Что такое оператор OFFSET в ассемблере. Как использовать OFFSET для получения смещения адреса. Какие преимущества дает применение OFFSET в ассемблерных программах. Каковы особенности работы с OFFSET в разных режимах процессора.
Понятие и назначение оператора OFFSET в ассемблере
Оператор OFFSET в ассемблере используется для получения смещения адреса переменной или метки относительно начала сегмента. Это важный инструмент для эффективного управления памятью и адресацией в ассемблерных программах.
Ключевые особенности оператора OFFSET:
- Возвращает смещение адреса, а не само значение по этому адресу
- Работает с метками и именованными переменными
- Позволяет получить адрес без прямого указания числового значения
- Упрощает работу с адресами при написании переносимого кода
Как работает OFFSET? Он определяет количество байтов между началом сегмента и меткой/переменной, к которой применяется. Это смещение и возвращается в качестве результата.

Синтаксис использования оператора OFFSET
Базовый синтаксис применения оператора OFFSET выглядит следующим образом:
OFFSET имя_метки
Где имя_метки — это идентификатор переменной или метки, для которой нужно получить смещение адреса.
Пример использования:
data segment
message db 'Hello, World!$'
data ends
code segment
start:
mov dx, OFFSET message
mov ah, 09h
int 21h
code ends
В этом примере OFFSET message возвращает смещение строки относительно начала сегмента данных.
Преимущества использования оператора OFFSET
Применение оператора OFFSET дает ряд преимуществ при разработке ассемблерных программ:
- Повышение читаемости кода за счет использования символьных имен вместо числовых адресов
- Упрощение сопровождения программ, так как при изменении адресов не требуется вручную корректировать код
- Возможность написания позиционно-независимого кода
- Уменьшение вероятности ошибок при работе с адресами
OFFSET особенно полезен при передаче адресов в подпрограммы, инициализации указателей и работе со структурами данных.

Особенности работы OFFSET в разных режимах процессора
Поведение оператора OFFSET может различаться в зависимости от режима работы процессора:
- В реальном режиме OFFSET возвращает 16-битное смещение
- В защищенном режиме возвращается 32-битное смещение
- В длинном режиме (x64) OFFSET дает 64-битное смещение
Размер возвращаемого смещения важно учитывать при написании кода для разных архитектур и режимов процессора. Это влияет на совместимость и корректность работы программы.
Примеры использования OFFSET в типичных задачах
Рассмотрим несколько примеров применения оператора OFFSET в распространенных сценариях программирования на ассемблере:
1. Передача адреса строки в подпрограмму
.data message db 'Hello, World!',0 .code main proc push OFFSET message call print_string ret main endp print_string proc ; Код для вывода строки ret print_string endp
2. Инициализация указателя
.data
buffer db 100 dup(?)
pointer dd ?
.code
mov pointer, OFFSET buffer
3. Вычисление размера структуры
mystruct STRUCT
field1 db ?
field2 dw ?
field3 dd ?
mystruct ENDS
size_of_struct equ OFFSET mystruct.field3 - OFFSET mystruct
В этих примерах OFFSET позволяет элегантно работать с адресами, делая код более читаемым и гибким.
Альтернативы оператору OFFSET в ассемблере
Хотя OFFSET является мощным инструментом, в некоторых ситуациях могут применяться альтернативные подходы:
- Использование директивы LEA (Load Effective Address) для загрузки эффективного адреса
- Прямое указание числовых смещений (менее гибкий подход)
- Применение макросов для генерации адресов
- Использование специфических для компилятора директив
Выбор между OFFSET и альтернативами зависит от конкретной задачи, стиля программирования и требований к производительности.
Ограничения и особенности применения OFFSET
При работе с оператором OFFSET следует учитывать некоторые ограничения и особенности:
- OFFSET работает только с именованными метками и переменными
- Нельзя применять OFFSET к регистрам или непосредственным значениям
- В некоторых ситуациях OFFSET может давать неожиданные результаты при работе с массивами
- При использовании OFFSET с внешними символами могут потребоваться дополнительные директивы компоновщика
Понимание этих нюансов поможет избежать ошибок и эффективно использовать OFFSET в программах.
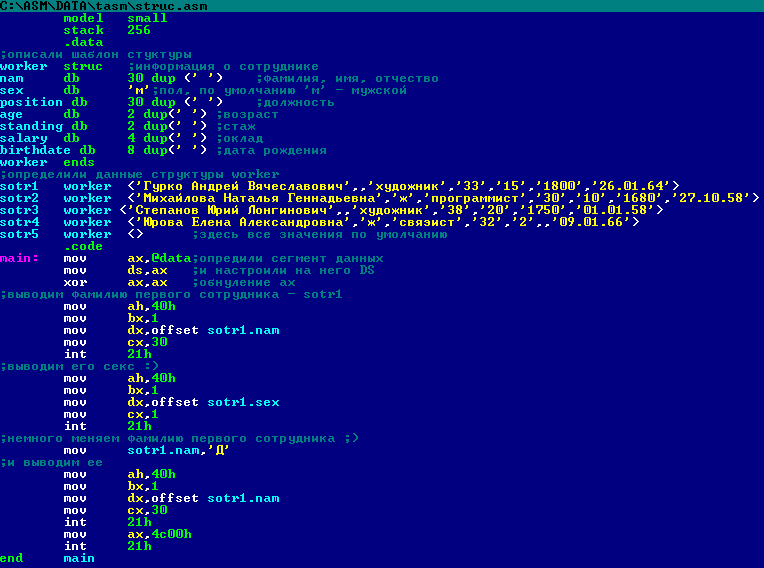
Оптимизация кода с использованием OFFSET
- Уменьшение размера программы за счет использования относительных адресов
- Ускорение доступа к данным при правильной организации структур
- Упрощение реализации динамического выделения памяти
- Облегчение создания переносимого кода между разными сегментами памяти
Оптимизация с помощью OFFSET особенно эффективна в больших проектах с сложной структурой данных.
