Что такое спектрограмма звука. Как формируется спектрограмма. Какую информацию можно получить из спектрограммы. Где применяются спектрограммы звука. Как анализировать спектрограммы акустических сигналов.
Что такое спектрограмма звука
Спектрограмма звука — это визуальное представление спектра частот звукового сигнала с течением времени. Она позволяет анализировать частотный состав и другие характеристики звука в динамике.
Основные параметры спектрограммы:
- По горизонтальной оси откладывается время
- По вертикальной оси — частота
- Интенсивность или амплитуда сигнала отображается цветом или яркостью
Таким образом, спектрограмма представляет собой трехмерное изображение звука, где третье измерение (амплитуда) кодируется цветом.
Как формируется спектрограмма звука
Процесс построения спектрограммы включает следующие этапы:
- Звуковой сигнал разбивается на короткие временные отрезки (окна)
- Для каждого окна вычисляется спектр частот с помощью преобразования Фурье
- Полученные спектры выстраиваются последовательно по оси времени
- Амплитуда спектральных составляющих кодируется цветом или яркостью
Ключевой момент — использование оконного преобразования Фурье, позволяющего анализировать изменение спектра во времени.
Какую информацию можно получить из спектрограммы
Спектрограмма позволяет визуально оценить следующие характеристики звука:
- Частотный состав сигнала
- Интенсивность различных частотных составляющих
- Изменение спектра во времени
- Наличие гармоник и обертонов
- Присутствие шумовых компонентов
- Модуляции сигнала
По спектрограмме можно определить основную частоту звука, его тембр, особенности артикуляции речи и многое другое.
Где применяются спектрограммы звука
Основные области применения спектрограмм:
- Анализ речи и распознавание голоса
- Акустическая фонетика
- Музыкальный анализ
- Биоакустика (изучение звуков животных)
- Техническая диагностика по спектру шума и вибраций
- Сейсмология
- Радиоастрономия
Спектрограммы стали важным инструментом исследования звуковых сигналов в самых разных сферах науки и техники.
Как анализировать спектрограммы акустических сигналов
При анализе спектрограмм обращают внимание на следующие характеристики:
- Наличие ярко выраженных частотных полос (формант)
- Распределение энергии по частотам
- Изменение частотного состава во времени
- Присутствие гармоник основного тона
- Шумовые компоненты
- Модуляции сигнала
Для речевых сигналов анализируют расположение формант, их ширину и интенсивность. Для музыкальных звуков изучают гармоническую структуру. В технической диагностике ищут характерные спектральные признаки различных неисправностей.
Программные инструменты для построения спектрограмм
Для создания и анализа спектрограмм используются различные программные средства:
- Специализированные аудиоредакторы (Audacity, Adobe Audition)
- Программы для анализа речи (Praat)
- Математические пакеты (MATLAB, GNU Octave)
- Библиотеки для обработки сигналов (SciPy в Python)
- Онлайн-сервисы для визуализации звука
Выбор инструмента зависит от конкретных задач и требуемой функциональности. Для научных исследований чаще используют специализированное ПО.
Ограничения метода спектрального анализа звука
При использовании спектрограмм важно учитывать некоторые ограничения метода:
- Существует компромисс между временным и частотным разрешением
- Анализ нестационарных сигналов может быть затруднен
- Интерпретация спектрограмм требует опыта и знаний
- Метод чувствителен к шумам и помехам
- Не всегда возможно однозначно выделить отдельные компоненты сигнала
Тем не менее, при правильном применении спектрограммы остаются мощным инструментом анализа акустических сигналов в самых разных областях.
Перспективы развития методов спектрального анализа звука
Современные тенденции в развитии спектрального анализа звука включают:
- Применение вейвлет-преобразований для анализа нестационарных сигналов
- Использование методов машинного обучения для автоматизации анализа
- Разработку адаптивных методов анализа с переменным разрешением
- Создание трехмерных и многомерных спектрограмм
- Комбинирование спектрального анализа с другими методами обработки сигналов
Развитие технологий открывает новые возможности для более глубокого и детального анализа акустических сигналов с помощью спектрограмм.
Рисуем звук / Хабр
Пять лет назад на Хабре была опубликована статья
«Печать и воспроизведение звука на бумаге»— о системе создания и проигрывания
. Затем, полтора года назад
Meklonопубликовал
квест, в котором такая чёрно-белая логарифмическая спектрограмма стала одним из этапов. По авторскому замыслу, её надо было распечатать на принтере, отсканировать смартфоном с приложением-проигрывателем, и воспользоваться таким образом «надиктованным» паролем.
У меня в тот момент не было в досягаемости ни принтера, ни смартфона, так что меня заинтересовали два аспекта задачи:
- Как проще всего расшифровать спектрограмму без дополнительных устройств и без дополнительного софта — желательно, прямо в браузере?
- Можно ли её расшифровать вообще без софта — «на глаз»?
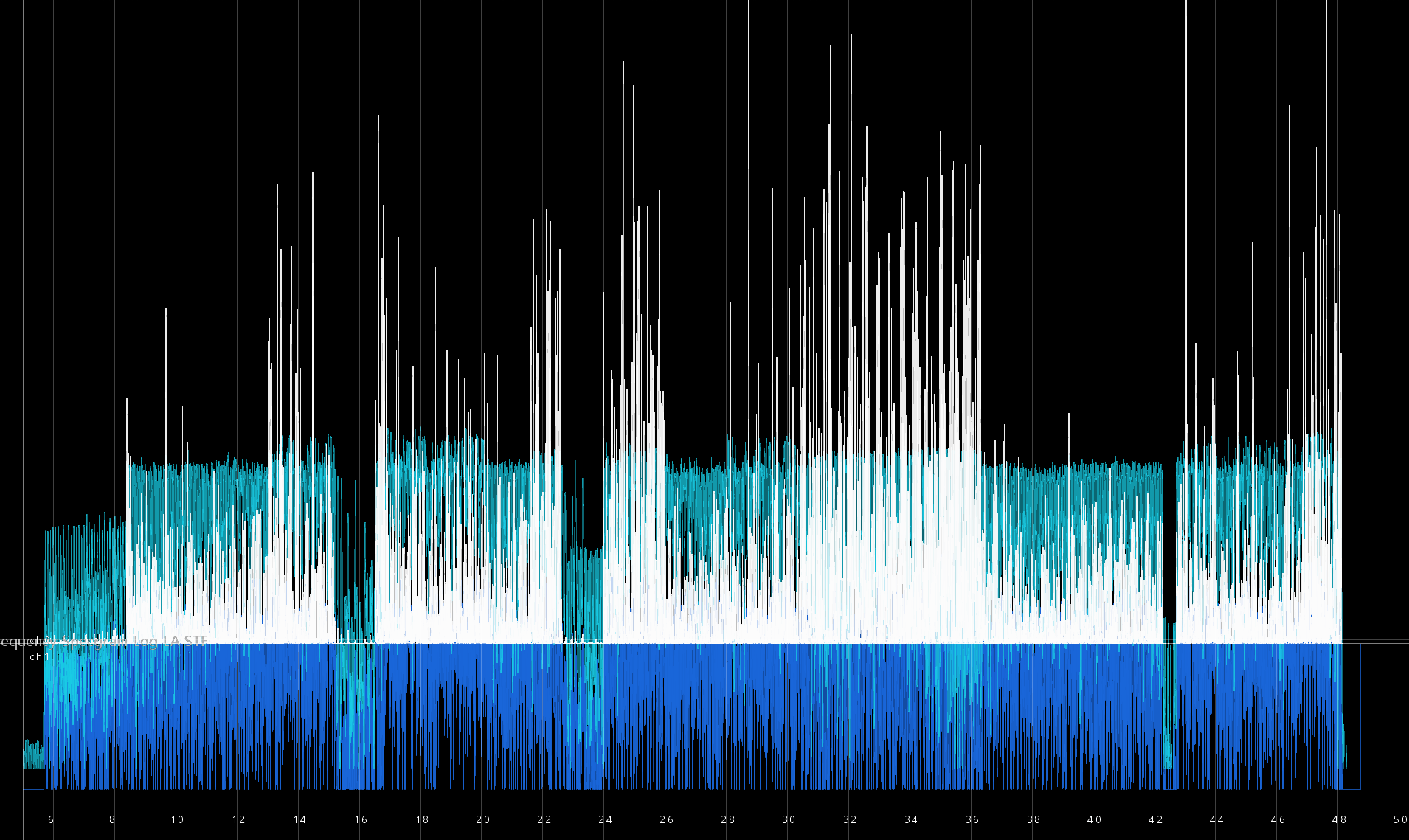
(Для тех, кто видит спектрограммы впервые, стоит пояснить, что это график, где по горизонтальной оси идёт время воспроизведения, по вертикальной (она логарифмическая) — частота звука, а степень черноты точки обозначает мощность данной частоты в данный момент времени.
Готовых скриптов для воспроизведения спектрограмм я не нашёл, хотя для обратного преобразования — звука в спектрограмму — легко*находятся примеры, благодаря тому, что функциональность AnalyserNode.getByteFrequencyData() встроена в Web Audio API. А вот для преобразования массива частот в массив PCM для воспроизведения — не обойтись без реализации в скрипте обратного преобразования Фурье (DFT).
*В первом примере в качестве аудиозаписи для спектрального анализа предлагается фрагмент трека «» от Aphex Twin: в качестве секретного послания музыкант встроил в этот трек селфи, проявляющееся на логарифмической спектрограмме. К сожалению, в этом примере спектрограмма отображается линейно, так что лицо получается растянутым вверху и сжатым внизу.
По поводу реализации DFT сразу ясно, что такая «числодробилка» на чистом JavaScript будет работать медленно и печально; к счастью, я обнаружил
библиотеки FFTW («Fastest Fourier Transform in the West») на asm.js — это форма представления низкоуровневого кода, обычно написанного на Си, которую современные браузеры обещают выполнять со скоростью почти как у скомпилированного в машинный код. Обвязку для FFTW, превращающую чёрно-белое изображение в WAV-файл, я взял из
ARSSи собственноручно переписал на JavaScript. ARSS принимает изображения, инвертированные по сравнению с PhonoPaper, и я не стал это менять.
Результатом вы можете полюбоваться на tyomitch.github.io/#meklon.png
Внизу видны повторяющиеся горизонтальные полосы — форманты, по положению которых распознаются гласные. Вверху — вертикальные «всплески», соответствующие шумным согласным: более широкие — щелевым (фрикативным), более узкие — смычным. Сонорным же согласным ([р] и [л]) соответствуют «облака» в средних частотах.
Для того, чтобы можно было поиграть со спектрограммой, я приделал примитивную рисовалку, почти целиком скопированную из туториала по рисованию на canvas. Кнопка «Copy» позволяет перевести изображение в красный канал (он игнорируется синтезатором) и попытаться «обвести» звуки.
Википедия пишет: «Считается, что для характеристики звуков речи достаточно выделения четырёх формант». Обведём форманты F2-F4 (F1 почему-то игнорируется синтезатором), и убедимся, что гласные вполне распознаются:
Затем обведём шумные согласные: аффриката [ч] — это [т], плавно переходящее в [ш]; а звонкое [д] от глухого [т] отличается наличием среднечастотных формант. Теперь уже можно различить цифры «шесть» и «де’ить»:
Добавляем тёмно-серым сонорные согласные: заодно заметим, что [р] немного «приподнимает» гласные форманты, а [л] — наоборот, опускает.
Остались недорисованными только губные согласные [б] и [в], но и без них пароль более-менее ясен.
А можно ли нарисовать звук с чистого листа, не обводя спектрограмму аудиозаписи? Скажу честно, у меня не получилось. Может быть, хотите попробовать сами?
Как нейронная сеть SincNet выделяет значимые частоты в звуке через Back Propagation / Хабр
Недавно вышла одна очень интересная статья «Speaker Recognition from raw waveform with SincNet», в которой была описана end-to-end архитектура нейронной сети для распознавания говорящего по голосу. Ключевая особенность этой архитектуры — специальные одномерные сверточные слои, которые имеют всего два параметра с четкой интерпретацией. Интерпретируемость параметров нейронной сети — дело довольно затруднительное, поэтому эта статья привлекла мой интерес.
Если заинтересовало описание идеи этой статьи, а также почему эта идея близка по смыслу к построению мел-спектрограмм, то милости прошу под кат.
