Как создать простой синтезатор на Python. Какие существуют современные подходы к генерации звука с помощью ИИ. Как работает модель AudioGPT для синтеза речи и музыки. Каковы перспективы развития технологий генерации звука.
Создание простого синтезатора на Python
Программная генерация звука — это увлекательная область на стыке программирования и акустики. Рассмотрим, как создать простой синтезатор на Python, который позволит генерировать звуки разной частоты, длительности и громкости.
Для начала нам понадобятся следующие библиотеки:
- numpy — для математических вычислений
- pyaudio — для работы со звуком
- pygame — для обработки нажатий клавиш
Основная функция для генерации звука выглядит следующим образом:
«`python import numpy as np SAMPLE_RATE = 44100 S_16BIT = 2 ** 16 def generate_sample(freq, duration, volume): amplitude = np.round(S_16BIT * volume) total_samples = np.round(SAMPLE_RATE * duration) w = 2.0 * np.pi * freq / SAMPLE_RATE k = np.arange(0, total_samples) return np.round(amplitude * np.sin(k * w)) «`
- freq — частота звука в герцах
- duration — длительность звука в секундах
- volume — громкость звука от 0 до 1
Как работает эта функция генерации звука. Она создает синусоидальную волну заданной частоты, длительности и амплитуды (громкости). Результатом является массив значений, представляющих звуковую волну.
Расширение функциональности синтезатора
Чтобы превратить эту базовую функцию в полноценный синтезатор, нужно добавить несколько дополнительных компонентов:
- Функцию для генерации нот первой октавы
- Настройку PyAudio для вывода звука
- Обработку нажатий клавиш с помощью Pygame
Давайте рассмотрим каждый из этих компонентов подробнее.
Генерация нот первой октавы
Для генерации нот первой октавы мы можем использовать массив частот и функцию, которая будет создавать звуковые сэмплы для каждой ноты:
«`python import numpy as np SAMPLE_RATE = 44100 S_16BIT = 2 ** 16 def generate_sample(freq, duration, volume): amplitude = np.round(S_16BIT * volume) total_samples = np.round(SAMPLE_RATE * duration) w = 2.0 * np.pi * freq / SAMPLE_RATE k = np.arange(0, total_samples) return np.round(amplitude * np.sin(k * w)) freq_array = np.array([261.63, 293.66, 329.63, 349.23, 392.00, 440.00, 493.88]) def generate_tones(duration): tones = [] for freq in freq_array: tone = np.array(generate_sample(freq, duration, 1.0), dtype=np.int16) tones.append(tone) return tones «`Как работает функция generate_tones. Она создает список звуковых сэмплов для каждой ноты первой октавы, используя заданные частоты. Эти сэмплы затем можно воспроизводить при нажатии соответствующих клавиш.
Настройка PyAudio для вывода звука
Чтобы воспроизвести сгенерированные звуки, нам нужно настроить PyAudio:
«`python import numpy as np import pyaudio as pa SAMPLE_RATE = 44100 S_16BIT = 2 ** 16 def generate_sample(freq, duration, volume): amplitude = np.round(S_16BIT * volume) total_samples = np.round(SAMPLE_RATE * duration) w = 2.0 * np.pi * freq / SAMPLE_RATE k = np.arange(0, total_samples) return np.round(amplitude * np.sin(k * w)) freq_array = np.array([261.63, 293.66, 329.63, 349.23, 392.00, 440.00, 493.88]) def generate_tones(duration): tones = [] for freq in freq_array: tone = np.array(generate_sample(freq, duration, 1.0), dtype=np.int16) tones.append(tone) return tones # Настройка PyAudio p = pa.PyAudio() stream = p.open(format=p.get_format_from_width(width=2), channels=2, rate=SAMPLE_RATE, output=True) «`Эта настройка создает поток PyAudio, который мы будем использовать для вывода звука. Параметры настройки включают формат (16-битный), количество каналов (стерео) и частоту дискретизации.

Модели искусственного интеллекта для генерации звука
В последние годы искусственный интеллект произвел революцию в области генерации звука. Рассмотрим некоторые передовые модели и подходы.
AudioGPT: генерация речи и музыки на основе трансформеров
AudioGPT — это модель, основанная на архитектуре трансформеров, которая способна генерировать как речь, так и музыку. Как она работает.
- Модель принимает на вход текст в качестве входных данных
- Текст преобразуется в последовательность токенов
- Трансформер обрабатывает эту последовательность, изучая зависимости между различными частями
- На выходе генерируется аудиосигнал, соответствующий входному тексту
Какие преимущества дает использование архитектуры трансформеров для генерации звука. Трансформеры способны улавливать сложные зависимости в данных, что позволяет генерировать более естественно звучащую речь и музыку.
Датасет для обучения AudioGPT
AudioGPT обучалась на датасете LJSpeech. Почему выбор датасета так важен для качества генерируемого звука.
- Датасет содержит более 13 000 аудиозаписей общей продолжительностью около 24 часов
- Все записи сделаны одним женским голосом на английском языке
- Для каждой аудиозаписи предоставлена текстовая транскрипция
Такой датасет позволяет модели изучить связь между текстом и соответствующим ему звучанием, что критически важно для качественного синтеза речи.
Оценка качества генерируемого звука
Как оценивается качество звука, генерируемого ИИ-моделями. Одним из основных методов является MOS (Mean Opinion Score).
