Как поисковые системы находят и индексируют веб-страницы. Какие факторы влияют на ранжирование сайтов в поисковой выдаче. Почему важно понимать работу поисковых алгоритмов. Как оптимизировать сайт для лучшей индексации и ранжирования.
Что такое поисковые системы и как они работают
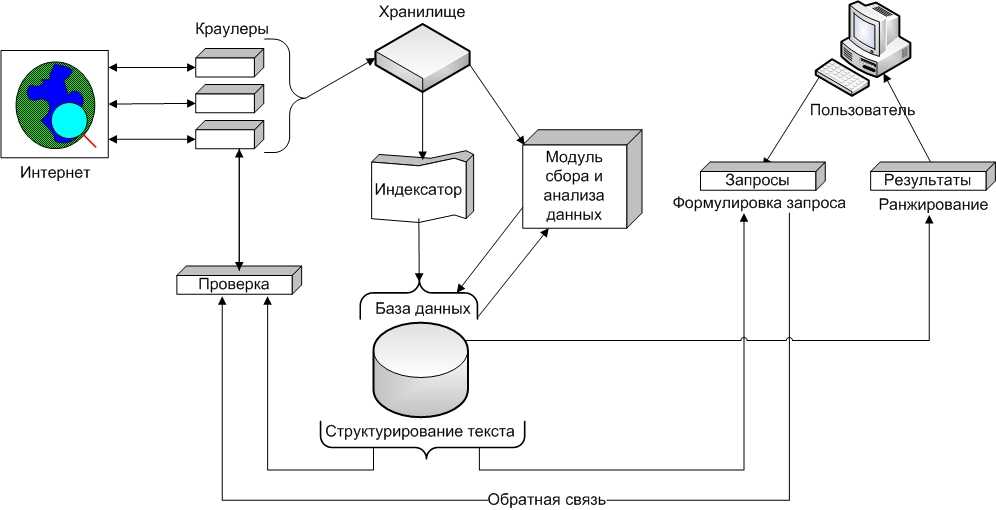
Поисковые системы — это сложные программные комплексы, предназначенные для поиска информации в интернете. Основные компоненты поисковой системы:
- Поисковый робот (краулер) — программа, которая сканирует веб-страницы
- Индекс — база данных найденных страниц
- Поисковый алгоритм — программа для ранжирования результатов поиска
Принцип работы поисковой системы можно описать следующим образом:
- Поисковый робот обходит веб-страницы по ссылкам
- Найденные страницы анализируются и добавляются в индекс
- При запросе пользователя поисковый алгоритм выбирает подходящие страницы из индекса
- Результаты ранжируются и выводятся пользователю
Ключевые этапы работы поисковых систем
1. Сканирование и индексация веб-страниц
- Переход по ссылкам с уже проиндексированных страниц
- Анализ файлов Sitemap
- Отправка URL через панели для вебмастеров
После сканирования происходит индексация — добавление информации о странице в поисковый индекс. Важно, чтобы страницы были доступны для сканирования и не содержали запретов на индексацию.
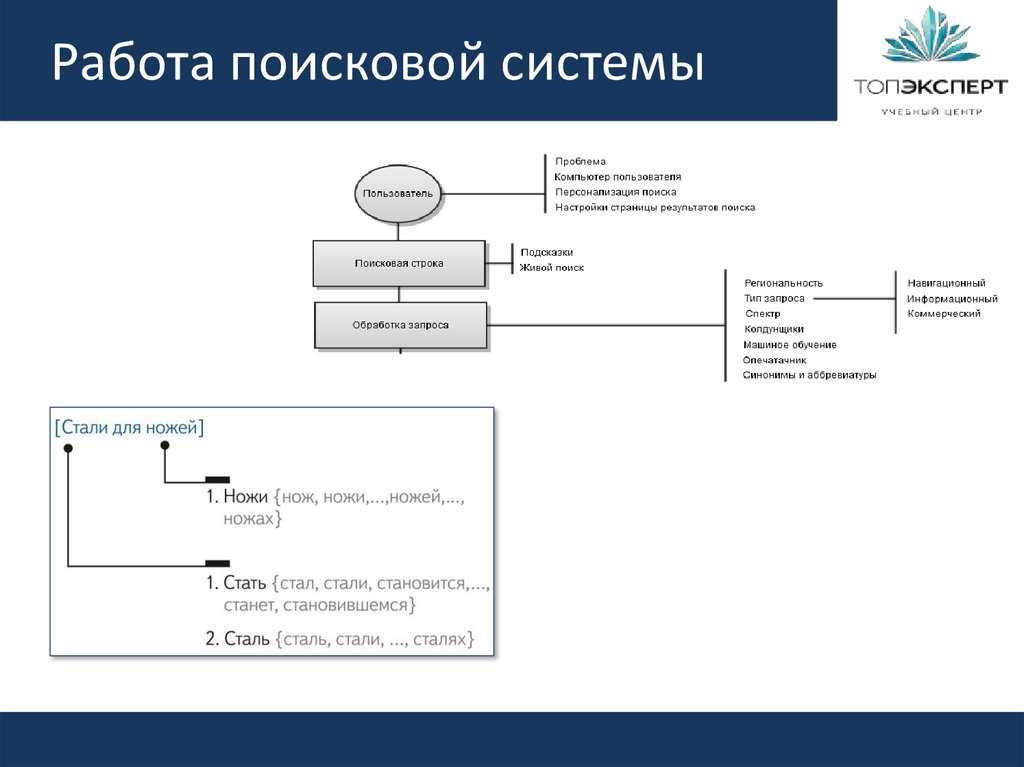
2. Обработка поисковых запросов
При вводе пользователем поискового запроса происходит следующее:
- Анализ запроса и определение его намерения
- Выбор релевантных страниц из индекса
- Ранжирование результатов поиска
- Формирование поисковой выдачи
Поисковые системы стремятся максимально точно понять, что хочет найти пользователь, и предоставить наиболее релевантные результаты.
Основные факторы ранжирования в поисковых системах
Поисковые алгоритмы учитывают сотни факторов при ранжировании результатов. Наиболее важными являются:
Релевантность контента
Насколько содержание страницы соответствует поисковому запросу. Учитывается:
- Наличие ключевых слов в тексте, заголовках, мета-тегах
- Тематическое соответствие контента запросу
- Полнота раскрытия темы
Качество и авторитетность сайта
Общая оценка сайта поисковой системой. Включает:

- Возраст и история домена
- Показатели качества контента
- Поведенческие факторы
- Наличие экспертного контента
Ссылочные факторы
Оценка внешних ссылок на сайт:
- Количество и качество ссылающихся доменов
- Тематическое соответствие ссылок
- Естественность ссылочного профиля
Оптимизация сайта для поисковых систем
Чтобы улучшить видимость сайта в поиске, необходимо провести комплекс мер по его оптимизации:
Техническая оптимизация
- Настройка корректной индексации страниц
- Оптимизация скорости загрузки
- Адаптация под мобильные устройства
- Настройка SSL-сертификата
Контентная оптимизация
- Создание качественного экспертного контента
- Оптимизация текстов под поисковые запросы
- Грамотное структурирование информации
- Регулярное обновление контента
Внешняя оптимизация
- Получение естественных внешних ссылок
- Работа с репутацией бренда
- Улучшение поведенческих факторов
Почему важно понимать принципы работы поисковых систем
Понимание того, как функционируют поисковые системы, дает ряд преимуществ:

- Возможность эффективно оптимизировать сайт
- Повышение видимости сайта в поисковой выдаче
- Увеличение целевого органического трафика
- Понимание причин проблем с индексацией и ранжированием
- Возможность прогнозировать изменения в алгоритмах
Это позволяет выстраивать долгосрочную стратегию развития сайта и успешно конкурировать в поисковой выдаче.
Тенденции развития поисковых систем
Поисковые системы постоянно совершенствуют свои алгоритмы. Основные направления развития:
- Использование искусственного интеллекта для лучшего понимания запросов
- Персонализация поисковой выдачи
- Развитие голосового поиска
- Улучшение поиска по изображениям и видео
- Интеграция с другими сервисами (карты, переводчики и т.д.)
Важно следить за этими тенденциями и адаптировать стратегию продвижения сайта под новые требования поисковых систем.
Заключение
Понимание принципов работы поисковых систем — ключ к успешному продвижению сайта. Это позволяет:
- Грамотно оптимизировать сайт под требования поисковиков
- Создавать контент, который будет высоко ранжироваться
- Выстраивать эффективную стратегию продвижения
- Своевременно реагировать на изменения алгоритмов
При этом важно помнить, что в центре внимания должны быть интересы пользователей, а не попытки обмануть поисковые алгоритмы. Только предоставляя действительно полезный и качественный контент можно добиться устойчивых высоких позиций в поисковой выдаче.
что это, виды, как устроена
Поисковая система (ПС) — это набор алгоритмов, позволяющих проводить поиск в интернете. Характерная особенность ПС — мгновенное нахождение информации по конкретной фразе или определенному слову. Благодаря процессу индексирования она способна сканировать и затем извлекать данные из миллионов документов. И все это — за считанные миллисекунды.
Присоединяйтесь к нашему Telegram-каналу!
- Теперь Вы можете читать последние новости из мира интернет-маркетинга в мессенджере Telegram на своём мобильном телефоне.
- Для этого вам необходимо подписаться на наш канал.
История поисковых систем
Первой ПС принято считать W3Catalog — она появилась в 1993 году. W3Catalog представлял из себя не классическую поисковую машину (ПМ), а скорее обычный каталог, содержащий списки сайтов / адресов. Полноценная ПМ в интернете появилась в 1994 году: и это была вовсе не Google, а Aliweb 🙂
W3Catalog доступен и в 2022 году. Пример сайтов — в разделе Media and Entertainment
Пример сайтов — в разделе Media and Entertainment
Aliweb первой в мире начала обрабатывать контент сайтов: сканировать, индексировать его, перемещая в собственный индекс.
Так выглядел Aliweb в 1995 годуНо даже у Aliweb еще не было краулеров в привычном для нас понимании, т. е. для автоматического сканирования всех новых страниц. Информацию о новых сайтах добавляли сами вебмастеры: они указывали названия и ключевые слова для каждой страницы в общую базу данных (БД), которую позже и сканировал Aliweb.
За несколько десятилетий было создано свыше тысячи разнообразных ПС. Лишь десятки из них сумели дойти до наших дней и остаются работоспособными сегодня. Самыми популярными поисковыми системами в России уже долгие годы остается Google и «Яндекс».