Отмечу, что все изображения, используемые в этом посте либо взяты из исходной статьи, либо их можно получить с помощью Jupyter Notebook’а, хранящегося в этом репозитории.
Авторами описываемой статьи был выложен исходный код на гитхаб, с ним можно ознакомиться здесь.
Мел-спектрограммы
Чтобы понять суть этой статьи, давайте сначала вспомним, что такое мел-спектрограмма, как ее получить и в чем ее смысл. Если эта тема вам знакома, то эта часть будет не очень интересной. Ее вычисляют по обычной спектрограмме, построенной с помощью оконного преобразования Фурье:
Суть этой операции в последовательном применении преобразования Фурье к коротким кусочкам речевого сигнала, домноженным на некоторую оконную функцию. Результат применения оконного преобразования — это матрица, где каждый столбец является спектром короткого участка исходного сигнала. Посмотрите на пример ниже:
Эксперименты ученых показали, что человеческое ухо более чувствительно к изменениям звука на низких частотах, чем на высоких. То есть, если частота звука изменится со 100 Гц на 120 Гц, человек с очень высокой вероятностью заметит это изменение. А вот если частота изменится с 10000 Гц на 10020 Гц, это изменение мы вряд ли сможем уловить.
В связи с этим была введена новая единица измерения высоты звука — мел. Она основана на психо-физиологическом восприятии звука человеком, и логарифмически зависит от частоты:
Собственно, мел-спектрограмма — это обычная спектрограмма, где частота выражена не в Гц, а в мелах. Переход к мелам осуществляется с помощью применения мел-фильтров к исходной спектрограмме. Мел-фильтры представляют из себя треугольные функции, равномерно распределенные на мел-шкале. В качестве примера здесь изображены 10 мел-фильтров (на практике их берут больше, здесь их мало для наглядности):
При переводе в частотную шкалы, те же самые фильтры будут выглядеть так:
Каждый столбец исходной спектрограммы скалярно умножается на каждый мел-фильтр (размещенный на частотной шкале), после чего получается вектор чисел, по размеру равный количеству фильтров. На картинке ниже изображен один из столбцов спектрограммы (значения амплитуды переведены в логарифмический масштаб для наглядности, то, что на картинке кодировалось цветом, здесь отражено по оси ординат) и два мел-фильтра, с помощью которых строится мел-спектрограмма:
В результате таких преобразований значения из низких частот спектрограммы остаются практически неизменными на мел-спектре, а в высоких частотах происходит усреднение значений из более широкого диапазона. В качестве примера предлагаю посмотреть на мел-спектрограмму, построенную по предыдущей спектрограмме с использованием 64 мел-фильтров:
Резюмируя все вышесказанное: на мел-спектрограмме сохраняется больше информации, которая хорошо воспринимается и различается человеком, чем на обычной спектрограмме. Иными словами, такое представление звука больше сфокусировано на низких частотах, и меньше — на высоких.
При чем же здесь SincNet?
Вспомним, что мел-шкала была создана на основе человеческого психо-физического восприятия звука. Но что если мы хотим выбрать другие полосы частот, которые нас интересуют больше чем остальные в какой-либо конкретной задаче? Как выбрать самый лучший набор фильтров для решения какой-либо задачи?
Именно эту задачу и решает предложенная авторами архитектура.
Авторы рассматривают в качестве фильтра следующую функцию:
в этой формуле — это прямоугольная функция. Такой фильтр задает диапазон частот от до . Вот ее график:
С помощью обратного преобразования Фурье для этой функции можно получить ее аналог во временной области:
Функция — это импульсная характеристика идеального полосового фильтра, который нельзя реализовать практически, поэтому авторы усекают эту функцию окном Хэмминга. В цифровой обработке сигналов такой подход называется синтезом фильтров методом окон.
Усеченный окном вариант функции авторы предлагают использовать в качестве шаблона для всех сверток, применяемых к сырым аудио данным. Эта функция дифференцируема по параметрам и , а значит ее можно использовать при оптимизации параметров сети методом обратного распространения ошибки.
По теореме о свертке, свертка исходного сигнала с функцией эквивалентна умножению спектра исходного сигнала на функцию . Грубо говоря, выполняя свертку исходного сигнала с функцией , мы «обращаем внимание» нейронной сети на данный диапазон частот в рассматриваемом сигнале.
Конечно, здесь не применяется преобразование Фурье и явно нейросети не сообщаются конкретные значения спектра в диапазоне . По всей видимости, задача извлечения спектральных характеристик возлагается на следующие блоки, расположенные в нейронной сети.
Из достоинств такого подхода, авторы отмечают следующее:
- Быстрая сходимость
- Гораздо меньшее количество параметров. В классическом сверточном блоке количество параметров равно длине свертки. При описанном же подходе, количество параметров не зависит от длины свертки и равно 2
- Интерпретируемость параметров
Выводы
Фильтров, с помощью которых преобразуются спектрограммы, существуют много. Например, кроме описанных мел-фильтров, есть еще барк-фильтры (почитать можно здесь и здесь). По крайней мере барк — это тоже психофизическая величина, подобранная «под человека».
В своем исследовании авторы предложили метод, по которому можно заставить нейронную сеть самостоятельно выбрать наиболее подходящие диапазоны частот в процессе обучения в зависимости от набора данных. Как по мне, это очень похоже на процесс построения мел-спектрограммы, при котором больший приоритет отдается низким частотам. Вот только мел-спектрограммы придумали на основе человеческого восприятия звука, а в предложенном методе нейросеть сама решает, что важно, а что нет.
Рисуем звук. Часть 1
Привет! В серии статей мы расскажем для чего и как в системе визуализации звука SVS используется спектрограмма, как выбрать лучшую частоту для анализа даже в шумной среде, расскажем о кейсах, которые мы решили.
Начнем, пожалуй 🙂
Физики под звуком понимают «воспринимаемое слухом физическое явление, порождаемое колебательными движениями частиц воздуха или другой среды». Например, натянутой гитарной струны.
Звук как физическое явление характеризуется тремя параметрами: высотой, силой, звуковым спектром.
Что такое спектрограмма?
Под спектрограммой понимают «изображение, показывающее зависимость спектральной плотности мощности сигнала от времени». Иными словами, спектрограмма – это графическое изображение звука.
Спектрограмму сформировать можно двумя способами: аппроксимировать как набор фильтров или рассчитать сигнал по времени с помощью оконного преобразования Фурье.
Распространенное представление спектрограммы – это двумерная диаграмма: на горизонтальной оси представлено время, по вертикальной оси — частота; третье измерение с указанием амплитуды на определенной частоте в конкретный момент времени представлено интенсивностью или цветом каждой точки изображения. Источники интенсивного звука отображаются красным цветом, а тихие области – темно-синим.
Cпектрограмма работы компрессора. Получена с помощью системы визуализации звука SVS
Например, на изображении представлена спектрограмма, полученная при исследовании работы компрессора системой SVS. Один из элементов издавал характерный стук (этот стук видим в виде полосы красного цвета).
Зачем нужна спектрограмма?
Спектрограмма позволяет понимать окружающие звуки. Эта функция может помочь во время поиска неисправности оборудования, а также помочь оптимизировать и улучшить диагностику оборудования. В системе визуализации звука SVS спектрограмма нужна именно для этих целей. Хотите попробовать работу спектрограммы, тогда загляни сюда. В режиме реального времени, звук с микрофона преобразуется (только не забудьте разрешить доступ в браузере), в спектрограмму. При нажатии на спектрограмму приложение воспроизводит звук с соответствующей высотой тона.
Спектрограмма трека Aphex Twin Получена с помощью системы визуализации звука SVS
Проанализировав спектрограмму аудиофайла можно увидеть хаотичное изображение. Например, профессиональные музыканты с помощью таких изображений анализируют музыку и определяют проблемные места. Открылись новые возможности для стеганографии. В спектрограммы зашифровывают целые изображения. Чем и пользуются некоторые энтузиасты: знаменитый диджей Aphex Twin в качестве секретного послания музыкант встроил в этот трек селфи, проявляющееся на логарифмической спектрограмме.
В следующей статье расскажем, как выбрать частоту для анализа звуковой среды.
Готовы ответить на вопросы, пишите @ni_meleshko.
Звуковая спектрограмма — CodeRoad
Я сделал приложение, которое рисует FFT на экране в реальном времени (с микрофона). Время по оси x, частота по оси y и цвет пикселя представляют амплитуду (в значительной степени ванильная спектрограмма FFT).
Моя проблема в том, что, хотя я могу видеть паттерн из музыки, там также много шума. Погуглив его, я вижу, как люди применяют логарифмический расчет к амплитуде. Должен ли я это делать? И если да,то как будет выглядеть формула? (Я использую C#,, но я могу перевести математику в код, так что любой образец в порядке.)
Я могу обойти эту проблему, применив цветовую схему, показывающую более низкие значения как более темные цвета. Я просто не уверен, что звук правильно представлен без логарифмического расчета.
algorithm audioПоделиться Источник Tedd Hansen 20 апреля 2011 в 13:04
2 ответа
-
Спектрограмма между индексами matlab
У меня есть сигнал длиной 507150 образцов, и мне нужна спектрограмма только между образцами 202336 и 234398. Как мне отформатировать функцию спектрограммы? Или есть другой способ?
-
MP3 Звуковая Спектрограмма?
Я искал способ сделать это весь день без всякой надежды. Я создаю проект с функцией воспроизведения MP3 и пытаюсь включить спектрограмму (или анализатор спектра.. не уверен, что это правильное название для него) похоже на этот http://puu.sh/4lkMn.png (Winamp) (хотя, если он не в барах, это тоже…
8
Представление амплитуды в логарифмической шкале приближается к чувствительности слуховой системы человека и, следовательно, дает вам лучшее представление о том, что вы слышите, по сравнению с нелогарифмической шкалой. Математически все, что вам нужно сделать, это:
Alog = 20*log10 (abs (A))
Где A — амплитуда данных FFT, а Alog -выходной сигнал. коэффициент 20 -это просто условность и не влияет на изображение, которое вы, вероятно, все равно масштабируете до цветовой схемы.
EDIT
Пояснение относительно коэффициента 20 : Единица измерения дБ (децибел) является логарифмической единицей измерения коэффициентов : она представляет собой шкалу, на которой расстояние между 100 и 10 такое же, как между 1000 и 100 (поскольку они имеют одинаковое соотношение: 1000/100 = 100/10)., если вы измеряете его в дБ, вы получаете:
10*log10 (1000/100) = 10*log10 (100/10) = 10
Коэффициент 10 -это потому , что deci означает tenth, что означает, что 1 Бел равен 10 deciBels (например, 1 килограмм равен 1000 граммам)
Поскольку слуховая система человека также (приблизительно) измеряет отношения, имеет смысл измерять уровень звука по логарифмической шкале, то есть измерять отношение уровня звука к некоторому эталонному значению.2) = 20*log10 (A/Aref)
по правилам журнала. Это происхождение фактора 20 — помните, что в компьютере звук представлен мгновенной амплитудой звуковой волны.
Поделиться Itamar Katz 20 апреля 2011 в 13:08
3
Просмотр вашей спектрограммы логарифмически-это действительно лучший способ просмотра аудиосигналов. Имейте также в виду, что вам нужно хорошее разрешение как в направлении времени, так и в направлении частоты. Если у вас слишком мало ящиков в одном или другом, это может выглядеть странно.
Еще один важный момент заключается в том, что просмотр STFT в логарифмическом масштабе не является методом шумоподавления. То , что вы видите как «noise» , может быть реальным шумом или такими вещами, как гармоники, переходные процессы, спектральная утечка и другие вещи, которые, как ожидается, будут там. В зависимости от вашего приложения, если вам нужно выполнить кратковременный анализ сигнала, вейвлет -преобразование может быть более подходящим для ваших нужд. Это устраняет некоторые недостатки STFT, такие как постоянный размер окна.
Поделиться Phonon 20 апреля 2011 в 13:25
Похожие вопросы:
Спектрограмма и что это такое
Мне очень интересно узнать, как выглядит верхняя правая цифра в :http://en.wikipedia.org/wiki/ генерируется спектрограмма (сценарий) и как ее анализировать, то есть какую информацию она передает?Я…
Звуковая карта в iPhone
Ну, я не уверен, как это должно называться.. Но мне нужно прочитать звуковой файл и сгенерировать его (в iOS): Это своего рода звуковая карта или звуковая диаграмма… Спасибо!
