Какие бывают типы компьютерных сетей. Как классифицируются сети по территориальному признаку. Какие существуют топологии компьютерных сетей. На какие виды делятся сети по способу администрирования.
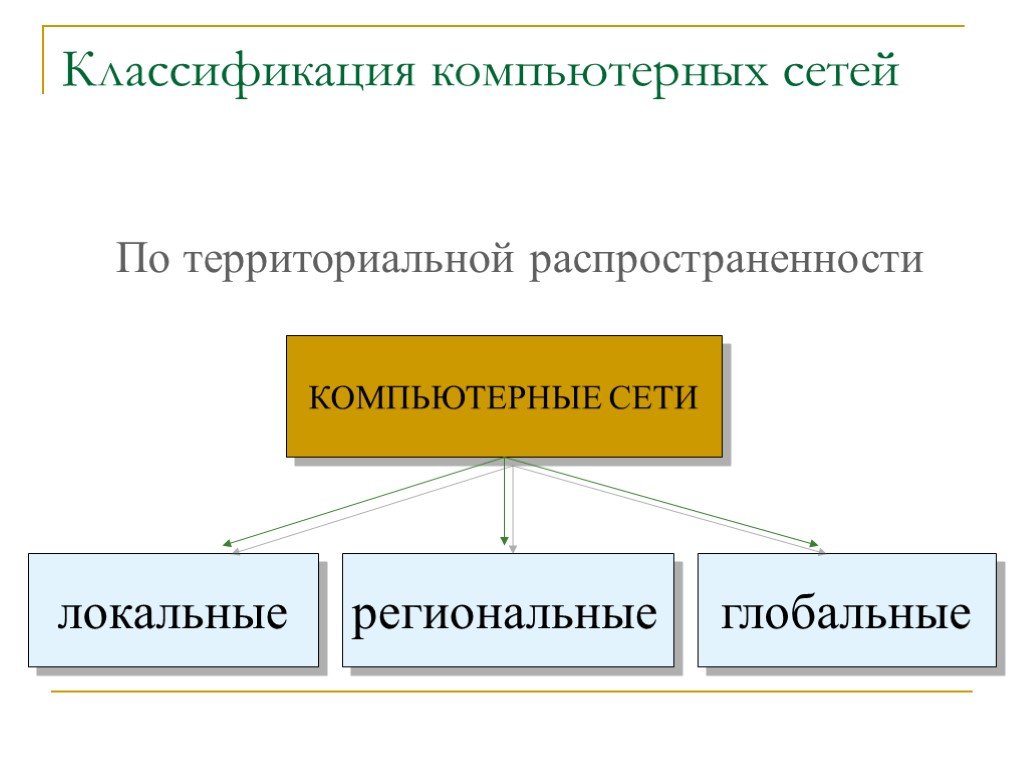
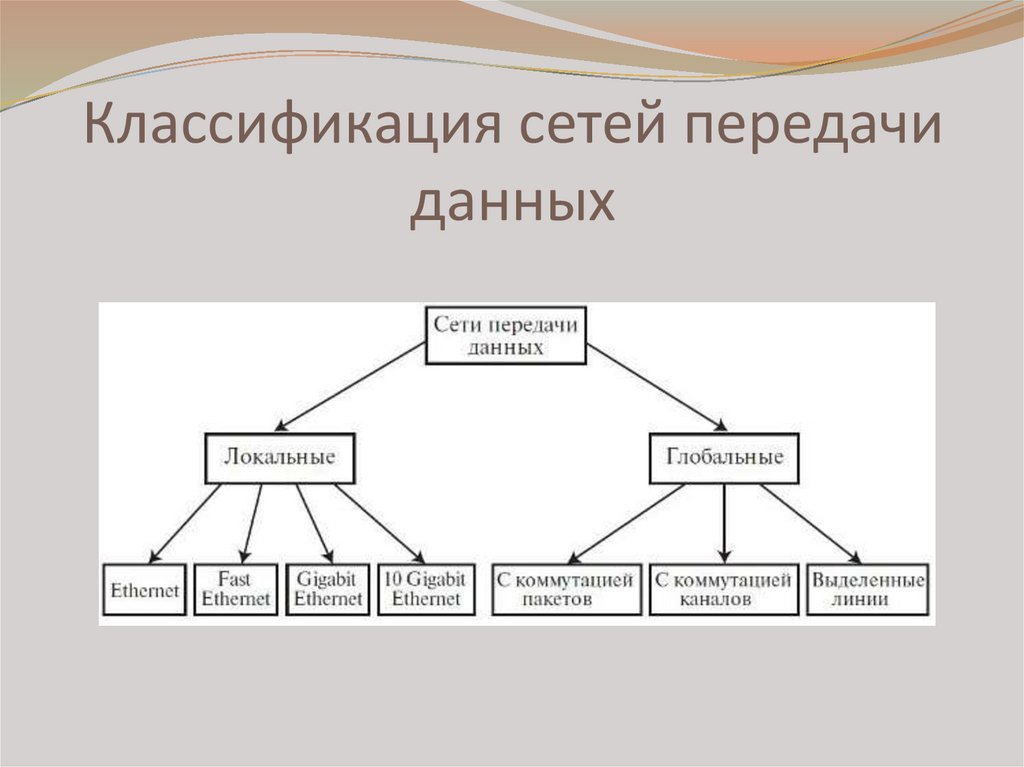
Классификация компьютерных сетей по территориальному признаку
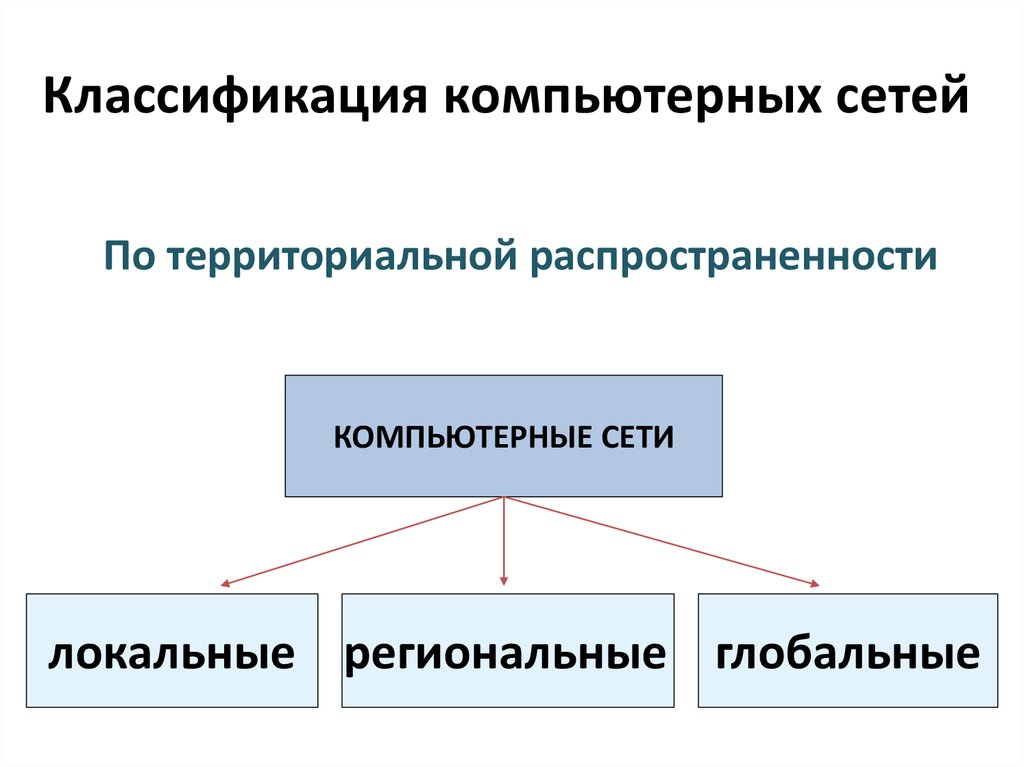
Компьютерные сети можно классифицировать по различным признакам. Одним из основных критериев является территориальный охват сети. По этому признаку выделяют следующие типы сетей:
- Локальные сети (LAN)
- Городские сети (MAN)
- Глобальные сети (WAN)
Давайте рассмотрим особенности каждого типа более подробно.
Локальные сети (LAN)
Локальные вычислительные сети (LAN — Local Area Network) охватывают небольшую территорию, обычно в пределах одного здания или группы близко расположенных зданий. Основные характеристики LAN:
- Протяженность до 1-2 км
- Высокая скорость передачи данных (100 Мбит/с — 1 Гбит/с)
- Использование высококачественных линий связи
- Широкий набор предоставляемых сервисов
- Работа преимущественно в режиме онлайн
Городские сети (MAN)
Городские сети (MAN — Metropolitan Area Network) занимают промежуточное положение между локальными и глобальными сетями. Их особенности:
- Охват территории города или региона (десятки километров)
- Использование высокоскоростных магистральных линий связи
- Объединение множества локальных сетей
- Скорости передачи данных сопоставимы с LAN
Глобальные сети (WAN)
Глобальные сети (WAN — Wide Area Network) охватывают большие территории (страны, континенты). Их ключевые характеристики:
- Неограниченная географическая протяженность
- Использование разнородных каналов связи
- Более низкие скорости передачи данных по сравнению с LAN
- Ориентация на передачу данных в фоновом режиме
- Сложные методы обеспечения надежности передачи
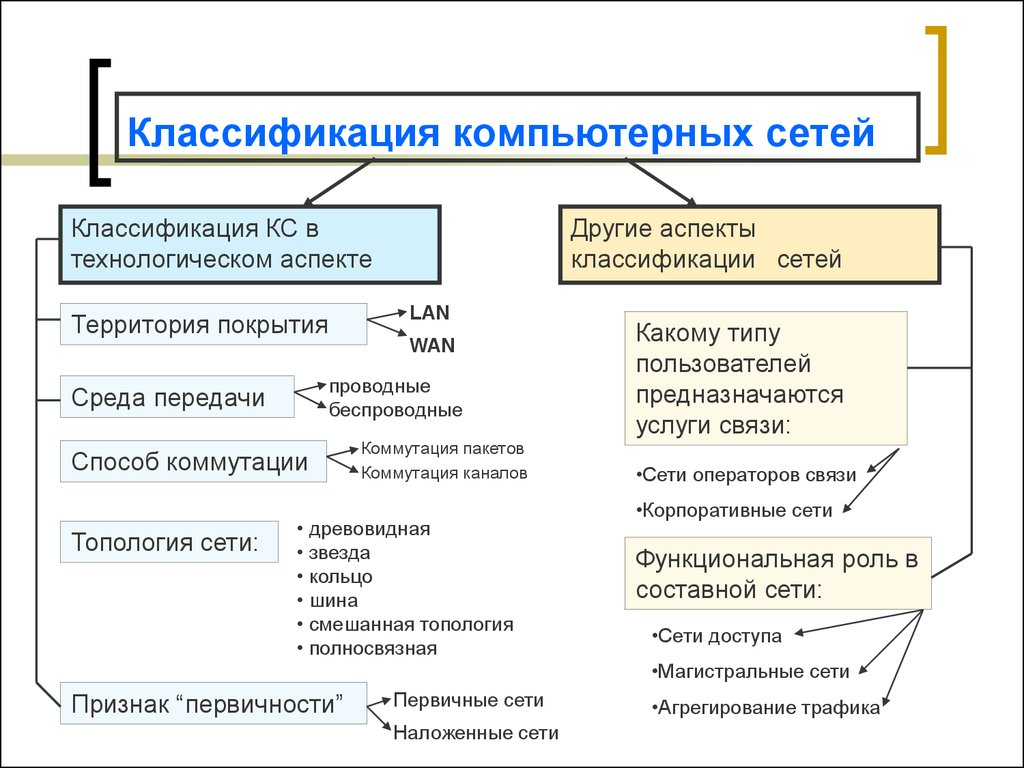
Классификация компьютерных сетей по топологии
Топология сети определяет физическое расположение компьютеров, кабелей и других компонентов сети. Выделяют следующие основные топологии:
Шинная топология
При шинной топологии все компьютеры подключены к общему кабелю — шине. Особенности:
- Простота реализации
- Экономия кабеля
- Легкость подключения новых узлов
- Уязвимость (повреждение центрального кабеля нарушает работу всей сети)
Кольцевая топология
В кольцевой топологии компьютеры соединены в замкнутое кольцо. Характеристики:
- Равноправный доступ для всех узлов
- Стабильная работа при большом количестве узлов
- Выход из строя одного узла может нарушить работу всей сети
Звездообразная топология
При звездообразной топологии все компьютеры подключены к центральному узлу (концентратору). Преимущества и недостатки:
- Централизованное управление
- Легкость подключения новых узлов
- Зависимость от работоспособности центрального узла
Классификация по способу администрирования
По способу администрирования и распределения ресурсов компьютерные сети делятся на два основных типа:
Одноранговые сети
В одноранговых сетях все компьютеры равноправны. Особенности:
- Отсутствие выделенного сервера
- Каждый компьютер может выступать как клиентом, так и сервером
- Простота организации
- Сложность централизованного управления
Сети на основе сервера (клиент-серверные)
В клиент-серверных сетях выделяются серверы, предоставляющие свои ресурсы клиентам. Характеристики:
- Централизованное хранение данных и управление доступом
- Повышенная защищенность данных
- Эффективное использование ресурсов
- Сложность администрирования
Классификация по масштабу
По масштабу охвата и количеству компьютеров сети можно разделить на:
- Малые (до 50 компьютеров)
- Средние (50-500 компьютеров)
- Крупные (свыше 500 компьютеров)
Масштаб сети влияет на выбор оборудования, технологий и методов управления.
