Какие преимущества имеют ПЛИС перед графическими процессорами в радиолокационных системах. Как ПЛИС применяются для обработки радиолокационной информации. Почему ПЛИС эффективнее графических процессоров при работе с небольшими объемами данных. Какие инструменты используются для программирования ПЛИС.
Преимущества ПЛИС в радиолокационных системах
Программируемые логические интегральные схемы (ПЛИС) имеют ряд существенных преимуществ перед графическими процессорами (GPU) при использовании в радиолокационных системах:
- Более высокая эффективность при работе с небольшими объемами данных, характерными для радиолокации
- Меньшее время задержки обработки сигналов
- Более высокая пропускная способность ввода/вывода
- Значительно меньшее энергопотребление
- Возможность прямой обработки потоковых данных от АЦП
Применение ПЛИС для обработки радиолокационной информации
ПЛИС широко применяются на различных этапах обработки радиолокационной информации:

- Первичная обработка сигналов
- Быстрое преобразование Фурье (БПФ)
- Формирование диаграммы направленности
- Пространственно-временная адаптивная обработка (STAP)
- Сжатие импульсов
- Доплеровская фильтрация
- Обнаружение движущихся целей
Эффективность ПЛИС при работе с небольшими объемами данных
ПЛИС демонстрируют значительно более высокую эффективность по сравнению с GPU при обработке небольших объемов данных, характерных для многих радиолокационных алгоритмов. Это обусловлено несколькими факторами:
- Архитектура ПЛИС позволяет создавать оптимизированные параллельные тракты обработки данных
- ПЛИС не имеют ограничений по пропускной способности ввода/вывода, характерных для GPU
- Отсутствие необходимости обрабатывать тысячи потоков для эффективной работы, как в GPU
- Возможность выполнять одну операцию за один такт в каждом тракте данных
Сравнение производительности ПЛИС и GPU на примере алгоритма Холецкого
Алгоритм Холецкого часто используется в радиолокации для решения систем линейных уравнений. Сравнение производительности ПЛИС и GPU на этом алгоритме наглядно демонстрирует преимущества ПЛИС при работе с матрицами небольшого размера:
- ПЛИС Altera Stratix V (460K логических элементов):
- Матрица 360×360: 91 GFLOPS
- Матрица 60×60: 84 GFLOPS (2 ядра)
- Матрица 30×30: 75 GFLOPS (3 ядра)
- GPU NVIDIA (1.35 TFLOPS):
- Матрица 512×512: 58.4 GFLOPS
- Матрица 1024×1024: 67.96 GFLOPS
Как видно из приведенных данных, ПЛИС демонстрирует значительно более высокую производительность на матрицах меньшего размера, которые типичны для радиолокационных систем.
Инструменты для программирования ПЛИС
Для эффективного программирования ПЛИС в радиолокационных системах используются специализированные инструменты:
- Библиотека DSP Builder Advanced Blockset от Altera — позволяет эффективно реализовывать алгоритмы с плавающей точкой на ПЛИС
- Язык OpenCL с расширениями для ПЛИС — обеспечивает возможность портирования кода с GPU на ПЛИС
- Языки описания аппаратуры Verilog и VHDL — традиционные средства программирования ПЛИС
Энергоэффективность ПЛИС в радиолокационных системах
Одним из ключевых преимуществ ПЛИС в радиолокационных системах является их высокая энергоэффективность. Измерения показывают:

- ПЛИС: 5-10 GFLOPS/Вт в зависимости от сложности алгоритма
- GPU: около 0.25 GFLOPS/Вт на алгоритме Холецкого
Таким образом, ПЛИС потребляют в 20-40 раз меньше энергии на единицу производительности по сравнению с GPU. Это критически важно для мобильных и бортовых радиолокационных систем, где размер, вес и энергопотребление играют ключевую роль.
Перспективы применения ПЛИС в радиолокационных системах
Развитие технологий ПЛИС открывает новые перспективы их применения в радиолокационных системах:
- Создание радиолокационных систем с производительностью в десятки TFLOPS при низком энергопотреблении
- Реализация сложных алгоритмов адаптивной обработки сигналов в реальном времени
- Разработка компактных многофункциональных радиолокационных систем для беспилотных аппаратов
- Создание программно-определяемых радиолокационных систем с гибкой архитектурой
Использование современных ПЛИС позволяет значительно повысить производительность и функциональные возможности радиолокационных систем при снижении их массогабаритных характеристик и энергопотребления. Это открывает новые возможности для развития радиолокационной техники различного назначения.
ПЛИС — интегральные схемы программируемой логики
Основные понятия ПЛИС
В русскоязычной литературе любую программируемую логику принято называть термином ПЛИС (программируемая логическая интегральная схема). В англоязычной литературе принято различать следующие разновидности программируемых микросхем: PLA, PAL, GAL, SPLD, CPLD, ASIC, FPGA, FPAA, FPID, SoCи т.д.
ПЛИС PLA (Programmable Logic Array)
Программируемые логические интегральные схемы PLA
Программируемые логические интегральные схемы наподобие ППЗУ. В данных устройствах оба массива элементов и , и являются программируемыми. На рисунке схематично представлен вариант содержащий две программные плоскости и имеющие по четыре входа и выхода.
В данных устройствах оба массива элементов и , и являются программируемыми. На рисунке схематично представлен вариант содержащий две программные плоскости и имеющие по четыре входа и выхода.
ПЛИС PAL (Programmable Array Logic)
Программируемые логические интегральные схемы PAL
Программируемые логические интегральные схемы наподобие ППЗУ. Однако, в отличие от последних, в данных схемах массив элементов является программируемым, а массив — нет. Для примера рассмотрим простую PAL с тремя входами и тремя выходами.
ПЛИС GAL (Generic Array Logic)
Устройства PAL и PLA – однократно программируемые, их конфигурация не может быть изменена; в отличие от них микросхемы GAL основаны на EEPROM и могут реконфигурироваться. Микросхемы GAL были изобретены Lattice Semiconductor. Аналогичные устройства, PEEL (programmable electrically erasable logic), были предложены International CMOS Technology (ICT).