Найти образец аудио в аудиофайле (спектрограмма уже существует)
Я пытаюсь добиться следующего: Используя Skype, позвоните в мой почтовый ящик (работает) Введите пароль и сообщите почтовому ящику, что я хочу записать новое приветственное сообщение (работает)…
Спектрограмма между индексами matlab
У меня есть сигнал длиной 507150 образцов, и мне нужна спектрограмма только между образцами 202336 и 234398. Как мне отформатировать функцию спектрограммы? Или есть другой способ?
MP3 Звуковая Спектрограмма?
Я искал способ сделать это весь день без всякой надежды. Я создаю проект с функцией воспроизведения MP3 и пытаюсь включить спектрограмму (или анализатор спектра.. не уверен, что это правильное…
Рисование матрицы с градиентом цветов » спектрограмма»
После использования STFT (кратковременного преобразования Фурье) выход представляет собой матрицу, которая представляет собой график 3d, как если бы (A[X, Y] = M) A — это выходная матрица, X-время,…
Как отобразить спектрограмму из wav-файла в C++?
Я делаю проект, в котором хочу встроить изображения в файл .wav, чтобы, когда кто-то увидит спектрограмму с определенными параметрами, он увидел скрытое изображение. Мой вопрос заключается в том,…
Неправильная спектрограмма при использовании scipy.signal.spectrogram
Когда я использую plt.specgram из matplotlib с помощью следующего кода, генерируемая спектрограмма является правильной import matplotlib.pyplot as plt from scipy import signal from scipy.io import…
Спектрограмма в формате matlab — временной оси
У меня есть сигнал тонального всплеска от 0.20 мс до 0.40 МС. От 0 до 0.20ms и от 0.40ms до 3.27ms она равна нулю. Я сделал fft, который показывает частотное содержание около 25 kHz. Число точек fft…
Спектрограмма в python с использованием numpy
Мне нужно сделать спектрограмму, используя numpy. Я беру 1 секцию аудио и разбиваю ее на 0.02s кусок. Затем я вычисляю FFT, используя numpy, и складываю их обратно в одно изображение. Результаты…
Анализ звуков
Звук и основные свойства звуковых волнАнализ звуков
В настоящее время анализ звуков осуществляется с помощью электронных устройств, таких, как анализаторы частот и динамические спектрографы, или сонографы. В первом случае представляется возможность оценивать амплитудно-частотные характеристики звука, но без учета изменений свойств звука во времени. Применение динамических спектрографов дает возможность рассматривать звук в системе трех координат: частота и амплитуда колебаний, и время. Выраженность его спектральных составляющих, то есть интенсивность звучания, отражается на динамической спектрограмме степенью ее затемнения. Изображение сложных звуков в виде динамических спектров впервые было применено для анализа речи и получило название «видимая речь». Пока это является единственным более или менее удовлетворительным приемом преобразования звукового образа в зрительный. Глядя на динамическую спектрограмму, конечно, мы не слышим звука, однако тренированные люди на основе таких «картин» звуков могут даже их имитировать. Для того чтобы в какой-то мере научиться читать динамические спектрограммы, обратимся к примерам.
В качестве первого примера рассмотрим динамическую спектрограмму звука «и», выделенного из слитной речи. На представленной здесь фотографии спектрограммы слева от нее по вертикали изображена шкала частот, соответствующая набору фильтров динамического спектрографа. Каждый из этих фильтров реагирует лишь на определенный узкий диапазон частот и в случае наличия именно таких частот в сигнале отражает их в спектрограмме затемнением той или иной плотности. Диапазон частот, на которые реагирует фильтр, называют полосой пропускания фильтра. Прибор, используемый для анализа данного звука «и», имел 48 фильтров; их полосы пропускания соответствовали значениям частотной избирательности слуха человека. Если фильтры различны по ширине пропускания, то шкала частот на динамической спектрограмме приобретает сложный вид и состоит из разных участков — как с логарифмическим, так и с линейным масштабом. Однако в биоакустических работах применяют и такие динамические спектрографы, у фильтров которых ширина полос пропускания одинакова. Поэтому спектрограммы, полученные с помощью такого прибора, имеют простую, то есть линейную, шкалу частот. Чаще всего берутся фильтры с довольно широкой полосой пропускания — порядка 300 герц. Эта величина указывает на разрешающую способность по частоте динамического спектрографа.
3. Динамическая спектрограмма звука «и», выделенного из слитной речи. Шкала частот сложная и состоит из разных участков — как в линейном, так и в логарифмическом масштабе. Вертикальные линии — метки времени: период следования равен 0,1 секунды. Три участка с наибольшей плотностью потемнения (F1, F2, F3) являются формантными частотами данного гласного звука. На спектрограмме видно, что звук частотно-модулирован по второй форманте.Однако вернемся к рассматриваемой динамической спектрограмме. Длина ее соответствует продолжительности звука «и», которая в данном случае равна 0,2 секунды. На спектрограмме видны несколько зон почернения, отражающих наличие звуковой энергии в тех или иных областях частот, что указывает на присутствие тех или иных спектральных составляющих. Эти зоны почернения называют спектральными максимумами. Самые плотные почернения соответствуют областям формантных частот, каждая из которых представляет собой совокупность нескольких гармоник. Однако на динамической спектрограмме звука «и» они слились в одну область почернения, так как частота основного тона звуков речи (определяющая, как уже отмечалось, расстояние между соседними гармониками) меньше ширины полосы пропускания фильтров спектрографа, с помощью которого произведен анализ этого звука. В силу ограниченных возможностей прибора на данной динамической спектрограмме отсутствует и частота основного тона. Обычно ее определяют с помощью другого, специально предназначенного для этой цели прибора — интонографа.
Рассматривая динамическую спектрограмму звука «и», можно отметить, что одна, а именно вторая форманта постепенно опускается вниз. Это означает изменение (в данном случае — понижение) частоты этой форманты во времени и отражает одну из физических характеристик звука — его частотную модуляцию. Частотная модуляция может иметь разную форму и глубину. Но ее может и не быть совсем, и тогда звук характеризуется как стабильный по частоте. На другой динамической спектрограмме представлены результаты анализа звука визга малыша ондатры, близкого по звучанию к звуку «и», но более громкого и более продолжительного. Здесь частота каждого спектрального максимума изменяется в больших пределах. Другим предстает и характер изменения частоты во времени. Ввиду того, что частота основного тона голоса грызуна выше, чем у человека, на динамической спектрограмме она хорошо видна — это самая низкая по частоте область потемнения. Отчетливо видны и гармоники, представленные здесь в виде трех черных полос, форма которых аналогична форме кривой, отражающей частоту основного тона. Кроме того, в начале и в конце динамической спектрограммы визга легко обнаружить участки с равномерным распределением звуковой энергии в довольно широкой области частот. Это участки звука с так называемым шумовым заполнением.
4. Динамическая спектрограмма визга ондатренка. Шкала частот, как и в предыдущем рисунке, сложная. Вертикальные линии на спектрограмме — метки времени, они следуют с периодом 0,1 секунды. На спектрограмме хорошо видны частота основного тона, соответствующая первой гармонике (f1), и высшие гармоники ([f2, f3, f4). Звук частотно-модулирован. В начале и конце спектрограммы отчетливо видны более или менее равномерно затемненные участки — это участки с шумовым заполнением.На третьей из помещенных здесь фотографий в качестве примера представлено название нашей книги в двух вариантах — в виде текста и в виде динамической спектрограммы произнесенной фразы. Внимательно изучим все три примера, это поможет нам перекинуть мост через пропасть, разделяющую в нашем сознании звук и графическое представление о нем.
5. Динамическая спектрограмма прочитанного вслух названия нашей книги.Распознавание звуков с помощью глубокого обучения
Вы когда-нибудь просыпались с непонятным ощущением: слышишь какой-то звук, но точно знаешь, что в этом звуке что-то не то?
Распознавание звуков — это один базовых инстинктов, позволявших людям избегать опасности. Это умение помогало нам узнавать о приближении хищника. Да и сейчас звуки продолжают играть большую роль в нашей жизни: мы различаем человеческие голоса, наслаждаемся музыкой и пением птиц…
Поэтому совершенно естественно, что важнейшей задачей стала разработка аудиоклассификаторов. Они необходимы для того, чтобы классифицировать источник звука, и уже широко применяются в различных целях. Так, в музыке существует классификатор музыкальных жанров. В последнее время подобные системы стали использоваться и для классификации звуков, издаваемых птицами. Раньше этим занимались орнитологи. Цель этих систем — распределить птиц по категориям. Задача непростая с учётом того, как сложно уловить звуки, издаваемые птицами в полях или шумных окрестностях.
В последнее время глубокое обучение превратилось в одну из самых популярных технологий для решения множества задач. Произошло это благодаря точности глубокого обучения, а также совершенствованию вычислительных устройств, таких как CPU (центральный процессор) и GPU (графический процессор). На приведённой ниже диаграмме показано, насколько важен рынок глубокого обучения, а также его ожидаемый размер с точки зрения программного обеспечения, аппаратного оборудования и услуг:
Рынок глубокого обучения США с 2014 по 2025 год (изображение взято из grandviewresearch.com)В этой статье наша задача — считывание аудиофайла со звуками, издаваемыми птицами (количество: от нуля до нескольких звуков). Кроме того, мы задействуем глубокое обучение для выявления, какой птице какой звук принадлежит. Будем использовать для этого Cornell Birdcall Identification Challenge, в котором мы получили серебряную медаль (с высоким результатом 2%).
Как обращаться с данными
Обработке аудиоданных с получением спектрограммы посвящено бесчисленное множество статей с объяснениями, как загружать звуковые данные, в том числе переводить их в формат спектрограммы, и почему это важно. Вот спектрограмма звуков, издаваемых птицами, на примере мухоловки ольховой и фотография этой птицы (на случай если вам интересно):
Спектрограмма звуков, издаваемых мухоловкой ольховой (изображение автора)Скорость обработки данных — одно из главных условий для применения модели глубокого обучения. Но в то же время с увеличением вычислительной мощности и задействованием центрального процессора стоимость вычислений, связанных с обработкой аудиосигналов, по-прежнему высока. А вот если для обработки данных выбрать другой вычислительный ресурс, например графический процессор, то можно увеличить скорость от десяти до ста раз! Мы продемонстрируем, как быстро обрабатывать спектрограммы, используя библиотеку torchlibrosa, которая позволяет делать это на графическом процессоре.
Создаём процессор для спектрограммы
torchlibrosa — это библиотека Python, в которой есть несколько функций обработки аудиосигналов, реализованных в PyTorch с возможностью использовать ресурсы графического процессора. PyTorch позволяет запускать алгоритм этой спектрограммы на графическом процессоре. Вот пример извлечения функций спектрограммы с помощью torchlibrosa:
from torchlibrosa.stft import Spectrogram
spectrogram_extractor = Spectrogram(
win_length=1024,
hop_length=320
).cuda()Загружаем аудиоданные
Аудиоданные загрузим через одну из популярных на Python библиотек обработки аудиосигналов librosa:
import librosa
# получаем необработанные аудиоданные
example, _ = librosa.load('example.wav', sr=32000, mono=True)Обрабатываем спектрограмму
raw_audio = torch.Tensor(example).unsqueeze(0).cuda()
spectrogram = spectrogram_extractor(raw_audio)Скорость обработки при тестировании
Будем обрабатывать аудиоданные на графическом процессоре, используя библиотеку torchlibrosa. Вы спросите: «А насколько графический процессор справится быстрее, чем центральный процессор?». Вот скорость обработки при тестировании на устройстве:
Мы просто взяли аудио из данных, полученных в ходе проведения Cornell Birdcall Identification Kaggle Challenge (всё из открытого доступа), и сравнили, сколько времени она занимает на центральном процессоре и графическом процессоре. Тестировали на Colab с целью воспроизвести производительность. Оказалось, что обработка log-mel спектрограммы из 5 минутного аудио происходит примерно в 15 раз быстрее на графическом процессоре, чем на центральном процессоре.
Как классифицировать звук
Таким образом, глубокое обучение показало блестящие результаты в аудиосфере. Оно правильно улавливает многочисленные паттерны целевых классов в данных временных рядов. Более важным представляется окружение, в котором птицы издают звуки, и соответствующие данные. Окружающая обстановка (полевые или горные условия) является источником разнообразных шумов, смешивающихся со звуками, издаваемыми птицами. На продолжительной записи могут быть запечатлены звуки нескольких птиц. Поэтому нужно создать аудиоклассификатор со множеством меток и надёжным распознаванием звуков.
