Как работать с топиками в Kafka. Как настроить продюсеров и консьюмеров. Как управлять брокерами и кластером Kafka. Основные команды для мониторинга и диагностики проблем в Kafka.
Основные команды для работы с топиками в Apache Kafka
Apache Kafka — это распределенная система обмена сообщениями и потоковой передачи данных. Для эффективного управления Kafka необходимо знать основные команды для работы с топиками. Вот некоторые из наиболее важных:
Создание нового топика
Чтобы создать новый топик в Kafka, используйте следующую команду:
kafka-topics.sh --create --bootstrap-server localhost:9092 --replication-factor 1 --partitions 1 --topic my_topicЗдесь мы создаем топик с именем «my_topic», 1 разделом и коэффициентом репликации 1. Как правильно выбрать количество разделов и коэффициент репликации для топика.
Просмотр списка топиков
Чтобы увидеть список всех топиков в кластере Kafka, выполните:
kafka-topics.sh --list --bootstrap-server localhost:9092Получение детальной информации о топике
Для просмотра подробной информации о конкретном топике используйте команду:
kafka-topics.sh --describe --bootstrap-server localhost:9092 --topic my_topicЭта команда покажет количество разделов, коэффициент репликации, расположение лидеров разделов и другие важные параметры топика.
Настройка продюсеров и консьюмеров в Kafka
Продюсеры и консьюмеры — ключевые компоненты для работы с данными в Kafka. Рассмотрим основные команды для их настройки и использования.
Запуск консольного продюсера
Чтобы отправить сообщения в топик с помощью консольного продюсера, выполните:
kafka-console-producer.sh --broker-list localhost:9092 --topic my_topicПосле запуска вводите сообщения, каждое с новой строки. Как оптимизировать настройки продюсера для повышения производительности.
Запуск консольного консьюмера
Для чтения сообщений из топика используйте консольный консьюмер:
kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic my_topic --from-beginningОпция —from-beginning указывает читать сообщения с начала топика. Без нее будут читаться только новые сообщения.
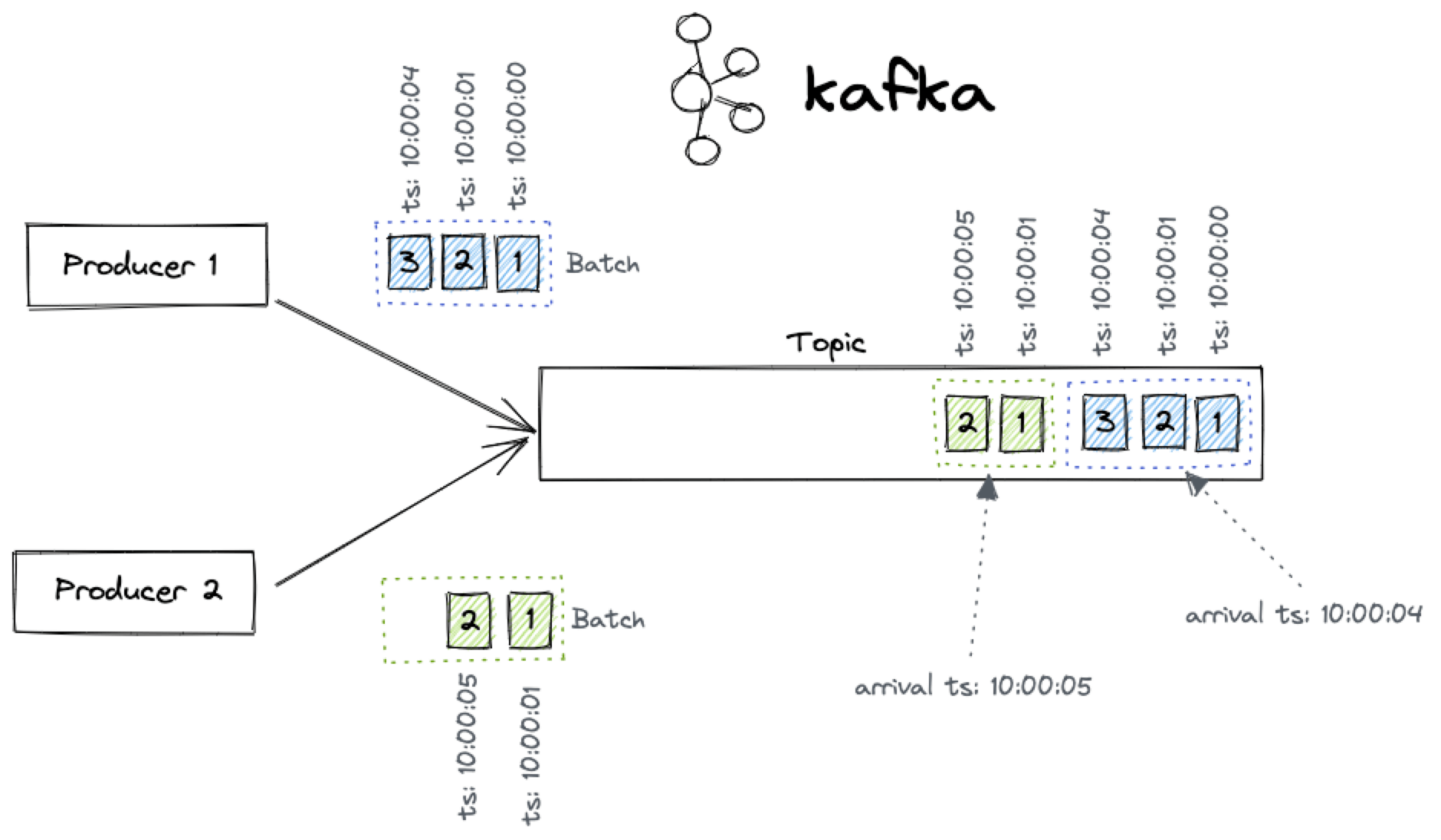
Управление брокерами и кластером Kafka
Эффективное управление брокерами и кластером Kafka критически важно для обеспечения надежности и производительности системы. Рассмотрим основные команды для этих задач.
Просмотр информации о брокерах
Чтобы получить информацию о брокерах в кластере, используйте команду:
kafka-broker-api-versions.sh --bootstrap-server localhost:9092Эта команда покажет список всех брокеров, их идентификаторы и поддерживаемые версии API.
Изменение конфигурации брокера
Для изменения конфигурации брокера в runtime используйте:
kafka-configs.sh --bootstrap-server localhost:9092 --entity-type brokers --entity-name 0 --alter --add-config max.connections=10000
Здесь мы увеличиваем максимальное количество соединений для брокера с ID 0. Какие параметры брокера наиболее критичны для производительности.
Мониторинг и диагностика проблем в Kafka
Мониторинг и своевременная диагностика проблем — ключевые аспекты поддержки Kafka-кластера. Рассмотрим основные инструменты для этих задач.
Проверка состояния потребительской группы
Чтобы проверить состояние потребительской группы, выполните:
kafka-consumer-groups.sh --bootstrap-server localhost:9092 --describe --group my-groupЭта команда покажет информацию о смещениях, отставании и активных членах группы.
Просмотр метрик JMX
Для просмотра метрик JMX брокера используйте инструмент JConsole или jmxterm. Например, чтобы посмотреть количество сообщений в секунду:
jmxterm -l localhost:9999
get -b kafka.server:type=BrokerTopicMetrics,name=MessagesInPerSec -a OneMinuteRate
Какие метрики JMX наиболее важны для мониторинга здоровья кластера Kafka.
Оптимизация производительности Kafka
Оптимизация производительности Kafka — важная задача для обеспечения эффективной работы системы. Рассмотрим несколько ключевых аспектов оптимизации.
Настройка параметров производительности
Для оптимизации производительности Kafka важно правильно настроить следующие параметры:
- num.network.threads и num.io.threads для брокеров
- batch.size и linger.ms для продюсеров
- fetch.min.bytes и fetch.max.wait.ms для консьюмеров
Как подобрать оптимальные значения этих параметров для конкретной нагрузки.

Мониторинг задержек
Для мониторинга задержек в Kafka используйте инструмент kafka-producer-perf-test.sh:
kafka-producer-perf-test.sh --topic test-topic --num-records 1000000 --record-size 1000 --throughput 100000 --producer-props bootstrap.servers=localhost:9092
Эта команда проведет тест производительности, отправив 1 миллион сообщений размером 1KB с максимальной пропускной способностью 100000 сообщений в секунду.
Обеспечение безопасности в Kafka
Безопасность — критически важный аспект при работе с Kafka, особенно в производственной среде. Рассмотрим основные механизмы обеспечения безопасности.
Настройка SSL/TLS шифрования
Для настройки SSL/TLS шифрования в Kafka необходимо:
- Создать сертификаты и ключи
- Настроить SSL параметры в server.properties брокеров
- Настроить SSL параметры для клиентов
Пример настройки SSL для брокера:
ssl.keystore.location=/path/to/kafka.server.keystore.jks
ssl.keystore.password=test1234
ssl.key.password=test1234
ssl.truststore.location=/path/to/kafka.server.truststore.jks
ssl.truststore.password=test1234
security.inter.broker.protocol=SSL
ssl.client.auth=required
Настройка SASL аутентификации
Для настройки SASL аутентификации в Kafka:
- Выберите механизм SASL (PLAIN, SCRAM, GSSAPI)
- Настройте SASL параметры в server.properties брокеров
- Настройте SASL параметры для клиентов
Пример настройки SASL PLAIN для брокера:
security.inter.broker.protocol=SASL_PLAINTEXT
sasl.mechanism.inter.broker.protocol=PLAIN
sasl.enabled.mechanisms=PLAINКак выбрать оптимальный механизм аутентификации для конкретного сценария использования Kafka.
Резервное копирование и восстановление данных в Kafka
Регулярное резервное копирование и возможность быстрого восстановления данных критически важны для обеспечения надежности Kafka-кластера. Рассмотрим основные подходы к этим задачам.