- MOS — это среднее значение оценок качества от группы экспертов или респондентов
- Оценка производится по шкале от 1 до 5, где 1 — очень плохо, 3 — средне, 5 — отлично
- AudioGPT показала MOS 3,7 для задачи генерации речи
Что означает полученная оценка. MOS 3,7 указывает на то, что качество генерируемой речи выше среднего, но все еще есть пространство для улучшения.
Перспективы развития технологий генерации звука
Какие направления развития технологий генерации звука наиболее перспективны.
- Улучшение качества синтезируемой речи и музыки
- Генерация звуков окружающей среды для виртуальной и дополненной реальности
- Создание персонализированных голосовых ассистентов
- Автоматическое озвучивание текста для аудиокниг и видеоконтента
Как эти технологии могут изменить нашу повседневную жизнь. Представьте себе персонализированного голосового ассистента, который звучит как ваш любимый актер, или систему, способную мгновенно озвучить любую книгу голосом, который вы выберете.
Этические аспекты генерации звука с помощью ИИ
Развитие технологий генерации звука с помощью ИИ поднимает ряд этических вопросов. Какие проблемы могут возникнуть.
- Возможность создания фейковых аудиозаписей, имитирующих голоса реальных людей
- Вопросы авторского права при использовании голосов известных личностей
- Проблемы приватности при сборе голосовых данных для обучения моделей
Как можно решить эти этические проблемы. Необходима разработка четких правил и стандартов использования технологий генерации звука, а также создание механизмов верификации подлинности аудиозаписей.
Применение технологий генерации звука в различных отраслях
Технологии генерации звука находят применение во многих сферах. Рассмотрим некоторые из них:
Индустрия развлечений
Как генерация звука с помощью ИИ меняет индустрию развлечений.
- Создание саундтреков для фильмов и видеоигр
- Автоматическое озвучивание анимационных персонажей
- Генерация фоновой музыки для стримов и подкастов
Образование
Какие возможности открывают технологии генерации звука в сфере образования.
- Создание аудиоверсий учебных материалов
- Разработка интерактивных обучающих программ с голосовым сопровождением
- Помощь в изучении иностранных языков через генерацию речи носителей языка
Медицина
Как генерация звука может применяться в медицине.
- Создание голосовых протезов для людей, потерявших способность говорить
- Разработка систем ранней диагностики заболеваний по голосу
- Генерация успокаивающих звуков для терапии стресса и тревожности
Эти примеры показывают, насколько широко могут применяться технологии генерации звука в различных сферах нашей жизни.
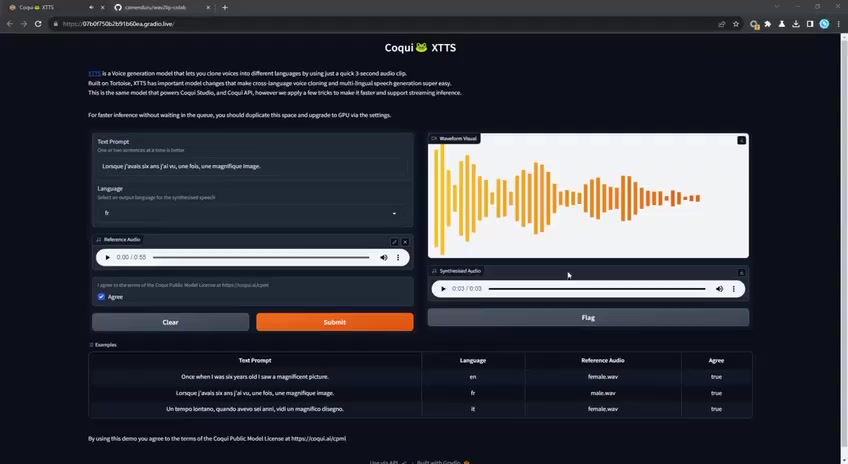
Пишем простой синтезатор на Python
В предыдущем посте я писал про генерацию звука на Rust`е для азбуки Морзе.
Сегодняшняя статья будет короткой, но в ней мы рассмотрим написание упрощенной версии программного синтезатора.
Ну что же, поехали!
Не будем изобретать что-то новое, а возьмём функцию генерации звука из прошлой статьи и адаптируем её под python:
import numpy as np
# частота дискретизации
SAMPLE_RATE = 44100
# 16-ти битный звук (2 ** 16 -- максимальное значение для int16)
S_16BIT = 2 ** 16
def generate_sample(freq, duration, volume):
# амплитуда
amplitude = np.round(S_16BIT * volume)
# длительность генерируемого звука в сэмплах
total_samples = np.round(SAMPLE_RATE * duration)
# частоте дискретизации (пересчитанная)
w = 2.0 * np.pi * freq / SAMPLE_RATE
# массив сэмплов
k = np.arange(0, total_samples)
# массив значений функции (с округлением)
return np. round(amplitude * np.sin(k * w))
round(amplitude * np.sin(k * w))
 round(amplitude * np.sin(k * w))
round(amplitude * np.sin(k * w))
Теперь, когда у нас есть функция генерации звука любой частоты, длительности и громкости, остаётся сгененрировать ноты из первой октавы и подать их на устройство воспроизведения.