Представим архитектуру глубокого обучения, использованную на конкурсе Cornell Birdcall Identification Kaggle Challenge.
Архитектура
Это принципиально новая архитектура аудиоклассификатора, которая эффективно улавливает характеристики временных рядов за счёт использования CNN (свёрточной нейронной сети), RNN (рекуррентной нейронной сети) и механизмов внимания. Вот небольшая блочная диаграмма архитектуры, которая была представлена на этом конкурсе:
Архитектура классификатора звуков, издаваемых птицами (изображение автора)В качестве входных данных архитектуры используем ещё не обработанное аудио с log-mel спектрограммой. Оно проходит через магистральную сеть ResNeSt50, которая является одной из архитектур классификации изображений. После этого доставляем функции, содержащие пространственную и временную информацию, к слоям RoI pooling (области интереса) и bi-GRU (двунаправленным рекуррентным блокам). В этих слоях улавливается информация, касающаяся времени, и уменьшается размер функции. Ведь мы посчитали, что извлечение временных функций имеет решающее значение для классификации количества звуков, издаваемых птицами, в продолжительном аудио. И в заключение передаём данные в механизм внимания, чтобы оценить результаты по каждому временному шагу и выявить, на каком временном шаге проявляют себя птицы.
Обучаем модель
Важно не только создать архитектуру глубокого обучения для представления данных, но и научиться обучать модель (так называемый «рецепт обучения»). Чтобы классифицировать аудио с шумным фоном, в которых есть различные звуки, издаваемые птицами, смешиваем все эти звуки в аудио с шумами, такими как «белый шум». А что касается многочисленных вариаций звуков, издаваемых птицами, увеличиваем высоту звука и маскируем некоторые аудиокадры с помощью SpecAugment.
Вот краткий пример (смешанная версия мухоловки ольховой и американской шилоклювки) тех аугментаций, которые мы применяли.
Заключение
Вы когда-нибудь просыпались с непонятным ощущением: слышишь какой-то звук, но точно знаешь, что в этом звуке что-то не то? С помощью алгоритмов машины смогут избавить вас от непонятных звуков, чтобы вам спалось лучше.
Впервые опубликовано на YourDataBlog.
Читайте также:
Читайте нас в Telegram, VK и Яндекс.Дзен
Перевод статьи Hyeongchan Kim: Detecting Sounds with Deep Learning
Что такое белый шум и почему его не используют в системах маскировки звука
Сегодня в офисах по всему миру борются с шумом с помощью шумовых завес (систем маскировки звука). Часто эти комплексы путают с генераторами белого или розового шума, которые можно встретить в частных домах и отелях. Инженеры-акустики компании Soft dB максимально просто поясняют разницу между ними.
Вы наверняка слышали термин «белый шум». Эту фразу часто употребляют в переносном смысле, когда хотят сказать о потоке бесполезной информации, скрывающей истинную суть происходящего. Возможно, вы также читали о том, что белый шум помогает быстрее уснуть или лучше сосредоточиться, поскольку скрывает громкие звуки в помещении – «маскирует» их. В статьях, посвященных акустике, понятие «белый шум» часто соседствует с терминами «розовый шум» и «маскировка звука». Многие считают их равнозначными и называют системы маскировки звука генераторами белого/розового/красного шума. Это большая ошибка, цена которой — неправильный выбор оборудования для устранения нежелательных шумов в офисе. Почему? Мы попытаемся как можно проще объяснить разницу между разными шумами.
Что такое «белый шум» и почему он «белый»?
Для начала разберемся с белым шумом. Почему его называют «белым»? Разве звук может иметь цвет? Нет, конечно. Тут дело в аналогии. Любой школьник знает, что белый свет – это сочетание всех цветов спектра. По аналогии со светом, белый шум – это «смесь» звуков, воспроизводимых одновременно на всех частотах, которые воспринимает наше ухо. Конечно, инженер бы сказал иначе: белый шум – это шум, спектральные составляющие которого равномерно распределены по всему диапазону используемых частот, т.е. спектральная плотность мощности которых одинакова либо слабо отличается в каком-либо рассматриваемом диапазоне. Но мы ведь договорились объяснять тему максимально просто, поэтому для простоты скажем, что пример белого шума в природе – характерный звук водопада.
Белый шум напоминает звук телевизора, не настроенного на прием ТВ-каналов.
Розовый и красный шумы — это тоже сочетание звуков с определенными характеристиками. Пример розового шума — звук пролетающего вертолета. А в системах маскировки звука (шумовых завесах) используются специально «сконструированные» шумы. Их применяют, чтобы выровнять акустический фон в офисах и повысить конфиденциальность разговоров — сделать неразборчивыми слова, произнесенные на отдалении от невольного слушателя, и не предназначенные для его ушей.
Все «цветные» шумы называют широкополосными: их энергия распределена по всему диапазону звуковых частот. Иначе говоря, это непрерывные беспорядочные шумы, которые звучат одновременно на низких, средних и высоких частотах. Цвет шума определяется тем, в каких пропорциях энергия шума распределяется по диапазону его частот. На цветные шумы похожи звуки, которые мы встречаем в жизни: звук ливня, водопада или ветра, гудение вентиляционной системы или шум большого стадиона. На белый шум больше всего похож звук, который издает телевизор, когда не настроен на прием ТВ-сигнала, и на его экране мы видим «снег».
В чем разница между широкополосными шумами
Белый и розовый шумы, а также маскирующий звук системы саундмаскинга (шумовой завесы, системы маскировки звука) — широкополосные. Но, по большому счету, это единственное, что объединяет эти шумы. Причем если розовый шум в каком-то смысле можно считать производным от белого шума, то звук системы саундмаскинга (иногда его называют «маскер») им не является. Неправильно также считать его сочетанием белого и розового шумов. Как мы уже говорили, это специально «сконструированный» шум. Причем созданный с единственной целью: эффективно маскировать нежелательные шумы (звук посторонних разговоров, громкие и резкие звуки в тихом помещении), которые отвлекают офисных сотрудников от работы.
К числу самых сильных отвлекающих шумов, особенно в шумных помещениях с открытой планировкой («опенспейс»), относят в первую очередь разговоры сотрудников, которые ведутся на отдалении от невольных слушателей — коллег, сидящих за соседними столами. Человек непроизвольно отвлекается на обрывки фраз, произнесенных сослуживцами, причем делает это неосознанно. В зависимости от задачи, которую выполняет работник, ему требуется от одной до десяти минут, чтобы вновь сосредоточиться.
Шумный офис — не лучшее место для работы. Но и слишком тихий офис — тоже плохо: в полной тишине сотрудникам может отвлечь даже звуку упавшего на пол карандаша. Задача системы маскировки звука — выровнять акустический фон в помещении, а также сделать посторонние разговоры неразборчивыми. И делает она это с помощью специально рассчитанного инженерами шума.
Бороться с шумом с помощью другого шума? Казалось бы, странная идея. Но именно так и работает хорошая система маскировки звука.
Почему нужен специально рассчитанный шум маскера? Разве белого или розового шума недостаточно, чтобы замаскировать нежелательные шумы? Действительно, в какой-то мере резкие звуки можно нивелировать с помощью любого широкополосного шума. Именно поэтому считается, что белый шум помогает быстрее уснуть. Но в отличие от других широкополосных шумов, маскер шумовой завесы рассчитан устранять именно распространенные офисные шумы, особенно в офисах «опенспейс». Разница будет особенно очевидна, если ради эксперимента установить в офисе бытовой генератор белого шума. Тогда вы сразу поймете, что белый шум в офисе абсолютно бесполезен.
Чем белый шум отличается от розового
Если попросить инженера-акустика пояснить разницу между белым и розовым шумом, его рассказ будет коротким, но малопонятным: белый шум имеет примерно одинаковую спектральную плотность мощности на всех частотах, а розовый — примерно одинаковую спектральную плотность мощности во всех октавных полосах частот. Если попытаться объяснить проще, то и белый и розовый шумы включают звуки одновременно всех частот, различимых человеческим ухом, т.е. от 20 Гц до 20 000 Гц. Но энергия этих звуков распределяется по частотам совершенно по-разному.
Розовый шум напоминает шум дождя, не правда ли?
Спектр белого шума
Главная причина путаницы при сравнении белого и розового шума — их спектры. Путаница в основном связана с тем, что графические представления этих шумов полностью различается в зависимости от типа используемого спектроанализатора.
Например, спектрограмма белого шума, представленная в узких полосах частот, выглядит, как на рисунке ниже. Видите, насколько равномерен спектр? Он таков, что энергия шума во всех полосах частот (на графике частоты возрастают слева направо по оси Х) распределена примерно равномерно.
Спектр белого шума в узких полосах частот
Рис. 1. Спектр белого шума, показанный на графике в узких полосах частот. Энергия шума распределена примерно одинаково по всем полосам. Похоже на стену, не правда ли? Поэтому иногда белый шум сравнивают с непроницаемой стеной.
А теперь посмотрите, как выглядит тот же самый спектр белого шума не в узких, а в третьоктавных полосах частот (рис. 2). Совершенно другая картина по сравнению с рисунком 1. Спектрограмма уже не плоская: энергия растет с повышением частоты.
Спектр белого шума в третьоктавных полосах частот
Рис. 2 Белый шум. Его энергия равномерно распределена по всем частотам, но чем дальше вправо по оси частот мы движемся, тем более высокие частоты группируются в октавные полосы, и тем интенсивнее шум.
Если проанализировать белый шум в третьоктавных полосах, то чем выше частоты, тем мощнее шум. Но ведь мы уже говорили, что на каждой отдельной частоте (100 Гц, 200 Гц, 1000 Гц, 5000 Гц и т.п.) энергия шума должна быть примерно одинаковой. Почему же мы видим ее повышение? Действительно, компоненты белого шума имеют одинаковую энергию на каждой отдельной частоте, но не в каждой октавной полосе. И чтобы понять, почему так происходит, давайте разберемся, что такое октавы.
Что такое октавы?
Упрощенно говоря, октавы — это группы частот, которые помогают количественно оценить то, как мы воспринимаем разные частоты на слух. Каждая октава представляет общий уровень энергии шума в определенном диапазоне частот. Важный факт: чем выше частоты, тем более широкий их диапазон собирается в октавные полосы. Это поясняется тем, что человеческий слух легче улавливает разницу между отдельными низкими частотами, но с повышением частот мы все хуже распознаем каждую частоту по отдельности, даже если они разнесены достаточно далеко друг от друга.
Поэтому в низкочастотных диапазонах октавные полосы более узкие, чем в высокочастотных. В таблице ниже указаны октавные полосы и входящие в них частоты. Цифры говорят сами за себя: в октавную полосу 8000 Гц объединено намного больше частот, чем в октавную полосу 63 Гц.
Октавные полосы и входящие в них частоты
|
ЦЕНТРАЛЬНАЯ ЧАСТОТА ОКТАВНОГО ДИАПАЗОНА (ГЦ) |
НИЖНЯЯ ЧАСТОТА |
ВЕРХНЯЯ ЧАСТОТА |
ОКТАВНАЯ ПОЛОСА ЧАСТОТ (КОЛИЧЕСТВО ЧАСТОТ) |
|
63 |
44 |
88 |
44 |
|
125 |
88 |
177 |
89 |
|
250 |
177 |
355 |
178 |
|
500 |
355 |
710 |
355 |
|
1000 |
710 |
1420 |
710 |
|
2000 |
1420 |
2840 |
1420 |
|
4000 |
2840 |
5680 |
2840 |
|
8000 |
5680 |
11360 |
5680 |
Говоря математическим языком, октава — это интервал, в котором соотношение частот звука составляет один к двум. Например, как показано в таблице выше, между частотами 88 Гц и 177 Гц расположена одна октавная полоса, а именно полоса 125 Гц. Между частотами 177 Гц and 355 Гц — октавная полоса 250 Гц. Эта полоса содержит 178 отдельных частот, а полоса 125 Гц — только 89. Т.е. октавная полоса 250 Гц шире, чем полоса 125 Гц.
