0000
X1 Byte DGROUP:0010
X2 Word DGROUP:0011
X3 Dword DGROUP:0013
X4 Qword DGROUP:0017
X5 Tbyte DGROUP:001F
X6 Pword DGROUP:0029
X7 Pword DGROUP:002F
Groups & Segments Bit Size Align Combine Class
DGROUP Group
_DATA 16 0060 Word Public DATA
_TEXT 16 000A Word Public CODE
Вид модуля в
отладчике AFD
показан на рис. 1.
1.
В ыделенная внизу область – это сегмент данных программы. Адреса данных складываются из двух шестнадцатеричных чисел: в левом столбце и верхней строке над данными. Так, начальный байт имеет адрес 0000h, а его значение равно 42h, или ‘B’ лат., первый символ строки String1 имеет адрес 0030h + 5h = 0035h, а его значение равно 53h или ‘S’ лат. Справа от шестнадцатеричного дампа памяти расположено ASCII-представление этих данных (символьное представление, удобное для чтения текстовых констант).
Рисунок 1
С
егмент
данных в модуле приведен на рис.2. Показаны
зарезервированные в исходном модуле
области данных. Обратное по отношению
с записью в исходном модуле расположение
байтов – характерный эффект, связанный
с представлением ячеек памяти в окне
отладчика слева направо (от младших к
старшим). Так, двойное слово x3,
значение которого инициализировано
шестнадцатеричной константой 12345678h,
занимает байты с адресами 13, 14, 15, 16. При
этом две младшие цифры числа (7 и 8)
занимают младший байт с адресом 13,
следующие две цифры (5 и 6) занимают
следующий байт с адресом 14 и т.д. Строка
текста в окне отладчика читается так
же, как и в исходном модуле, т.к. расположение
текста в памяти – от начала текста в
младших адресах к концу текста в старших
адресах – совпадает с естественным
расположением читаемого текста слева
направо (см. рис.1). Байты с адресами 3E,
3F,
значения которых равны нулю, не
инициализируются программой. Байты с
адресами 40-5F
занимают область, зарезервированную
с использованием оператора dup.
Так, двойное слово x3,
значение которого инициализировано
шестнадцатеричной константой 12345678h,
занимает байты с адресами 13, 14, 15, 16. При
этом две младшие цифры числа (7 и 8)
занимают младший байт с адресом 13,
следующие две цифры (5 и 6) занимают
следующий байт с адресом 14 и т.д. Строка
текста в окне отладчика читается так
же, как и в исходном модуле, т.к. расположение
текста в памяти – от начала текста в
младших адресах к концу текста в старших
адресах – совпадает с естественным
расположением читаемого текста слева
направо (см. рис.1). Байты с адресами 3E,
3F,
значения которых равны нулю, не
инициализируются программой. Байты с
адресами 40-5F
занимают область, зарезервированную
с использованием оператора dup.
Рисунок 2
Вид модуля в отладчике TurboDebuger 5.0 показан на рис.3.
Рисунок 3
Сборка— Что означает `dup (?)` в TASM?
спросил
Изменено 1 год, 9 месяцев назад
Просмотрено 60 тысяч раз
У меня есть этот код, но я не знаком с синтаксисом.
STACK16_SIZE = 100 ч stack16 db STACK16_SIZE дубликат (?)
Я думаю, что dup означает, что мы объявляем переменную типа массив, так как это стек, но я не уверен. Итак, что же означает dup в TASM?
- в сборе
- x86
- тасм
0
STACK16_SIZE dup (?) означает дублирование данных в скобках STACK16_SIZE раз. Это эквивалентно написанию ?, ?, ?, ?, … (100ч раз)
Данные в скобках являются «неинициализированными данными». То есть память выделяется, но при загрузке не устанавливается какое-либо конкретное значение.
Сборка не предоставляет массив «тип». Если это так, это только для отладчиков для использования при проверке данных. Однако в этом фрагменте кода stack16 — это символ с адресом, начинающим блок памяти байтов, что противоречит здравому смыслу и потенциально может стать источником тонкой ошибки. Для стека ЦП его действительно следует определять как 16-битные слова (
Для стека ЦП его действительно следует определять как 16-битные слова ( dw ) или 32-битные слова ( dd ).