ПЛИС SPLD (Simple Programmable Logic Devices)
В англоязычной литературе микросхемы PROM, PAL, PLA, GAL принято обобщать термином SPLD.
Программируемые логические интегральные схемы SPLD
ПЛИС CPLD (Complex PLD). Разновидность ПЛИС, содержащая относительно крупные программируемые логические блоки — макроячейки (англ. macrocells), соединённые с внешними выводами и внутренними шинами.
Программируемые логические интегральные схемы CPLD
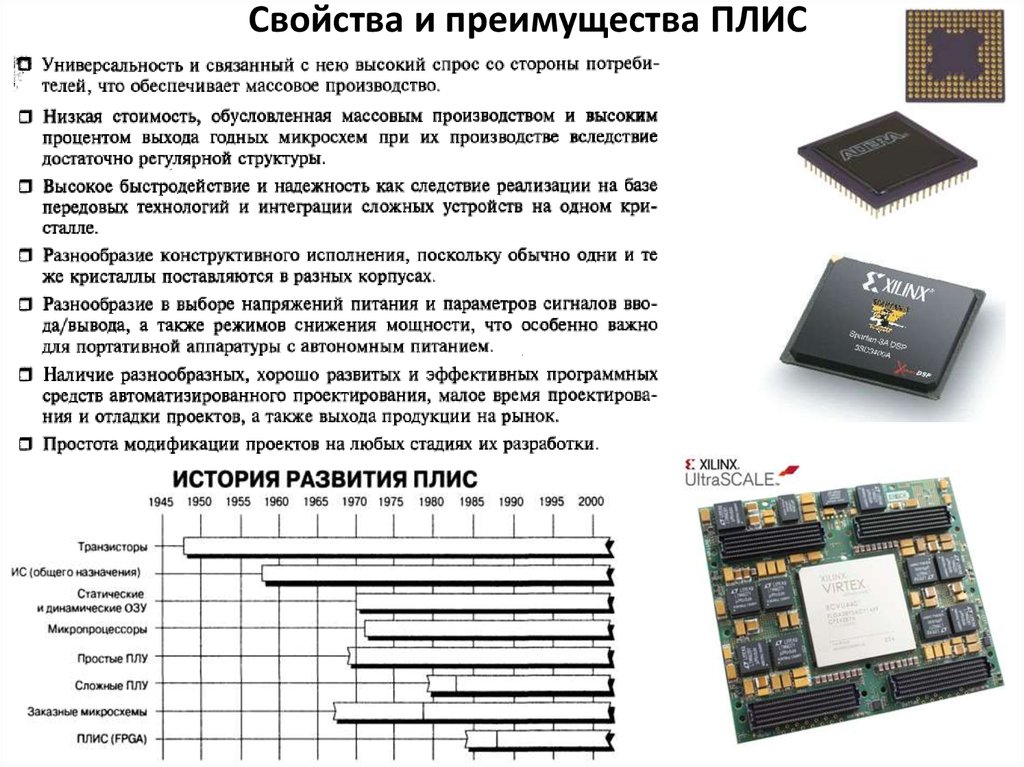
Существенный прорыв в разработке ПЛИС произошел в 1984г., когда компания Altera предложила CPLD, применив сочетание CMOS и EPROM технологий. Использование технологии CMOS позволило достичь значительной функциональной плотности и сложности при сравнительно небольшом потреблении энергии, а ячейки (англ. cells) EPROM оказались идеальным средством для использования их при разработке и создании прототипов оборудования.
ПЛИС ASIC (Application Specific IC)
Заказная интегральная схема для решения конкретной задачи. Микросхема способна выполнять ограниченный набор функций с высокой эффективностью. Является своего рода конкурентом ПЛИС. В русскоязычной терминологии — БМК – базовый матричный кристалл, т.
ПЛИС FPGA (Field Programmable Gate Array)
Программируемые логические интегральные схемы FPGA
Разновидность ПЛИС, содержащая логические элементы и блоки коммутации. Программа для FPGA хранится в распределённой оперативной памяти микросхемы, поэтому требуется начальный загрузчик.
Примерно к 80-х годам 20 столетия на рынке цифровых микросхем сложилась ситуация, когда возникла ниша между наличием сложных и дорогих в производстве микросхем ASIC и PLD (SPLD и CPLD). Эта ниша заполнилась микросхемами FPGA. Разработчиком FPGA является основатель компании Xilinx Росс Фримен — изобретатель концепции матричного кристалла программируемого пользователем (FPGA).
Развитие архитектур ПЛИС привело к созданию комбинированных структур сочетающих достоинства FPGA и CPLD – например, семейство FLEX (Flexible Logic Element Matrix) от Altera.
ПЛИС FPAA (Field Programmable Analog Array)
Программируемые логические интегральные схемы FPAA
Традиционно схемы аналоговой обработки сигналов выполняются на дискретных компонентах. В ряде случаев аналоговая часть занимает значительную площадь печатной платы и требует сложной настройки. Решить проблему создания аналоговых устройств (иногда для определенной полосы частот спектра) позволяет использование программируемых аналоговых микросхем. На настоящий момент крупнейшим производителем таких микросхем является компания Anadigm.
ПЛИС FPID (Field Programmable Interconnect Device)
Эти программируемые логические интегральные схемы содержат программируемые соединения и блоки ввода/вывода, но не содержат логических блоков. Они предназначены для произвольного соединения своих внешних выводов в соответствии с заложенной программой. При отработке прототипов и при создании динамически конфигурируемых систем такие микросхемы весьма полезны. Соединяя ПЛИС через FPIC можно легко варьировать их межсоединения, чего не обеспечивают технологии с жесткой трассировкой (печатные платы и др. ).
).