Октавы – логарифмическая мера частот
Давайте вернемся к рис. 2. Почему октавные полосы указаны на нем как имеющие одинаковую ширину, хотя выше мы объясняли, что это не так? В действительности ширина полос разная, но для упрощения их часто изображают на спектрограмме равными по ширине, как на рис. 2. Мы называем этот формат «отображением октавных полос в логарифмическом масштабе».
В этом случае, что же такое «третьоктавные полосы»? Это одна рассматриваемая полоса, разделенная на три равные части. С помощью такого деления инженер-акустик может точнее анализировать составляющие шума.
Чем выше частота, тем более громким шум воспринимается на слух
Еще один интересный факт: на слух белый шум воспринимается более резким, чем можно было бы ожидать, увидев на графике относительно ровный частотный спектр. Причина в том, что система слуха человека воспринимает звук в логарифмическом масштабе — т.е. октавами, а не в линейном масштабе (т.е. узкими полосами). Иными словами, нам кажется, что высокочастотные звуки громче, чем низкочастотные той же мощности. Поэтому с точки зрения восприятия белый шум звучит громче и имеет шипящие нотки в высокочастотных октавных полосах. Если говорить точнее, мощность белого шума возрастает на 3 дБ на каждую октаву вверх по частотному диапазону.
Как создать розовый шум
Что будет, если взять спектр белого шума, отображенный в логарифмическом масштабе (см. рис. 2), и выровнять растущую кривую мощности? Вы получите октавные полосы, мощность шума в которых будет одинаковой. Помните определение розового шума? Это шум, компоненты которого имеют одинаковую спектральную мощность в каждой октаве. Иными словами, мы превратим белый шум в розовый.
Розовый шум в третьоктавных диапазонах
Рис. 3. Если говорить очень упрощенно, розовый шум — это белый шум со «срезанными» высокими частотами. Вот почему его воспринимают как более мягкий и приятный по сравнению с белым шумом. Действительно, шум телевизора, не принимающего ТВ-сигнал (белый шум) менее приятен большинству людей, чем мягкий шум небольшого дождя (розовый шум).
Теперь вспомним, что на рис. 1 спектр белого шума выглядел плоским в линейном масштабе. Исходя из полученных знаний о розовом шуме и о том, как он отличается по распределению мощности, давайте ответим на вопрос, как выглядит его спектр в узких полосах частот, а не в третьоктавных.
Если спектральная мощность белого шума равномерна на всех частотах, а его спектр в октавных полосах демонстрирует повышение мощности (восходящая прямая на графике), то мощность розового шума равномерно распределяется по октавам. Это значит, что на узкополосной спектрограмме кривая мощности будет падать, (см. рис. 4)
Спектр розового шума в узких полосах частот
Рис 4. Энергия белого шум равномерно распределяется по частотам, а энергия розового уменьшается по мере повышения частот.
Белый шум в сравнении со звуком шумовой завесы – маскером
Мы, инженеры Soft dB, занимаемся разработкой систем маскировки звука, которые повышают конфиденциальность разговоров в офисе и помогают сотрудникам сосредоточиться, не отвлекаясь на посторонние шумы. Нас часто спрашивают: «Вы ведь продаете генератор белого (или розового) шума?». Наш ответ – нет. Достаточно просто посмотреть на спектрограмму маскирующего звука шумовой завесы в третьоктавных полосах (в логарифмическом масштабе), и сравнить этот график со спектрограммой белого шума. Вы сразу поймете, что они различаются.
Если взглянуть на спектрограмму, можно заметить что звук шумовой завесы — полная противоположность белому шуму. По мере повышения частоты мощность белого шума растет на 3 дБ на каждую октаву, а маскирующий звук шумовой завесы, наоборот, теряет в мощности 3 дБ на октаву.
Спектр маскирующего звука шумовой завесы в третьоктавных полосах частот
Рис 5. Идеальный спектр шума саундмаскинга в третьоктавных полосах частот, рассчитанный Национальным исследовательским советом Канады (NRC). В отличие от белого шума типичный звук маскера теряет мощность по мере повышения частоты. Меньшая мощность на высоких частотах делает звук системы саундмаскинга намного более приятным на слух.
Какая система маскировки звука лучше
Цель любого производителя систем маскировки звука – выровнять акустический фон в офисе, повысить конфиденциальность бесед и устранить отвлекающий фактор в виде посторонних разговоров сотрудников. По большому счету, все поставщики борются за единственный «магический» параметр: спектр маскирующего шума. И все заявляют, что по этому параметру они лучшие на рынке. Мы, инженеры Soft dB, не исключение.
Но рабочие настройки шумовой завесы выполняет не производитель, а системный интегратор или инсталлятор оборудования, который устанавливает шумовую завесу у конечного заказчика. И здесь вступает в игру не только спектр, но и гибкость настроек системы под нужды конкретного клиента.
Система маскировки звука SoftdB
Как инженеры-акустики мы утверждаем, что спектр шума системы маскировки звука Soft dB точнее, чем у конкурирующих систем, соответствует идеальной спектрограмме, рассчитанной Национальным исследовательским советом Канады (NRC). Но еще одно неоспоримое преимущество нашей системы в том, что она в реальном времени адаптирует спектр к постоянно меняющейся шумовой обстановке в офисе и даже в каждой его зоне по отдельности. Причем делает это очень точно.
Звук шумовой завесы Soft dB не тревожит сотрудников, получается мягким, приятным и едва различимым на слух. А главное — он эффективно маскирует разговоры, которые ведутся на удалении от невольного слушателя. И все это благодаря тонкой подстройке спектра маскирующего звука в реальном времени, с учетом постоянно меняющейся шумовой обстановки. На то, чтобы добиться максимальной эффективности, у нас ушли годы научных исследований и полевых испытаний. Их итог – несколько патентов и уникальная по своей действенности система маскировки звука.
Шумовая завеса – это целая система, а не одна машина
С хорошей системой маскировки звука сотрудники сразу отметят, что в офисе стало тише и спокойнее. Более того, в отличие от генераторов белого и розового шума, звук маскера практически не слышен, и сложно понять, откуда он доносится. Отчасти это происходит потому, что шумовая завеса – это целый комплекс оборудования, а не одиночный генератор белого шума, стоящий, например, у прикроватного столика в отеле.
Генератор белого шума бесполезен в офисах
Система маскировки звука включает множество специализированных динамиков разной формы и размера для установки небольшими группами, которые охватывают определенные зоны офиса. Неважно, сколько выделено таких зон: управление отдельными группами динамиков (большинство из которых спрятаны за фальш-потолком, а часть — открыто), выполняется через единый пользовательский интерфейс. И это очень удобно. Представьте, сколько времени вы потратили бы, перемещаясь по офису и настраивая параметры каждого динамика. Поэтому одно из главных преимуществ маскировки звука Soft dB — это сетевое управление всей системой.
Как работает шумовая завеса Soft dВ
А другое преимущество, как мы уже сказали, — это автоматическая подстройка (адаптация) звука маскера под меняющуюся шумовую обстановку в офисе. С помощью акустических сенсоров система определяет уровень шумового фона и меняет параметры маскера, чтобы эффективность маскировки звука всегда была самой высокой.
Плюс, динамики саундмаскинга Soft dB можно использовать как систему голосового оповещения в офисе.
Можно ли использовать белый и розовый шум вместо звукомаскировки?
Как мы уже говорили, в системах маскировки звука используется не белый и не розовый, а специально подобранный широкополосный шум. Означает ли это, что генераторы белого и розового шума совершенно бесполезны? Не совсем так. Согласно нескольким исследованиям (например, работа Pink noise: Effect on complexity synchronization of brain activity and sleep consolidation, опубликованная 2012 году в журнале the Journal of Theoretical Biology), белый и розовый шумы помогают уснуть, поскольку до некоторой степени маскируют резкие звуки вроде шума автомобилей, лая собак, звука сирен и т.п.
Более того, в присутствии белого и розового шумов качество сна повышалось даже по сравнению с условиями, когда испытуемых помещали в абсолютно тихое помещение. По мнению ученых, это происходит потому, что наш мозг считает абсолютную тишину чем-то неестественным, нетипичным для нашей среды обитания. Поэтому в полной тишине многие люди ощущают тревогу, хуже засыпают и более чутко спят.
Бытовые генераторы белого и розового шума часто используют дома у прикроватных столиков и в гостиницах. Пожалуй, этим их применение ограничивается. Для офисов с их особой акустической обстановкой такие устройства не подходят.
Выводы
Системы маскировки звука, как и генераторы белого и розового шумов, используют в своей работе широкополосные шумы. Но как мы уже выяснили, шум шуму рознь. Производители шумовых завес стараются рассчитать звук маскера так, чтобы он эффективно скрывал именно офисные шумы. Самые эффективные шумовые завесы (например, Soft dB) делают свои системы адаптивными – способными в реальном времени отслеживать акустическую обстановку и менять под нее шум маскера. С такой системой все офисные сотрудники почувствуют, что в офисе стало намного комфортнее работать.
См. также:
Если вы хотите получить дополнительную информацию о системах маскировки звука, узнать стоимость проекта для вашего офиса или ознакомиться с работой системы вживую, заполните форму и наши специалисты свяжуться с вами:
Подписка на новости
Видение звука: что такое спектрограмма?
Грег Грин, каталогизатор аудиопроектов за открытие нашего звукового наследия, пишет:
В эту цифровую эпоху большинство из нас знакомо с формами звуковых волн, «волнистыми» изображениями, которые представляют динамический ход конкретной звукозаписи. На самом деле осциллограммы представляют собой тип графика со временем по оси X и амплитудой (или громкостью) по оси Y.
Рисунок 1: форма волны представляет запись звука, показывая амплитуду во времени
Сигналыочень полезны для передачи основной информации о записи. E.г. где громкие биты, где тихие биты и насколько динамична запись. Если вы слушали интервью, осциллограмма может четко показать вам, где кто-то говорит. К сожалению, формы волны не могут многое сказать нам о высоте тона, частоте или гармоническом содержании записи. Для этого мы можем использовать другое визуальное представление звука… поприветствуем спектрограмму!
Как читать спектрограмму
Спектрограммы сохраняют время по оси X, но помещают частоту по оси Y.Амплитуда также представлена как своего рода тепловая карта или шкала насыщенности цвета. Первоначально спектрограммы создавались в виде черно-белых диаграмм на бумаге с помощью устройства, называемого звуковым спектрографом, тогда как в настоящее время они создаются с помощью программного обеспечения и могут иметь любой диапазон цветов, который только можно вообразить!
Рисунок 2: осциллограмма и спектрограмма одной и той же записи. Колеблющееся низкочастотное жужжание преобладает над формой волны, только спектрограмма показывает, где птица звонит
Спектрограммы отображают звук аналогично партитуре, только отображая частоту, а не музыкальные ноты.Такое распределение частотной энергии во времени позволяет нам четко различать каждый из звуковых элементов в записи и их гармоническую структуру. Это особенно полезно в акустических исследованиях при анализе звуков, например пения птиц и музыкальных инструментов. Так что эти графики не только выглядят действительно круто, но и могут многое рассказать нам о звуке, даже не слушая.
Рисунок 3: спектрограмма, показывающая гармонически насыщенные крики лебедей-кликунов
Крики лебедя-кликуна записаны Джоном Корбеттом (полка BL WS1734 C5)
В приведенном выше примере мы можем видеть крики лебедя-кликуна, представленные на спектрограмме.Основная частота вызовов составляет около 750 Гц, что является частотой с наибольшей энергией (обычно самой низкой частотой звука) и придает звуку его воспринимаемую высоту. Выше находятся гармоники — дополнительные, более тихие частоты, которые придают звуку его «цвет» и создают своего рода звуковую подпись — лебедь-кликун, поющий идеальную ноту G, будет иметь гармоническую структуру, совершенно отличную от гармонической структуры фортепиано, играющего то же Примечание. Эта информация может быть использована для анализа пения и криков птиц в разных местах или для понимания словаря вида.
Творческое использование спектрограмм
Очевидно, спектрограммы могут многое рассказать нам об акустических элементах звука, но они используются не только для научных исследований. Редактирование звука чаще всего выполняется с осциллограммами, так как легче вырезать или обрабатывать выбранный временной диапазон. Однако когда программное обеспечение для редактирования использует спектрограммы, это открывает совершенно новые возможности! С помощью этого спектрального редактирования мы можем изучать микроскопические детали звука и применять процессы к очень конкретным временным и частотным диапазонам.Например, навязчивые шаги или автомобильная сигнализация могут быть идентифицированы и удалены из записи, как звук «фотошопа»!
