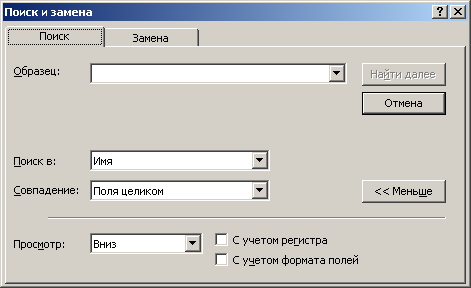
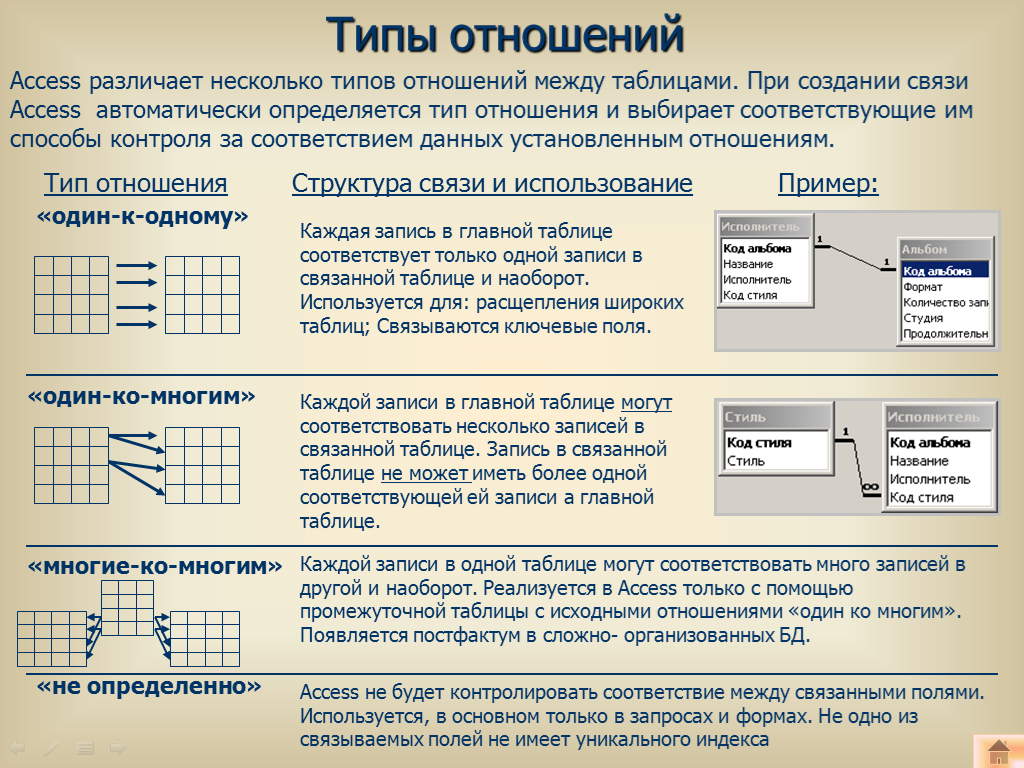
Что такое сложные фильтры в базах данных. Как они отличаются от простых фильтров. Какие преимущества дает использование сложных фильтров. Как создавать и применять сложные фильтры на практике.
Что такое сложные фильтры в базах данных
Сложные фильтры в базах данных представляют собой инструмент для отбора записей по нескольким критериям одновременно. В отличие от простых фильтров, которые используют только одно условие, сложные фильтры позволяют комбинировать множество условий с помощью логических операторов.
Основные характеристики сложных фильтров:
- Содержат несколько условий фильтрации
- Используют логические операторы AND, OR, NOT
- Позволяют создавать вложенные условия
- Могут применяться к нескольким полям и таблицам одновременно
- Обеспечивают более точный и гибкий отбор данных
Отличия сложных фильтров от простых
Чем же сложные фильтры отличаются от простых? Основные различия заключаются в следующем:
| Простые фильтры | Сложные фильтры |
|---|---|
| Одно условие | Несколько условий |
| Применяются к одному полю | Могут охватывать несколько полей |
| Ограниченная гибкость | Высокая гибкость настройки |
| Простота использования | Требуют навыков построения запросов |
Как видим, сложные фильтры обладают гораздо большей мощью и гибкостью по сравнению с простыми. Это позволяет точнее настраивать выборку данных под конкретные задачи.
Преимущества использования сложных фильтров
Применение сложных фильтров дает ряд существенных преимуществ при работе с базами данных:
- Точность выборки. Комбинирование условий позволяет получить именно те записи, которые нужны.
- Гибкость настройки. Можно создавать сложные условия отбора под любые задачи.
- Экономия времени. Отпадает необходимость в последовательном применении нескольких простых фильтров.
- Возможность сохранения. Сложные фильтры можно сохранять для повторного использования.
- Работа с большими объемами данных. Эффективная фильтрация больших таблиц и баз данных.
Все эти преимущества делают сложные фильтры незаменимым инструментом для аналитиков, разработчиков баз данных и других специалистов, работающих с большими массивами информации.
Основные компоненты сложных фильтров
Для эффективного использования сложных фильтров важно понимать их структуру. Основными компонентами являются:
- Условия фильтрации — задают критерии отбора записей
- Логические операторы — связывают условия между собой
- Поля таблиц — указывают, к каким данным применяется фильтр
- Операторы сравнения — определяют способ сопоставления значений
- Функции — позволяют производить вычисления в условиях
Правильное сочетание этих компонентов позволяет создавать сложные фильтры практически любой степени сложности.

Создание сложных фильтров на практике
Рассмотрим пошаговый процесс создания сложного фильтра на примере:
- Определите поля, к которым будет применяться фильтр
- Сформулируйте условия отбора для каждого поля
- Выберите логические операторы для связи условий
- Запишите выражение фильтра, используя синтаксис SQL
- Проверьте корректность фильтра на тестовых данных
- При необходимости откорректируйте условия
Пример сложного фильтра в SQL:
SELECT * FROM Employees
WHERE (Age > 30 AND Department = 'Sales')
OR (Salary > 50000 AND City = 'New York')
Этот фильтр отберет сотрудников старше 30 лет из отдела продаж, а также всех сотрудников из Нью-Йорка с зарплатой выше 50000.
Типичные ошибки при работе со сложными фильтрами
При создании и использовании сложных фильтров важно избегать распространенных ошибок:
- Неправильное использование скобок в выражениях
- Ошибки в порядке применения логических операторов
- Некорректное указание имен полей и таблиц
- Использование несовместимых типов данных в условиях
- Создание избыточно сложных фильтров
Внимательная проверка синтаксиса и логики фильтра поможет избежать этих ошибок и обеспечить корректную работу запросов.
Оптимизация производительности сложных фильтров
Сложные фильтры могут существенно влиять на производительность базы данных. Для оптимизации рекомендуется:
- Использовать индексы для полей, участвующих в фильтрации
- Избегать использования функций в условиях фильтра
- Правильно структурировать запросы, выносить общие условия
- Ограничивать количество возвращаемых полей
- Использовать подзапросы и временные таблицы для сложных выборок
Применение этих методов позволит значительно ускорить работу сложных фильтров даже на больших объемах данных.
Примеры использования сложных фильтров в различных СУБД
Рассмотрим примеры реализации сложных фильтров в популярных системах управления базами данных:
MySQL
SELECT * FROM Orders
WHERE (OrderDate BETWEEN '2023-01-01' AND '2023-12-31')
AND (TotalAmount > 1000 OR CustomerID IN (SELECT CustomerID FROM Premium_Customers))
PostgreSQL
SELECT * FROM Products
WHERE (Category = 'Electronics' AND Price > 500)
OR (Category = 'Books' AND Author = 'John Doe')
ORDER BY Price DESC
Microsoft SQL Server
SELECT * FROM Employees
WHERE Department IN ('Sales', 'Marketing')
AND (DATEDIFF(YEAR, HireDate, GETDATE()) > 5 OR Salary > 75000)
Как видно из примеров, несмотря на различия в синтаксисе, принципы построения сложных фильтров остаются схожими в разных СУБД.
Заключение
Сложные фильтры являются мощным инструментом для работы с базами данных, позволяющим точно и эффективно отбирать нужную информацию. Освоение техники создания и оптимизации сложных фильтров значительно повышает эффективность работы с данными и открывает новые возможности для анализа и обработки информации.