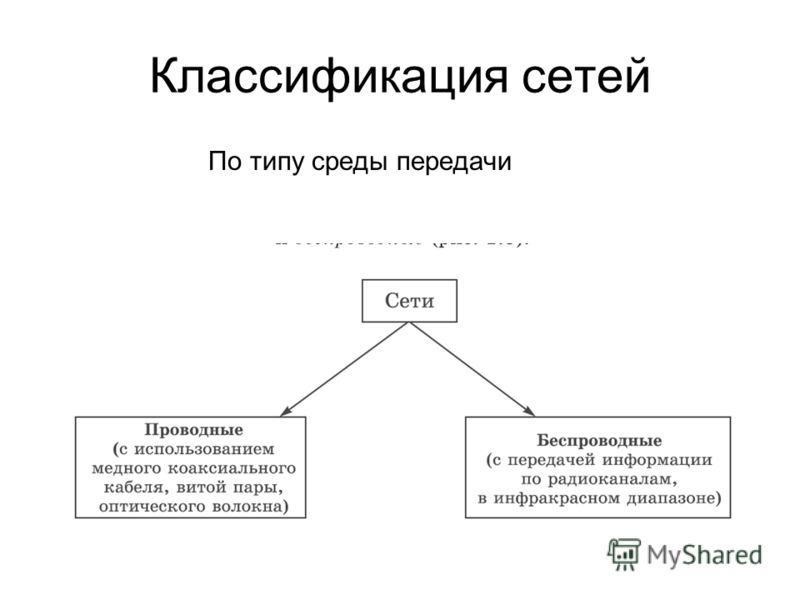
Классификация по среде передачи данных
По типу среды передачи данных сети бывают:
- Проводные (витая пара, коаксиальный кабель, оптоволокно)
- Беспроводные (Wi-Fi, Bluetooth, сотовые сети)
Выбор среды передачи зависит от требований к скорости, дальности связи и помехозащищенности.
Заключение
Существует множество критериев для классификации компьютерных сетей. Основными являются территориальный охват, топология, способ администрирования и масштаб. Понимание различных типов сетей помогает выбрать оптимальную структуру для конкретных задач и условий эксплуатации. При проектировании сетей важно учитывать все факторы и особенности различных классификаций.
Классификация сетей. структура и принципы работы локальных и глобальных сетей. — Энциклопедия современных знаний
Компьютерная сеть (КС) являет собой систему распределенной обработки информации, которая составляет как минимум из двух компьютеров, взаимодействующих между собой с помощью специальных средств связи. Или другими словами сеть являет собой совокупность соединенных друг с другом ПК и других вычислительных устройств, таких как принтеры, факсимильные аппараты и модемы. Сеть дает возможность отдельным сотрудникам организации взаимодействовать друг с другом и обращаться к совместно используемым ресурсам; позволяет им получать доступ к данным, что сохраняется на персональных компьютерах в удаленных офисах, и устанавливать связь с поставщиками.
Для классификации компьютерных сетей используются разные признаки, выбор которых заключается в том, чтобы выделить из существующего многообразия такие, которые позволили бы обеспечить данной классификационной схеме такие обязательные качества:
— возможность классификации всех, как существующих, так и перспективных, КС;
— дифференциацию существенно разных сетей;
— однозначность классификации любой компьютерной сети;
— наглядность, простоту и практическую целесообразность классификационной схемы.
Определенное несоответствие этих требований делает задание выбору рациональной схемы классификации КС достаточно сложной, такой, которая не нашла до этого времени однозначного решения. В основном КС классифицируют за признаками структурной и функциональной организации.
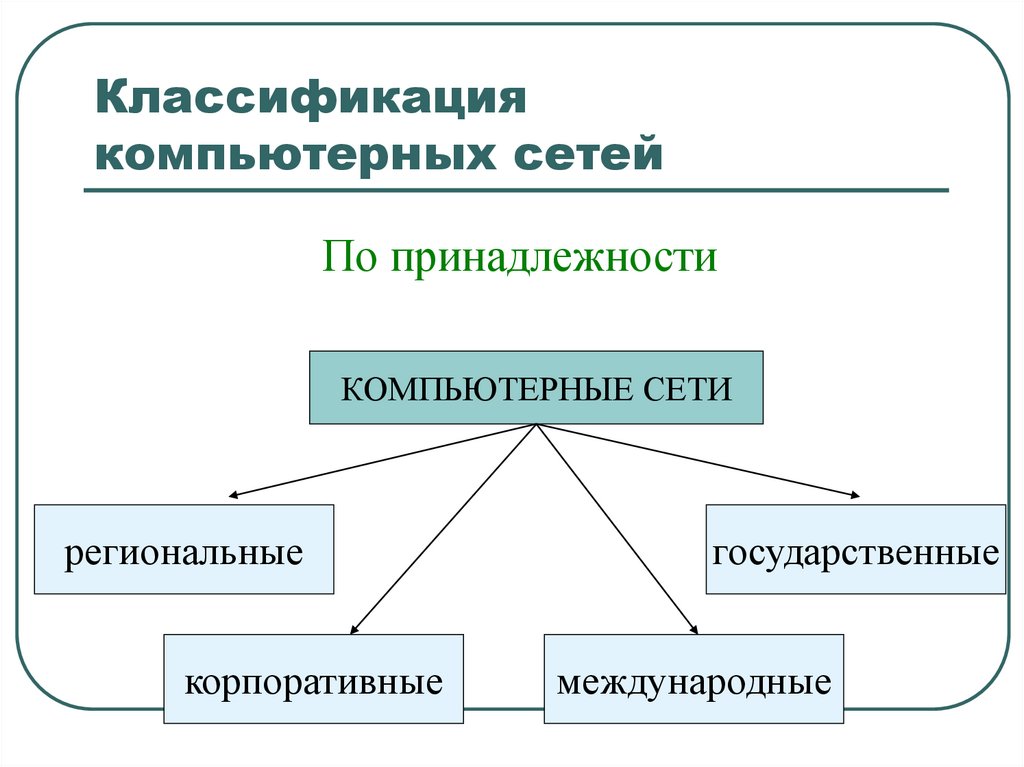
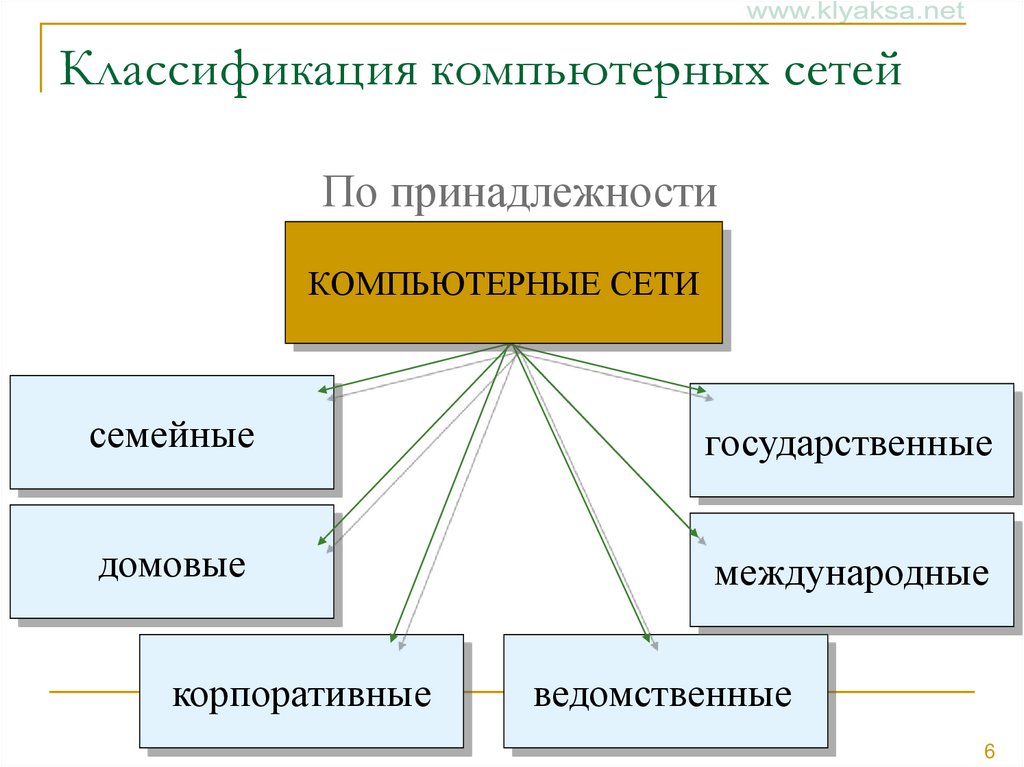
По назначению КС распределяются на:
1. вычислительные;
2. информационные;
3. смешанные (информационно-вычислительные).
Вычислительные сети предназначены главным образом для решения заданий пользователей с обменом данными между их абонентами. Информационные сети ориентированы в основном на предоставление информационных услуг пользователям. Смешанные сети совмещают функции первых двух.
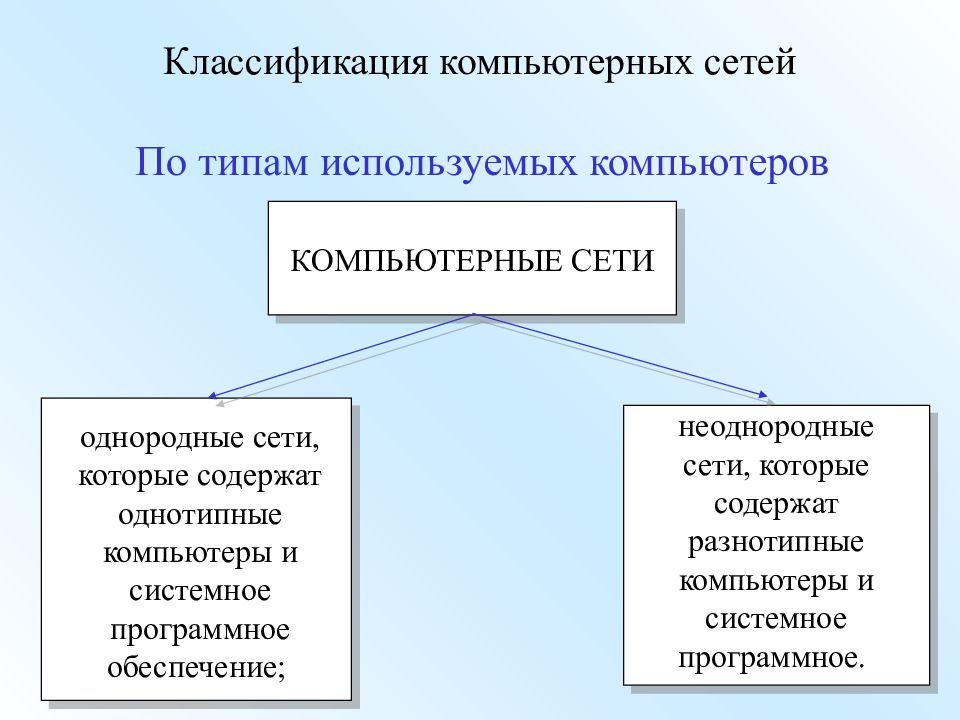
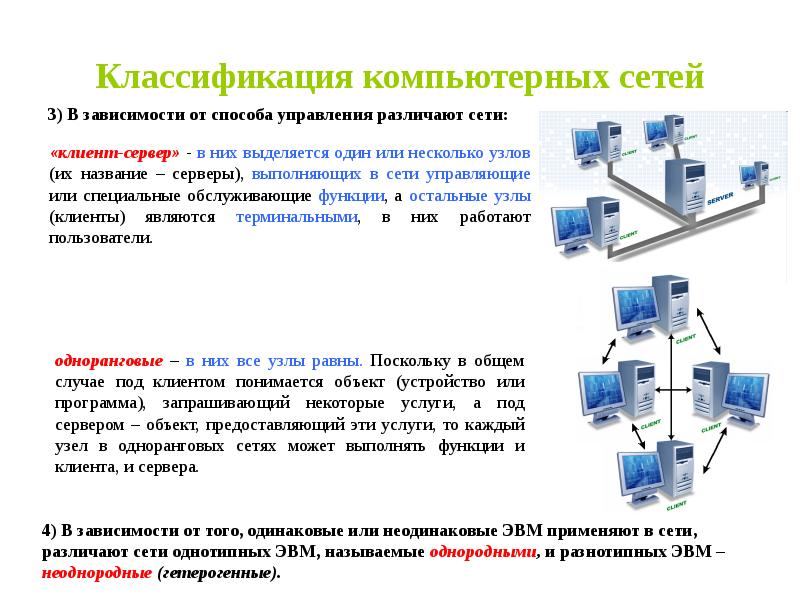
По типа компьютеров, которые входят в состав КС, различают:
1. однородные компьютерные сети, которые состоят из программно общих ЭВМ;
2. неоднородные, в состав которых входят программно-несовместительные компьютеры.