Рисунок 4: запись пения малиновки была испорчена лаем собаки и некоторым низким уровнем шума — спектрограмма выявляет нежелательные шумы и позволяет записывающему устройству их удалить.
Спектральный ремонт ДО
Спектральный ремонт ПОСЛЕ
Музыканты также могут использовать спектральное редактирование для создания и создания звуков, которые невозможно было бы сделать другим способом.Узоры и формы можно «нарисовать» в спектрограммах и воспроизвести как частотный контент. В некоторых случаях подробные графические изображения могут быть скрыты внутри спектрограмм. Aphex Twin использовал эту технику, чтобы скрыть изображение лица во втором треке своего EP «Windowlicker» (1999).
Еще несколько примеров изображений, скрытых в спектральном содержании популярных песен, можно найти здесь: https://twistedsifter.com/2013/01/hidden-images-embedded-into-songs-spectrographs/
Итак, теперь вы знаете, что такое спектрограммы, как их читать, а также некоторые из их многочисленных научных, творческих и причудливых применений.Следите за нашими твитами #SpectrogramSunday @BLSoundHeritage, начиная с этих выходных!
Что такое спектрограмма? | Тихоокеанская северо-западная сейсмическая сеть
Что такое спектрограмма?
Спектрограмма — это визуальный способ представления силы или «громкости» сигнала с течением времени на различных частотах, присутствующих в конкретной форме волны. Можно не только увидеть, больше или меньше энергии, например, при 2 Гц против 10 Гц, но также можно увидеть, как уровни энергии меняются с течением времени.В других науках спектрограммы обычно используются для отображения частот звуковых волн, производимых людьми, машинами, животными, китами, струями и т. Д., Записанными с помощью микрофонов. В сейсмическом мире спектрограммы все чаще используются для изучения частотного состава непрерывных сигналов, записываемых отдельными или группами сейсмометров, чтобы помочь различать и характеризовать различные типы землетрясений или других вибраций в земле.
Как вы читаете спектрограмму?
Спектрограммы — это в основном двухмерные графики, третье измерение которых представлено цветами.Время идет слева (самый старый) направо (самый молодой) по горизонтальной оси. Каждая из наших подгрупп спектрограмм вулканов и землетрясений показывает данные за 10 минут с отметками на горизонтальной оси, соответствующими 1-минутным интервалам. Вертикальная ось представляет частоту, которую также можно рассматривать как высоту тона или тон, с самыми низкими частотами внизу и самыми высокими частотами вверху. Амплитуда (или энергия, или «громкость») конкретной частоты в конкретный момент времени представлена третьим измерением, цветом, с темно-синим цветом, соответствующим низким амплитудам, и более яркими цветами, проходящими вверх через красный, соответствующими все более сильным (или более громким) амплитудам.
Над спектрограммой находится необработанная сейсмограмма, построенная с использованием той же горизонтальной оси времени, что и спектрограмма (включая те же отметки), с вертикальной осью, представляющей амплитуду волны. Этот график аналогичен графикам (или сейсмограммам) в стиле веб-заказа, к которым можно получить доступ через другие части нашего веб-сайта. В совокупности комбинация спектрограмма-сейсмограмма является очень мощным инструментом визуализации, поскольку она позволяет вам видеть необработанные формы волны для отдельных событий, а также силу или «громкость» на различных частотах.Частотный состав события может быть очень важным при определении того, что произвело сигнал (см. Примеры).
Почему на каждой странице спектрограммы отображается несколько разных спектрограмм?
Наши веб-страницы спектрограмм показывают группы спектрограмм с нескольких станций, обычно от 5 до 7, со станциями, упорядоченными от ближайшего (верхняя часть экрана мультиспектрограммы) к самому дальнему (внизу) относительно точки интереса, такой как вулкан. Слабые сейсмические источники, которые возникают на поверхности или над ней (порывы ветра, шаги животных, вертолеты, гром, автомобильное движение и т. Д.)) обычно обнаруживаются только на одной станции, тогда как более сильные источники, возникающие на поверхности земли или под ней (землетрясения, взрывы), обычно обнаруживаются на нескольких станциях. Отображение спектрограмм для нескольких станций на одном и том же графике позволяет ученым быстро определить, генерируется ли конкретный сигнал слабым или сильным источником и находится на поверхности или внутри земли, и, следовательно, различать «шум» (сигналы от источников, в которых мы обычно не представляют интереса) и более значимый с геофизической точки зрения сигнал.Конечно, наиболее интересными для нас источниками являются те, которые возникают на Земле, такие как землетрясения, извержения вулканов и камнепады / лавины.
Интерпретация спектрограмм
Есть три основных категории землетрясений, которые вы можете увидеть на спектрограммах. Они делятся в зависимости от расстояния от сейсмической сети и традиционно называются местными (в пределах Тихоокеанского Северо-Запада), региональными (вблизи Тихоокеанского Северо-Запада, например, из Британской Колумбии, Калифорнии или от берега) и телесейсмами (более 1000 км или 600 миль от Тихоокеанский Северо-Запад).Конечно, мы записываем много типов «шумовых» сигналов; здесь приведены несколько примеров.
Вернуться на главную страницу спектрограммы.
Понимание спектрограмм
Спектрограмма — один из самых ярких и информативных звуковых инструментов, имеющихся в нашем распоряжении. В этой статье мы расскажем, как работает спектрограмма, как использовать ее для изучения аудиофайла и как точно настроить тип и количество информации, представленной в спектрограмме RX.
Что такое спектрограмма?
Спектрограмма — это подробное представление звука, способное отображать время, частоту и амплитуду на одном графике. Спектрограмма может визуально выявить широкополосный, электрический или прерывистый шум в звуке и может позволить вам легко локализовать эти проблемы со звуком визуально. Из-за высокого уровня детализации спектрограмма особенно полезна при постобработке, поэтому неудивительно, что вы найдете ее в таких инструментах, как RX 8 и Insight 2.
Вид спектрограммы в RX 8
Спектрограмма и форма волны
В звуковом программном обеспечении мы привыкли видеть форму волны, которая отображает изменения амплитуды сигнала с течением времени. Однако спектрограмма отображает изменения частот сигнала с течением времени. Затем амплитуда отображается в третьем измерении с переменной яркостью или цветом.
Давайте посмотрим на аудиофайл в традиционном виде осциллограммы и спектрограммы.Во-первых, вот синусоидальная волна, движущаяся вверх по высоте от 60 Гц до 12 кГц, как видно на традиционной форме волны:
Синусоидальная волна, показанная как традиционная форма волны
Вы заметите, что форма волны показывает амплитуду во времени, но мы не можем реально увидеть, что происходит на отдельных частотах. Мы можем видеть, что синусоидальная волна находится на постоянном уровне на протяжении всего файла, но мы не можем многое сказать о том, как высота тона или частота изменяется с течением времени.
Вот тот же аудиофайл с использованием спектрограммы.
В виде спектрограммы вертикальная ось отображает частоту в герцах, горизонтальная ось представляет время (точно так же, как отображение формы сигнала), а амплитуда представлена яркостью.
Черный фон — это тишина, а ярко-оранжевая кривая — это синусоидальная волна, движущаяся вверх по высоте. Это позволяет нам видеть диапазон частот (самые низкие внизу экрана, самые высокие вверху) и насколько громкими бывают события на разных частотах.Громкие события будут казаться яркими, а тихие — темными.
Теперь давайте посмотрим на более сложный пример звука: человеческий голос.
Вот короткая произносимая фраза, отображаемая на экране формы сигнала. Здесь мы видим амплитуду произнесенных слов во времени.
Диалог в традиционной форме сигнала
Если мы переключимся в представление спектрограммы, мы увидим много вещей, которые не видим в представлении формы волны.
Диалог в виде спектрограммы
Вот почему подробное отображение спектрограммы так важно при редактировании звука: оно помогает четко отображать проблемы, которые вы, возможно, захотите исправить.
Ключ к успешному восстановлению звука заключается в вашей способности правильно анализировать ситуацию — подобно тому, как врач распознает симптомы, указывающие на определенное заболевание.
Постоянно тренируя ухо распознавать шумы и звуковые события, которые необходимо исправить, может потребоваться вся жизнь.К счастью, как объяснялось ранее, технология спектрограмм упрощает эту задачу, представляя эти звуковые события визуально.
Спектрограмма / форма волны отображается в RX
RX имеет усовершенствованный дисплей спектрограммы, который способен отображать большее разрешение по времени и частоте, чем другие спектрограммы, что позволяет вам видеть беспрецедентный уровень детализации при работе со звуком.
Обзор формы волны всего аудиофайла будет отображаться над основным дисплеем спектрограммы / формы волны в обзоре формы волны.Обзор формы волны всегда будет отображать весь аудиофайл, а также будут отображать любые выборы, сделанные на основном дисплее.
Вы также можете просмотреть традиционную форму волны или их сочетание, переместив ползунок «Непрозрачность формы волны / спектрограммы» влево под спектрограммой.
Ползунок непрозрачности формы волны / спектрограммы
Цель любого хорошего инструмента визуализации для ремонта и восстановления звука — предоставить вам больше информации о звуковой проблеме.Это не только помогает обосновать ваши решения по редактированию, но, в случае отображения спектрограммы, может предоставить новые захватывающие способы редактирования звука, особенно при использовании в тандеме с отображением формы волны.
Как настроить дисплей
Не все спектрограммы одинаковы. Для вычисления этого визуального отображения используется алгоритм, известный как «быстрое преобразование Фурье» или сокращенно БПФ. Многие плагины с отображением спектрограммы позволяют настраивать размер БПФ, но что это означает для ремонта и восстановления звука? Изменение размера БПФ изменит способ вычисления спектрограммы алгоритмом, в результате чего она будет выглядеть по-другому.В зависимости от типа звука, с которым вы работаете и визуализируете, изменение размера БПФ может помочь.
Как правило, более высокие размеры БПФ дают более подробную информацию о частотах, называемую частотным разрешением, в то время как меньшие размеры БПФ дают более подробную информацию во времени, называемую временным разрешением.
Если вы пытаетесь определить взрывной сигнал, шум от микрофона или другую нечеткую низкочастотную информацию, вам поможет более высокий размер БПФ в настройках спектрограммы. Если вы пытаетесь идентифицировать высокочастотное событие или работаете с переходным сигналом (например, перкуссией или лупом ударных), выберите меньший размер FFT.
Использование спектрограммы для решения проблем со звуком
Существует ряд различных проблем со звуком, которые могут помочь вам исправить инструменты RX. Определение того, какая у вас проблема, может помочь определить наиболее подходящий инструмент и метод для ее решения.
Мы собрали советы, которые помогут вам определить семь распространенных типов проблем со звуком в спектрограмме, а также модули в RX для их быстрого и эффективного устранения. Мы рассмотрим следующие проблемы со звуком:
- гул
- Базз
- Шипение и другие широкополосные шумы
- Щелчки, хлопки и другие короткие импульсные шумы
- Обрезка или искажение
- Прерывистые шумы
- Разрывы и выпадения
Hum
Жужжание обычно является результатом электрического шума где-то в записанной сигнальной цепи.Обычно он слышен как низкочастотный тон с частотой 50 или 60 Гц.
Гул на спектрограмме
Вы увидите гул, увеличив низкие частоты. Он будет выглядеть как серия горизонтальных линий, обычно с яркой линией на 50 или 60 Гц и несколькими более светлыми линиями на гармониках.
Для удаления шума используйте модуль RX De-hum. Лучше всего это работает, когда частоты гудения не перекрываются с какими-либо полезными переходными сигналами.
Базз
В некоторых случаях электрический шум распространяется до более высоких частот и проявляется в виде жужжания. Подобные звуки также могут исходить от люминесцентных ламп, двигателей и некоторых встроенных микрофонов.
Жужжание на спектрограмме
Вы увидите гудение на высоких частотах, где оно будет отображаться в виде тонкой горизонтальной линии.
Чтобы удалить гудение на частотах выше 400 Гц, используйте инструмент Spectral De-noise.Для низкочастотного гудения, похожего на гудение, более эффективен инструмент De-hum.
Шипение и другие широкополосные шумы
В отличие от шума и гудения, широкополосный шум не концентрируется на определенных частотах и может быть обнаружен по всему частотному спектру. Шипение ленты и шум от вентиляторов и систем отопления, вентиляции и кондиционирования воздуха — отличные тому примеры.
