Как работает шифратор 8 на 3 в цифровых схемах. Какие преимущества дает использование шифратора 8 на 3. Где применяется шифратор 8 на 3 в электронике. Какие есть разновидности шифраторов 8 на 3.
Что такое шифратор 8 на 3 и каков принцип его работы?
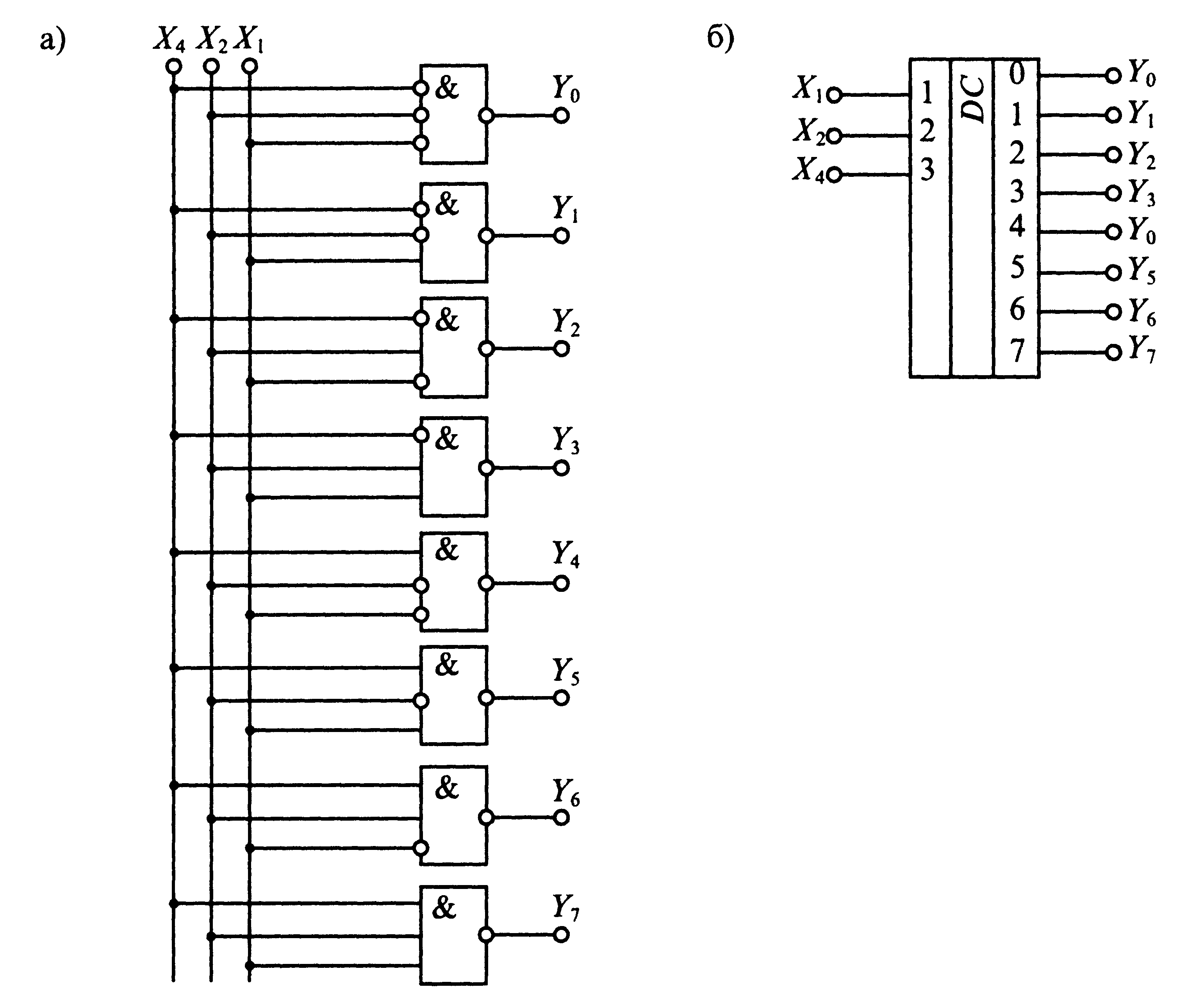
Шифратор 8 на 3 (также называемый кодером) — это комбинационное логическое устройство, выполняющее преобразование 8-разрядного позиционного кода в 3-разрядный двоичный код. Принцип работы шифратора 8 на 3 заключается в следующем:
- На 8 входов подаются сигналы, из которых только один может иметь активный уровень (обычно логическую 1).
- Шифратор определяет, на каком именно входе присутствует активный сигнал.
- На 3 выходах формируется двоичный код, соответствующий номеру активного входа.
Таким образом, шифратор 8 на 3 позволяет закодировать информацию о том, какой из 8 входов активен, с помощью 3-битного двоичного кода на выходе.
Какие преимущества дает использование шифратора 8 на 3?
Применение шифратора 8 на 3 в цифровых схемах имеет ряд существенных преимуществ:
- Уменьшение количества линий для передачи информации (с 8 до 3).
- Компактное представление информации в двоичном виде.
- Возможность легко декодировать сигнал обратно в 8-разрядный код.
- Упрощение логики обработки сигналов в цифровых устройствах.
- Снижение энергопотребления за счет использования меньшего количества линий.
Эти преимущества делают шифратор 8 на 3 востребованным компонентом во многих областях цифровой электроники.
Где применяется шифратор 8 на 3 в электронных устройствах?
Шифраторы 8 на 3 широко используются в различных электронных системах и устройствах:
- Клавиатуры компьютеров и других устройств ввода
- Системы управления с несколькими кнопками/переключателями
- Мультиплексоры и демультиплексоры
- Устройства приоритетного прерывания
- Аналого-цифровые преобразователи
- Устройства отображения информации
- Системы кодирования данных
В этих применениях шифратор 8 на 3 позволяет эффективно преобразовывать информацию из одного формата в другой, оптимизируя работу электронных систем.
Какие существуют разновидности шифраторов 8 на 3?
Существует несколько основных разновидностей шифраторов 8 на 3, различающихся по принципу работы и характеристикам:
- Простой шифратор — выдает код при наличии единственного активного входа
- Приоритетный шифратор — при наличии нескольких активных входов выдает код старшего по приоритету
- Шифратор с разрешающим входом — работает только при наличии разрешающего сигнала
- Двунаправленный шифратор — может работать как шифратор и как дешифратор
- Каскадируемый шифратор — позволяет объединять несколько микросхем для увеличения разрядности
Выбор конкретного типа шифратора зависит от требований разрабатываемой электронной системы и особенностей решаемой задачи.
Как реализуется шифратор 8 на 3 на логических элементах?