Запишем частоты нот первой октавы в массив и напишем функцию, которая будет их генерировать
# до ре ми фа соль ля си
freq_array = np.array([261.63, 293.66, 329.63, 349.23, 392.00, 440.00, 493.88])
def generate_tones(duration):
tones = []
for freq in freq_array:
# np.array нужен для преобразования данных под формат 16 бит (dtype=np.int16)
tone = np.array(generate_sample(freq, duration, 1.0), dtype=np.int16)
tones.append(tone)
return tones
Остаётся последнее — вывести звук.
Для вывода звука будем использовать кроссплатформенную библиотеку PyAudio.
Так же нам понадобится как-то отслеживать нажатия клавиш, чтобы наша программа была похожа на настоящий синтезатор. Поэтому я взял pygame, т.к. он прост в работе. Вы же можете использовать то, что вам больше нравится!
Поэтому я взял pygame, т.к. он прост в работе. Вы же можете использовать то, что вам больше нравится!
Не будем медлить. Начнём!
import pyaudio as pa
import pygame
# ... место для предыдущего кода ...
# наши клавиши
key_names = ['a', 's', 'd', 'f', 'g', 'h', 'j']
# коды клавиш
key_list = list(map(lambda x: ord(x), key_names))
# состояние клавиш (нажато/не нажато)
key_dict = dict([(key, False) for key in key_list])
if __name__ == '__main__':
# длительность звука
duration_tone = 1/64.0
# генерируем тона с заданной длительностью
tones = generate_tones(duration_tone)
# инициализируем
p = pa.PyAudio()
# создаём поток для вывода
stream = p.open(format=p.get_format_from_width(width=2),
channels=2, rate=SAMPLE_RATE, output=True)
# размер окна pygame
window_size = 320, 240
# настраиваем экран
screen = pygame.display.set_mode(window_size)
pygame.display.flip()
running = True
while running:
# обрабатываем события
for event in pygame.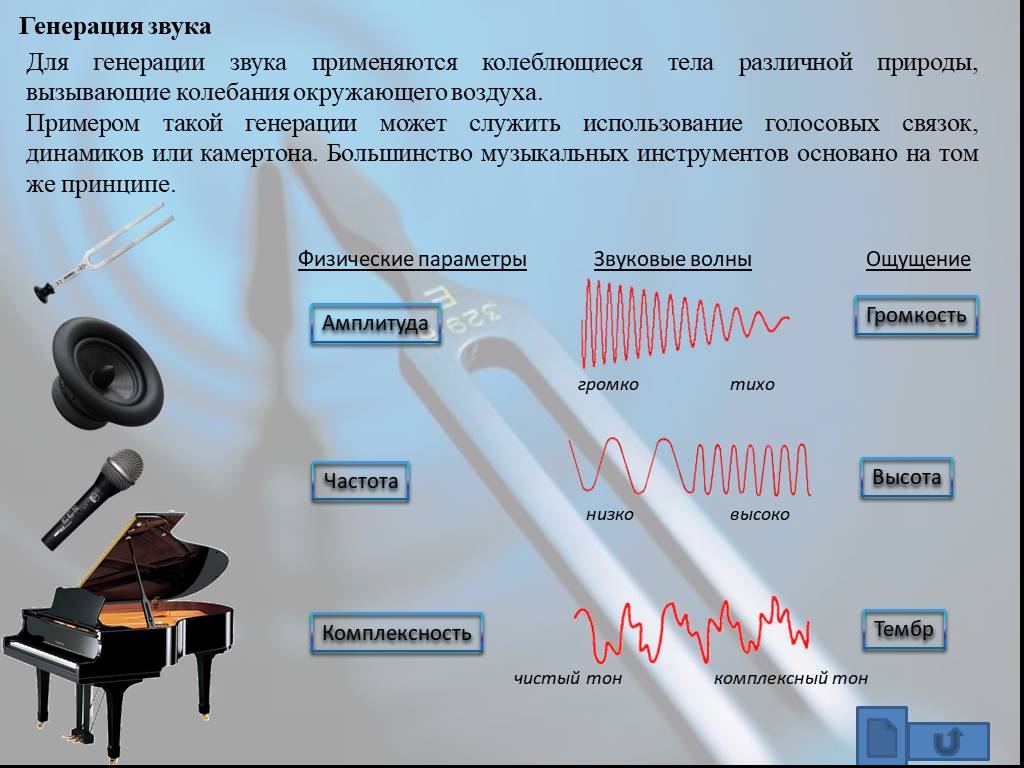 event.get():
# событие закрытия окна
if event.type == pygame.QUIT:
running = False
# нажатия клавиш
if event.type == pygame.KEYDOWN:
if event.key == ord('q'):
running = False
# обрабатываем нажатые клавиши по списку key_list
for (index, key) in enumerate(key_list):
if event.key == key:
# зажимаем клавишу
key_dict[key] = True
# отпускание клавиш
if event.type == pygame.KEYUP:
for (index, key) in enumerate(key_list):
if event.key == key:
# отпускаем клавишу
key_dict[key] = False
# обрабатываем нажатые клавиши
for (index, key) in enumerate(key_list):
# если клавиша нажата
if key_dict[key] == True:
# то выводим звук на устройство
stream.