5
Начнем с другого примера. Вы можете прочитать 20 DUP (0) как «двадцать нулевых дубликатов». Все выражение INPUTSTR DB 20 DUP (0) эквивалентно INPUTSTR DB 0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0, 0,0,0,0 .
Теперь, потому что ? означает «неинициализированное значение», 20 DUP (?) даст вам 20 неинициализированных байтов. И в этом конкретном случае, когда у вас есть STACK16_SIZE DUP (?) , вы получите STACK16_SIZE неинициализированных байтов.
Этот синтаксис не специфичен для TASM. MASM также поддерживает это; загляните в официальный справочник MASM от Microsoft.
? означает отсутствие определенного значения, неинициализированное. DUP означает дубликат.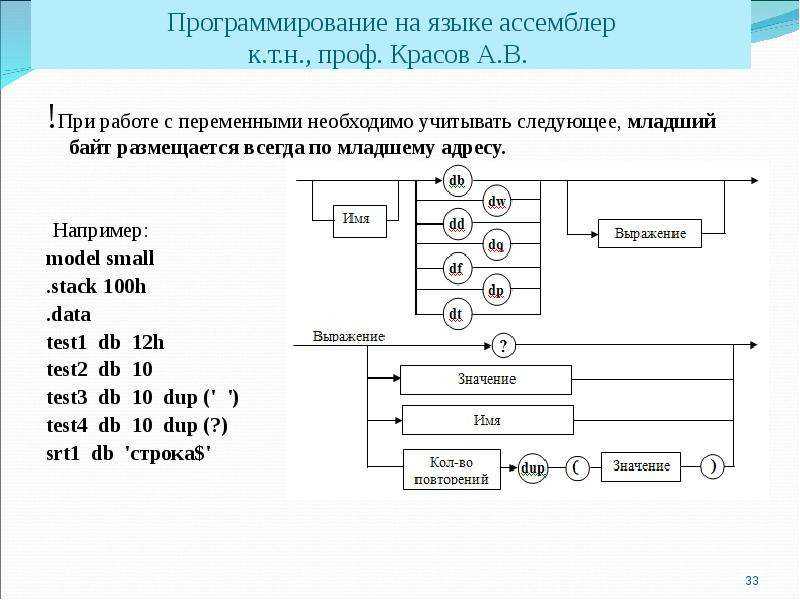
Таким образом, вы получаете 100h неинициализированных байтов.
Зарегистрируйтесь или войдите в систему
Зарегистрируйтесь с помощью Google
Зарегистрироваться через Facebook
Зарегистрируйтесь, используя адрес электронной почты и пароль
Опубликовать как гость
Электронная почта
Обязательно, но не отображается
Опубликовать как гость
Электронная почта
Требуется, но не отображается
x86 16 — Относительно директив DB и DUP сборки 8086
Задавать вопрос
спросил
Изменено 2 года, 9 месяцев назад
Просмотрено 14 тысяч раз
Итак, я столкнулся с проблемой, которая заставила меня усомниться в моем базовом понимании DB (определить байт) и DUP (дубликат). Как я их понял:
Как я их понял:
-
NUM DB 34создаст переменную с именем NUM и присвоит ей значение 34. Например, Cchar NUM = 34;1 -
NUM DB 34 DUP(?)даст мне массив из 34 элементов, каждый из которых не назначен. -
NUM DB 3 DUP(4)даст мне массив с именем NUM с 3 элементами: 4, 4, 4.
Это правильно?
В моем учебнике я встретил:
PRINT_SELECT БД 133 (?)
ДБ 123 (?)
Это просто ошибка в учебнике, или эти две строчки кода означают совсем другое?
Сноска 1: (примечание редактора): NUM = 34 в ассемблере определяет постоянную времени сборки, не хранящуюся в памяти данных. В ассемблере синтаксиса MASM в некоторых контекстах он работает аналогично переменной. а например mul NUM работает только с источником памяти, а не с непосредственным, в то время как imul eax, ecx, NUM или shl ax, NUM , или mov ax, NUM/2 работает только с непосредственным, а не источник памяти.