ПЛИС SoC (System on Chip)
Уменьшение топологических норм проектирования и ряд технологических усовершенствований довели уровень интеграции современных программируемых логических интегральных схем до величин в несколько миллионов эквивалентных вентилей, а быстродействие — до тактовых частот в сотни мегагерц. На таких кристаллах размещают целиком всю цифровую систему (процессор, память, интерфейсы, и др.).
Применение ПЛИС
ПЛИС SPLD
Микросхемы SPLD по-прежнему выпускаются многими производителями. Среди них есть и такие всемирно известные корпорации, как Texas Instruments, NXP, Lattice. У Lattice такие компоненты называются «mature devices», т. е. зрелые, продуманные. Для программирования логических интегральных схем SPLD были разработаны специальные программы (логические компиляторы) для перевода булевых уравнений, таблиц истинности или диаграмм состояний в так называемый файл JEDEC* — закодированный в стандартизированной форме список плавких перемычек, которые следует уничтожить. В дальнейшем, при появлении новых типов ПЛИС, логические компиляторы стали называться языками HDL (Hardware Description Language). На сайте NXP приведены варианты использования компонентов SPLD, в AN036 рассматривается применение микросхемы PLC42VA12 в контроллере расширителя интерфейса I2C.
В дальнейшем, при появлении новых типов ПЛИС, логические компиляторы стали называться языками HDL (Hardware Description Language). На сайте NXP приведены варианты использования компонентов SPLD, в AN036 рассматривается применение микросхемы PLC42VA12 в контроллере расширителя интерфейса I2C.
Компания Altera предлагает несколько вариантов применения CPLD серии MAX V**:
1. ПЛИС CPLD применяется для расширения количества портов ввода/вывода других стандартных устройств.
Применение ПЛИС CPLD для расширения количества портов
2. Программируемые логические интегральные схемы CPLD применяются для создания мостов (bridge’s) между интерфейсами, т. е. для соединения друг с другом несовместимых по протоколам устройств.
Применение ПЛИС CPLD для создания мостов
3. Так же ПЛИС CPLD применяется для управления последовательностью включения источников питания и мониторинга других устройств.
Применение ПЛИС CPLD для управления последовательностью включения источников питания
4. Программируемые логические интегральные схемы CPLD могут быть использованы для управления конфигурацией или инициализацией других устройств.
Программируемые логические интегральные схемы CPLD могут быть использованы для управления конфигурацией или инициализацией других устройств.
Применение ПЛИС CPLD для управления конфигурацией или инициализацией других устройств
5. ПЛИС CPLD для управления стандартными аналоговыми устройствами в цифровом формате посредством широтно-импульсной модуляции (ШИМ) без применения ЦАП. LUT-архитектура CPLD, выходы с высокой нагрузочной способностью и внутренний генератор микросхемы позволяют обеспечить прямое соединение этой микросхемы с различными стандартными аналоговыми продуктами при использовании ШИМ.
————————————
*JEDEC Standard JESD3-C, Standard Data Transfer Format Between Data Preparation System and Programmable Logic Device Programmer, June 1994.
**Altera, WP-01146-1.2
Коок Д.А.
Обработка радиолокационной информации: ПЛИС ?
Введение
ПЛИС и процессоры (CPU) уже давно являются неотъемлемой частью устройств обработки радиолокационной информации. ПЛИС традиционно используют для первичной обработки информации, а процессоры (CPU) — для ее окончательной обработки. Радиолокационные системы (РЛС) наращивают свои возможности и усложняются, что приводит к резкому росту требований в области обработки информации. ПЛИС сохранили темпы увеличения производительности обработки информации и пропускную способность, в то время как процессоры отставали в обеспечении производительности обработки сигнала в РЛС нового поколения. Поэтому что бы обеспечить работу при столь больших нагрузках пришлось прийти к использованию процессорных ускорителей, таких как графические ускорители (GPU).
ПЛИС традиционно используют для первичной обработки информации, а процессоры (CPU) — для ее окончательной обработки. Радиолокационные системы (РЛС) наращивают свои возможности и усложняются, что приводит к резкому росту требований в области обработки информации. ПЛИС сохранили темпы увеличения производительности обработки информации и пропускную способность, в то время как процессоры отставали в обеспечении производительности обработки сигнала в РЛС нового поколения. Поэтому что бы обеспечить работу при столь больших нагрузках пришлось прийти к использованию процессорных ускорителей, таких как графические ускорители (GPU).
За последние несколько лет GPU получили мощные платформы для операций с плавающей запятой, известные как GP-GPU, которые дают высокую пиковую производительность для операций с плавающей запятой в секунду (FLOPs). ПЛИС, традиционно использовавшиеся для обработки цифрового сигнала (DSP) с фиксированной точкой, теперь предлагают конкурирующие уровни производительности для операций с плавающей точкой, что делает их подходящими для быстрой конечной обработки информации с РЛС.
Высокопроизводительные ПЛИС корпорации Altera следующего поколения будут иметь производительность как минимум 5 TFLOPs, используя ядро Intel 14 Нм Tri-Gate. Можно ожидать получение производительности до 100 GFLOPs/Вт, используя эту передовую технологию изготовления полупроводниковых приборов. Более того, ПЛИС корпорации Altera теперь поддерживают язык OpenCL, используемый в графических процессорах.
Оценка ПЛИС с пиковой производительностью в GFLOPs
Современные ПЛИС имеют производительность в 1+ пиковая TFLOPs [1], в то время как новейшие графические процессоры AMD и Nvidia обладают более высокой производительностью, примерно до 4 TFLOPs. Однако для ПЛИС с пиковой производительностью в GFLOPs или TFLOPs имеется мало информации о производительности данного устройства в конкретном применении. На нем просто указывается общее число теоретических сложений и умножений с плавающей запятой, которые могут быть выполнены в секунду. Этот анализ показывает, что ПЛИС во многих случаях превышают пропускную способность GPU по алгоритмам и объемам данных при обработке информации РЛС.