event.get():
# событие закрытия окна
if event.type == pygame.QUIT:
running = False
# нажатия клавиш
if event.type == pygame.KEYDOWN:
if event.key == ord('q'):
running = False
# обрабатываем нажатые клавиши по списку key_list
for (index, key) in enumerate(key_list):
if event.key == key:
# зажимаем клавишу
key_dict[key] = True
# отпускание клавиш
if event.type == pygame.KEYUP:
for (index, key) in enumerate(key_list):
if event.key == key:
# отпускаем клавишу
key_dict[key] = False
# обрабатываем нажатые клавиши
for (index, key) in enumerate(key_list):
# если клавиша нажата
if key_dict[key] == True:
# то выводим звук на устройство
stream. write(tones[index])
# закрываем окно
pygame.quit()
# останавливаем устройство
stream.stop_stream()
# завершаем работу PyAudio
stream.close()
p.terminate()
write(tones[index])
# закрываем окно
pygame.quit()
# останавливаем устройство
stream.stop_stream()
# завершаем работу PyAudio
stream.close()
p.terminate()
Вот и всё. Наш минимальный синтезатор готов!
[1] Предыдущий пост
[2] Исходный код с модификациями
[3] Документация по PyAudio
[4] Документация по pygame
[5] Программный синтез звука на ранних персональных компьютерах #1
[6] Программный синтез звука на ранних персональных компьютерах #2
AudioGPT модель генерации звуков из текста на основе трансформера
- State-of-the-art
AudioGPT — text-to-speech и text-to-audio модель от OpenAI, основанная на серии языковых моделей GPT. AudioGPT способна генерировать аудио-сэмплы с естественно звучащей речью, музыку и выполнять задачи классификации. Модель может оказать значительное влияние на приложения, использующие голосовых помощников, синтез речи из текста и генерацию музыки. Это первая успешная попытка применения архитектуры трансформера к обработке аудио.
Это первая успешная попытка применения архитектуры трансформера к обработке аудио.
Исходный код модели
Разработчики выложили код модели в открытом доступе на Github. Репозиторий содержит реализацию модели на PyTorch и TensorFlow, а также скрипты для обработки данных и обучения модели. Кроме того, в репозитории также содержится набор данных, на котором была обучена модель, а также примеры использования модели для генерации аудио на основе заданных текстовых входных данных.
Репозиторий не является официальным источником кода модели AudioGPT, но может быть полезным для тех, кто заинтересован в использовании этой модели для своих задач.
Обучение
AudioGPT использует текст в качестве входных данных и обучается на любом языке. Модель принимает на вход текстовую последовательность, которая может быть произвольной длины — предложения, абзацы, статьи или диалоги, и генерирует соответствующую аудиозапись, которая соответствует заданному тексту.
В процессе обучения модели входные данные обычно подвергаются предварительной обработке, такой как токенизация и векторизация, чтобы представить текст в виде числовых последовательностей, которые могут быть использованы для обучения модели.
Архитектура AudioGPT
Модель AudioGPT построена на архитектуре трансформера, которая состоит из слоев само-внимания и нейронных сетей с обратной связью. Эта архитектура способна улавливать неочевидные корелляции и производить последовательные выводы. В AudioGPT архитектура используется для моделирования зависимостей между различными частями звукового сигнала, такими как частотные и временные компоненты. Модель обучается на большом наборе аудио-сэмплов, что позволяет ей изучать статистические закономерности, характерные для естественных звуков.
Датасет
AudioGPT обучалась на датасете LJSpeech. Это набор из более чем 13 000 аудиозаписей, продолжительностью в общей сложности около 24 часов (средняя длина семпла — 6,6 секунд). Аудиозаписи в наборе данных были записаны женским голосом на английском языке, для каждой аудиозаписи предоставлены транскрипции в виде текстовых файлов.
Результаты
Результаты оценивались по метрике MOS (Mean Opinion Score) — это среднее значение оценок качества, которые дает группа экспертов или респондентов на шкале от 1 до 5, где 1 — очень плохо, 3 — средне, 5 — отлично.
- Генерация звука: модель была обучена генерировать звуковые сигналы различной продолжительности. Среди сгенерированных звуковых сигналов были голоса людей, музыкальные композиции, шумы и звуки природы. В задаче генерации звука AudioGPT показала MOS в размере 3,57.
- Классификация звука: AudioGPT достигла точности классификации на уровне 90%. Ей было предложено распознать различные звуковые сигналы, включая голоса людей, звуки животных, шумы и музыку.
- Генерация речи: AudioGPT показала MOS в размере 3,7. В ходе эксперимента были использованы образцы текста на английском языке.
Tagged in: GPT-3Генерация музыкиОбработка видео и звука
КОРРЕЛЯЦИЯ ГЕНЕРАЦИИ ЗВУКА И МЕТАБОЛИЧЕСКОГО ТЕПЛОВОГО ПОТОКА В БОМБЕ ШМЕЛА LAPIDARIUS
. 1994 г., февраль; 187(1):315-8. дои: 10.1242/jeb.187.1.315.P Schultze-Motel, I Lamprecht I
- PMID: 9317879
-
DOI:
10.
 1242/джеб.187.1.315
1242/джеб.187.1.315
P Шульце-Мотель и др. J Эксперт Биол. 1994 фев.