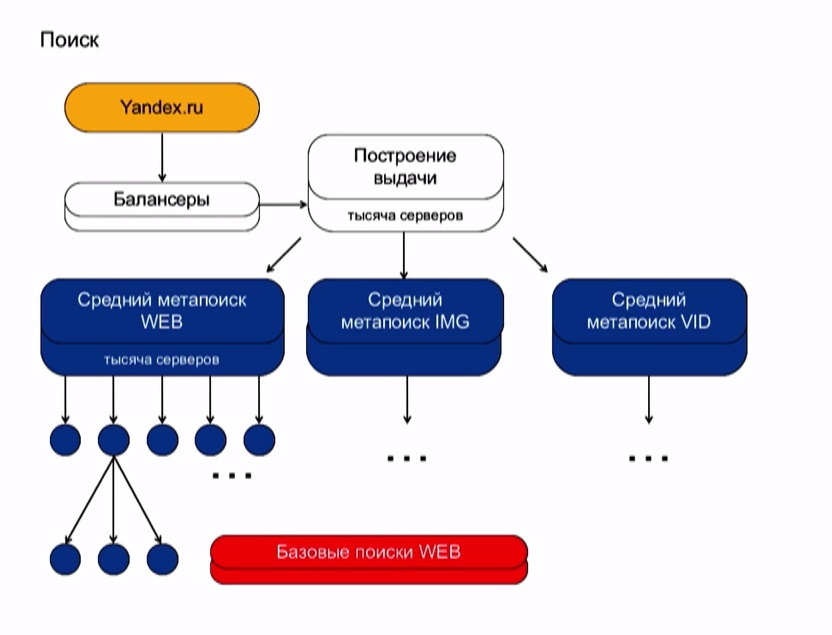
Самые популярные ПС в мире. Динамика с 2014 по 2021 годыКак устроены поисковые системы
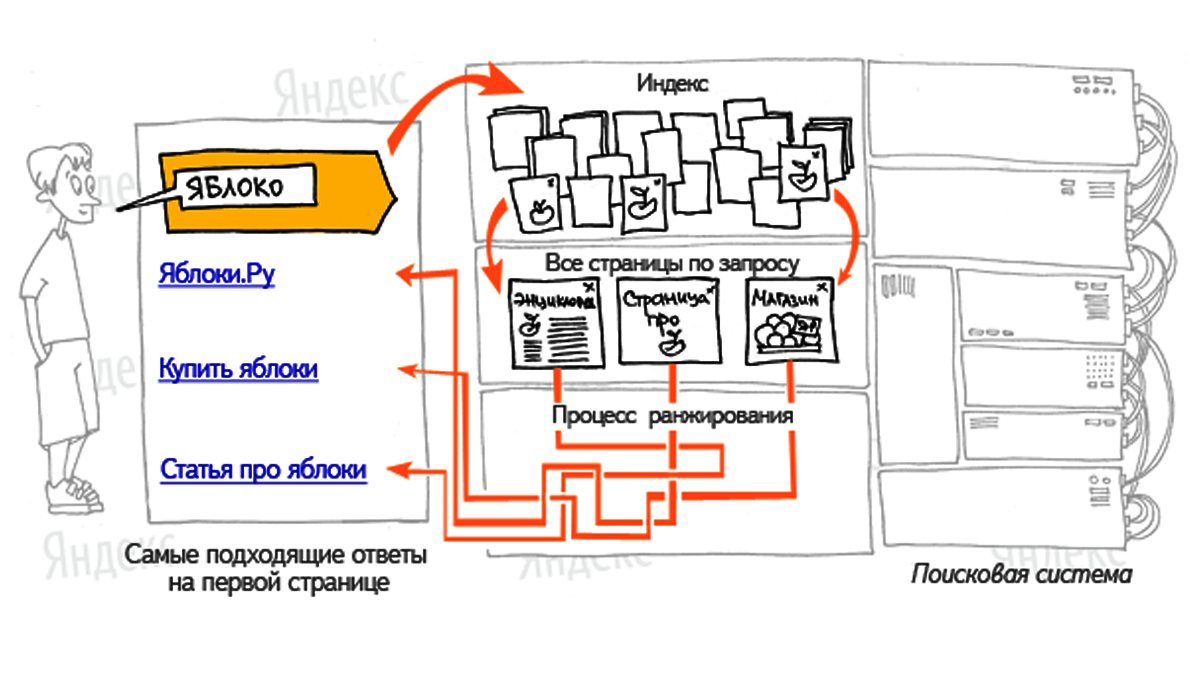
Если проводить аналогию с нецифровым миром, ПС — это картотека в библиотеке, где у каждой книги есть свой уникальный номер. По этому номеру ее можно найти в каталоге.
По этому номеру ее можно найти в каталоге.
Упрощенный алгоритм работы таков:
- Пользователь указывает поисковый запрос.
- ПС анализирует весь ранее собранный индекс и находит документы, которые ему максимально релевантны.
- Наиболее релевантные документы сортируются: от наиболее близких поисковому запросу к наименее.
- Результаты выводятся на странице поисковой выдачи.
Что такое краулер поисковой системы
Краулер — это специальная программа, используемая ПС для перехода по URL, которые он обнаруживает на веб-странице. Затем краулер помечает такие ссылки специальным образом.
Благодаря найденным URL поисковый робот находит все новые и новые страницы (о которых ПС не знала ранее)Последовательность работы ПС: этапы обработки документа
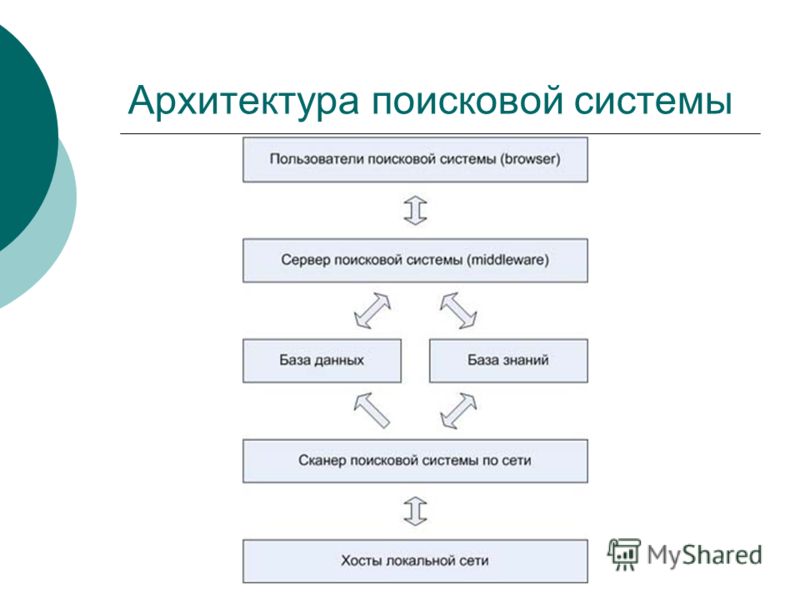
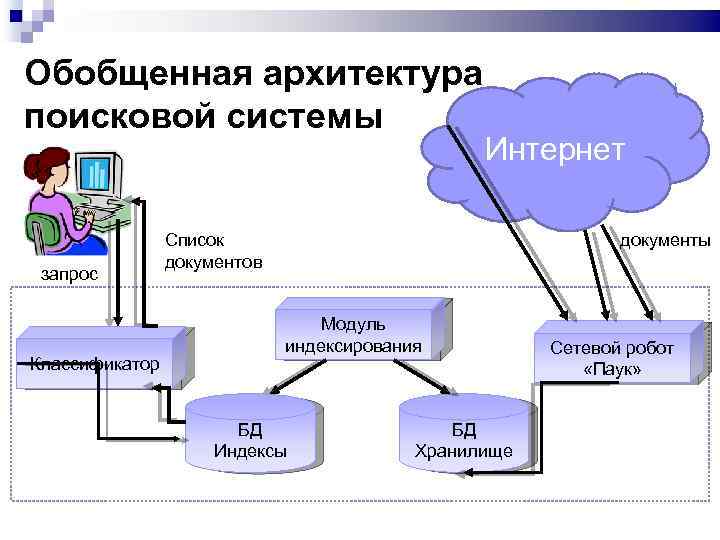
Поисковая система состоит из трех компонентов:
Далее поговорим о том, как индексирование документов помогает функционировать поисковым системам.
Зачем поисковым системам нужен индекс
Индекс по своей сути — это просто база данных, необходимая для ускорения поискового процесса: извлечения данных о документах, обработки и представлении результатов поиска пользователю. Любые данные из индексной БД «вынимаются» за миллисекунды, ведь в индексе ПС уже хранится информация обо всех страницах в интернете.
Индексация — извлечение важных для ПС данных и дальнейшая их конвертация в понятные поисковой системе форматы
Кэш поисковой системы нужен для ускорения экстракции данных (по аналогии, например, с разархивированием архива в WinRar) с ранее посещенных веб-страниц.
ПС хранят индекс не просто так: они обращаются к нему в дальнейшем, при работе с запросами. Так что хранить эту базу данных где-то, в любом случае, нужно.
Читайте также:
Индексация в поисковых системах: что это простыми словами
Как поисковые системы хранят индекс на своей стороне
Google хранит документы фрагментарно или полностью на своих серверах. Само хранение происходит в кэше (это отдельная память, обладающая высокой скоростью доступа). Другие поисковики хранят только определенные фразы или каждое слово и связывают его с документом в дальнейшем.
Само хранение происходит в кэше (это отдельная память, обладающая высокой скоростью доступа). Другие поисковики хранят только определенные фразы или каждое слово и связывают его с документом в дальнейшем.
Как ПС обновляют свой индекс и базы данных
В среде SEO-специалистов обновления индекса систем называются апдейтами выдачи. У каждой поисковой системы такие апдейты происходят по-разному. Google добавляет новые документы в свой индекс ежедневно, причем несколько раз в сутки. «Яндекс» действует по-другому — новые страницы попадают в индекс произвольно (апдейт происходит 2 раза в неделю, например).
Самыми важными факторами является суммарная релевантность ключевой фразы и подобранного документа, проработанность индекса и особенности морфологических параметров языка пользователя.
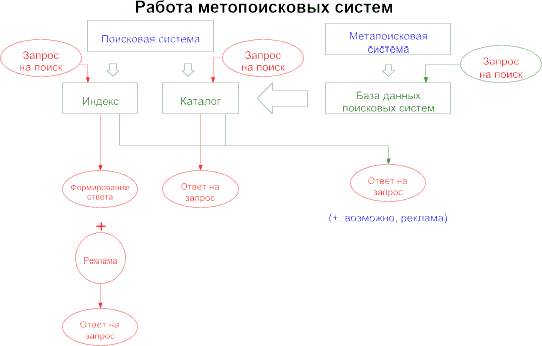
Виды поисковых систем
Выделим три классификации:
- По особенностям использования индекса.
- По типу индекса.
- По области поиска.
I По особенностям использования индекса
Безиндексные ПС
Это мультипотоковые системы, которые функционируют через крупные поисковые системы. Безиндексные системы просто агрегатируют их результаты поиска и проводят собственную сортировку.
Безиндексные системы просто агрегатируют их результаты поиска и проводят собственную сортировку.
Примеры: Bing (Microsoft Bing), AskNet, Quintura, Ixuick, MetaCrawler.
«Нигма» — самая известная российская метапоисковая система (ныне не существует)Классические поисковые машины
Еще говорят «поисковый движок», «поисковые машины с индексом». Пауки ПС сканируют все страницы в интернете, затем формируют собственный индекс (базы данных) с информацией о веб-документах. Поиск по БД в случае классической поисковой машины, условно, состоит из трех этапов:
- Нахождение наиболее релевантного поисковой фразе документа.
- Ранжирование остальных документов исходя из их суммарной релевантности.
- Кластеризация документов.
Кроме этих функций, маркер классической ПМ — разные методы поиска ссылок в ручном и автоматическом режимах. В первом случае их добавляют в поисковую машину сами вебмастеры, во втором — краулеры сканируют сеть самостоятельно.
Примеры: Google и «Яндекс».
Гибридные ПС
Относятся к классическим поисковым машинам, однако с неким допущением можно выделить их и в отдельную категорию.
Индекс здесь собирается не только за счет сканирования краулером ПС, но и благодаря пользовательским источникам данных: реестрам документов, каталогам, справочникам.
Примеры: Yahoo, «Яндекс», Google.
«Яндекс» — поисковая машина гибридного типа
Читайте также:
Отличия SEO под Яндекс и Google
Каталожные поисковые системы
Это пользовательские БД, где все данные добавляются вручную. Качество результатов поиска в таких ПС в теории должно быть заметно выше, чем в автогенерируемых системах.
Они могут выглядеть как рубрикатор заданной иерархии с большим количеством категорий и подкатегорий. Для каждого сайта указывается описание контента, заголовок и ссылка на страницу.
Примеры: Russia on the Net, AtRus, Yahoo!, Directory (сейчас некоторые уже не существуют).
II По типу индекса
В 2022 году массово распространены два типа ПС: с инвертированным индексом и с индексом, имеющим предопределенное расположение ключевых слов. Разница между ними легко прослеживается.
Инвертированный индекс (ИИ)
Для слов в наборе документов указаны все страницы в реестре, где они упоминались. В свою очередь, сам ИИ может быть двух видов:
- Лист документов для каждого слова.
- Лист документов для каждого слова + позиция слова в каждом веб-документе.
Пример: Google.