Создание резервных копий
Для создания резервных копий данных в Kafka можно использовать следующие методы:
- Копирование лог-файлов топиков
- Использование инструмента MirrorMaker для репликации данных в другой кластер
- Применение Kafka Connect для экспорта данных во внешнее хранилище
Пример использования MirrorMaker для создания резервной копии:
kafka-mirror-maker.sh
--consumer.config consumer.properties
--producer.config producer.properties
--whitelist ".*"Восстановление данных
Для восстановления данных в Kafka можно:
- Восстановить лог-файлы топиков из резервной копии
- Использовать MirrorMaker для репликации данных из резервного кластера
- Применить Kafka Connect для импорта данных из внешнего хранилища
Какой метод резервного копирования и восстановления выбрать в зависимости от объема данных и требований к времени восстановления.
Работа с Kafka в Unix/Linux
Хотелось бы сделать себе заметку (что-то типа cheat-sheet) с командами для работе с Kafka. Сейчас я приведу готовые примеры использования команд на готовых примера можно будет увидеть работу самой кафки.
Установка Kafka скриптов в Unix/Linux
Чтобы использовать скрипты для работы с Кафка, выполним небольшую установку:
$ KAFKA_VERSION=2.12-2.2.1 && \
wget -q -O - https://www-us.apache.org/dist/kafka/2.2.1/kafka_${KAFKA_VERSION}.tgz | (cd /opt; tar -zxvf -) && cd /opt/kafka_${KAFKA_VERSION}Для простоты использования, можно добавить PATH (в ~/.bashrc):
export KAFKA_VERSION=2.12-2.2.1
export KAFKA_HEAP_OPTS="-Xmx1g -Xms1g -XX:MetaspaceSize=96m -XX:+UseG1GC -XX:MaxGCPauseMillis=20 -XX:InitiatingHeapOccupancyPercent=35 -XX:G1HeapRegionSize=16M -XX:MinMetaspaceFreeRatio=50 -XX:MaxMetaspaceFreeRatio=80"
export PATH="$PATH:/opt/kafka_${KAFKA_VERSION}/bin"После этого, стоит обновить файл:
$ . ~/.bashrcИли:
$ source ~/.bashrcПолезное чтиво:
Установка Kafka в Unix/Linux
Перейдем к работе!
Работа с Kafka в Unix/Linux
Вывести список топиков:
$ kafka-topics.sh --list \
--zookeeper zookeeper_host:zookeeper_host_portГде:
- zookeeper_host — Хост зукипера, например, — это может быть localhost, 192.168.13.113 и так далее.
- zookeeper_host_port — Порт зукипера, например по умолчанию — это 2181-й порт.
Так же, можно использовать:
$ kafka-topics.sh --list \
--zookeeper $(cat ZooKeeperList.txt)Где:
- ZooKeeperList.txt — это список хостов самого зукипера (zookeeper:port).
Получить информацию о топике:
$ kafka-topics.sh --describe \
--zookeeper zookeeper_host:zookeeper_host_port \
--topic test_topic
Где:
- zookeeper_host — Хост зукипера, например, — это может быть localhost, 192.168.13.113 и так далее.
- zookeeper_host_port — Порт зукипера, например по умолчанию — это 2181-й порт.
Создание топика:
$ kafka-topics.sh --create \
--zookeeper $(cat ZooKeeperList.txt) \
--topic test_topic \
--replication-factor 2 \
--partitions 3Вот небольшой скрипт для создания топиков:
ENV=nonprod # 1: A name for the topic # 2: A replication factor # 3: A partition KAFKA_TOPIC_LIST=( "MyKafkaTopic:3:1" "MyKafkaTopic2:3:1" ) for topic in "${KAFKA_TOPIC_LIST[@]}" ; do a_topic=$(echo "$topic"| cut -d ":" -f1) a_replication_factor=$(echo "$topic"| cut -d ":" -f2) a_partition=$(echo "$topic"| cut -d ":" -f3) kafka-topics.sh --create \ --zookeeper $(cat /opt/kafka_2.12-2.2.1/mskkafkatest-${ENV}_ZooKeeperList.txt) \ --topic $a_topic \ --replication-factor $a_replication_factor \ --partitions $a_partition done;
Записать в топик меседжы:
$ kafka-console-producer.sh \
--broker-list $(cat BrokersList.txt) \
--producer.config producer.properties \
--topic topic_name_hereПрочитать с топика меседжы:
$ kafka-console-consumer.sh \
--bootstrap-server $(cat BrokersList.txt) \
--consumer.config producer.properties \
--topic topic_name_here \
--from-beginningУдалить топик:
$ kafka-topics.sh --delete \
--zookeeper zookeeper_host:zookeeper_host_port \
--topic test_topicГде:
- zookeeper_host — Хост зукипера, например, — это может быть localhost, 192.168.13.113 и так далее.
- zookeeper_host_port — Порт зукипера, например по умолчанию — это 2181-й порт.
Так, написал небольшой скрипт для удаление:
#--------------
# Delete topics
#--------------
ENV=nonprod
KAFKA_TOPIC_LIST=(
"MyKafkaTopic2"
"test"
"test2"
)
for topic in "${KAFKA_TOPIC_LIST[@]}" ; do
echo "Deleting ${topic} ....."
kafka-topics.sh --delete \
--zookeeper $(cat ZooKeeperList.txt) \
-topic $topic
done;Добавить партицию:
$ kafka-topics.sh --alter \
--zookeeper zookeeper_host:zookeeper_host_port \
--topic test_topic \
--partitions 3Где:
- zookeeper_host — Хост зукипера, например, — это может быть localhost, 192.168.13.113 и так далее.
- zookeeper_host_port — Порт зукипера, например по умолчанию — это 2181-й порт.
Посмотреть конфиг для топика:
$ kafka-configs.sh --describe \
--zookeeper zookeeper_host:zookeeper_host_port \
--entity-type topics \
--entity-name test_topicГде:
- zookeeper_host — Хост зукипера, например, — это может быть localhost, 192.168.13.113 и так далее.
- zookeeper_host_port — Порт зукипера, например по умолчанию — это 2181-й порт.
Установить время хранения (не рекомендуется) записей в топике:
$ kafka-topics.sh --alter \
--zookeeper zookeeper_host:zookeeper_host_port \
--topic test_topic \
--config retention.ms=1000Где:
- zookeeper_host — Хост зукипера, например, — это может быть localhost, 192.168.13.113 и так далее.
- zookeeper_host_port — Порт зукипера, например по умолчанию — это 2181-й порт.
Установить время хранения (современный способ) записей в топике:
$ kafka-configs.sh --alter \
--zookeeper zookeeper_host:zookeeper_host_port \
--entity-type topics \
--entity-name test_topic \
--add-config retention.ms=1000Где:
- zookeeper_host — Хост зукипера, например, — это может быть localhost, 192.168.13.113 и так далее.
- zookeeper_host_port — Порт зукипера, например по умолчанию — это 2181-й порт.
Если вам нужно удалить все сообщения в теме, вы можете использовать данную проперти и задать время хранения. Сначала установите время хранения на очень низкое значение (1000 мс), подождите несколько секунд, а затем верните время хранения обратно к предыдущему значению.
Примечание: Время хранения по умолчанию составляет 24 часа (86400000 миллисекунд).
Можно вернуть все как и было:
$ kafka-topics.sh --alter \
--zookeeper zookeeper_host:zookeeper_host_port \
--topic mytopic \
--delete-config retention.msПоказать список сообщений для конкретного топика:
$ kafka-console-consumer.sh \
--zookeeper zookeeper_host:zookeeper_host_port \
--topic test_topic \
--from-beginningГде:
- zookeeper_host — Хост зукипера, например, — это может быть localhost, 192.168.13.113 и так далее.
- zookeeper_host_port — Порт зукипера, например по умолчанию — это 2181-й порт.
Или:
$ kafka-console-consumer.sh \
--bootstrap-server $(cat BrokersList.txt) \
--consumer.config producer.properties \
--topic jive_invoices_staging \
--from-beginningЧтобы просмотреть offset позиции для consumer группы (для каждой из партиций):
$ kafka-consumer-offset-checker.sh \
--zookeeper zookeeper_host:zookeeper_host_port \
--group group_ID_here \
--topic your_topic_hereГде:
- zookeeper_host — Хост зукипера, например, — это может быть localhost, 192.168.13.113 и так далее.
- zookeeper_host_port — Порт зукипера, например по умолчанию — это 2181-й порт.
Чтобы начать заново (сбросьте смещение на 0):
$ kafka-streams-application-reset.sh \
--input-topics your_topic_here \
--application-id group_ID_here \
--bootstrap-servers bootstrap_host:bootstrap_portГде:
- your_topic_here — Топик.
- group_ID_here — ИД группы.
- bootstrap_host — Хост.
- bootstrap_port — Порт.
Получить самое раннее смещение в топике:
$ kafka-run-class.sh kafka.tools.GetOffsetShell \
--broker-list localhost:9092 \
--topic mytopic \
--time -2Получить последнее смещение еще в топике:
$ kafka-run-class.sh kafka.tools.GetOffsetShell \
--broker-list localhost:9092 \
--topic mytopic \
--time -1Получить потребительские смещения (consumer offsets) для топика:
$ kafka-consumer-offset-checker.sh \
--zookeeper=zookeeper_host:zookeeper_host_port \
--topic=mytopic \
--group=my_consumer_groupГде:
- zookeeper_host — Хост зукипера, например, — это может быть localhost, 192.168.13.113 и так далее.
- zookeeper_host_port — Порт зукипера, например по умолчанию — это 2181-й порт.
Считать из __consumer_offsets:
$ kafka-console-consumer.sh \
--consumer.config config/consumer.properties \
--from-beginning \
--topic __consumer_offsets \
--zookeeper zookeeper_host:zookeeper_host_port \
--formatter "kafka.coordinator.GroupMetadataManager\$OffsetsMessageFormatter"Где:
- zookeeper_host — Хост зукипера, например, — это может быть localhost, 192.168.13.113 и так далее.
- zookeeper_host_port — Порт зукипера, например по умолчанию — это 2181-й порт.
Вывести список consumer групп:
$ kafka-consumer-groups.sh --list \
--zookeeper zookeeper_host:zookeeper_host_port Или:
kafka-consumer-groups.sh --list \
--new-consumer \
--bootstrap-server localhost:9092 Просмотр сведений о consumer группе:
$ kafka-consumer-groups.sh --describe \
--zookeeper zookeeper_host:zookeeper_host_port \
--group group_nameГде:
- zookeeper_host — Хост зукипера, например, — это может быть localhost, 192.168.13.113 и так далее.