Ключевые моменты для успешного использования сложных фильтров:
- Четкое понимание структуры данных и связей между таблицами
- Умение правильно формулировать условия отбора
- Знание синтаксиса SQL и особенностей конкретной СУБД
- Навыки оптимизации запросов для повышения производительности
- Регулярная практика и изучение новых возможностей фильтрации
Овладев искусством создания сложных фильтров, вы сможете эффективно решать самые разнообразные задачи по обработке и анализу данных в любых информационных системах.
сложный фильтр — это… Что такое сложный фильтр?
- сложный фильтр
- total filter
Большой англо-русский и русско-английский словарь. 2001.
- сложный сплайн
- сложный цвет
Смотреть что такое «сложный фильтр» в других словарях:
сложный фильтр — sudėtingasis filtras statusas T sritis fizika atitikmenys: angl. complex filter vok. zusammengesetztes Filter, n rus. сложный фильтр, m pranc. filtre complexe, m … Fizikos terminų žodynas
Фильтр Калмана — Фильтр Калмана эффективный рекурсивный фильтр, оценивающий вектор состояния динамической системы, используя ряд неполных и зашумленных измерений. Назван в честь Рудольфа Калмана. Фильтр Калмана широко используется в инженерных и… … Википедия
Выжимание
— (отжатие) вместе с процеживанием (фильтрованием, см. Процеживание), составляет очень распространенный в обыденной жизни и в фабрично заводской деятельности прием для отделения жидкостей от твердых тел при их взаимном смешении. Хотя процеживанием… … Энциклопедический словарь Ф.А. Брокгауза и И.А. ЕфронаВыжимaниe (отжатие) — вместе с процеживанием (фильтрованием, см. Процеживание), составляет очень распространенный в обыденной жизни и в фабрично заводской деятельности прием для отделения жидкостей от твердых тел при их взаимном смешении. Хотя процеживанием чаще всего … Энциклопедический словарь Ф.А. Брокгауза и И.А. Ефрона
Речь — I речевая деятельность, общение, опосредствованное Языком, один из видов коммуникативной (см. Коммуникация) деятельности человека. Р. возникла в коллективе как средство координации совместной трудовой деятельности и как одна из форм… … Большая советская энциклопедия
Речь — I речевая деятельность, общение, опосредствованное Языком, один из видов коммуникативной (см. Коммуникация) деятельности человека. Р. возникла в коллективе как средство координации совместной трудовой деятельности и как одна из форм… … Большая советская энциклопедия
Пожары* — являются злейшим врагом человеческого общежития, причиняющим неисчислимые бедствия. Особенно велика их разрушительная сила у нас в России. Число П. и сумма причиняемых ими убытков в Европейской России ежегодно возрастают; с 1860 по 1869 г. было… … Энциклопедический словарь Ф.А. Брокгауза и И.А. Ефрона
Пожары — являются злейшим врагом человеческого общежития, причиняющим неисчислимые бедствия. Особенно велика их разрушительная сила у нас в России. Число П. и сумма причиняемых ими убытков в Европейской России ежегодно возрастают; с 1860 по 1869 г. было… … Энциклопедический словарь Ф.А. Брокгауза и И.А. Ефрона
complex filter — sudėtingasis filtras statusas T sritis fizika atitikmenys: angl. complex filter vok. zusammengesetztes Filter, n rus. сложный фильтр, m pranc. filtre complexe, m … Fizikos terminų žodynas
filtre complexe — sudėtingasis filtras statusas T sritis fizika atitikmenys: angl. complex filter vok. zusammengesetztes Filter, n rus. сложный фильтр, m pranc. filtre complexe, m … Fizikos terminų žodynas
sudėtingasis filtras — statusas T sritis fizika atitikmenys: angl. complex filter vok. zusammengesetztes Filter, n rus. сложный фильтр, m pranc. filtre complexe, m … Fizikos terminų žodynas
…::Билеты по информатике (ликбез)::…
…::Билеты по информатике (ликбез)::… НазадСловарь терминов по информационным технологиям
_____________________________________________________________
Англоязычные
BMP
(Bit MaP image)используемый в Windows и поддерживаемый многими графическими редакторами,
включая Paint. Может содержать изображения с глубиной цвета 10, 16, 24 и 36 бита.
Рекомендуется для хранения и обмена данными с другими приложениями.
CorelDRaw files
— оригинальный формат векторных графических файлов,используемый в профессиональной графической системе CorelDraw.
EPS
(Encapculated PostScript) — универсальный формат векторных графических файлов,используемый для печати и создания иллюстраций в настольных издательских системах.
GIF
(Graphics Interchange Format) — универсальный формат растровых графических файлов,используемый для размещения изображений на Web-страницах в интернете.
Включает алгоритм сжатия без потери информации. Рекомендуется для хранения изображений,
создаваемых программным путем (диаграмм, графиков и др.), и рисунков (типа аппликации)
с ограниченным числом цветов (до 256).
HTM, HTML
— Универсальный формат хранения Web-страниц. Содержит управляющиекоды (теги) языка разметки гипертекста (HTML).
Imaging
— Стандартная программа Windows, которая позволяет просматриватьи осуществлять простейшее редактирование графических документов.
JPG
(Joint Photographic Expert Group) — Универсальный формат растровых графических файлов,используемый для размещения отсканированных фотографий, иллюстраций и изображений
на Web-страницах в Интернете. Алгоритм сжатия позволяет уменьшить объем файла в десятки раз,
однако приводит к необратимой потере части информации.
LX
— Оригинальный формат используемой версии отечественного редактора Лексикон.Полностью сохраняет форматирование. Использует 16-битную кодировку Unicode.
OLE
(Object Linking Embeding) — Механизм встраивания и внедрения объектов, позволяющийкопировать и вставлять объекты из одного приложения в другое, в том числе получать
из обычного текстового документа мультимедиа документ.
Paint
— Стандартная программа Windows, которая позволяет создавать и редактироватьизображения в форматах BMP, GIF, JPG.
RTF (Rich Text Format)
— Универсальный формат текстовых файлов, сохраняющий текст с форматированием. Преобразует управляющими кодами в команды, которые могут быть прочитаны многими приложениями в различных операционных системах.TIFF (Tagged Image File Format)
— универсальный формат растровых графических файлов,используемый для обмена документами между различными программами. Включает алгоритм сжатия
без потери информации. Рекомендуется для использования при работе с графическими системами.
TXT (Text Only)
— Наиболее универсальный формат текстовых файлов, содержащий текст без форматирования вместе с управляющими символами конца абзацев. Служит для использования в приложениях в различных операционных системах.WMF (Windows MetaFile)
— универсальный формат векторных графических файлов,используемый Windows для хранения коллекции графических изображений Microsoft Clip Gallery.
WordPad
— Стандартная программа Windows, которая позволяет создавать простые документы в формате DOC. Является < < урезанной> > версией редактора Word.Русскоязычные
Абзац
— В компьютерных документах — это любой текст, заканчивающийся управляющим символом (маркером) конца абзаца. Ввод конца абзаца обеспечивается нажатием клавиши {Enter} и отображается непечатаемым символом абзаца (в соответствующем режиме). Абзац может состоять из любого количества символов, рисунков и объектов других приложений.Абсолютная ссылка (адресация) в формуле ЭТ — Служит для указания фиксированного (неизменяемого) адреса ячейки ЭТ. Имеет следующий вид, например, $F$1. При перемещении или копировании формулы абсолютные ссылки не изменяются.
Автоматизация деятельности человека — Возможность реализации поставленной задачи с помощью машины, специально сконструированной для выполнения отдельных команд алгоритма и выполняющая их в последовательности, указанной в алгоритме.
Автосуммирование в ЭТ — Кнопка на панели инструментов Стандартная, используемая для автоматического суммирования чисел с помощью функции СУММ (значений выделенного диапазона ячеек ЭТ).
Активная ячейка ЭТ — Ячейка, с которой производятся какие-либо действия и выделяемая рамкой.
Алгоритм — Последовательность действий, приводящих к решению поставленной задачи (достижение цели) за конечное число шагов. Каждый алгоритм строится в расчете на некоторого исполнителя действий (команд).
Алгоритм сжатия
— Алгоритм, используемый в растровом графическом редакторедля уменьшения объема графического файла и включаемый в его формат.