Заключение: роль OFFSET в современном ассемблерном программировании
Оператор OFFSET остается важным инструментом в арсенале ассемблерного программиста, несмотря на развитие высокоуровневых языков. Его применение позволяет:
- Создавать эффективный и гибкий код для работы с памятью
- Упрощать разработку системного программного обеспечения
- Оптимизировать критические участки программ
- Лучше понимать внутреннее устройство компьютерных систем
Освоение техник работы с OFFSET расширяет возможности программиста и позволяет создавать более качественное и производительное программное обеспечение на низком уровне.

Оператор OFFSET
Главная / Ассемблер / Для чайников / Введение в Ассемблер /
|
Английский за 3 месяца
Хотим мы того или нет, но английский язык стал международным средством общения. В Европе он входит в школьную программу, причём на таком уровне, что после школы все дети умеют достаточно хорошо говорить на английском. Это надо просто принять как данность и использовать. Лишать себя возможности быть частью мирового сообщества, это, как минимум, недальновидно. Подробнее… |
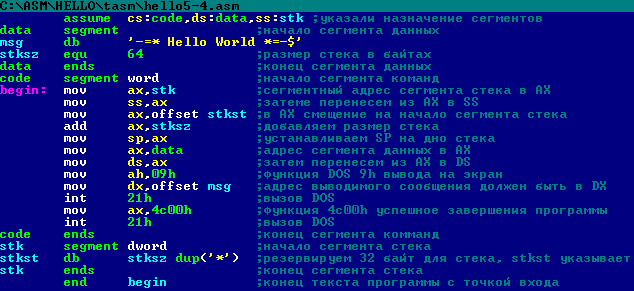
OFF SET можно перевести как “вне набора”. Применительно к языку ассемблера ещё более вольный перевод может звучать так: за пределами набора команд. Почему этот оператор назвали именно так, поймёте, прочитав эту статью. Ну а вообще слово OFFSET переводится как “смещение”. И это, конечно, настоящий перевод. Но я позволил себе немного пофилософствовать )))
Ну а вообще слово OFFSET переводится как “смещение”. И это, конечно, настоящий перевод. Но я позволил себе немного пофилософствовать )))
Оператор OFFSET возвращает адрес (смещение) некоторой метки данных относительно начала сегмента. Под смещением здесь понимается то количество байтов, которое отделяет метку данных от начала сегмента.
В защищённом режиме работы процессора смещения всегда являются 32-разрядными числами без знака. В реальном и виртуальном режимах адресации смещения всегда 16-разрядные.
С помощью оператора OFFSET в ассемблере можно объявлять переменные, то есть связывать адрес в памяти с именем переменной. По этой ссылке вы найдёте пример объявления строки. Но переменные могут быть, разумеется, не только строковыми.
Пример:
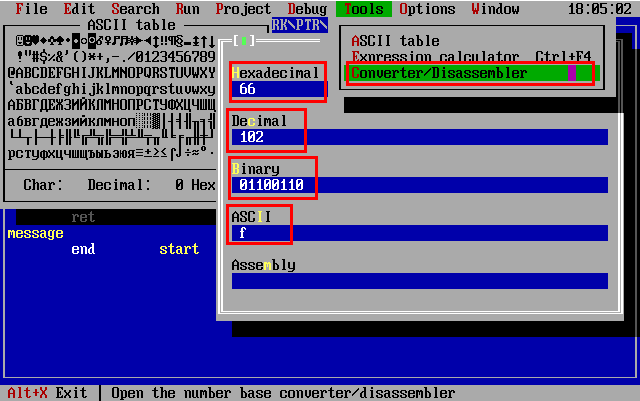
.model tiny .code ORG 100h start: MOV AX, wVar ; AX = 65535 MOV DX, OFFSET wVar ; DX = 107 RET wVar DD 65535 ; Объявляем переменную типа WORD END start
Здесь мы объявили переменную wVar и назначили сразу ей какой-то значение (в нашем случае 65535). В программе мы записали ЗНАЧЕНИЕ этой переменной в регистр АХ. А вот потом, с помощью оператора OFFSET,
мы получаем адрес (смещение) переменной
В программе мы записали ЗНАЧЕНИЕ этой переменной в регистр АХ. А вот потом, с помощью оператора OFFSET,
мы получаем адрес (смещение) переменной wVar, относительно начала сегмена (в нашем случае это 100h).
И в нашем случае смещение будет равно 107 в шестнадцатеричной системе, потому что:
- Сегмент начинается с адреса 100h (
ORG 100h) - Команда
MOV AX, wVar - Команда
MOV DX, OFFSET wVarзанимает следующие 3 байта с адресами: 103h, 104h, 105h - Команда
RETзанимает 1 байт по адресу: 106h
Ну и получается, что наша переменная wVar находится по адресу 107h.
Таким вот нехитрым образом можно получить адрес первого байта любой объявленной переменной. Соответственно, чтобы получить адрес следующего байта, надо просто прибавить 1 к смещению. Это обычно используется при работе со строками, когда надо получить отдельный символ строки. Пример:
Пример:
.model tiny .code ORG 100h start: MOV AH, 09h ;Номер функции 09h MOV DX, OFFSET stroka+7 ;Адрес строки записываем в DX INT 21h RET stroka DB 'Hello, World!!!$' ;Строка для вывода END start END start
Здесь мы выводим не всю строку, а начиная с 8-го символа, потому что к смещению адреса переменной stroka мы прибавили 7. Но прибавили мы 7, а не 8, потому что адресация начинается с нуля, а не с единицы. Таким образом на экран будет выведено:
World!!!
то есть только нужная нам часть строки.
На этом пока всё. Подключайтесь к группе Основы программирования в Телеграм, или к другим каналам (ссылки ниже), чтобы ничего не пропустить.