- zookeeper_host_port — Порт зукипера, например по умолчанию — это 2181-й порт.
Посмотр сообщений в топике:
$ kafkacat -C -b localhost:9092 -t mytopic -p 0 -o -5 -eИли:
$ kafka-console-consumer.sh \
--bootstrap-server $(cat BrokersList.txt) \
--consumer.config producer.properties \
--topic test2 \
--from-beginningЧтобы записать в топик:
$ kafka-console-producer.sh \
--broker-list $(cat BrokersList.txt) \
--producer.config producer.properties \
--topic test2Запускаем Zookeeper shell:
$ zookeeper-shell.sh \
zookeeper_host:zookeeper_host_portПровести перформенс тесты:
$ kafka-producer-perf-test.sh \
--topic topic_here \
--num-records 1 \
--record-size 2048 \
--throughput -1 \
--producer.config producer.properties \
--producer-props \
acks=1 \
buffer.memory=67108864 \
compression.type=none \
batch.size=8196Вот и все, статья «Работа с Kafka в Unix/Linux» завершена.
Почему нельзя просто уйти от Zookeeper в Kafka 2.8.0: план миграции
Спустя пару месяцев с выпуска Apache Kafka 2.7.0, Confluent анонсировал новый релиз этой платформы потоковой передачи событий, в котором, наконец, случится долгожданный отказ от Zookeeper. Читайте далее, как это облегчит жизнь администратору Kafka-кластера и разработчику распределенных приложений потоковой аналитики больших данных, а также как подготовить свою Big Data инфраструктуру к таким изменениям.
13 плюсов KIP-500 для администратора и разработчика Big Data
Уже совсем скоро, в марте 2021 года, ожидается новый релиз Apache Kafka 2.8.0 [1], главной фишкой которого будет долгожданный KIP-500 (Kafka Improvement Proposal) по отказу от Zookeeper, как обязательной части Кафка-кластера. Напомним, до сих пор Kafka использует сервис синхронизации распределенных систем Apache ZooKeeper для хранения метаданных, таких как расположение разделов и конфигурация топиков. Вопрос ухода от Зукипер был поднят еще в 2019 году, о чем мы писали здесь.
Удаление Зукипер из Kafka значительно упростит администрирование, благодаря сокращению объема настраиваемых служб и возможности развернуть контроллер и брокер в одной JVM. Кроме того, администратору Big Data кластера больше не придется [2]:
- тратить время на изучение, конфигурирование, обновление и поддержку еще одной распределенной системы;
- определять количества серверов для ансамбля Зукипер, чтобы сбалансировать емкость чтения и записи;
- обеспечивать наличие отдельной конфигурации безопасности для Зукипер, которая отличается от остальной части Kafka-кластера;
- обеспечивать совместное использование ансамбля Зукипер между приложениями Kafka и сторонними сервисами;
- настраивать таймауты брокера на Зукипер через конфигурации connection.timeout.ms и zookeeper.session.timeout.ms;
- изменять конфигурации Зукипер при добавлении новой функциональной возможности, например, для явного разрешения отдельных команд;
- периодически перезапускать ансамбль Зукипер в рамках управления исправлениями и обновлениями;
- подбирать оптимальный размер дорогих SSD-дисков для каждого сервера ZooKeeper;
- настраивать политику для очистки старых данных Зукипер через purgeInterval и autopurge.snapRetainCount;
- обеспечивать совместное использование путей к каталогам для журнала транзакций ZooKeeper и каталогов моментальных снимков (snapshot’ов).
С точки зрения разработчика Kafka-приложений при отказе новый релиз этой Big Data платформы принесет следующие преимущества [2]:
- повышение скорости обработки данных за счет того, что брокеры будут хранить метаданные локально в журнале и считывать с контроллера только последний набор изменений, аналогично тому, как потребители Kafka могут читать самый конец журнала, а не весь журнал;
- отсутствие ограничений на число разделов кластера Kafka – теперь масштабирование будет действительно бесконечным;
- устранение причины потери сообщений в случае рассинхронизации Kafka и Зукипер из-за его перезапуска или сбоя.
Как отказаться от Zookeeper на практике: план перехода на Apache Kafka 2.8.0
Чтобы использовать все вышеназванные и другие преимущества отказа от Zookeeper в новом релизе Apache Kafka 2.8.0, необходимо подготовиться к переходу на новую версию. Для этого нужно внести следующие изменения, настроив [3]:
- клиенты, сервисы и инструменты администрирования Kafka, о чем мы поговорим далее;
- REST Proxy API – перейти с v1 на v2 или v3;
- получить ID Кафка-кластера, что пригодится администратору в случае мониторинга, аудита, агрегирования журналов и устранения неполадок. Ранее получить идентификатора кластера можно было из Зукипер с помощью команды zookeeper-shell: zookeeper-shell zookeeper:2181 get /cluster/id. Теперь для этого придется использовать файл журнала брокера или файл metadata.properties. При отсутствии доступа к журналам брокера, можно использовать функцию descriptionCluster() в AdminClient или инструменты администрирования Кафка с включенным ведением журнала на уровне TRACE.
Настройка клиентов, сервисов и инструментов администрирование
Здесь идет речь о клиентских приложениях (потребители и продюссеры), приложения Kafka Streams и ksqlDB, сервисы платформs Confluent (Kafka Connect, Confluent Replicator, Confluent REST Proxy, Confluent Schema Registry, Confluent Control Center или Confluent Metrics Reporter), команды CLI-интерфейса. Все они нуждаются в новой конфигурации, которая указывает, как подключиться к кластеру Кафка. В старых версиях Кафка это делалось через соединение ZooKeeper. В более новых версиях появилась возможность подключаться к брокерам вместо Зукипер. Поэтому в production-развертываниях следует проверить наличие старых клиентов или сервисов, которые настроенные для подключения к Зукипер: zookeeper.connect = zookeeper: 2181.
При переходе на Кафка 2.8.0 рекомендуется выполнить аудит всех клиентских приложений и служб, чтобы заменить вышеуказанную конфигурацию для подключения к брокерам Kafka вместо Зукипер: bootstrap.servers = брокер: 9092.
Также потребуется замена в реестре схем (Schema Registry: вместо конфигурации kafkastore.connection.url = zookeeper: 2181 нужно задать kafkastore.bootstrap.servers = broker: 9092.
Аналогично, в инструментах командной строки вместо аргумента –zookeeper с информацией о подключении Зукипер, например,
kafka-themes –zookeeper zookeeper: 2181 –create –topic test1 –partitions 1 –replication-factor 1,
будет
kafka-themes –bootstrap-server broker: 9092 –create –topic test1 –partitions 1 –replication-factor 1 –command-config
В случае защищенных кластеров с использованием SSL или SASL_SSL, инструменты администрирования требуют дополнительных настроек безопасности для подключения к брокерам, в частности, аргумент –command-config, чтобы указать на файл свойств соединения AdminClient.
Краткий перечень мероприятий по отказу от Зукипер показан далее в таблице.
| Действие | С ZooKeeper | Без ZooKeeper |
| Настройка клиентов и сервисов | zookeeper.connect=zookeeper:2181 | bootstrap.servers=broker:9092 |
| Конфигурирование Schema Registry | kafkastore.connection.url=zookeeper:2181 | kafkastore.bootstrap.servers=broker:9092 |
| Настройка инструментов администрирования | kafka-topics –zookeeper zookeeper:2181 … | kafka-topics –bootstrap-server broker:9092 … –command-config <properties to connect to brokers> |
| REST Proxy API | v1 | v2 or v3 |
| Получение идентификатора Кафка-кластера (Kafka cluster ID) | zookeeper-shell zookeeper:2181 get /cluster/id | kafka-metadata-quorum or view metadata.properties or confluent cluster describe –url http://broker:8090 –output json |
Дополнительно к вышеотмеченным подготовительным мероприятиям по отказу от Зукипер, при развертывании Apache Kafka 2.8.0 администратору кластера нужно сделать следующее [3]:
- проверить конфигурации и клиентские инструменты, чтобы определить все параметры и аргументы ZooKeeper;
- определить возможные зависимости Зукипер в порядке запуска сервиса. Например, при использовании Docker, следует проверить конфигурацию depends_on, чтобы увидеть, где контейнер ZooKeeper является необходимым условием.
- Найти косвенные зависимости ZooKeeper, такие как модули Runbook, которые используют Зукипер в качестве узла перехода для выполнения команд на другом узле.
Что еще нового вас ожидает в релизе Apache Kafka 2.8.0, читайте в нашей свежей статье.
Освойте администрирование кластера Apache Kafka и инструментарий этой платформы для разработки распределенных приложений потоковой аналитики больших данных на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
Источники
- https://cwiki.apache.org/confluence/pages/viewpage.action?pageId=173081737
- https://www.confluent.io/blog/42-ways-zookeeper-removal-improves-kafka/
- https://www.confluent.io/blog/how-to-prepare-for-kip-500-kafka-zookeeper-removal-guide/
Как перейти на Apache Kafka без Zookeeper: готовимся к KIP-500 в релизе 2.8.0 | by Nick Komissarenko
Спустя пару месяцев с выпуска Apache Kafka 2.7.0, Confluent анонсировал новый релиз этой платформы потоковой передачи событий, в котором, наконец, случится долгожданный отказ от Zookeeper. Читайте далее, как это облегчит жизнь администратору Kafka-кластера и разработчику распределенных приложений потоковой аналитики больших данных, а также как подготовить свою Big Data инфраструктуру к таким изменениям.
13 плюсов KIP-500 для администратора и разработчика Big Data
Уже совсем скоро, в марте 2021 года, ожидается новый релиз Apache Kafka 2.8.0 [1], главной фишкой которого будет долгожданный KIP-500 (Kafka Improvement Proposal) по отказу от Zookeeper, как обязательной части Кафка-кластера. Напомним, до сих пор Kafka использует сервис синхронизации распределенных систем Apache ZooKeeper для хранения метаданных, таких как расположение разделов и конфигурация топиков. Вопрос ухода от Зукипер был поднят еще в 2019 году, о чем мы писали здесь.