Алгоритм сжатия для отсканированных фотографий и иллюстраций
— Алгоритм, используемый в растровом графическом редакторе для уменьшения объема графического файла в десятки раз путем уменьшения глубины цвета (цветов и оттенков), например, в JPG. Может привести к необратимой потере информации (файлы не могут быть восстановлены в исходном виде).Алгоритм сжатия для рисунков типа аппликации
— Алгоритм, используемый в растровом графическом редакторе для уменьшения объема графического файла в несколько раз путем замены последовательности повторяющихся величин (пикселей одинакового цвета) на две величины (пиксел и количество его повторений), например, в BMP.Алгоритм сжатия для рисунков типа диаграмм
— Алгоритм, используемый в растровом графическом редакторе для уменьшения объема графического файла в несколько раз путем поиска и замены последовательности повторяющихся узоров, например, в GIF, TIFF.База данных (БД) — Организованная совокупность данных, предназначенная для длительного хранения во внешней памяти ЭВМ и постоянного применения
.Блокнот —
Стандартная программа Windows, которая позволяет создавать неформатированные текстовые документы в формате TXT. Часто применяется при создании и редактировании Web-страниц с использованием языка HTML.Блок-схема алгоритма — Графический способ записи алгоритма. Блоки обозначают действия исполнителя, а соединяющие их стрелки указывают на последовательность выполнения действий.
Быстрый поиск данных в БД — Поиск записей, в которых значения определенного поля полностью или частично совпадают с некоторой величиной.
Векторная графика
— Графика, в которой (векторные) изображения формируются из объектов, кторые хранятся в памяти компьютера в виде графических примитивов и описывающих их математических формул. Эти изображения могут быть масштабированы (увеличены или уменьшены) без потери качества. Файлы, хранящие векторные графические изображения имеют сравнительно небольшой объем.Вложенная сортировка данных в ЭТ — Упорядоточение данных по нескольким столбцам, с заданием последовательности сортировки столбцов (при одинаковом значении в предыдущем столбце).
Внедренная диаграмма ЭТ — Диаграмма, являющаяся иллюстрацией к данным на конкретном рабочем листе и размещенная на одном листе с ними.
Вспомогательный алгоритм — Алгоритм, по которому решается некоторая подзадача из основной задачи и который, как правило, выполняется многократно
(или процедура, или подпрограмма в языках программирования).Выравнивание абзаца — Расположение текста относительно границ полей страницы (по левому краю, по центру, по правому краю, по ширине, при котором последняя строка выравнивается по левому краю).
Главный ключ в БД — Поле (или совокупность полей), значение которого не повторяется у разных записей.
Глубина цвета изображения
— Количество разрядов, используемых для кодирования цвета изображения.Графики в ЭТ — Частный случай построения диаграмм, используемый для отображения изменения данных за равные промежутки времени. Графики позволяют анализировать закономерности изменения величин.
Графические примитивы
— Штатные графические объекты (фигуры типа линии, различного вида стрелки, овал, прямоугольники, и др.), задаваемые своими координатами и цветом. Их пиктограммы используются в панели Рисования векторных графических редакторов.Диаграмма ЭТ — Графическое представление данных рабочего листа в различной форме (диаграммы линейчатые (столбчатые
), круговые, графики и другие типы). При обновлении данных на рабочем листе диаграммы также обновляются.Дискретность алгоритма — Разделение выполнения решения задачи на отдельные операции (выполняемые исполнителем по определенным командам, входящих в систему команд исполнителя — свойство понятности).
Документ редактирования
— Совокупность объектов, составляющих документ: символы, абзацы, таблицы, фрагменты или документ в целом.Документальная БД — БД, содержащая обширную информацию самого разного типа: текстовую, графическую, звуковую, мультимедийную.
Заголовок столбца ЭТ — Обозначается буквами или сочетаниями букв (F, G, FG).
Заголовок строки ЭТ
— Обозначается числами (1, 17, 255).Записи БД различаются значениями ключей.
Запросы СУБД — Инструменты (самостоятельные объекты БД) для отбора данных на основе заданных условий. Запросы как и фильтры бывают простые (содержат одно условие) и сложные (несколько условий для различных полей).
Знаки логических операций — Служебные смысловые связки типа “и” (логическое умножение или конъюнкция), “или” (логическое сложение или дизъюнкция), “не” (отрицание).
Значения полей — Это некоторые величины определенных типов. От типа величины зависят действия, которые можно с ней производить. Например, с числовыми величинами можно выполнять арифметические операции, а с символьными и логическими нельзя.
Изменение внешнего вида таблиц — Установка границ, фона ячеек автоматически (с помощью соответствующей команды и диалоговой панели, обеспечивающей задание различных вариантов оформления таблицы) или вручную (с помощью соответствующей команды, обеспечивающей задание требуемых параметров оформления таблицы, а также типа и ширины линий границы, фона ячеек или выбор узора).
Изменение исходных данных в ячейке ЭТ — Приводит к автоматическому пересчету формул, в которые эти данные входят.
Информационная система — Совокупность БД и комплекса аппаратно-программных средств для ее хранения, изменения и поиска информации, для взаимодействия с пользователем.
Исполнитель алгоритма — Объект управления (технические устройство или живое существо), например, робот.
Ключи сортировки записей БД — Поля, по которым производится сортировка записей (первичный ключ, вторичный ключ и т.д.).
Команда (или указание) алгоритма — Предписание исполнителю выполнить одно конкретное законченное действие.
Команды удаления записей в БД — Формат команд: . удалить <логическое выражение>, . удалить все (в реальных СУБД сначала лишь помечаются записи), . добавить (ввод полей новой записи, заносимой в конец таблицы).
Конвертор текстовых файлов — Специальная программа, используемая в большинстве текстовых редакторов для преобразования текстового файла из одного формата в другой, например из формата RTF в формат DOC.
Линейная алгоритмическая конструкция — Алгоритм, состоящий из серий команд.
Логическое выражение — Это некоторое высказывание,
по поводу которого можно заключить истинно оно или ложно.
Логическое сложение — В результате логического сложения получается истина, если значение хотя бы одного операнда истинно.
Логическое умножение — В результате логического умножения получается истина, если два операнда истинны.
Макросы — Служат для автоматизации повторяющихся операций.
Мастер диаграмм ЭТ — Средство, позволяющее создавать диаграмму по шагам с помощью серии диалоговых окон.
Мастер отчетов БД — Инструмент СУБД, позволяющий задавать параметры внешнего вида отчета с помощью диалоговых окон.
Мастер форм БД — Вид графического интерфейса, помогающий с помощью серии диалоговых окон пользователю создание Формы.
Мастер функций ЭТ — Команда [Вставка-Функция…], обеспечивающая выбор требуемой функции из соответствующей категории встроенных в Excel функций (математические, статистические, финансовые, дата и время и др.).
Межстрочный интервал (интерльяж) — Расстояние между строк документа. Обычно задается числами 1; 1,5; 2 и др., а также соответствующим коэффициентом.
Метод последовательной детализации при построении алгоритмов — Метод, при котором сначала записывается основной алгоритм, а затем описываются использованные в нем вспомогательные алгоритмы (программирование сверху вниз).
Модули (процедуры обработки событий) СУБД
— Служат для автоматизации работы с БД и пишутся на языках программирования, например на VBA.Мультимедиа технология
— Технология, позволяющая одновременно использовать различные способы представления информации: текст, числа, графику, анимацию, видео и звук. Графический интерфейс мультимедийных продуктов обеспечивает интерактивность взаимодействия с пользователем (кнопки, текстовые окна и др.)Настольные издательские системы — Мощные программы обработки текста, предназначенные для подготовки документов для публикации.
Настройка изображения
— Панель, используемая для изменения готового графического объекта в (векторных) графических редакторах после его выделения.Начертание символов — Основное свойство отображения символов. Различают нормальное, полужирное
, курсивное, полужирное курсивное.Неполная команда ветвления
имеет следующий формат:если <условие> то <серия 1> иначе <следующая команда алгоритма>.
Нулевой
отступ первой строки — Применяется в обычном тексте и в абзацах, выровненных по центру.Окно БД — Один из главных элементов интерфейса СУБД, в котором систематизированы все основные объекты БД: таблицы, запросы, формы, отчеты, макросы и модули. Для работы с ними служат окна работы с объектами. Причем в каждый момент времени одно окно является активным.