Особенное значение занимает классификация по территориальному признаку, то есть по величине территории, что покрывает сеть.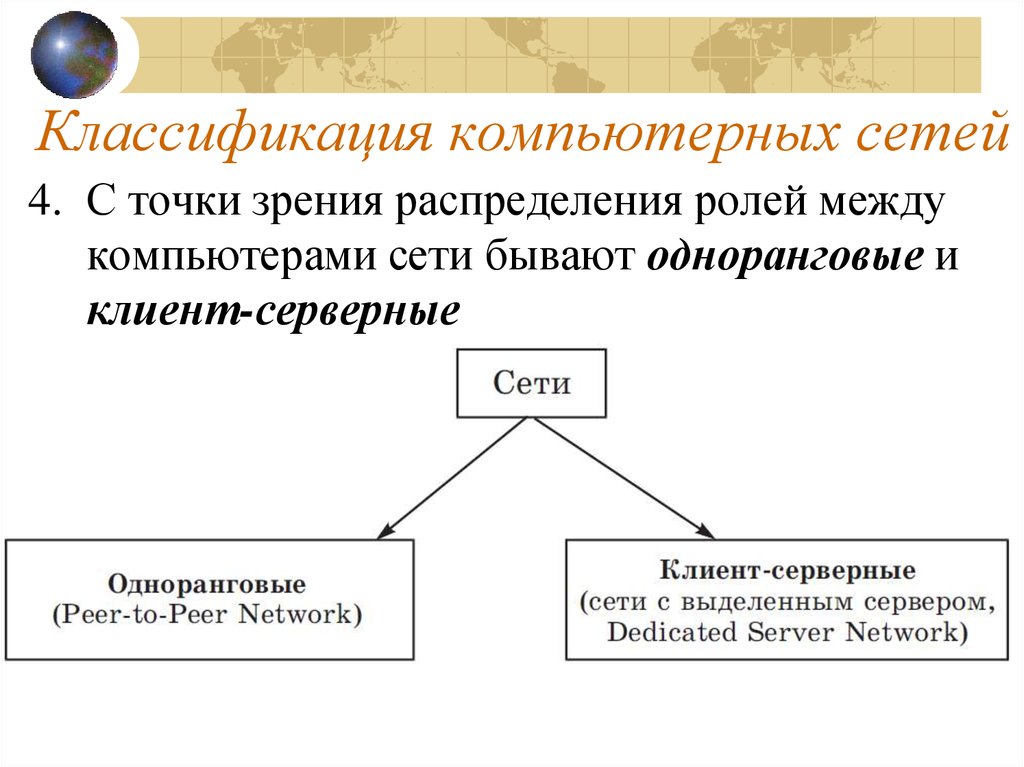 И для этого есть весомые причины, потому что отличия технологий локальных и глобальных сетей очень значительные, невзирая на их постоянное сближение.
И для этого есть весомые причины, потому что отличия технологий локальных и глобальных сетей очень значительные, невзирая на их постоянное сближение.
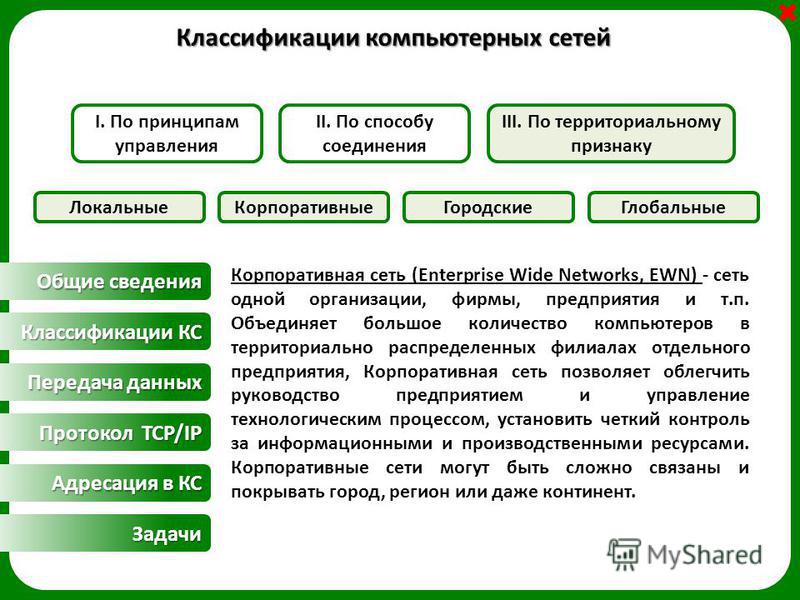
Классифицируя сети по территориальному признаку, различают:
1. локальные (LocalAreaNetworks– LAN) сети;
2. глобальные (WideAreaNetworks– WAN) сети;
3. городские (MetropolitanAreaNetworks– MAN) сети.
LAN– сосредоточены на территории не больше 1–2 км; построенные с использованием дорогих высококачественных линий связи, которые позволяют, применяя простые методы передачи данных, достигать высоких скоростей обмена данными порядка 100 Мбит/с, предоставленные услуги отличаются широкой разнообразностью и обычно предусматривают реализацию в режиме on-line.
WAN– совмещают компьютеры, рассредоточенные на расстоянии сотен и тысяч километров. Часто используются уже существующие не очень качественные линии связи. Больше низкие, чем в локальных сетях, скорости передачи данных (десятки килобит в секунду) ограничивают набор предоставленных услуг передачей файлов, преимущественно не в оперативном, а в фоновом режиме, с использованием электронной почты.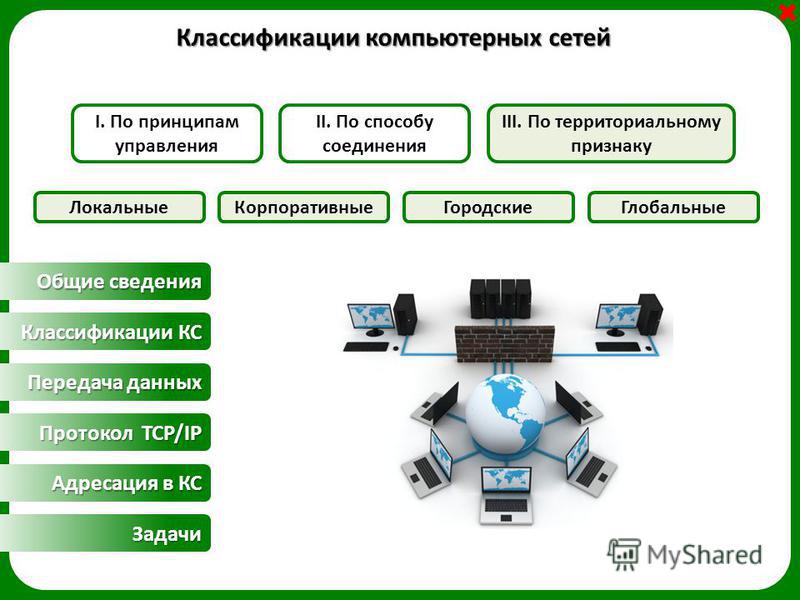 Для стойкой передачи дискретных данных применяются более сложные методы и оборудование, чем в локальных сетях.
Для стойкой передачи дискретных данных применяются более сложные методы и оборудование, чем в локальных сетях.
MAN– занимают промежуточное положение между локальными и глобальными сетями. При достаточно больших расстояниях между узлами (десятки километров) они имеют качественные линии связи и высоких скоростей обмена, иногда даже больше высокими, чем в классических локальных сетях. Как и в случае локальных сетей, при построении MANуже существующие линии связи не используются, а прокладываются заново.
Также дополнительно выделяют:
4. кампусные сети (Campus Area Network – CAN), которые совмещают значительно удаленные друг от друга абонентские системы или локальные сети, но еще не требуют отдаленных коммуникаций через телефонные линии и модемы;
5. широкомасштабные сети (WideAreaNetwork – WAN), которые используют отдаленные мосты и маршрутизаторы с возможно невысокими скоростями передачи данных.
Отличительные признаки локальной сети:
1. высокая скорость передачи, большая пропускная способность;
2. низкий уровень ошибок передачи (или, что то же, высококачественные каналы связи). Допустимая вероятность ошибок передачи данных должна быть порядку 10-7 – 10-8;
низкий уровень ошибок передачи (или, что то же, высококачественные каналы связи). Допустимая вероятность ошибок передачи данных должна быть порядку 10-7 – 10-8;
3. эффективный, быстродействующий механизм управления обменом;
4. ограничено, точно определенное число компьютеров, которые подключаются к сети.
Глобальные сети отличаются от локальных тем, которые рассчитаны на неограниченное число абонентов и используют, как правило, не слишком качественные каналы связи и сравнительно низкую скорость передачи, а механизм управления обменом, у них в принципе не может быть гарантировано скорым. В глобальных сетях намного более важное не качество связи, а сам факт ее существования.
Правда, в настоящий момент уже нельзя провести четкий и однозначный предел между локальными и глобальными сетями. Большинство локальных сетей имеют выход в глобальную сеть, но характер переданной информации, принципы организации обмена, режимы доступа, к ресурсам внутри локальной сети, как правило, сильно отличаются от тех, что принято в глобальной сети. И хотя все компьютеры локальной сети в данном случае включены также и в глобальную сеть, специфику локальной сети это не отменяет. Возможность выхода в глобальную сеть остается всего лишь одним из ресурсов, поделенные пользователями локальной сети.
И хотя все компьютеры локальной сети в данном случае включены также и в глобальную сеть, специфику локальной сети это не отменяет. Возможность выхода в глобальную сеть остается всего лишь одним из ресурсов, поделенные пользователями локальной сети.
Следующей не менее распространенной классификацией есть классификация КС по типа топологии.
Локальные и глобальные компьютерные сети | Информатика 9 класс #22 | Инфоурок
Похожие статьи.
-
Структура глобальной сети
-
Структура локальной сети
-
Классификация компьютерных сетей
-
Классификация сетей: по области действия, по масштабу производственного подразделения, по способам администрирования, по топологии.
Классификация сетей. Выбор сети
» Информационные системы
» Информационные сети
»
Классификация сетей.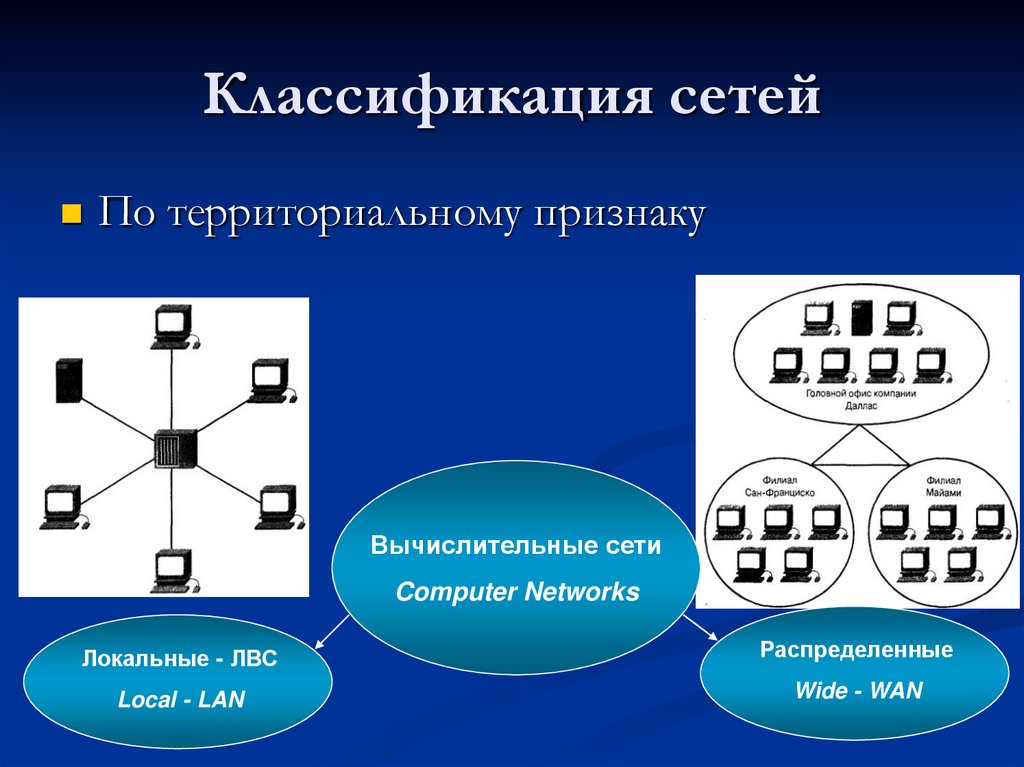 Выбор сети
Выбор сети
Вычислительные сети – совокупность ПК, соединенных линиями связи. Линии связи образовываются кабелями, сетевыми адаптерами и др. коммуникационными уст-вами.
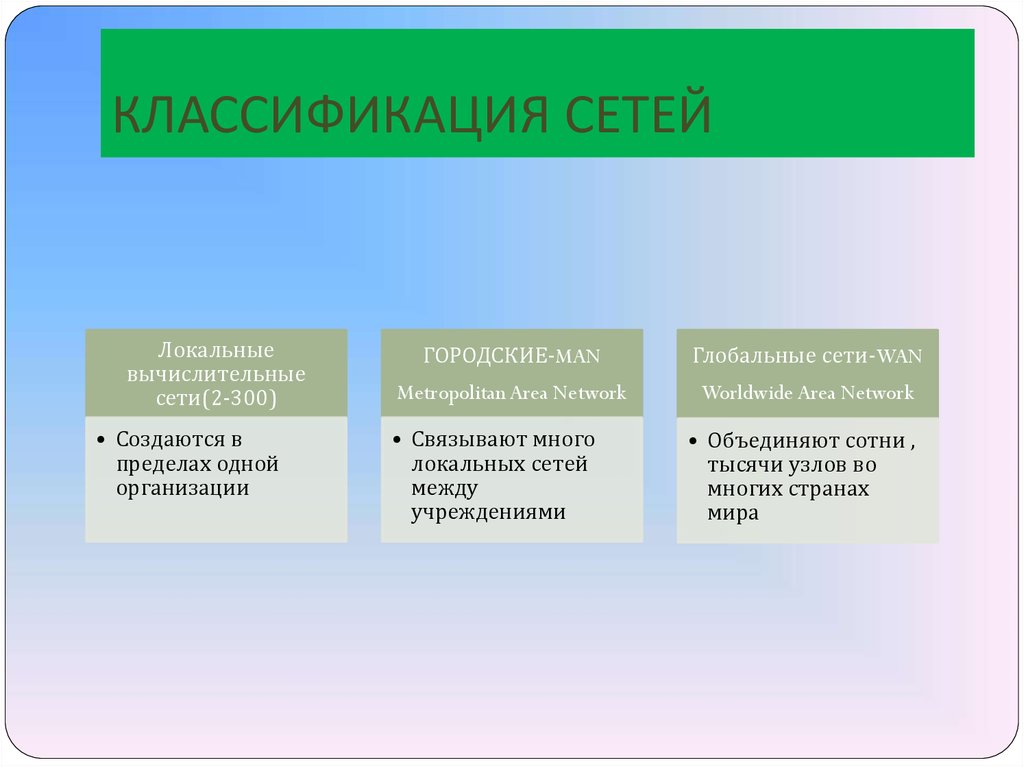
Сети делятся по территориальному признаку:
· глобальные (WAN) (произошли от телефонных)
· локальные (LAN) 100Мбит/с-1Гбит/с, 1-2 км
· городские (MAN) 80 км
LAN– сосредоточены на территории не больше 1–2 км; с использованием дорогих высококачественных ЛС, которые позволяют достигать высоких скоростей обмена данными порядка 100 Мбит/с, предоставленные услуги отличаются широкой разнообразностью и обычно предусматривают реализацию в режиме on-line.