Удаление Зукипер из Kafka значительно упростит администрирование, благодаря сокращению объема настраиваемых служб и возможности развернуть контроллер и брокер в одной JVM. Кроме того, администратору Big Data кластера больше не придется [2]:
тратить время на изучение, конфигурирование, обновление и поддержку еще одной распределенной системы;
определять количества серверов для ансамбля Зукипер, чтобы сбалансировать емкость чтения и записи;
обеспечивать наличие отдельной конфигурации безопасности для Зукипер, которая отличается от остальной части Kafka-кластера; обеспечивать совместное использование ансамбля Зукипер между приложениями Kafka и сторонними сервисами;
настраивать таймауты брокера на Зукипер через конфигурации connection.timeout.ms и zookeeper.session.timeout.ms;
изменять конфигурации Зукипер при добавлении новой функциональной возможности, например, для явного разрешения отдельных команд;
периодически перезапускать ансамбль Зукипер в рамках управления исправлениями и обновлениями;
подбирать оптимальный размер дорогих SSD-дисков для каждого сервера ZooKeeper; настраивать политику для очистки старых данных Зукипер через purgeInterval и autopurge.snapRetainCount;
обеспечивать совместное использование путей к каталогам для журнала транзакций ZooKeeper и каталогов моментальных снимков (snapshot’ов).
С точки зрения разработчика Kafka-приложений при отказе новый релиз этой Big Data платформы принесет следующие преимущества [2]:
повышение скорости обработки данных за счет того, что брокеры будут хранить метаданные локально в журнале и считывать с контроллера только последний набор изменений, аналогично тому, как потребители Kafka могут читать самый конец журнала, а не весь журнал;
отсутствие ограничений на число разделов кластера Kafka — теперь масштабирование будет действительно бесконечным;
устранение причины потери сообщений в случае рассинхронизации Kafka и Зукипер из-за его перезапуска или сбоя.
Как отказаться от Zookeeper на практике: план перехода на Apache Kafka 2.8.0
Чтобы использовать все вышеназванные и другие преимущества отказа от Zookeeper в новом релизе Apache Kafka 2.8.0, необходимо подготовиться к переходу на новую версию. Для этого нужно внести следующие изменения, настроив [3]:
клиенты, сервисы и инструменты администрирования Kafka, о чем мы поговорим далее; REST Proxy API — перейти с v1 на v2 или v3; получить ID Кафка-кластера, что пригодится администратору в случае мониторинга, аудита, агрегирования журналов и устранения неполадок. Ранее получить идентификатора кластера можно было из Зукипер с помощью команды zookeeper-shell: zookeeper-shell zookeeper:2181 get /cluster/id. Теперь для этого придется использовать файл журнала брокера или файл metadata.properties. При отсутствии доступа к журналам брокера, можно использовать функцию descriptionCluster() в AdminClient или инструменты администрирования Кафка с включенным ведением журнала на уровне TRACE. Настройка клиентов, сервисов и инструментов администрирование
Здесь идет речь о клиентских приложениях (потребители и продюссеры), приложения Kafka Streams и ksqlDB, сервисы платформs Confluent (Kafka Connect, Confluent Replicator, Confluent REST Proxy, Confluent Schema Registry, Confluent Control Center или Confluent Metrics Reporter), команды CLI-интерфейса. Все они нуждаются в новой конфигурации, которая указывает, как подключиться к кластеру Кафка. В старых версиях Кафка это делалось через соединение ZooKeeper. В более новых версиях появилась возможность подключаться к брокерам вместо Зукипер. Поэтому в production-развертываниях следует проверить наличие старых клиентов или сервисов, которые настроенные для подключения к Зукипер: zookeeper.connect = zookeeper: 2181.
При переходе на Кафка 2.8.0 рекомендуется выполнить аудит всех клиентских приложений и служб, чтобы заменить вышеуказанную конфигурацию для подключения к брокерам Kafka вместо Зукипер: bootstrap.servers = брокер: 9092.
Также потребуется замена в реестре схем (Schema Registry: вместо конфигурации kafkastore.connection.url = zookeeper: 2181 нужно задать kafkastore.bootstrap.servers = broker: 9092.
Аналогично, в инструментах командной строки вместо аргумента — zookeeper с информацией о подключении Зукипер, например,
kafka-themes — zookeeper zookeeper: 2181 — create — topic test1 — partitions 1 — replication-factor 1,
будет
kafka-themes — bootstrap-server broker: 9092 — create — topic test1 — partitions 1 — replication-factor 1 — command-config
В случае защищенных кластеров с использованием SSL или SASL_SSL, инструменты администрирования требуют дополнительных настроек безопасности для подключения к брокерам, в частности, аргумент — command-config, чтобы указать на файл свойств соединения AdminClient.
Краткий перечень мероприятий по отказу от Зукипер показан далее в таблице.
Дополнительно к вышеотмеченным подготовительным мероприятиям по отказу от Зукипер, при развертывании Apache Kafka 2.8.0 администратору кластера нужно сделать следующее [3]:
проверить конфигурации и клиентские инструменты, чтобы определить все параметры и аргументы ZooKeeper; определить возможные зависимости Зукипер в порядке запуска сервиса. Например, при использовании Docker, следует проверить конфигурацию depends_on, чтобы увидеть, где контейнер ZooKeeper является необходимым условием. Найти косвенные зависимости ZooKeeper, такие как модули Runbook, которые используют Зукипер в качестве узла перехода для выполнения команд на другом узле.
Освойте администрирование кластера Apache Kafka и инструментарий этой платформы для разработки распределенных приложений потоковой аналитики больших данных на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
Apache Kafka для разработчиков
Администрирование кластера Kafka
Источники
1. https://cwiki.apache.org/confluence/pages/viewpage.action?pageId=173081737
2. https://www.confluent.io/blog/42-ways-zookeeper-removal-improves-kafka/
3. https://www.confluent.io/blog/how-to-prepare-for-kip-500-kafka-zookeeper-removal-guide/
Шпаргалка по командам кафки. Бложик переехал. На медиум писаться… | by Михаил Чугунков
Бложик переехал. На медиум писаться больше ничего не будет.
За полгода работы с кафкой накопился набор часто используемых команд. А из-за того, что CLI интерфейс кафки совершенно неудобный, держать команды в голове невозможно, и приходится писать очередную шпаргалку.
Больше всего раздражает разделение команд по нескольким утилитам. Получается, что для выполнения одного действия необходимо знать не только аргументы командной строки, но и название конкретной утилиты. А получилось так, потому что админские команды отправляются в кафку через однострочные баш-скрипты, запускающие Scala-классы. Пример содержимого такого скрипта:
$(dirname $0)/kafka-run-class kafka.admin.ConfigCommand “$@”
Поэтому приходится вести заметку с нужными командами.
kafka-consumer-groups --bootstrap-server kafka.dev.big-company.com:9092 --describe --group group.dev
Выводит оффсеты и лаги группы group.dev по всем топикам. Каждая партиция отдельно.
kafka-consumer-groups --bootstrap-server kafka.dev.big-company.com:9092 --reset-offsets --to-offset 340000 --group group.dev --topic actions --execute
Выставляет оффсет топика actions на указанное значение, если это возможно. Консьюмеры должны быть выключены в момент исполнения команды.
kafka-consumer-groups --bootstrap-server kafka.dev.big-company.com:9092 --reset-offsets --to-latest --group group.dev — topic actions --execute
Выставляет оффсет топика actions на самое раннее возможное значение. Консьюмеры должны быть выключены.
Для предыдущих двух команд можно указать--all-topics вместо названия топика.
kafka-topics --zookeeper zk.dev.big-company.com --create --replication-factor 2 --partitions 2 --topic actions
Создаёт топик с указанным количеством реплик и партиций.
kafka-topics --zookeeper zk.dev.big-company.com --delete --topic actions
Удаление топика.
kafka-topics --zookeeper zk.dev.big-company.com --list
Выводит список всех топиков.
kafka-topics --zookeeper zk.dev.big-company.com --describe
Выводит всю информацию по топикам: кастомные конфиги, количество реплик и партиций, лидирующую партицию.
kafka-configs --zookeeper zk.dev.big-company.com --describe --entity-type topics --entity-name actions
Выводит кастомные конфиги топика, то есть параметры, которые перегружают основной конфигурационный файл кафки.
kafka-topics.sh --zookeeper zk.dev.big-company.com --alter --topic actions --config segment.bytes=104857600
Выставляет значение segment.bytes для топика actions .
kafka-topics.sh --zookeeper zk.dev.big-company.com --alter --topic actions --delete-config segment.bytes
Удаляет кастомный параметр. Для этого топика будет использоваться параметр из общего конфига.
Отдельной команды для этого нет, поэтому надо хитрить с таймаутом, после которого сообщения удаляются с жёсткого диска.
kafka-topics.sh --zookeeper zk.dev.big-company.com --alter --topic actions --config retention.ms=1000
Ждём 1000 миллисекунд…
kafka-topics.sh --zookeeper zk.dev.big-company.com --alter --topic mytopic --delete-config retention.ms
Работа с Kafka в Unix/Linux » BlogLinux.ru
Хотелось бы сделать себе заметку (что-то типа cheat-sheet) с командами для работе с Kafka. Сейчас я приведу готовые примеры использования команд на готовых примера можно будет увидеть работу самой кафки.
Установка Kafka скриптов в Unix/Linux
Чтобы использовать скрипты для работы с Кафка, выполним небольшую установку:
$ KAFKA_VERSION=2.12-2.2.1 &&
wget -q -O - https://www-us.apache.org/dist/kafka/2.2.1/kafka_${KAFKA_VERSION}.tgz | (cd /opt; tar -zxvf -) && cd /opt/kafka_${KAFKA_VERSION}Для простоты использования, можно добавить PATH (в ~/.bashrc):
export KAFKA_VERSION=2.12-2.2.1
export KAFKA_HEAP_OPTS="-Xmx1g -Xms1g -XX:MetaspaceSize=96m -XX:+UseG1GC -XX:MaxGCPauseMillis=20 -XX:InitiatingHeapOccupancyPercent=35 -XX:G1HeapRegionSize=16M -XX:MinMetaspaceFreeRatio=50 -XX:MaxMetaspaceFreeRatio=80"
export PATH="$PATH:/opt/kafka_${KAFKA_VERSION}/bin"После этого, стоит обновить файл:
$ . ~/.bashrcИли:
$ source ~/.bashrcПолезное чтиво:
Установка Kafka в Unix/Linux
Перейдем к работе!