Шифратор 8 на 3 может быть построен на основе простых логических элементов по следующей схеме:
- Используются элементы ИЛИ с 4 входами (3 штуки)
- Каждый выход шифратора формируется одним элементом ИЛИ
- На входы элементов ИЛИ подключаются входные сигналы шифратора
- Комбинация подключений определяет правило кодирования
Например, младший разряд выхода формируется элементом ИЛИ, на входы которого поданы нечетные входы шифратора. Средний разряд — ИЛИ входов с номерами 2-3 и 6-7. Старший разряд — ИЛИ входов 4-7.

Какие микросхемы шифраторов 8 на 3 доступны на рынке?
На рынке электронных компонентов представлен ряд популярных интегральных микросхем шифраторов 8 на 3:
- 74148 — приоритетный шифратор 8 на 3 (TTL)
- 74LS348 — приоритетный шифратор 8 на 3 (КМОП)
- CD4532 — приоритетный шифратор 8 на 3 (КМОП)
- К555ИВ3 — шифратор 8 на 3 (отечественный аналог)
Эти микросхемы различаются быстродействием, энергопотреблением, наличием дополнительных функций. При выборе необходимо учитывать параметры разрабатываемого устройства.
Как тестировать работоспособность шифратора 8 на 3?
Для проверки правильности работы шифратора 8 на 3 можно использовать следующую методику тестирования:
- Подать поочередно активный уровень на каждый из 8 входов
- Проверить соответствие выходного кода номеру активного входа
- Подать одновременно активный уровень на несколько входов (для приоритетного шифратора)
- Убедиться, что выходной код соответствует входу с наивысшим приоритетом
- Проверить работу при отсутствии активных входов
Такое тестирование позволяет выявить возможные неисправности или ошибки в работе шифратора 8 на 3 и убедиться в его корректном функционировании.
Шифратор — Студопедия
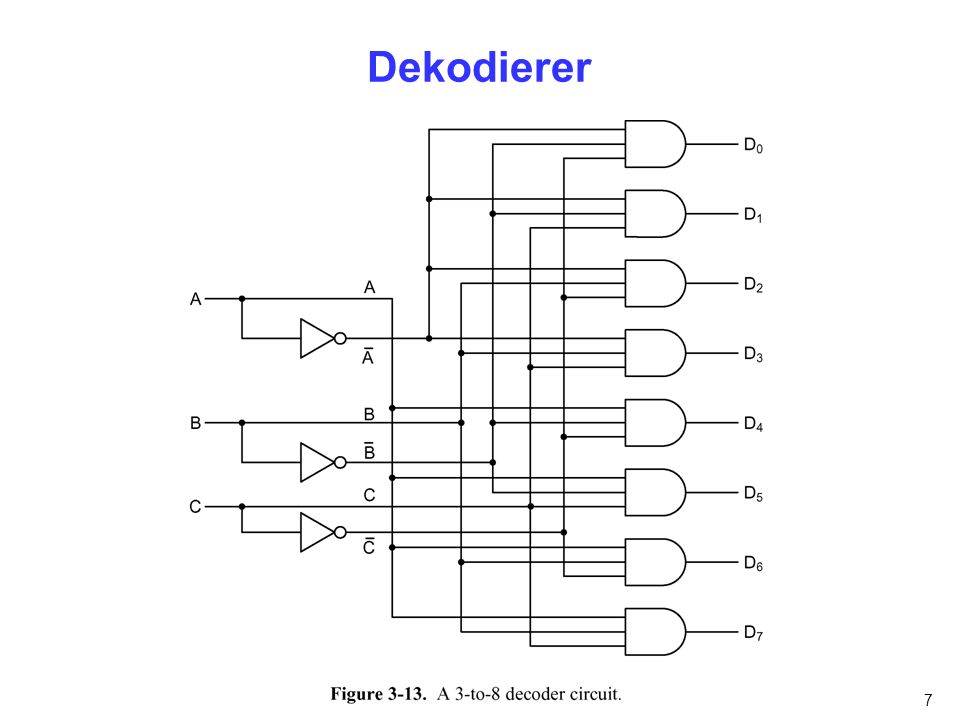
Шифратором или кодером называется логическое устройство для преобразования десятичного кода в двоичный, то есть шифратор может иметь 4, 8, 10, или 16 входов и соответственно 2, 3 или 4 выхода.
Рассмотрим шифратор, преобразующий числа от 0 до 9 (10 входов) на 4 выхода (n = 4), сигналы на которых представлены в двоично-десятичном коде 1, 2, 4, 8 (1 = 20; 2 = 21; 4 = 22; 8 = 23). Так как число входов меньше чем 2n, такой шифратор называется неполным.
Работа шифратора описывается таблицей истинности (таблица 4.3).
Таблица 4.3
Таблица истинности шифратора
| X9 | X8 | X7 | X6 | X5 | X4 | X3 | X2 | X1 | X0 | Q3 | Q2 | Q1 | Q0 |
Из таблицы истинности можно записать систему уравнений ФАЛ шифратора:
(4. 3)
3)
При анализе выражения (4.3) видно, что минимизировать такую систему функций невозможно. Поэтому для технической реализации шифратора потребуется один ЛЭ 5ИЛИ, два ЛЭ 4ИЛИ и один ЛЭ 2ИЛИ. В п. 3.3 было отмечено, что ЛЭ, имеющих пять входов, не существует (есть 4 или 8 входов). Чтобы не загромождать схему преобразованиями, изобразим элемент для получения выхода Q0 условно (как 5ИЛИ). Следует также отметить, что сигнал входа шифратора Х0 не участвует в формировании выходных сигналов. Схема шифратора представлена на рис. 4.5.
| |
Рис. 4.5. Схема шифратора
При работе шифратора активный входной сигнал может присутствовать только на одном входе. Если активных входных сигналов будет два или больше, работа шифратора нарушится.
На принципиальных электрических схемах логических устройств шифратор изображается условным графическим обозначением.
| |
Рис. 4.6. Условное графическое изображение шифратора
Ввиду простой схемы и ограниченности решаемой задачи – преобразования десятичного кода в двоичный, техническая реализация шифратора на микросхемах не выпускается. При необходимости шифраторы выполняют на элементах ИЛИ-НЕ с дополнительными инверторами на выходе, либо на элементах И-НЕ, применяя к выражению (4.3) принцип двойственности. В некоторых схемах шифраторы выполняют на контактах реле, диодной матрице или на контактах декадных галетных переключателей.