Общим алгоритмом средней сложности является быстрое преобразование Фурье (FFT). Поскольку РЛС зачастую выполняют большую часть обработки информации в частотной области, очень часто используется алгоритм FFT. Например, расчет FFT на 4096 точек может быть выполнен с помощью операций с плавающей запятой одинарной точности. Это дает возможность ввода и вывода четырех комплексных выборок за один временной цикл. Каждое ядро с алгоритмом FFT может работать с производительностью 80 GFLOPs, а большая ПЛИС, созданная по 28‑нм технологии, может заменить семь таких ядер.
Однако, как показано на рис. 1, производительность алгоритма FFT на этой ПЛИС равна почти 400 GFLOPs. Этот результат основан на компиляции в среде OpenCL, без опробования на ПЛИС. При использовании логики блокирования и Design Space Explorer (DSE) при оптимизации семиядерная архитектура сможет достичь fmax одноядерной архитектуры, повышая эту величину более чем до 500 GFLOPs, то есть с более чем 10 GFLOPs/Вт при использовании ПЛИС, изготовленной по 28‑нм технологии.![]()
Рис. 1. Производительность ПЛИС с алгоритмом FFT Stratix V 5SGSD8 и плавающей запятой
С точки зрения сравнения параметров графических процессоров, они не являются эффективными на этих длинах быстрого преобразования Фурье, и поэтому таблицы истинности здесь не представлены. Использование GPU становится эффективным с длинами быстрого преобразования Фурье на нескольких сотнях тысяч точек, когда оно может дать полезное ускорение для процессора. Однако короткие длины преобразования Фурье широко распространены при обработке радиолокационной информации, где длины 512–8192 точек являются нормой.
В целом полезная производительность в GFLOPs зачастую представляет собой долю пиковой или теоретической производительности. По этой причине для сравнения лучше всего использовать такой алгоритм, который дает корректное представление характеристик для типовых применений. Хотя алгоритм таблиц истинности и увеличивает сложность, но он дает более представительную фактическую производительность РЛС.
Алгоритм таблиц истинности
Вместо того чтобы полагаться на приводимую производителем пиковую производительность в GFLOPs, в технологических устройствах обработки информации следует использовать альтернативу в виде сторонних оценок с использованием примеров достаточной сложности. Общим алгоритмом для обработки данных с пространственно-временной адаптацией (Space-Time Adaptive Processing, STAP) РЛС является разложение Холецкого. Этот алгоритм часто используется в линейной алгебре для эффективного решения множественных уравнений и может быть использован в корреляционных матрицах.
Алгоритм Холецкого имеет высокую числовую сложность и почти всегда требует численного представления с плавающей запятой для получения корректных результатов. Необходимые вычисления пропорциональны N3, где N — размер матрицы. Поскольку РЛС обычно работают в режиме реального времени, обязательным требованием является высокая пропускная способность. Результат будет зависеть от размера матрицы и пропускной способности для требуемой обработки матрицы, что часто составляет более 100 GFLOPs.
В таблице 1 представлены результаты сравнительного анализа графического процессора Nvidia с номиналом в 1,35 TFLOPs и использованием различных библиотек, и Xilinx Virtex6 XC6VSX475T, оптимизированной ПЛИС для обработки цифрового сигнала с фиксированной запятой (DSP) с плотностью распределения 475K LCs. Эти устройства схожи по плотности с ПЛИС корпорации Altera, использующими таблицы истинности Холецкого. Библиотеки LAPACK и MAGMA являются коммерческими библиотеками, в то время как ядро графического процессора с производительностью в GFLOPs использует язык программирования OpenCL, разработанный в университете штата Теннесси [2]. Приведенные ниже данные со всей очевидностью показывают больший уровень оптимизации на матрицах меньших размеров.
|
Матрица |
Библиотека LAPACK GFLOPs |
Библиотека «Магма», GFLOPs |
Ядро графического процессора, |
ПЛИС, GFLOPs |
|
512 (SP) 512 (DP) |
19,49 11,99 |
22,21 20,52 |
58,4 57,49 |
19,23 |
|
768 (SP) 768 (DP) |
29,53 18,12 |
38,53 36,97 |
81,87 54,02 |
20,38 |
|
1024 (SP) 1024 (DP) |
36,07 22,06 |
57,01 49,6 |
67,96 42,42 |
21 |
|
2048 (SP) 2048 (DP) |
65,55 32,21 |
117,49 87,78 |
96,15 52,74 |
– |
Примечание.
SP — одинарная точность; DP — двойная точность.
ПЛИС Stratix V корпорации Altera среднего размера (460K логических элементов (LEs)) сравнивалась с ПЛИС Altera с использованием алгоритма Холецкого на операциях с плавающей запятой одинарной точности. Как показано в таблице 2, производительность ПЛИС Stratix V с алгоритмом Холецкого намного выше, чем у Xilinx. Сравнительный анализ Altera также включает QR-разложение, представляющее собой алгоритм обработки другой матрицы разумной сложности. Алгоритм Холецкого и QR-разложение используются как параметризуемые ядра от корпорации Altera.
|
Алгоритм (комплекс, одинарная точность) |
Размер матрицы |
Векторное множество |
fmax, |
GFLOPs |
|
Холецкий |
360×360 |
90 |
190 |
92 |
|
60×60 |
60 |
255 |
42 |
|
|
30×30 |
30 |
285 |
25 |
|
|
QR |
450×450 |
75 |
225 |
135 |
|
400×400 |
100 |
201 |
159 |
|
|
250×400 |
100 |
203 |
162 |
Следует отметить, что размеры матрицы для сравнительного анализа неодинаковы. Результаты, полученные в университете Теннесси, начинаются с размеров матрицы 512×512, в то время как сравнительный анализ корпорации Altera начинается с размеров 360×360 для алгоритма Холецкого и 450×450 для QR-разложения. Причина в том, что ядро графического процессора очень неэффективно при меньших размерах матриц, поэтому нет смысла использовать его для ускорения процессора в этих случаях. Напротив, ПЛИС может эффективно работать с гораздо меньшим размером матрицы. Эта эффективность имеет решающее значение, поскольку радиолокационным системам нужна довольно высокая пропускная способность, выражаемая в тысячах матриц в секунду. Таким образом, используются меньшие размеры матриц, даже за счет разделения большой матрицы на более мелкие с последующей обработкой.