Определенность (или точность) алгоритма — Возможность понимания и выполнения каждого действия, предписываемого командами алгоритма.
Оригинальный формат графического файла
— Формат, который может быть обработан создающим его графическим редактором, например CDR.Оригинальный формат текстовых файлов — Формат, используемый отдельными текстовыми редакторами.
Основные алгоритмические конструкции: линейная, разветвляющаяся, циклическая.
Основные типы полей БД: числовой (только числа), символьный (слова, тексты, коды и др.), логический (значения “истина” и “ложь”), дата.
Основные элементы блок-схема алгоритма — начало или конец алгоритма (обычно овал или ромб), простая команда (прямоугольник), обращение к вспомогательному алгоритму (прямоугольник с двойными линиями по узким сторонам), проверка условия (ромб).
Относительная ссылка (адресация) в формуле ЭТ — Служит для указания (изменяемого) адреса ячейки ЭТ, вычисляемого относительно ячейки, в которой находится формула. Имеет следующий вид, например, F1. При перемещении или копировании формулы из активной ячейки относительные ссылки автоматически обновляются (изменяются) в зависимости от нового положения формулы. По умолчанию при наборе формул в Excel используются относительные ссылки.
Отношение
“один-ко-многим” есть форма логического выражения реляционных БД.Отношение есть форма логического выражения.
Отрицание — Изменяет значение логической величины на противоположное: не истина = ложь, не ложь = истина.
Отрицательный отступ первой строки — Расположение первой строки левее относительно всех остальных строк абзаца. Применяется в словарях, определениях.
Отступ первой строки (красная строка) — Расположение первой строки относительно
всех остальных строк абзаца.
Отчеты БД — Производные объекты БД, создаваемые на основе таблиц, форм и запросов.
Отчеты СУБД — Служат для печати данных, содержащихся в таблицах и запросах, в требуемой форме.
Параметры страницы — Совокупность показателей страницы, включая ее формат (размер), ориентацию (вертикальную или книжную, горизонтальную или альбомную), размеры полей (слева, справа, сверху, снизу) и другие.
Печать документа — Режим, обеспечивающий с помощью диалоговой панели Печать выбор типа принтера, числа станиц и номеров страниц, выводимых на печать.
Пиксел
— Минимальный участок изображения, которому независимым образом можно задать цвет.Подбор параметра в ЭТ — Сервисная функция ЭТ, обеспечивающая возможность определения неизвестного значения аргумента, при котором функция принимает заданное значение 0.
Подчеркивание
— Свойство отображения символов.Поиск данных в ЭТ —
Нахождение строк в соответствии с заданными условиями (фильтром). При этом необходимо выделить хотя бы одну ячейку с данными.Полная команда ветвления имеет следующий формат:
если <условие> то <серия 1> иначе <серия 2>. Различают положительную ветвь ветвления
(условие истинно) и отрицательную ветвь ветвления (условие ложно).
Полный набор данных — Необходим для успешной реализации алгоритма.
Положительный отступ первой строки — Расположение первой строки правее относительно всех остальных строк абзаца. Применяется в обычном тексте.
Получение справки из БД — Указания выводимых полей и условий поиска (условие, которому должны удовлетворять выводимые записи). Например,
.справка <список выводимых полей> для <условие поиска>. Результат выводится на экран в виде таблицы. Для вывода на экран всех записей следует указать в команде: .справка все.
Поля — Это различные характеристики (атрибуты) объекта. Значения полей в одной строке относятся к одному объекту. Разные поля отличаются именами.
Порядок выполнения операций в сложном логическом выражении — Определяется старшинством операций (по убыванию старшинства — не, и, или). возведение в степень, * умножение, / деление, +, — сложение, вычитание. Несколько подряд записанных операций выполняются в порядке их записи в формуле (слева направо). В формулах допускается применение некоторых математических функций, причем аргументы пишутся после имени функции в круглых скобках.
Предварительный просмотр документа — Режим, позволяющий увидеть, как будет выглядеть в напечатанном виде несколько страниц документа.
Программа — Это алгоритм, записанный на языке исполнителя.
Программирование внизу вверх — Сборочный метод, при котором сначала записываются вспомогательные алгоритмы, использованные в основном алгоритме, а затем описывается основной алгоритм.
Прозрачный фон
— Трансформация, производимая с однотонным фоном рисунка.Простейшая форма логического выражения — одна величина логического типа.
Простое логическое выражение — состоит из одной логической переменной или одного отношения.
Простой фильтр БД — Фильтр, содержащий условия отбора записей только для одного поля конкретной таблицы.
Пункт — Единица измерения размера шрифта (пункт): 1 пт = 0,376 мм.
В одном дюйме (
Работа с базой данных начинается с открытия файлов.
Рабочая книга — Совокупность нескольких рабочих листов, образующих файл ЭТ Excel. Для удобства работы с рабочей книгой в нижней части окна размещены ярлыки листов и кнопки прокрутки.
Рабочие листы — Основной тип документа, используемый в Excel для хранения и обработки данных. Допускает вычисления на основе данных из нескольких листов, именуемых по умолчанию “Лист 1”, “Лист 2” и т.п.
Разветвляющаяся алгоритмическая конструкция — Выполнение той или иной последовательности серии команд алгоритма в зависимости от истинности ветвления.
Размер шрифта — Единицей измерения размера шрифта является пункт: 1 пт = 0,376 мм.
В Word по умолчанию используется шрифт Times New Roman размером 12 пт.
Разметка страницы
документа — Режим, обеспечивающий создание, форматирование и редактирование документа в том виде, в котором он будет напечатан.Распределенная БД — БД, разные части которой хранятся на различных ЭВМ компьютерной сети.
Растровая графика
— Графика, в которой (растровое) изображение хранится с помощью точек различного цвета (пикселов), образующих строки и столбцы.Редактирование
(документа) —Преобразование, обеспечивающее добавление, удаление, перемещение или исправление содержания и внешнего вида документа.
Редактирование содержимого ячеек — Выравнивание текста и форматирование шрифта. Осуществляется традиционным способом с помощью соответствующих команд группы Формат.
Редактирование структуры таблицы —
Изменение ширины столбцов или высоты строк, вставка или удаление строк таблицы. Осуществляется с помощью мыши (перетаскиванием границ) или с помощью соответствующих команд группы Таблица.
Режим (вид) Конструктор — позволяет просматривать и изменять структуру таблицы.
Режим (вид) Таблицы — позволяет создавать и изменять структуру таблицы, а также вводить и редактировать данные.
Режим (вид) Формы — отображает одну запись в удобном для пользователя виде с помощью управляющих элементов и надписей, дизайн которых (размер, цвет и др.) пользователь может изменять. Форма может содержать рисунки, графики и другие внедренные объекты.
Результативность (или конечность) алгоритма — Требование исполнения алгоритма за конечное число шагов.
Реляционная БД — БД, содержащая связанные между собой двумерные прямоугольные таблицы данных, строки которой называются записями, а столбцы — полями. Межтабличная связь обеспечивает целостность данных.
Свойства алгоритма — Важнейшими свойствами алгоритма являются: дискретность, определенность (или точность), результативность (или конечность), возможность формализации.
Серия команд (операторов) — Совокупность нескольких команд, которые должны быть выполнены последовательно одна за другой.
Символы — Основные объекты документа, включающие в себя буквы, цифры, пробелы, знаки пунктуации, специальные символы (&, @, * и др.).
Система команд исполнителя — Совокупность команд, которые могут быть выполнены исполнителем.
Система управления базами данных (СУБД) — Программное обеспечение, предназначенное для работы с базами данных. СУБД имеет определенные режимы работы (обычно Конструктор, Таблицы, Формы) и систему команд, а также пользовательский интерфейс.
Сложное логическое выражение
— Выражение, содержащее логические операции.Сложный фильтр БД
— Фильтр, содержащий несколько условий отбора записей для различных полей конкретной таблицы.Смешанная ссылка (адресация) в формуле ЭТ — Служит для указания фиксированного (неизменяемого) компонента адреса ячейки ЭТ. Имеет следующий вид, например, $F1 (координата столбца абсолютная, а строки относительная), F$1 (координата строки абсолютная, а столбца относительная).
Создание таблицы — Операция задания числа столбцов и строк при помощи соответствующей команды или пиктограммы.