WAN– совмещают компьютеры, рассредоточенные на расстоянии сотен и тысяч километров. Часто используются уже существующие не очень качественные линии связи. Невысокие скорости передачи данных (десятки кбит/с) ограничивают набор предоставленных услуг передачей файлов, преимущественно в фоновом режиме, с использованием эл.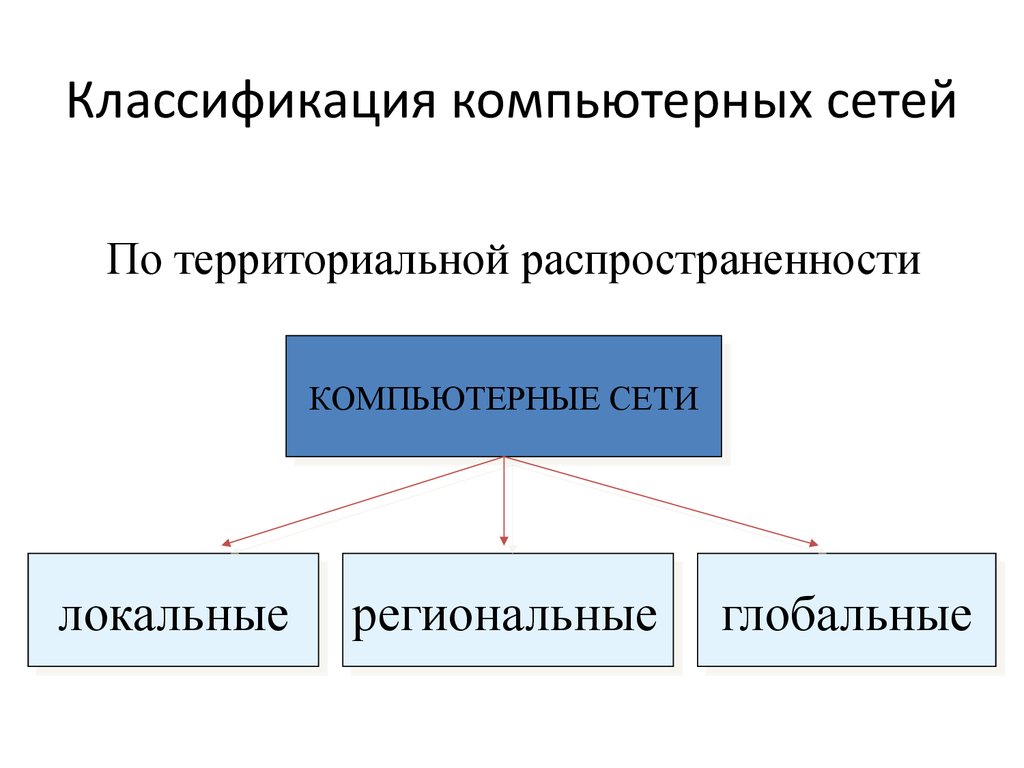 почты. Для стойкой передачи дискретных данных применяются более сложные методы и оборудование, чем в локальных сетях.
почты. Для стойкой передачи дискретных данных применяются более сложные методы и оборудование, чем в локальных сетях.
MAN–промежуточное положение между LAN и WAN. При достаточно больших расстояниях между узлами (десятки км) они имеют качественные линии связи и высоких скоростей обмена, иногда даже больше высокими, чем в классических локальных сетях. Как и в случае локальных сетей, при построении MAN уже существующие линии связи не используются, а прокладываются заново.
Также дополнительно выделяют:
4. кампусные сети (Campus Area Network – CAN), которые совмещают значительно удаленные друг от друга абонентские системы или локальные сети, но еще не требуют отдаленных коммуникаций через телефонные линии и модемы;
5. широкомасштабные сети (WideAreaNetwork – WAN), которые используют отдаленные мосты и маршрутизаторы с возможно невысокими скоростями передачи данных.
Классификация сетей по приоритету:
1. Одноранговые сети, в которых все компьютеры и, соответственно, абоненты равноправны по отношению друг к другу (применяется, например, для использования принтера, сканера и др.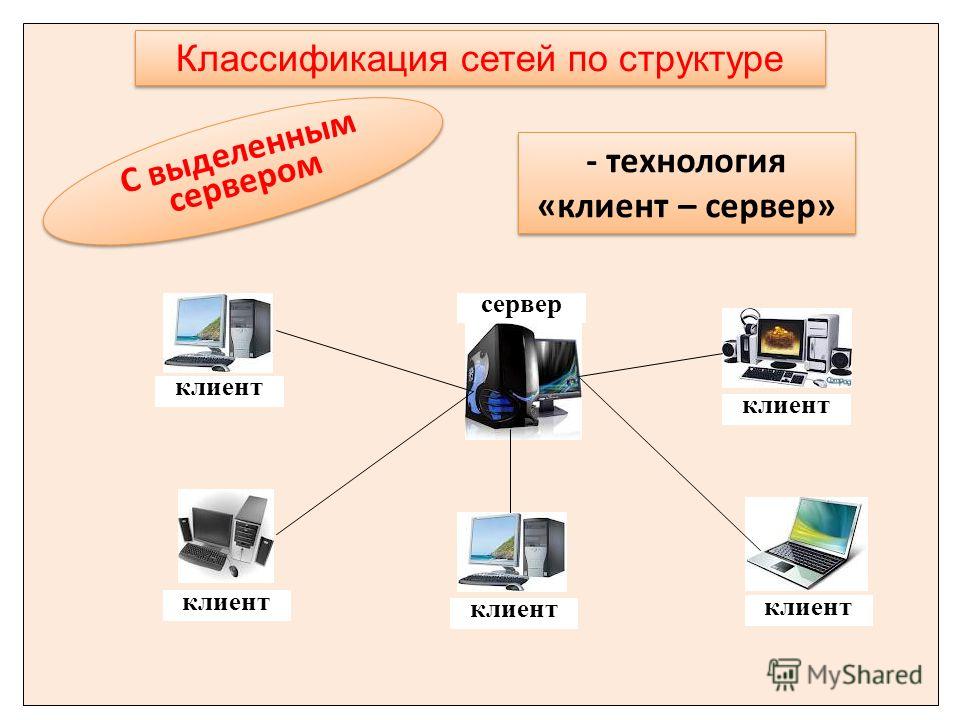
2. Сети «клиент-сервер» имеют более крупный масштаб или это ЛВС, в которой повышены требования к доступу и защите информации. В таких сетях один или несколько компьютеров выделяются для обслуживания потребностей абонентов и называются серверами. Они должны обладать высокой производительностью, большими объёмами внутренней и внешней памяти, возможностью постоянной работы, средствами защиты электропитания. Остальные компьютеры сети называются клиентами или рабочими станциями.
Классификация сетей по способу соединения (топологии):
- линейная(шина) сеть, в которой все компьютеры подключены к общему каналу связи (кабелю), содержит только два конечных узла и имеет только один путь между любыми двумя узлами;
- сеть «кольцо», в которой к каждому узлу подсоединены только две ветви;
- сеть «звезда», в которой имеется только один промежуточный узел;
- сеть «дерево», построенная по иерархической модели модели.

Тип соединения | Плюсы | Минусы |
Шина | -экономия кабеля -расширяемость -простота эксплуатации | -уменьшение пропускной способности при возрастании объема траффика -повреждение центрального кабеля повлечет остановку большого числа пользователей |
Кольцо | -количество подключенных узлов не оказывает влияния на производительность всей системы — все компьютеры имеют равноправный доступ | -повреждение одного из узлов может повлиять на работу всей сети |
|
Звезда | -централизованный контроль за ЛВС — быстрая расширяемость | -при выходе из строя концентратора прекращается работа всей сети |
Кроме основных видов топологий достаточно часто встречаются гибридные и комбинированные топологии, позволяющие полностью покрыть все требования по охвату локальной сети.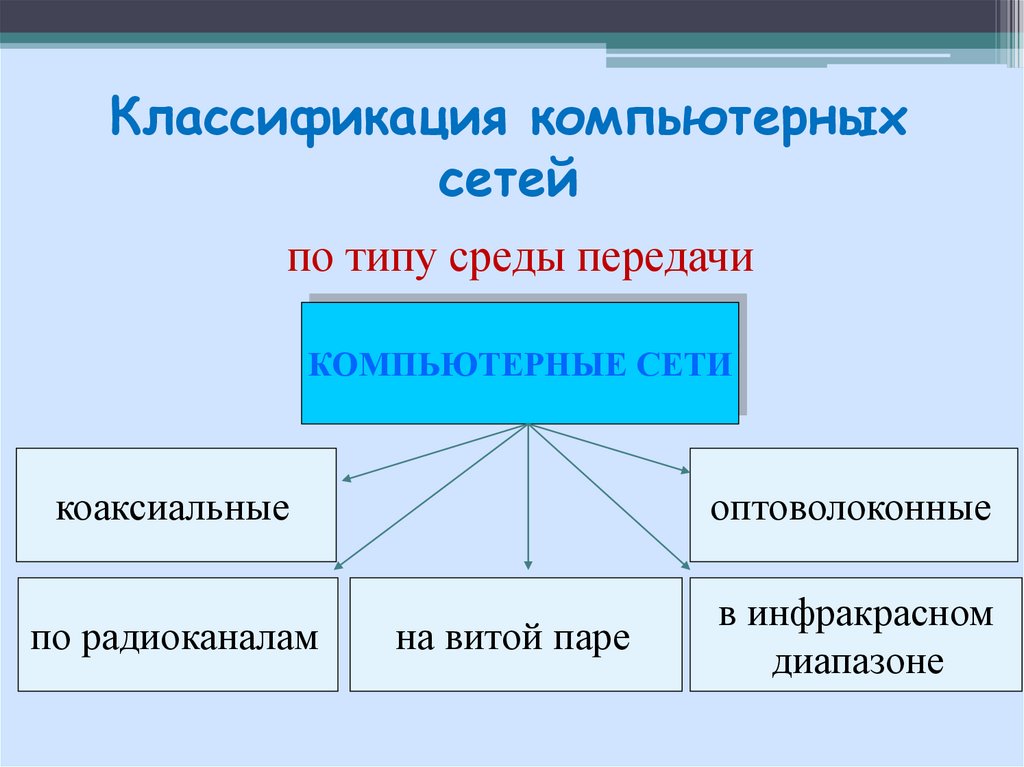
Друзья! Приглашаем вас к обсуждению. Если у вас есть своё мнение, напишите нам в комментарии.
Классификация нейронных сетей | решатель
Введение
Искусственные нейронные сети представляют собой относительно грубые электронные сети нейронов, основанные на нейронной структуре мозга. Они обрабатывают записи по одной и учатся, сравнивая свою классификацию записи (то есть в значительной степени произвольную) с известной фактической классификацией записи. Ошибки начальной классификации первой записи возвращаются в сеть и используются для изменения алгоритма сети для дальнейших итераций.
Нейрон в искусственной нейронной сети — это
1. Набор входных значений (xi) и соответствующих весов (wi).
2. Функция (g), которая суммирует веса и отображает результаты на выходе (y).
Нейроны организованы в слои: входной, скрытый и выходной. Входной слой состоит не из полных нейронов, а просто из значений записи, которые являются входными данными для следующего слоя нейронов.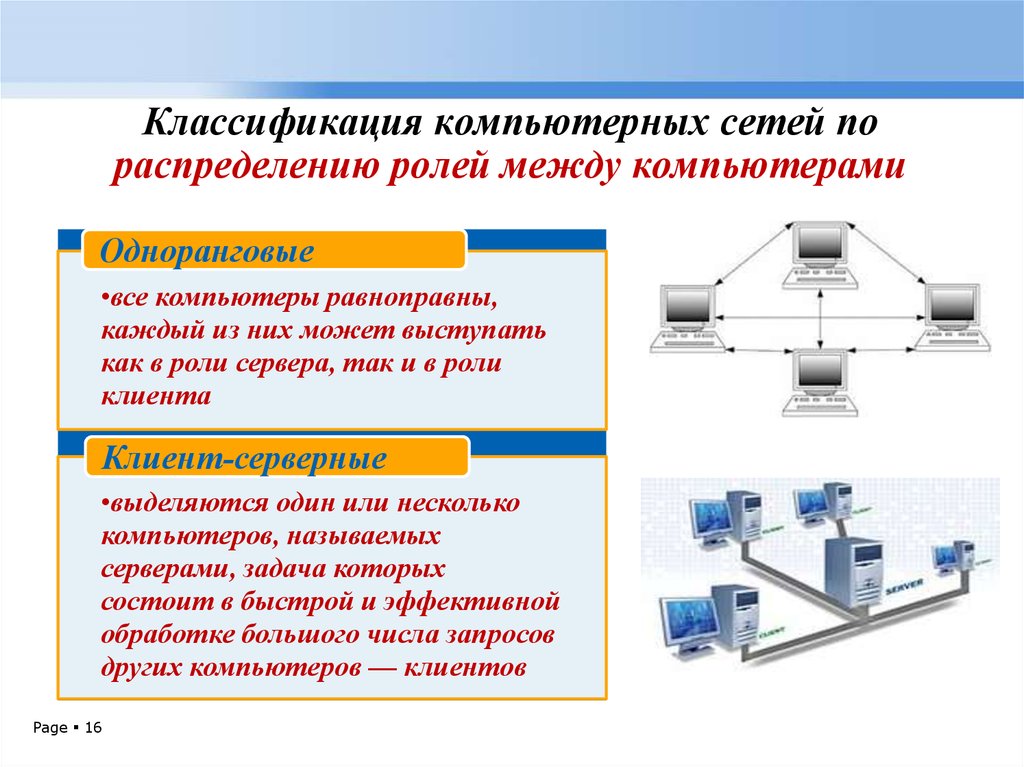 Следующий слой — это скрытый слой. В одной нейронной сети может существовать несколько скрытых слоев. Последний слой — это выходной слой, где для каждого класса имеется по одному узлу. Один проход вперед по сети приводит к присвоению значения каждому выходному узлу, а запись присваивается узлу класса с наибольшим значением.