Вступить в группу «Основы программирования»
Подписаться на рассылки по программированию
|
Первые шаги в программирование Главный вопрос начинающего программиста – с чего начать? Вроде бы есть желание, но иногда «не знаешь, как начать думать, чтобы до такого додуматься». |
 У человека, который никогда не имел дело с информационными технологиями, даже простые вопросы могут вызвать большие трудности и отнять много времени на решение.
Подробнее…
У человека, который никогда не имел дело с информационными технологиями, даже простые вопросы могут вызвать большие трудности и отнять много времени на решение.
Подробнее…
|
Способом, или режимом адресации
называют процедуру нахождения операнда для выполняемой команды. Если команда
использует два операнда, то для каждого из них должен быть задан способ адресации,
причем режимы адресации первого и второго операнда могут как совпадать, так
и различаться. Операнды команды могут находиться в разных местах: непосредственно
в составе кода команды, в каком-либо регистре, в ячейке памяти; в последнем
случае существует несколько возможностей указания его адреса. Строго говоря,
способы адресации являются элементом архитектуры процессора, отражая заложенные
в нем возможности поиска операндов. mov mem, AX в качестве операндов используется
обозначение ячейки памяти mem, a также обозначение регистра АХ. В то же время,
для соответствующей машинной команды операндами являются содержимое ячейки памяти
и содержимое регистра. inc СН ;Плюс 1 к содержимому
СН Непосредственная адресация. Операнд (байт или слово) указывается в команде и после трансляции поступает в код команды; он может иметь любой смысл (число, адрес, код ASCII), а также быть представлен в виде символического обозначения. mov АН, 40h ;Число 40h
загружается в АН Команда mov, использованная
в последнем предложении, имеет два операнда; первый операнд определяется с помощью
регистровой адресации, второй — с помощью непосредственной. ; Сегмент данных В приведенном примере относительный
адрес строки mes, т.е. расстояние в байтах первого байта этой строки от начала
сегмента, в котором она находится, заносится в регистр DX. ;Сегмент данных Сравнивая этот пример с
предыдущим, мы видим, что указание в команде имени ячейки памяти обозначает,
что операндом является содержимое этой ячейки; указание имени ячейки с описателем
offset — что операндом является адрес ячейки. assume DS:data то команды обращения к
памяти транслируются без какого-либо префикса, а процессор при выполнении этих
команд берет сегментный адрес из регистра DS. assume ES:data (в этом случае сегмент
данных должен располагаться перед сегментом команд), то команды обращения к
полям этого сегмента транслируются с добавлением префикса замены для сегмента
ES. При этом предложения программы выглядят обычным образом; в них по-прежнему
просто указываются имена полей данных, к которым производится обращение. mov AX,CS:mem В этом случае транслятор
включит в код команды префикс замены для сегмента CS. Другие примеры команд
с заменой сегмента будут приведены ниже. mov AX,0B800h ;Сегментный
адрес видеобуфера Настроив регистр ES на
сегментный адрес видеобуфера BS00h, мы пересылаем код знака «!» сначала
по относительному адресу 0 (в самое начало видеобуфера, в байт со смещением
0), а затем на следующее знакоместо, имеющее смещение 2 (в нечетных байтах видеобуфера
хранятся атрибуты символов, т. mov byte ptr ES:0, ‘ ! ‘ не имеет возможности определить размер операнда-приемника. Разумеется, видеобуфер, как и любая память, состоит из байтов, однако надо ли рассматривать эту память, как последовательность байтов или слов? Команда без явного задания размера операнда mov ES:0, ‘ ! ‘ вызовет ошибку трансляции,
так как ассемблер не сможет определить, надо ли транслировать это предложение,
как команду пересылки в видеобуфер байта 21h, или как команду пересылки слова
0021h. mov word ptr ES:0,’!’ не вызовет ошибки трансляции,
но приведет к неприятным результатам. В этом случае в видеобуфер будет записано
слово 002lh, которое заполнит байт 0 видеобуфера кодом 21h, а байт 1 кодом 00h.
Однако атрибут 00h обозначает черный цвет на черном фоне, и символ на экране
виден не будет (хотя и будет записан в видеобуфер). mov AL,’!’ mov ES:0,AL Здесь операндом-источником
служит регистр AL, размер которого (1 байт) известен, и размер операнда-приемника
определять не надо. mov ES:0,AX заполнит в видеобуфере
не байт, а слово. mov AX,0B800h ;Сегментный
адрес Любопытно, что хотя обозначение
DS: здесь необходимо, транслятор не включит в код команды префикс замены сегмента,
так как команда без префикса выполняет адресацию по умолчанию через DS. mov 6,10 должна была бы переслать число 10 в число 6, что, разумеется, лишено смысла и выполнено быть не может. Команда же mov DS:6,10 пересылает число 10 по
относительному адресу 6, что имеет смысл. Таким образом, обозначение сегментного
регистра с двоеточием перед операндом говорит о том, что операнд является адресом.