Результаты, полученные в университете Теннесси, начинаются с размеров матрицы 512×512, в то время как сравнительный анализ корпорации Altera начинается с размеров 360×360 для алгоритма Холецкого и 450×450 для QR-разложения. Причина в том, что ядро графического процессора очень неэффективно при меньших размерах матриц, поэтому нет смысла использовать его для ускорения процессора в этих случаях. Напротив, ПЛИС может эффективно работать с гораздо меньшим размером матрицы. Эта эффективность имеет решающее значение, поскольку радиолокационным системам нужна довольно высокая пропускная способность, выражаемая в тысячах матриц в секунду. Таким образом, используются меньшие размеры матриц, даже за счет разделения большой матрицы на более мелкие с последующей обработкой.
В дополнение ко всему сравнительный анализ корпорации Altera проводился по каждому ядру с алгоритмом Холецкого. Каждое параметризуемое ядро с алгоритмом Холецкого позволяет выбрать размер матрицы, векторное множество и глубину канала. Векторное множество примерно определяет ресурсы ПЛИС. Больший (360×360) размер матрицы использует большее векторное множество, что позволяет использовать одно ядро в этом ПЛИС с 91 GFLOPs. Меньший (60×60) размер матрицы использует меньше ресурсов, поэтому два ядра могут быть реализованы, в общей сложности, на 2×42 = 84 GFLOPs. Наименьший (30×30) размер матрицы допускает использование трех ядер, в общей сложности 3×25 = 75 GFLOPs.
Векторное множество примерно определяет ресурсы ПЛИС. Больший (360×360) размер матрицы использует большее векторное множество, что позволяет использовать одно ядро в этом ПЛИС с 91 GFLOPs. Меньший (60×60) размер матрицы использует меньше ресурсов, поэтому два ядра могут быть реализованы, в общей сложности, на 2×42 = 84 GFLOPs. Наименьший (30×30) размер матрицы допускает использование трех ядер, в общей сложности 3×25 = 75 GFLOPs.
ПЛИС гораздо лучше подходит для решения задач с меньшими размерами данных, что приемлемо для многих РЛС. Пониженная эффективность ядра графических процессоров связана с вычислительными нагрузками, увеличивающимися как N3, данными ввода/вывода, возрастающими как N2, и, в конечном счете, узкими местами ввода/вывода ядра графического процессора, создавая меньше проблем при увеличении набора данных. Кроме того, из-за увеличения размеров матрицы ее пропускная способность в секунду резко падает из-за увеличения времени обработки каждой матрицы. В какой-то момент пропускная способность становится слишком низкой и непригодной для работы в реальном времени в РЛС.
При использовании преобразования Фурье нагрузка вычисления увеличивается до Nlog2N, в то время как данные ввода/вывода возрастают как N. Опять же, при очень больших объемах данных ядро графического процессора становится эффективной вычислительной системой. Напротив, ПЛИС является эффективным вычислительным устройством для всех размеров данных и лучше подходит для большинства радиолокационных операций, где размеры преобразования Фурье небольшие, а пропускная способность является основным параметром.
Методология проектирования графического процессора и ПЛИС
Ядро графического процессора программируется с использованием либо собственного языка CUDA от Nvidia, либо открытого стандарта языка программирования OpenCL. Эти языки очень похожи по своим возможностям, с той единственной разницей, что CUDA может использоваться только на графических процессорах Nvidia.
ПЛИС, как правило, программируются с помощью языков описания аппаратуры Verilog или VHDL. Ни один из этих языков полностью не подходит для поддержки программирования с плавающей запятой, хотя последние версии включают определение, пусть и не обязательного обобщения, чисел с плавающей запятой. Например, в языке описания Verilog простая вещественная переменная является аналогом числа одинарной точности стандарта IEEE, а вещественная переменная — аналогом числа двойной точности стандарта IEEE.
Например, в языке описания Verilog простая вещественная переменная является аналогом числа одинарной точности стандарта IEEE, а вещественная переменная — аналогом числа двойной точности стандарта IEEE.
Библиотека DSP Builder Advanced Blockset
Синтез трактов данных с плавающей запятой в ПЛИС с использованием традиционных методов очень неэффективен, что подтверждено низкой производительностью ПЛИС фирмы Xilinx на алгоритме Холецкого, реализованного с помощью генератора параметризированных модулей Core Generator фирмы Xilinx с универсальным ядром, предназначенным для автоматизированной подготовки описаний элементов, выполняющих различные арифметические операции с плавающей запятой. Тем не менее корпорация Altera предлагает две альтернативы. Первая заключается в использовании библиотеки DSP Builder Advanced Blockset с технологией проектирования компании Mathworks на базе Model-Based Design. Этот инструмент поддерживает числа как с фиксированной, так и с плавающей запятой, а также семь различных уровней точности обработки с плавающей запятой, включая половинную, одинарную и двойную точность по стандарту IEEE.![]() Он также поддерживает векторизацию, которая необходима для эффективного применения линейной алгебры. Самое главное заключается в его способности эффективно отображать цепи с плавающей запятой на сегодняшних архитектурах ПЛИС с фиксированной запятой, о чем свидетельствует их сравнительный анализ производительности в 100 GFLOPs на алгоритме Холецкого при среднем размере ПЛИС по 28‑нм технологии. Для сравнения, использование алгоритма Холецкого на тех же размерах ПЛИС фирмы Xilinx без этой возможности синтеза дает только 20 GFLOPs производительности по тому же алгоритму [2].
Он также поддерживает векторизацию, которая необходима для эффективного применения линейной алгебры. Самое главное заключается в его способности эффективно отображать цепи с плавающей запятой на сегодняшних архитектурах ПЛИС с фиксированной запятой, о чем свидетельствует их сравнительный анализ производительности в 100 GFLOPs на алгоритме Холецкого при среднем размере ПЛИС по 28‑нм технологии. Для сравнения, использование алгоритма Холецкого на тех же размерах ПЛИС фирмы Xilinx без этой возможности синтеза дает только 20 GFLOPs производительности по тому же алгоритму [2].
