Что такое компьютерная сеть. Как классифицируются компьютерные сети по территориальному охвату. Какие бывают топологии сетей. Каковы основные характеристики и преимущества разных типов сетей.
Что такое компьютерная сеть и зачем она нужна
Компьютерная сеть представляет собой систему связанных между собой компьютеров и других устройств, предназначенную для обмена данными и совместного использования ресурсов. Основные задачи, которые решают компьютерные сети:
- Обеспечение совместного доступа к файлам, базам данных, программам
- Организация общего использования периферийных устройств (принтеров, сканеров и т.д.)
- Обмен сообщениями между пользователями
- Распределение вычислительной нагрузки между компьютерами
- Повышение надежности за счет дублирования ресурсов
Объединение компьютеров в сеть позволяет значительно повысить эффективность работы и оптимизировать использование ресурсов. Именно поэтому компьютерные сети сегодня широко применяются как в организациях, так и для домашнего использования.
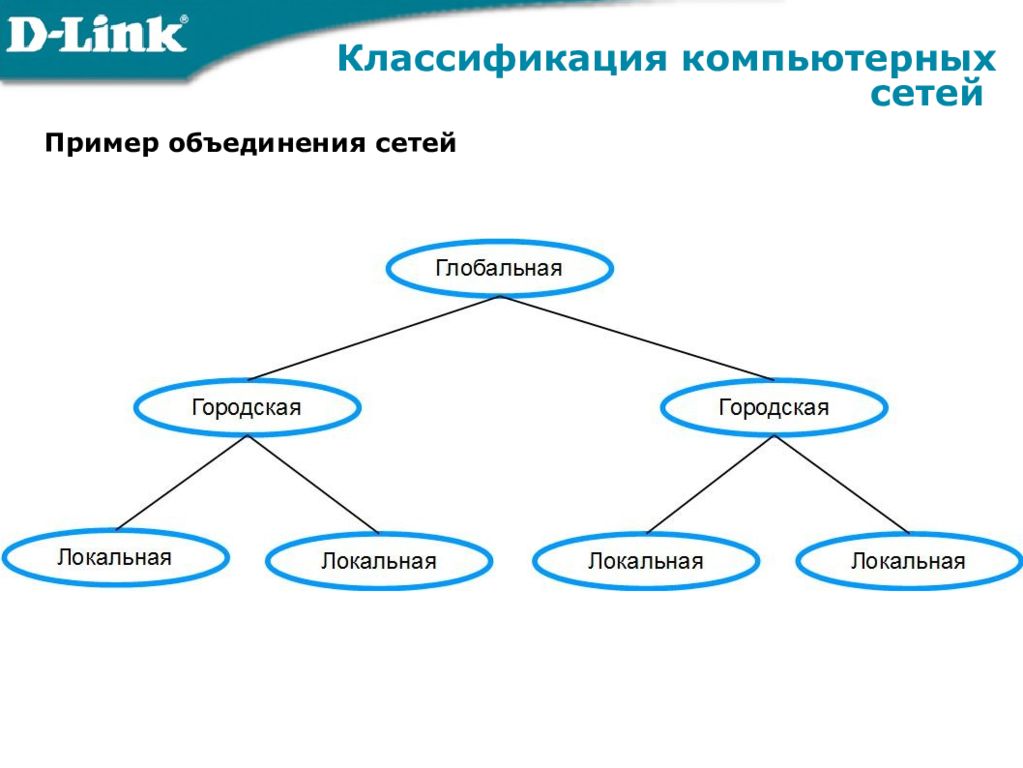
Классификация компьютерных сетей по территориальному охвату
По территориальному охвату компьютерные сети принято разделять на следующие основные типы:
Персональные сети (PAN)
Персональные сети (Personal Area Network) охватывают небольшое пространство вокруг рабочего места пользователя. Обычно имеют радиус действия до 10 метров. Примеры: Bluetooth, инфракрасная связь.
Локальные сети (LAN)
Локальные сети (Local Area Network) объединяют компьютеры в пределах одного или нескольких близко расположенных зданий. Радиус действия до нескольких километров. Наиболее распространенный тип сетей в организациях.
Городские сети (MAN)
Городские сети (Metropolitan Area Network) охватывают территорию города или крупного населенного пункта. Радиус действия десятки километров. Часто используются для объединения офисов одной компании в пределах города.
Глобальные сети (WAN)
Глобальные сети (Wide Area Network) объединяют компьютеры и локальные сети на больших территориях, охватывающих регионы, страны и континенты. Самый известный пример — сеть Интернет.
Основные топологии компьютерных сетей
Топология сети — это способ физического соединения компьютеров в сети. Выделяют три базовые топологии:
Шина
В топологии «шина» все компьютеры подключены к одному общему кабелю — шине. Преимущества: простота монтажа, небольшой расход кабеля. Недостатки: при повреждении кабеля нарушается работа всей сети.
Звезда
В топологии «звезда» каждый компьютер подключен отдельным кабелем к центральному устройству (концентратору). Преимущества: выход из строя одного компьютера не влияет на работу остальных. Недостатки: большой расход кабеля, зависимость от работоспособности центрального устройства.
Кольцо
В топологии «кольцо» компьютеры соединены последовательно в замкнутое кольцо. Преимущества: равноправие компьютеров, простота монтажа. Недостатки: выход из строя одного узла нарушает работу всей сети.
Основные характеристики компьютерных сетей
При оценке и выборе компьютерных сетей учитывают следующие ключевые характеристики:
- Скорость передачи данных — определяет, как быстро информация может передаваться по сети
- Пропускная способность — максимальный объем данных, передаваемых по сети в единицу времени
- Надежность — способность сети сохранять работоспособность при отказе отдельных элементов
- Безопасность — защищенность от несанкционированного доступа
- Масштабируемость — возможность легкого расширения сети
- Прозрачность — удобство использования сетевых ресурсов для пользователя
Выбор оптимального типа и топологии сети зависит от конкретных задач и условий применения. Правильно спроектированная сеть позволяет значительно повысить эффективность работы организации.
Преимущества использования компьютерных сетей
Внедрение компьютерных сетей дает организациям следующие важные преимущества:
- Повышение эффективности использования ресурсов за счет совместного доступа
- Ускорение обмена информацией между сотрудниками
- Оптимизация бизнес-процессов и документооборота
- Сокращение затрат на приобретение оборудования
- Повышение надежности хранения данных
- Упрощение администрирования и поддержки IT-инфраструктуры
При грамотном проектировании и внедрении компьютерные сети позволяют существенно повысить производительность труда и конкурентоспособность организации. Именно поэтому сетевые технологии сегодня активно используются во всех сферах деятельности.
Классификация компьютерных сетей — Студопедия
Все многообразие компьютерных сетей можно классифицировать по группе признаков:
1. Территориальной распространенности.
2. Ведомственной принадлежности.
3. Скорости передачи информации.
4. Типу среды передачи.
По территориальной распространенности сети могут быть локальными, региональными и глобальными.
Локальные сети — это сети перекрывающие территорию не более 10 квадратных километров.
Региональные — это сети расположенные на территории города или области.
Глобальные — это сети расположенные на территории государства или группы государств, например, всемирная сеть Internet.
По ведомственной принадлежности различают ведомственные и государственные сети.
Ведомственные сети принадлежат одной организации и располагаются на ее территории. Это может быть локальная сеть предприятия.
Корпоративные сети. Несколько отделений одной кампании, расположенные на территории города, области, страны или государства образуют корпоративную компьютерную сеть.
Государственные сети – сети, используемые в государственных структурах.
По скорости передачи информациикомпьютерные сети делятся на: низкоскоростные, среднескоростные, высокоскоростные.
По типу среды передачи разделяются на сети
· коаксиальные,
· на витой паре,
· оптоволоконные,
· с передачей информации по радиоканалам,
· в инфракрасном диапазоне и т.д.
Следует заметить, что основные отличия в принципах построения сетей определяются средой передачи.
Помимо рассмотренных признаков компьютерные сети могут классифицироваться по типу, топологии, сетевой архитектуре и т.п..
Локальные вычислительные сети (ЛВС)
Под локальной вычислительной сетью следует понимать совместное подключение нескольких рабочих станций (отдельных компьютерных рабочих мест) и других устройств к общему каналу передачи данных.
виды по занимаемой территории, способу управления
Что такое компьютерные сети
Компьютерными сетями называют совокупность компьютеров, которые объединены друг с другом каналами передачи данных и обработки информации. Каналы реализуют надежный и оперативный доступ пользователя ко всем информационным услугам или ресурсам сети.
Особенности компьютерных сетей используют для хранения и обработки информационных данных, предоставления удаленного доступа к ним и передачи данных пользователям с результатами обработки.
Преимущества использования компьютерных сетей:
- общедоступность файлов;
- совместный доступ к устройствам ввода-вывода;
- простота использования;
- надежность через резервное копирование;
- безопасность посредством авторизации.
Назначение и классификация компьютерных сетей
По архитектуре
- Локальные (Local Area Network — LAN). Частные, расположенные на ограниченной несколькими десятками метров территории здания/организации. Используются для совместного доступа к таким ресурсам, как принтер или сканер и обмена данными.
- Региональные (Metropolitan Area Network — MAN). Сеть, ограниченная пределами города. Пример — кабельное телевидение. Региональные сети объединяют локальные.
- Глобальные (Wide Area Network — WAN). Могут покрывать территорию страны или континента. Предназначены для организации связи между различными географическими областями как способа коммуникации в режиме реального времени, постоянного доступа к информационным ресурсам, электронной почте, обмен файлами в сети Интернет.
По масштабу администрирования
- Офисные (сети отделов).
- Учрежденческие (сети кампусов).
- Корпоративные.
- Сети общего доступа (Интернет).