В дальнейшем мы еще столкнемся с этим важным правилом. mov AX,0B800h ;Сегментный
адрес Настроив ES, мы засылаем
в регистр ВХ требуемое смещение (для разнообразия к середине видеобуфера, который
имеет объем точно 4000 байт), и в последней команде засылаем код в видеобуфер
с помощью косвенной базовой адресации через пару регистров ES:BX с указанием
замены сегмента (ES:). mov AX,0B800h ;Сегментный
адрес Кстати, этот фрагмент немного
эффективнее предыдущего в смысле расходования памяти. mov D1,2000 ;Смещение к
середине экрана Не так обстоит дело с регистром
ВР. Этот регистр специально предназначен для работы со стеком, и при адресации
через этот регистр в режимах косвенной адресации подразумевается сегмент стека;
другими словами, в качестве сегментного регистра по умолчанию используется регистр
SS. mov BX,2000 ;Смещение к
середине экрана можно использовать одну mov byte ptr ES:2000,’!’ ;Выведем символ в середину экрана Однако команда с базовой
адресацией занимает меньше места в памяти (так как в нее не входит адрес ячейки)
и выполняется быстрее команды с прямой адресацией (из-за того, что команда короче,
процессору требуется меньше времени на ее считывание из памяти). Поэтому базовая
адресация эффективна в тех случаях, когда по заданному адресу приходится обращаться
многократно, особенно, в цикле. mov AX,0B800h ;Сегментный
адрес В этом примере в качестве
базового выбран регистр DI; в него заносится базовый относительный адрес памяти,
в данном случае смещение в видеобуфере к началу последней строки экрана. ;Основная программа Здесь продемонстрирован
классический прием чтения содержимого стека без извлечения из него этого содержимого. Рис.2.15. Состояние
стека после загрузки в него трех параметров и перехода на подпрограмму Если бы подпрограмма просто
сняла со стека находящиеся там параметры, она первым делом изъяла бы из стека
адрес возврата, и лишила бы себя возможности вернуться в основную программу
(подробнее вопросы вызова подпрограммы и возврата из нее будут обсуждаться в
последующих разделах). Поэтому в данном случае вместо команд pop удобнее воспользоваться
командами mov. Подпрограмма копирует в ВР содержимое трех параметров и перехода
на мое SP и использует затем этот адрес в качестве базового, модифицируя его
с помощью базовой адресации со смещением. ;Сегмент данных Цикл начинается с команды,
помеченной меткой fill (правила образования имен меток такие же, как и для имен
полей данных). В этой команде содержимое АХ, поначалу равное 0, переносится
в ячейку памяти, адрес которой вычисляется, как сумма адреса массива array и
содержимого индексного регистра SI, в котором в первом шаге никла тоже 0. [ВХ] [SI] (подразумевается
DS:[BX][SI]) Это чрезвычайно распространенный
способ адресации, особенно, при работе с массивами. В нем используются два регистра,
при этом одним из них должен быть базовый (ВХ или ВР), а другим — индексный
(SI или DI). ;Сегмент данных Повышение эффективности
достигается за счет того, что команда занесения числа в элемент массива оказывается
короче (так как в нее не входит адрес массива) и выполняется быстрее, так как
этот адрес не надо каждый раз считывать из памяти. sims db «QWERTYUIOP{}’
Последовательность команд загрузит в регистр DL элемент
с индексом 6 из второго ряда, т. mov BX, off set sym |
 С другой стороны, различные способы адресации
определенным образом обозначаются в языке ассемблера и в этом смысле являются
разделом языка.
С другой стороны, различные способы адресации
определенным образом обозначаются в языке ассемблера и в этом смысле являются
разделом языка. Было бы правильнее говорить об операндах машинных команд
и о параметрах, или аргументах команд языка ассемблера.
Было бы правильнее говорить об операндах машинных команд
и о параметрах, или аргументах команд языка ассемблера. Мы будем придерживаться распространенной,
но не единственно возможной терминологии.
Мы будем придерживаться распространенной,
но не единственно возможной терминологии.

 Для сегментного регистра
ES код префикса составляет 26h, для SS — 361i, для CS — 2Eh. Если префикс отсутствует,
сегментный адрес берется из регистра DS (хотя для него тоже предусмотрен свой
префикс).
Для сегментного регистра
ES код префикса составляет 26h, для SS — 361i, для CS — 2Eh. Если префикс отсутствует,
сегментный адрес берется из регистра DS (хотя для него тоже предусмотрен свой
префикс).
 д. Разумеется, такое обращение
возможно только если мы знаем абсолютный адрес интересующей нас ячейки. В этом
случае необходимо сначала настроить один из сегментных регистров на начато интересующей
нас области, после чего можно адресоваться к ячейкам по их смещениям.
д. Разумеется, такое обращение
возможно только если мы знаем абсолютный адрес интересующей нас ячейки. В этом
случае необходимо сначала настроить один из сегментных регистров на начато интересующей
нас области, после чего можно адресоваться к ячейкам по их смещениям. е. цвет символов и фона под ними). В обеих командах
необходимо с помощью обозначения ES: указать сегментный регистр, который используется
для адресации памяти. Встретившись с этим обозначением, транслятор включит в
код команды префикс замены сегмента, в данном случае код 26h.
е. цвет символов и фона под ними). В обеих командах
необходимо с помощью обозначения ES: указать сегментный регистр, который используется
для адресации памяти. Встретившись с этим обозначением, транслятор включит в
код команды префикс замены сегмента, в данном случае код 26h.
 Разумеется, команда
Разумеется, команда Команда (неправильная)
Команда (неправильная) В МП 86 косвенная адресация допустима
только через регистры ВХ, ВР, SI и DI. При использовании регистров ВХ или ВР
адресацию называют базовой, при использовании регистров SI или DI — индексной.
В МП 86 косвенная адресация допустима
только через регистры ВХ, ВР, SI и DI. При использовании регистров ВХ или ВР
адресацию называют базовой, при использовании регистров SI или DI — индексной. Из-за отсутствия в коде
последней команды префикса замены сегмента он занимает на 1 байт меньше места.
Из-за отсутствия в коде
последней команды префикса замены сегмента он занимает на 1 байт меньше места.
 Выигрыш оказывается тем больше, чем большее
число раз происходит обращение по указанному адресу. С другой стороны, возможности
этого режима адресации невелики, и на практике чаще используют более сложные
способы, которые будут рассмотрены ниже.
Выигрыш оказывается тем больше, чем большее
число раз происходит обращение по указанному адресу. С другой стороны, возможности
этого режима адресации невелики, и на практике чаще используют более сложные
способы, которые будут рассмотрены ниже. Модификация
этого адреса с целью получить смещение по строке экрана осуществляется с помощью
констант 2 и 4, которые при вычислении процессором исполнительного адреса прибавляются
к содержимому базового регистра DI.