Проектирование дешифраторов и шифраторов
Проектирование дешифраторов и шифраторов| Справочное руководство по Electronics Workbench |
 n. В ЭВМ с
помощью дешифраторов осуществляется выборка необходимых ячеек запоминающих
устройств, расшифровка кодов операций с выдачей соответствующих управляющих
сигналов и т.д.
n. В ЭВМ с
помощью дешифраторов осуществляется выборка необходимых ячеек запоминающих
устройств, расшифровка кодов операций с выдачей соответствующих управляющих
сигналов и т.д.
Если входные переменные представить как двоичную систему запись чисел, то логическая единица формируется в том выходе, номер которого соответствует десятичной записи того же числа. Например, A = 1, B = 0, C = 0, D = 1, число 1001 в двоичном коде. В десятичной коде это число соответствует 9, т.е. при данной комбинации входных переменных F9 = 1. Дешифраторы широко используются в качестве преобразователей двоичного кода в десятичный, а также во многих других устройствах.
Функционирование дешифратора описывается системой логических уравнений составленных на основе таблицы истинности.
Одноступенчатый дешифратор(линейный) —
наиболее быстродействующий, но его реализация при значительной разрядности
входного слова затруднена, поскольку требует применения логических элементов с
большим числом входов (равным n+1 для вариантов со стробированием по выходу) и
сопровождается большой нагрузкой на источники входных сигналов. 3=8.
3=8.
Построение дешифратора на основе простых элементов, с помощью таблицы истинности (см. таблицу 3.2.1.1) и составленных соответственно логических уравнений.
|
A |
B |
C |
Y1 |
Y2 |
Y3 |
Y4 |
Y5 |
Y6 |
Y7 |
Y8 | |
|
1 |
0 |
0 |
0 |
1 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
|
2 |
0 |
0 |
1 |
0 |
1 |
0 |
0 |
0 |
0 |
0 |
0 |
|
3 |
0 |
1 |
0 |
0 |
0 |
1 |
0 |
0 |
0 |
0 |
0 |
|
4 |
0 |
1 |
1 |
0 |
0 |
0 |
1 |
0 |
0 |
0 |
0 |
|
5 |
1 |
0 |
0 |
0 |
0 |
0 |
0 |
1 |
0 |
0 |
0 |
|
6 |
1 |
0 |
1 |
0 |
0 |
0 |
0 |
0 |
1 |
0 |
0 |
|
7 |
1 |
1 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
1 |
0 |
|
8 |
1 |
1 |
1 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
1 |
Таблица 3.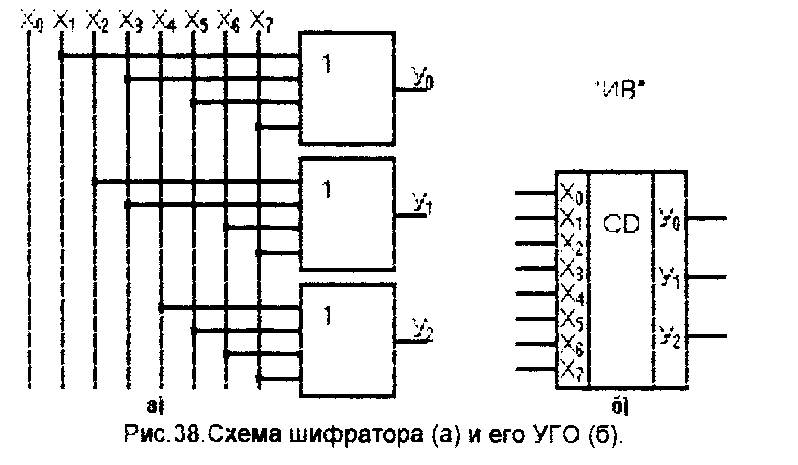 B C;
B C;
На рисунке 3.2.1.1 приведена временная диаграмма работы дешифратора.
Рисунок 3.2.1.2 — Диаграмма работы дешифратора на 3 входа и 8 выходов
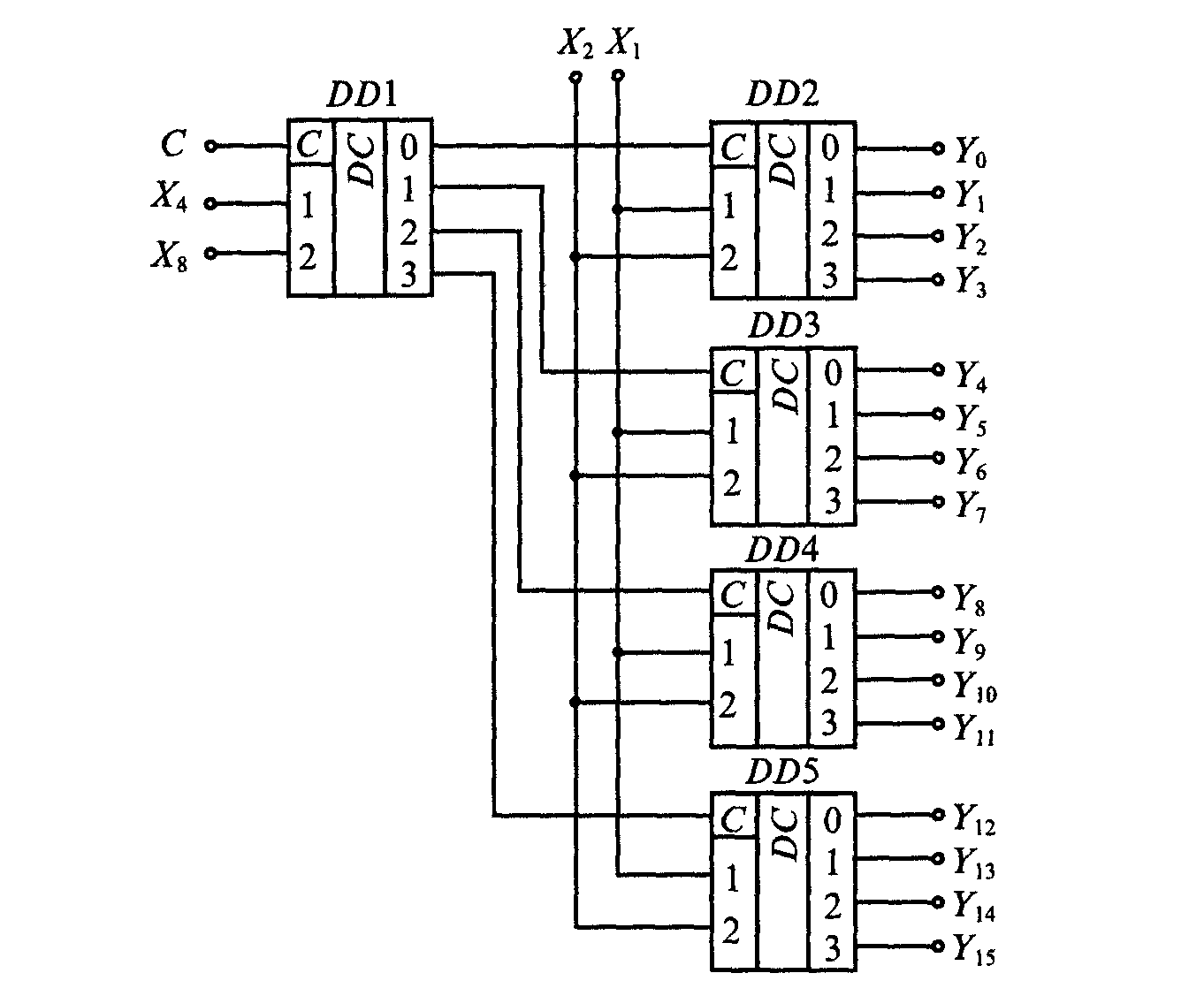
Появление малоразрядных дешифраторов (пирамидальный и матричный) в виде СИС поставило вопрос о применении их как средств построения дешифраторов большей разрядности, что дает существенную экономию аппаратурных затрат.