По уровню однородности
- Одноранговые. Равноправные компьютерные сети, которые функционируют как самостоятельные рабочие станции, отвечают на запросы в качестве сервера или отправляют запросы в качестве клиента другим компьютерам. Одноранговые сети просты в использовании и экономичны, но эффективность и безопасность информации зависит от каждого компьютера, способного внепланово отключиться от сети.
- Иерархические. Один или несколько мощных компьютеров назначаются серверами, которые обеспечивают управление сетями и хранят информацию. Остальные компьютеры — клиенты. При таком виде разделения отключение рабочих станций не влияет на функционирование сети, а также достигается высокий уровень защиты информации.
По скорости передачи данных
- Низкоскоростные. Не более 10 Мбит/с.
- Среднескоростные. Не более 100 Мбит/с.
- Высокоскоростные. Более 100 Мбит/с.
По типу передающей среды
- Проводная. Передача сигнала происходит по кабелю в конкретном направлении пути.
- Беспроводная. Передача сигналов происходит на расстоянии при помощи радиоволнового, микроволнового, инфракрасного излучения.
По топологии сети
Топология сети — это физическая или электрическая конфигурация кабелей и соединений сети.
Специальные термины:
- Узел сети — компьютер/устройство коммутации.
- Ветвь сети — путь от одного узла к другому.
- Логическая связь — маршрут передачи сигнала между узлами.
- Шина — соединяющий элемент для передачи сигнала.
Три типа основных топологических конфигураций:
- «Общая шина». Самый простой вариант, когда к кабелю подводятся все компьютеры. Сигналы от компьютера к сети передаются по шине в оба направления к другим компьютерам.
- «Звезда». Для каждого компьютера используется свой кабель, идущий от центрального компьютера, который передает принятые сигналы остальным компьютерам.
- «Кольцо». Компьютеры соединяются друг с другом по замкнутой линии, по кольцу идет передача сигнала в одном направлении. Характеризуется присоединением к узлам только по две ветви. Происходит цикл, где одно устройство является передатчиком, а другое — приемником. Узел-приемник анализирует сигналы, переданные конкретно ему.
КОМПЬЮТЕРНЫЕ СЕТИ.НАЗНАЧЕНИЕ И КЛАССИФИКАЦИЯ
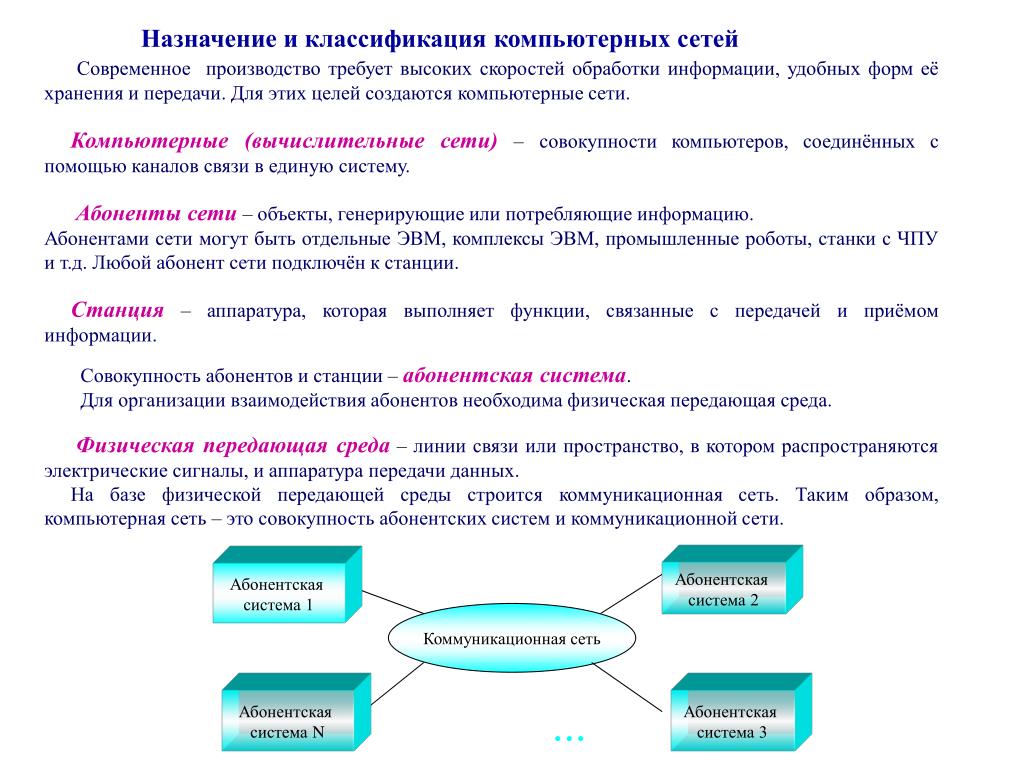
⇐ ПредыдущаяСтр 8 из 9Следующая ⇒Появление персональных компьютеров потребовало нового подхода к организации системы обработки данных, к созданию новых информационных технологий. Возникла потребность перехода от использования отдельных ЭВМ в системах централизованной обработки данных к распределенной обработке данных.
Распределенная обработка данных — это обработка данных, выполняемая на независимых, но связанных между собой компьютерах, представляющих распределенную систему.
Компьютерная (вычислительная) сеть — это совокупность компьютеров и терминалов, соединенных с помощью каналов связи в единую систему, удовлетворяющую требованиям распределенной обработки данных.
Абонентами сети (т. е. объектами, генерирующими или потребляющими информацию в сети) могут быть отдельные компьютеры, комплексы ЭВМ, терминалы, промышленные роботы, станки с числовым программным управлением и т. д.
В зависимости от территориального расположения абонентов компьютерные сети делятся на:
- глобальные — вычислительная сеть объединяет абонентов, расположенных в различных странах, на различных континентах. Глобальные вычислительные сети позволяют решить проолему объединения информационных ресурсов человечества и организации доступа к этим ресурсам;
- региональные — вычислительная сеть связывает абонентов, расположенных на значительном расстоянии друг от друга. Она может включать абонентов большого города, экономического региона, отдельной страны;
- локальные — вычислительная сеть объединяет абонентов, расположенных в пределах небольшой территории. К классу локальных сетей относятся сети отдельных предприятий, фирм, офисов и т. д.
Объединение глобальных, региональных и локальных компьютерных сетей позволяет создавать многосетевые иерархии, обеспечивающие мощные средства обработки огромных информационных массивов и доступ к неограниченным информационным ресурсам.
В общем случае компьютерная сеть представляется совокупностью трех вложенных друг в друга подсистем: сети рабочих станций, сети серверов и базовой сети передачи данных.
Рабочая станция (клиентская-машина, рабочее место, абонентский пункт, терминал) — это компьютер, за которым непосредственно работает абонент компьютерной сети. Сеть рабочих станций представлена совокупностью рабочих станций и средств связи, обеспечивающих взаимодействие рабочих станций с сервером и между собой.
Сервер — это компьютер, выполняющий общие задачи компьютерной сети и предоставляющий услуги рабочим станциям. Сеть серверов — это совокупность серверов и средств связи, обеспечивающих подключение серверов к базовой сети передачи данных.
Базовая сеть передачи данных — это совокупность средств передачи данных между серверами. Она состоит из каналов связи и узлов связи. Узел связи — это совокупность средств коммутации и передачи данных в одном пункте. Узел, связи принимает данные, поступающие по каналам связи, и передает данные в каналы, ведущие к абонентам.
Базовыми требованиями, определяющими архитектуру компьютерных сетей, являются следующие:
- открытость — возможность включения дополнительных компьютеров, терминалов, узлов и линий связи без изменения технических и программных средств существующих компонентов;
- живучесть — сохранение работоспособности при изменении структуры;
- адаптивность — допустимость изменения типов компьютеров, терминалов, линий связи, операционных систем;
- эффективность — обеспечение требуемого качества обслуживания пользователей при минимальных затратах;
- безопасность информации. Безопасность — это способность сети обеспечить защиту информации от несанкционированного доступа.
Указанные требования обеспечиваются модульной организацией управления процессами в сети, реализуемой по многоуровневой схеме. Чисдо уровней и распределение функций между ними существенно влияет на сложность программного обеспечения компьютеров, входящих в сеть, и на эффективность сети. Формальной процедуры выбора числа уровней не существует. Классической является семиуровневая схема. Эта архитектура пришита в качестве эталонной модели.
Уровень 1 — физический — реализует управление каналом связи, что сводится к подключению и отключению канала связи и формированию сигналов, представивших передаваемые данные.
Уровень 2 — канальный — обеспечивает надежную передачу данных через физический канал, организованный на уровне 1.
Уровень 3 — сетевой — обеспечивает выбор маршрута передачи сообщений по линиям, связывающим узлы сети.
Уровни 1-3 организуют базовую сеть передачи данных как систему, обеспечивающую надежную передачу данных между абонентами сети.
Уровень 4 — транспортный — обеспечивает сопряжение абонентов сети с базовой сетью передачи данных.
Уровень 5 — сеансовый — организует сеансы связи на период взаимодействия процессов. На этом уровне по рапросам процессов создаются порты для приема и передачи сообщений и организуются соединения — логические каналы.
Уровень 6 — представительный — осуществляет трансформацию различных языков, форматов данных и кодов для взаимодействия разнотипных компьютеров.
Уровень 7 — прикладной — обеспечивает поддержку прикладных процессов пользователей. Порядок реализации связей в сети регулируется протоколами. Протокол — это набор коммутационных правил и процедур по формированию и передаче данных в сети.