Индекс с предопределенным расположением ключевых слов (устаревший)
Все фразы упорядочены и отсортированы уже изначально по иерархическому принципу. В настоящий момент не известно ни одной крупной поисковой машины с этим типом индекса.
III По области поиска
Локальная ПС
Отдельностоящее ПО либо веб-приложение, которое разворачивается на компьютере пользователя и позволяет искать информацию, например, на жестком диске или в в пределах домашней сети.
Примеры: Tracker, Copernic Desktop Search.
Глобальная ПС
Веб-сайт / веб-приложение / сервис для поиска документов во всем интернете (или, например, в пределах конкретной доменной зоны).
«Спутник» — национальная поисковая система. Ныне закрытаПримеры: Google, Bing, Yandex, Baidu.
При этом они могут содержать в себе элементы локальных поисковых систем: например, поиск в определенной доменной зоне или поддержка китайского языка по умолчанию, как Baidu. Есть также национальные ПС, созданные для использования в конкретной стране — наши «Спутник» и «Поиск Mail.ru».
Также существуют поисковые системы для поиска информации только в определенных каналах. Например:
- на новостных сайтах;
- внутри FTP-хранилищ.
- в RSS-каналах;
- в библиотечных ресурсах;
- в интернет-магазинах;
- в юзнете.
Юзнет — это глобальная компьютерная сеть для интернет-дискуссий и публикации файлов, состоит из набора групп новостей, организованных по темам. Пользователи размещают статьи или сообщения в этих группах новостей. Затем эти материалы публикуются уже на других платформах.
Пользователи размещают статьи или сообщения в этих группах новостей. Затем эти материалы публикуются уже на других платформах.
Что нужно знать о поисковых системах вебмастеру и пользователю
Поисковая система — это сложный набор алгоритмов, которые работают внутри единой компьютерной программы.
Чтобы новая страница сайта отображалась в результатах поиска, она должна попасть в индекс. Краулеры ПС автоматически обходят все страницы в интернете, добавляя их в специальную базу данных. Обрабатывается также и содержимое страниц.
Читайте также:
Факторы ранжирования Google и «Яндекс»: что это и как работает
Поисковая выдача зависит от суммарной релевантности документа по отношению к запросу. У каждой ПС свои методы определения релевантности, и подробно о них узнать нельзя. Известно лишь об общих принципах оценки:
- Семантический анализ слов в запросе, включая слова в поисковых фразах вместе и по отдельности.

- Идентифицирование типа запроса.
- Интерпретация орфографических ошибок.
- Определение синонимичности запроса.
- Сопоставление поисковой фразы с особенностями языковой модели.
- Определение актуальности информации.
- Определение региональности запроса.
СДЕЛАЕМ САЙТ, КОТОРЫЙ НРАВИТСЯ ПОИСКОВЫМ СИСТЕМАМ
Сайт
Телефон
Как работают поисковые системы? Руководство для начинающих
Joshua Hardwick
Глава отдела контента в Ahrefs (проще говоря, я отвечаю за то, чтобы каждый пост в блоге был КРУТЫМ).
Показывает, сколько различных веб-сайтов ссылаются на этот контент. Как правило, чем больше сайтов ссылаются на вас, тем выше вы ранжируетесь в Google.
Показывает ежемесячный рассчетный поисковый трафик на эту статью по данным Ahrefs. Фактический поисковый трафик (по данным Google Analytics) обычно в 3–5 раз больше.
Количество ретвитов этой статьи в Twitter.
Поделиться этой статьей
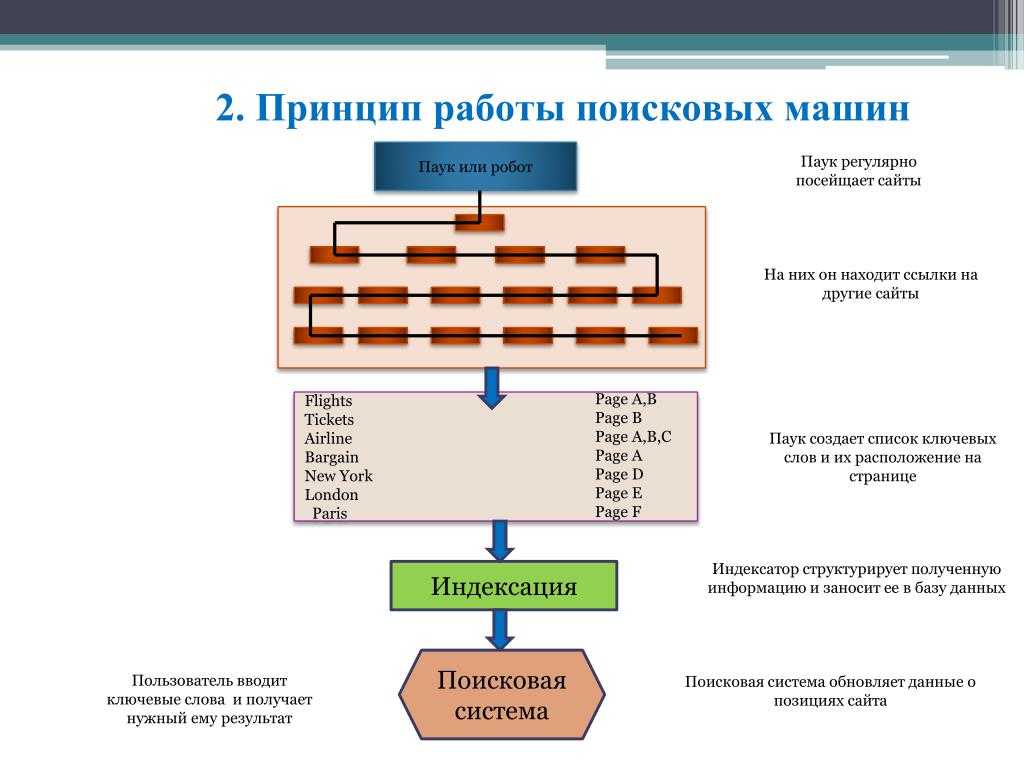
Поисковые системы работают, сканируя Интернет с помощью ботов, называемых краулерами или пауками. Они переходят по ссылкам со страницы на страницу в поисках нового контента для добавления в поисковый индекс. Когда вы используете поисковую систему, релевантные результаты извлекаются из индекса и ранжируются согласно алгоритму.
Если это звучит сложно, это потому, что так и есть. Но если вы хотите ранжироваться выше в поисковых системах, чтобы привлечь больше трафика на свой веб-сайт, вам необходимо базовое понимание того, как поисковые системы находят, индексируют и ранжируют контент.
Вот что вы узнаете из этого руководства:
Contents
Содержание
Прежде чем мы перейдем к техническим вопросам, давайте сначала убедимся, что мы понимаем, что такое поисковые системы на самом деле, почему они существуют и почему это вообще имеет значение.
Что такое поисковые системы?
Поисковые системы — это инструменты, которые находят и ранжируют веб-контент, соответствующий поисковому запросу пользователя.
Каждая поисковая система состоит из двух основных частей.
- Поисковый индекс. Цифровая библиотека информации о веб-страницах.
- Поисковые алгоритмы. Компьютерные программы, которые ранжируют сопоставленные результаты из поискового индекса.
Примеры популярных поисковых систем включают Google, Bing и DuckDuckGo.
В чем состоит цель поисковых систем?
Каждая поисковая система стремится предоставлять пользователям наилучшие и наиболее релевантные результаты. Вот как они получают или удерживают долю рынка — по крайней мере, теоретически.
Как поисковые системы зарабатывают деньги?
Поисковые системы предоставляют два типа результатов поиска.
- Органические результаты из поискового индекса. Вы не можете заплатить, чтобы попасть сюда.
- Платная реклама от рекламодателей. Вы можете заплатить, чтобы попасть сюда.
Каждый раз, когда кто-то нажимает на рекламу в поиске, рекламодатель платит поисковой системе. Это называется рекламой с оплатой за клик (от англ. pay-per-click, PPC).
Это называется рекламой с оплатой за клик (от англ. pay-per-click, PPC).
Вот почему доля рынка имеет значение. Больше пользователей означает больше кликов по рекламе и больший доход.
Почему вам должно быть важно, как работают поисковые системы?
Поняв, как поисковые системы находят, индексируют и ранжируют контент, вы сможете ранжировать ваш сайт в органических результатах поиска по релевантным и популярным ключевым словам.
Если вы сможете занять высокие позиции по этим запросам, вы получите больше кликов и органического трафика на ваш контент.
Какая поисковая система самая популярная?
Google. Их доля рынка составляет 92%.
Google — это поисковая система, которая интересует большинство специалистов по SEO и владельцев веб-сайтов, потому что она способна направить больше трафика, чем любая другая.
Большинство известных поисковых систем, таких как Google и Bing, содержат в своих поисковых индексах триллионы страниц. Прежде чем говорить об алгоритмах ранжирования, давайте подробнее рассмотрим механизмы, используемые для создания и поддержания веб-индекса.
Вот основной процесс, любезно предоставленный Google::
Давайте рассмотрим процесс, шаг за шагом:
- URL-адреса
- Сканирование
- Обработка и рендеринг
- Индексирование
Примечание.
Приведенный ниже процесс применяется конкретно в Google, но, вероятно, он очень похож и у других поисковых систем, таких как Bing. Существуют и другие типы поисковых систем, такие как Amazon, YouTube и Wikipedia, которые показывают результаты только со своих веб-сайтов.
Шаг 1. URL-адреса
Все начинается со списка известных URL-адресов. Google обнаруживает URL-адреса с помощью различных процессов, но наиболее распространенными из них являются приведенные ниже.
Из обратных ссылок
У Google уже есть индекс, содержащий триллионы веб-страниц. Если кто-то добавит ссылку на одну из ваших страниц, ведущую с одной из них, Google сможет найти ее в этом индексе.
Вы можете бесплатно просматривать обратные ссылки своего веб-сайта с помощью Сайт Эксплорера в Ahrefs Webmaster Tools.
- Зарегистрируйте бесплатную учетную запись Ahrefs Webmaster Tools
- Вставьте свой домен в Сайт Эксплорер
- Перейдите в отчет Бэклинки
Наш краулер является вторым по активности после Google, поэтому этот отчет предоставляет вам достаточно полное представление о ваших обратных ссылках.
Из карт сайта
Карты сайта перечисляют все важные страницы вашего сайта. Если вы добавите карту сайта в Google, это может помочь им быстрее обнаружить ваш сайт.
Из добавлений URL-адресов
Google также позволяет добавлять отдельные URL-адреса через Google Search Console.
Шаг 2. Сканирование
На этом шаге компьютерный бот (краулер), например, Googlebot, посещает и скачивает обнаруженные страницы.
Важно отметить, что Google не всегда сканирует страницы в том порядке, в котором они их обнаруживают.
Google ставит URL-адреса в очередь для сканирования на основе нескольких факторов, в том числе:
- PageRank URL-адреса;
- как часто меняется URL-адрес;
- новый он или нет.
Это важно, потому что это означает, что поисковые системы могут сканировать и индексировать одни из ваших страниц раньше других. Если у вас большой веб-сайт, поисковым системам может потребоваться время, чтобы полностью его просканировать.
Шаг 3. Обработка
Обработка — это этап, на котором Google распознает и извлекает ключевую информацию из просканированных страниц. Никто, кроме Google, не знает всех подробностей этого процесса, но важными частями для нашего понимания являются извлечение ссылок и сохранение контента для индексации.
Google необходимо получить рендеры страниц, чтобы полностью обработать их, и именно здесь Google выполняет код страницы, чтобы понять, как она выглядит для пользователей.
При этом часть обработки происходит как до, так и после рендеринга, как вы можете видеть на диаграмме.
Шаг 4. Индексирование
На этом шаге обработанная информация с просканированных страниц добавляется в большую базу данных, называемую поисковым индексом. По сути, это цифровая библиотека из триллионов веб-страниц, из которой поступают результаты поиска Google.
По сути, это цифровая библиотека из триллионов веб-страниц, из которой поступают результаты поиска Google.