. 1994 г., февраль; 187(1):315-8. дои: 10.1242/jeb.187.1.315.Авторы
P Schultze-Motel, I Lamprecht I
- PMID: 9317879
- DOI: 10.1242/джеб.187.1.315
Абстрактный
Летающие насекомые выделяют огромное количество тепла в качестве побочного продукта во время сокращения их грудных летательных мышц (Heinrich, 1989). Перед полетом метаболическое тепло может служить для разогрева грудных мышц до тех пор, пока не будет достигнута минимальная температура отрыва (Генрих, 19 лет). 74б; Стоун и Уиллмер, 1989 г.; Эш и Голлер, 1991). Общественные пчелы и осы также могут использовать тепло, выделяемое их летательными мышцами, для инкубации расплода и для активного регулирования температуры гнезд (Heinrich, 1974a; Seeley and Heinrich, 1981; Schultze-Motel, 1991). В этом исследовании мы сообщаем об одновременных измерениях теплового потока и генерации звука жужжанием крыльев у отдельных рабочих шмелей (Bombus lapidarius L.). Используемые в экспериментах шмели были отобраны из семей в наблюдательных гнездовьях (Шультце-Мотель, 19).91) и помещают в цилиндрический 100 мл сосуд из нержавеющей стали микрокалориметра типа Кальве (MS 70, Setaram, Lyon; Wadso, 1987). Небольшой микрофон был установлен под завинчивающейся крышкой сосуда калориметра. Чувствительность калориметра в этих условиях составила 41,7 мВ Вт-1. Сигналы калориметра и микрофона усиливались и записывались на двухканальный самописец. В 32 из 36 измерений у шмелей были обнаружены длительные периоды звукообразования, чаще всего в начале опытов.
74б; Стоун и Уиллмер, 1989 г.; Эш и Голлер, 1991). Общественные пчелы и осы также могут использовать тепло, выделяемое их летательными мышцами, для инкубации расплода и для активного регулирования температуры гнезд (Heinrich, 1974a; Seeley and Heinrich, 1981; Schultze-Motel, 1991). В этом исследовании мы сообщаем об одновременных измерениях теплового потока и генерации звука жужжанием крыльев у отдельных рабочих шмелей (Bombus lapidarius L.). Используемые в экспериментах шмели были отобраны из семей в наблюдательных гнездовьях (Шультце-Мотель, 19).91) и помещают в цилиндрический 100 мл сосуд из нержавеющей стали микрокалориметра типа Кальве (MS 70, Setaram, Lyon; Wadso, 1987). Небольшой микрофон был установлен под завинчивающейся крышкой сосуда калориметра. Чувствительность калориметра в этих условиях составила 41,7 мВ Вт-1. Сигналы калориметра и микрофона усиливались и записывались на двухканальный самописец. В 32 из 36 измерений у шмелей были обнаружены длительные периоды звукообразования, чаще всего в начале опытов. Мы предполагаем, что звук был вызван не тревожной реакцией, а летательными движениями крыльев, когда животные пытались взлететь внутри сосуда-калориметра. Жужжащие звуки, издаваемые шмелями, вызываются колебаниями летательных мышц внутри заднегруди (Schneider, 19).75). Предыдущие эндоскопические наблюдения за шмелями, сидящими на дне нашего калориметрического сосуда, показали, что между эпизодами движений крыльев и производством звука существует корреляция один к одному. Таким образом, записи с микрофона позволили легко измерить двигательную активность внутри калориметра. Одновременная регистрация сигналов калориметра и микрофона показала очень хорошее соответствие между периодами генерации звука и повышенным метаболическим потоком тепла от животных. Это было наиболее заметно в некоторых экспериментах без непрерывного жужжания крыльев, но с отчетливыми эпизодами интенсивной генерации звука, которые всегда были связаны с одновременным увеличением теплового потока (рис. 1). Между эпизодами генерации звука тепловой поток обычно возвращался от максимальных значений, превышающих 200 Вт·кг-1, к базовым значениям около 10 Вт·кг-1.
Мы предполагаем, что звук был вызван не тревожной реакцией, а летательными движениями крыльев, когда животные пытались взлететь внутри сосуда-калориметра. Жужжащие звуки, издаваемые шмелями, вызываются колебаниями летательных мышц внутри заднегруди (Schneider, 19).75). Предыдущие эндоскопические наблюдения за шмелями, сидящими на дне нашего калориметрического сосуда, показали, что между эпизодами движений крыльев и производством звука существует корреляция один к одному. Таким образом, записи с микрофона позволили легко измерить двигательную активность внутри калориметра. Одновременная регистрация сигналов калориметра и микрофона показала очень хорошее соответствие между периодами генерации звука и повышенным метаболическим потоком тепла от животных. Это было наиболее заметно в некоторых экспериментах без непрерывного жужжания крыльев, но с отчетливыми эпизодами интенсивной генерации звука, которые всегда были связаны с одновременным увеличением теплового потока (рис. 1). Между эпизодами генерации звука тепловой поток обычно возвращался от максимальных значений, превышающих 200 Вт·кг-1, к базовым значениям около 10 Вт·кг-1. В одном эксперименте мы зафиксировали отклонение от обычно наблюдаемой синхронности между метаболическим тепловым потоком и звукогенерацией (рис. 2). Акустическая активность животного начиналась примерно через 45 мин после начала эксперимента. Примечательно, что сигнал теплового потока резко возрастал уже за 5 мин до появления первой генерации звука. В период непрерывного жужжания крыла измерялись тепловые потоки более 350 Вт·кг-1. Эти потоки соответствуют скорости метаболизма во время свободного полета у других перепончатокрылых: около 300 Вт/кг у пчелы-плотника Xylocopa capitata (Nicolson and Louw, 19).82), 300-500 Вт кг-1 у медоносных пчел Apis mellifera (Nachtigall et al. 1989) и около 350 Вт кг-1 у шмелей Bombus lucorum и B. pascuorum, летящих в аэродинамической трубе (Ellington et al. 1990). . Мы предполагаем, что резкое увеличение теплового потока перед началом генерации звука представляет собой предполетный эндотермический прогрев. По-видимому, разогрев лётных мышц прошёл без жужжания крыльев.