Язык программирования OpenCL для ПЛИС
Язык программирования OpenCL сходен с языками программирования ядра графического процессора. Компилятор OpenCL [3] для ПЛИС означает, что код OpenCL, написанный для AMD или Nvidia GPU, может быть скомпилирован на ПЛИС. Кроме того, компилятор OpenCL корпорации Altera позволяет программам ядра графического процессора использовать ПЛИС без необходимости разработки типового набора приемов проектирования ПЛИС.
Использование OpenCL с ПЛИС дает несколько ключевых преимуществ по сравнению с ядром графического процессора. Важно, что ядра графических процессоров, как правило, ограничены по входу/выходу. Все входные и выходные данные должны быть переданы центральным процессором через интерфейс PCI Express (PCIe). Получаемые задержки могут привести к потере скорости обработки ядром процессора, что снижает производительность.
Расширения языка программирования OpenCL для ПЛИС
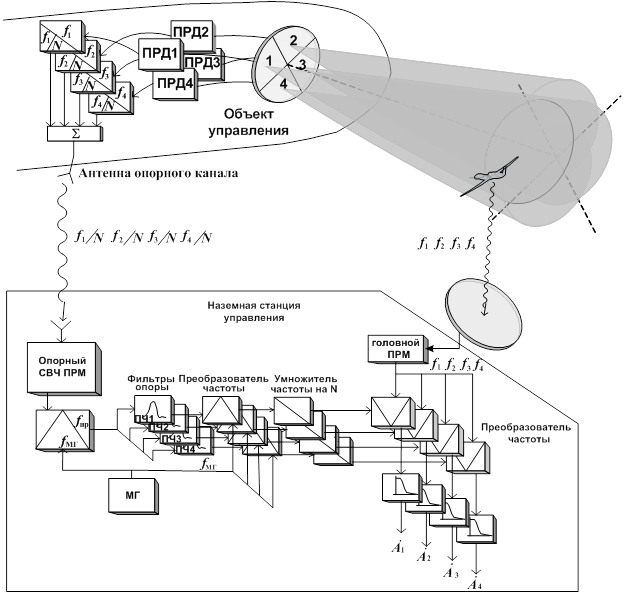
ПЛИС хорошо известны благодаря высокой пропускной способности ввода/вывода, что позволяет осуществлять поточную передачу данных в ПЛИС и из него через Gigabit Ethernet (GbE), Serial RapidIO (SRIO) или непосредственно через АЦП и ЦАП. Корпорация Altera определила специфическое для производителя расширение стандарта OpenCL для поддержки непрерывного режима передачи данных. Это расширение является важнейшей особенностью в РЛС, так как позволяет передавать данные непосредственно от формирования диаграммы направленности, с предварительной обработкой с фиксированной запятой, и цифрового преобразования с понижением частоты на стадии обработки с плавающей запятой для сжатия импульса. Эффект Доплера, пространственно-временная адаптация, индикатор типа сообщения (MTI) движущейся цели и другие функции показаны на рис. 2. Таким образом, поток данных избегает узких мест процессора перед передачей в ускоритель ядра графического процессора, так что в целом задержка обработки уменьшается.
Эффект Доплера, пространственно-временная адаптация, индикатор типа сообщения (MTI) движущейся цели и другие функции показаны на рис. 2. Таким образом, поток данных избегает узких мест процессора перед передачей в ускоритель ядра графического процессора, так что в целом задержка обработки уменьшается.
Рис. 2. Основная блок-схема обработки сигнала РЛС
ПЛИС также может предложить гораздо более низкое время задержки обработки, чем ядро графического процессора, даже независимо от узких мест ввода/вывода. Хорошо известно, что ядра графических процессоров для эффективной работы должны обрабатывать многие тысячи потоков из-за чрезвычайно длинных задержек при вводе и выводе из памяти и даже между несколькими ядрами графического процессора. По сути, ядро графического процессора должно обработать множество операций, чтобы удержать ядра процессора от потери скорости обработки при ожидании данных, что приводит к очень длительному времени задержки для любой конкретной задачи.
ПЛИС использует вместо этого архитектуру «крупнозернистого параллелизма», с помощью которой создается множество оптимизированных и параллельных трактов данных, каждый из которых выдает один результат за один временной цикл. Количество трактов данных зависит от ресурсов ПЛИС, но, как правило, их гораздо меньше, чем количество ядер графического процессора. Тем не менее каждый тракт данных имеет гораздо более высокую пропускную способность, чем ядро графического процессора. Основное преимущество такого подхода заключается в низкой временной задержке, критическом значении для производительности во многих приложениях.
Еще одно преимущество ПЛИС состоит в гораздо более низком энергопотреблении, в результате чего резко снижено соотношение GFLOPs/Вт. Измерения производительности ПЛИС с использованием прототипной платы показывают 5–6 GFLOPs/Вт для таких алгоритмов, как алгоритм Холецкого и QR-разложение, и около 10 GFLOPs/Вт для простых алгоритмов, таких как быстрое преобразование Фурье. Измерения энергоэффективности графического процессора найти гораздо труднее, но с использованием ядра графического процессора с производительностью 50 GFLOPs с алгоритмом Холецкого и среднего потребления энергии в 200 Вт получается 0,25 GFLOPs/Вт, что в двадцать раз больше энергии, потребленной на полезный FLOPs.
Измерения энергоэффективности графического процессора найти гораздо труднее, но с использованием ядра графического процессора с производительностью 50 GFLOPs с алгоритмом Холецкого и среднего потребления энергии в 200 Вт получается 0,25 GFLOPs/Вт, что в двадцать раз больше энергии, потребленной на полезный FLOPs.