Базовые принципы организации компьютерной сети определяют ее основные характеристики:
- операционные возможности — перечень основных действий по обработке данных. Абоненты сети имеют возможность использовать память и процессоры многих компьютеров для хранения и обработки данных. Предоставляемая компьютерной сетью возможность параллельной обработки данных многими компьютерами и дублирования необходимых ресурсов позволяет сократить время решения задач, повысить надежность системы и достоверность результатов;
- производительность — представляет собой суммарную производительность компьютеров, участвующих в решении задачи пользователя;
- время доставки сообщений — определяется как статистическое среднее время от момента передачи сообщения в сеть до момента получения сообщения адресатом;
- стоимость предоставляемых услуг.
ВИДЫ ТОПОЛОГИЙ.ПРЕИМУЩЕСТВА И НЕДОСТАТКИ
Топология — это способ физического соединения компьютеров в локальную сеть
Существует три основных топологии, применяемые при построении компьютерных сетей:
— топология «Шина»;
— топология «Звезда»;
— топология «Кольцо».
Топология «Шина»
Все компьютеры подключаются к одному кабелю. На его концах должны быть расположены терминаторы. По такой топологии строятся 10 Мегабитные сети 10Base-2 и10Base-5. В качестве кабеля используется Коаксиальные кабели.
Пассивная топология, строится на использовании одного общего канала связи и коллективного использования его в режиме разделения времени. Нарушение общего кабеля или любого из двух терминаторов приводит к выходу из строя участка сети между этими терминаторами (сегмент сети). Отключение любого из подключенных устройств на работу сети никакого влияния не оказывает. Неисправность канала связи выводит из строя всю сеть Все компьютеры в сети “слушают” несущую и не участвуют в передаче данных между соседями. Пропускная способность такой сети снижается с увеличением нагрузки или при увеличении числа узлов. Для соединения кусков шины могут использоваться активные устройства — повторители (repeater) с внешним источником питания.
Топология “Звезда”
Каждый компьютер (и т.п.) подключен отдельным проводом к отдельному порту устройства, называемого концентратором или повторителем (репитер), или хабом(Hub).
Концентраторы могут быть как активные, так и пассивные. Если между устройством и концентратором происходит разрыв соединения, то вся остальная сеть продолжает работать. Правда, если этим устройством был единственный сервер, то работа будет несколько затруднена. При выходе из строя концентратора сеть перестанет работать.
Данная сетевая топология наиболее удобна при поиске повреждений сетевых элементов: кабеля, сетевых адаптеров или разъемов. При добавлении новых устройств «звезда» также удобней по сравнению с топологией общая шина. Также можно принять во внимание, что 100 и 1000 Мбитные сети строятся по топологии «Звезда».
Топология “Кольцо”
Активная топология. Все компьютеры в сети связаны по замкнутому кругу. Прокладка кабелей между рабочими станциями может оказаться довольно сложной и дорогостоящей если они расположены не по кольцу, а, например, в линию.
В качестве носителя в сети используется витая пара или оптоволокно. Сообщения циркулируют по кругу.
Рабочая станция может передавать информацию другой рабочей станции только после того, как получит право на передачу (маркер), поэтому коллизии исключены. Информация передается по кольцу от одной рабочей станции к другой, поэтому при выходе из строя одного компьютера, если не принимать специальных мер выйдет из строя вся сеть.
Время передачи сообщений возрастает пропорционально увеличению числа узлов в сети. Ограничений на диаметр кольца не существует, т.к. он определяется только расстоянием между узлами в сети.
Кроме приведенных выше топологий сетей широко применяются т. н. гибридные топологии: “звезда-шина”, “звезда-кольцо”, “звезда-звезда”.
Читайте также:
Классификация Компьютерных Сетей — 3 Основных Вида
Существуют разные виды сетей, они сильно различаются друг от друга. Мы рассмотрим 3 вида классификации сетей:
- Протяженность сети;
- Технологии передачи данных;
- Вид коммутации.
Тип коммутации
Сеть делится на сети с коммутацией (сопряжением) каналов и пакетов. Перед тем, как осуществить передачу информации в сетях с коммутацией каналов, нужно установить связь между отправителем и получателем. Например, как на картинке, красной линией.
После этого все данные идут по налаженному соединению. Коммутация каналов осуществляется в телефонной сети. Сопряжение пакетов осуществляется в компьютерных сетях. Данные разделяются на пакеты, которые, в свою очередь, отправляются отдельно. Такие пакеты могут проходить сквозь сеть различными путями.
Отказоустойчивость — это достоинство сети с коммутацией пакетов. Если сломается один из переходных узлов, будет возможность найти обходной путь через сеть, например, как на картинке ниже.
В сетях с сопряжением каналов при поломке одного из промежуточных узлов соединение прерывается и передавать информацию нельзя. В сетях с коммутацией пакетов при подходе пакета на промежуточный узел необходимо решать задачу маршрутизации, определять куда дальше направлять этот пакет.
Решить задачу маршрутизации можно отдельно для индивидуального пакета, на каждом промежуточном устройстве. Это требует времени и создает вычислительную нагрузку на промежуточные устройства. В сетях с коммутацией каналов установка соединения происходит один раз и расходов на маршрутизацию нет.
Технология передачи
Бывают широковещательные сети, в таких сетях, те данные которые передаются в сеть доступны всем компьютерам в сети.
Сети “Точка-Точка” данные передаются от одного компьютера к другому, иногда приходится передавать данные через несколько переходных узлов.
Протяженность
Следующая классификация по протяженности. Самые маленькие сети называются персональные, их протяженность примерно 1 м, размещаются на столе или рядом с человеком. Примером персональной сети является Bluetooth.
Следующий тип сети — локальная. Как правило сеть внутри одного здания или нескольких расположенных рядом друг с другом. Протяженность такой сети от нескольких метров до нескольких километров.
Муниципальная сеть — сеть в районе города. Сейчас становятся известными сети, которые позволяют по одному сетевому подключению обеспечить доступ к интернет, телевидению и телефон.
Глобальная — сети в масштабах страны или континента. В России такие сети строят компании Ростелеком и Транстелеком.
Объединение сетей — сети которые включают в себя весь мир. Например, сеть интернет.
Классификация компьютерных сетей
Развитие современных информационных технологий сопровождается увеличением роли телекоммуникационных систем различного назначения и распространением различных классов компьютерных сетей. Это объясняется необходимостью более быстрой передачи информации, в том числе и управленческой, для которой важное значение имеют время и оперативность ее доставки до пользователей. Более весомым становится использовании средств электронной связи документов — электронной почты, программного обеспечения браузеров и т.д. — с помощью которых намного увеличивается эффективность работы специалистов различных уровней управления современными предприятиями и учреждениями.
Особое место в этих задачах занимают современные технологии компьютерных сетей, среди которых следует выделить локальные и глобальные сети. Это объясняется необходимостью использования корпоративной информации, содержащейся в корпоративных базах данных, которые могут располагаться как в отдельных подразделениях предприятия, так и за его пределами. Итак современные технологии обработки документов различного назначения должны базироваться на средствах телекоммуникационной связи и стандартов компьютерных сетей, выступающих как транспортные системы передачи данных.
Для повышения эффективности функционирования сетей предприятия должны использоваться средства их распространения в случае увеличения количества рабочих станций и пользователей. Это приводит к необходимости более детального изучения и использования специальных приспособлений и соответствующих стандартов для объединения отдельных локальных сетей в единую. К ним относятся концентраторы, мосты, шлюзы, коммутаторы, которые позволяют увеличивать эффективность отдельных сетей за счет объединения сетей с различными стандартами и протоколами. Выбор определенного стека протоколов обеспечивает определение возможностей работы сети по выбранным стандартом и позволяет решать вопросы оценки эффективности развертывания сети с заданным уровнем масштабируемости и распределенности данных. В связи с этим возникает необходимость обоснования выбора системного сетевого обеспечения в условиях клиент-серверной технологии доступа и обработки запросов пользователей.
Классы компьютерных сетей
Компьютерная сеть или сеть передачи данных представляет собой некоторую совокупность узлов (компьютеров, рабочих станций или другого оборудования), соединенных коммуникационными каналами, а также набор оборудования, который обеспечивает соединение станций и передачу между ними информации.
На сегодня существует огромное количество компьютерных сетей различного назначения, построенных на основе различных компьютерных и коммуникационных технологий и обусловленных использованием той или иной сетевой архитектуры.
Сетевая архитектура — это совокупность сетевых аппаратных и программных решений, методов доступа и протоколов обмена информациею. Архитектура и номенклатура сетевого оборудования современных компьютерных сетей является результатом развития технических средств и вызваны необходимостью пользователей компьютерной техники обмениваться между собой данными.
Обратимся к истокам компьютерных сетей. Первые компьютеры 50-х годов XX века были громоздкими и дорогими, они предназначались для небольшого круга пользователей. Довольно часто такие компьютеры занимали целые здания и были предназначены для использования в режиме пакетной обработки, а не для интерактивной работы пользователей.
Системы пакетной обработки, как правило, строились на базе мейнфрейма — мощного и надежного компьютера универсального назначения. Пользователи подготавливали перфокарты с данными и командами программ и передавали их в вычислительный центр. Операторы вводили эти карты в компьютер, а распечатанные результаты пользователи получали, как правило, только на следующий день. Таким образом, ошибка в перфокарте означала как минимум суточную задержку. Конечно, для пользователей интерактивный режим работы, при котором можно с терминала оперативно руководить процессом обработки своих данных, был бы удобнее. Разработчики компьютерных сетей в то время в значительной мере не учитывали интересы пользователей, поскольку пытались достичь наибольшей эффективности работы самого дорогого устройства вычислительной машины — процессора.