Сортировка БД — Это упорядочение записей в таблице по возрастанию или убыванию значений какого-нибудь поля (или по нескольким полям одновременно).
Сортировка данных в ЭТ — Упорядоточение данных по определенному признаку.
Специализированный формат ЭТ — Форматы типа: Денежный, Текстовый, Дата и время и другие, удобные для соответствующих расчетов.
Способы записи алгоритмов — Существуют следующие основные способы описания алгоритмов:
записаны на естественном языке, изображены в виде блок-схемы, записаны на алгоритмическом языке, закодированы на языке программирования (в соответствующем синтаксисе языка).Справка — это таблица, содержащая интересующие пользователя сведения, извлеченные из базы данных.
Существуют 6 вариантов отношений: “равно”, “не равно”, “больше”, “меньше”, “больше или равно”, “меньше или равно”. Отношения применимы ко всем типам полей.
Отношение
Таблица — Объект, состоящий из строк и столбцов, на пересечении которых образуются ячейки. С помощью таблиц можно форматировать документы, например, расположить абзацы текста в несколько рядов, совместить рисунок с текстовой надписью и др.
Таблица истинности — Таблица, иллюстрирующая правила выполнения трех логических операций над операндами А и Б, причем величина “истина” обозначается буквой И, “ложь” — буквой Л.
Таблицы БД хранятся в файлах на жестких магнитных дисках.
Текст в ЭТ
— Последовательность символов, состоящая из букв, цифр и пробелов, которая по умолчанию выравнивается в ячейке по левой стороне.Текстовый процессор — Текстовый редактор, имеющий расширенные возможности для создания документа, изменения его содержания формы представления.
Текстовый редактор — Программа для создания, редактирования, форматирования, сохранения и печати документа.
Тип поля БД — Определяет, какого вида информация храниться в поле и какие действия над ней можно производить.
Универсальный формат графического файла
– Формат, который может быть обработанбольшинством графических редакторов.
Универсальный формат текстовых файлов — Формат, используемый большинством текстовых редакторов, например, RTF.
Условия поиска в командах СУБД — это логические выражения.
Фактографическая БД — БД, содержащая краткие сведения об описываемых объектах, представленные в строго определенном формате
.Фильтр в ЭТ
— Заданные условия поиска данных (строк ) в электронных таблицах. Диалоговые панели Автофильтр, Последовательный автофильтр позволяют вводить условия поиска.Формальное исполнение алгоритма — Строгое (механическое) выполнение исполнителем некоторых правил, инструкций (команд алгоритма) независимо от содержания поставленной задачи.
Формат графического файла
— Определяет способ хранения информации в файле (растровый или векторный), а также форму хранения информации (используемый алгоритм сжатия).Форматирование
(документа) — Преобразование, изменяющее форму представления документа.Форматирование символов — Изменение основных свойств (внешнего вида) символа (шрифта, размера или начертания), а также дополнительных параметров (верхний и нижний индексы и др.).
Формула в ЭТ — Последовательность, начинающаяся со знака равенства и включающая в себя числа, имена ячеек, функции и знаки математических операций, исключая текст. В первую очередь выполняются операции в скобках, а при их отсутствии последовательность операций определяется их старшинством
Фрагмент (или блок) таблицы — Это любая ее прямоугольная часть (часть строки или часть столбца, или одна ячейка, с которыми можно производить операции манипулирования (удаление, вставка, перенос, сортировка). Расчеты с числовыми фрагментами таблиц — Используются статистические функции (суммирование, усреднение, нахождение наибольшего или наименьшего значения и др.).
х (чисел, текста, дат, логических значений) по возрастанию или убыванию в определенном порядке:
числа — от наименьшего отрицательного до наибольшего положительного числа; текст — числа, знаки, латинский алфавит, русский алфавит; логические значения — Лож, Истина; все ошибочные значения равны; пустые ячейки помещаются в конец списка.
Циклическая алгоритмическая конструкция — Многократное выполнение последовательности серии команд алгоритма (тело цикла). Различают циклы со счетчиком (тело цикла выполняется определенное число раз) и циклы по условию (тело цикла выполняется до тех пор, пока выполняется условие). Существует структура алгоритма: цикл с вложенным ветвлением.
Числа в ЭТ — Основной тип данных, записываемый в числовом или экспоненциальном формате, например, 199,1 или 1,991+02. По умолчанию числа выравниваются в ячейке по правому краю.
Числовой формат данных ЭТ — Отображает два десятичных знака после запятой, например, 199,10.
Шрифт — Полный набор символов определенного начертания, включая прописные и строчные буквы, знаки препинания, специальные символы, цифры, знаки арифметических действий. Каждый шрифт имеет свое название, например, Arial.
Шрифт векторный — Шрифт, символы которого описываются математическими формулами и допускают произвольное масштабирование. Наибольшее распространение получили шрифты типа True Type (TT).
Шрифт моноширинный —
Шрифт, символы которого имеют одинаковую ширину, например, шрифт Courier.Шрифт растровый — Шрифт, символы которого представляют собой группы пикселов. Эти шрифты допускают масштабирование только с определенными коэффициентами.
Шрифты рубленые —
Шрифт, символы которого обычно используются для заголовков, выделений в тексте и подписей к рисункам, например, Arial.Шрифты с засечками — Шрифты, символы которых имеют засечки, обеспечивающие лучшее восприятие, например, Times New Roman. Используются в большинстве печатных текстов.
Экпоненциальном формат данных ЭТ — Применяется для чисел, содержащих большое число разрядов, которые не умещаются в ячейке. DOC — Оригинальный формат используемой версии Word. Полностью сохраняет форматирование. Использует 16-битную кодировку Unicode.
Электронная таблица (ЭТ) — Работающая в диалоговом режиме программа обработки числовых данных, хранящаяся и обрабатывающая данные в прямоугольных таблицах, состоящих из столбцов и строк. В MS Office электронная таблица реализуется помощью приложения Excel.
Ячейка таблицы — Элементарный элемент таблицы, образуемый на пересечении ее строк и столбцов. В ячейках таблиц могут быть помещены различные данные (текст, числа, графика
Ячейка ЭТ — Место пересечения столбца и строки, имеющая свой адрес, состоящий из заголовка столбца и заголовка строки, например, F1, D7.
Назад
Расширенный фильтр и немного магии
У подавляющего большинства пользователей Excel при слове «фильтрация данных» в голове всплывает только обычный классический фильтр с вкладки Данные — Фильтр (Data — Filter):
Такой фильтр — штука привычная, спору нет, и для большинства случаев вполне сойдет. Однако бывают ситуации, когда нужно проводить отбор по большому количеству сложных условий сразу по нескольким столбцам. Обычный фильтр тут не очень удобен и хочется чего-то помощнее. Таким инструментом может стать расширенный фильтр (advanced filter), особенно с небольшой «доработкой напильником» (по традиции).
Основа
Для начала вставьте над вашей таблицей с данными несколько пустых строк и скопируйте туда шапку таблицы — это будет диапазон с условиями (выделен для наглядности желтым):
Между желтыми ячейками и исходной таблицей обязательно должна быть хотя бы одна пустая строка.
Именно в желтые ячейки нужно ввести критерии (условия), по которым потом будет произведена фильтрация. Например, если нужно отобрать бананы в московский «Ашан» в III квартале, то условия будут выглядеть так:
Чтобы выполнить фильтрацию выделите любую ячейку диапазона с исходными данными, откройте вкладку Данные и нажмите кнопку Дополнительно (Data — Advanced). В открывшемся окне должен быть уже автоматически введен диапазон с данными и нам останется только указать диапазон условий, т.е. A1:I2:
Обратите внимание, что диапазон условий нельзя выделять «с запасом», т.е. нельзя выделять лишние пустые желтые строки, т.к. пустая ячейка в диапазоне условий воспринимается Excel как отсутствие критерия, а целая пустая строка — как просьба вывести все данные без разбора.
Переключатель Скопировать результат в другое место позволит фильтровать список не прямо тут же, на этом листе (как обычным фильтром), а выгрузить отобранные строки в другой диапазон, который тогда нужно будет указать в поле Поместить результат в диапазон. В данном случае мы эту функцию не используем, оставляем Фильтровать список на месте и жмем ОК. Отобранные строки отобразятся на листе:
Добавляем макрос
«Ну и где же тут удобство?» — спросите вы и будете правы. Мало того, что нужно руками вводить условия в желтые ячейки, так еще и открывать диалоговое окно, вводить туда диапазоны, жать ОК. Грустно, согласен! Но «все меняется, когда приходят они ©» — макросы!