Любой нужный дешифратор может быть построен по пирамидальной структуре. При входное слово делится на поля, разрядность которых соответствует числу входов имеющихся СИС дешифраторов, а затем из СИС строится пирамидальная структура, составляющая совокупность линейных дешифраторов.
Матричные дешифраторы формируются на
основе простых линейных дешифраторов меньшей размерности, т. n
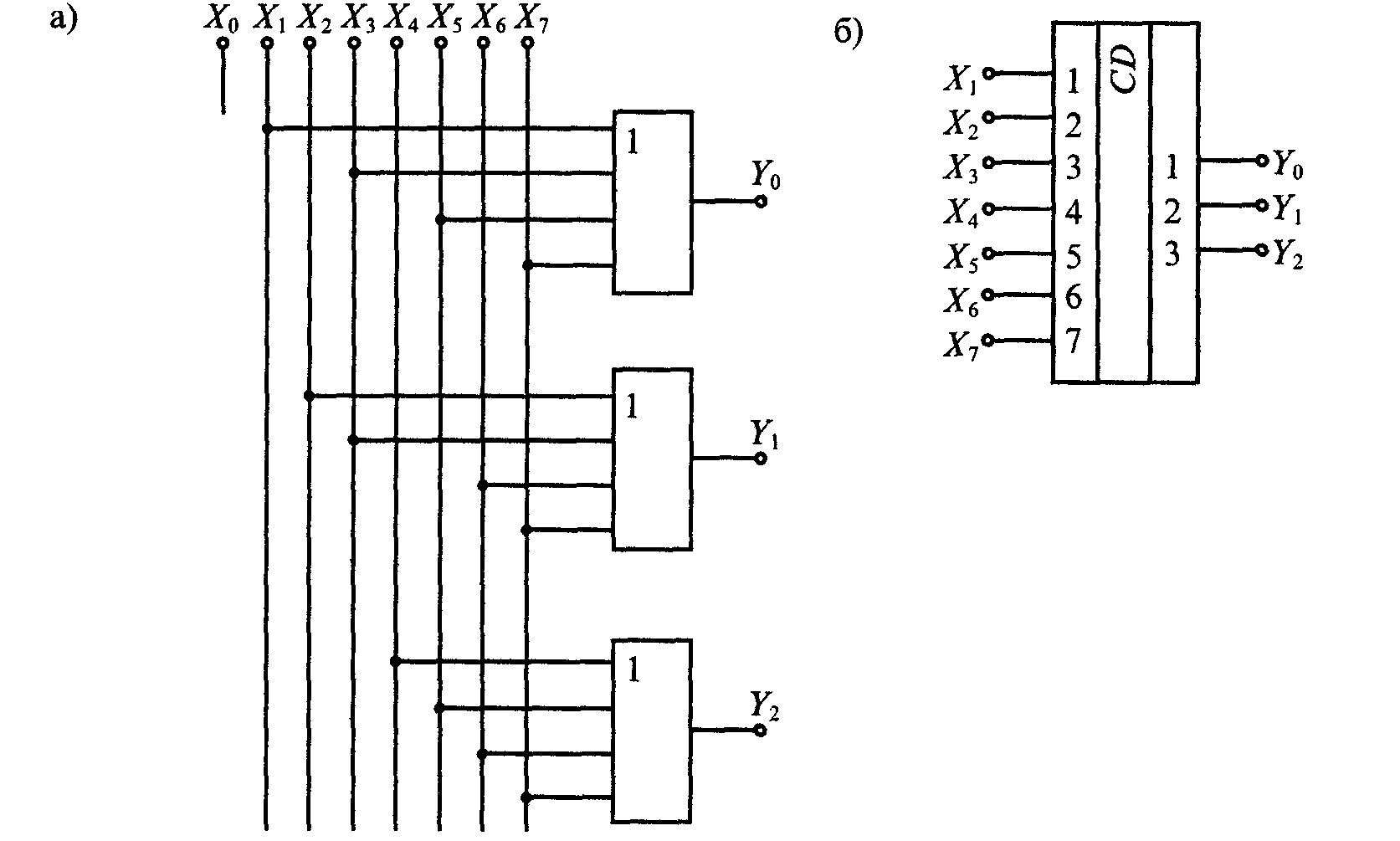
входов и n выходов. Одно из основных применений шифратора — ввод данных с
клавиатуры, при котором нажатие клавиши с десятичной цифрой должно приводить к
передаче в устройство двоичного кода данной цифры. Пример построения шифратора
показан на рисунке 3.2.1.3, а на рисунке 3.2.1.4 приведена временная диаграмма
работы шифратора.
n
входов и n выходов. Одно из основных применений шифратора — ввод данных с
клавиатуры, при котором нажатие клавиши с десятичной цифрой должно приводить к
передаче в устройство двоичного кода данной цифры. Пример построения шифратора
показан на рисунке 3.2.1.3, а на рисунке 3.2.1.4 приведена временная диаграмма
работы шифратора.
Рисунок 3.2.1.3 — Схема шифратора
Рисунок 3.2.1.4 — Диаграмма работы шифратора
Задание:
— Дешифратора;
— Шифратора;
В отчет включить:
— Схемы дешифратора и шифратора;
— Временные диаграммы работы дешифратора и шифратора;
Задания выполняются соответственно по вариантам:
- Спроектировать линейный дешифратор на 4 входа и шифратор;
- Спроектировать пирамидальный дешифратор на 4 входа и шифратор;
- Спроектировать матричный дешифратор на 4 входа и
шифратор.