Шипение показано на спектрограмме
На дисплее спектрограммы широкополосный шум обычно появляется в виде пятен, окружающих программный материал, как показано в примере.
Используйте инструмент Spectral De-noise для удаления этих типов широкополосного шума.
Щелчки, хлопки и другие короткие импульсные шумы
Щелчки и треск — обычное явление для записей, сделанных с винила, шеллака и других рифленых носителей. Они также могут быть вызваны цифровыми ошибками, в том числе записью в DAW со слишком низкой настройкой буфера или плохим редактированием звука, при котором пропущено пересечение нуля. В эту категорию попадают даже звуки изо рта, такие как щелчок языком или шлепок губами.
Щелчки и треск на спектрограмме
Эти короткие импульсивные шумы появляются на спектрограмме в виде вертикальных линий.Чем громче щелчок или хлопок, тем ярче будет линия. В этом примере показаны щелчки и треск, появляющиеся в аудиозаписи, перенесенной с винила.
Для обычных щелчков и щелчков используйте модуль De-click, чтобы распознать, изолировать, уменьшить и удалить их. Если вы сталкиваетесь с щелчком рта говорящего, вам подойдет модуль Mouth De-click.
Обрезка или искажение
Цифровое клиппирование — очень распространенная проблема в аудиопроизводстве. Это может произойти, когда сигнал слишком громкий для записи аналого-цифровым преобразователем, микшерным пультом, полевым рекордером или каким-либо другим каскадом усиления в сигнальной цепи.Это может вызвать искажение и потерю аудиоинформации на пиках сигнала.
Ограниченная форма волны
Чтобы идентифицировать обрезанный звук, вам нужно работать с отображением формы волны, а не со спектрограммой. Ограничение отображается в виде «квадратичных» участков сигнала.
Увеличьте масштаб сигнала, чтобы увидеть, где волна была усечена из-за ограничения.
Усеченные пики ограниченного сигнала
Обратите внимание, что иногда звук, ограниченный кирпичной стеной, также выглядит «квадратично», но это не обязательно означает, что он будет звучать так же сильно искаженным, как обрезанные формы волны, которые были обрезаны.Вы можете увеличить масштаб, чтобы увидеть, действительно ли обрезаны вершины отдельных сигналов.
Чтобы исправить обрезку, используйте инструмент De-clip, который может интеллектуально перерисовать форму волны там, где она могла бы быть естественной, если бы сигнал не был обрезан.
Прерывистые шумы
Прерывистые шумы отличаются от шипения и гула — они могут появляться нечасто и быть непостоянными по высоте или продолжительности. Общие примеры включают кашель, чихание, шаги, автомобильные гудки, звонки сотовых телефонов, птиц и сирены.
Эти шумы могут проявляться по-разному. Вот пара примеров:
Звонок на спектрограмме
Кашель на спектрограмме
Используйте инструмент Spectral Repair, чтобы изолировать эти прерывистые звуки, проанализировать звук вокруг них и ослабить или заменить их.
Пробелы и выпадения
Иногда в записи могут быть короткие участки с отсутствующим или поврежденным звуком.Это называется разрывом или выпадением.
Выпадение показано на спектрограмме
Обычно они очень очевидны как для глаза, так и для уха и появляются в виде пробела на дисплее спектрограммы.
Используйте инструменты Spectral Repair и Ambience Match, чтобы заменить отсутствующие звуковые элементы и создать согласованную звуковую дорожку.
Заключение
Спектрограмма была основным продуктом RX с первой версии, и нетрудно понять, почему.Предлагая хирургически точную визуализацию звука, над которым вы работаете, таким образом, чтобы вы могли лучше понять звук, теперь вы можете определять области, требующие коррекции, с помощью нескольких органов чувств. А при использовании в сочетании с ведущими в отрасли модулями восстановления звука в RX, он может помочь вам быстро выполнить следующий проект постпродакшена. Удачного редактирования!
Анализатор спектра| Academo.org — Бесплатное интерактивное обучение.
Загрузите свой
Анализатор спектра, представленный выше, дает нам график всех частот, которые присутствуют в звукозаписи в данный момент времени.Полученный график известен как спектрограмма. Более темные области — это те, где частоты имеют очень низкую интенсивность, а оранжевый и желтый области представляют собой частоты с высокой интенсивностью звука. Вы можете переключаться между линейной или логарифмической шкалой частоты, установив или сняв флажок логарифмической частоты.
Во многом эта демонстрация похожа на демонстрацию виртуального осциллографа, но есть одно важное и очень важное отличие. В демонстрации осциллографа график показывает смещение звукового сигнала в зависимости от времени, которое называется сигналом во временной области. Эта демонстрация показывает сигнал, представленный другим способом: в частотной области. Частотный спектр генерируется путем применения преобразования Фурье к сигналу во временной области.
Приведенная выше демонстрация позволяет вам выбрать ряд предустановленных аудиофайлов, таких как щелчки китов / дельфинов, полицейские сирены, песни птиц, свист, музыкальные инструменты и даже старый коммутируемый модем 56k. Каждый из них имеет уникальные и интересные закономерности, которые вы можете наблюдать. Кроме того, вы можете загружать свои собственные аудиофайлы.Чтобы просмотреть спектрограмму, выберите свой звуковой вход, затем нажмите кнопку воспроизведения, и на экране появится график, перемещающийся справа налево. Вы можете остановить движение, нажав кнопку паузы на аудиоплеере.
Запись скрипки, в частности, ясно демонстрирует богатое гармоническое содержание для каждой сыгранной ноты (это отображается на спектрограмме в виде нескольких более высоких частот, генерируемых для каждой основной частоты). Это контрастирует с записью со свистом, которая имеет очень сильный фундаментальный компонент, и имеет только одну дополнительную гармонику, что указывает на то, что человеческий свист очень близок к чистой синусоиде.
Вот несколько ссылок на сайты, на которых есть интересные звуковые файлы, с помощью которых вы можете создавать свои собственные спектрограммы.
Обратите внимание: нам известно о проблеме с браузером Safari, из-за которой спектрограмма не отображается. Кроме того, Internet Explorer не еще есть функции для поддержки демонстрации. Поэтому для достижения наилучших результатов используйте Chrome или Firefox. Спасибо.
Кредиты
Пожалуйста, включите JavaScript, чтобы просматривать комментарии от Disqus.Идентификация звуков в спектрограммах
Идентификация звуков в спектрограммахРаспознавание звуков в спектрограммах
Давайте посмотрим, как различные звуки появляются на спектрограмме.
Гласные
Гласные обычно имеют очень четко определенные формантные полосы, например:
В дифтонгах вы можете видеть, как форманты меняют частоту по мере того, как тело языка движется через рот:
Вы не всегда можете точно сказать , на какой формат вы смотрите — F1, F2, F3 и т. Д.- если вы уже не представляете, где их ожидать. Но существование формант обычно достаточно очевидно, чтобы вы, по крайней мере, могли быть уверены, что смотрите на гласную.
(Особенно часто возникают трудности с определением формант. В [ɑ], а иногда и в других гласных заднего ряда, F1 и F2 часто расположены так близко друг к другу, что появляются как одна широкая формантная группа. часто объединяются в одну широкую полосу.)
Fricatives
Fricatives — это просто.Турбулентный воздушный поток фрикативов создает хаотическую смесь случайных частот, каждая из которых длится очень короткое время. Результат звучит очень похоже на статический шум, а на спектрограмме выглядит как , как статический шум, который вы можете увидеть на экране телевизора.
В то время как каждый мгновенный всплеск энергии происходит со случайной частотой, существуют тенденции, в которых частоты случайные всплески группируются вокруг. [s] имеет более высокую среднюю частоту, чем [ʃ]; и оба выше, чем [f] или [θ].
Звонкие фрикативы демонстрируют как обычные вибрации голосовых связок, так и случайно турбулентный воздушный поток.
[в]
[h] на самом деле глухая версия предшествующей или следующей гласной. На спектрограмме это немного похоже на нечто среднее между фрикативом и гласным. В нем будет много случайных шумов, которые выглядят статичными, но сквозь них обычно видны слабые полосы формант глухих гласных.
Взрывчатые вещества
Средняя фаза безмолвного взрывного устройства — это полная тишина. На спектрограмме это отображается как белый пробел.
Тихие колебания голосовых складок в звонком взрывном звуке иногда проявляются в виде слабой полосы в нижней части спектрограммы на частоте f0. (Но очень часто вы ничего там не увидите, либо потому, что голос теряется в фоновом шуме, либо потому, что записывающее или компьютерное оборудование срезает такие низкие частоты.)
Чтобы отличить взрывные звуки, слушатели полагаются на релизный пакет и формантные переходы. На спектрограмме всплеск высвобождения выглядит как очень и очень тонкий фрикатив. Формантные переходы (если вы их видите) выглядят так, как будто форманты были искажены в сторону от частот, которые они имеют во время большей части гласной.
Устремление будет выглядеть как промежуток в [h] между пробелом и гласной — в частности, глухая версия следующей гласной.(Вспомните, что тело языка находится в положении для следующей гласной и что стремление — это просто задержка начала голоса.)
NB: Аспирация — это не то же самое, что всплеск высвобождения. Период устремления (который есть только у некоторых безмолвных взрывчатых веществ) намного длиннее, чем очень короткий всплеск высвобождения (который есть у всех выпущенных взрывчатых веществ).
Приведенная выше спектрограмма представляет собой английское слово attack [əˈtʰæk].
Обозначены периоды времени:
| А: | начальная шва |
| В: | медиальная фаза [т] (тишина) |
| С: | выпуск серии [t] |
| D: | стремление (задержка начала озвучивания на [æ]) |
| E: | [æ] — озвучивание наконец началось.Прямо в конце гласного вы можете увидеть, как F2 и F3 начинают сближаться друг с другом в образце перехода формант (часто называемом «велярная щепотка»), который обычно отмечает фазу начала велярного согласного. |
| Факс: | медиальная фаза [k] (опять молчание) |
| G: | — всплеск выпуска [k] (который я объявил как выпущенный для целей этой спектрограммы) |
Носовые и [l]
Носовые и [l] обычно выглядят как довольно слабые гласные без большой амплитуды на высоких частотах.
Еще можно увидеть некоторые вещи, похожие на форманты. Но акустические свойства трубок с ответвлениями и боковыми камерами намного сложнее, как с антиформантами, так и с формантами, поэтому полосы формант будут появляться в разных положениях и обычно будут более слабыми. Какое у — носовое или латеральное — это обычно не то, что вы можете понять, глядя только на спектрограмму.
Общие сведения об аудиоданных, преобразовании Фурье, БПФ и спектрограмме для системы распознавания речи | Картик Чаудхари
Быстрое преобразование Фурье (БПФ) — математический алгоритм, который вычисляет дискретное преобразование Фурье (ДПФ) заданной последовательности.Единственное различие между FT (преобразование Фурье) и FFT состоит в том, что FT рассматривает непрерывный сигнал, а FFT принимает дискретный сигнал в качестве входного. DFT преобразует последовательность (дискретный сигнал) в ее частотные составляющие точно так же, как FT для непрерывного сигнала. В нашем случае у нас есть последовательность амплитуд, выбранных из непрерывного звукового сигнала. Алгоритм DFT или FFT может преобразовать этот дискретный сигнал временной области в частотный.
Обзор алгоритма БПФПростая синусоида для понимания БПФ
Чтобы понять результат БПФ, давайте создадим простую синусоиду.Следующий фрагмент кода создает синусоидальную волну с частотой дискретизации = 100, амплитудой = 1 и частотой = 3 . Значения амплитуды вычисляются каждые 1/100 секунды (частота дискретизации) и сохраняются в списке с именем y1. Мы передадим эти дискретные значения амплитуды для вычисления ДПФ этого сигнала с помощью алгоритма БПФ.
Если вы нанесете эти дискретные значения (y1), сохраняя номер выборки на оси x и значение амплитуды на оси y, он сгенерирует красивый график синусоидальной волны, как показано на следующем снимке экрана —
Теперь у нас есть последовательность амплитуд, сохраненная в список y1.Мы передадим эту последовательность алгоритму БПФ, реализованному scipy. Этот алгоритм возвращает список yf из комплексных амплитуд частот , найденных в сигнале. Первая половина этого списка возвращает термины с положительной частотой, а другая половина возвращает термины с отрицательной частотой, которые аналогичны положительным. Вы можете выбрать любую половину и вычислить абсолютные значения для представления частот, присутствующих в сигнале. Следующая функция берет образцы в качестве входных данных и строит график частот —
На следующем графике мы построили частоты для нашей синусоидальной волны, используя указанную выше функцию fft_plot.Вы можете видеть, что этот график ясно показывает одно значение частоты, присутствующее в нашей синусоиде, которое равно 3. Кроме того, он показывает амплитуду, связанную с этой частотой, которую мы оставили равной 1 для нашей синусоидальной волны.