Это важный момент. Когда вы вводите запрос в поисковую систему, вы не ищете соответствующие результаты напрямую в Интернете. Вы выполняете поиск в индексе веб-страниц поисковой системы. Если веб-страница отсутствует в поисковом индексе, пользователи поисковых систем не найдут ее. Вот почему так важно проиндексировать ваш сайт в основных поисковых системах, таких как Google и Bing.
Обнаружение, сканирование и индексирование контента — это лишь первая часть головоломки. Поисковым системам также необходим способ ранжирования подходящих результатов, когда пользователь выполняет поиск. Это работа для алгоритмов поисковых систем.
Каждая поисковая система использует уникальные алгоритмы для ранжирования веб-страниц. Но поскольку Google является наиболее широко используемой поисковой системой (по крайней мере, в западном мире), именно на ней мы собираемся сосредоточиться в остальной части этого руководства.
У Google более 200 факторов ранжирования.
Никто не знает все эти факторы ранжирования, но мы знаем о ключевых из них.
Давайте кратко обсудим их.
- Обратные ссылки
- Релевантность
- Новизна
- Тематическая авторитетность
- Скорость загрузки страницы
- Оптимизация для мобильных устройств
Обратные ссылки
Обратные ссылки — один из самых важных факторов ранжирования Google.
Андрей Липатцев, старший стратег Google по качеству поиска, подтвердил это во время вебинара в прямом эфире в 2016 году. Когда его спросили о двух наиболее важных факторах ранжирования, он ответил просто: контент и ссылки.
Конечно. Я могу сказать вам, какие они [два главных фактора ранжирования]. Это контент. И это ссылки, указывающие на ваш сайт.
Ссылки являются важным фактором ранжирования в Google с 1997 года, когда они ввели PageRank, формулу для оценки ценности веб-страницы на основе количества и качества обратных ссылок, указывающих на нее.
Когда мы проанализировали более миллиарда страниц, мы обнаружили четкую корреляцию между количеством веб-сайтов, ссылающихся на страницу, и объемом органического трафика, который она получает из Google.
Однако дело не только в количестве, потому что не все обратные ссылки одинаковы. Вполне возможно, что страница с несколькими обратными ссылками высокого качества превзойдет страницу с большим количеством обратных ссылок низкого качества.
У хорошей обратной ссылки есть шесть ключевых атрибутов.
Давайте подробнее рассмотрим, возможно, два самых важных из них: авторитет и релевантность.
Авторитет ссылки
Обратные ссылки с авторитетных страниц и веб-сайтов обычно имеют наибольшее влияние на ранжирование.
Как определить авторитет? В контексте SEO авторитетные страницы и веб-сайты — это те, которые имеют много обратных ссылок или “избирательных голосов”.
В Ahrefs есть две метрики для оценки относительного авторитета веб-сайтов и страниц.
- Рейтинг домена (DR): относительный авторитет веб-сайта по шкале от 0 до 100.
- Рейтинг URL-адреса (UR): относительный авторитет страницы по шкале от 0 до 100.
Вы можете проверить авторитет любого веб-сайта или веб-страницы в Сайт Эксплорере Ahrefs.
Релевантность ссылки
Ссылки с релевантных веб-сайтов и страниц имеют наивысшую ценность.
Google говорит о релевантности в контексте ранжирования полезных страниц на своей странице о том, как работает поиск.
Если другие известные веб-сайты по данной теме ссылаются на эту страницу, это явный признак высокого качества информации.
Если вам интересно, почему важна релевантность, подумайте о том, как все работает в реальном мире. При поиске лучшего итальянского ресторана вы, вероятно, поверите совету вашего друга-повара, а не совету друга-ветеринара. Но если бы вы искали рекомендации по кошачьему корму, было бы наоборот.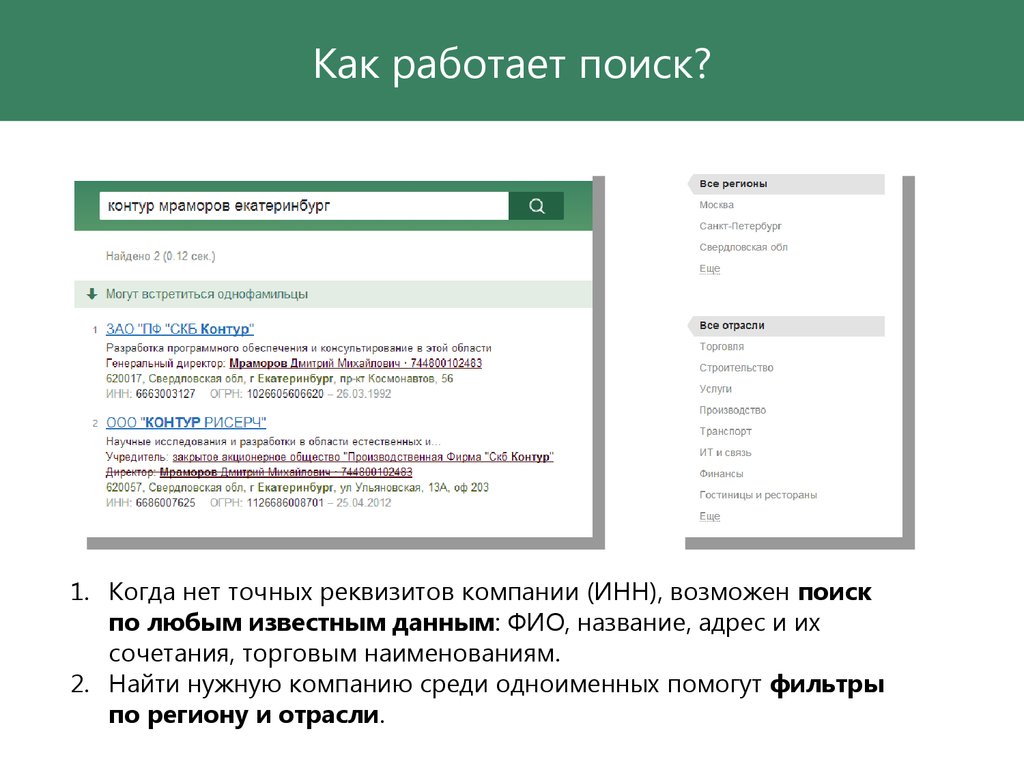
Релевантность
У Google есть много способов определения релевантности страницы.
На самом базовом уровне он ищет страницы, содержащие те же ключевые слова, что и поисковый запрос.
Но релевантность выходит далеко за рамки совпадения по ключевым словам.
Google также использует данные о взаимодействии, чтобы оценить, соответствуют ли результаты поиска запросам. Другими словами, находят ли эту страницу полезной пользователи?
Отчасти поэтому все лучшие результаты по запросу “apple” (яблоко) относятся к технологической компании, а не к фрукту. Из данных о взаимодействии Google знает, что большинство пользователей ищут информацию о первом, а не втором.
Однако данные о взаимодействии — далеко не единственное, что Google учитывает.
Google инвестировал во множество технологий, помогающих понимать взаимосвязи между сущностями, такими как люди, места и предметы. Граф знаний — одна из таких технологий, которая, по сути, представляет собой огромную базу знаний об объектах и связях между ними.
И apple (яблоко, фрукт), и Apple (технологическая компания) являются сущностями в графе знаний.
Google использует связи между сущностями, чтобы лучше понять релевантность страницы. Соответствующий результат по слову “apple”, в котором говорится об апельсинах и бананах, явно относится к фруктам. Но тот, в котором говорится об iPhone, iPad и iOS, явно относится к технологической компании.
Отчасти благодаря графу знаний Google может выйти за рамки сопоставления ключевых слов.
Иногда вы даже можете увидеть результаты поиска, в которых не упоминаются, казалось бы, важные ключевые слова из запроса. Возьмем для примера второй результат для “приложение Paper в магазине Apple”, в котором нигде на странице не упоминается слово “apple”.
Google может сказать, что это релевантный результат, отчасти потому, что он упоминает такие сущности, как iPhone и iPad, которые, несомненно, тесно связаны с Apple в графе знаний.
Примечание.
Данные о взаимодействии и граф знаний — не единственные технологии, которые Google использует для определения релевантности страницы поисковому запросу. Большая часть работы выполняется с использованием технологий, таких как BERT и RankBrain, позволяющих понять смысл и интент самого запроса. Google даже иногда незаметно переписывает запросы, чтобы предоставлять более релевантные результаты.
Большая часть работы выполняется с использованием технологий, таких как BERT и RankBrain, позволяющих понять смысл и интент самого запроса. Google даже иногда незаметно переписывает запросы, чтобы предоставлять более релевантные результаты.
Новизна
Новизна как фактор ранжирования зависит от запроса, т. е. для одних запросов она важнее, чем для других.
Для такого запроса, как “что нового на Amazon Prime”, важна свежесть, потому что пользователи хотят знать о недавно добавленных фильмах и телешоу. Вероятно, поэтому Google ранжирует недавно опубликованные или обновленные результаты поиска выше.
Для таких запросов, как “лучшие наушники”, свежесть важна, но не настолько. Технологии наушников развиваются быстро, поэтому результаты 2015 года вряд ли будут очень полезны, но пост, опубликованный 2—3 месяца назад, вполне может оказаться полезен.
Google знает об этом и показывает результаты, которые были обновлены или опубликованы в последние несколько месяцев.
Есть также вопросы, по которым новизна результатов не имеет значения, например, “как завязать галстук”. В этом процессе ничего не изменилось за десятилетия, поэтому не имеет значения, были ли результаты поиска написаны вчера или в 1998 году. Google знает это и не стесняется ранжировать посты, опубликованные много лет назад.
В этом процессе ничего не изменилось за десятилетия, поэтому не имеет значения, были ли результаты поиска написаны вчера или в 1998 году. Google знает это и не стесняется ранжировать посты, опубликованные много лет назад.
Тематическая авторитетность
Google хочет ранжировать контент с веб-сайтов, авторитетных в данной теме. Это означает, что Google может рассматривать веб-сайт как хороший источник результатов для запросов по одной теме, но не по другой.
Google говорит об этом в одном из своих патентов:
Считает ли поисковая система сайт авторитетным, обычно зависит от запроса. […] поисковая система может рассматривать сайт Центра по контролю за заболеваниями, “cdc.gov”, как авторитетный сайт для запроса “CDC об укусах комаров”, но не может считать тот же сайт авторитетным для запроса “рекомендации ресторанов”.
Хотя это лишь один из многих патентов, поданных Google, мы видим доказательства того, что “тематический авторитет” играет роль для результатов поиска по многим запросам.
Достаточно взглянуть на результаты поиска по запросу “вакууматор для готовки sous vide”.
Здесь мы видим два небольших нишевых сайта о готовке в вакууме, превосходящих The New York Times.
Хотя здесь, несомненно, играют роль и другие факторы, вполне вероятно, что “тематическая авторитетность” является одной из причин, по которым эти сайты ранжируются на своих позициях.
Вероятно поэтому в руководстве Google по поисковой оптимизации для начинающих сказано следующее:
Старайтесь заслужить репутацию в своей области.
Скорость загрузки страницы
Никто не любит ждать, пока загрузится страница, и Google это знает. Вот почему они сделали скорость страницы фактором ранжирования для поиска на компьютерах в 2010 году и на мобильных устройствах в 2018 году.
Многие люди зацикливаются на скорости загрузки страниц, поэтому стоит отметить, что ваши страницы не должны загружаться молниеносно, чтобы ранжироваться. Google заявляет, что скорость загрузки страниц считается проблемой только для страниц, которые “загружаются у пользователей медленнее всего”.
Другими словами, сокращение на несколько миллисекунд и без того быстрого сайта вряд ли поможет ему ранжироваться выше. Просто он должен быть достаточно быстрым, чтобы не влиять негативно на восприятие пользователей.
Вы можете проверить скорость любой веб-страницы в инструменте PageSpeed Insights, который также генерирует предложения по ускорению загрузки страниц.