В одном эксперименте мы зафиксировали отклонение от обычно наблюдаемой синхронности между метаболическим тепловым потоком и звукогенерацией (рис. 2). Акустическая активность животного начиналась примерно через 45 мин после начала эксперимента. Примечательно, что сигнал теплового потока резко возрастал уже за 5 мин до появления первой генерации звука. В период непрерывного жужжания крыла измерялись тепловые потоки более 350 Вт·кг-1. Эти потоки соответствуют скорости метаболизма во время свободного полета у других перепончатокрылых: около 300 Вт/кг у пчелы-плотника Xylocopa capitata (Nicolson and Louw, 19).82), 300-500 Вт кг-1 у медоносных пчел Apis mellifera (Nachtigall et al. 1989) и около 350 Вт кг-1 у шмелей Bombus lucorum и B. pascuorum, летящих в аэродинамической трубе (Ellington et al. 1990). . Мы предполагаем, что резкое увеличение теплового потока перед началом генерации звука представляет собой предполетный эндотермический прогрев. По-видимому, разогрев лётных мышц прошёл без жужжания крыльев.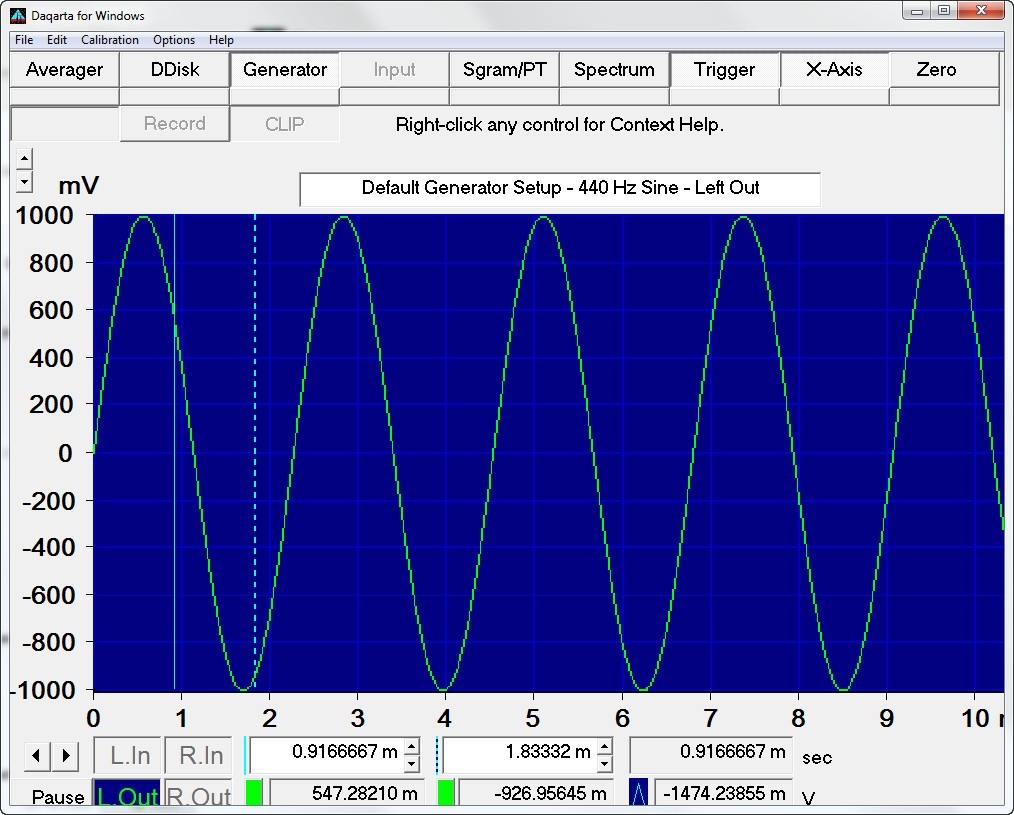
Похожие статьи
-
Как колебательные аэродинамические силы объясняют тембр жужжания колибри и других животных в машущем полете.
Хайтауэр Б.Дж., Вейнингс П.В., Шольте Р., Ингерсолл Р., Чин Д.Д., Нгуен Дж., Шорр Д., Лентинк Д. Хайтауэр Б.Дж. и др. Элиф. 2021 16 марта; 10: e63107. doi: 10.7554/eLife.63107. Элиф. 2021. PMID: 33724182 Бесплатная статья ЧВК.
-
Терморегуляция у эндотермических насекомых.
Генрих Б. Генрих Б. Наука. 1974 г., 30 августа; 185 (4153): 747-56. doi: 10.1126/наука.185.4153.747. Наука. 1974. PMID: 4602075 Обзор.