Чтобы проверить выходной сигнал БПФ для сигнала, имеющего на более одной частоты , давайте создадим еще одну синусоидальную волну. На этот раз мы оставим : частота дискретизации = 100, амплитуда = 2 и значение частоты = 11 . Следующий код генерирует этот сигнал и строит синусоидальную волну —
Сгенерированная синусоида выглядит как на графике ниже.Было бы более плавно, если бы мы увеличили частоту дискретизации. Мы сохранили частоту дискретизации = 100 , потому что позже мы добавим этот сигнал к нашей старой синусоиде.
Очевидно, функция БПФ также покажет одиночный всплеск с частотой = 11 и для этой волны. Но мы хотим увидеть, что произойдет, если мы сложим эти два сигнала с одинаковой частотой дискретизации, но с разными значениями частоты и амплитуды. Здесь последовательность y3 будет представлять результирующий сигнал.
Если мы построим сигнал y3, он будет выглядеть примерно так —
Если мы передадим эту последовательность (y3) нашей функции fft_plot. Он генерирует для нас следующий частотный график. Он показывает два пика для двух частот, присутствующих в нашем результирующем сигнале. Таким образом, наличие одной частоты не влияет на другую частоту в сигнале. Также следует отметить, что амплитуды частот находятся на линии с нашими сгенерированными синусоидальными волнами.
БПФ для нашего аудиосигнала
Теперь, когда мы увидели, как этот алгоритм БПФ дает нам все частоты в данном сигнале. давайте попробуем передать в эту функцию наш исходный аудиосигнал. Мы используем тот же аудиоклип, который мы ранее загрузили в питон, с частотой дискретизации = 16000 .
Теперь посмотрите на следующий график частот. Этот сигнал «длиной 3 секунды» состоит из тысяч различных частот. Амплитуды значений частот> 2000 очень малы, так как большинство этих частот, вероятно, вызвано шумом.Мы наносим на график частоты в диапазоне от 0 до 8 кГц, потому что наш сигнал был дискретизирован с частотой дискретизации 16k, и согласно теореме дискретизации Найквиста он должен иметь только частоты ≤ 8000 Гц (16000/2).
Сильные частоты находятся в диапазоне от 0 до 1 кГц только потому, что этот аудиоклип был человеческой речью. Мы знаем, что в типичной человеческой речи этот диапазон частот доминирует.
Звук и спектрограммы — Soundbirding
На этой странице рассматриваются различные технические вопросы обо всех типах звуков, которые может издавать птица, их визуальном отображении и способах их описания.Он также предоставляет ключи для анализа спектрограмм.
- Звуки, песни и звонки.
- Что такое звук?
- Песня или звонок?
- Звуки других птиц: барабанная дробь, звуки крыльев, хлопки купюрами…
- Что такое спектрограмма?
- Почему спектрограммы?
- Три измерения спектрограммы
- Описание звуков
- Продолжительность, высота тона и громкость
- Основная частота и гармоники
- Тон
- Звуковая текстура
- Пространственное положение
1.Звуки, песни и звонки
1.1. Что за звук?
Звук — это волна, то есть механическая вибрация частиц воздуха. Места сжатия частиц — это области высокого давления. Места разрыва частиц — это области низкого давления. Поскольку ваша барабанная перепонка очень чувствительна к небольшим колебаниям давления воздуха, вы можете слышать звуки.
По сути, создание звука — это просто движение частиц воздуха особым образом, поэтому вы можете слышать ветер: тем сильнее (т.е наиболее жесткая) вибрация частиц, чем громче звук, тем быстрее ритм в изменении давления, тем выше тональность звука и так далее…
1.2. Песня или звонок?
Обычно мы разделяем песни и звонки. Песня часто определяется как относительно структурированная вокализация, используемая для целей воспроизведения. Звонки, как правило, являются более короткими, менее сложными звуками, используемыми для сообщения о тревоге или местонахождении человека.
У каждого вида и особи есть множество песен и призывов, используемых в разных контекстах.В большинстве случаев разница между песней и призывом очевидна, если вы знакомы с поющими видами. Однако мы иногда не можем классифицировать вокализации как «песни» или «звонки». Поэтому можно встретить такие слова, как «песня-позыв», «субпесня»
. Проверьте этот пример для болотной синицы (Poecile palustris):
Вот типичная песня:
Там типичный звонок:
И вот очень удивительный вокал, который я записал в Бретани.Это довольно уникально, но болотная синица, как известно, очень креативна. Это можно назвать своего рода «песней-звонком»:
Большинство птиц, которые вы услышите поют, — это самцы, но недавние статьи показывают, что самки тоже могут петь у большинства видов птиц.
1.3 Другие звуки птиц: барабанная дробь, звуки крыльев, хлопки купюрами…
Помимо использования органов голоса, многие виды птиц издают другие звуки, которые иногда могут быть диагностическими.
Посмотрите следующие примеры:
Крылышки козодоя (Caprimulgus europaeus):
Барабанье евразийского трехпалого дятла (Picoides tridactylus):
Звук полета крыльев обыкновенного золотоглазого (Bucephala clangula):
Билл хлопает в ладоши белого аиста (Ciconia ciconia):
2.Что такое спектрограмма?
2.1 Почему спектрограммы?
- Люди — существа зрительные: у большинства из нас зрительная память намного лучше, чем слуховая.
- Наши уши привыкли понимать длинные низкие последовательности слогов, но не короткие высокие ноты
Следовательно, идея анализа незнакомых звуков состоит в том, чтобы… преобразовать их во что-то визуальное!
Вот что это такое: спектрограмма — это просто двух- или трехмерная визуализация звука.
2.2 Три измерения спектрограммы
Обычно бывает две оси: на первой отображается время, а на второй — частота. Также часто существует третье измерение: громкость, которую можно отобразить с помощью цветов. Самые яркие цвета обычно изображают самые громкие звуки.
Итак, три измерения:
- Длительность, отображаемая на первой оси спектрограммы (абсцисса). Единица измерения — секунда (ы).Сколько секунд длится звук? Чем длиннее звук, тем длиннее спектрограмма.
- Шаг, который виден на второй оси спектрограммы (ордината). Фактически, это частота (чем выше частота звуковых волн, тем выше звук). Другими словами, высокие звуки возникают, когда давление воздуха в данном месте претерпевает быстрые изменения. Таким образом, единицей измерения высоты звука является герц (Гц), а для звуков птиц он обычно составляет от 1 до 10 килогерц (кГц).Чем выше точка на спектрограмме, тем выше звук. Легко, не правда ли?
- Громкость, часто отображаемая цветами на спектрограммах. Вот почему спектрограммы на самом деле трехмерны (третье измерение = цвет). ). Единица измерения — децибел (Дб). Обычно чем ярче цвет, тем громче звук.
Как читать громкость на спектрограмме
3. Описание звуков
Существует шесть способов анализа звуковых волн птиц.Их:
- продолжительность
- шаг
- громкость
- тон
- звуковая текстура
- пространственное положение
3.1 Продолжительность, высота и громкость
К счастью, первые три компонента сразу видны на спектрограмме, поэтому, просто считывая числа на спектрограмме, вы уже можете описать большую часть звука!
Duration и pitch очень легко описать, потому что вы можете непосредственно прочитать их значение на двух основных осях. Громкость обычно также можно увидеть с помощью цветов или оттенков серого. В большинстве программ обработки звука вы можете получить значение громкости, щелкнув в определенном месте спектрограммы
.Посмотрите этот пример вызова Common Cran (Grus grus), открытого с помощью программного обеспечения RavenLite:
Перемещая курсор на заданную часть спектрограммы, вы можете прочитать значения в нижней части окна.Мы читаем значения времени (продолжительность звука = время в конце — время в начале), высоты звука (= частота) и громкости (= мощность) сразу под спектрограммой.
3.2 Основная частота и гармоники
Обратите внимание, что в этом случае (и довольно часто в звуках птиц) на спектрограмме присутствует несколько частот. Самая низкая частота называется основной частотой (или первой гармоникой), а затем у вас есть вторая гармоника и так далее… Итак, здесь у нас есть четыре видимые гармоники: частота первой составляет около 1 кГц, второй — около 2,3 кГц, третий — 3,5 кГц, а четвертый — около 4.7 кГц (мы предполагаем, что есть еще и очень слабая пятая, около 5,9 кГц)
Основная частота и гармоники
3.3 Звуковая текстура
Звуковая текстура описывает закономерности, встречающиеся в песнях птиц. Как мы видели в разделе «О песнях птиц», птицы могут издавать несколько звуков одновременно. Также они часто повторяют один мотив несколько раз. Это создает уникальный образец звуковой суперпозиции или композиции.
3.3.1 Отдельные примечания и последовательности
Первое, на что нужно обратить внимание, это то, издает ли птица отдельный звук или же она объединяет звуки, чтобы создать последовательность.
Последовательность и изолированный звукБольшинство песен представляют собой последовательности, в то время как звонки часто представляют собой изолированные звуки. Но границы довольно размыты из-за огромного разнообразия звуков птиц.
Часто можно подсчитать количество слогов в звуке, как это делается в человеческом языке. Следовательно, изолированные звуки могут быть односложными, двусложными или трехсложными, и у нас могут быть двусложные последовательности, как в этом примере:
Последовательность двусложных звуковОбратите внимание, что трехсложный «изолированный» звук также часто можно рассматривать как последовательность.
3.3.2 Фразы, серии, трели и трели.
Есть четыре основных шаблона для описания последовательностей:
- Первое, на что нужно обратить внимание, это то, схожи ли ноты во всей последовательности. Обычно это хорошо видно на спектрограммах .
- Второй шаг — определить, можно ли легко разделить ноты (слышите ли вы, когда закончилась предыдущая нота и когда началась следующая, или это сложно, потому что последовательность довольно непрерывна?).Еще один способ подумать о проблеме: сможете ли вы посчитать, сколько нот появляется, когда вы слушаете последовательность, или она будет быстрой?
3.3.3 Шаблоны по длительности и шагу
Наконец, часто можно выделить некоторые тенденции в последовательности: как звуковая последовательность развивается от начала до конца? Сосредоточившись на скорости и подаче, мы можем выяснить некоторые закономерности:
Звуковые шаблоны для скорости и высоты звука3.4 тона
Тон — это нечто более субъективное и хитрое. Он отображает форму звука на спектрограмме.
Его можно описать несколькими объективными переменными:
- Модуляция
- Четкость
- Переменные, которые вы уже знаете (продолжительность, частота…)
3.4.1 Модуляция
Модуляция количественно определяет изменения высоты звука, которые происходят в одном звуке. Сильно модулированные звуки — это звуки, в которых частоты сильно различаются.Немодулированные звуки часто называют «монотонными звуками»
Модулированные и монотонные звуки.
Модуляция видна на спектрограмме как последовательность изогнутых вверх и изогнутых вниз линий
Кривые вверх и вниз спектрограммы
3.4.2 Четкость
Мы говорим, что звук чистый, если его форма на спектрограмме резкая и четко определенная. В противном случае звук считается шумным или полифоническим, если есть несколько перекрывающихся звуков
Чистый звук Шумный звук Полифонический звук
3.4.3 Собери все вместе
С помощью этих объективных критериев вы можете описать тона. Мы используем множество субъективных отдельных слов, таких как «носовой», «свистящий» … которые описывают определенные модели модуляции, четкости, высоты тона и скорости. См. Следующие примеры:
Жужжащий звук — это звук с очень быстрой модуляцией и повторяющимся характером. Щелкающий звук — это очень короткий односложный звук, охватывающий широкий диапазон частот. Носовой звук — это шумный звук с сильными гармониками.Свистящий звук — это слегка изогнутый звук средней или высокой частоты.
3.5 Пространственное расположение
Наконец, пространственное положение относится к тому, как конкретная птица интегрирует свою песню в общую звуковую атмосферу (звуковой ландшафт).