PageSpeed Insights также показывает производительность вашей страницы, по метрикам Core Web Vitals.
Core Web Vitals или основные интернет-показатели состоят из трех метрик, которые оценивают загрузку, интерактивность и визуальную стабильность ваших веб-страниц. Google подтвердил, что Core Web Vitals станут сигналом ранжирования в июне 2021 года.
Вы можете проверить производительность всех страниц своего веб-сайта с помощью отчета “Основные интернет-показатели” в Google Search Console.
Если окажется, что многие URL-адреса работают плохо или нуждаются в улучшении, обратитесь к разработчику.
Оптимизация для мобильных устройств
В Google 65% поисковых запросов выполняются на мобильных устройствах. Вот почему удобство для мобильных устройств с 2015 года является важным для мобильных устройств.
Вот почему удобство для мобильных устройств с 2015 года является важным для мобильных устройств.
С 2019 года удобство для мобильных устройств также является фактором ранжирования для поиска на компьютерах благодаря переходу Google на индексацию, ориентированную на мобильные устройства. Это означает, что “для индексирования и ранжирования Google отдают преимущество мобильной версии контента” на всех устройствах.
Другими словами, отсутствие поддержки мобильных устройств может повлиять на ранжирование по запросам с любых устройств.
Вы можете проверить удобство использования любой веб-страницы на мобильных устройствах с помощью инструмента Google Проверка оптимизации для мобильных или в отчете Удобство для мобильных в Google Search Console.
Поисковые системы понимают, что разным людям нравятся разные результаты. Поэтому они адаптируют свои результаты для каждого пользователя.
Если вы когда-либо искали одно и то же на нескольких устройствах или в разных браузерах, вы, вероятно, могли заметить эффект такой персонализации. Результаты часто отображаются на разных позициях в зависимости от различных факторов.
Результаты часто отображаются на разных позициях в зависимости от различных факторов.
Именно из-за этой персонализации, если вы занимаетесь SEO, для отслеживания позиций ранжирования вам лучше использовать специальный инструмент, такой как Ранк Трекер от Ahrefs. Заявленные позиции в этих инструментах, вероятно, будут ближе к истине, потому что они просматривают Интернет так, чтобы поисковые системы получали минимум информации для персонализации.
Как поисковые системы персонализируют результаты?
Google заявляет: “Чтобы предоставлять пользователям наиболее подходящую и актуальную информацию, мы учитываем сведения об их местоположении, предыдущих запросах, настройках Google Поиска и т. д.”.
Давайте подробнее рассмотрим эти три пункта.
1. Местоположение
Если вы введете что-то вроде “итальянский ресторан”, все результаты на картах будут местными ресторанами.
Google делает это, потому что вы вряд ли проедете полмира ради обеда.
Но Google также использует ваше местонахождение для персонализации результатов поиска не только на картах. Если мы пролистаем поисковую выдачу по запросу “итальянский ресторан”, даже результаты TripAdvisor будут персонализированными, и мы увидим, что многие из лучших результатов — это веб-сайты местных ресторанов.
Если мы пролистаем поисковую выдачу по запросу “итальянский ресторан”, даже результаты TripAdvisor будут персонализированными, и мы увидим, что многие из лучших результатов — это веб-сайты местных ресторанов.
Схожая ситуация с запросом “купить дом”. Google показывает страницы с местными объявлениями вместо международных, потому что вы, вероятно, не хотите переезжать в другую страну.
Ваше местонахождение настолько сильно влияет на результаты локальных запросов, что при поиске одного и того же запроса из двух разных мест, поисковые выдачи почти полностью отличаются.
2. Язык
Google знает, что нет смысла показывать результаты на английском пользователям в Испании. Поэтому Google ранжирует английскую версию нашего руководства по SEO для YouTube для поиска на английском языке, а испанскую версию для поиска на испанском языке.
Однако в этом Google в некоторой степени полагается на владельцев веб-сайтов. Если у вас есть страницы на нескольких языках, Google может не понять этого, пока вы им на это не укажете.
Вы можете сделать это с помощью HTML-атрибута под названием hreflang.
Hreflang немного сложен и выходит далеко за рамки этого руководства, но, если коротко, это небольшой фрагмент кода, указывающий на взаимосвязь между несколькими версиями одной и той же страницы на разных языках.
3. Журнал поиска
Возможно, наиболее очевидный пример использования Google истории поиска для персонализации результатов — это когда он “ставит” результат, по которому вы ранее кликали, выше при следующем выполнении того же поиска.
Это случается не всегда, но кажется довольно часто, особенно если вы нажимаете или посещаете страницу несколько раз за короткий промежуток времени.
Подведем итоги
Понимание того, как работают поисковые системы, — это первый шаг к более высокому ранжированию в Google и увеличению трафика. Если поисковые системы не могут найти, просканировать и проиндексировать ваши страницы, то они будут неконкурентоспособными еще до того, как вы начнете их оптимизировать.
Если вы хотите знать, как это сделать и как начать оптимизацию своего сайта для SEO, прочитайте наше руководство по основам SEO.
Есть вопросы? Дайте знать в комментариях или Твиттере.
Как работают поисковые системы? Руководство для начинающих
Джошуа Хардвик
Руководитель отдела контента @ Ahrefs (или, говоря простым языком, я отвечаю за то, чтобы каждый пост в блоге, который мы публикуем, был EPIC).
СТАТИСТИКА СТАТИКА
-
Ежемесячный трафик 4 544
-
Связывание веб -сайтов 329
-
твиты 74
. содержание. Как правило, чем больше веб-сайтов ссылаются на вас, тем выше ваш рейтинг в Google.
Показывает расчетный месячный поисковый трафик этой статьи по данным Ahrefs. Фактический поисковый трафик (по данным Google Analytics) обычно в 3-5 раз больше.
Фактический поисковый трафик (по данным Google Analytics) обычно в 3-5 раз больше.
Сколько раз этой статьей поделились в Твиттере.
Поделиться этой статьей
Поисковые системы сканируют миллиарды страниц с помощью поисковых роботов. Также известные как пауки или боты, поисковые роботы перемещаются по сети и переходят по ссылкам, чтобы найти новые страницы. Затем эти страницы добавляются в индекс, из которого поисковые системы извлекают результаты.
Понимание того, как работают поисковые системы, имеет решающее значение, если вы занимаетесь SEO. В конце концов, трудно что-то оптимизировать, если вы не знаете, как это работает.
Этому вы научитесь в этом руководстве.
Contents
Contents
Давайте начнем с изучения того, что такое поисковые системы, почему они существуют и как они зарабатывают деньги.
Что такое поисковые системы?
Поисковые системы — это доступные для поиска базы данных веб-контента. Они состоят из двух основных частей:
Они состоят из двух основных частей:
- Индекс поиска. Цифровая библиотека информации о веб-страницах.
- Алгоритм(ы) поиска . Компьютерная программа(ы), которой поручено сопоставлять результаты поискового индекса.
Какова цель поисковых систем?
Каждая поисковая система стремится предоставить пользователям наилучшие и наиболее релевантные результаты. Отчасти именно так они завоевывают долю рынка.
Как поисковые системы зарабатывают деньги?
Поисковые системы имеют два типа результатов поиска:
- Обычные результаты из поискового индекса. Вы не можете платить за то, чтобы быть здесь.
- Платные результаты от рекламодателей. Вы можете заплатить, чтобы быть здесь.
Каждый раз, когда кто-то нажимает на платный результат поиска, рекламодатель платит поисковой системе. Это известно как реклама с оплатой за клик (PPC), и именно поэтому доля рынка имеет значение. Чем больше пользователей, тем больше кликов по объявлениям и больше доходов.
Чем больше пользователей, тем больше кликов по объявлениям и больше доходов.
У каждой поисковой системы свой процесс построения поискового индекса. Ниже представлена упрощенная версия процесса, который использует Google. [1]
Давайте разберемся.
URL-адреса
Все начинается с известного списка URL-адресов. Google обнаруживает их разными способами, но наиболее распространенными являются три:
- По обратным ссылкам. Google имеет индекс сотен миллиардов веб-страниц. [2] Если кто-то ссылается на новую страницу с известной страницы, Google может найти ее оттуда.
- Из карт сайта. Файлы Sitemap сообщают Google, какие страницы и файлы, по вашему мнению, важны на вашем сайте. [3]
- Из отправленных URL. Google позволяет владельцам сайтов запрашивать сканирование отдельных URL-адресов в Google Search Console.
Сканирование
Сканирование — это когда компьютерный бот, называемый пауком, посещает и загружает известные URL-адреса. Поисковый робот Google — Googlebot. [4]
Поисковый робот Google — Googlebot. [4]
Обработка и рендеринг
Обработка — это то, где Google работает, чтобы понять и извлечь ключевую информацию из просканированных страниц. Для этого он должен отобразить страницу, где он запускает код страницы, чтобы понять, как она выглядит для пользователей.
Никто за пределами Google не знает всех деталей этого процесса. Но это не имеет значения. Все, что нам действительно нужно знать, это то, что это включает в себя извлечение ссылок и сохранение контента для индексации.
Индексирование
Индексирование — это добавление обработанной информации с просканированных страниц в поисковый индекс.
Поисковый индекс — это то, что вы ищете, когда используете поисковую систему. Вот почему индексирование в основных поисковых системах, таких как Google и Bing, так важно. Пользователи не смогут найти вас, если вы не в индексе.
Обнаружение, сканирование и индексирование контента — это только первая часть головоломки.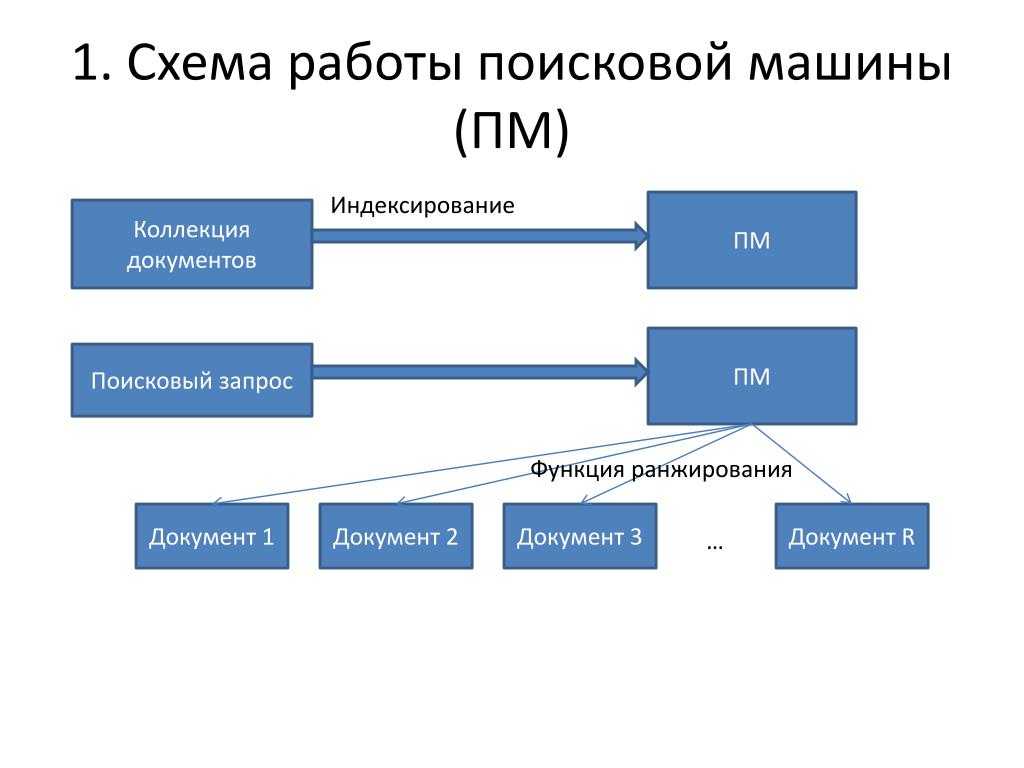 Поисковым системам также нужен способ ранжирования результатов поиска, когда пользователь выполняет поиск. Это работа поисковых алгоритмов.