Работу с расширенным фильтром можно в разы ускорить и упростить с помощью простого макроса, который будет автоматически запускать расширенный фильтр при вводе условий, т.е. изменении любой желтой ячейки. Щелкните правой кнопкой мыши по ярлычку текущего листа и выберите команду Исходный текст (Source Code). В открывшееся окно скопируйте и вставьте вот такой код:
Private Sub Worksheet_Change(ByVal Target As Range)
If Not Intersect(Target, Range("A2:I5")) Is Nothing Then
On Error Resume Next
ActiveSheet.ShowAllData
Range("A7").CurrentRegion.AdvancedFilter Action:=xlFilterInPlace, CriteriaRange:=Range("A1").CurrentRegion
End If
End Sub
Эта процедура будет автоматически запускаться при изменении любой ячейки на текущем листе. Если адрес измененной ячейки попадает в желтый диапазон (A2:I5), то данный макрос снимает все фильтры (если они были) и заново применяет расширенный фильтр к таблице исходных данных, начинающейся с А7, т.е. все будет фильтроваться мгновенно, сразу после ввода очередного условия:
Так все гораздо лучше, правда? 🙂
Реализация сложных запросов
Теперь, когда все фильтруется «на лету», можно немного углубиться в нюансы и разобрать механизмы более сложных запросов в расширенном фильтре. Помимо ввода точных совпадений, в диапазоне условий можно использовать различные символы подстановки (* и ?) и знаки математических неравенств для реализации приблизительного поиска. Регистр символов роли не играет. Для наглядности я свел все возможные варианты в таблицу:
| Критерий | Результат |
| гр* или гр | все ячейки начинающиеся с Гр, т.е. Груша, Грейпфрут, Гранат и т.д. |
| =лук | все ячейки именно и только со словом Лук, т.е. точное совпадение |
| *лив* или *лив | ячейки содержащие лив как подстроку, т.е. Оливки, Ливер, Залив и т.д. |
| =п*в | слова начинающиеся с П и заканчивающиеся на В т.е. Павлов, Петров и т.д. |
| а*с | слова начинающиеся с А и содержащие далее С, т.е. Апельсин, Ананас, Асаи и т.д. |
| =*с | слова оканчивающиеся на С |
| =???? | все ячейки с текстом из 4 символов (букв или цифр, включая пробелы) |
| =м??????н | все ячейки с текстом из 8 символов, начинающиеся на М и заканчивающиеся на Н, т.е. Мандарин, Мангостин и т.д. |
| =*н??а | все слова оканчивающиеся на А, где 4-я с конца буква Н, т.е. Брусника, Заноза и т.д. |
| >=э | все слова, начинающиеся с Э, Ю или Я |
| <>*о* | все слова, не содержащие букву О |
| <>*вич | все слова, кроме заканчивающихся на вич (например, фильтр женщин по отчеству) |
| = | все пустые ячейки |
| <> | все непустые ячейки |
| >=5000 | все ячейки со значением больше или равно 5000 |
| 5 или =5 | все ячейки со значением 5 |
| >=3/18/2013 | все ячейки с датой позже 18 марта 2013 (включительно) |
Тонкие моменты:
- Знак * подразумевает под собой любое количество любых символов, а ? — один любой символ.
- Логика в обработке текстовых и числовых запросов немного разная. Так, например, ячейка условия с числом 5 не означает поиск всех чисел, начинающихся с пяти, но ячейка условия с буквой Б равносильна Б*, т.е. будет искать любой текст, начинающийся с буквы Б.
- Если текстовый запрос не начинается со знака =, то в конце можно мысленно ставить *.
- Даты надо вводить в штатовском формате месяц-день-год и через дробь (даже если у вас русский Excel и региональные настройки).
Логические связки И-ИЛИ
Условия записанные в разных ячейках, но в одной строке — считаются связанными между собой логическим оператором И (AND):
Т.е. фильтруй мне бананы именно в третьем квартале, именно по Москве и при этом из «Ашана».
Если нужно связать условия логическим оператором ИЛИ (OR), то их надо просто вводить в разные строки. Например, если нам нужно найти все заказы менеджера Волиной по московским персикам и все заказы по луку в третьем квартале по Самаре, то это можно задать в диапазоне условий следующим образом:
Если же нужно наложить два или более условий на один столбец, то можно просто продублировать заголовок столбца в диапазоне критериев и вписать под него второе, третье и т.д. условия. Вот так, например, можно отобрать все сделки с марта по май:
В общем и целом, после «доработки напильником» из расширенного фильтра выходит вполне себе приличный инструмент, местами не хуже классического автофильтра.
Ссылки по теме
Expression Engine — возможно ли, чтобы тег exp:channel:entries имел сложные фильтры?
Исходя из Codeigniter и нового для Expression Engine, я не знаю, как делать сложные фильтры на теге exp:channel:entries.
Меня интересуют эти фильтры
status
start_on
stop_before
Как вы реализуете фильтры для такого сложного состояния, как это?
(status=X|Y|Z AND start_on=A AND stop_before=B) OR (status=X AND start_on=C AND stop_before=D)
Возможно ли это вообще?
expressionengineПоделиться Источник developarvin 04 октября 2012 в 03:59
3 ответа
1
К сожалению, вы можете использовать параметр search= только для поиска в полях “Ввод текста”, “Textarea” и “Раскрывающиеся списки”. Поэтому для этого вам нужно будет использовать модуль запроса.
Если вы просто запрашиваете эти параметры, вы должны быть в состоянии получить необходимые идентификаторы записей из таблицы exp_channel_titles , а затем использовать что-то вроде плагина Stash для подачи результатов entry_id в тег записей обычного канала. Да, номинально это еще один запрос, но поскольку EE довольно сильно абстрагирует схему бд, альтернативой является заблудиться в беспорядке JOIN с.
Так что что-то вроде (псевдокод, не будет работать как есть):
Получите записи, статусы — это просто строка в exp_channel_titles, entry_date -это столбец даты, который вы хотите, который хранится как unix timestamp, поэтому вам нужно будет выбрать его с чем-то вроде DATE( FROM_UNIXTIME(entry_date)) в зависимости от формата ваших данных фильтра.
{exp:stash:set name="filtered_ids"}{exp:query sql="SELECT entry_id
FROM exp_channel_titles
WHERE status LIKE ...<your filter here>"
backspace="1"
}{entry_id}|{/exp:query}{/exp:stash:set}
Позже в шаблоне:
{exp:channel:entries
entry_id="{exp:stash:get name="filtered_ids"}"
}
{!--loop --}
{/exp:channel:entries}
Да, это беспорядок по сравнению с тем, к чему вы, вероятно, привыкли в чистом CI, но компромисс-это все, что вы получаете бесплатно от EE (CP, шаблоны, управление членами и т. Д.).
Кстати, заначка потрясающая — ее можно использовать для массового смягчения большинства проблем с производительностью EE/обойти проблемы с порядком разбора
Поделиться Tom Davies 05 октября 2012 в 09:59
0
Вы можете получить большую часть этой функциональности, используя параметр search= в цикле {exp:channel:entries...} .
Мне не сразу понятно, как вы получите искомую сложность, поэтому вы можете в конечном итоге прибегнуть к query module .
Поделиться Scott Hepler 04 октября 2012 в 11:22
0
Если вы работаете с датами, вам может пригодиться плагин DT.
Поделиться Tyssen 23 октября 2012 в 23:33
Похожие вопросы:
Интеграция Eventbrite с Expression Engine
Кто-нибудь делал интеграцию Eventbrite с сайтом Expression Engine? Мы хотели бы организовать мероприятия с помощью Eventbrite и поручить им все управление билетами. Но мы хотели бы иметь возможность…
как создать внутренние ссылки в expression engine?
У меня есть список записей, и я пытаюсь создать вверху список заголовков, на которые можно нажать, чтобы страница прокрутилась к телу. Следующее не работает, потому что, когда я использую entry_id,…
Бесплатный способ сделать разработку Expression Engine 2?
Я собираюсь заняться разработкой движка Expression Engine, но похоже, что с Expression Engine 2.x больше нет бесплатной базовой версии для загрузки. Это для одного клиента, так как обычно я не…
Возможно ли, чтобы каждый combobox в сетке имел другой itemsource?