Вернуться к содержанию
Шифратор (электроника) — Википедия
Материал из Википедии — свободной энциклопедии
У этого термина существуют и другие значения, см. Шифратор.Шифратор (кодер) — (англ. encoder) логическое устройство, выполняющее логическую функцию (операцию) — преобразование позиционного n-разрядного кода в m-разрядный двоичный, троичный или k-ичный код.
Двоичный шифратор 4-к-2Виды шифраторов
Двоичный шифратор
Двоичный шифратор выполняет логическую функцию преобразования унитарного n-ичного однозначного кода в двоичный. При подаче сигнала на один из n входов (обязательно на один, не более) на выходе появляется двоичный код номера активного входа.
Если количество входов настолько велико, что в шифраторе используются все возможные комбинации сигналов на выходе, то такой шифратор называется полным, если не все, то неполным. Число входов и выходов в полном шифраторе связано соотношением:
n=2m,{\displaystyle \ n=2^{m},} где
n{\displaystyle \ n} — число входов,
m{\displaystyle \ m} — число выходных двоичных разрядов. {m}}, где
n{\displaystyle \ n} — число входов,
m{\displaystyle \ m} — число выходных k-ичных разрядов,
k{\displaystyle \ k} — основание системы счисления.
Приоритетный шифратор
Приоритетный шифратор отличается от шифратора наличием дополнительной логической схемы выделения активного уровня старшего входа для обеспечения условия работоспособности шифратора (только один уровень на входе активный). Уровни сигналов на остальных входах схемой игнорируются.
Примеры
- К555ИВ1 — ТТЛ микросхема приоритетного шифратора (n = 8, m = 3). Зарубежный аналог 74148.
- К555ИВ3 — ТТЛ микросхема неполного декадного шифратора (n = 9, m = 4). Зарубежный аналог 74147.
См. также
Литература
Кодирование Unicode
\ uXXXX U + xxxx — декодер, кодировщик, переводчик
Поиск инструмента
Кодировка Unicode
Инструмент для перевода кодов Unicode. Юникод — это стандарт кодировки символов, цель которого — дать каждому символу числовой идентификатор.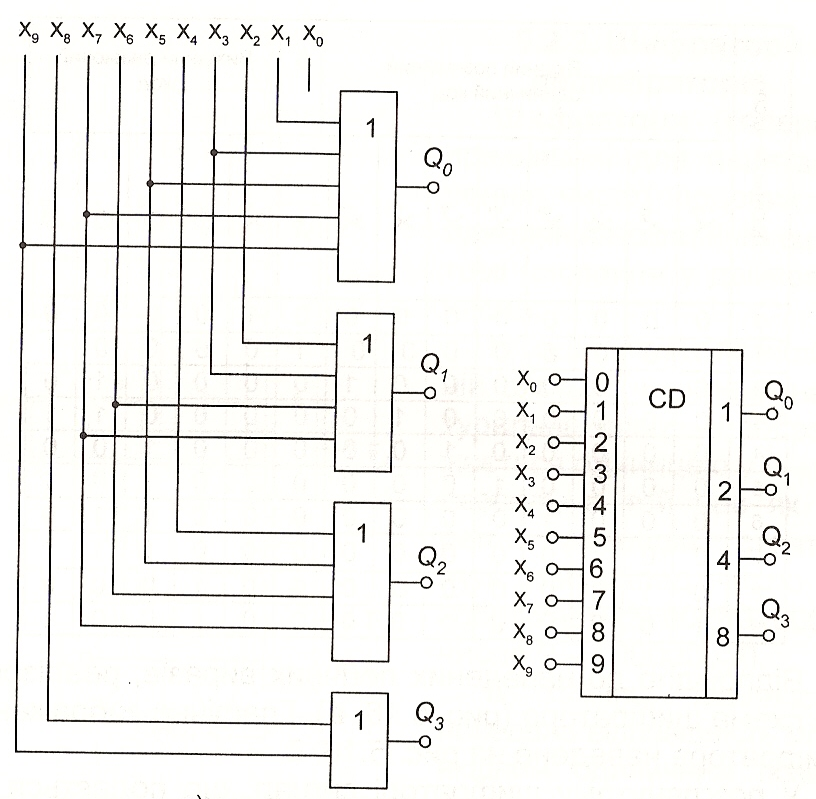
Результаты
Кодировка Unicode— dCode
Тэги: Кодировка символов, Интернет
Поделиться
dCode и другие
dCode является бесплатным, а его инструменты являются ценным подспорьем в играх, математике, геокэшинге, головоломках и задачах, которые нужно решать каждый день!
Предложение? обратная связь? Жук ? идея ? Запись в dCode !
Декодер Unicode
Кодировщик Unicode
Инструмент для перевода кодов Unicode.Юникод — это стандарт кодировки символов, цель которого — дать каждому символу числовой идентификатор.
Ответы на вопросы
Что такое стандарт Unicode?
Unicode — это компьютерная система кодирования, цель которой — унифицировать обмен текстами на международном уровне. В коде Unicode каждый компьютерный символ описывается именем и кодом, однозначно идентифицирующим его, независимо от используемого компьютерного носителя или программного обеспечения. Unicode уже содержит более 100000 символов.
Unicode уже содержит более 100000 символов.
Среди первых символов Unicode — 128 кодов ASCII (включая латинский алфавит), затем международный фонетический алфавит, затем местные алфавиты (греческий, кириллица и т. Д.), Затем символы и многие другие …
Сообщение, закодированное с помощью Unicode , состоит из чисел, которые автоматически переводятся на экран в символы, которые могут отображаться пользователю (через UTF-8 или UTF16).
Как зашифровать текст с помощью шифра Unicode?
Unicode шифрование может быть выполнено путем отображения кодов Unicode каждого из символов в сообщении.
Пример: Сообщение DCΦD € (слово DCODE с буквой phi Φ и символом евро €)
Каждый символ фактически закодирован в виде:
| Отображаемый Символ | Unicode Код | Шестнадцатеричный Unicode Код |
|---|---|---|
| D | 68 | 44 |
| C | 67 | 43 |
| Φ | 934 | 03A6 |
| D | 68 | 44 |
| € | 8364 | 20AC |
идентификаторы Unicode числовые , как и ASCII, регулярно отображаются в шестнадцатеричном формате для более лаконичного написания.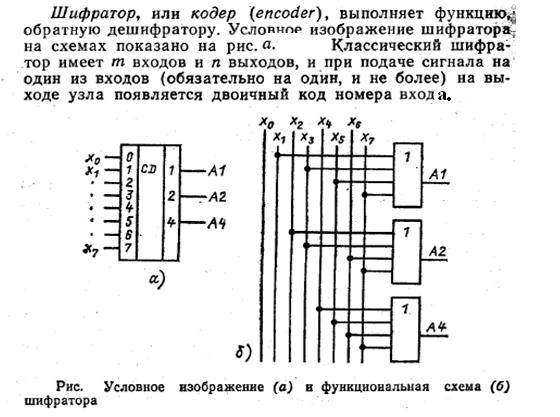
Полная таблица кодирования доступна на официальном сайте здесь (ссылка) или здесь (ссылка)
Как расшифровать текст с помощью шифра Unicode?