-
Функция митохондрий летающих мышц перепончатокрылых: увеличение метаболической мощности увеличивает окислительный стресс.

Hedges CP, Wilkinson RT, Devaux JBL, Hickey AJR. Хеджес С.П. и др. Comp Biochem Physiol A Mol Integr Physiol. 2019Апр; 230:115-121. doi: 10.1016/j.cbpa.2019.01.002. Epub 2019 22 января. Comp Biochem Physiol A Mol Integr Physiol. 2019. PMID: 30677507
-
Предварительные исследования по распространенности возбудителей болезней медоносных пчел в национальной популяции шмелей.
Сокол Р., Михальчик М., Михолап П. Сокол Р. и др. Энн Параситол. 2018;64(4):385-390. дои: 10.17420/ap6404.175. Энн Параситол. 2018. PMID: 30738423
-
Влияние окружающей среды и генетики на скорость метаболизма в полете у медоносной пчелы Apis mellifera.
Харрисон Дж.Ф., Фьюэлл Дж.Х. Харрисон Дж. Ф. и соавт.
 Comp Biochem Physiol A Mol Integr Physiol. 2002 г., октябрь; 133 (2): 323–33. doi: 10.1016/s1095-6433(02)00163-0.
Comp Biochem Physiol A Mol Integr Physiol. 2002.
PMID: 12208303
Обзор.
Comp Biochem Physiol A Mol Integr Physiol. 2002 г., октябрь; 133 (2): 323–33. doi: 10.1016/s1095-6433(02)00163-0.
Comp Biochem Physiol A Mol Integr Physiol. 2002.
PMID: 12208303
Обзор.
Посмотреть все похожие статьи
Цитируется
-
Экология опыления узкоэндемичной зимнецветущей Primula allionii (Primulaceae).
Minuto L, Guerrina M, Roccotiello E, Roccatagliata N, Mariotti MG, Casazza G. Минуто Л. и др. J Завод Res. 2014;127(1):141-50. doi: 10.1007/s10265-013-0588-9. Epub 2013 21 августа. J Завод Res. 2014. PMID: 23963860
Функциональная морфология и гомология носового комплекса зубатых китов: влияние на генерацию звука
Сравнительное исследование
. 1996 г., июнь; 228 (3): 223–85. doi: 10. 1002/(SICI)1097-4687(199606)228:3<223::AID-JMOR1>3.0.CO;2-3.
1002/(SICI)1097-4687(199606)228:3<223::AID-JMOR1>3.0.CO;2-3.
Т. В. Крэнфорд 1 , М. Амундин, К. С. Норрис
принадлежность
- 1 Институт морских наук Калифорнийского университета в Санта-Круз 95064, США.
- PMID: 8622183
- DOI: 10.1002/(SICI)1097-4687(199606)228:3<223::AID-JMOR1>3.0.CO;2-3
Сравнительное исследование
TW Cranford et al. J Морфол. 1996 июнь
. 1996 г., июнь; 228 (3): 223–85. doi: 10. 1002/(SICI)1097-4687(199606)228:3<223::AID-JMOR1>3.0.CO;2-3.
1002/(SICI)1097-4687(199606)228:3<223::AID-JMOR1>3.0.CO;2-3.
Авторы
Т. В. Крэнфорд 1 , М. Амундин, К. С. Норрис
принадлежность
- 1 Институт морских наук Калифорнийского университета в Санта-Круз 95064, США.
- PMID: 8622183
- DOI: 10.1002/(SICI)1097-4687(199606)228:3<223::AID-JMOR1>3.0.CO;2-3
Абстрактный
Место и физиологические механизмы, ответственные за генерацию сигналов биосонара зубатых китов, десятилетиями ускользали от исследователей. Чтобы решить эти проблемы, мы подвергли посмертных голов зубатых китов допросу с использованием методов медицинской визуализации. Большинство из 40 образцов (из 19 видов) исследовали с помощью рентгеновской компьютерной томографии (КТ) и/или магнитно-резонансной томографии (МР). Интерпретации сканированных изображений способствовало последующее рассечение образцов или, в одном случае, криосрез. Во всех образцах мы описали сходный комплекс тканей и идентифицировали его как генератор гипотетического биосонарного сигнала. Этот комплекс включает небольшую пару жировых сумок, встроенных в пару соединительнотканных губ, хрящевую пластинку, прочную связку и множество воздушных мешков из мягких тканей. Сравнение и противопоставление морфологических паттернов носовых структур у видов, представляющих все существующие надсемейства зубатых китов, выявляет вероятные гомологичные отношения, которые предполагают, что все зубатые киты могут подавать свои биосонарные сигналы с помощью аналогичного механизма.