У меня есть приложение WPF, которое имеет datagrid. Одна из колонок в datagrid имеет combobox. Я хочу, чтобы каждый экземпляр combobox имел свой собственный itemsource. Возможно ли это?
Использовать встраиваемые переменные в тег канала Expression Engine?
Я создаю веб-сайт, который активно использует карусели изображений. В каждой секции есть своя карусель с разными горками. Поэтому я создал встраивание под названием global_embeds/image_carousel.html…
Cron заданий с Expression Engine 2?
Я разрабатываю сайт Expression Engine. На сайте есть таблица базы данных, заполненная из внешнего канала, и этот канал необходимо анализировать дважды в день. Очевидно, что работа cron кажется…
jQuery UI вкладки не работают на веб-сайте expression engine
я пытался заставить jquery ui работать в области, в которой я хотел бы иметь вкладки, и пытался в течение последних нескольких дней, но безуспешно! Идея состоит в том, чтобы отображать или не…
Inline jQuery/AJAX не работает в Expression Engine
У меня есть несколько встроенных jQuery для загрузки комментариев Disqus по запросу для моего шаблона Expression Engine, но по какой-то странной причине у меня возникли проблемы с тем, чтобы…
Expression Engine — показать запись по умолчанию, если url_title отсутствует в url
{exp:channel:entries dynamic=yes limit=1} // some code {/exp:channel:entries} Dynamic имеет значение on, так что он будет отображать запись, url_title которой присутствует в качестве последнего…
Содержимое канала Expression Engine не отображается
Я новичок в expression engine. У меня есть канал под названием news, и я опубликовал несколько страниц. В моем шаблоне я использовал код как {exp:channel:entries channel=news}…
Выполнение запросов — Документация Django 3.0
После создания модели, Django автоматически создает API для работы с базой данных, который позволяет вам создавать, получать, изменять и удалять объекты. Этот раздел расскажет вам как использовать этот API. В описании моделей вы можете найти список всех существующих опций поиска.
В этом разделе(и последующих) мы будем использовать такие модели:
Создание объектов
Для представления данных таблицы в виде объектов Python, Django использует интуитивно понятную систему: класс модели представляет таблицу, а экземпляр модели — запись в этой таблице.
Чтобы создать объект, создайте экземпляр класса модели, указав необходимые поля в аргументах и вызовите метод save() чтобы сохранить его в базе данных.
Предположим, что модель находится в mysite/blog/models.py:
>>> from blog.models import Blog >>> b = Blog(name='Beatles Blog', tagline='All the latest Beatles news.') >>> b.save()
В результате выполнения этого кода будет создан INSERT SQL-запрос. Django не выполняет запросов к базе данных, пока не будет вызван метод save().
Метод save() ничего не возвращает.
См.также
save() принимает ряд аргументов, не описанных в этом разделе. Смотрите документацию о методе save() для подробностей.
Чтобы создать и сохранить объект используйте метод create().
Сохранение изменений в объектах
Для сохранения изменений в объект, который уже существует в базе данных, используйте save().
В данном примере изменяется название объекта b5 модели Blog и обновляется запись в базе данных:
>>> b5.name = 'New name' >>> b5.save()
В результате выполнения этого кода будет создан UPDATE SQL запрос. Django не выполняет каких либо запросов к базе данных, пока не будет вызван метод save().
Сохранение полей
ForeignKey и ManyToManyField
Updating a ForeignKey field works exactly the same
way as saving a normal field – assign an object of the right type to the field
in question. This example updates the blog attribute of an Entry
instance entry, assuming appropriate instances of Entry and Blog
are already saved to the database (so we can retrieve them below):
>>> from blog.models import Blog, Entry >>> entry = Entry.objects.get(pk=1) >>> cheese_blog = Blog.objects.get(name="Cheddar Talk") >>> entry.blog = cheese_blog >>> entry.save()
Обновление ManyToManyField работает немного по-другому; используйте метод add() поля, чтобы добавить связанный объект. В этом примере объект joe модели Author добавляется к объекту entry:
>>> from blog.models import Author >>> joe = Author.objects.create(name="Joe") >>> entry.authors.add(joe)
Для добавления сразу нескольких объектов в ManyToManyField, добавьте несколько аргументов в метод add(). Например:
>>> john = Author.objects.create(name="John") >>> paul = Author.objects.create(name="Paul") >>> george = Author.objects.create(name="George") >>> ringo = Author.objects.create(name="Ringo") >>> entry.authors.add(john, paul, george, ringo)
Django вызовет исключение, если вы попытаетесь добавить объект неверного типа.
Получение объектов
Для получения объектов из базы данных, создается QuerySet через Manager модели.
QuerySet представляет выборку объектов из базы данных. Он может не содержать, или содержать один или несколько фильтров – критерии для ограничения выборки по определенным параметрам. В терминах SQL, QuerySet — это оператор SELECT, а фильтры — условия такие, как WHERE или LIMIT.
Вы получаете QuerySet, используя Manager. Каждая модель содержит как минимум один Manager, и он называется objects по умолчанию. Обратиться к нему можно непосредственно через класс модели:
>>> Blog.objects
<django.db.models.manager.Manager object at ...>
>>> b = Blog(name='Foo', tagline='Bar')
>>> b.objects
Traceback:
...
AttributeError: "Manager isn't accessible via Blog instances."
Примечание
Обратиться к менеджерам можно только через модель и нельзя через ее экземпляр. Это сделано для разделения «table-level» операций и «record-level» операций.
Manager — главный источник QuerySet для модели. Например, Blog.objects.all() вернет QuerySet, который содержит все объекты Blog из базы данных.
Получение всех объектов
Самый простой способ получить объекты из таблицы — это получить их всех. Для этого используйте метод all() менеджера(Manager):
>>> all_entries = Entry.objects.all()
Метод all() возвращает QuerySet всех объектов в базе данных.
Получение объектов через фильтры
QuerySet, возвращенный Manager, описывает все объекты в таблице базы данных. Обычно вам нужно выбрать только подмножество всех объектов.
Для создания такого подмножества, вы можете изменить QuerySet, добавив условия фильтрации. Два самых простых метода изменить QuerySet — это:
filter(**kwargs)- Возвращает новый
QuerySet, который содержит объекты удовлетворяющие параметрам фильтрации. exclude(**kwargs)- Возвращает новый
QuerySetсодержащий объекты, которые не удовлетворяют параметрам фильтрации.
Параметры фильтрации (**kwargs в определении функций выше) должны быть в формате описанном в разделе Field lookups.
Например, для создания QuerySet чтобы получить записи с 2006, используйте filter() таким образом:
Entry.objects.filter(pub_date__year=2006)
Это аналогично:
Entry.objects.all().filter(pub_date__year=2006)
Цепочка фильтров
Результат изменения QuerySet — это новый QuerySet и можно использовать цепочки фильтров. Например:
>>> Entry.objects.filter( ... headline__startswith='What' ... ).exclude( ... pub_date__gte=datetime.date.today() ... ).filter( ... pub_date__gte=datetime.date(2005, 1, 30) ... )
В этом примере к начальному QuerySet, который возвращает все объекты, добавляется фильтр, затем исключающий фильтр, и еще один фильтр. Полученный QuerySet содержит все объекты, у которых заголовок начинается с «What», и которые были опубликованы между 30-го января 2005 и текущей датой.
Filtered
QuerySets are unique
После каждого изменения QuerySet, вы получаете новый QuerySet, который никак не связан с предыдущим QuerySet. Каждый раз создается отдельный QuerySet, который может быть сохранен и использован.
Например:
>>> q1 = Entry.objects.filter(headline__startswith="What") >>> q2 = q1.exclude(pub_date__gte=datetime.date.today()) >>> q3 = q1.filter(pub_date__gte=datetime.date.today())
Эти три QuerySets независимы. Первый – это базовый QuerySet, который содержит все объекты с заголовками, которые начинаются с «What». Второй – это множество первых с дополнительным критерием фильтрации, который исключает объекты с pub_date больше, чем текущая дата. Третий – это множество первого, с отфильтрованными объектами, у которых pub_date больше, чем текущая дата. Первоначальный QuerySet (q1) не изменяется последующим добавлением фильтров.