Поисковым системам также нужен способ ранжирования результатов поиска, когда пользователь выполняет поиск. Это работа поисковых алгоритмов.
Что такое алгоритмы поиска?
Алгоритмы поиска — это формулы, которые сопоставляют и ранжируют релевантные результаты индекса. Google использует множество факторов в своих алгоритмах.
Ключевые факторы ранжирования Google
Никто не знает всех факторов ранжирования Google, потому что Google их не раскрывает. Но мы знаем некоторые ключевые. Давайте посмотрим на некоторые из них.
Обратные ссылки
Обратные ссылки — это ссылки со страницы одного веб-сайта на другой. Они являются одним из самых сильных факторов ранжирования Google. [6] Вероятно, поэтому мы увидели сильную корреляцию между связывающими доменами и органическим трафиком в нашем исследовании более миллиарда страниц. [7]
Однако дело не только в количестве. Качество тоже имеет значение. Страницы с несколькими высококачественными обратными ссылками часто опережают страницы с большим количеством некачественных обратных ссылок.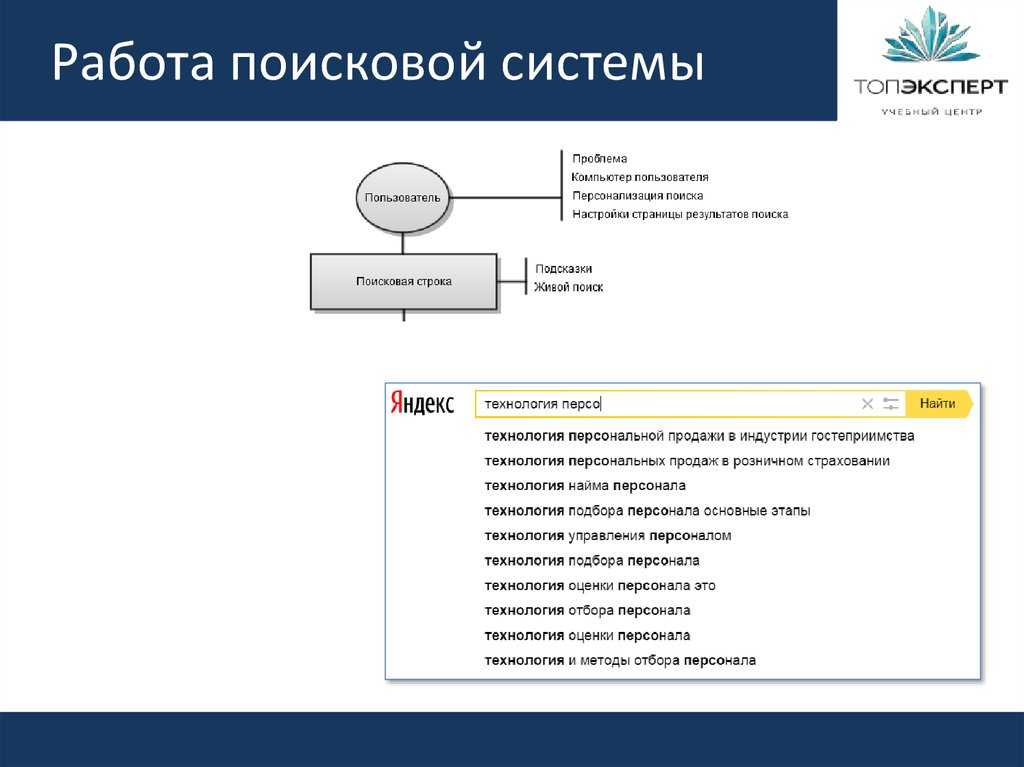
Актуальность
Релевантность — полезность данного результата для искателя. У Google есть много способов определить это. На самом базовом уровне он ищет страницы, содержащие те же ключевые слова, что и поисковый запрос. Он также просматривает данные о взаимодействии, чтобы узнать, нашли ли другие результаты полезными. [9]
Актуальность
Актуальность — это фактор ранжирования, зависящий от запроса. Это сильнее для поисков, которые требуют свежих результатов. [9] Вот почему вы видите недавно опубликованный лучший результат для «новой серии netflix», а не для «как собрать кубик Рубика».
Скорость страницы
Скорость страницы является фактором ранжирования на настольных и мобильных устройствах. [10][11] Но это скорее отрицательный фактор ранжирования, чем положительный. Это связано с тем, что это негативно влияет на самые медленные страницы, а не положительно влияет на молниеносные страницы.
Удобство для мобильных устройств
Удобство для мобильных устройств стало фактором ранжирования на мобильных и настольных компьютерах с тех пор, как Google перешел на индексирование для мобильных устройств в 2019 году. [12]
[12]
Google адаптирует результаты поиска для каждого пользователя. Для этого он использует такую информацию, как ваше местоположение, язык и историю поиска. [9] Давайте рассмотрим эти вещи поближе.
Местоположение
Google использует ваше местоположение для персонализации результатов поиска с местными намерениями. Вот почему все результаты поиска по запросу «итальянский ресторан» относятся к местным ресторанам или о них. Google знает, что вы вряд ли пролетите полмира, чтобы пообедать.
Язык
Google знает, что нет смысла показывать результаты на английском языке испанским пользователям. Вот почему он ранжирует локализованные версии контента (если они доступны) среди пользователей, говорящих на разных языках.
История поиска
Google сохраняет ваши действия и места, которые вы посещаете, чтобы сделать поиск более персонализированным. [13] Вы можете отказаться от этого, но большинство людей, вероятно, этого не сделают.
Основные выводы
- Поисковая система состоит из двух основных частей: индекса и алгоритмов.
- Для создания индекса он сканирует известные страницы и переходит по ссылкам, чтобы найти новые.
- Целью алгоритмов поиска является предоставление наилучших и наиболее релевантных результатов.
- Качество результатов поиска важно для увеличения доли рынка.
- Никто не знает всех факторов ранжирования Google для органических результатов.
- Ключевые факторы ранжирования включают обратные ссылки, релевантность и свежесть.
- Google персонализирует свои результаты на основе вашего местоположения, языка и истории поиска.
Ссылки
- «Понимание основ JavaScript SEO». Гугл. Проверено 16 августа 2022 г.
- «Организация информации — как работает поиск Google». Гугл. Проверено 16 августа 2022 г.
- «Узнайте о картах сайта». Гугл. Проверено 16 августа 2022 г.
- «Googlebot». Гугл . Проверено 16 августа 2022 г.
- «Доля рынка поисковых систем в мире». Счетчик статистики . Проверено 16 августа 2022 г.
- «Google Q&A+ #March». Ютуб . Проверено 16 августа 2022 г.
- «90,63% контента не получает трафика от Google. И как быть в других 9,37%». Арефс . 31 января 2020 г. Проверено 16 августа 2022 г.
- «Радар CloudFlare». CloudFlare . Проверено 16 августа 2022 г.
- «Рейтинг результатов поиска — как работает поиск Google». Гугл. Проверено 16 августа 2022 г.
- «Использование скорости сайта в рейтинге веб-поиска». Гугл. Проверено 16 августа 2022 г.
- «Использование скорости страницы в рейтинге мобильного поиска». Гугл. Проверено 16 августа 2022 г.
- «Передовой опыт мобильного индексирования». Гугл. Проверено 16 августа 2022 г.
- «Находите и контролируйте свою активность в Интернете и приложениях».
 Гугл. Проверено 16 августа 2022 г.
Гугл. Проверено 16 августа 2022 г.
Что такое поисковые операторы? Список основных операторов поиска
Полное руководство по операторам и параметрам поиска Google
Операторы расширенного поиска можно ввести непосредственно в поле поиска Google для уточнения поиска. Параметры поиска можно использовать для создания собственных строк поиска, введя их в адресную строку, также называемую омнибаром Chrome.
Оператор поиска может выглядеть так:
allintitle: tesla vs edison
Параметр поиска может выглядеть так:
https://www.google.com/search?q="nikola+tesla"
Что такое поисковые операторы Google?
Поисковые операторы Google — это специальные символы и команды, иногда называемые «расширенными операторами», или параметры поиска, расширяющие возможности обычного текстового поиска. Поисковые операторы могут быть полезны для всего: от исследования контента до технического SEO-аудита.
Как использовать операторы поиска?
Вы можете вводить поисковые операторы непосредственно в поле поиска Google, как и при текстовом поиске:
За исключением особых случаев (таких как оператор «in»), Google выдаст стандартные органические результаты.
Шпаргалка по поисковым операторам Google
Вы можете найти все основные операторы органического поиска ниже, разбитые на три категории: «Базовый», «Расширенный» и «Ненадежный». Базовые операторы поиска — это операторы, которые изменяют стандартные текстовые поиски.
| I. Основные операторы поиска | |
|---|---|
| » » | «никола тесла» Поместите любую фразу в кавычки, чтобы заставить Google использовать точное соответствие. На отдельные слова, всякие синонимы. |
| ИЛИ | tesla ИЛИ edison Поиск Google по умолчанию использует логическое И между терминами. 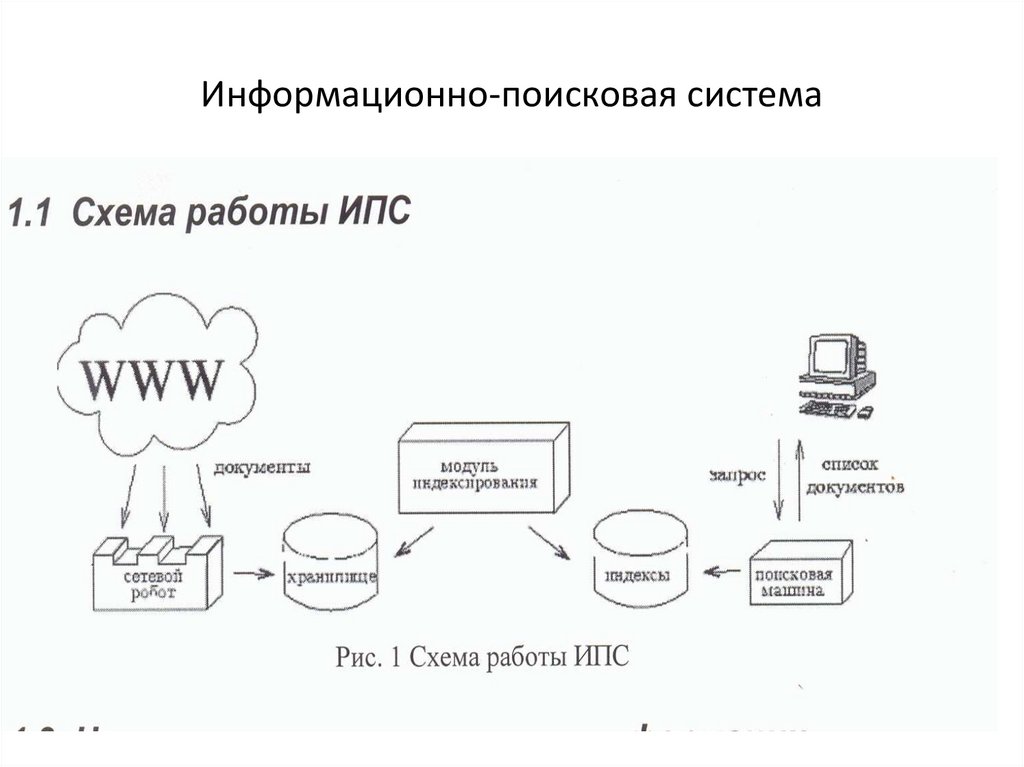 Укажите «ИЛИ» для логического ИЛИ (ВСЕ ЗАГЛАВНЫЕ). Укажите «ИЛИ» для логического ИЛИ (ВСЕ ЗАГЛАВНЫЕ). |
| | | тесла | edison Оператор трубы (|) идентичен «ИЛИ». Полезно, если у вас сломался Caps-lock 🙂 |
| ( ) | (tesla ИЛИ edison) переменный ток Используйте скобки для группировки операторов и управления порядком их выполнения. |
| — | tesla-motors Поставьте минус (-) перед любым термином (включая операторов), чтобы исключить его из результатов. |
| * | tesla «rock * roll» Звездочка (*) действует как подстановочный знак и соответствует любому слову. |
| #..# | объявление tesla 2015..2017 Используйте (..) с числами с обеих сторон, чтобы найти соответствие любому целому числу в этом диапазоне чисел. |
| $ | Тесла депозит $1000 Поиск цен со знаком доллара ($).  Вы можете комбинировать ($) и (.) для получения точных цен, например 19,99 долларов США. Вы можете комбинировать ($) и (.) для получения точных цен, например 19,99 долларов США. |
| € | Обеды по цене 9,99 € Поиск цен со знаком евро (€). Google не соблюдает большинство других знаков валюты. |
| дюймы | 250 км/ч в милях/ч Используйте «in» для преобразования между двумя эквивалентными единицами измерения. Это возвращает специальный результат в стиле карты знаний. |
Операторы расширенного поиска — это специальные команды, которые изменяют поиск и могут потребовать дополнительных параметров (например, имени домена). Расширенные операторы обычно используются для сужения поиска и более глубокого изучения результатов.