По мере удешевления процессоров в начале 60-х годов XX века появились новые способы организации вычислительного процесса, которые позволили учесть интересы пользователей. Начали развиваться интерактивные многотерминальные системы распределения времени. В таких системах каждый пользователь получал собственный терминал, с помощью которого он мог вести диалог с компьютером. Количество одновременно работающих с компьютером пользователей зависела от его мощности, а время реакции вычислительной системы было незначительным, и пользователю не очень заметна была параллельная работа с компьютером других пользователей.
Терминалы, выйдя за пределы вычислительного центра, рассредоточились по всему предприятию. И хотя вычислительная мощность оставалась полностью централизованной, некоторые функции — такие, как ввод и вывод данных, стали распределенными. Подобные многотерминальные централизованные системы внешне уже были очень похожи на локальные вычислительные сети. Действительно, обычный пользователь воспринимал работу за терминалом мейнфрейма примерно так же, как сейчас он воспринимает работу с подключенным к сети персональным компьютером. Пользователь мог получить доступ к общим файлам и периферийному оборудованию, при этом у него поддерживалась полная иллюзия единоличного владения компьютером, так как он мог запустить нужную ему программу в любой момент и почти сразу получить результат.
Однако до появления локальных сетей нужно было пройти еще большой путь, потому что многотерминальные системы, хотя и имели внешние черты распределенных систем, все еще поддерживали только централизованную обработку данных. С другой стороны, и потребность предприятий в создании локальных сетей в это время еще не возникла — в одном здании просто нечего было объединять в сеть, так как из-за высокой стоимости вычислительной техники предприятия не могли себе позволить роскошь приобретения нескольких компьютеров. В этот период был справедлив закон, который эмпирически отражал уровень технологии того времени. Согласно этому закону быстродействие компьютера была пропорциональна квадрату его стоимости, отсюда следовало, что за ту же сумму было выгоднее купить одну мощную машину, чем две менее мощные, так как их суммарная мощность была значительно меньше быстродействие дорогой машины.
В начале 70-х годов XX века в результате технологического прорыва в сфере производства компьютерных компонентов появились большие интегральные схемы (БИС). Их сравнительно невысокая стоимость и хорошие функциональные возможности привели к созданию мини-компьютеров, которые стали реальными конкурентами мейнфреймов. Десяток мини-компьютеров, имея ту же стоимость, что и один мейнфрейм, решали некоторые задачи намного быстрее.
Даже небольшие подразделения предприятий получили возможность иметь собственные компьютеры. Мини-компьютеры решали задачи управления технологическим оборудованием, составом и другие задачи на уровне отдела предприятия. Таким образом, появилась концепция распределения компьютерных ресурсов по всему предприятию. Однако при этом все компьютеры одной организации по-прежнему продолжали работать автономно.
Со временем потребности пользователей в быстродействии компьютерной техники росли. Их уже не удовлетворяла изолированная работа на собственном компьютере, пользователям хотелось обмениваться компьютерными данными с пользователями других подразделений в автоматическом режиме.
Ответ на эту потребность пришел в виде появления первых локальных вычислительных сетей.
В общем представлены локальные сети представляют собой объединение компьютеров, сосредоточенных на небольшой территории, как правило, в радиусе не более 1-2 км, хотя в отдельных случаях локальная сеть может иметь и большие размеры, например, несколько десятков километров. В общем случае локальная сеть представляет собой коммуникационную систему, принадлежит одной организации.
Сначала для соединения компьютеров друг с другом использовались нестандартные сетевые технологии.
Сетевая технология — это согласованный набор программных и аппаратных средств (например, драйверов, сетевых адаптеров, кабелей и разъемов) и механизмов передачи данных по линиям связи, достаточных для построения вычислительной сети.
Первые локальные сети оснащались различными устройствами соединения, которые использовали собственные способы представления данных на линиях связи, свои типы кабелей и т.д. Эти устройства могли соединять только конкретные модели компьютеров, для которых они и были разработаны.
Со временем появилась необходимость унификации оборудования и технологий компьютерных сетей. Первые стандартные технологии локальных сетей опирались на принципы коммутации, который был с успехом опробован и доказал свои преимущества при передаче трафика данных в глобальных компьютерных сетях.
В середине 80-х годов XX века утвердились стандартные сетевые технологии объединения компьютеров в сеть — Ethernet, ArcNet, Token Ring, Token Bus, чуть позже – FDDI.
Стандартные сетевые технологии превратили процесс построения локальной сети из искусства в рутинную работу. Для создания сети достаточно было приобрести стандартный кабель, сетевые адаптеры международного стандарта (например, Ethernet), установить адаптеры в компьютеры, присоединить их к кабелю стандартными соединителями и установить на компьютеры одну из популярных сетевых операционных систем (например, Novell NetWare).
Простые алгоритмы работы определили низкую стоимость оборудования Ethernet. Широкий диапазон иерархии скоростей позволял рационально строить локальную сеть, выбирая ту технологию семейства, которая в наибольшей степени отвечала задачам предприятия и потребностям пользователей. Важно также, что все технологии Ethernet очень близки друг к другу принципами работы, что упрощало обслуживание и интеграцию этих сетей.
Классы IP адресов компьютерных сетейДля классификации компьютерных сетей используются различные признаки, но чаще всего сети делят на типы по территориальному признаку, то есть по величине территории, которую покрывает сеть. И для этого есть веские причины, поскольку различия технологий локальных и глобальных сетей очень значительны, несмотря на их постоянное сближение.
К локальным сетям Local Area Networks (LAN) относят сети компьютеров, сосредоточенные на небольшой территории (обычно в радиусе не более 1-2 км). В общем случае локальная сеть представляет собой коммуникационную систему, принадлежит одной организации. Через короткие расстояния в локальных сетях имеется возможность использования относительно дорогих высококачественных линий связи, которые позволяют, применяя простые методы передачи данных, достигать высоких скоростей обмена данными порядка 1000 Мбит/с. В связи с этим услуги, предоставляемые локальными сетями, отличаются широким разнообразием и обычно предусматривают реализацию в режиме on-line.
Глобальные сети Wide Area Networks (WAN) объединяют компьютеры, территориально рассредоточились, которые могут находиться в разных городах и странах. Поскольку прокладка высококачественных линий связи на большие расстояния обходится очень дорого, в глобальных сетях часто используются уже существующие линии связи, изначально предназначенные совсем для других целей. Например, многие глобальные сети строятся на основе телефонных и телеграфных каналов общего назначения (ADSL технология). Из-за сравнительно низких скоростей таких линий связи в глобальных сетях (десятки мегабит в секунду) набор услуг обычно ограничивается передачей файлов, преимущественно не в оперативном, а в фоновом режиме, с использованием электронной почты. Для устойчивой передачи дискретных данных по некачественным линиям связи применяются методы и оборудование, существенно отличные от методов и оборудования, характерных для локальных сетей. Как правило, здесь применяются процедуры контроля и восстановления данных, поскольку наиболее типичный режим передачи данных по территориальному каналу связи связан со значительными искажениями сигналов.
Городские сети (или сети мегаполисов) Metropolitan Area Networks (MAN) являются менее распространенным типом сетей. Эти сети появились сравнительно недавно. Они предназначены для обслуживания территории крупного города мегаполиса. В то время как локальные сети наилучшим образом подходят для разделения ресурсов на коротких расстояниях и широковещательных передач, а глобальные сети обеспечивают работу на больших расстояниях, но с ограниченной скоростью и небогатым набором услуг, сети мегаполисов занимают некоторое промежуточное положение. Они используют цифровые магистральные линии связи, часто оптоволоконные, со скоростями от 100 Мбит/с, и предназначены для связи локальных сетей в масштабах города и соединения локальных сетей с глобальными. Эти сети первоначально были разработаны для передачи данных, но сейчас они поддерживают и такие услуги, как Видеоконференции и интегральную передачу голоса и текста. Развитие технологии сетей мегаполисов осуществлялся местными телефонными компаниями. Исторически сложилось так, что местные телефонные компании всегда обладали слабыми техническими возможностями и поэтому не могли привлечь крупных клиентов. Чтобы преодолеть свою отсталость и занять достойное место в мире локальных и глобальных сетей, местные предприятия связи занялись разработкой сетей на основе самых современных технологий, например технологии коммутации ячеек SMDS или АТМ. Сети мегаполисов являются общественными сетями, и поэтому их услуги обходятся дешевле, чем построение собственной (частной) сети в пределах города.
Общие принципы построения сетей
Изучение конкретных технологий для сетей LAN, WAN и MAN, таких как Ethernet, IP или ATM, показало, что в этих технологий есть много общего. При этом они не являются тождественными, в каждой технологии и протоколе есть свои особенности, так что нельзя механически перенести знания по одной технологии к другой.
Система принципов построения сетей передачи данных появилась в результате решения ряда ключевых проблем, многие из которых являются общими для телекоммуникационных сетей любого типа.
Одной из основных, если не сказать главных, проблем построения сетей является коммутация. Каждый узел выполняет транзитную передачу трафика, должен уметь его коммутировать, то есть обеспечивать взаимодействие пользователей сети.
На технологию коммутации непосредственно влияет принцип выбора маршрута передачи информационных потоков по сети. Маршрут, то есть последовательность транзитных узлов сети, которые должны пройти данные, чтобы попасть к получателю, должен выбираться так, чтобы одновременно достигались две цели. При этом, во-первых, данные каждого пользователя должны передаваться как можно быстрее, с минимальными задержками на пути; во-вторых, ресурсы сети должны использоваться максимально эффективно, так чтобы сеть за единицу времени передавала больше данных, поступающих от всех пользователей сети.
Задача состоит в том, чтобы добиться сочетания этих целей (эгоистической цели отдельного пользователя и коллективной цели сети как единой системы). Компьютерные сети традиционно решали эту проблему неэффективно, в пользу индивидуальных потоков, и только в последнее время появились более продуманные методы маршрутизации.