Чтобы выполнить перевод сообщения Unicode , повторно ассоциируйте каждый код идентификатора с его символом Unicode .
Пример: Сообщение 68,67,934,68,8364 переводится на каждое число: 68 => D, 67 => C и так далее, чтобы получить DCΦD €.
Как распознать зашифрованный текст Unicode?
Сообщение состоит из чисел (десятичный или шестнадцатеричный формат, реже двоичный).Для текста, состоящего из букв латинского алфавита, наиболее частыми будут числа от 64 до 122 (соответствующие кодам ASCII и Unicode букв A-Z и a-z).
Что такое UTF-8? (Определение)
UTF-8 — это система кодирования, полностью совместимая с Unicode и , которая имеет то преимущество, что она обратно совместима с ASCII. UTF8 используется более чем на 90% веб-сайтов.
UTF-16 — вариант 16-битной кодировки, используемый Windows. UTF-32 — еще один вариант, который пока мало используется.
Задайте новый вопросДвоичный кодер и декодер
Двоичный кодировщик и декодер
В этой статье мы обсудим устройство и работу двоичного кодировщика и декодера с логическими диаграммами и таблицами истинности.
Двоичный кодировщик
Цифровой кодировщик , более известный как двоичный кодировщик , принимает все свои входные данные по одному, а затем преобразует их в один закодированный выход.
Можно сказать, что двоичный кодировщик — это комбинационная логическая схема с несколькими входами, которая преобразует данные логического уровня «1» на своих входах в эквивалентный двоичный код на своем выходе.
«n-битный» двоичный кодер имеет 2 n входных линий и n-битных выходных линий, например конфигурации 4-к-2, 8-к-3 и 16-к-4 строкам.
Выходные строки цифрового кодировщика генерируют двоичный эквивалент входной строки, значение которой равно «1», и доступны для кодирования либо десятичного, либо шестнадцатеричного входного шаблона в двоичный или двоично-десятичный (двоично-десятичный) выходной сигнал. код.
код.
4-в-2-битный двоичный кодировщик
Рис.1
Одним из основных недостатков стандартных цифровых энкодеров является то, что они могут генерировать неправильный выходной код, когда на логическом уровне «1» присутствует более одного входа.Например, если мы сделаем входы D 1 и D 2 ВЫСОКИМ при логической «1» одновременно, результирующий выход не будет ни «01», ни «10», но будет иметь «11», что является выходным двоичным числом, которое отличается от фактического присутствующего входного числа. Кроме того, выходной код всех логических «0» может быть сгенерирован, когда все его входы находятся на «0», ИЛИ, когда вход D 0 равен единице.
Одним из простых способов решения этой проблемы является добавление приоритета к уровню каждого входного вывода, и если бы было более одного входа на логическом уровне «1», фактический выходной код соответствовал бы только входу с наивысшим назначенным приоритетом.Затем этот тип цифрового кодировщика широко известен как Priority Encoder или P-encoder для краткости.%D0%A8%D0%98%D0%A4%D0%A0%D0%90%D0%A2%D0%9E%D0%A0%D0%AB.doc_html_29ed583efed510c1.png)
Кодер приоритета
Кодер приоритета решает проблемы, упомянутые выше, назначая уровень приоритета каждому входу.
Кодеры приоритета Выход соответствует текущему активному входу, имеющему наивысший приоритет.
Таким образом, когда присутствует вход с более высоким приоритетом, все другие входы с более низким приоритетом будут игнорироваться.
Кодировщик приоритета имеет множество различных форм с примером кодировщика приоритета с 8 входами вместе с его таблицей истинности, показанной ниже.
Кодировщик приоритета 8-в-3
Рис.2
КодерыPriority доступны в стандартной форме IC.
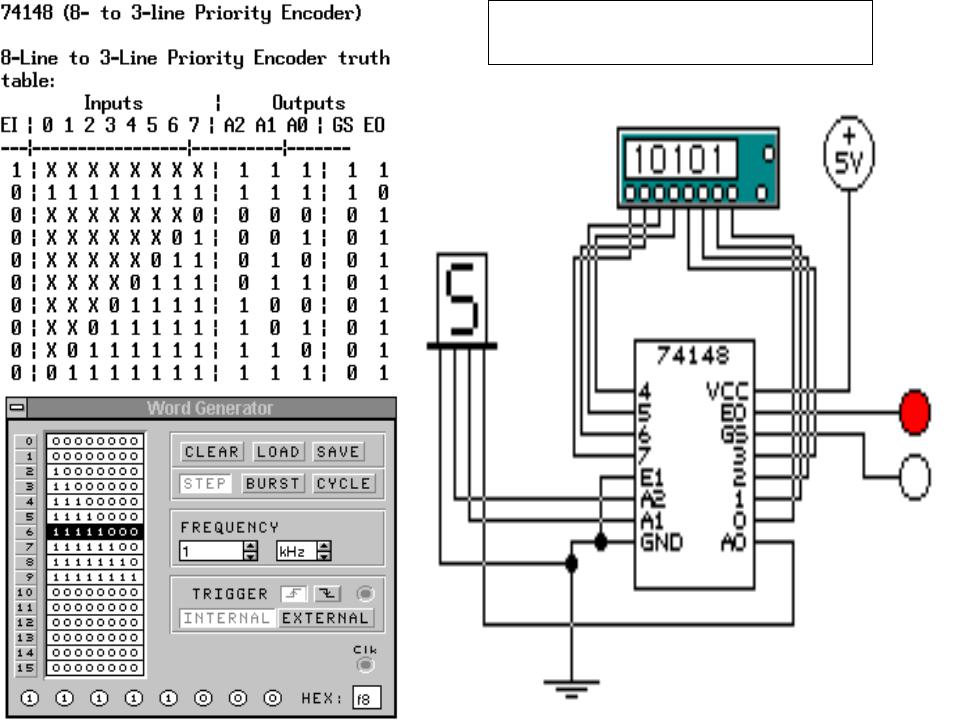
TTL 74LS148 — это кодировщик с приоритетом от 8 до 3, который имеет восемь активных входов LOW (логический «0») и обеспечивает 3-битный код входа с наивысшим рейтингом на своем выходе.
Приоритетные энкодеры сначала выводят вход наивысшего порядка, например, если входные линии «D2», «D3» и «D5» применяются одновременно, выходной код будет для входа «D5» («101»), поскольку он имеет наивысший порядок. из 3 входов.После удаления входа «D5» следующий по величине выходной код будет для входа «D3» («011») и так далее.