Работа с Kafka в Unix/Linux
Вывести список топиков:
$ kafka-topics.sh --list
--zookeeper zookeeper_host:zookeeper_host_portГде:
- zookeeper_host — Хост зукипера, например, — это может быть localhost, 192.168.13.113 и так далее.
- zookeeper_host_port — Порт зукипера, например по умолчанию — это 2181-й порт.
Так же, можно использовать:
$ kafka-topics.sh --list
--zookeeper $(cat ZooKeeperList.txt)Где:
- ZooKeeperList.txt — это список хостов самого зукипера (zookeeper:port).
Получить информацию о топике:
$ kafka-topics.sh --describe
--zookeeper zookeeper_host:zookeeper_host_port
--topic test_topicГде:
- zookeeper_host — Хост зукипера, например, — это может быть localhost, 192.168.13.113 и так далее.
- zookeeper_host_port — Порт зукипера, например по умолчанию — это 2181-й порт.
Создание топика:
$ kafka-topics.sh --create
--zookeeper $(cat ZooKeeperList.txt)
--topic test_topic
--replication-factor 2
--partitions 3Вот небольшой скрипт для создания топиков:
ENV=nonprod
# 1: A name for the topic
# 2: A replication factor
# 3: A partition
KAFKA_TOPIC_LIST=(
"MyKafkaTopic:3:1"
"MyKafkaTopic2:3:1"
)
for topic in "${KAFKA_TOPIC_LIST[@]}" ; do
a_topic=$(echo "$topic"| cut -d ":" -f1)
a_replication_factor=$(echo "$topic"| cut -d ":" -f2)
a_partition=$(echo "$topic"| cut -d ":" -f3)
kafka-topics.sh --create
--zookeeper $(cat /opt/kafka_2.12-2.2.1/mskkafkatest-${ENV}_ZooKeeperList.txt)
--topic $a_topic
--replication-factor $a_replication_factor
--partitions $a_partition
done;Записать в топик меседжы:
$ kafka-console-producer.sh
--broker-list $(cat BrokersList.txt)
--producer.config producer.properties
--topic topic_name_hereПрочитать с топика меседжы:
$ kafka-console-consumer.sh
--bootstrap-server $(cat BrokersList.txt)
--consumer.config producer.properties
--topic topic_name_here
--from-beginningУдалить топик:
$ kafka-topics.sh --delete
--zookeeper zookeeper_host:zookeeper_host_port
--topic test_topicГде:
- zookeeper_host — Хост зукипера, например, — это может быть localhost, 192.168.13.113 и так далее.
- zookeeper_host_port — Порт зукипера, например по умолчанию — это 2181-й порт.
Так, написал небольшой скрипт для удаление:
#--------------
# Delete topics
#--------------
ENV=nonprod
KAFKA_TOPIC_LIST=(
"MyKafkaTopic2"
"test"
"test2"
)
for topic in "${KAFKA_TOPIC_LIST[@]}" ; do
echo "Deleting ${topic} ....."
kafka-topics.sh --delete
--zookeeper $(cat ZooKeeperList.txt)
-topic $topic
done;Добавить партицию:
$ kafka-topics.sh --alter
--zookeeper zookeeper_host:zookeeper_host_port
--topic test_topic
--partitions 3Где:
- zookeeper_host — Хост зукипера, например, — это может быть localhost, 192.168.13.113 и так далее.
- zookeeper_host_port — Порт зукипера, например по умолчанию — это 2181-й порт.
Посмотреть конфиг для топика:
$ kafka-configs.sh --describe
--zookeeper zookeeper_host:zookeeper_host_port
--entity-type topics
--entity-name test_topicГде:
- zookeeper_host — Хост зукипера, например, — это может быть localhost, 192.168.13.113 и так далее.
- zookeeper_host_port — Порт зукипера, например по умолчанию — это 2181-й порт.
Установить время хранения (не рекомендуется) записей в топике:
$ kafka-topics.sh --alter
--zookeeper zookeeper_host:zookeeper_host_port
--topic test_topic
--config retention.ms=1000Где:
- zookeeper_host — Хост зукипера, например, — это может быть localhost, 192.168.13.113 и так далее.
- zookeeper_host_port — Порт зукипера, например по умолчанию — это 2181-й порт.
Установить время хранения (современный способ) записей в топике:
$ kafka-configs.sh --alter
--zookeeper zookeeper_host:zookeeper_host_port
--entity-type topics
--entity-name test_topic
--add-config retention.ms=1000Где:
- zookeeper_host — Хост зукипера, например, — это может быть localhost, 192.168.13.113 и так далее.
- zookeeper_host_port — Порт зукипера, например по умолчанию — это 2181-й порт.
Если вам нужно удалить все сообщения в теме, вы можете использовать данную проперти и задать время хранения. Сначала установите время хранения на очень низкое значение (1000 мс), подождите несколько секунд, а затем верните время хранения обратно к предыдущему значению.
Примечание: Время хранения по умолчанию составляет 24 часа (86400000 миллисекунд).
Можно вернуть все как и было:
$ kafka-topics.sh --alter
--zookeeper zookeeper_host:zookeeper_host_port
--topic mytopic
--delete-config retention.msПоказать список сообщений для конкретного топика:
$ kafka-console-consumer.sh
--zookeeper zookeeper_host:zookeeper_host_port
--topic test_topic
--from-beginningГде:
- zookeeper_host — Хост зукипера, например, — это может быть localhost, 192.168.13.113 и так далее.
- zookeeper_host_port — Порт зукипера, например по умолчанию — это 2181-й порт.
Или:
$ kafka-console-consumer.sh
--bootstrap-server $(cat BrokersList.txt)
--consumer.config producer.properties
--topic jive_invoices_staging
--from-beginningЧтобы просмотреть offset позиции для consumer группы (для каждой из партиций):
$ kafka-consumer-offset-checker.sh
--zookeeper zookeeper_host:zookeeper_host_port
--group group_ID_here
--topic yourltopic_hereГде:
- zookeeper_host — Хост зукипера, например, — это может быть localhost, 192.168.13.113 и так далее.
- zookeeper_host_port — Порт зукипера, например по умолчанию — это 2181-й порт.
Чтобы начать заново (сбросьте смещение на 0):
$ kafka-streams-application-reset.sh
--input-topics yourltopic_here
--application-id group_ID_here
--bootstrap-servers bootstrap_host:bootstrap_portГде:
- yourltopic_here — Топик.
- group_ID_here — ИД группы.
- bootstrap_host — Хост.
- bootstrap_port — Порт.
Получить самое раннее смещение в топике:
$ kafka-run-class.sh kafka.tools.GetOffsetShell
--broker-list localhost:9092
--topic mytopic
--time -2Получить последнее смещение еще в топике:
$ kafka-run-class.sh kafka.tools.GetOffsetShell
--broker-list localhost:9092
--topic mytopic
--time -1Получить потребительские смещения (consumer offsets) для топика:
$ kafka-consumer-offset-checker.sh
--zookeeper=zookeeper_host:zookeeper_host_port
--topic=mytopic
--group=my_consumer_groupГде:
- zookeeper_host — Хост зукипера, например, — это может быть localhost, 192.168.13.113 и так далее.
- zookeeper_host_port — Порт зукипера, например по умолчанию — это 2181-й порт.
Считать из __consumer_offsets:
$ kafka-console-consumer.sh
--consumer.config config/consumer.properties
--from-beginning
--topic __consumer_offsets
--zookeeper zookeeper_host:zookeeper_host_port
--formatter "kafka.coordinator.GroupMetadataManager$OffsetsMessageFormatter"Где:
- zookeeper_host — Хост зукипера, например, — это может быть localhost, 192.168.13.113 и так далее.
- zookeeper_host_port — Порт зукипера, например по умолчанию — это 2181-й порт.
Вывести список consumer групп:
$ kafka-consumer-groups.sh --list
--zookeeper zookeeper_host:zookeeper_host_port Или:
kafka-consumer-groups.sh --list
--new-consumer
--bootstrap-server localhost:9092 Просмотр сведений о consumer группе:
$ kafka-consumer-groups.sh --describe
--zookeeper zookeeper_host:zookeeper_host_port
--group group_nameГде:
- zookeeper_host — Хост зукипера, например, — это может быть localhost, 192.168.13.113 и так далее.
- zookeeper_host_port — Порт зукипера, например по умолчанию — это 2181-й порт.
Посмотр сообщений в топике:
$ kafkacat -C -b localhost:9092 -t mytopic -p 0 -o -5 -eИли:
$ kafka-console-consumer.sh
--bootstrap-server $(cat BrokersList.txt)
--consumer.config producer.properties
--topic test2
--from-beginningЧтобы записать в топик:
$ kafka-console-producer.sh
--broker-list $(cat BrokersList.txt)
--producer.config producer.properties
--topic test2Запускаем Zookeeper shell:
$ zookeeper-shell.sh
zookeeper_host:zookeeper_host_portПровести перформенс тесты:
$ kafka-producer-perf-test.sh
--topic topic_here
--num-records 1
--record-size 2048
--throughput -1
--producer.config producer.properties
--producer-props
acks=1
buffer.memory=67108864
compression.type=none
batch.size=8196Вот и все, статья «Работа с Kafka в Unix/Linux» завершена.
В чем польза ZooKeeper для админов и разработчиков. Семинар в Яндексе
Привет! Меня зовут Андрей Степачев. В конце прошлого года я выступил перед коллегами с небольшим рассказом о том, что такое ZooKeeper, и как его можно использовать. Доклад изначально был рассчитан на широкий круг аудитории и может быть полезен и разработчикам, и админам, желающим разобраться, как все это примерно работает.