| II. Операторы расширенного поиска | |
|---|---|
| intitle: | intitle:»tesla vs edison» Поиск слова или фразы только в заголовке страницы.  Используйте точное соответствие (кавычки) для фраз. Используйте точное соответствие (кавычки) для фраз. |
| allintitle: | allintitle: tesla vs edison Найдите в заголовке страницы каждый отдельный термин, следующий за «allintitle:». То же, что несколько intitle:’s. |
| inurl: | объявления tesla inurl:2016 Найдите слово или фразу (в кавычках) в URL-адресе документа. Может сочетаться с другими терминами. |
| allinurl: | allinurl: amazon field-keywords nikon Найдите в URL каждый отдельный термин, следующий за «allinurl:». То же, что несколько inurl:’s. |
| intext: | intext:»orbi vs eero vs google wifi» Поиск слова или фразы (в кавычках), но только в основном тексте/тексте документа. |
| allintext: | allintext: orbi eero google wifi Поиск в основном тексте каждого отдельного термина, следующего за словом «allintext:». 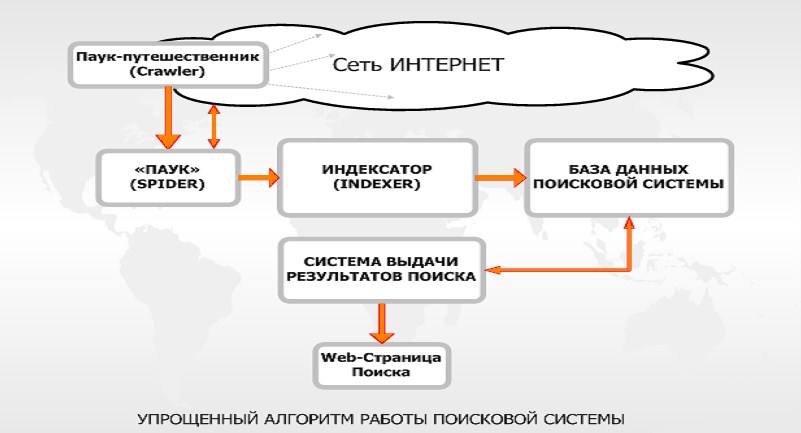 То же, что несколько intexts:’s. То же, что несколько intexts:’s. |
| тип файла: | «объявления tesla» тип файла: pdf Соответствует только определенному типу файла. Некоторые примеры включают PDF, DOC, XLS, PPT и TXT. |
| связанные: | связанные:nytimes.com Возврат сайтов, связанных с целевым доменом. Работает только для больших доменов. |
| AROUND(X) | tesla AROUND(3) edison Возвращает результаты, в которых два термина/фразы находятся в пределах (X) слов друг от друга. |
Было обнаружено, что ненадежные операторы дают противоречивые результаты или вообще не рекомендуются. Оператор link: был официально объявлен устаревшим в начале 2017 года. Похоже, что операторы inanchor: все еще используются, но возвращают очень узкие и иногда ненадежные результаты. Используйте операторы на основе ссылок только для первоначальных исследований.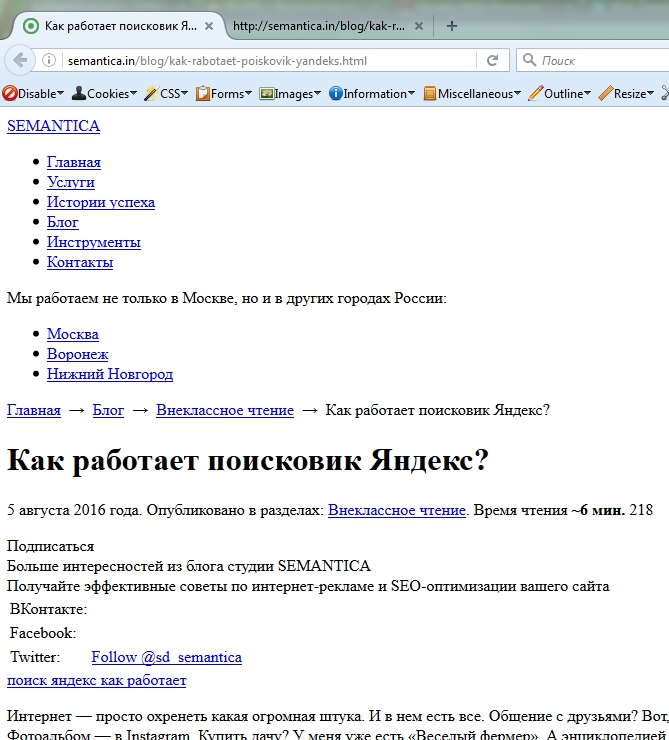
| III. Ненадежные/устаревшие операторы | |
|---|---|
| ~ | ~автомобили Включите синонимы. Кажется ненадежным, и теперь включение синонимов по умолчанию. |
| + | +cars Принудительное точное совпадение для одной фразы. Устарело с запуском Google+. |
| daterange: | объявления tesla daterange: 2457663-2457754 Возвращает результаты в указанном диапазоне. Может быть непоследовательным. Требуются юлианские даты. |
| ссылка: | ссылка:nytimes.com Поиск страниц, ссылающихся на целевой домен. Этот оператор устарел в начале 2017 года. |
| inanchor: | inanchor:»объявления tesla» Поиск страниц, связанных с указанным текстом/фразой привязки.  Данные сильно сэмплированы. Данные сильно сэмплированы. |
| allinanchor: | allinanchor: объявления tesla Найдите страницы со всеми отдельными терминами после «inanchor:» во входящем якорном тексте. |
Обратите внимание, что для всех операторов «allin…:» Google попытается применить оператор к каждому термину, следующему за ним. Комбинирование операторов «allin…:» с любыми другими операторами почти никогда не даст желаемых результатов.
Советы и рекомендации оператора поиска
Наличие всех частей — это только первый шаг в сборке головоломки. Настоящая сила поисковых операторов заключается в их объединении.
1. Объединение в цепочку комбинаций операторов
Вы можете объединить практически любую комбинацию текстового поиска, основных и расширенных операторов:
"Никола Тесла" intitle:"5..10 лучших фактов" -site:youtube.com inurl:2015
Этот поиск возвращает все страницы, на которых упоминается «Никола Тесла» (точное совпадение), есть фраза «Лучшие ( X) facts» в заголовке, где X находится в диапазоне от 5 до 10, не находятся на YouTube.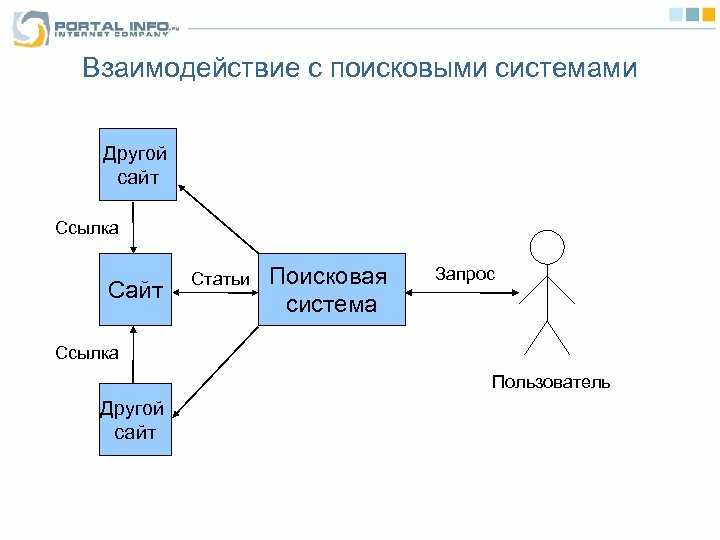 com, а где-то в URL есть «2015».
com, а где-то в URL есть «2015».
2. Выследите плагиат
Пытаетесь выяснить, уникален ли ваш контент или кто-то занимается плагиатом? Используйте уникальную фразу из вашего текста, поместите ее в кавычки (точное совпадение) после оператора «intext:» и исключите свой собственный сайт с помощью «-site:»…
intext:"они резвились в наших внутренностях" -site:moz.com
Точно так же вы можете использовать «intitle:» с длинной фразой с точным соответствием, чтобы найти дубликаты вашего контента.
3. Проведите аудит перехода HTTP->HTTPS
Переключение сайта с HTTP на HTTPS может оказаться сложной задачей. Дважды проверьте свой прогресс, увидев, сколько страниц каждого типа проиндексировано Google. Используйте оператор «site:» в корневом домене, а затем исключите страницы HTTPS с помощью «-inurl:»…
site:moz.com -inurl:https
Это поможет вам отследить отставших или найти страницы, которые Google, возможно, не просканировал повторно.
Это всего лишь несколько примеров почти бесконечного набора комбинаций. Ищете другие примеры? Вам повезло! Мы создали мега-список из 67 примеров, чтобы подтолкнуть вас к мастерству оператора сайта.
Поднимитесь в рейтинге с Moz Pro
Обладая первоклассными данными о ссылках и ключевых словах, а также углубленной аналитикой, Moz Pro обеспечивает отслеживание и аналитику, необходимые для достижения #1. Воспользуйтесь бесплатной 30-дневной пробной версией и узнайте, чего вы можете достичь:
Начать бесплатную пробную версию
Подробное изучение параметров поиска Google
Вы когда-нибудь хотели узнать, как создавать собственные строки поиска Google? Это окончательное руководство содержит все параметры строки поиска Google. Вы также можете создать свой собственный расширенный поиск, используя форму расширенного поиска Google.
http://www.google.com/search?
URL-адрес Google. Вы увидите это, если посмотрите на адресную строку или омнибар Chrome.
q=запрос+идет+сюда
Строка запроса. Слова разделяются знаком +.
Все, начиная с этого места, начинается со знака &, так как оно помечено до конца. Здесь все становится интереснее…
as_epq=query+goes+здесь
Результаты должны включать запрос в отображаемом порядке слов.
Показывает как «запрос идет сюда»
as_oq="запрос+строка"+идет+здесь
Результаты должны содержать одно или несколько слов из этой строки. По сути, это как более продвинутая версия вышеприведенного, использующая фильтр «или». Таким образом, каждый результат должен иметь основной исходный запрос и один или несколько наборов терминов в этих строках.
Показывается как «строка запроса» ИЛИ идет ИЛИ здесь
as_eq=не+включать+эти+слова
Результаты НЕ должны содержать никаких слов в этой строке.
Показывает как -не -включать -эти -слова
num=xx
Управляет количеством отображаемых результатов. Должно быть числовым значением и может быть любым до 100. Не работает с дробями.
Должно быть числовым значением и может быть любым до 100. Не работает с дробями.
as_filetype=расширение
Возвращает только результаты, оканчивающиеся на .extension. В настоящее время поддерживает любой ввод. Попробуйте — создайте файл со случайным расширением, проиндексируйте его и выполните поиск. Также показывает, что до тех пор, пока он подтверждает что-то.