Чтобы решить эти проблемы, мы подвергли посмертных голов зубатых китов допросу с использованием методов медицинской визуализации. Большинство из 40 образцов (из 19 видов) исследовали с помощью рентгеновской компьютерной томографии (КТ) и/или магнитно-резонансной томографии (МР). Интерпретации сканированных изображений способствовало последующее рассечение образцов или, в одном случае, криосрез. Во всех образцах мы описали сходный комплекс тканей и идентифицировали его как генератор гипотетического биосонарного сигнала. Этот комплекс включает небольшую пару жировых сумок, встроенных в пару соединительнотканных губ, хрящевую пластинку, прочную связку и множество воздушных мешков из мягких тканей. Сравнение и противопоставление морфологических паттернов носовых структур у видов, представляющих все существующие надсемейства зубатых китов, выявляет вероятные гомологичные отношения, которые предполагают, что все зубатые киты могут подавать свои биосонарные сигналы с помощью аналогичного механизма.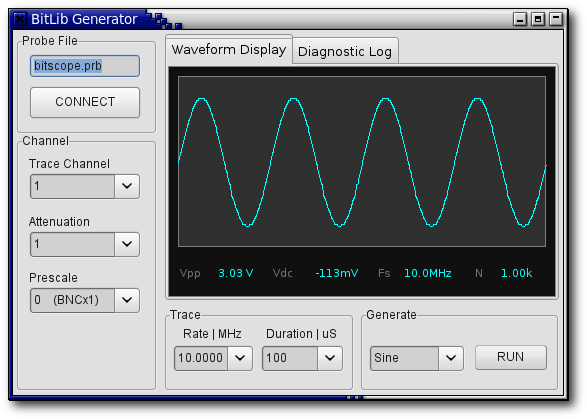
Похожие статьи
-
[Дополнительные элементы скелета в строении носового черепа Phocoena phocoena и развитие носовой области у зубатых китов].
Клима М., ван Бри П.Дж. Клима М. и др. Гегенбаурс Морфол Ярб. 1985;131(2):131-78. Гегенбаурс Морфол Ярб. 1985. PMID: 4007451 Немецкий.
-
Pakicetus inachus и происхождение китов и дельфинов (Mammalia: Cetacea).
Эльшлегер HA. Эльшлегер ХА. Гегенбаурс Морфол Ярб. 1987;133(5):673-85. Гегенбаурс Морфол Ярб. 1987. PMID: 3692104
-
Гистологические исследования хрящевых структур передней области головы кашалота Physeter macrocephalus.
Клима М. Клима М.
 Гегенбаурс Морфол Ярб. 1990;136(1):1-16.
Гегенбаурс Морфол Ярб. 1990.
PMID: 2318391
Немецкий.
Гегенбаурс Морфол Ярб. 1990;136(1):1-16.
Гегенбаурс Морфол Ярб. 1990.
PMID: 2318391
Немецкий. -
Обзор носа китообразных: форма, функция и эволюция.
Берта А., Экдейл Э.Г., Крэнфорд Т.В. Берта А и др. Анат Рек (Хобокен). 2014 ноябрь; 297(11):2205-15. doi: 10.1002/ar.23034. Анат Рек (Хобокен). 2014. PMID: 25312374 Обзор.
-
Измерение проходимости носа.
Мальм Л. Мальм Л. Аллергия. 1997; 52 (40 Дополнение): 19-23. doi: 10.1111/j.1398-9995.1997.tb04879.x. Аллергия. 1997. PMID: 9353556 Обзор. Аннотация недоступна.
Посмотреть все похожие статьи
Цитируется
-
Характерная расщелина лба дельфина Риссо ( Grampus griseus ) практически не влияет на формирование луча биосонара.
Вэй С., Гилл Л.Г., Эрбе С., Смит А.Б., Ян В.К. Вэй С и др. Животные (Базель). 2022 8 декабря; 12 (24): 3472. дои: 10.3390/ани12243472. Животные (Базель). 2022. PMID: 36552392 Бесплатная статья ЧВК.
-
Различные звуковые характеристики, производимые левым и правым грудными плавниками, представляют собой новую форму латерализации у вокальной рыбы.
Майдич ИП, Ладич Ф. Maiditsch IP, et al. J Exp Zool A Ecol Integr Physiol. 2023 янв; 339(1):112-119. doi: 10.1002/jez.2660. Epub 2022 10 октября. J Exp Zool A Ecol Integr Physiol. 2023. PMID: 36214323 Бесплатная статья ЧВК.
-
Онтогенез асимметрии у эхолокирующих китов.
Ланцетти А., Кумбс Э.Дж., Портела Мигес Р., Фернандес В., Госвами А. Ланцетти А.
 и др.
Proc Biol Sci. 2022 10 августа; 289(1980): 20221090. doi: 10.1098/rspb.2022.1090. Epub 2022 3 августа.
Proc Biol Sci. 2022.
PMID: 35919995
и др.
Proc Biol Sci. 2022 10 августа; 289(1980): 20221090. doi: 10.1098/rspb.2022.1090. Epub 2022 3 августа.
Proc Biol Sci. 2022.
PMID: 35919995 -
Разрушение стереотипов: телескопирование способствует эволюции более интегрированных и разнородных черепов у китообразных.
Буоно М.Р., Влахос Э. Буоно М.Р. и др. Пир Дж. 2022 5 мая; 10:e13392. doi: 10.7717/peerj.13392. Электронная коллекция 2022. Пир Дж. 2022. PMID: 35539009 Бесплатная статья ЧВК.
-
Слух, эхолокация и управление лучом с 0-го дня у летучих мышей, щелкающих языком.
Смарш ГК, Тарновский Ю., Йовель Ю. Смарш Г.С. и соавт. Proc Biol Sci. 2021 27 октября; 288 (1961): 20211714. doi: 10.1098/rspb.2021.1714. Epub 2021 27 октября. Proc Biol Sci. 2021. PMID: 34702074 Бесплатная статья ЧВК.