Компьютерные сети и их классификация
Компьютерная сеть (Computer NetWork) – это совокупность компьютеров и других устройств, соединенных линиями связи и обменивающихся информацией между собой в соответствии с определенными правилами – протоколом.
Протокол играет очень важную роль, поскольку недостаточно только соединить компьютеры линиями связи. Нужно еще добиться того, чтобы они «понимали» друг друга.
Основная цель сети – обеспечить пользователей потенциальную возможность совместного использования ресурсов сети. Ресурсами сети называют информацию, программы и аппаратные средства.
Преимущества работы в сети:
-
Разделение дорогостоящих ресурсов – совместное использование периферийных устройств (лучше и дешевле купить один дорогой, но хороший и быстродействующий принтер и использовать его как сетевой чем к каждому компьютеру покупать дешевые, но плохие принтеры), разделение вычислительных ресурсов (возможность использования удаленного запуска программ).
-
Совершенствование коммуникаций (доступ к удаленным БД, обмен информации)
-
улучшение доступа к информации
-
свобода в территориальном размещении компьютеров
Физическая среда передачи данных – может представлять собой кабель, т.е. набор проводов, изоляционных и защитных оболочек и соединительных разъемов, а также земную атмосферу или космическое пространство, через которые распространяются электромагнитные волны
В зависимости от среды передачи данных линии связи разделяются на:
|
Проводные (воздушные) |
Кабельные |
Радиоканалы наземной и спутниковой связи |
|
Телефонные или телеграфные линии – провода без каких-либо изолирующих или экранирующих оплеток, проложенные между столбами и висящие в воздухе. Плохое качество связи |
В компьютерных сетях используют три основных типа кабеля:
|
беспроводные линии связи |
Наиболее перспективным в настоящее время – оптоволокно.
Классификации сетей:
В зависимости от территориального расположения абонентов компьютерные сети делятся на:
-
глобальные — вычислительная сеть объединяет абонентов, расположенных в различных странах, на различных континентах. Глобальные вычислительные сети позволяют решить проблему объединения информационных ресурсов человечества и организации доступа к этим ресурсам;
-
региональные — вычислительная сеть связывает абонентов, расположенных на значительном расстоянии друг от друга. Она может включать абонентов большого города, экономического региона, отдельной страны;
-
локальные — вычислительная сеть объединяет абонентов, расположенных в пределах небольшой территории. К классу локальных сетей относятся сети отдельных предприятий, фирм, офисов и т. д.
По топологии физических связей – по способу соединения компьютеров между собой
Под топологией вычислительной сети понимается конфигурация графа, вершинам которого соответствуют компьютеры сети (а иногда и другое оборудование), а ребрами — физические связи между ними.
|
Полносвязная топология – каждый компьютер связан со всеми остальными. Громоздкий и неэффективный вариант, т.к. каждый компьютер должен иметь большое кол-во коммуникационных портов. |
|
|
Ячеистая топология – получается из полносвязной путем удаления некоторых связей. Непосредственно связываются только те компьютеры, между которыми происходит интенсивный обмен данными. Даная топология характерна для глобальных сетей |
|
|
Общая шина – до недавнего времени самая распространенная топология для локальных сетей. Компьютеры подключаются к одному коаксиальному кабелю. Дешевый и простой способ, недостатки – низкая надежность. Дефект кабеля парализует всю сеть. Дефект коаксиального разъема редкостью не является |
|
|
Кольцевая топология – данные передаются по кольцу от одного компьютера к другому, если компьютер распознает данные как свои, он копирует их себе во внутренний буфер. |
|
|
Топология Звезда – каждый компьютер отдельным кабелем подключается к общему устройству – концентрат (хаб). Главное преимущество перед общей шиной – большая надежность. Недостаток – высокая стоимость оборудования и ограниченное кол-во узлов в сети (т.к. концентрат имеет ограниченное число портов) |
|
|
Иерархическая Звезда (древовидная топология, снежинка) – топология типа звезды, но используется несколько концентратов, иерархически соединенных между собой связями типа звезда. Самый распространенный способ связей как в локальных сетях, так и в глобальных. |
Выбор топологии электрических связей существенно влияет на многие характеристики сети. Например, Наличие резервных связей повышает надежность сети.
Базовые требования компьютерных сетей:
-
открытость — возможность включения дополнительных компьютеров, терминалов, узлов и линий связи без изменения технических и программных средств существующих компонентов;
-
живучесть — сохранение работоспособности при изменении структуры;
-
адаптивность — допустимость изменения типов компьютеров, терминалов, линий связи, операционных систем;
-
эффективность — обеспечение требуемого качества обслуживания пользователей при минимальных затратах;
-
безопасность информации. Безопасность — это способность сети обеспечить защиту информации от несанкционированного доступа.
Базовые принципы организации компьютерной сети:
-
операционные возможности — перечень основных действий по обработке данных. Абоненты сети имеют возможность использовать память и процессоры многих компьютеров для хранения и обработки данных;
-
производительность — представляет собой суммарную производительность компьютеров, участвующих в решении задачи пользователя;
-
время доставки сообщений — определяется как статистическое среднее время от момента передачи сообщения в сеть до момента получения сообщения адресатом;
-
стоимость предоставляемых услуг.
Network Classification — скачать ppt
Презентация на тему: «Классификация сетей» — стенограмма презентации:
1 Классификация сети
2 4.1 Основы работы с сетью зачем нужна сеть? Необходимость совместного использования информации и ресурсов между различными компьютерами привела к созданию связанных компьютерных систем, называемых сетями, в которых компьютеры соединены так, что данные могут передаваться с машины на машину. В этих сетях пользователи компьютеров могут обмениваться сообщениями и совместно использовать ресурсы, такие как возможности печати и средства хранения данных, которые разбросаны по всей системе.
3 4.1 Основы работы в сети Базовое программное обеспечение, необходимое для поддержки таких приложений: простой пакет служебных программ расширяющаяся система сетевого программного обеспечения, которая обеспечивает сложную инфраструктуру всей сети (в некотором смысле превращается в операционную систему всей сети).
4 4.1 Основы сети классификация сети (1) Компьютерная сеть часто классифицируется как локальная сеть (LAN), городская сеть (MAN) или глобальная сеть (WAN).ЛВС обычно состоит из набора компьютеров в одном здании или строительном комплексе (компьютеры в университетском городке или на производственном предприятии).
5 4.1 Основы сети классификация сети (1) Компьютерная сеть часто классифицируется как локальная сеть (LAN), городская сеть (MAN) или глобальная сеть (WAN). ЛВС обычно состоит из набора компьютеров в одном здании или строительном комплексе (компьютеры в университетском городке или на производственном предприятии).
6
4.1 Основы сети A MAN (охватывающий местное сообщество)
WAN (в соседних городах или на противоположных сторонах мира)
7 4.1 Основы сети Классификация сетей: (2) Другой способ классификации сетей основан на топологии сети, которая относится к схеме, в которой подключены машины.Шина и звезда — две наиболее популярные топологии.
8 4.1 Основы сети Топология шины получила широкое распространение в 1990-х годах, когда она была реализована в соответствии с набором стандартов, известных как Ethernet, и сети Ethernet остаются одной из самых популярных сетевых систем, используемых сегодня. Звезда: в которой одна машина служит центральной точкой, к которой подключены все остальные.
CS231n Сверточные нейронные сети для визуального распознавания
Это вводная лекция, предназначенная для ознакомления людей, не относящихся к компьютерному зрению, с проблемой классификации изображений и подходом, основанным на данных.Содержание:
Классификация изображений
Мотивация . В этом разделе мы познакомимся с проблемой классификации изображений, которая заключается в присвоении входному изображению одной метки из фиксированного набора категорий. Это одна из основных проблем компьютерного зрения, которое, несмотря на свою простоту, имеет множество практических приложений. Более того, как мы увидим позже, многие другие, казалось бы, отдельные задачи компьютерного зрения (такие как обнаружение объектов, сегментация) могут быть сведены к классификации изображений.
Пример . Например, на изображении ниже модель классификации изображений берет одно изображение и присваивает вероятности 4 меткам: {кошка, собака, шляпа, кружка} . Как показано на изображении, имейте в виду, что для компьютера изображение представляется как один большой трехмерный массив чисел. В этом примере изображение кошки имеет ширину 248 пикселей, высоту 400 пикселей и три цветовых канала: красный, зеленый, синий (или сокращенно RGB). Таким образом, изображение состоит из 248 x 400 x 3 чисел, или всего 297 600 чисел.Каждое число является целым числом от 0 (черный) до 255 (белый). Наша задача — превратить эту четверть миллиона чисел в одну метку, например, «кот» .
Задача классификации изображений — спрогнозировать единственную метку (или распределение по меткам, как показано здесь, чтобы показать нашу уверенность) для данного изображения. Изображения представляют собой трехмерные массивы целых чисел от 0 до 255, размером Ширина x Высота x 3. Число 3 представляет три цветовых канала: красный, зеленый, синий.
Вызовы .Поскольку эта задача распознавания визуального концепта (например, кошки) относительно проста для выполнения человеком, стоит рассмотреть возникающие проблемы с точки зрения алгоритма компьютерного зрения. Поскольку мы представляем (неисчерпывающий) список проблем ниже, не забывайте о необработанном представлении изображений в виде трехмерного массива значений яркости:
- Вариант точки обзора . Отдельный экземпляр объекта может быть по-разному ориентирован относительно камеры.
- Изменение масштаба .Визуальные классы часто различаются по размеру (размеру в реальном мире, а не только по размеру изображения).
- Деформация . Многие представляющие интерес объекты не являются твердыми телами и могут быть сильно деформированы.
- Окклюзия . Интересующие объекты могут быть закрыты. Иногда может быть видна только небольшая часть объекта (всего несколько пикселей).