Начнем, пожалуй, с истории появления ZooKeeper. Сначала, как известно, в Google написали сервис Chubby для управления своими серверами и их конфигурацией. Заодно решили задачу со взаимными блокировками. Но у Chubby была одна особенность: для захвата локов необходимо открывать объект, потом закрывать. От этого страдала производительность. В Yahoo посчитали, что им нужен инструмент, при помощи которого они могли бы строить различные системы для конфигураций своих кластеров. Именно в этом основная цель ZooKeeper — хранение и управление конфигурациями определенных систем, а локи получились как побочный продукт. В итоге вся эта система была создана для построения различных примитивных синхронизаций клиентским кодом. В самом ZooKeeper явных понятий подобных очередям нет, все это реализуется на стороне клиентских библиотек.
Основа ZooKeeper — виртуальная файловая система, которая состоит из взаимосвязанных узлов, которые представляют собой совмещенное понятие файла и директории. Каждый узел этого дерева может одновременно хранить данные и иметь подчиненные узлы. Помимо этого в системе существует два типа нод: есть так называемые persistent-ноды, которые сохраняются на диск и никогда не пропадают, и есть эфемерные ноды, которые принадлежат какой-то конкретной сессии и существуют, пока существует она.
На картинке буквами Р —обозначены клиенты. Они устанавливают сессии — активные соединения с ZooKeeper-сервером, в рамках которого происходят обмен heartbeat-пакетами. Если в течение одной трети от тайм-аута мы не услышали хартбита, по истечении двух третей тайм-аута, клиентская библиотека присоединится к другому ZooKeeper-серверу, пока сессия на сервере не успела пропасть. Если сессия пропадает, эфемерные ноды (на схеме обозначены синим) пропадают. У них обычно есть атрибут, который указывает, какая из сессий ими владеет. Такие узлы не могут иметь детей, это строго объект, в который можно сохранить какие-то данные, но нельзя сделать зависимые.
Разработчики ZooKeeper посчитали, что очень удобно было бы иметь это все в виде файловой системы.
Вторая базисная для ZooKeeper вещь — это так называемая синхронная реализация записи и FIFO-обработка сообщений. Идея заключается в том, что вся последовательность команд в ZooKeeper проходит строго упорядоченно т.е. данная система поддерживает total ordering.
Все операции в ZooKeeper превращается в эту идемпотентную операцию. Если мы хотим изменить какую-то ноду, то мы создаем запись о том, что мы ее изменили, при этом запоминаем ту версию ноды, которая была и которая будет. За счет этого мы можем много раз получать одно и то же сообщение, при этом мы будем точно знать, в какой момент можно его применить. Соответственно, любые операции на запись осуществляются строго последовательно в одном потоке, в одном сервере (мастере). Есть лидер, который выбирается между несколькими машинками, и только он выполняет все операции на запись. Чтения могут происходить с реплики. При этом у клиента выполняется строгая последовательность его операций. Т.е. если он послал операцию на запись и на чтение, то сначала выполнится запись. Даже несмотря на то, что операцию чтения можно было бы выполнить не блокируясь, операция на чтение будет выполнена только после того как выполнена предыдущая операция на запись. За счет этого можно реализовывать предсказуемые системы асинхронной работы с ZooKeeper. Сама система в основном ориентирована на асинхронную работу. То что клиентские библиотеки реализуют синхронный интерфейс — это для удобства программиста. На самом деле, высокую производительность ZooKeeper обеспечивает именно при асинхронной работе, как обычно и бывает.
Каким образом это все работает? Есть один лидер плюс несколько фолловеров. Изменения применяются с использованием двухфазного коммита. Оновное, на что ориентируется ZooKeeper — это то, что он работает по TСP плюс total ordering. В целом целом протокол ZAB (ZooKeeper Atomic Broadcast) — это упрощенная версия Паксоса, которая, как известно, переживает переупорядочивание сообщений, умеет с этим бороться. ZAB с этим бороться не умеет, он изначально ориентирован на полностью упорядоченный поток событий. Параллельной обработки нет, но часто она и не требуется, потому что система ориентирована больше на чтение, чем на запись.
Например, у нас есть такой кластер, есть клиенты. Если сейчас клиенты сделают чтение они увидят то значение, которое сейчас сейчас видят фолловеры, считают, что сейчас значение у некого поля сейчас 1. Если мы в каком-то клиенте запишем 2, то фолловер выполнит операцию через лидера и получит в результате новое состояние.
Лидеру для того чтобы запись считалась успешной, нужно, чтобы как минимум 2 из 3 машин подтвердили то, что они эти данные надежно сохранили. Представьте, что у нас вот тот фолловер, который с 1, сейчас, например в каком-нибудь Амстердаме или другом удаленном ДЦ. Он отстает от остальных фолловеров. Следовательно, локальные машины уже будут видеть 2, а тот удаленный фолловер, если клиент произведет с него чтение до того, как фолловер успеет догнать мастера, увидит отстающее значение. Для того чтобы ему прочитать правильное значение, нужно послать специальную команду, чтобы ZooKeeper принудительно синхронизировался с мастером. Т.е. как минимум на момент выполнения команды sync будет точно известно, что мы получили состояние достаточно свежее по отношению к мастеру. Это называется slow read — медленное чтение. Обычно мы читаем очень быстро, но если все будут пользоваться медленным чтением, то понятно, что весь кластер будут читать всегда с мастера. Соответственно, масштабирования не будет. Если мы читаем быстро, позволяем себе отставать, то мы можем масштабироваться на чтение довольно хорошо.
Рецепты применения
Управление конфигурацией
Первое и самое основное применение — это управление конфигурацией. Записываем в Zookeper какую-то настройку, например, URL коннекта с базой или просто флажок, который запрещает или разрешает работу какому-то сервису внутри нашего кластера. Соответственно, участники кластера подписываются на раздел с конфигурацией и отслеживают ее модификации.
Если они зафиксировали изменение, они могут его прочитать и как-то отреагировать на это. За счет т.н. эфемерных нод можно отслеживать, например, жива ли еще машинка. Или получить список активных машин. Если у нас есть набор воркеров, то мы можем зарегистрировать каждого из них. И в зукипере мы будем видеть все машины, которые реально на связи. За счет наличия таймстемпа последней модификации или списка сессий, мы можем даже предсказывать, насколько машинки у нас отстают. Если мы видим, что машина начинает приближаться к тайм-ауту, можно предпринимать какие-то действия.
Рандеву
Еще один вариант — так называемое рандеву. Идея заключается в том, что есть некий путь воркеров и дилер, который раздает им задачи.
Мы не знаем, заранее, сколько у нас воркеров, они могут подключаться и отключаться, мы этот процесс не контролируем. Для этого можно создать каталог workers. И когда у нас появляется новый воркер, он регистрирует эфемерную ноду, которая будет сообщать о том, что воркер все еще жив, и, например, свой каталог, куда будут попадать задания для него. Лидер будет отслеживать каталог workers. Он заметит, если один из воркеров отвалится в какой-то момент. Обнаружив это он может, например, перенести задачи из queue к другому воркеру. Таким образом, мы можем построить на ZooKeeper несложную систему обработки заданий.
Блокировки
Допустим, пришел один клиент. Он создает эфемерную ноду. Тут нужно оговориться, что в ZooKeeper помимо обычных есть sequential-ноды. К ним в конце может приписываться некий атомарно растущий сиквенс.
Второй клиент, приходя создает еще одну эфемерную ноду, получает список детей и отсортировав их, смотрит, является ли он первым. Он видит, что он не первый, вешает обработчик событий на первый и ждет, пока он исчезнет.
Почему не нужно вешать на сам каталог my-lock и ждать когда там все исчезнет? Потому что, если у вас много машин, которые пытаются что-то заблокировать, то когда пропадет lock–0001, у вас будет шторм уведомлений. Мастер будет просто занят рассылкой уведомлений об одном конкретном локе. Поэтому лучше их сцеплять именно таким образом — друг за другом, чтобы они следили только за предыдущей нодой. Они выстраиваются в цепочку.
Когда первый клиент отпускает лок, удаляет эту запись, второй клиент видит это и считает, что теперь он является владельцем лока, т.к. впереди никого нет. За счет сиквенса никто вперед него гарантированно не залезет. Соответственно, если первый клиент придет снова, он создаст ноду уже в конце цепочки.
Производительность
На графике ниже по оси x отображено отношение записи к чтению. Заметно, что с ростом количества операций записи в процентном отношении, производительность сильно проседает.
Это результаты работы в асинхронном режиме. Т.е. операции шлются по 100. Если бы они слались по одной, числа по оси y нужно поделить на 100. На чтение можно расти лучше. В ZooKeeper помимо возможности построить кворум из, скажем, пяти машин, которые будут гарантировать сохранение данных, можно еще делать неголосующие машины, которые работают как репитеры: просто читают события, но сами в записи не участвуют. За счет этого и получается преимущество в записи.
| Servers | 100% reads | 0% reads |
| 13 | 460k | 8k |
| 9 | 296k | 12k |
| 7 | 257k | 14k |
| 5 | 165k | 18k |
| 3 | 87k | 21k |
Таблица выше демонстрирует, как добавление серверов влияет на чтение и запись. Видно, что скорость чтения растет вместе с количеством, а если мы увеличиваем кворум на запись, производительность падает.
На картинке ниже можно посмотреть, как ZooKeeper реагирует на различные сбои. Первый случай — выпадение реплики. Второй — выпадение реплики, к которой мы не присоединены.
Падение лидера для зукипера условно критично. При хорошей сети ZooKeeper может восстановить его примерно за 200 мс. Иногда лидер может выбираться и несколько минут. И в этот момент если мы пытаемся захватить lock, любые попытки записи без активного лидера ни к чему не приведут, мы будем вынуждены ждать его появления.
Задержки
| severs / workers | 3 | 5 | 7 | 9 |
| 1 | 776 | 748 | 758 | 711 |
| 10 | 1831 | 1831 | 1572 | 1540 |
| 20 | 2470 | 2336 | 1934 | 1890 |
Время в таблице выше представлено в наносекундах. Соответственно по скорости чтения ZooKeeper приближается к in-memory-базам. Фактически это такой кэш, который всегда читает из памяти. Вообще у ZooKeeper база данных всегда находится в памяти. Запись происходит примерно так: ZooKeeper пишет лог событий, он в соответствии с настройками тика сбрасывается на диск и периодически система делает снэпшот всей базы. Соответственно, при слишком большой базе или слишком загруженных дисках задержки могут быть сравнимы с тайм-аутом. Этот тест моделирует создание некой конфигурации: у нас есть 1килобайт данных, сначала идет один синхронный create, потом асинхронный delete, все это повторяется 50 000 раз.