Модификация
этого адреса с целью получить смещение по строке экрана осуществляется с помощью
констант 2 и 4, которые при вычислении процессором исполнительного адреса прибавляются
к содержимому базового регистра DI. После того, как основная, программа сохранила в стеке три параметра, которые
потребуются подпрограмме, командой call вызывается подпрограмма mysub. Эта команда
сохраняет в стеке адрес возврата (адрес следующего за call предложения основной
программы) и осуществляет переход на подпрограмму. Состояние стека при входе
в подпрограмму приведено на рис. 2.15.
После того, как основная, программа сохранила в стеке три параметра, которые
потребуются подпрограмме, командой call вызывается подпрограмма mysub. Эта команда
сохраняет в стеке адрес возврата (адрес следующего за call предложения основной
программы) и осуществляет переход на подпрограмму. Состояние стека при входе
в подпрограмму приведено на рис. 2.15.
 Действительно, ради краткости мы опустили операции, практически необходимые
в любой подпрограмме — сохранение в стеке (опять в стеке!) тех регистров, которые
будут использоваться в подпрограмме. Кстати, это относится и к регистру ВР.
В реальной подпрограмме эти действия следовало выполнить, что привело бы к изменению
смещений при регистре ВХ, которые приняли бы значения (с учетом сохранения 4
регистров) 10, 12 и 14.
Действительно, ради краткости мы опустили операции, практически необходимые
в любой подпрограмме — сохранение в стеке (опять в стеке!) тех регистров, которые
будут использоваться в подпрограмме. Кстати, это относится и к регистру ВР.
В реальной подпрограмме эти действия следовало выполнить, что привело бы к изменению
смещений при регистре ВХ, которые приняли бы значения (с учетом сохранения 4
регистров) 10, 12 и 14. Нам придется
воспользоваться несколькими новым командами (inc, add и loop), которые в дальнейшем
будут рассмотрены более подробно.
Нам придется
воспользоваться несколькими новым командами (inc, add и loop), которые в дальнейшем
будут рассмотрены более подробно. В
результате в первое слово массива заносится 0. Далее содержимое регистра АХ
увеличивается на 1, содержимое регистра SI — на 2 (из-за того, что массив состоит
из слов), и командой loop осуществляется переход на метку fill, после чего тело
цикла повторяется при новых значениях регистров АХ и SI. Число шагов в цикле,
отсчитываемое командой loop, определяется исходным содержимым регистра СХ.
В
результате в первое слово массива заносится 0. Далее содержимое регистра АХ
увеличивается на 1, содержимое регистра SI — на 2 (из-за того, что массив состоит
из слов), и командой loop осуществляется переход на метку fill, после чего тело
цикла повторяется при новых значениях регистров АХ и SI. Число шагов в цикле,
отсчитываемое командой loop, определяется исходным содержимым регистра СХ. Как правило, в одном из регистров находится адрес массива, а в
другом — индекс в нем, при этом совершенно безразлично, в каком что. Трансформируем
предыдущий пример, введя в него более эффективную базово-индексную адресацию.
Как правило, в одном из регистров находится адрес массива, а в
другом — индекс в нем, при этом совершенно безразлично, в каком что. Трансформируем
предыдущий пример, введя в него более эффективную базово-индексную адресацию.
 е. код ASCII буквы Г. Тот же результат можно
получить, загрузив в один из регистров не индекс, а адрес массива:
е. код ASCII буквы Г. Тот же результат можно
получить, загрузив в один из регистров не индекс, а адрес массива:Использование оператора OFFSET для массива в сборке x86?
Задавать вопрос
спросил
Изменено 7 лет, 10 месяцев назад
Просмотрено 9к раз
Сейчас я прохожу 9Язык ассемблера 0013 для процессоров x86, 6-е издание , автор Кип Р. Ирвин. Это довольно приятно, но что-то меня смущает.
В начале книги показан следующий код:
list BYTE 10,20,30,40 ListSize = ($ - список)
Это имело для меня смысл. Сразу после объявления массива вычтите текущее местоположение в памяти из начального местоположения массива, чтобы получить количество байтов, используемых массивом.
Сразу после объявления массива вычтите текущее местоположение в памяти из начального местоположения массива, чтобы получить количество байтов, используемых массивом.
Однако книга позже делает:
.data массивB БАЙТ 10h,20h,30h .код mov esi, OFFSET arrayB мов ал,[esi] вкл ЕСИ мов ал,[esi] вкл ЕСИ мов ал,[esi]
Насколько я понимаю, OFFSET возвращает положение переменной относительно сегмента программы. Этот адрес хранится в регистре esi . Затем для доступа к значению, хранящемуся по адресу, представленному в esi , используются непосредственные данные. Приращение перемещает адрес к следующим байтам .
Так в чем же разница между использованием OFFSET для массива и простым вызовом переменной массива? Раньше меня убеждали, что простой вызов переменной массива также даст мне ее адрес.
- массивы
- сборка
- x86
- смещение
1
.данные Номер дд 3 .код mov eax,Число mov ebx,смещение Номер
EAX прочитает память по определенному адресу и сохранит число 3
EBX сохранит этот определенный адрес.