Следующий слой — это скрытый слой. В одной нейронной сети может существовать несколько скрытых слоев. Последний слой — это выходной слой, где для каждого класса имеется по одному узлу. Один проход вперед по сети приводит к присвоению значения каждому выходному узлу, а запись присваивается узлу класса с наибольшим значением.
Обучение искусственной нейронной сети
На этапе обучения правильный класс для каждой записи известен (обучение с учителем), и выходным узлам могут быть присвоены правильные значения — 1 для узла, соответствующего правильный класс и 0 для остальных. (На практике лучшие результаты были получены при использовании значений 0,9 и 0,1 соответственно.) Таким образом, можно сравнить расчетные значения сети для выходных узлов с этими правильными значениями и вычислить член ошибки для каждого узла (правило дельты ). Эти члены ошибки затем используются для корректировки весов в скрытых слоях, чтобы, как мы надеемся, во время следующей итерации выходные значения были ближе к правильным значениям.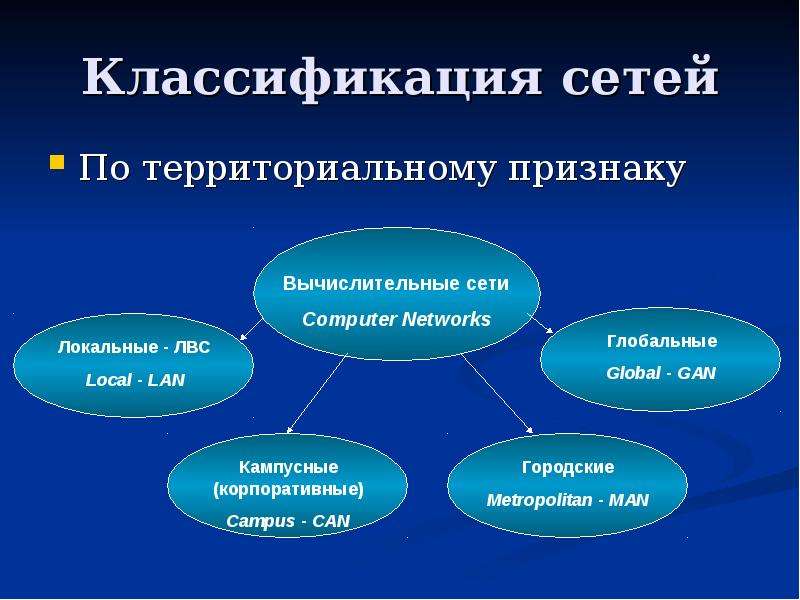
Итеративный процесс обучения
Ключевой особенностью нейронных сетей является итеративный процесс обучения, в котором записи (строки) представляются в сеть по одной за раз, а веса, связанные с входными значениями, корректируются каждый раз. После того, как все случаи представлены, процесс часто повторяется. На этом этапе обучения сеть обучается, регулируя веса, чтобы предсказать правильную метку класса входных выборок. Преимущества нейронных сетей включают их высокую устойчивость к зашумленным данным, а также их способность классифицировать шаблоны, на которых они не были обучены. Наиболее популярным алгоритмом нейронной сети является алгоритм обратного распространения, предложенный в 1980-е годы.
После того, как сеть структурирована для конкретного приложения, она готова к обучению. Чтобы начать этот процесс, начальные веса (описанные в следующем разделе) выбираются случайным образом. Затем начинается обучение (обучение).
Сеть обрабатывает записи в обучающем наборе по одной за раз, используя веса и функции в скрытых слоях, а затем сравнивает полученные выходные данные с желаемыми выходными данными.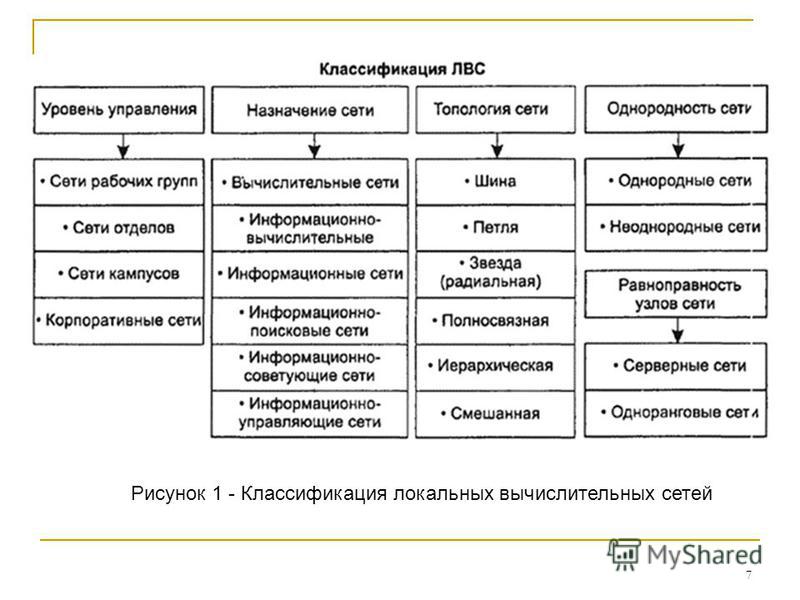 Затем ошибки распространяются обратно по системе, заставляя систему корректировать веса для применения к следующей записи. Этот процесс повторяется неоднократно по мере изменения весов. Во время обучения сети один и тот же набор данных обрабатывается много раз, так как веса соединений постоянно уточняются.
Затем ошибки распространяются обратно по системе, заставляя систему корректировать веса для применения к следующей записи. Этот процесс повторяется неоднократно по мере изменения весов. Во время обучения сети один и тот же набор данных обрабатывается много раз, так как веса соединений постоянно уточняются.
Обратите внимание, что некоторые сети никогда не обучаются. Это может быть связано с тем, что входные данные не содержат конкретной информации, из которой получают желаемый результат. Сети также не будут сходиться, если для полного обучения недостаточно данных. В идеале должно быть достаточно данных для создания проверочного набора.
Прямая связь, обратное распространение
Архитектура прямого распространения, обратного распространения была разработана в начале 1970-х несколькими независимыми источниками (Вербор, Паркер, Румельхарт, Хинтон и Уильямс). Эта независимая совместная разработка стала результатом множества статей и выступлений на различных конференциях, которые стимулировали всю отрасль. В настоящее время эта синергетически разработанная архитектура обратного распространения является самой популярной моделью для сложных многоуровневых сетей. Его наибольшая сила заключается в нелинейных решениях плохо определенных проблем.
В настоящее время эта синергетически разработанная архитектура обратного распространения является самой популярной моделью для сложных многоуровневых сетей. Его наибольшая сила заключается в нелинейных решениях плохо определенных проблем.
Типичная сеть обратного распространения имеет входной слой, выходной слой и по крайней мере один скрытый слой. Теоретического ограничения на количество скрытых слоев нет, но обычно их всего один или два. Некоторые исследования показали, что общее количество слоев, необходимых для решения задач любой сложности, равно пяти (один входной слой, три скрытых слоя и выходной слой). Каждый слой полностью связан с последующим слоем.
В процессе обучения обычно используется некий вариант дельта-правила, который начинается с расчетной разницы между фактическими выходными данными и желаемыми выходными данными. При использовании этой ошибки веса соединения увеличиваются пропорционально времени ошибки, которое является коэффициентом масштабирования для глобальной точности.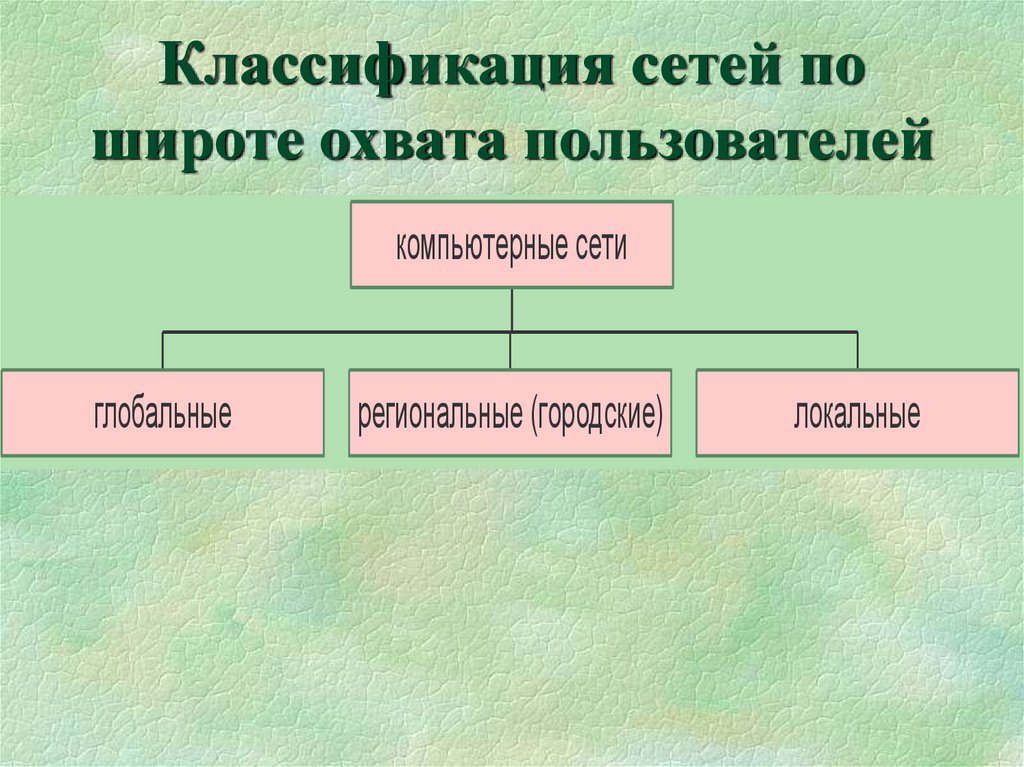 Это означает, что входы, выход и желаемый результат должны присутствовать в одном и том же элементе обработки. Наиболее сложной частью этого алгоритма является определение того, какие входные данные в наибольшей степени повлияли на неверный результат, и как следует изменить входные данные, чтобы исправить ошибку. (Неактивный узел не внесет вклад в ошибку, и ему не нужно будет изменять свои веса.) Чтобы решить эту проблему, обучающие входные данные применяются к входному слою сети, а желаемые выходные данные сравниваются на выходном уровне. В процессе обучения по сети выполняется прямой проход, и выходные данные каждого элемента вычисляются по слоям. Разница между выходом последнего слоя и желаемым выходом распространяется обратно на предыдущий слой (слои), обычно модифицируемый производной передаточной функции. Веса соединений обычно регулируются с помощью дельта-правила. Этот процесс продолжается для предыдущего слоя (слоев), пока не будет достигнут входной слой.
Это означает, что входы, выход и желаемый результат должны присутствовать в одном и том же элементе обработки. Наиболее сложной частью этого алгоритма является определение того, какие входные данные в наибольшей степени повлияли на неверный результат, и как следует изменить входные данные, чтобы исправить ошибку. (Неактивный узел не внесет вклад в ошибку, и ему не нужно будет изменять свои веса.) Чтобы решить эту проблему, обучающие входные данные применяются к входному слою сети, а желаемые выходные данные сравниваются на выходном уровне. В процессе обучения по сети выполняется прямой проход, и выходные данные каждого элемента вычисляются по слоям. Разница между выходом последнего слоя и желаемым выходом распространяется обратно на предыдущий слой (слои), обычно модифицируемый производной передаточной функции. Веса соединений обычно регулируются с помощью дельта-правила. Этот процесс продолжается для предыдущего слоя (слоев), пока не будет достигнут входной слой.
Структурирование сети
Важными решениями являются количество уровней и количество элементов обработки на уровне.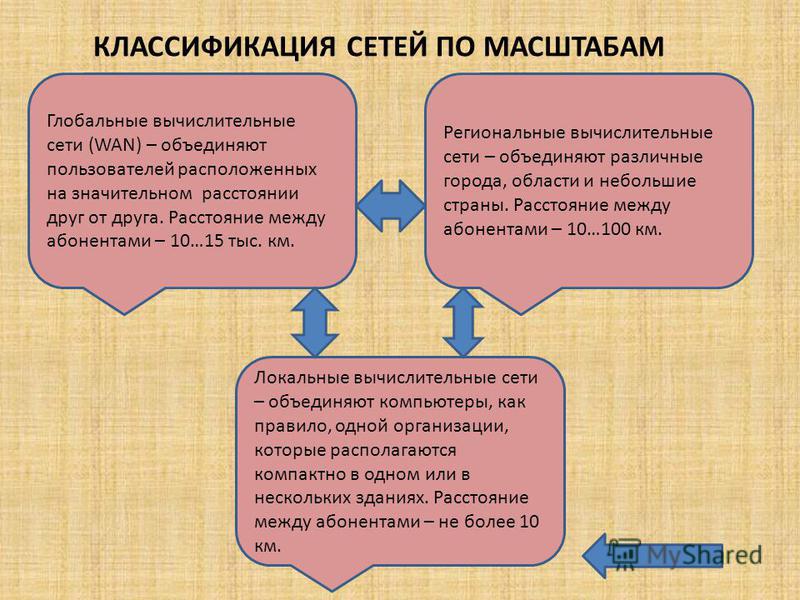 Для топологии с прямой связью и обратным распространением эти параметры также являются самыми эфирными — они являются искусством сетевого проектировщика. Не существует поддающегося количественной оценке ответа на вопрос о расположении сети для любого конкретного приложения. Есть только общие правила, выработанные с течением времени и соблюдаемые большинством исследователей и инженеров, применяющих эту архитектуру к своим задачам.