Автор: octo47
Источник
Серверу Apache ZooKeeper не удается сформировать кворум в Azure HDInsight
- Чтение занимает 3 мин
В этой статье
В этой статье описываются действия по устранению неполадок и возможные способы решения проблем, связанных с Zookeeper в кластерах Azure HDInsight.
Симптомы
- Оба диспетчера ресурсов переходят в режим ожидания
- Узлы имен находятся в режиме ожидания
- Не удается выполнить задания Spark, Hive и Yarn или запросы Hive из-за сбоев подключения Zookeeper
- Управляющие программы LLAP не запускаются в защищенных кластерах Spark или безопасных интерактивных кластерах Hive
Пример журнала
Вы можете увидеть в логах yarn (/var/log/hadoop-yarn/yarn/yarn-yarn*.log on the headnodes) сообщение об ошибке следующего вида:
2020-05-05 03:17:18.3916720|Lost contact with Zookeeper. Transitioning to standby in 10000 ms if connection is not reestablished.
Message
2020-05-05 03:17:07.7924490|Received RMFatalEvent of type STATE_STORE_FENCED, caused by org.apache.zookeeper.KeeperException$NoAuthException: KeeperErrorCode = NoAuth
...
2020-05-05 03:17:08.3890350|State store operation failed
2020-05-05 03:17:08.3890350|Transitioning to standby state
- Существует множество причин, по которым службы высокого уровня доступности, такие как Yarn, NameNode и Livy, могут выйти из строя.
- Обратитесь к журналам, связанным с подключениями Zookeeper
- Убедитесь, что эта ошибка возникает систематически (не используйте эти решения для однократно возникающих проблем).
- Задания могут временно завершаться со сбоем из-за проблем с подключением Zookeeper
Распространенные причины сбоев Zookeeper
- Высокая загрузка ЦП на серверах Zookeeper
- Если в пользовательском интерфейсе Ambari отображается, что ресурсы ЦП на серверах Zookeeper длительное время используются почти на 100 %, то сеансы Zookeeper, открытые в течение этого времени, могут истечь.
- Клиенты Zookeeper, которые сообщают о частом истечении времени ожидания
- В журналах диспетчера ресурсов, узла имен и других компонентов будут содержаться сведения о частом окончании времени ожидания подключения клиента.
- Это может привести к потере кворума, частой отработке отказа и другим проблемам.
Проверка состояния Zookeeper
- Найдите серверы Zookeeper в файле /etc/hosts или в пользовательском интерфейсе Ambari.
- Выполните следующую команду.
echo stat | nc <ZOOKEEPER_HOST_IP> 2181(или 2182)- Порт 2181 является экземпляром Apache Zookeeper.
- Порт 2182 используется службой HDInsight Zookeeper (для обеспечения высокой доступности служб, которые не имеют собственного уровня высокой доступности).
- Если команда не отображает выходные данные, это означает, что серверы Zookeeper не работают.
- Если серверы работают, в результате будут содержаться статические подключения клиентов и другие статистические данные.
Zookeeper version: 3.4.6-8--1, built on 12/05/2019 12:55 GMT
Clients:
/10.2.0.57:50988[1](queued=0,recved=715,sent=715)
/10.2.0.57:46632[1](queued=0,recved=138340,sent=138347)
/10.2.0.34:14688[1](queued=0,recved=264653,sent=353420)
/10.2.0.52:49680[1](queued=0,recved=134812,sent=134814)
/10.2.0.57:50614[1](queued=0,recved=19812,sent=19812)
/10.2.0.56:35034[1](queued=0,recved=2586,sent=2586)
/10.2.0.52:63982[1](queued=0,recved=72215,sent=72217)
/10.2.0.57:53024[1](queued=0,recved=19805,sent=19805)
/10.2.0.57:45126[1](queued=0,recved=19621,sent=19621)
/10.2.0.56:41270[1](queued=0,recved=1348743,sent=1348788)
/10.2.0.53:59097[1](queued=0,recved=72215,sent=72217)
/10.2.0.56:41088[1](queued=0,recved=788,sent=802)
/10.2.0.34:10246[1](queued=0,recved=19575,sent=19575)
/10.2.0.56:40944[1](queued=0,recved=717,sent=717)
/10.2.0.57:45466[1](queued=0,recved=19861,sent=19861)
/10.2.0.57:59634[0](queued=0,recved=1,sent=0)
/10.2.0.34:14704[1](queued=0,recved=264622,sent=353355)
/10.2.0.57:42244[1](queued=0,recved=49245,sent=49248)
Latency min/avg/max: 0/3/14865
Received: 238606078
Sent: 239139381
Connections: 18
Outstanding: 0
Zxid: 0x1004f99be
Mode: follower
Node count: 133212
Пиковая загрузка ЦП наблюдается каждый час.
- Войдите на сервер Zookeeper и проверьте файл /etc/crontab.
- Если в данный момент выполняются какие-либо ежечасные задания, следует задать время начала для разных серверов Zookeeper.
Удаление старых моментальных снимков
- Zookeeper настроен на автоматическую очистку старых моментальных снимков.
- По умолчанию сохраняются последние 30 моментальных снимков.
- Для управления количеством хранящихся моментальных снимков используется ключ конфигурации
autopurge.snapRetainCount. Это свойство находится в следующих файлах:/etc/zookeeper/conf/zoo.cfgдля Hadoop Zookeeper;/etc/hdinsight-zookeeper/conf/zoo.cfgдля HDInsight Zookeeper.
- Задайте для параметра
autopurge.snapRetainCountзначение 3 и перезапустите серверы Zookeeper.- Обновить конфигурацию Hadoop Zookeeper и перезапустить службу можно с помощью Ambari.
- Остановите работу и перезапустите HDInsight Zookeeper вручную.
sudo lsof -i :2182предоставит идентификатор процесса для завершения.sudo python /opt/startup_scripts/startup_hdinsight_zookeeper.py
- Не удаляйте моментальные снимки вручную, поскольку это может привести к утере данных.
CancelledKeyException в журнале сервера Zookeeper не требует удаления моментальных снимков.
- Это исключение может проявляться на серверах zookeeper (/var/log/zookeeper/zookeeper-zookeeper-* или /var/log/hdinsight-zookeeper/zookeeper* files)
- Это исключение обычно означает, что клиент больше не активен и серверу не удается отправить сообщение.
- Это исключение также указывает, что клиент Zookeeper завершает сеансы преждевременно.
- Определите, имеются ли другие симптомы, описанные в этом документе.
Дальнейшие действия
Если вы не видите своего варианта проблемы или вам не удается ее устранить, дополнительные сведения можно получить, посетив один из следующих каналов.
- Получите ответы специалистов Azure на сайте поддержки сообщества пользователей Azure.
- Подпишитесь на @AzureSupport — официальный канал Microsoft Azure для работы с клиентами. Вступайте в сообщество Azure для получения нужных ресурсов: ответов, поддержки и советов экспертов.
- Если вам нужна дополнительная помощь, отправьте запрос в службу поддержки на портале Azure. Выберите Поддержка в строке меню или откройте центр Справка и поддержка. Дополнительные сведения см. в статье Создание запроса на поддержку Azure. Доступ к управлению подписками и поддержкой выставления счетов уже включен в вашу подписку Microsoft Azure, а техническая поддержка предоставляется в рамках одного из планов Службы поддержки Azure.
ZooKeeper CLI — интерфейс командной строки | Учебник Apache Zookeeper
Команды ZooKeeper
ZooKeeper Command Line Interface (CLI) используется для взаимодействия с ансамблем ZooKeeper, который позволяет выполнять простые операции, подобные файлам. Это полезно для отладки.
-
Для выполнения операций ZooKeeper CLI сначала запустите сервер ZooKeeper, а затем клиент ZooKeeper с помощью «bin / zkCli.sh». После запуска клиента в оболочке введите help, чтобы получить список команд, которые могут быть выполнены клиентом, например:
[zk: localhost: 2181 (CONNECTED) 0] справка ZooKeeper -server host: аргументы порта cmd подключить хост: порт получить путь [смотреть] ls path [смотреть] установить данные пути [версия] rmr путь delquota [-n | -b] путь покидать распечатки вкл | выкл создать [-s] [-e] путь к данным acl путь статистики [смотреть] Закрыть ls2 path [смотреть] история listquota путь setAcl путь acl getAcl путь путь синхронизации повторить cmdno аутентификация схемы addauth удалить путь [версия] setquota -n | -b val путь [zk: localhost: 2181 (ПОДКЛЮЧЕНО) 1] -
Отсюда вы можете попробовать несколько команд, чтобы почувствовать этот простой интерфейс командной строки.Сначала начните с ввода команды list, например ls:
.[zk: localhost: 2181 (ПОДКЛЮЧЕНО) 1] ls / [работник зоопарка] -
Затем создайте новый znode, запустив create / zk_test my_data. Это создает новый znode и связывает строку «my_data» с узлом. Вы должны увидеть:
[zk: localhost: 2181 (ПОДКЛЮЧЕНО) 2] создать / zk_test my_data Создано / zk_test -
Выполните еще одну команду ls /, чтобы увидеть, как выглядит каталог:
[zk: localhost: 2181 (ПОДКЛЮЧЕНО) 3] ls / [zookeeper, zk_test]Обратите внимание, что каталог zk_test создан.