Для бортовой самолетной РЛС или станции, установленной на автомобиле, размер, вес и потребляемая мощность (SWaP) имеют первостепенное значение. Можно легко представить себе радиолокационный пеленг беспилотников производительностью в десятки TFLOPs в будущих системах. Доступная величина вычислительной мощности коррелирует с допустимым разрешением и охватом современной РЛС.
Сопоставленный тракт данных
OpenCL и DSP Builder используют технологию, известную как «сопоставленный тракт данных» (рис. 3), где операции с плавающей запятой осуществляются в целях резкого сокращения количества требуемых многорегистровых схем циклического сдвига, что, в свою очередь, позволяет осуществлять встраивание с использованием ПЛИС для крупномасштабного и высокопроизводительного программирования с плавающей запятой.
Рис. 3. Реализация сопоставленного тракта данных в операции с плавающей запятой
Для уменьшения частоты реализации многорегистровой схемы циклического сдвига процесс синтеза ищет возможности компенсации потребности в частой нормализации и денормализации с помощью большей ширины мантиссы. Возможность использования фиксированных множителей 27×27 и 36×36 допускает бóльшие множители, чем 23 бит, необходимые для реализаций одинарной точности, а также создание множителей 54×54 и 72×72 допускает бóльшие множители, чем 52 бита, необходимые для реализаций двойной точности. Для реализации больших схем суммирования с фиксированной запятой, с включением встроенных схем ускоренного переноса, логика ПЛИС оптимизируется.
Там, где требуется нормализация и денормализация, альтернативным способом является использование мультипликаторов, что позволяет избежать низкой производительности и чрезмерной маршрутизации. Для мантиссы одинарной точности в 24 бита (включая знаковый бит) множитель 24×24 сдвигает ввод путем умножения на 2n. Опять же, возможность использования фиксированных множителей 27×27 и 36×36 позволяет применять расширенные размеры мантиссы в реализациях одинарной точности и может быть использована для создания размеров множителя для реализаций двойной точности.
Опять же, возможность использования фиксированных множителей 27×27 и 36×36 позволяет применять расширенные размеры мантиссы в реализациях одинарной точности и может быть использована для создания размеров множителя для реализаций двойной точности.
Скалярное произведение векторов является операцией, потребляющей основную часть производительности в FLOPs, и используется во многих алгоритмах линейной алгебры. Реализация скалярного произведения векторов одинарной точности длиной 64 потребует 64 множителя с плавающей запятой, с последующим суммированием на 63 сумматорах с плавающей запятой. Такая реализация потребует большого количества многорегистровых схем циклического сдвига.
Вместо этого выходы 64 множителей можно денормализовать до общего показателя, самого крупного из 64‑х. Затем эти 64 выхода можно суммировать с помощью схемы суммирования с фиксированной запятой и окончательной нормализацией в конце. Эта операция с плавающей запятой в локализованном блоке обходится без промежуточной нормализации и денормализации, необходимой для каждого отдельного суммирования, и показана на рис. 4. Даже при операции с плавающей запятой стандарта IEEE 754 число с наибольшим показателем определяет показатель в конце, поэтому это изменение просто перемещает выравнивание показателя к более ранней точке в расчете.
4. Даже при операции с плавающей запятой стандарта IEEE 754 число с наибольшим показателем определяет показатель в конце, поэтому это изменение просто перемещает выравнивание показателя к более ранней точке в расчете.
Рис. 4. Оптимизация скалярного произведения векторов
Однако при обработке сигнала лучшие результаты получаются при наиболее точном выполнении округления результатов в конце расчета. Такой подход компенсируется путем использования наибольшей ширины бита мантиссы сверх того, что требуется при операции с плавающей запятой одинарной точности, как правило, 27–36 бит. Расширение мантиссы выполняется множителями с плавающей запятой, чтобы устранить необходимость нормализации произведения на каждом этапе.
Этот подход может также давать один результат за один временной цикл. Архитектуры ядра графического процессора могут производить все операции умножения с плавающей запятой параллельно, но не могут эффективно выполнять параллельное суммирование. Эта неспособность обусловлена требованиями того, что разные ядра должны передавать данные через локальную память (для связи друг с другом), тем самым уменьшая гибкость в соединениях архитектуры ПЛИС.
Эта неспособность обусловлена требованиями того, что разные ядра должны передавать данные через локальную память (для связи друг с другом), тем самым уменьшая гибкость в соединениях архитектуры ПЛИС.
Подход «сопоставленный тракт данных» генерирует результаты, которые являются более точными, чем обычные результаты с плавающей запятой стандарта IEEE 754, как показано в таблице 3.
|
Размер комплексной |
Векторное множество |
Ошибка |
Ошибка |
|
360×360 |
50 |
2,1112×10–6 |
1,1996×10–6 |
|
60×60 |
100 |
2,8577×10–7 |
1,3644×10–7 |
|
30×30 |
100 |
1,5488×10–6 |
9,0267×10–8 |
Эти результаты были получены путем реализации обращения большой матрицы с использованием алгоритма разложения Холецкого. Этот же алгоритм был реализован тремя различными способами:
Этот же алгоритм был реализован тремя различными способами:
- в MATLAB+Simulink при операции с плавающей запятой одинарной точности стандарта IEEE 754;
- в RTL при операции с плавающей запятой одинарной точности, используя подход «сопоставленный тракт данных»;
- в MATLAB при операции с плавающей запятой двойной точности.
Реализация двойной точности точнее примерно в один миллиард раз (109), чем реализация одинарной точности.
Сравнение ошибок, полученных в MATLAB с одинарной точностью, в RTL с одинарной точностью и в MATLAB с двойной точностью, подтверждает достоверность подхода сопоставленного тракта данных. Этот подход продемонстрирован для нормализованной ошибки во всех сложных элементах в выходной матрице и матричного элемента с максимальной погрешностью. Суммарная ошибка или норма рассчитывается с использованием нормы Фробениуса:
Поскольку норма включает ошибки всех элементов, то она часто бывает много больше, чем отдельные ошибки.