Для топологии с прямой связью и обратным распространением эти параметры также являются самыми эфирными — они являются искусством сетевого проектировщика. Не существует поддающегося количественной оценке ответа на вопрос о расположении сети для любого конкретного приложения. Есть только общие правила, выработанные с течением времени и соблюдаемые большинством исследователей и инженеров, применяющих эту архитектуру к своим задачам.
Правило первое: По мере увеличения сложности связи между входными данными и желаемым выходом количество элементов обработки в скрытом слое также должно увеличиваться.
Правило второе: Если моделируемый процесс можно разделить на несколько этапов, то могут потребоваться дополнительные скрытые слои. Если процесс не разделен на этапы, то дополнительные слои могут просто позволить запоминание обучающей выборки, а не истинное общее решение.
Правило третье: Количество доступных обучающих наборов устанавливает верхнюю границу количества элементов обработки в скрытых слоях. Чтобы вычислить эту верхнюю границу, используйте количество случаев в обучающем наборе и разделите это число на сумму количества узлов во входном и выходном слоях в сети. Затем снова разделите этот результат на коэффициент масштабирования от пяти до десяти. Большие коэффициенты масштабирования используются для относительно менее зашумленных данных. Если используется слишком много искусственных нейронов, тренировочный набор будет запоминаться, а не обобщаться, и сеть будет бесполезна на новых наборах данных.
Чтобы вычислить эту верхнюю границу, используйте количество случаев в обучающем наборе и разделите это число на сумму количества узлов во входном и выходном слоях в сети. Затем снова разделите этот результат на коэффициент масштабирования от пяти до десяти. Большие коэффициенты масштабирования используются для относительно менее зашумленных данных. Если используется слишком много искусственных нейронов, тренировочный набор будет запоминаться, а не обобщаться, и сеть будет бесполезна на новых наборах данных.
Методы ансамбля
XLMiner V2015 предлагает два мощных метода ансамбля для использования с нейронными сетями: пакетирование (агрегация начальной загрузки) и повышение. Алгоритм нейронной сети сам по себе может использоваться для поиска одной модели, которая приводит к хорошей классификации новых данных. Мы можем просмотреть статистику и матрицы путаницы текущего классификатора, чтобы увидеть, хорошо ли наша модель соответствует данным, но как мы узнаем, есть ли лучший классификатор, ожидающий своего поиска? Ответ заключается в том, что мы не знаем, существует ли лучший классификатор. Однако ансамблевые методы позволяют нам комбинировать несколько моделей классификации слабых нейронных сетей, которые вместе образуют новую, более точную модель сильной классификации. Эти методы работают, создавая несколько разнообразных моделей классификации, беря разные образцы исходного набора данных, а затем объединяя их выходные данные. (Выходные данные могут быть объединены несколькими методами, например, большинством голосов для классификации и усреднения для регрессии.) Эта комбинация моделей эффективно снижает дисперсию в сильной модели. Два разных типа ансамблевых методов, предлагаемых в XLMiner (бэггинг и бустинг), различаются по трем пунктам: 1) выбор обучающих данных для каждого классификатора или слабой модели; 2) как генерируются слабые модели; и 3) как результаты объединяются. Во всех трех методах каждая слабая модель обучается на всем тренировочном наборе, чтобы освоить какую-то часть набора данных.
Однако ансамблевые методы позволяют нам комбинировать несколько моделей классификации слабых нейронных сетей, которые вместе образуют новую, более точную модель сильной классификации. Эти методы работают, создавая несколько разнообразных моделей классификации, беря разные образцы исходного набора данных, а затем объединяя их выходные данные. (Выходные данные могут быть объединены несколькими методами, например, большинством голосов для классификации и усреднения для регрессии.) Эта комбинация моделей эффективно снижает дисперсию в сильной модели. Два разных типа ансамблевых методов, предлагаемых в XLMiner (бэггинг и бустинг), различаются по трем пунктам: 1) выбор обучающих данных для каждого классификатора или слабой модели; 2) как генерируются слабые модели; и 3) как результаты объединяются. Во всех трех методах каждая слабая модель обучается на всем тренировочном наборе, чтобы освоить какую-то часть набора данных.
Бэггинг (агрегация начальной загрузки) был одним из первых когда-либо написанных ансамблевых алгоритмов.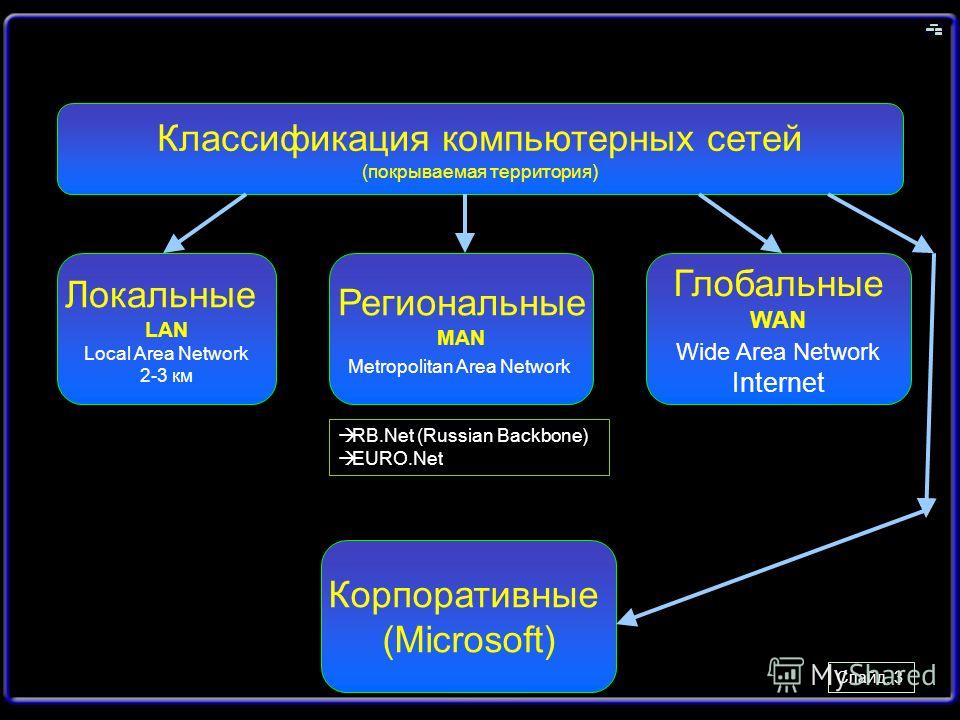 Это простой алгоритм, но очень эффективный. Бэггинг генерирует несколько обучающих наборов, используя случайную выборку с заменой (самозагрузочная выборка), применяет алгоритм классификации к каждому набору данных, затем получает большинство голосов среди моделей, чтобы определить классификацию новых данных. Самым большим преимуществом бэггинга является относительная простота распараллеливания алгоритма, что делает его лучшим выбором для очень больших наборов данных.
Это простой алгоритм, но очень эффективный. Бэггинг генерирует несколько обучающих наборов, используя случайную выборку с заменой (самозагрузочная выборка), применяет алгоритм классификации к каждому набору данных, затем получает большинство голосов среди моделей, чтобы определить классификацию новых данных. Самым большим преимуществом бэггинга является относительная простота распараллеливания алгоритма, что делает его лучшим выбором для очень больших наборов данных.
Ускорение строит сильную модель путем последовательного обучения моделей, чтобы сосредоточиться на неправильно классифицированных записях в предыдущих моделях. После завершения все классификаторы объединяются взвешенным большинством голосов. XLMiner предлагает три различных варианта повышения, реализованных с помощью алгоритма AdaBoost (одного из самых популярных алгоритмов ансамбля, используемых сегодня): M1 (Фрейнд), M1 (Брейман) и SAMME (поэтапное аддитивное моделирование с использованием мультиклассовой экспоненты).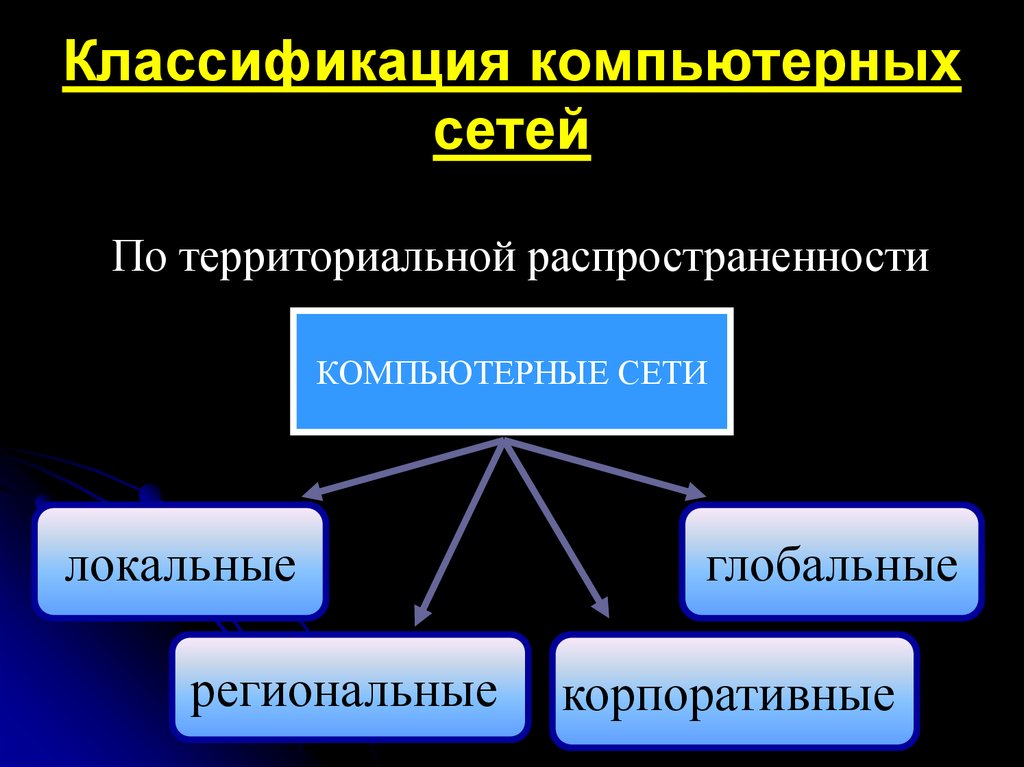
Сначала Adaboost.M1 присваивает вес (wb(i)) каждой записи или наблюдению. Первоначально этот вес установлен равным 1/n и обновляется на каждой итерации алгоритма. Исходная модель классификации создается с использованием этого первого обучающего набора (Tb), и ошибка рассчитывается как:
где функция I() возвращает 1, если истинно, и 0, если нет.
Ошибка модели классификации в b-й итерации используется для вычисления константы ?b. Эта константа используется для обновления веса (wb(i). В AdaBoost.M1 (Freund) константа рассчитывается как:
αb= ln((1-eb)/eb)
), константа рассчитывается как:
αb= 1/2ln((1-eb)/eb)
В SAMME константа рассчитывается как:
αb= 1/2ln((1-eb)/eb + ln(k-1), где k — количество классов
где количество категорий равно 2, SAMME ведет себя так же, как AdaBoost Breiman.
В любой из трех реализаций (Фрейнд, Брейман или SAMME) новый вес для (b + 1)-й итерации будет равен
После этого все веса корректируются до суммы 1. Как В результате веса, присвоенные наблюдениям, которые были классифицированы неправильно, увеличиваются, а веса, присвоенные наблюдениям, которые классифицируются правильно, уменьшаются. Эта корректировка заставляет следующую модель классификации уделять больше внимания записям, которые были неправильно классифицированы. (Константа ? также используется в окончательных расчетах, что дает большее влияние модели классификации с наименьшей ошибкой.) Этот процесс повторяется до тех пор, пока b = количество слабых учащихся. Затем алгоритм вычисляет взвешенную сумму голосов для каждого класса и назначает победившую классификацию записи. Повышение обычно дает лучшие модели, чем бэггинг; однако у него есть недостаток, поскольку его нельзя распараллелить. В результате, если количество слабых учеников велико, буст не подходит.
Как В результате веса, присвоенные наблюдениям, которые были классифицированы неправильно, увеличиваются, а веса, присвоенные наблюдениям, которые классифицируются правильно, уменьшаются. Эта корректировка заставляет следующую модель классификации уделять больше внимания записям, которые были неправильно классифицированы. (Константа ? также используется в окончательных расчетах, что дает большее влияние модели классификации с наименьшей ошибкой.) Этот процесс повторяется до тех пор, пока b = количество слабых учащихся. Затем алгоритм вычисляет взвешенную сумму голосов для каждого класса и назначает победившую классификацию записи. Повышение обычно дает лучшие модели, чем бэггинг; однако у него есть недостаток, поскольку его нельзя распараллелить. В результате, если количество слабых учеников велико, буст не подходит.
Методы ансамбля нейронных сетей являются очень мощными методами и обычно обеспечивают лучшую производительность, чем одна нейронная сеть. XLMiner V2015 предоставляет пользователям более точные модели классификации, и его следует рассматривать в рамках одной сети.