-
Затем убедитесь, что данные были связаны с znode, выполнив команду get, например:
[zk: localhost: 2181 (ПОДКЛЮЧЕНО) 4] get / zk_test мои данные cZxid = 0x8 ctime = Пн, 30 ноября, 18:41:06 IST 2015 mZxid = 0x8 mtime = Пн, 30 ноября, 18:41:06 IST 2015 pZxid = 0x8 cversion = 0 dataVersion = 0 aclVersion = 0 ephemeralOwner = 0x0 dataLength = 7 numChildren = 0 -
Мы можем изменить данные, связанные с zk_test, выполнив команду set, например:
[zk: localhost: 2181 (ПОДКЛЮЧЕНО) 5] установить / zk_test мусор cZxid = 0x8 ctime = Пн, 30 ноября, 18:41:06 IST 2015 mZxid = 0x9 mtime = Пн, 30 ноября, 18:43:06 IST 2015 pZxid = 0x8 cversion = 0 dataVersion = 1 aclVersion = 0 ephemeralOwner = 0x0 dataLength = 4 numChildren = 0 -
Наконец, давайте удалим узел, введя:
[zk: localhost: 2181 (ПОДКЛЮЧЕНО) 6] удалить / zk_test
Другие важные команды Zookeeper
Zookeeper Часы
Часы показывают уведомление при изменении данных указанного znode.Вы можете установить часы только в команде get, например:
get / path-to-znode [смотреть] 1
Давайте запустим команду часов, например:
[zk: localhost: 2181 (ПОДКЛЮЧЕНО) 7] get / zk_test 1
мои данные
cZxid = 0x8
ctime = Пн, 30 ноября, 18:41:06 IST 2015
mZxid = 0x8
mtime = Пн, 30 ноября, 18:41:06 IST 2015
pZxid = 0x8
cversion = 0
dataVersion = 0
aclVersion = 0
ephemeralOwner = 0x0
dataLength = 7
numChildren = 0
Вывод аналогичен команде get, но будет ждать изменений znode в фоновом режиме.
Создать подузел
Вы создаете подчиненный узел таким же образом, как и новый z-узел. Единственная разница в том, что путь дочернего znode также будет иметь родительский путь. Давайте создадим дочерний элемент zk_test znode, как показано ниже:
[zk: localhost: 2181 (ПОДКЛЮЧЕНО) 8] create / zk_test / Child1 «firstchild»
создано / zk_test / Child1
[zk: localhost: 2181 (ПОДКЛЮЧЕНО) 9] create / zk_test / Child2 «secondchild»
создано / zk_test / Child2
Список детей
Теперь, чтобы получить список всех дочерних элементов нашего типа znode ‘zk_test’, как показано ниже:
[zk: localhost: 2181 (ПОДКЛЮЧЕНО) 10] ls / zk_test
[Child1, Child2]
Проверить статус
Метаданные znode содержат такие детали, как отметка времени, номер версии, ACL, длина данных и дочерний znode.Если вы хотите просмотреть метаданные, используйте команду проверки статуса, как показано ниже:
[zk: localhost: 2181 (ПОДКЛЮЧЕНО) 11] stat / zk_test
cZxid = 0x8
ctime = Пн, 30 ноября, 18:41:06 IST 2015
mZxid = 0x8
mtime = Пн, 30 ноября, 18:41:06 IST 2015
pZxid = 0x8
cversion = 0
dataVersion = 0
aclVersion = 0
ephemeralOwner = 0x0
dataLength = 7
numChildren = 0
Выйти из
Наконец, чтобы выйти из интерфейса командной строки, введите quit:
[zk: localhost: 2181 (ПОДКЛЮЧЕНО) 12] выйти
Выход...
[[электронная почта защищена] корзина] $
Zookeeper метаданные znode
Используя команду get, мы можем просмотреть данные и метаданные, хранящиеся в нашем новом znode.
[zk: localhost: 2181 (ПОДКЛЮЧЕНО) 13] get / zk_test
мои данные
cZxid = 0x8
ctime = Пн, 30 ноября, 18:41:06 IST 2015
mZxid = 0x8
mtime = Пн, 30 ноября, 18:41:06 IST 2015
pZxid = 0x8
cversion = 0
dataVersion = 0
aclVersion = 0
ephemeralOwner = 0x0
dataLength = 7
numChildren = 0
Давайте рассмотрим возвращаемые данные и метаданные:
- my_data : Эта строка текста — данные, которые мы сохранили в znode.
- cZxid = 0x8 : zxid (идентификатор транзакции ZooKeeper) изменения, которое привело к созданию этого znode.
- ctime = Mon Nov 30 18:41:06 IST 2015 : время, когда был создан этот znode.
- mZxid = 0x8 : zxid изменения, которое последним изменило этот znode.
- mtime = Mon Nov 30 18:41:06 IST 2015 : время последнего изменения этого znode.
- pZxid = 0x8 : zxid изменения, которое последним изменило дочерние элементы этого znode.
- cversion = 0 : количество изменений дочерних элементов этого znode.
- dataVersion = 0 : количество изменений в данных этого znode.
- aclVersion = 0 : количество изменений в ACL этого znode.
- ephemeralOwner = 0x0 : идентификатор сеанса владельца этого znode, если znode является эфемерным узлом. Если это не эфемерный узел, он будет равен нулю.
- dataLength = 7 : длина поля данных этого znode.
- numChildren = 0 : количество потомков этого узла.
сливающихся местных служб zookeeper start
сливающихся местных служб zookeeper start | Конфлюентная документация- Дом
- Справочник команд интерфейса командной строки Confluent
- сливной местный
- сливающиеся местные услуги
- сливные местные службы zookeeper
Важно
Конфлюентные локальные команды предназначены для одноузловой среды разработки и не подходят для производственной среды.Производимые данные являются временными и предназначены для временный. Для рабочих процессов, готовых к работе, см. Confluent Platform.
Описание
Запустите Apache ZooKeeper ™.
сливающиеся локальные службы zookeeper start [флаги]
Подсказка
Вы должны экспортировать путь как переменную среды для каждого сеанса терминала или установить путь к своей платформе Confluent. установка в вашем профиле оболочки. Например:
cat ~ / .bash_profile
экспорт CONFLUENT_HOME = <путь-к-конфлюенту>
экспорт PATH = "$ {CONFLUENT_HOME} / bin: $ PATH"
Флаги
-c, --config string Настройте Apache ZooKeeper ™ с помощью определенного файла свойств.
Глобальные флаги
-h, --help Показать справку по этой команде. -v, --verbose count Увеличить уровень детализации (-v для предупреждения, -vv для информации, -vvv для отладки, -vvvv для трассировки).
© Авторские права , Confluent, Inc. Политика конфиденциальности | Положения и условия.Apache, Apache Kafka, Kafka и логотип Kafka являются товарными знаками Фонд программного обеспечения Apache. Все остальные товарные знаки, знаки обслуживания и авторские права являются собственность их владельцев.
Подключиться к Apache ZooKeeper с помощью командной строки
zkCli.sh — это утилита для подключения к локальной или удаленной службе ZooKeeper и выполнения некоторых команд. В этой статье описывается, как можно использовать zkCli.sh для подключения к кластерам в Instaclustr. В этой статье мы предполагаем, что ваш кластер был правильно настроен и подготовлен, как показано в нашем предыдущем руководстве «Создание кластера».
Содержание
Предварительные требования
Вам также потребуются двоичные файлы ZooKeeper, которые можно загрузить с https://zookeeper.apache.org/releases.html. Мы рекомендуем версию двоичных файлов ZooKeeper, соответствующую вашему кластеру ZooKeeper.Вам не нужно устанавливать после загрузки и распаковки.
Общедоступный IP-адрес вашего компьютера должен быть добавлен к ZooKeeper Allowed Addresses на вкладке Settings вашего кластера в консоли Instaclustr (см. Эту статью поддержки).
Имя пользователя, пароль и файл сертификата можно найти на странице Connection Info вашего кластера. Файлы сертификатов необходимы для подключения к вашему кластеру с помощью SSL.
Аутентификация пользователя
Apache ZooKeeper не применяет аутентификацию.Пользователи всегда могут подключиться к серверам ZooKeeper как «мировой» пользователь. Однако доступ к данным (znodes) может быть ограничен ACL, которые связаны с аутентифицированным пользователем. Мы предоставляем пользователя по умолчанию, которого вы можете использовать при подключении к серверам ZooKeeper. Если вы решите это сделать, создайте файл, содержащий учетные данные (например, jaas.conf) со следующим содержимым
Клиент { org.apache.zookeeper.server.auth.DigestLoginModule требуется username = «iczookeeper» пароль = «<пароль>«; };
| Клиент { орг.apache.zookeeper.server.auth.DigestLoginModule требуется username = «iczookeeper» password = «<пароль>«; }; |
и установите переменную среды перед подключением, как описано в следующих разделах.
Подключение к Instaclustr без SSL
Если в вашем кластере не включено шифрование, вы можете подключиться к нему с помощью zkCli.sh без SSL.
Для Mac / Linux откройте терминал и используйте следующую команду для подключения к кластеру.
bin / zkCli.sh -server
| bin / zkCli.sh -server |
den Если вы установите учетные данные следующая переменная среды.
export CLIENT_JVMFLAGS = "- Djava.security.auth.login.config = jaas.conf"
| экспорт CLIENT_JVMFLAGS = "- Djava.security.auth.login.config = 9262 |
Если в вашем кластере включено шифрование, SSL необходим для подключения к кластеру, и вам необходимо получить доверенный магазин.jks из сертификата кластера.
Для Mac / Linux: откройте терминал и с помощью следующей команды установите переменную среды.
экспорт CLIENT_JVMFLAGS = " -Dzookeeper.clientCnxnSocket = org.apache.zookeeper.ClientCnxnSocketNetty -Dzookeeper.client.secure = true -Dzookeeper.ssl.trustStore.location = truststore.jks -Dzookeeper.ssl.trustStore.password = instaclustr "
| экспорт CLIENT_JVMFLAGS =" -Dzookeeper.clientCnxnSocket = org.apache.zookeeper.ClientCnxnSocketNetty -Dzookeeper.client.secure = true -Dzookeeper.ssl.trustStore.location = truststore.jks -Dzookeeper.ssl.trustStore.passrword |
| bin / zkCli.sh -server |
Если вы добавите следующие учетные данные переменная перед подключением
экспорт CLIENT_JVMFLAGS = "$ {CLIENT_JVMFLAGS} -Djava.security.auth.login.config = jaas.conf "
| экспорт CLIENT_JVMFLAGS =" $ {CLIENT_JVMFLAGS} -Djava.security.auth.login.config = jaas.security.auth.login.config = jaas.conf " | 2 | Edge для частного облака v4.18.01