mov ebx,смещение Номер
в данном случае эквивалентен
lea ebx,Number
1
Зарегистрируйтесь или войдите в систему
Зарегистрируйтесь с помощью Google
Зарегистрироваться через Facebook
Зарегистрируйтесь, используя электронную почту и пароль
Опубликовать как гость
Электронная почта
Требуется, но не отображается
Опубликовать как гость
Электронная почта
Требуется, но не отображается
Конспект лекций — Глава 12
Конспект лекций — Глава 12 — СборкаПРОЦЕСС СБОРКИ -------------------- -- компьютер понимает машинный код -- люди (и компиляторы) пишут на ассемблере сборка ------------------ машина источник --> | ассемблер | --> код код ------------------ ассемблер — это программа — очень детерминированная программа — он переводит каждую инструкцию в свой машинный код.Раньше между ними существовала прямая переписка. инструкции языка ассемблера и инструкции машинного языка. это уже не так. Ассемблеры в настоящее время сделаны больше мощный и может «переделывать» код. Pentium (основанный на 8086) имеет один к одному соответствие между инструкциями на языке ассемблера и инструкции машинного языка. СБОРКА --------- работа сборщика состоит в том, чтобы 1. назначить адреса 2. сгенерировать машинный код ассемблер будет -- назначить адреса -- сгенерировать машинный код -- сгенерировать образ того, как должна выглядеть память для программа, которую нужно выполнить. простой ассемблер сделает 2 полных прохода по данным (исходный код) для выполнения этой задачи. проход 1: создать полную ТАБЛИЦУ СИМВОЛОВ генерировать машинный код для инструкций, отличных от ветки, прыжки, зов, леа и т. д. (эти инструкции которые полагаются на адрес для своего машинного кода). проход 2: полный машинный код для инструкций, которые не получили закончился в проходе 1.
ассемблер начинается в начале исходного кода программы, и СКАНЫ. Он ищет -- директивы (.data .code .stack .486 и т.д.) -- инструкции ВАЖНЫЙ: есть отдельные области памяти для данных и инструкций. ассемблер размещает их в ПОСЛЕДОВАТЕЛЬНОМ ПОРЯДКЕ по мере сканирования через исходный код программы. начальные адреса фиксированы -- будет собрана ЛЮБАЯ программа иметь данные и инструкции, которые начинаются с одного и того же адреса. Генерация машинного кода для инструкции --------------------------------------------------------- Это сложно из-за большого разнообразия адресации. режимов в сочетании с большим количеством инструкций. Чаще всего машинный код инструкции состоит из 1) 8-битный код операции (выбор опкода будет несколько зависеть от адресации режимы, используемые для операндов) с последующим 2) один или несколько байтов, описывающих режимы адресации для операнды. ПРИМЕР ИНСТРУКЦИИ: добавить еакс, 24 Найдите Приложение C. Именно там находится весь этот машинный код.
материал указан. Для инструкции добавления в таблице перечислены: добавить рег, р/м 03 /р об/м, рег 01 /об р/м, иммед 81/0 id Единственный, который будет соответствовать типам операндов, это третий в списке: добавить r/m, immed 81/0 id Итак, это тот, который мы выбираем. 81 — это 8-битный код операции. За опкодом следует информация об адресации режим 2-х операндов (у сложения всегда ровно 2 операнда и режим адресации каждого должен быть явно указан) Обычно оба операнда описываются (точно) кодирование одного байта, который Intel называет байтом ModR/M. В описании машинного кода (идентификатор 81/0) Символ /0 описывает часть этого байта ModR/M. /0 можно найти в таблице пояснений на странице 352. В нем говорится, что поле reg байта ModR/M равно 000. Байт ModR/M: Этот байт описывает режим адресации операндов. Он разделен на 3 поля следующим образом БИТЫ 7 6 5 4 3 2 1 0 мод reg/opcode r/m Для этого примера инструкции биты 5, 4, 3 установлены на 000, давать БИТЫ 7 6 5 4 3 2 1 0 мод reg/opcode r/m 0 0 0 Это говорит о том, что второй операнд является немедленным.
Описание первого операнда будет сделано с помощью поля режима и r/m байта ModR/M. Посмотрите в таблице (стр. 353), чтобы найти режим регистрации, используя регистр EAX (поскольку он есть в примере инструкции). В таблице указано, что Mod равен 11, R/M равен 000, что дает БИТЫ 7 6 5 4 3 2 1 0 мод reg/opcode r/m 1 1 0 0 0 0 0 0 Последний шаг — получить часть идентификатора. Из объяснения table (стр. 352), id описан как 32-битный непосредственный. Поэтому id соответствует 32-битному представлению с дополнением до двух. стоимости 24. Это 0000 0000 0000 0000 0000 0000 0001 1000 В шестнадцатеричном формате это 0x00000018. Собрав все это воедино, мы получаем машинный код для пример инструкции ( добавить eax, 24 ) Обратите внимание, что все в шестнадцатеричном формате. И непосредственные значения указываются младшим значащим байтом первым! код операции 81 ModR/M байт с0 немедленный 18 00 00 00 Написано слева направо: 81 с0 18 00 00 00 Еще один пример генерации машинного кода.
Машинный код для инструкции Pentium dec двойное слово ptr [EDX] Со страницы 349, нам нужна форма инструкции декремента дек р/м фф /1 Код операции ff, и он описывает, что будет один операнд, и это общего вида. /1 говорит, что Поле Reg байта ModR/M будет равно 001. БИТЫ 7 6 5 4 3 2 1 0 Mod Reg/Opcode R/M 0 0 1 В таблице на стр. 353 описаны поля Mod и R/M. Найдите режим прямой адресации регистра, используя регистр EDX в таблице. Это дает Mod 00 и R/M 010. БИТЫ 7 6 5 4 3 2 1 0 Mod Reg/Opcode R/M 0 0 0 0 1 0 1 0 В шестнадцатеричном формате это 0a. Теперь машинный код завершен: ff 0a. БОЛЬШОЙ ПРИМЕР: .данные а1 дд 4 а2 дд? а3 дд 5 дуп(0) .код главная: mov ecx, 20 мов акс, 15 мов эдкс, 0 jz target_label loop1: добавить edx, eax имул [эбп + 8] дек экх джг петля1 target_label: сделанный Первый шаг: сборка раздела данных. При сканировании исходного кода считывается токен .data. Это директива, которая сообщает ассемблеру, что последующее выделяется в разделе данных программы.