Фотонная глубокая нейронная сеть на кристалле для классификации изображений
- Артикул
- Опубликовано:
- Фаршид Аштиани ORCID: orcid.org/0000-0002-8418-9626 1 ,
- Александр Дж. Гирс ORCID: orcid.org/0000-0003-3096-3927 1 и
- Фируз Афлатуни ORCID: orcid.org/0000-0001-9314-2486 1
Природа том 606 , страницы 501–506 (2022)Цитировать эту статью
-
17 тыс.
 обращений
обращений -
35 цитирований
-
412 Альтметрический
-
Сведения о показателях
Предметы
- Электротехника и электроника
- Оптика и фотоника
- Кремниевая фотоника
Abstract
Глубокие нейронные сети с приложениями от компьютерного зрения до медицинской диагностики 1,2,3,4,5 обычно реализуются с использованием процессоров с тактовой частотой 6,7,8,9,10,11,12,13 ,14 , в котором скорость вычислений в основном ограничена тактовой частотой и временем доступа к памяти. В оптической области, несмотря на успехи в фотонных вычислениях 15,16,17 , отсутствие масштабируемой встроенной оптической нелинейности и потеря фотонных устройств ограничивают масштабируемость оптических глубоких сетей. Здесь мы сообщаем о интегрированной сквозной фотонной глубокой нейронной сети (PDNN), которая выполняет субнаносекундную классификацию изображений посредством прямой обработки оптических волн, падающих на массив пикселей на кристалле, когда они распространяются через слои нейронов. В каждом нейроне линейные вычисления выполняются оптически, а нелинейная функция активации реализуется оптоэлектронно, что обеспечивает время классификации менее 570 пс, что сравнимо с одним тактовым циклом современных цифровых платформ. Равномерно распределенный источник света обеспечивает одинаковый диапазон выходного оптического сигнала для каждого нейрона, что обеспечивает возможность масштабирования до крупномасштабных PDNN. Двухклассная и четырехклассная классификация рукописных букв с точностью выше 93,8% и 89,8% соответственно. Прямая бестактовая обработка оптических данных исключает аналого-цифровое преобразование и потребность в большом модуле памяти, что позволяет использовать более быстрые и энергоэффективные нейронные сети для систем глубокого обучения следующего поколения.
Здесь мы сообщаем о интегрированной сквозной фотонной глубокой нейронной сети (PDNN), которая выполняет субнаносекундную классификацию изображений посредством прямой обработки оптических волн, падающих на массив пикселей на кристалле, когда они распространяются через слои нейронов. В каждом нейроне линейные вычисления выполняются оптически, а нелинейная функция активации реализуется оптоэлектронно, что обеспечивает время классификации менее 570 пс, что сравнимо с одним тактовым циклом современных цифровых платформ. Равномерно распределенный источник света обеспечивает одинаковый диапазон выходного оптического сигнала для каждого нейрона, что обеспечивает возможность масштабирования до крупномасштабных PDNN. Двухклассная и четырехклассная классификация рукописных букв с точностью выше 93,8% и 89,8% соответственно. Прямая бестактовая обработка оптических данных исключает аналого-цифровое преобразование и потребность в большом модуле памяти, что позволяет использовать более быстрые и энергоэффективные нейронные сети для систем глубокого обучения следующего поколения.
Это предварительный просмотр содержимого подписки, доступ через ваше учреждение
Соответствующие статьи
Статьи открытого доступа со ссылками на эту статью.
-
Интегрированный фотонный процессор на базе Microcomb
- Боуэн Бай
- , Ципэн Ян
- … Синцзюнь Ван
Связь с природой Открытый доступ 05 января 2023 г.
-
Обработка тензорных потоков высокого порядка с использованием интегральных фотонных схем
- Шаофу Сюй
- , Цзин Ван
- … Вэйвэнь Цзоу
Связь с природой Открытый доступ 28 декабря 2022 г.
-
Высокоразмерная оптическая нейронная сеть на основе чипа
- Синью Ван
- , Пэн Се
- … Синцай Чжан
Нано-микробуквы Открытый доступ 14 ноября 2022 г.
Варианты доступа
Подписаться на журнал
Получить полный доступ к журналу на 1 год
199,00 €
всего 3,90 € за выпуск
Подписаться
Расчет налога будет завершен во время оформления заказа.
Купить статью
Получите ограниченный по времени или полный доступ к статье на ReadCube.
32,00 $
Купить
Все цены указаны без учета стоимости.
Рис. 1. Обычные и фотонно-электронные глубокие нейронные сети. Рис. 2: Реализация фотонно-электронного нейрона. Рис. 3: Реализованный чип фотонного классификатора. Рис. 4: Демонстрация классификации изображений.Доступность данных
Доступ к данным, поддерживающим графики на рис. 4, можно получить по адресу https://doi.org/10.5061/dryad.q2bvq83mw.
Наличие кода
Коды, которые используются в этой статье, можно получить у соответствующего автора по обоснованному запросу.
Каталожные номера
-
Серр Т., Вольф Л., Билески С., Ризенхубер М.
 и Поджио Т. Надежное распознавание объектов с помощью корковоподобных механизмов. IEEE Trans. Анальный узор. Мах. Интел. 29 , 411–426 (2007).
и Поджио Т. Надежное распознавание объектов с помощью корковоподобных механизмов. IEEE Trans. Анальный узор. Мах. Интел. 29 , 411–426 (2007). Артикул пабмед Google Scholar
-
Ван, Д., Су, Дж. и Ю, Х. Извлечение признаков и анализ обработки естественного языка для глубокого изучения английского языка. Доступ IEEE 8 , 46335–46345 (2020).
Артикул Google Scholar
-
Ribeiro, A.H. et al. Автоматическая диагностика ЭКГ в 12 отведениях с использованием глубокой нейронной сети. Нац. коммун. 11 , 1760 (2020).
Артикул КАС ОБЪЯВЛЕНИЯ пабмед ПабМед Центральный Google Scholar
-
Лай, Л. и др. Компьютерная диагностика воронкообразной деформации грудной клетки с использованием изображений КТ и методов глубокого обучения.
 Науч. Респ. 10 , 20294 (2020).
Науч. Респ. 10 , 20294 (2020). Артикул КАС пабмед ПабМед Центральный Google Scholar
-
Юань Б. и др. Неконтролируемое и контролируемое обучение с помощью нейронной сети для анализа транскриптома человека и диагностики рака. Науч. Респ. 10 , 19106 (2020).
Артикул КАС ОБЪЯВЛЕНИЯ пабмед ПабМед Центральный Google Scholar
-
Шин Х. и др. Глубокие сверточные нейронные сети для компьютерного обнаружения: архитектуры CNN, характеристики набора данных и трансферное обучение. IEEE Trans. Мед. Imaging 35 , 1285–1298 (2016).
Артикул пабмед Google Scholar
-
Таджбахш, Н. и др. Сверточные нейронные сети для анализа медицинских изображений: полное обучение или тонкая настройка? IEEE Trans.
 Мед. Визуализация 35 , 1299–1312 (2016).
Мед. Визуализация 35 , 1299–1312 (2016). Артикул пабмед Google Scholar
-
ЛеКун, Ю. и Бенжио, Ю. в Справочник по теории мозга и нейронным сетям (изд. Арбиб, Массачусетс) 255–258 (MIT Press, 1998).
-
ЛеКун Ю., Бенжио Ю. и Хинтон Г. Глубокое обучение. Природа 521 , 436–444 (2015).
Артикул КАС ОБЪЯВЛЕНИЯ пабмед Google Scholar
-
Барбастатис, Г., Озджан, А. и Ситу, Г. Об использовании глубокого обучения для вычислительной обработки изображений. Оптика 6 , 921–943 (2019).
Артикул ОБЪЯВЛЕНИЯ Google Scholar
-
Крижевский А., Суцкевер И. и Хинтон Г. Э. Классификация Imagenet с глубокими свёрточными нейронными сетями. Доп.
 Нейронная инф. Процесс. Сист. 25 , 1097–1105 (2012).
Нейронная инф. Процесс. Сист. 25 , 1097–1105 (2012). Google Scholar
-
Nair, V. & Hinton, G. E. Ректифицированные линейные единицы улучшают ограниченные машины Больцмана. В проц. 27-я Международная конференция по машинному обучению (под редакцией Фюрнкранца, Дж. и Йоахимса, Т.) 807–814 (Omnipress, 2010).
-
Рен, С., Хе, К., Гиршик, Р. и Сан, Дж. Быстрее R-CNN: к обнаружению объектов в реальном времени с сетями предложений регионов. IEEE Trans. Анальный узор. Мах. Интел. 39 , 1137–1149 (2017).
Артикул пабмед Google Scholar
-
Ли, Х., Лин, З., Шен, X., Брандт, Дж. и Хуа, Г. Каскад сверточной нейронной сети для распознавания лиц. В конференции IEEE 2015 года по компьютерному зрению и распознаванию образов (CVPR ) 5325–5334 (IEEE, 2015).

-
Shen, Y. et al. Глубокое обучение с когерентными нанофотонными схемами. Нац. Фотоника 11 , 441–446 (2017).
Артикул КАС ОБЪЯВЛЕНИЯ Google Scholar
-
Шастри, Б.Дж. и др. Фотоника для искусственного интеллекта и нейроморфных вычислений. Нац. Фотоника 15 , 102–114 (2021).
Артикул КАС ОБЪЯВЛЕНИЯ Google Scholar
-
Bogaerts, W. et al. Программируемые фотонные схемы. Природа 586 , 207–216 (2020).
Артикул КАС ОБЪЯВЛЕНИЯ пабмед Google Scholar
-
Moons, B. & Verhelst, M. Энергоэффективный прецизионно масштабируемый процессор ConvNet на 40-нм CMOS. IEEE J. Твердотельные схемы 52 , 903–914 (2017).
Артикул ОБЪЯВЛЕНИЯ Google Scholar
 «>
«> Lee, J. et al. UNPU: энергосберегающий ускоритель глубоких нейронных сетей с полностью переменным битовым весом. IEEE J. Твердотельные схемы 54 , 173–185 (2019 г.)).
Артикул ОБЪЯВЛЕНИЯ Google Scholar
-
Hill, P. et al. DeftNN: устранение узких мест для выполнения DNN на графических процессорах за счет устранения векторов синапсов и разделения данных ушных вычислений. В 2017 г. 50-й ежегодный международный симпозиум IEEE/ACM по микроархитектуре (MICRO) 786–799 (IEEE, 2017).
-
Нурвитадхи, Э. и др. Ускорение бинаризованных нейронных сетей: сравнение FPGA, CPU, GPU и ASIC. В 2016 Международная конференция по программируемым пользователем технологиям (FPT) 77–84 (IEEE, 2016).
-
Аштиани Ф., Ризи А. и Афлатуни Ф. Одночиповый нанофотонный формирователь изображений ближнего поля. Optica 6 , 1255–1260 (2019).

Артикул КАС ОБЪЯВЛЕНИЯ Google Scholar
-
Ченг З., Риос К., Перинс У. Х. П., Райт К. Д. и Бхаскаран Х. Фотонный синапс на кристалле. науч. Доп. 3 , e1700160 (2017).
Артикул ОБЪЯВЛЕНИЯ пабмед ПабМед Центральный Google Scholar
-
Tait, A. N. et al. Нейроморфные фотонные сети с использованием кремниевых банков фотонных весов. Науч. Респ. 7 , 7430 (2017).
Артикул ОБЪЯВЛЕНИЯ пабмед ПабМед Центральный Google Scholar
-
Feldmann, J. et al. Полностью оптические импульсные нейросинаптические сети с возможностью самообучения. Природа 569 , 208–214 (2019).
Артикул КАС ОБЪЯВЛЕНИЯ пабмед ПабМед Центральный Google Scholar
 «>
«> Miscuglio, M. et al. Полностью оптическая нелинейная функция активации для фотонных нейронных сетей. Опц. Матер. Экспресс 8 , 3851–3863 (2018).
Артикул КАС ОБЪЯВЛЕНИЯ Google Scholar
-
Джа А., Хуанг К. и Прукнал П. Р. Реконфигурируемые полностью оптические нелинейные функции активации для нейроморфной фотоники. Опц. лат. 45 , 4819–4822 (2020).
Артикул ОБЪЯВЛЕНИЯ пабмед Google Scholar
-
Feldmann, J. et al. Параллельная сверточная обработка с использованием встроенного фотонного тензорного ядра. Природа 589 , 52–58 (2021).
Артикул КАС ОБЪЯВЛЕНИЯ пабмед Google Scholar
-
Zuo, Y. et al. Полностью оптическая нейронная сеть с нелинейными функциями активации.
 Оптика 6 , 1132–1137 (2019).
Оптика 6 , 1132–1137 (2019). Артикул КАС ОБЪЯВЛЕНИЯ Google Scholar
-
Лин, X. и др. Полностью оптическое машинное обучение с использованием дифракционных глубоких нейронных сетей. Наука 361 , 1004–1008 (2018).
Артикул MathSciNet КАС ОБЪЯВЛЕНИЯ пабмед Google Scholar
-
Bueno, J. et al. Обучение с подкреплением в крупномасштабной фотонной рекуррентной нейронной сети. Optica 5 , 756–760 (2018).
Артикул ОБЪЯВЛЕНИЯ Google Scholar
-
Чжоу Т. и др. Крупномасштабные нейроморфные оптоэлектронные вычисления с реконфигурируемым блоком дифракционной обработки. Нац. Фотоника 15 , 367–373 (2021).
Артикул КАС ОБЪЯВЛЕНИЯ Google Scholar
 «>
«> Чанг, Дж. и др. Гибридные оптико-электронные сверточные нейронные сети с оптимизированной дифракционной оптикой для классификации изображений. Науч. Респ. 8 , 12324 (2018).