из 3 входов.После удаления входа «D5» следующий по величине выходной код будет для входа «D3» («011») и так далее.
Таблица истинности для кодировщика с приоритетом от 8 до 3 бит имеет следующий вид:
Рис.3
Где X равно «безразлично», то есть логический «0» или логическая «1».
Из этой таблицы истинности логическое выражение для кодировщика выше с входами данных от D 0 до D 7 и выходами Q 0 , Q 1 , Q 2 дается как:
Выход Q 0 :
Выход Q 1 :
Выход Q 2 :
Мы можем сконструировать простой кодировщик из приведенного выше выражения, используя отдельные логические элементы ИЛИ следующим образом.
Цифровой кодировщик с логическими воротами
Рис.4
Двоичный декодер
Двоичный декодер — это комбинационная логическая схема, которая полностью противоположна схеме кодировщика.
Название «Декодер» означает перевод или декодирование кодированной информации из одного формата в другой, поэтому цифровой декодер преобразует набор цифровых входных сигналов в эквивалентный десятичный код на своем выходе.
Декодер обычно декодирует двоичное значение в недвоичное, устанавливая ровно один из своих n выходов на логическую «1».
Если двоичный декодер получает n входов (обычно сгруппированных как одно двоичное или логическое число), он активирует один и только один из своих 2n выходов на основе этого входа, при этом все остальные выходы деактивированы.
Можно сказать, что стандартный декодер с комбинационной логикой — это декодер n-to-m, где m ≤ 2n, и чей выход Q зависит только от его текущих входных состояний.
Другими словами, двоичный декодер смотрит на свои текущие входы, определяет, какой двоичный код или двоичное число присутствует на его входах, и выбирает соответствующий выход, который соответствует этому двоичному входу.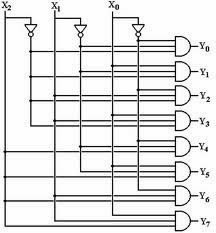
Обычно доступные декодеры BCD-to-Decimal включают TTL 7442 или CMOS 4028.
Обычно выходной код декодера обычно имеет больше битов, чем его входной код, а практические схемы «двоичного декодера» включают в себя конфигурации строк с 2 на 4, с 3 на 8 и с 4 на 16.
Пример декодера 2–4 строк вместе с его таблицей истинности приведен ниже.
Двоичный декодер 2-в-4
Рис.5
Рис.6
Этот простой пример двоичного декодера 2–4 строк состоит из массива из четырех логических элементов И.
2 двоичных входа, обозначенных A и B, декодируются в один из 4 выходов. Каждый выход представляет собой одно из значений двух входных переменных.
Двоичные входы A и B определяют, какая выходная линия от Q 0 до Q 3 является «ВЫСОКОЙ» на логическом уровне «1», в то время как остальные выходы удерживаются на «НИЗКОМ» при логическом «0». Таким образом, только один выход может быть активным (ВЫСОКИЙ) одновременно.
Следовательно, какая бы выходная строка ни была «ВЫСОКОЙ», это идентифицирует двоичный код, присутствующий на входе, другими словами, она «расшифровывает» двоичный вход.
Некоторые двоичные декодеры имеют дополнительный входной вывод с надписью «Enable», который управляет выходами устройства. Этот дополнительный вход позволяет включать или выключать выходы декодера по мере необходимости. Эти типы двоичных декодеров обычно используются как «декодеры адреса памяти» в приложениях микропроцессорной памяти.
Рис.7
Можно сказать, что двоичный декодер — это демультиплексор с дополнительной линией данных, которая используется для включения декодера.
Альтернативный подход к схеме декодера — рассматривать входы A, B и C как сигналы адреса.Каждая комбинация A, B или C определяет уникальный адрес памяти.
Sasmita
Привет! Я Сасмита. В ElectronicsPost.com я продолжаю свою любовь к преподаванию. Я магистр электроники и телекоммуникаций.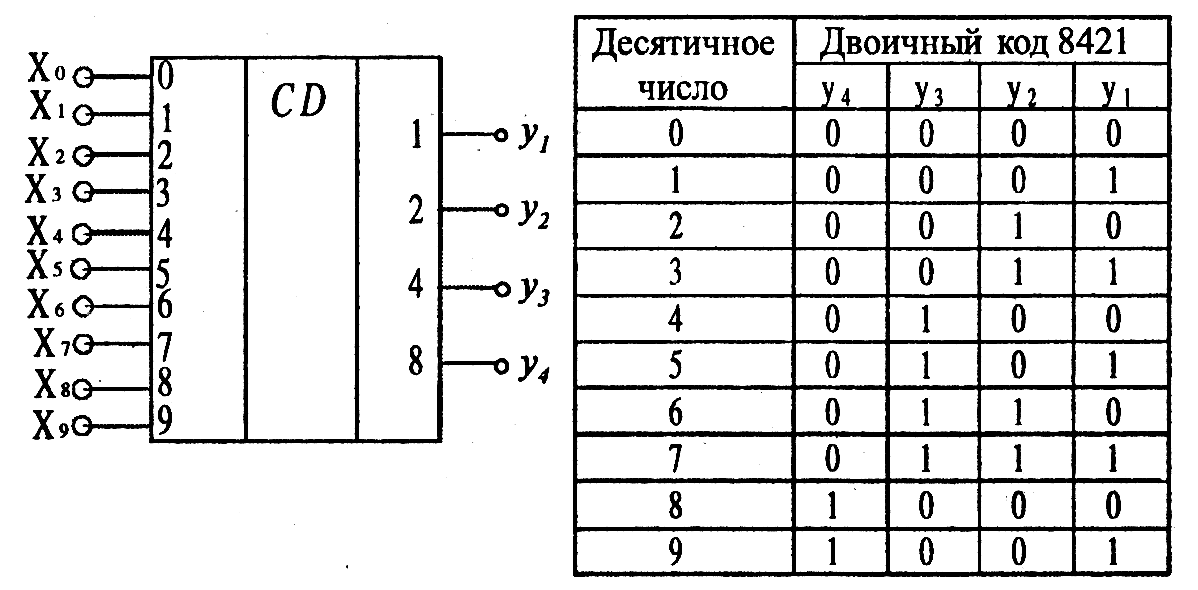 И, если вы действительно хотите узнать обо мне больше, посетите мою страницу «О нас».
Узнать больше
И, если вы действительно хотите узнать обо мне больше, посетите мою страницу «О нас».