Кроме того, инструменты потоков DSP Builder Advanced Blockset and OpenCL со всей очевидностью поддерживают и оптимизируют принятые методы расчета для архитектуры ПЛИС следующего поколения. Пиковую производительность в 100 GFLOPs/Вт можно ожидать благодаря архитектурным технологическим инновациям.
Заключение
Высокопроизводительные РЛС получили теперь новые процессорные платформы. В дополнение к значительно улучшенному SWaP, ПЛИС может обеспечить меньшее время ожидания и более высокую производительность в GFLOPs, чем решения на базе процессоров. Эти преимущества будут еще более явными с введением нового поколения ПЛИС, оптимизированного для высокопроизводительных вычислений.
Компилятор OpenCL корпорации Altera обеспечивает почти прямой путь программистам ядра графических процессоров для оценки достоинства этой новой архитектуры обработки сигнала. Язык программирования OpenCL 1.2 совместим с полным набором математической библиотеки поддержки. Это позволяет абстрагироваться от традиционных проблем ПЛИС по времени свертывания, управления памятью DDR и сопряжения с хост-процессором PCIe.
Для разработчиков безъядерных графических процессоров корпорация Altera предлагает инструмент потока DSP Builder Advanced Blockset, который позволяет разработчикам осуществлять DSP-программирование с высоким fmax и фиксированной или плавающей запятой, сохраняя при этом преимущества моделирования на основе Mathworks и среды разработки. Этот инструмент использовался в течение многих лет разработчиками РЛС с использованием ПЛИС для более производительного рабочего процесса и моделирования, который дает ту же производительность fmax, как и ручное программирование в коде HDL.
Статья опубликована в №4-2014 журнала «Компоненты и технологии»
Литература
- Получение одного TFLOPs на ПЛИС с технологией 28 нанометров. altera.com/literature/wp/wp‑01142‑teraflops.pdf /ссылка устарела/
- Depeng Yang, Junqing Sun, Jun Ku Lee, Getao Liang, David D. Jenkins, Gregory D.
 Peterson, and Husheng Li. Сравнение производительности разложения Холецкого на графическом процессоре и ПЛИС.
Peterson, and Husheng Li. Сравнение производительности разложения Холецкого на графическом процессоре и ПЛИС. - Реализация программирования ПЛИС языком OpenCL Standard. altera.com/literature/wp/wp‑01173‑opencl.pdf /ссылка устарела/
PLIS — Wiktionary
См. Также: PLRIS , PLIS , и PLI
Содержание
- 1 Albanian
- 1.1 Этимология 1
- 1.1.1 Альтернативные формы
- 1.1.2 Существительное
- 1.1.2.1 Синонимы
- 1.1.2.2 Производные термины
- 1.2 Этимология 2
- 1.2.1 Существительное
- 1.2.1.1 Производные термины
- 1.2.1 Существительное
- 1.3 Каталожные номера
- 1.1 Этимология 1
- 2 французский
- 2.1 Произношение
- 2.2 Существительное
- 2.3 Анаграммы
- 3 Гаитянский креольский
- 3.1 Этимология
- 3.
 2 Определитель
2 Определитель
- 3.2.1 См. также
- 4 высокой четкости
- 4.1 Этимология
- 4.2 Существительное
- 4.3 Каталожные номера
- 5 маврикийский креольский
- 5.1 Произношение
- 5.2 Этимология 1
- 5.2.1 Существительное
- 5.2.1.1 Связанные термины
- 5.2.1 Существительное
- 5.3 Этимология 2
- 5.3.1 Глагол
- 6 Ток Писин
- 6.1 Этимология
- 6.2 Междометие
Албанский [править]
Этимология 1 , откалываться, откалываться»).
[1] В качестве альтернативы протоалбанскому *plitja , опять же родственному санскритскому फलति (phálati, «лопнуть, расколоться»), латинскому spolium («содранная кожа»). [2]Альтернативные формы. множественное число
плисат )- ком (земли), комок
- кожный мешок, пыж
Синонимы
Etymology 2 [Edit]
от протоалбанского *P (i) LITJA , Cognate со старым высоким немецким FILZ , Latin Pellis , Pilleus , Grek , Pilleus , , ( (9014 40189. , праславянский *пьлсть . [3]
, праславянский *пьлсть . [3]
Существительное [Прайти]
PLIS M ( Неопределенный плюс.
- шерстяной войлок
- фетровая тюбетейка
- войлочная прокладка, помещаемая под ярмо или вьючное седло для защиты шеи тягловых животных
Производные термины[править]
- плисар
- Орел, Владимир (1998), «плис», в Албанском этимологическом словаре , Лейден, Бостон, Кельн: Brill, → ISBN , стр. 335
-
Audio (file) - множественное число от pli
- подробнее
- pase
- лошадь
- Зигмунт Фрайзингер, Эрин Шей, Грамматика Hdi (2002, → ISBN
- Topics in Chadic linguistics 3 , volume 3 (2007), page 71
- IPA (key) : /plis/
- плюс
- дополнение
- выгода, преимущество
- pli
- Медиа форма плисе ; очистить.

- пожалуйста
- {{randomImageQuizHook.

Pronunciation[edit]
Noun[edit]
plis m
Анаграммы0031
Гаитянский креольский[править]
Этимология[править]
От французского плюс («больше»).
Определитель[править]
плис
См. также [править]
Этимология
Существительное[править]
плис
Ссылки[править]
Mauritian Creole[edit]
Pronunciation[edit]
Etymology 1 [править]
От французского плюс .
Существительное[править]
плис
Связанные термины[править]
Этимология 2
Глагол[править]
плис
Ток Писин[править]
Этимология[править]
С английского пожалуйста .
Междометие[править]
плиз
mise en plis на английском языке
mise en plis
сущ.
поставил [существительное] процесс укладки волос
шампунь и укладка.
Обзор
мис де фонд
мизан обвинение
мизансцена
мизансцена
мис ан плис
вопрос
мизансцена
скряга
скряга (сур)
Проверьте свой словарный запас с помощью наших веселых викторин по картинкам