Помните, что директива — это «команда» для ассемблера. о том, как собрать исходный код. Следующая встреченная лексема — это метка a1. Этот символ (метка) еще не находится в своей таблице символов, поэтому ассемблер присваивает адрес и помещает его в символ стол. Помните, ассемблер назначает первый доступный адрес в разделе данных. Таблица символов адрес символа --------------------- a1 0040 0000 (я придумал этот адрес, потому что нам нужно начальный адрес раздела данных.) Следующий токен — dd. Это позволяет ассемблеру знать, что нужно выделить одно двойное слово пробела по текущему адресу. Следующий токен равен 4. Он сообщает ассемблеру, что значение выделенное пространство должно иметь значение 4. Следующая строка делает то же самое, размещение a2 в таблице символов по следующему доступному адресу (0x0040 0004) выделение 1 двойного слова не помещая что-то конкретное в выделенное пространство Когда закончите с разделом данных, у нас будет таблица символов адрес символа --------------------- а1 0040 0000 а2 0040 0004 а3 0040 0008 0040 000с 0040 0010 0040 0014 0040 0018 0040 001c (следующий доступный адрес в раздел данных.
НЕ ЧАСТЬ ТАБЛИЦЫ.) и, карта памяти раздела данных адрес содержание примечания шестигранник 0040 0000 0000 0004 для а1 0040 0004 0000 0000 для a2 (по умолчанию 0) 0040 0008 0000 0000 5 двойных слов для a3 0040 000с 0000 0000 0040 0010 0000 0000 0040 0014 0000 0000 0040 0018 0000 0000 При встрече с директивой .code ассемблер знает, что следующие адреса, которые он назначает, будут находиться в разделе кода программы (отдельно от данных). Предположим, что код будет собран таким образом, что первый инструкция размещается по адресу 0x0000 0000. Код (повторяется): .код главная: mov ecx, 20 мов акс, 15 движение акс, 0 jz target_label loop1: добавить edx, eax имул [эбп + 8] дек экх джг петля1 target_label: сделанный Первый токен, полученный после директивы .code является основным ярлыком. (Как и для ВСЕХ символов) ассемблер проверяет, находится ли этот символ уже в таблице символов. Это не так, поэтому ассемблер назначает первый доступный адрес и помещает его в таблицу символов.
таблица символов адрес символа --------------------- а1 0040 0000 а2 0040 0004 а3 0040 0008 0040 000с 0040 0010 0040 0014 0040 0018 0040 001c (следующий доступный адрес в раздел данных. НЕ ЧАСТЬ ТАБЛИЦЫ.) основной 0000 0000 Далее ассемблер подбирает токен mov. Он знает, что это инструкция, и читает остальную часть инструкции чтобы сгенерировать машинный код для этой инструкции. мов экх, 20 мов рег, immed b8 + rd Байт ModR/M не требуется, так как регистр встроен в байт кода операции, и немедленное должно следовать. rd (из таблицы на стр. 352) равно 1, b8+1=b9Непосредственный 0x00000014. Итак, машинный код будет б9 14 00 00 00 Эти 5 байт размещаются по адресу 0x0000 0000, и следующий доступный адрес для инструкции становится 0x0000 0005. Ассемблер готов к следующему токену. Это будет вторая инструкция mov в программе. Он знает, что это инструкция, и читает остальную часть инструкции чтобы сгенерировать машинный код для этой инструкции.
мов акс, 15 мов рег, immed b8 + rd Байт ModR/M не требуется, так как регистр встроен в байт кода операции, и немедленное должно следовать. rd (из таблицы на стр. 352) равно 0, b8+0=b8 Непосредственный 0x0000000f. Итак, машинный код будет б8 10 00 00 00 Эти 5 байт размещаются по адресу 0x0000 0005, и следующий доступный адрес для инструкции становится 0x0000 000а. Ассемблер готов к следующему токену. Это будет инструкция третьего хода в программе. Он знает, что это инструкция, и читает остальную часть инструкции чтобы сгенерировать машинный код для этой инструкции. мов эдкс, 0 мов рег, immed b8 + rd Байт ModR/M не требуется, так как регистр встроен в байт кода операции, и немедленное должно следовать. rd (из таблицы на стр. 352) равно 2, b8+2=ba Непосредственный 0x00000000. Итак, машинный код будет ба 00 00 00 00 Эти 5 байт размещаются по адресу 0x0000 000a, и следующий доступный адрес для инструкции становится 0x0000 000f.
Ассемблер готов к следующему токену. Это будет jz инструкция в программе. Он знает, что это инструкция, и читает остальную часть инструкции чтобы сгенерировать машинный код для этой инструкции. jz target_label jz rel32 0f 84 "кд" «cd» — это 32-битное смещение кода. Это должно быть разница между тем, каким будет ПК при выполнении этого code и адрес, назначенный для метки target_label. Проблема в том, что target_label еще не присвоен адрес. Итак, ассемблеру нужно подождите, пока выяснится часть смещения 32-битного кода этой инструкции до второго прохода ассемблера. Ассемблер знает, что эта инструкция будет ровно 6 байт, так что можно продолжить сборку по адресу 0x0000 0015. Карта памяти текстового раздела на данный момент: карта памяти текстового раздела содержимое адреса 0000 0000 б914 00 00 00 0000 0005 b8 0f 00 00 00 0000 000а ба 00 00 00 00 0000 000f 0f 84 ?? ?? ?? ?? 0000 0015 Ассемблер готов к следующему токену. Это будет метка петля1.