Узнать больше
Base64 — онлайн
Около
Встречайте Base64 Decode and Encode, простой онлайн-инструмент, который делает именно то, что говорит: декодирует из кодировки Base64, а также быстро и легко кодирует в нее.Base64 кодирует ваши данные без проблем или декодирует их в удобочитаемый формат. Схемы кодированияBase64 обычно используются, когда необходимо кодировать двоичные данные, особенно когда эти данные необходимо хранить и передавать на носителях, предназначенных для работы с текстом. Это кодирование помогает гарантировать, что данные останутся нетронутыми без изменений во время транспортировки. Base64 обычно используется в ряде приложений, включая электронную почту через MIME, а также для хранения сложных данных в XML или JSON.
Дополнительные параметры
- Набор символов: На нашем веб-сайте используется набор символов UTF-8, поэтому ваши входные данные передаются в этом формате.
 Измените этот параметр, если вы хотите преобразовать данные в другой набор символов перед кодированием. Обратите внимание, что в случае текстовых данных схема кодирования не содержит набора символов, поэтому вам, возможно, придется указать соответствующий набор в процессе декодирования. Что касается файлов, по умолчанию используется двоичный параметр, который не учитывает преобразование; эта опция требуется для всего, кроме текстовых документов.
Измените этот параметр, если вы хотите преобразовать данные в другой набор символов перед кодированием. Обратите внимание, что в случае текстовых данных схема кодирования не содержит набора символов, поэтому вам, возможно, придется указать соответствующий набор в процессе декодирования. Что касается файлов, по умолчанию используется двоичный параметр, который не учитывает преобразование; эта опция требуется для всего, кроме текстовых документов. - Разделитель новой строки: Системы Unix и Windows используют разные символы разрыва строки, поэтому перед кодированием любой вариант будет заменен в ваших данных выбранным параметром. Для раздела файлов это частично неактуально, поскольку файлы уже содержат соответствующие разделители, но вы можете определить, какой из них использовать для функций «кодировать каждую строку отдельно» и «разбивать строки на куски».
- Кодировать каждую строку отдельно: Даже символы новой строки преобразуются в их закодированные в Base64 формы.
 Используйте эту опцию, если вы хотите закодировать несколько независимых записей данных, разделенных переносом строки. (*)
Используйте эту опцию, если вы хотите закодировать несколько независимых записей данных, разделенных переносом строки. (*) - Разделить строки на фрагменты: Закодированные данные станут непрерывным текстом без пробелов, поэтому отметьте этот параметр, если хотите разбить его на несколько строк. Применяемое ограничение на количество символов определено в спецификации MIME (RFC 2045), в которой указано, что длина закодированных строк не должна превышать 76 символов. (*)
- Выполнить безопасное кодирование URL: Использование стандартного Base64 в URL требует кодирования символов «+», «/» и «=» в их процентной форме, что делает строку излишне длиннее.Включите этот параметр, чтобы кодировать в вариант Base64, удобный для URL и имени файла (RFC 4648 / Base64URL), где символы «+» и «/» соответственно заменены на «-» и «_», а также заполнение «= знаки опущены.
- Режим реального времени: Когда вы включаете эту опцию, введенные данные немедленно кодируются с помощью встроенных функций JavaScript вашего браузера, без отправки какой-либо информации на наши серверы.
 В настоящее время этот режим поддерживает только набор символов UTF-8.
В настоящее время этот режим поддерживает только набор символов UTF-8.
Надежно и надежно
Все коммуникации с нашими серверами происходят через безопасные зашифрованные соединения SSL (https). Мы удаляем загруженные файлы с наших серверов сразу после обработки, а получившийся загружаемый файл удаляется сразу после первой попытки загрузки или 15 минут бездействия (в зависимости от того, что короче). Мы никоим образом не храним и не проверяем содержимое отправленных данных или загруженных файлов. Прочтите нашу политику конфиденциальности ниже для получения более подробной информации.
Совершенно бесплатно
Наш инструмент можно использовать бесплатно.Отныне вам не нужно скачивать какое-либо программное обеспечение для таких простых задач.
Подробности кодирования Base64
Base64 — это общий термин для ряда аналогичных схем кодирования, которые кодируют двоичные данные, обрабатывая их численно и переводя в представление base-64. Термин Base64 происходит от конкретной кодировки передачи содержимого MIME.
Термин Base64 происходит от конкретной кодировки передачи содержимого MIME.
Дизайн
Конкретный выбор символов для создания 64 символов, необходимых для Base64, варьируется в зависимости от реализации.Общее правило состоит в том, чтобы выбрать набор из 64 символов, который является как 1) частью подмножества, общего для большинства кодировок, и 2) также пригодным для печати. Эта комбинация оставляет маловероятным изменение данных при передаче через такие системы, как электронная почта, которые традиционно не были 8-битными чистыми. Например, реализация MIME Base64 использует A-Z, a-z и 0-9 для первых 62 значений, а также «+» и «/» для последних двух. Другие варианты, обычно производные от Base64, разделяют это свойство, но отличаются символами, выбранными для последних двух значений; Примером является безопасный для URL и имени файла вариант «RFC 4648 / Base64URL», в котором используются «-» и «_».
Пример
Вот отрывок цитаты из Левиафана Томаса Гоббса:
« Человек отличается не только по своей причине, но . .. »
.. »
Это представлено как последовательность байтов ASCII и закодировано в MIME. Схема Base64 выглядит следующим образом:
TWFuIGlzIGRpc3Rpbmd1aXNoZWQsIG5vdCBvbmx5IGJ5IGhpcyByZWFzb24sIGJ1dCAuLi4 =
В приведенной выше цитате закодированное значение Man Man. Закодированные в ASCII буквы «M», «a» и «n» сохраняются как байты 77, 97, 110, которые эквивалентны «01001101», «01100001» и «01101110» в базе 2.Эти три байта объединяются в 24-битный буфер, образуя двоичную последовательность «010011010110000101101110». Пакеты из 6 бит (6 бит имеют максимум 64 различных двоичных значения) преобразуются в 4 числа (24 = 4 * 6 бит), которые затем преобразуются в соответствующие им значения в Base64.
| Текстовое содержание | M | a | n | |||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| ASCII | 77 | 97 | 110 | |||||||||||||||||||||
| Битовая комбинация | 0 | 1 | 0 | 0 | 1 | 1 | 0 | 1 | 0 | 1 | 1 | 0 | 0 | 0 | 0 | 1 | 0 | 1 | 1 | 0 | 1 | 1 | 1 | 0 |
| Индекс | 19 | 22 | 5 | 46 | ||||||||||||||||||||
| в кодировке Base64 | Т | Вт | F | u | ||||||||||||||||||||
Как показывает этот пример, при кодировании Base64 3 некодированных байта (в данном случае символы ASCII) преобразуются в 4 закодированных символа ASCII.