Артикул ОБЪЯВЛЕНИЯ пабмед ПабМед Центральный Google Scholar
-
Сюй, X. и др. 11 Фотонный сверточный ускоритель TOPS для оптических нейронных сетей. Природа 589 , 44–51 (2021).
Артикул КАС ОБЪЯВЛЕНИЯ пабмед Google Scholar
-
AMD Radeon TM RX 6700 XT Графика. https://www.amd.com/en/products/graphics/amd-radeon-rx-6700-xt.
-
Шолле, Ф. и др. Керас. https://keras.io (2015).
-
Tait, A. N. et al. Нейрон кремниевого фотонного модулятора. Физ. Преподобный заявл. 11 , 064043 (2019).
Артикул КАС ОБЪЯВЛЕНИЯ Google Scholar
 «>
«> Стоун М. Перекрёстный выбор и оценка статистических прогнозов. JR Stat. соц. Серия B Стат. Методол. 36 , 111–147 (1974).
MathSciNet МАТЕМАТИКА Google Scholar
-
Лекун Ю. и др. Набор данных MNIST рукописных цифр. http://yann.lecun.com/exdb/mnist/ (1999).
-
Лекун Ю., Боттоу Л., Бенжио Ю. и Хаффнер П. Градиентное обучение применительно к распознаванию документов. Проц. IEEE 86 , 2278–2324 (1998).
Артикул Google Scholar
-
Раковски М. и др. 45-нм CMOS — монолитная технология кремниевой фотоники (45CLO) для маломощных и высокоскоростных оптических межсоединений нового поколения. Конференция и выставка оптоволоконных коммуникаций 2020 (OFC) (IEEE, 2020).
-
Фаренкопф, Н. М. и др. AIM Photonics MPW: высокодоступная передовая технология для быстрого прототипирования фотонных интегральных схем.
 IEEE J. Сел. Вершина. Квантовый электрон. 25 , 1–6 (2019).
IEEE J. Сел. Вершина. Квантовый электрон. 25 , 1–6 (2019). Артикул Google Scholar
-
Борджи, А., Ченг, М., Цзян, Х. и Ли, Дж. Обнаружение заметных объектов: эталон. IEEE Trans. Процесс изображения. 24 , 5706–5722 (2015).
Артикул MathSciNet ОБЪЯВЛЕНИЯ пабмед Google Scholar
-
Ченг, М., Митра, Н. Дж., Хуанг, X., Торр, П. Х. С. и Ху, С. Обнаружение значимых областей на основе глобального контраста. IEEE Trans. Анальный узор. Мах. Интел. 37 , 569–582 (2015).
Артикул пабмед Google Scholar
-
Кист А. М. Глубокое обучение на граничных TPU. Препринт на https://arxiv.org/abs/2108.13732 (2021 г.).
-
Камера IMAGO Technologies Edge AI. https://imago-technologies.
 com/wp-content/uploads/2021/01/Specification-VisionAI-V1.2.pdf.
com/wp-content/uploads/2021/01/Specification-VisionAI-V1.2.pdf. -
Интеллектуальное машинное зрение JeVois. https://www.jevoisinc.com/collections/jevois-hardware/products/jevois-pro-deep-learning-smart-camera.
-
Кулюкин В. и др. О классификации изображений в видеоанализе всенаправленного трафика Apis mellifera : случайные армированные леса против неглубоких сверточных сетей. Заяв. науч. 11 , 8141 (2021).
Артикул КАС Google Scholar
-
Chiu, T. Y., Wang, Y. & Wang, H. Распределенный усилитель с низким энергопотреблением и переменным усилением, работающий на частоте 3,7–43,7 ГГц, выполненный на 90-нм КМОП. Микрофон IEEE. Провод. комп. лат. 31 , 169–172 (2021).
Артикул Google Scholar
-
Сюань З. и др.
 Маломощный оптический приемник 40 Гбит/с в кремнии. В 2 015 IEEE Radio Frequency Integrated Circuits Symposium (RFIC) 315–318 (IEEE, 2015).
Маломощный оптический приемник 40 Гбит/с в кремнии. В 2 015 IEEE Radio Frequency Integrated Circuits Symposium (RFIC) 315–318 (IEEE, 2015).
Скачать ссылки
Благодарности
Эта работа была поддержана Управлением военно-морских исследований США под номером N00014-19-1-2248.
Информация о авторе
Авторы и принадлежности
-
Департамент электротехники и системной инженерии, Университет Пенсильвании, Филадельфия, Пенсиль Ashtiani
Посмотреть публикации автора
Вы также можете искать этого автора в PubMed Google Scholar
- Александр Дж. Гирс
Посмотреть публикации автора
Вы также можете искать этого автора в PubMed Google Scholar
- Firooz Aflatouni
Просмотр публикаций автора
Вы также можете искать этого автора в PubMed Google Scholar
Contributions
Идея дизайна принадлежит Ф. Аштиани и Ф. Афлатуни. Ф. Аштиани спроектировал, смоделировал и изложил фотонный чип. Ф. Аштиани и А.Дж.Г. провел замеры. Ф. Афлатуни руководил проектом. Рукопись написали Ф. Аштиани и Ф. Афлатуни.
Аштиани и Ф. Афлатуни. Ф. Аштиани спроектировал, смоделировал и изложил фотонный чип. Ф. Аштиани и А.Дж.Г. провел замеры. Ф. Афлатуни руководил проектом. Рукопись написали Ф. Аштиани и Ф. Афлатуни.
Автор, ответственный за переписку
Переписка с Фируз Афлатуни.
Декларации этики
Конкурирующие интересы
Ф. Афлатуни и Ф. Аштиани подали патент на предложенную архитектуру PDNN (номер публикации WO2022020437A1).
Рецензирование
Информация о рецензировании
Nature благодарит Вольфрама Перниса и других анонимных рецензентов за их вклад в рецензирование этой работы.
Дополнительная информация
Примечание издателя Springer Nature остается нейтральной в отношении юрисдикционных претензий в опубликованных картах и институциональной принадлежности.
Рисунки и таблицы с расширенными данными
Расширенные данные Рис. 1 Формирование изображения и установка измерения.
a , Показана апертура массива входных пикселей и конструкция ответвителя (пикселя) решетки. Печатная плата (PCB) наклонена (примерно на 12°), чтобы максимизировать эффективность пикселей при 1532 нм. b , Настройка измерения классификации. Лазер 1, излучающий с длиной волны 1532 нм, служит источником света для формирования изображения на входной матрице пикселей (на этапе классификации) или калибровочной матрицы (на этапе обучения), а лазер 2, излучающий с длиной волны 1559,93 нм, используется как свет питания. Целевые объекты (набор данных) печатаются на прозрачной пленке, закрепленной на специально изготовленной раме. Для сканирования набора данных используется высокоточный XY-позиционер. Микроконтроллер используется для записи весов в фотонный чип и реализации циклов управления выравниванием MRM.
Расширенные данные Рис. 2. Обучение микросхемы PDNN и расчеты пороговых значений.
a , Реализованный алгоритм поиска и пересмотра пороговых значений для правильного разделения N различных классов. Линейная комбинация выхода сети, в данном случае дифференциального выхода, определенного как В из = Out1 − Out2, измеряется и сравнивается с различными пороговыми уровнями. Пороговые значения (TH j ) пересматриваются одно за другим как измеренные дифференциальные выходные значения сети ( V out, i ) последовательно передаются в алгоритм.
Линейная комбинация выхода сети, в данном случае дифференциального выхода, определенного как В из = Out1 − Out2, измеряется и сравнивается с различными пороговыми уровнями. Пороговые значения (TH j ) пересматриваются одно за другим как измеренные дифференциальные выходные значения сети ( V out, i ) последовательно передаются в алгоритм.
Расширенные данные Рис. 3 Измерение времени распространения.
a , Установка и упаковка для измерения времени распространения. b , Калибровочная установка с использованием испытательной конструкции, состоящей из решетчатого соединителя и ФД. c , Два обнаруженных импульса в узлах A и B показывают сквозную системную задержку около 570 пс. d , Установка измерения, используемая для демонстрации влияния отклика MRM с прямым смещением на форму импульса.
Расширенные данные Рис. 4 Сравнение с современным уровнем техники.
Схемы классификации изображений, реализованные с использованием оптических и электронных нейронных сетей.
Расширенные данные Рис. 5 Масштабируемость и методы увеличения времени вычислений.
a , Фотонная нейронная сеть N , в которой каждый слой имеет свой источник света, что позволяет масштабировать глубокую сеть с большим количеством слоев. Расширение полосы пропускания за счет поглощения паразитной емкости частичных разрядов в линии передачи с сосредоточенными элементами ( b ) и с использованием одного PD на нейрон (после оптического объединения) ( c ).
Расширенные данные Рис. 6 Алгоритм выравнивания микрокольца и характеристика.
a , Блок-схема реализованного алгоритма выравнивания микрокольца. Минимизируемая функция стоимости равна V SUM , которая представляет собой сумму выходов второго и третьего слоев (то есть H i и O i ). Все микрокольца термически настроены, чтобы найти оптимальные напряжения нагревателя, которые соответствуют одной и той же резонансной длине волны для всех семи колец.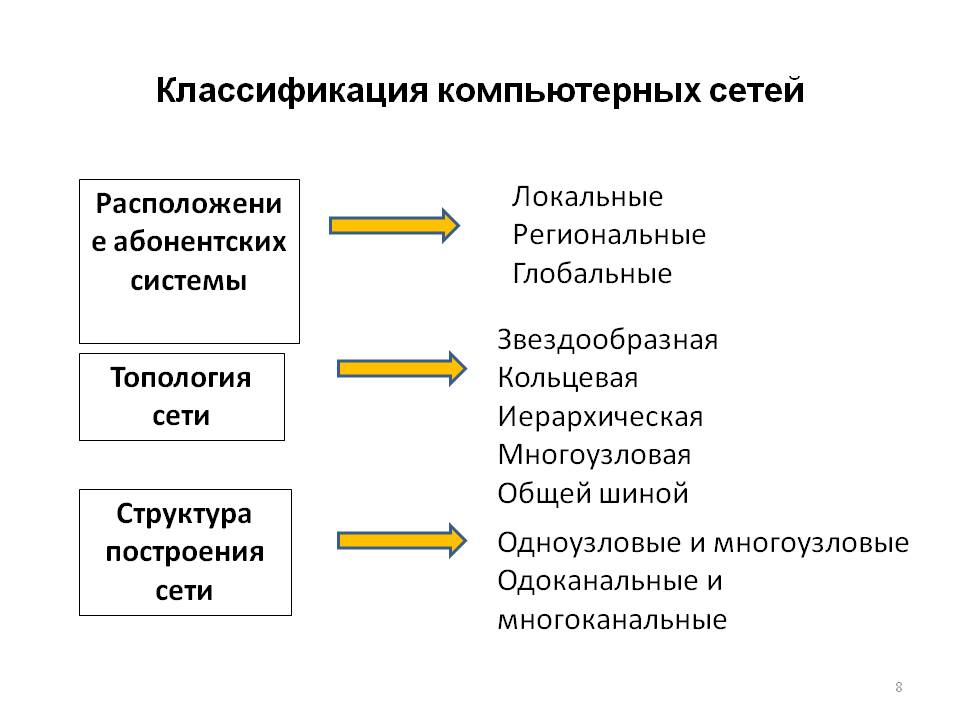 b , При отсутствии входного освещения выходы нейронов первого слоя (I i ) равны нулю. Если микрокольца правильно выровнены, выходы нейронов второго и третьего слоев остаются низкими. c , В случае, когда оптический вход равномерно освещает массив входных пикселей, если все кольца выровнены, I 1 до I 4 будет увеличиваться, сдвигая резонансные длины волн MRM, что приводит к большому изменение выходов нейронов второго и третьего слоев.
b , При отсутствии входного освещения выходы нейронов первого слоя (I i ) равны нулю. Если микрокольца правильно выровнены, выходы нейронов второго и третьего слоев остаются низкими. c , В случае, когда оптический вход равномерно освещает массив входных пикселей, если все кольца выровнены, I 1 до I 4 будет увеличиваться, сдвигая резонансные длины волн MRM, что приводит к большому изменение выходов нейронов второго и третьего слоев.
Расширенные данные Рис. 7 Блок-схема электронной схемы управления.
Микроконтроллер отправляет сигналы синхронизации и данных на последовательные ЦАП, тогда как выходы ЦАП подключены к соответствующим драйверам для управления встроенными фотонными устройствами (штыревые аттенюаторы, кольцевые PN-переходы и микрокольцевые тепловые фазовращатели) .
Расширенная таблица данных 1 Показатели производительности различных встроенных устройствПолноразмерная таблица
Расширенная таблица данных 2 Сравнение производительности с современными оптическими и электронными реализациямиПолная таблица
Расширенная таблица данных 3 Список оборудования и устройствПолная таблица
Права и разрешения
Перепечатки и разрешения
Об этой статье
Интегрированный фотонный процессор на базе Microcomb
- Боуэн Бай
- Ципэн Ян
- Синджун Ван
Nature Communications (2023)
Обработка тензорных потоков высокого порядка с использованием интегральных фотонных схем
- Шаофу Сюй
- Цзин Ван
- Вэйвэнь Цзоу
Nature Communications (2022)
Фемтоджоульное фемтосекундное полностью оптическое переключение в нанофотонике ниобата лития
- Цюши Го
- Риото Секине
- Алиреза Маранди
Природа Фотоника (2022)
Нелинейный германий-кремниевый фотодиод для активации и мониторинга в фотонных нейроморфных сетях
- Ян Ши
- Цзюню Жэнь
- Синьлян Чжан
Nature Communications (2022)
Высокоразмерная оптическая нейронная сеть на основе чипа
- Синью Ван
- Пэн Се
- Синцай Чжан
Nano-Micro Letters (2022)
Комментарии
Отправляя комментарий, вы соглашаетесь соблюдать наши Условия и Правила сообщества.