- Условия освещения . Эффекты освещения на пиксельном уровне очень сильны.
- Фоновые помехи . Интересующие объекты могут смешивать с окружающей их средой, что затрудняет их идентификацию.
- Внутриклассовая вариация . Интересующие классы часто могут быть относительно широкими, например стул . Есть много разных типов этих объектов, каждый со своим внешним видом.
Хорошая модель классификации изображений должна быть инвариантной к перекрестному произведению всех этих вариаций, одновременно сохраняя чувствительность к межклассовым вариациям.
Подход, основанный на данных . Как мы можем написать алгоритм, который может классифицировать изображения по отдельным категориям? В отличие от написания алгоритма, например, для сортировки списка чисел, не очевидно, как можно написать алгоритм для идентификации кошек на изображениях. Поэтому вместо того, чтобы пытаться указать, как каждая из категорий интересов выглядит непосредственно в коде, подход, который мы примем, мало чем отличается от того, который вы бы применили с ребенком: мы собираемся предоставить компьютеру множество примеров каждый класс, а затем разработайте алгоритмы обучения, которые рассматривают эти примеры и узнают о внешнем виде каждого класса.Этот подход называется подходом , управляемым данными, , поскольку он основан на первом накоплении обучающего набора данных помеченных изображений. Вот пример того, как может выглядеть такой набор данных:
Пример тренировочного набора для четырех визуальных категорий. На практике у нас могут быть тысячи категорий и сотни тысяч изображений для каждой категории.
Конвейер классификации изображений . Мы видели, что задача классификации изображений состоит в том, чтобы взять массив пикселей, представляющий одно изображение, и присвоить ему метку.Наш полный конвейер можно формализовать следующим образом:
- Входные данные: Наши входные данные состоят из набора изображений N , каждое из которых помечено одним из K различных классов. Мы называем эти данные обучающим набором .
- Learning: Наша задача — использовать обучающую выборку, чтобы узнать, как выглядит каждый из классов. Мы называем этот шаг обучением классификатора или обучением модели .
- Оценка: В конце мы оцениваем качество классификатора, прося его предсказать метки для нового набора изображений, которые он никогда раньше не видел.Затем мы сравним истинные метки этих изображений с предсказанными классификатором. Интуитивно мы надеемся, что многие прогнозы совпадают с истинными ответами (которые мы называем базовой истиной ).
Классификатор ближайшего соседа
В качестве первого подхода мы разработаем то, что мы называем классификатором ближайшего соседа . Этот классификатор не имеет ничего общего со сверточными нейронными сетями и очень редко используется на практике, но он позволит нам получить представление об основном подходе к проблеме классификации изображений.
Пример набора данных классификации изображений: CIFAR-10. Одним из популярных наборов данных классификации изображений игрушек является набор данных CIFAR-10. Этот набор данных состоит из 60 000 крошечных изображений размером 32 пикселя в высоту и ширину. Каждое изображение имеет один из 10 классов (например, «самолет, автомобиль, птица и т. Д.» ). Эти 60 000 изображений разделены на обучающий набор из 50 000 изображений и тестовый набор из 10 000 изображений. На изображении ниже вы можете увидеть 10 случайных примеров изображений из каждого из 10 классов:
Слева: Примеры изображений из набора данных CIFAR-10.Справа: в первом столбце показано несколько тестовых изображений, а рядом с каждым мы показываем 10 самых близких соседей в обучающем наборе в соответствии с разницей в пикселях.Предположим теперь, что нам дан обучающий набор CIFAR-10 из 50 000 изображений (5 000 изображений для каждой метки), и мы хотим пометить оставшиеся 10 000. Классификатор ближайшего соседа возьмет тестовое изображение, сравнит его с каждым из обучающих изображений и спрогнозирует метку ближайшего обучающего изображения. На изображении выше и справа вы можете увидеть пример результата такой процедуры для 10 тестовых изображений.Обратите внимание, что только примерно в 3 из 10 примеров извлекается изображение того же класса, в то время как в остальных 7 примерах это не так. Например, в 8-м ряду ближайшим тренировочным изображением к голове лошади является красная машина, предположительно из-за сильного черного фона. В результате это изображение лошади в этом случае будет неправильно обозначено как автомобиль.
Возможно, вы заметили, что мы оставили неуказанными подробности того, как именно мы сравниваем два изображения, которые в данном случае представляют собой всего лишь два блока размером 32 x 32 x 3.p_2 \ справа | \]
Где сумма берется по всем пикселям. Вот визуализированная процедура:
Пример использования пиксельных различий для сравнения двух изображений с расстоянием L1 (для одного цветового канала в этом примере). Два изображения вычитаются поэлементно, а затем все различия суммируются до одного числа. Если два изображения идентичны, результат будет нулевым. Но если изображения будут сильно отличаться, результат будет большим.
Давайте также посмотрим, как мы можем реализовать классификатор в коде.Во-первых, давайте загрузим данные CIFAR-10 в память как 4 массива: данные / метки для обучения и данные / метки для тестирования. В приведенном ниже коде Xtr (размером 50000 x 32 x 32 x 3) содержит все изображения в обучающем наборе, а соответствующий одномерный массив Ytr (длиной 50000) содержит обучающие метки (от 0 по 9):
Xtr, Ytr, Xte, Yte = load_CIFAR10 ('data / cifar10 /') # волшебная функция, которую мы предоставляем
# сделать все изображения одномерными
Xtr_rows = Xtr.reshape (Xtr.shape [0], 32 * 32 * 3) # Xtr_rows становится 50000 x 3072
Xte_rows = Xte.reshape (Xte.shape [0], 32 Остаточные CNN для задач классификации изображений
ResNet — это короткое название остаточной сети, но что такое остаточное обучение ?
Глубокие сверточные нейронные сети достигли результата классификации изображений человеческого уровня. Глубокие сети извлекают функции и классификаторы нижнего, среднего и высокого уровня сквозным многоуровневым способом, а количество составленных слоев может обогатить «уровни» функций.Сложенный слой имеет решающее значение, посмотрите на результат ImageNet.
Рисунок 1: Ошибка обучения (слева) и ошибка тестирования (справа) на CIFAR-10 с 20-слойными и 56-слойными «простыми» сетями. Более глубокая сеть имеет более высокую ошибку обучения и, следовательно, ошибку теста. Подобные явления в ImageNet представлены на рис. 4.Когда более глубокая сеть начинает сходиться, возникает проблема деградации: с увеличением глубины сети точность достигает насыщения (что может быть неудивительно), а затем быстро ухудшается.Такое ухудшение не вызвано переобучением или добавлением большего количества слоев в глубокую сеть, что приводит к более высокой ошибке обучения. Ухудшение точности обучения показывает, что не все системы легко оптимизировать.
Чтобы решить эту проблему, Microsoft представила структуру глубокого остаточного обучения. Вместо того, чтобы надеяться, что каждые несколько сложенных слоев напрямую соответствуют желаемому базовому отображению, они явно позволяют этим слоям соответствовать остаточному отображению. Формулировка F (x) + x может быть реализована с помощью нейронных сетей прямого распространения с быстрыми подключениями.Быстрые соединения — это соединения, пропускающие один или несколько слоев, показанных на рисунке 1. Быстрые соединения выполняют сопоставление идентичности, и их выходы добавляются к выходам сложенных слоев. Используя остаточную сеть, можно решить множество проблем, например:
Наборы данных
ImageNet — это набор данных из миллионов помеченных изображений с высоким разрешением, принадлежащих примерно к 22 тысячам категорий. Изображения были собраны из Интернета и помечены людьми с помощью инструмента краудсорсинга.Начиная с 2010 года, в рамках конкурса Pascal Visual Object Challenge проводится ежегодный конкурс ImageNet Large-Scale Visual Recognition Challenge (ILSVRC2013). ILSVRC использует подмножество ImageNet с примерно 1000 изображений в каждой из 1000 категорий. Существует приблизительно 1,2 миллиона обучающих изображений, 50 тысяч проверочных и 150 тысяч тестовых изображений.
PASCAL VOC предоставляет стандартизированные наборы данных изображений для распознавания классов объектов. Он также предоставляет стандартный набор инструментов для доступа к наборам данных и аннотациям, позволяет оценивать и сравнивать различные методы и запускать задачи по оценке производительности при распознавании классов объектов.
Архитектура
Рисунок 2. Пример сетевой архитектуры для ImageNet. Слева: модель VGG-19 (19,6 млрд FLOP) в качестве эталона. В центре: простая сеть из 34 уровней (3,6 миллиарда FLOP). Справа: ResNet с 34 слоями (3,6 миллиарда FLOP). Пунктирные ярлыки увеличивают размеры.Обычная сеть: Простые базовые линии (Рис. 2, в центре) в основном вдохновлены философией сетей VGG (Рис. 2, слева). Сверточные слои в основном имеют фильтры 3 × 3 и подчиняются двум простым правилам:
- Для одной и той же выходной карты объектов слои имеют одинаковое количество фильтров;
- Если размер карты объектов уменьшается вдвое, количество фильтров удваивается, чтобы сохранить временную сложность каждого слоя.
Стоит отметить, что модель ResNet имеет меньше фильтров и меньшую сложность, чем сети VGG.
Остаточная сеть: На основе вышеупомянутой простой сети вставляется быстрое соединение (рис. 2, справа), которое превращает сеть в аналогичную остаточную версию. Ярлыки идентичности F (x {W} + x) могут использоваться напрямую, когда вход и выход имеют одинаковые размеры (ярлыки сплошной линией на рис. 2). При увеличении размеров (обозначения пунктирной линией на рис.2) рассматривает два варианта:
- Ярлык выполняет отображение идентичности с добавлением дополнительных нулевых записей для увеличения размеров. Эта опция не вводит никаких дополнительных параметров.