Ассемблер проверяет, находится ли этот символ в таблица символов. Это не так, поэтому ассемблер присваивает адрес и помещает символ в таблицу. таблица символов адрес символа --------------------- а1 0040 0000 а2 0040 0004 а3 0040 0008 0040 000с 0040 0010 0040 0014 0040 0018 0040 001c (следующий доступный адрес в раздел данных. НЕ ЧАСТЬ ТАБЛИЦЫ.) основной 0000 0000 петля1 0000 0015 Ассемблер готов к следующему токену. Это будет добавить инструкцию в программу. Он знает, что это инструкция, и читает остальную часть инструкции чтобы сгенерировать машинный код для этой инструкции. добавить edx, eax добавить рег, р/м 03 /р или добавить р/м, reg 01 /р Мне все равно, какой из них выбран. Они одинаковая длина. Выбрал первый. /r означает, что байт ModR/M имеет регистр операнд и операнд R/M. БИТЫ 7 6 5 4 3 2 1 0 Mod Reg/Opcode R/M 1 1 0 1 0 0 0 0 В шестнадцатеричном формате это d0.
Итак, машинный код инструкции — 03 d0. Эти 2 байта размещаются по адресу 0x0000 0015. Следующий доступный адрес для кода будет 0x0000 0017. Карта памяти текстового раздела на данный момент: карта памяти текстового раздела содержимое адреса 0000 0000 б914 00 00 00 0000 0005 b8 0f 00 00 00 0000 000а ба 00 00 00 00 0000 000f 0f 84 ?? ?? ?? ?? 0000 0015 03 д0 0000 0017 К следующей инструкции. имул [эбп + 8] импульс р/м f7/5 /5 означает, что байт ModR/M имеет регистр поле 101 Режим адресации для [ebp + 8] находится под disp32[EBP] в таблице на стр. 353. БИТЫ 7 6 5 4 3 2 1 0 Mod Reg/Opcode R/M 1 0 1 0 1 1 0 1 В шестнадцатеричном формате это объявление. 32-битное смещение следует за байтом ModR/M. Это содержит 32-битное кодирование с дополнением до 2 для значения 8. 0x 00 00 00 08 Машинный код этой инструкции — f7 ad 08 00 00 00. Эти 6 байт размещаются по адресу 0x0000 0017. Следующий доступный адрес для кода будет 0x0000 0019.. Карта памяти текстового раздела на данный момент: карта памяти раздела кода содержимое адреса 0000 0000 b9 14 00 00 00 0000 0005 b8 10 00 00 00 0000 000а ба 00 00 00 00 0000 000f 0f 84 ?? ?? ?? ?? 0000 0015 03 д0 0000 0017 f7 объявление 08 00 00 00 0000 001д Следующая инструкция проста.
дек экх декабрь обр. 48 + рд rd равен 1 для ecx. Таким образом, машинный код — это один байт 49. карта памяти раздела кода содержимое адреса 0000 0000 b9 14 00 00 00 0000 0005 b8 10 00 00 00 0000 000а ба 00 00 00 00 0000 000f 0f 84 ?? ?? ?? ?? 0000 0015 03 д0 0000 0017 f7 объявление 08 00 00 00 0000 001д 4
001е За командой декремента следует джг петля1 jg rel32 0f 8f "кд" Как и другая инструкция управления: "cd" - это 32-битное смещение кода. Это должно быть разница между тем, каким будет ПК при выполнении этого code и адрес, назначенный для метки target_label. Ассемблер знает, что эта инструкция будет ровно 6 байт. Чтобы вычислить "cd", во время выполнения (для принятой управляющей инструкции): содержимое поля PC + offset --> PC ПК указывает на инструкцию после управляющей инструкции при добавлении смещения. во время сборки: смещение байта = целевой адрес - ( адрес инструкции после условного управляющий адрес ) = адрес петли 1 - (6 + 0x0000 001e) (взято из таблицы символов) = 0x0000 0015 - 0x0000 0024 Обратите внимание, что это будет отрицательное число.
То есть OK -- сгенерировать 32-битное значение дополнения до 2. 0000 0000 0000 0000 0000 0000 0001 0101 - 0000 0000 0000 0000 0000 0000 0010 0100 --------------------------------------------------------- становится 0000 0000 0000 0000 0000 0000 0001 0101 + 1111 1111 1111 1111 1111 1111 1101 1100 --------------------------------------------------------- 1111 1111 1111 1111 1111 1111 1111 0001 в шестнадцатеричном формате 0x ff ff ff f1 это значение "cd", давая машинный код 0f 8f f1 ff ff ff (Помните, что младший байт идет первым.) Снова, карта памяти раздела кода (пока) содержимое адреса 0000 0000 б914 00 00 00 0000 0005 b8 10 00 00 00 0000 000а ба 00 00 00 00 0000 000f 0f 84 ?? ?? ?? ?? 0000 0015 03 д0 0000 0017 f7 объявление 80 00 00 00 0000 001д 49 0000 001e 0f 8f f1 ff ff ff 0000 0024 Последнее, о чем мы будем беспокоиться в таблице, это следующая метка: target_addr Он помещается в таблицу символов в следующий доступный адрес, 0x0000 0024.
Теперь у нас есть заполненная таблица символов: адрес символа --------------------- а1 0040 0000 а2 0040 0004 а3 0040 0008 0040 000с 0040 0010 0040 0014 0040 0018 0040 001c (следующий доступный адрес в раздел данных. НЕ ЧАСТЬ ТАБЛИЦЫ.) основной 0000 0000 петля1 0000 0015 target_addr0000 0024 После того, как этот первый проход ассемблера выполнен, ВСЕ ярлыкам были даны адреса. Во время этого второго прохода ассемблера все оставшиеся код, оставшийся для завершения, завершен. Для этого примера фрагмент кода, то есть инструкция jz по адресу 0x0000 000f. Остается только вычислить смещение. Это работает так же, как расчет для другой команды управления. смещение байта = целевой адрес - ( адрес инструкции после условного управляющий адрес ) = адрес целевой_адрес - (6 + 0x0000 000f) (взято из таблицы символов) = 0x0000 0024 - 0x0000 0015 0000 0000 0000 0000 0000 0000 0010 0100 - 0000 0000 0000 0000 0000 0000 0001 0101 --------------------------------------------------------- 0000 0000 0000 0000 0000 0000 0000 1111 Обратите внимание, что это смещение является положительным числом.