Показывает как тип файла:расширение
as_sitesearch=example.com
Ограничивает результаты только выбранным вами сайтом.
Показывает как site:example.com
as_qdr=x
Замените x на следующее, чтобы ограничить поиск только файлами, впервые проиндексированными в:
- d — предыдущие 24 часа
- w — предыдущие семь дней
- m — предыдущий месяц
- y — прошлый год
- млн — предыдущее n число месяцев. Таким образом, m2 будет двумя предыдущими, m3 будет тремя и так далее. Работает ли в двузначных числах
as_rights=xxx
Ограничивает поиск файлами/страницами, имеющими определенные права. Возможные варианты:
Возможные варианты:
- (cc_publicdomain|cc_attribute|cc_sharealike|cc_noncommercial|cc_nonderived) — бесплатное использование или распространение
- (cc_publicdomain|cc_attribute|cc_sharealike|cc_nonderived).-(cc_noncommercial) — бесплатное использование или распространение, в том числе в коммерческих целях
- (cc_publicdomain|cc_attribute|cc_sharealike|cc_noncommercial).-(cc_nonderived) — бесплатное использование, совместное использование или изменение
- (cc_publicdomain|cc_attribute|cc_sharealike).-(cc_noncommercial|cc_nonderived) — бесплатное использование, распространение или изменение в коммерческих целях (|), и исключите биты, которые вы не делаете, поместив их в квадратные скобки, с предшествующим .- и снова разделенными вертикальной чертой.
allintitle%3AПоиск+термины
На самом деле это добавляется к параметру q=, поэтому для поиска рыбалки с термином allintitle «морской окунь» потребуется следующий запрос:
q=fishing+allintitle%3Asea+bass
Показывает как allintitle:search terms
N.
 B. Это также работает с allintext для поиска основного текста страницы, allinurl для поиска URL-адреса и allinanchor для поиска сайтов, на которые есть ссылки с определенным якорным текстом.
B. Это также работает с allintext для поиска основного текста страницы, allinurl для поиска URL-адреса и allinanchor для поиска сайтов, на которые есть ссылки с определенным якорным текстом. ннн..гггг
Подобно параметрам allin, фактически добавляется к параметру q=. Однако это позволяет вам искать результаты между числовыми диапазонами. Например, если вы хотите найти документы с номерами от 15 до 100, вы должны ввести 15..100. Очень полезно для поиска товаров в ценовом диапазоне в сочетании с ограничителем сайта. Работает с $, £ и другими подобными вещами.
Показывает как запрос 15..100
%2Bterm
Опять же, это добавляется к параметру q=. %2B на самом деле представляет собой закодированный знак + и будет возвращать результаты, содержащие только используемый термин, без множественного числа, альтернативных времен или синонимов.
Показывается как +term
~term
Еще один, который добавляется к параметру q=.
 Возвращает результаты для используемого термина и синонимов.
Возвращает результаты для используемого термина и синонимов. Отображается как ~term
определить%3Aword 9n2 и n% от n2
Функции калькулятора Google. Они по порядку складывают, вычитают, делят, умножают, возводят в степень и возвращают х процентов.
safe=active
Включает безопасный поиск. Чтобы отключить его, измените активное на изображения.
as_rq=example.com
Находит сайты, которые, по мнению Google, связаны с введенным URL-адресом.
Показывает как query related:example.com ты вставляешь.
Показывает как запрос link:example.com
newwindow=n
Открывает выбранные списки в новом окне. Очень полезно для одновременного открытия большого количества документов, для изучения конкурентов. Установите 1, чтобы активировать, и 0, чтобы выключить.
pws
Определяет, включен персональный поиск или нет. Установите 1, чтобы активировать, и 0, чтобы выключить.
adtest=on
Отключает соединение с базой данных AdWords, чтобы ваш просмотр не отображался как просмотр, и отключает URL-адреса. Включите, чтобы активировать, и выключите, чтобы выключить.
btnG=Поиск
Имитирует щелчок по обычным результатам Google buttpm. Измените на btnI, чтобы получить результат кнопки «Мне повезет».
т.е.=
Управляет настройками кодирования ввода. По умолчанию используется UTF-8 и обрабатывается на стороне сервера, поэтому его изменение ничего не дает.
oe=
Управляет настройками кодирования вывода. Работает так же, как и ie, так что можно повозиться, но ничего не получится.
&hl=значение
Изменяет язык интерфейса. Я не буду перечислять их все здесь, но вы можете найти их все здесь.
lr=значение
Ограничивает языки, используемые для возврата результатов. Не очень эффективно. Тем не менее, вот список всех из них:
- LANG_AR — Арабский
- LANG_HY — Арменан
- LANG_BE — Belarusian
- LANG_BG — Bulgarian
- LANG_CA -CATALAN
- LANG_HRIN
- — Датский
- lang_nl — Голландский
- lang_en — Английский
- lang_eo — Эсперанто
- lang_et — Estonian
- lang_tl — Filipino
- lang_fi — Finnish
- lang_fr — French
- lang_de — German
- lang_el — Greek
- lang_iw — Hebrew
- lang_hu — Hungarian
- lang_is — Icelandic
- lang_id — Indonesian
- lang_it — итальянский
- lang_ja — японский
- lang_ko — корейский
- lang_lv — латышский
- lang_lt — литовский
- lang_no — норвежский
- lang_fa — Persian
- lang_pl — Polish
- lang_pt — Portuguese
- lang_ro — Romanian
- lang_ru — Russian
- lang_sr — Serbian
- lang_sk — Slovak
- lang_sl — Slovenian
- lang_es — Spanish
- lang_sv — Swedish
- lang_th — тайский
- lang_tr — турецкий
- lang_uk — украинский
- lang_vi — вьетнамский
- lang_zh-CN — китайский упрощенный
- lang_zh-TW — китайский традиционный
cr=countryXX
Ограничивает результаты поиска страницами/сайтами из определенных местоположений. Замените XX на любой из следующих, чтобы ограничить результаты:
Замените XX на любой из следующих, чтобы ограничить результаты:
- AF — Афганистан
- AL — Албания
- DZ — Алжир
- AS — Американское Самоа
- AD — Андорра
- AI — Ангола 9000
- AQ — Антарктида
- AG — Антигуа и Барбуда
- AR — Аргентина
- AM — Армения
- AW — Аруба
- AU — Australia
- AT — Austria
- AZ — Azerbaijan
- BS — Bahamas
- BH — Bahrain
- BD — Bangladesh
- BB — Barbados
- BY — Belarus
- BE — Belgium
- BZ — Belize
- BJ — Benin
- BM — Бермуда
- BT — Bhutan
- BO — Боливия
- BA — Bosnia и Herzegovina
- BW — BOTSWANA
- BV — BOUVET ISPLIN0009 IO — Территория Британского Индийского океана
- VG — Британские Виргинские острова
- BN — Brunei
- BG — Болгария
- BF — Burkina FASO
- BI — Burundi
- KH — Cambodia
- CM -CARANI
- KH -Cambodia
- CM -CARANIN
- KH -Cambodia
- .
- CV — Cape Verde
- KY — Cayman Islands
- CF — Центральная Африканская Республика
- TD — Chad
- CL — Чили
- CN — Китай
- CX — остров Рождества
- CC — COCOSING).0013
- CO — Colombia
- KM — Comoros
- CG — Congo — Brazzaville
- CD — Congo — Kinshasa
- CK — Cook Islands
- CR — Costa Rica
- CI — Cote d’Ivoire
- HR — Croatia
- CU — Cuba
- CY — Кипр
- CZ — Чешская Республика
- DK — Дания
- DJ — DJIBOUTI
- DM — Dominica
- DO — Доминиканская Республика
- EC -ECUADOR
- DO — Dominican Republic
- ECUDOR
- .SV — El Salvador
- GQ — Equatorial Guinea
- ER — Eritrea
- EE — Estonia
- SZ — Eswatini
- ET — Ethiopia
- FK — Falkland Islands (Malvinas)
- FO — Faroe Islands
- FJ — Fiji
- FI — Финляндия
- FR — Франция
- GF — Французская Гвиана
- PF — Французская Полинезия
- TF — Французские Южные Территории
- GA — Габон
- GM1 Грузия — Гамбия
13
- DE — Германия
- GH — GHANA
- GI — Gibraltar
- GR — Greece
- GL — Гренландия
- GD — Grenada
- GP — Guadeloupe
- GUAM13
- GP — Guadeloupe
- 9000 9009
- GP -GUADELOUP
- GW — Guinea-Bissau
- GY — Guyana
- HT — Haiti
- HM — Heard and McDonald Islands
- VA — Holy Sea
- HN — Honduras
- HK — Hong Kong
- HU — Hungary
- IS — Iceland
- IN — India
- ID — Indonesia
- IQ — Iraq
- IE — Ireland
- IL — Israel
- IT — Italy
- JM — Jamaica
- JP — Japan
- JO — Jordan
- KZ — Казахстан
- KE — Кения
- KI — Кирибати
- KP — Корея, Народно-Демократическая Республика
- KR — Корея, Республика
- KW — Кувейт
- KG — Лаосская Народно-Демократическая Республика 3 3
- LV — Latvia
- LB — Lebanon
- LS — Lesotho
- LR — Liberia
- LY — Libyan Arab Jamahiriya
- LI — Liechtenstein
- LT — Lithuania
- LU — Luxembourg
- MO — Macau
- MK — Македония
- MG — Мадагаскар
- MW — Малави
- MY — Малайзия
- MV — Мальдивы
- ML — Мали
- MT — Мальта
- MH — Мартиник — Маршалловы острова0013
- MR — Mauritania
- MU — Mauritius
- YT — Mayotte
- MX — Мексика
- FM — Micronesia, Федеративные состояния
- MD — MODOVA, Республика
- MC — MONACO 9000 9000
- MN -MONGIOLIIA 9009 MONGIOLIIA 9009 MONGIOLIIA 9009 MONGIOLIIA 9009 MONGIOLIIA 9009 MONGIOLIIA
- .
 — Монтсеррат
— Монтсеррат - MA — Марокко
- MZ — Мозамбик
- MM — Мьянма
- NA — Намибия
- NR — Науру
- NP — Непал
- NL -3 Нидерланды
- NL -30013
- NC — Новая Caledonia
- NZ — Новая Зеландия
- NI — Никарагуа
- NE — NIGER
- NG — NIGERIA
- NU — NIUE
- NF -ISLIND
- MP -NIUE
- NF -НОР.
- OM — Oman
- PK — Pakistan
- PW — Palau
- PS — Palestinian Territory
- PA — Panama
- PG — Papua New Guinea
- PY — Paraguay
- PE — Peru
- PH — Philippines
- PN — Pitcairn
- PL — Польша
- PT — Португалия
- PR — Puerto Rico
- QA — Катар
- RE — Воссоединение
- RO — Romania
- Русская федерация 9009 9009 9009 9009 9009 9009 9009 9009 9009 999999999999999999. — Остров Святой Елены
- KN — Сент-Китс и Невис
- LC — Сент-Люсия
- PM — Сен-Пьер и Микелон
- VC — Сент-Винсент и Гренадины
- WS — Самоа
- 90 SM — Сан-Марино0009 ST — Sao Tome and Principe
- SA — Saudi Arabia
- SN — Senegal
- CS — Serbia and Montenegro
- SC — Seychelles
- SL — Sierra Leone
- SG — Singapore
- SK — Slovakia
- SI — Словения
- SB — Соломоновы острова
- SO — Сомали
- ZA — Южная Африка
- GS — Южная Георгия и Южные Сандвичевы острова
- ES — Испания
- LK — Шри-Ланка
- SD — Судан
- SD0013
- SR — Suriname
- SJ — Svalbard & Jan Mayen
- SE — Швеция
- CH — Швейцария
- SY — Сирийская арабская республика
- TW — Taiwan
- TJ -TJIKISTAN
- 9.