- Ярлык проекции в F (x {W} + x) используется для сопоставления размеров (выполняется свертками 1 × 1).
Для любого из вариантов, если ярлыки проходят через карты функций двух размеров, они выполняются с шагом 2.
Каждый блок ResNet имеет либо двухуровневую глубину (используется в небольших сетях, таких как ResNet 18, 34), либо трехуровневую (ResNet 50, 101, 152).
50-слойный ResNet: Каждый 2-слойный блок заменяется в 34-слойной сети этим 3-слойным узким местом, в результате получается 50-слойная ResNet (см. Таблицу выше). Они используют вариант 2 для увеличения размеров. Эта модель имеет 3,8 миллиарда FLOP.
101-слойная и 152-слойная ResNets: они создают 101-слойную и 152-слойную ResNets, используя больше трехслойных блоков (таблица выше). Даже после увеличения глубины 152-слойная сеть ResNet (11,3 миллиарда FLOP) имеет меньшую сложность, чем сети VGG-16/19 (15.3 / 19,6 млрд. FLOP)
Реализация
Размер изображения изменяется, его более короткая сторона выбирается случайным образом в [256 480] для увеличения масштаба. Кадрирование размером 224 × 224 выбирается случайным образом из изображения или его горизонтального отражения с вычитанием среднего попиксельного значения. Скорость обучения начинается с 0,1 и делится на 10, когда плато ошибок и модели обучаются до 60 × 10000 итераций. Они используют убывание веса 0,0001 и импульс 0,9.
[Pytorch] [Tensorflow] [Keras]
Результат
18-уровневая сеть — это всего лишь подпространство в 34-уровневой сети, и она по-прежнему работает лучше.ResNet превосходит со значительным отрывом, если сеть более глубокая.
Рисунок 3. Обучение в ImageNet. Тонкие кривые обозначают ошибку обучения, жирные кривые обозначают ошибку проверки центральных культур. Слева: простые сети из 18 и 34 слоев. Справа: ResNets 18 и 34 слоев. На этом графике остаточные сети не имеют дополнительных параметров по сравнению с их обычными аналогами.Сеть
ResNet сходится быстрее, чем ее обычный аналог. Рисунок 4 показывает, что более глубокая сеть ResNet обеспечивает лучший результат обучения по сравнению с мелкой сетью.
Рисунок: 4. ResNet-34 достиг первой пятерки ошибок валидации на 5,71% лучше, чем BN-inception и VGG.ResNet-152 достигает первой пятерки ошибок валидации 4,49%. Комбинация из 6 моделей с разной глубиной дает ошибку валидации в топ-5 в 3,57%. 1 место на ILSVRC-2015
Рисунок 4: Частота ошибок (%) результатов одной модели в наборе валидации ImageNet (за исключением данных, указанных в наборе тестов) Обнаружение и классификация объектовс использованием R-CNN — Telesens
В этом посте я подробно опишу, как работает R-CNN (Regions with CNN features), недавно представленный метод обнаружения и классификации объектов на основе глубокого обучения.Системы R-CNN доказали свою высокую эффективность в обнаружении и классификации объектов на естественных изображениях, достигая гораздо более высоких показателей MAP, чем предыдущие методы. Метод R-CNN описан в следующей серии статей Росс Гиршик и др.
- R-CNN (https://arxiv.org/abs/1311.2524)
- Fast R-CNN (https://arxiv.org/abs/1504.08083)
- Более быстрый R-CNN (https://arxiv.org/abs/1506.01497)
В этом посте описывается окончательная версия метода R-CNN, описанного в последней статье.Сначала я решил описать эволюцию метода от его первого введения до окончательной версии, однако это оказалось очень амбициозным мероприятием. Я остановился на подробном описании финальной версии.
К счастью, в Интернете доступно множество реализаций алгоритма R-CNN в TensorFlow, PyTorch и других библиотеках машинного обучения. Я использовал следующую реализацию:
https://github.com/ruotianluo/pytorch-faster-rcnn
Большая часть терминологии, используемой в этом посте (например, названия различных уровней), следует терминологии, используемой в коде.Понимание информации, представленной в этом посте, должно значительно упростить отслеживание реализации PyTorch и внесение ваших собственных изменений.
Почтовая организация
- Раздел 1 — Предварительная обработка изображения: В этом разделе мы опишем шаги предварительной обработки, которые применяются к входному изображению. Эти шаги включают вычитание среднего значения пикселя и масштабирование изображения. Шаги предварительной обработки должны быть идентичны между обучением и логическим выводом
- Раздел 2 — Организация сети: В этом разделе мы опишем три основных компонента сети — «головную» сеть, сеть региональных предложений (RPN) и классификационную сеть.
- Раздел 3 — Детали реализации (обучение): Это самый длинный раздел сообщения, в котором подробно описаны этапы обучения сети R-CNN
- Раздел 4 — Детали реализации (вывод): В этом разделе мы опишем шаги, выполняемые во время вывода, т. Е. Использование обученной сети R-CNN для определения перспективных регионов и классификации объектов в этих регионах.
- Приложение: Здесь мы рассмотрим детали некоторых из часто используемых алгоритмов во время работы R-CNN, таких как непревышенное подавление, и детали архитектуры Resnet 50.
Предварительная обработка изображений
Следующие шаги предварительной обработки применяются к изображению перед его отправкой по сети. Эти шаги должны быть идентичны как для обучения, так и для вывода. Вектор среднего (одно число, соответствующее каждому цветовому каналу) — это не среднее значение значений пикселей в текущем изображении, а значение конфигурации, которое идентично для всех обучающих и тестовых изображений.
Значения по умолчанию для параметров и — 600 и 1000 соответственно.
Сетевая организация
R-CNN использует нейронные сети для решения двух основных задач:
- Определите перспективные области (область интереса — область интереса) на входном изображении, которые могут содержать объекты переднего плана
- Вычислить распределение вероятностей классов объектов для каждой области интереса, т. Е. Вычислить вероятность того, что область интереса содержит объект определенного класса. Затем пользователь может выбрать класс объекта с наибольшей вероятностью в качестве результата классификации.
R-CNN состоят из трех основных типов сетей:
- Головка
- Региональная сеть предложений (RPN)
- Классификационная сеть
R-CNN используют первые несколько уровней предварительно обученной сети, такой как ResNet 50, для определения перспективных функций из входного изображения. Использование сети, обученной на одном наборе данных по другой проблеме, возможно, поскольку нейронные сети демонстрируют «трансферное обучение» (https://arxiv.org/abs/1411.1792). Первые несколько уровней сети учатся обнаруживать общие особенности, такие как края и цветные пятна, которые являются хорошими отличительными признаками для множества различных проблем.Функции, изученные на более поздних уровнях, являются более высокоуровневыми, более специфичными для проблемы функциями. Эти слои могут быть удалены или веса этих слоев могут быть точно настроены во время обратного распространения. Первые несколько уровней, которые инициализируются из предварительно обученной сети, составляют «головную» сеть. Сверточные карты характеристик, созданные головной сетью, затем проходят через сеть предложений региона (RPN), которая использует серию сверточных и полностью связанных слоев для создания многообещающих областей интереса, которые, вероятно, будут содержать объект переднего плана (проблема 1, упомянутая выше).Эти многообещающие ROI затем используются для вырезания соответствующих регионов из карт функций, созданных головной сетью. Это называется «объединение урожая». Затем регионы, полученные в результате объединения культур, проходят через классификационную сеть, которая учится классифицировать объект, содержащийся в каждом ROI.
Кстати, вы можете заметить, что веса для ResNet инициализируются любопытным образом:
Классификация сетей
Сеть позволяет двум или более компьютерным системам обмениваться информацией и совместно использовать ресурсы и периферийные устройства.Сети классифицируются по географическому региону. Их можно разделить на PAN (персональные сети), которые обычно включают портативный компьютер, мобильный телефон и КПК; ЛВС обычно размещаются в одном здании; MAN (городские сети), которые охватывают кампус или город; WAN (глобальные сети), которые не имеют географических ограничений и могут соединять компьютеры или локальные сети на противоположных сторонах мира. Обычно они связаны телефонными линиями, волоконно-оптическими кабелями или спутниками. Основные пути передачи в глобальной сети — это высокоскоростные линии, называемые магистралями.Беспроводные глобальные сети используют сети мобильной телефонной связи. Самая крупная из существующих глобальных сетей — это Интернет.
ЛВСмогут быть построены с двумя основными типами архитектуры: одноранговая, где два компьютера имеют одинаковые возможности, или клиент-сервер, где один компьютер действует как сервер, содержащий основной жесткий диск и управляющий другими рабочими станциями или узлы, все устройства, подключенные к сети (например, принтеры, компьютеры и т. д.). Компьютеры в локальной сети должны использовать один и тот же сетевой протокол (язык или набор правил) для связи друг с другом.Сети используют разные протоколы. Например, Интернет использует TCP / IP. Ethernet — один из наиболее распространенных протоколов для локальных сетей.
Маршрутизатор, устройство, которое пересылает пакеты данных, необходим для подключения локальной сети к другой сети, например в Сеть. Большинство сетей связаны с помощью кабелей или проводов, но новые технологии Wi-Fi, обеспечивающие точность беспроводной связи, позволяют создавать WLAN, в которых кабели или провода заменяются радиоволнами. Для построения WLAN вам потребуются точки доступа, радиоприемники-передатчики, подключенные к проводной LAN, и беспроводные адаптеры, установленные на вашем компьютере, чтобы связать его с сетью.
Точки доступа— это сети WLAN, доступные для публичного использования в таких местах, как аэропорты и отели, но иногда услуга также доступна на открытом воздухе (например, университетские городки, площади и т. Д.).
1. ЛВС соединяют компьютеры и другие устройства, расположенные далеко друг от друга.
2. В архитектуре клиент-сервер все рабочие станции имеют одинаковые возможности.
3. Слово протокол относится к форме сети.
4. Маршрутизаторы используются для соединения двух компьютеров.
5. Точки доступа не нужно подключать к проводной локальной сети.
6. Беспроводные адаптеры не являются обязательными при использовании WLAN.
7. Горячие точки можно найти только внутри здания.
8. Интернет — это пример локальной сети.
9. В беспроводных глобальных сетях в качестве устройств связи используются оптоволокно и кабель.
Пр. 2. Используйте слова в рамке, чтобы завершить предложения .
| LAN Узлы WLAN сервер магистральных сетей однорангового концентратора |
1.Все ПК подключены к одному — мощному ПК с большим жестким диском, доступным для всех. 2. Стиль сети позволяет каждому пользователю совместно использовать такие ресурсы, как принтеры. 3. Звезда — это топология компьютерной сети, в которой один компьютер занимает центральную часть, а остальные подключены исключительно к нему. 4. В настоящее время системы Wi-Fi передают данные со скоростью, более чем в 100 раз превышающей скорость модема коммутируемого доступа, что делает их идеальной технологией для соединения компьютеров друг с другом и с сетью в a.5. Все оптоволоконные кабели США, Канады и Латинской Америки пересекают Панаму. 6. А. объединяет несколько компьютеров (или других сетевых устройств) в единый сегмент сети, где все компьютеры могут напрямую связываться друг с другом.
Пр. 3. Прочтите эти описания различных физических топологий сетей связи .
Классификация намерений последовательностей с использованием иерархических сетей внимания
Ольга
Введение
В этой истории кода мы обсудим применения иерархических нейронных сетей внимания для классификации последовательностей.В частности, мы будем использовать нашу работу в области обнаружения и классификации вредоносных программ в качестве примера приложения. Вредоносное ПО или вредоносное ПО. — это вредоносные компьютерные программы, такие как вирусы, программы-вымогатели, шпионское ПО, рекламное ПО и другие, которые обычно устанавливаются и запускаются непреднамеренно. При обнаружении вредоносного ПО в работающем процессе типичной последовательностью для анализа может быть набор действий по доступу к диску, предпринятых программой. Чтобы анализировать программное обеспечение без его запуска, мы можем рассматривать серию инструкций по сборке в дизассемблированном двоичном файле как последовательности, которые необходимо классифицировать, чтобы идентифицировать участки кода со злым умыслом.В нашем новом подходе мы применяем методы, обычно используемые для обнаружения структуры в повествовательном тексте, к данным, которые описывают поведение исполняемых файлов.
Иерархические сети внимания (HAN) успешно использовались в области классификации документов (Ян и др., 2016, PDF). Этот подход потенциально применим к другим вариантам использования, которые включают последовательные данные, таким как анализ журналов приложений (обнаружение определенных моделей поведения), анализ сетевых журналов (обнаружение атак), классификация потоков, событий и т. Д.Мы продемонстрируем применение HAN для обнаружения вредоносных программ как статически (исполняемый двоичный анализ), так и динамически (анализ поведения процессов). Вспомогательный код использует Keras с Microsoft Cognitive Toolkit (CNTK) в качестве серверной части для обучения модели.
Эта работа была вдохновлена нашим сотрудничеством с Acronis и услугами, которые они предоставляют для обеспечения безопасности данных резервного копирования.
Данные
Мы будем использовать два общедоступных набора данных, чтобы проиллюстрировать наш подход и результаты.
Первый, CSDMC 2010 API, представляет собой корпус последовательностей, который также использовался в соревновании по интеллектуальному анализу данных, связанному с ICONIP 2010. Этот набор данных содержит вызовы Windows API от вредоносных программ и безопасного программного обеспечения.
Для простоты набор данных CSDMC 2010 содержит только имена Windows API, вызываемых запущенным процессом. Набор содержит метки классов для каждой последовательности, соответствующей полному экземпляру запущенного процесса. Однако мы рассмотрим эффективность классификации как для последовательностей вызовов API, так и для всей трассировки / процесса.
Microsoft Malware Classification Challenge в наборе данных WWW 2015 / BIG 2015. Он содержит набор манифестов метаданных 9 классов вредоносных программ. Манифесты метаданных были созданы с помощью инструмента дизассемблера IDA. Это файлы журналов, содержащие информацию, извлеченную из двоичного файла, такую как последовательность инструкций сборки для вызовов функций, объявления строк, адреса памяти, имена регистров и т. Д.
Для демонстрационных целей (и сохранения времени обучения до минут на NVIDIA GeForce GTX 1060 ) мы использовали сотни примеров вредоносных программ только для классов 1 и 2.Полный размер набора данных составляет 0,5 ТБ. Однако пример кода, представленный в этой записной книжке Jupyter, поддерживает несколько классов. Дампы дизассемблированных двоичных исполняемых файлов в наборе данных Microsoft Malware Classification состоят из последовательностей операций и операндов разной длины, по одной операции на строку. Мы будем анализировать контент как последовательности кортежей фиксированной длины, учитывая только количество полей, извлеченных из каждой строки в каждом эксперименте. Например, кортежи одного поля будут содержать только код операции, кортежи двух полей будут содержать код операции и первый операнд и т. Д.Производительность классификации будет рассматриваться как для каждой последовательности, так и для всего исполняемого файла.
Что такое нейронная сеть с иерархическим вниманием?
Ян, Зичао и др. предложила HAN для классификации документов, представленная на NAACL 2016. Решение использует иерархическую структуру документа, от слов до предложений и документов, отраженную в многоуровневой рекуррентной нейронной сети со специальными уровнями внимания, применяемыми на уровне слова и предложения . Архитектура HAN показана на рисунке ниже.Общий процесс подробно описан в этом сообщении в блоге.
Наша цель — применить подход, основанный на обработке естественного языка (NLP), к другому домену, используя последовательный характер их данных: например, классифицируя динамическое поведение процесса (последовательность вызовов API) или классифицируя двоичные файлы вредоносных программ (последовательность инструкции по сборке).
Принимая во внимание сценарий динамического анализа процесса, цель которого состоит в обнаружении вредоносных программ в запущенном процессе, решение на основе HAN будет использовать многоуровневую память для понимания последовательности наблюдаемых действий процесса.Классифицирующие шаблоны поведения процесса можно тогда рассматривать как классифицирующие документы. Здесь последовательность действий процесса аналогична последовательности слов в тексте, а группы действий аналогичны предложениям.
Пошаговое руководство по коду
Код HAN, который мы предоставляем в этой записной книжке Jupyter, основан на реализации LSTM HAN, найденной в этом репозитории GitHub Андреасом Аргириу, который, в свою очередь, был основан на реализации Ричардом Ляо иерархических сетей внимания и связанной с ним Google групповое обсуждение.В записную книжку также включен код из документации и блога Keras, а также из этого руководства по word2vec.
Наш код расширяет базовую записную книжку для поддержки случайной и стратифицированной выборки по процессам, понижающей / повышающей выборки классов (только для бинарных классов), настройки гиперпараметров обучения, показателей оценки для каждой последовательности и процесса, настраиваемых кортежей и размеры словаря, расширенный прием данных, настраиваемая среда обучения и другие модификации для поддержки наших экспериментов.
Важные примечания
- Формат данных: Код требует, чтобы «слова» в ваших последовательностях разделялись пробелами (табуляция, пробелы).
- Предварительная обработка: если ваш исходный источник данных (файл журнала / трассировки, дизассемблированный код) имеет огромный словарный запас, рассмотрите возможность нормализации во время предварительной обработки и / или ограничения длины кортежа и размера словаря по частоте во время обучения. Огромный «обычно» означает более 5-20К. Остерегайтесь вещей, которые могут «взорвать» ваш словарный запас: GUID, шестнадцатеричные адреса, имена временных файлов, IP-адреса.
- Количество слов в предложении и количество предложений в документе настраиваются в коде.
- Предполагается, что ввод использует токен «
» в качестве разделителя последовательности конца ввода. Каждый ввод будет далее разбит на последовательности (документы), состоящие из нескольких предложений, в качестве единицы классификации в обучающем коде HAN. Важно указать последнюю последовательность для данного входа, чтобы избежать смешивания содержимого из разных входов.Группы (подпоследовательности) действий рассматриваются как предложения. - Вложения слов можно инициализировать с помощью предварительно обученных векторов или оставить неинициализированными. Такое поведение определяется параметром USE_WORD2VEC.
- Другие настраиваемые параметры определяют различные параметры, такие как размеры сети, гиперпараметры обучения, параметры выборки данных и другие параметры среды обучения.
- Фреймворк глубокого обучения: мы используем Keras с бэкэндом CNTK с поддержкой графического процессора.
Ниже приводится общий обзор основных частей кода.Дополнительные сведения см. В документации к записной книжке Jupyter, доступной здесь.
- Сконфигурируйте тренировочную среду, задав глобальные параметры. К ним относятся: — MAX_SENT_LEN: количество слов в каждом предложении (слово в любом токене, появляющемся в кортеже действия процесса). — MAX_SENTS: количество предложений в каждом документе. — MAX_NB_WORDS: размер кодировки слова (количество наиболее часто встречающихся слов, которые нужно сохранить в словаре). — MIN_FREQ: минимальная частота токенов для включения в словарь.Окончательный размер словаря — это эффективный минимальный размер с учетом словаря токенов, параметров MAX_NB_WORDS и MIN_FREQ. — Стратегия обучения и тестирования: рандомизированная или стратифицированная по процессам. — USE_WORD2VEC: инициализировать сеть, используя предварительно обученные веса внедрения word2vec.