QuerySets are lazy
QuerySets – ленивы, создание QuerySet не выполняет запросов к базе данных. Вы можете добавлять фильтры хоть весь день и Django не выполнит ни один запрос, пока QuerySet не вычислен. Разберем такой пример:
>>> q = Entry.objects.filter(headline__startswith="What") >>> q = q.filter(pub_date__lte=datetime.date.today()) >>> q = q.exclude(body_text__icontains="food") >>> print(q)
Глядя на это можно подумать что было выполнено три запроса в базу данных. На самом деле был выполнен один запрос, в последней строке (print(q)). Результат QuerySet не будет получен из базы данных, пока вы не «попросите» об этом. Когда вы делаете это, QuerySet вычисляется запросом к базе данных. Для подробностей, в какой момент выполняется запрос, смотрите When QuerySets are evaluated.
Retrieving a single object with
get()
filter() всегда возвращает QuerySet, даже если только один объект возвращен запросом — в этом случае, это будет QuerySet содержащий один объект.
Если вы знаете, что только один объект возвращается запросом, вы можете использовать метод get() менеджера(Manager), который возвращает непосредственно объект:
>>> one_entry = Entry.objects.get(pk=1)
Вы можете использовать для get() аргументы, такие же, как и для filter() — смотрите Field lookups далее.
Учтите, что есть разница между использованием get() и filter() с [0]. Если результат пустой, get() вызовет исключение DoesNotExist. Это исключение является атрибутом модели, для которой выполняется запрос. Если в примере выше не существует объекта Entry с первичным ключом равным 1, Django вызовет исключение Entry.DoesNotExist.
Также Django отреагирует, если запрос get() вернет не один объект. В этом случае будет вызвано исключение MultipleObjectsReturned, которое также является атрибутом класса модели.
Other
QuerySet methods
В большинстве случаев вы будете использовать all(), get(), filter() и exclude() для получения объектов из базы данных. Однако это не все доступные возможности; смотрите документацию о QuerySet API для получения информации о всех существующих методах QuerySet.
Limiting
QuerySets
Используйте синтаксис срезов для списков Python для ограничения результата выборки QuerySet. Это эквивалент таких операторов SQL как LIMIT и OFFSET.
Например, этот код возвращает 5 первых объектов (LIMIT 5):
>>> Entry.objects.all()[:5]
Этот возвращает с шестого по десятый (OFFSET 5 LIMIT 5):
>>> Entry.objects.all()[5:10]
Отрицательные индексы (например, Entry.objects.all()[-1]) не поддерживаются.
На самом деле, срез QuerySet возвращает новый QuerySet – запрос не выполняется. Исключением является использовании «шага» в срезе. Например, этот пример выполнил бы запрос, возвращающий каждый второй объект из первых 10:
>>> Entry.objects.all()[:10:2]
Further filtering or ordering of a sliced queryset is prohibited due to the ambiguous nature of how that might work.
To retrieve a single object rather than a list
(e.g. SELECT foo FROM bar LIMIT 1), use an index instead of a slice. For
example, this returns the first Entry in the database, after ordering
entries alphabetically by headline:
>>> Entry.objects.order_by('headline')[0]
Это эквивалент:
>>> Entry.objects.order_by('headline')[0:1].get()
Заметим, что первый пример вызовет IndexError, в то время как второй — DoesNotExist, если запрос не вернёт ни одного объекта. Смотрите get() для подробностей.
Фильтры полей
Фильтры полей – это «операторы» для составления условий SQL WHERE. Они задаются как именованные аргументы для метода filter(), exclude() и get() в QuerySet.
Фильтры полей выглядят как field__lookuptype=value. (Используется двойное подчеркивание). Например:
>>> Entry.objects.filter(pub_date__lte='2006-01-01')
будет транслировано в SQL:
SELECT * FROM blog_entry WHERE pub_date <= '2006-01-01';
Как это работает
Python has the ability to define functions that accept arbitrary name-value arguments whose names and values are evaluated at runtime. For more information, see Keyword Arguments in the official Python tutorial.
Поля указанные при фильтрации должны быть полями модели. Есть одно исключение, для поля ForeignKey можно указать поле с суффиксом _id. В этом случае необходимо передать значение первичного ключа связанной модели. Например:
>>> Entry.objects.filter(blog_id=4)
При передаче неверного именованного аргумента, будет вызвано исключение TypeError.
API базы данных поддерживает около двух дюжин фильтров; полный список можно найти в разделе о фильтрах полей. Вот пример самых используемых фильтров:
exact«Точное» совпадение. Например:
>>> Entry.objects.get(headline__exact="Cat bites dog")
Создаст такой SQL запрос:
SELECT ... WHERE headline = 'Cat bites dog';
Если вы не указали фильтр – именованный аргумент не содержит двойное подчеркивание – будет использован фильтр
exact.Например, эти два выражения идентичны:
>>> Blog.objects.get(id__exact=14) # Explicit form >>> Blog.objects.get(id=14) # __exact is implied
Это сделано для удобства, т.к.
exactсамый распространенный фильтр.iexactРегистронезависимое совпадение. Такой запрос:
>>> Blog.objects.get(name__iexact="beatles blog")
Найдет
Blogс названием"Beatles Blog","beatles blog", и даже"BeAtlES blOG".containsРегистрозависимая проверка на вхождение. Например:
Entry.objects.get(headline__contains='Lennon')
Будет конвертировано в такой SQL запрос:
SELECT ... WHERE headline LIKE '%Lennon%';
Заметим, что этот пример найдет заголовок
'Today Lennon honored', но не найдет'today lennon honored'.Существуют также регистронезависимые версии,
icontains.startswith,endswith- Поиск по началу и окончанию соответственно. Существуют также регистронезависимые версии
istartswithиiendswith.
Это только основные фильтры. Полный список ищите в разделе о фильтрах по полям.
Фильтры по связанным объектам
Django offers a powerful and intuitive way to «follow» relationships in
lookups, taking care of the SQL JOINs for you automatically, behind the
scenes. To span a relationship, use the field name of related fields
across models, separated by double underscores, until you get to the field you
want.
Этот пример получает все объекты Entry с Blog, name которого равен 'Beatles Blog':
>>> Entry.objects.filter(blog__name='Beatles Blog')
Этот поиск может быть столь глубоким, как вам будет угодно.
It works backwards, too. To refer to a «reverse» relationship, use the lowercase name of the model.
Этот пример получает все объекты Blog, которые имеют хотя бы один связанный объект Entry с headline содержащим 'Lennon':
>>> Blog.objects.filter(entry__headline__contains='Lennon')
Если вы используйте фильтр через несколько связей и одна из промежуточных моделей не содержит подходящей связи, Django расценит это как пустое значение (все значения равны NULL). Исключение не будет вызвано. Например, в этом фильтре:
Blog.objects.filter(entry__authors__name='Lennon')
(при связанной модели Author), если нет объекта author связанного с entry, это будет расценено как отсутствие name, вместо вызова исключения т.к. author отсутствует. В большинстве случаев это то, что вам нужно. Единственный случай, когда это может работать не однозначно — при использовании isnull. Например:
Blog.objects.filter(entry__authors__name__isnull=True)
вернет объекты Blog у которого пустое поле name у author и также объекты, у которых пустой author``в ``entry. Если вы не хотите включать вторые объекты, используйте:
Blog.objects.filter(entry__authors__isnull=False, entry__authors__name__isnull=True)
Фильтрация по связям многие-ко-многим
Когда вы используете фильтрацию по связанным через ManyToManyField объектам или по обратной связи для ForeignKey, может быть два вида фильтров. Рассмотрим связь Blog/Entry (от Blog к Entry – это связь один-ко-многим). Нам может понадобиться получить блоги с записями, у которых заголовок содержит «Lennon» и которые были опубликованы в 2008. Или нам могут понадобиться блоги с записями с «Lennon» в заголовке и в то же время блоги с записями опубликованными до 2008. Т.к. один Blog может иметь несколько связанных Entry, оба варианта возможны.
Аналогичная ситуация и с ManyToManyField. Например, если Entry имеет ManyToManyField названное tags, нам могут понадобиться записи связанные с тегами «music» и «bands» или нам может понадобиться запись содержащая тег «music» и статусом «public».
Чтобы обеспечить оба варианта, Django использует определенные правила для вызовов filter(). Все, что в одном вызове filter(), применяется одновременно, чтобы отфильтровать все объекты, соответствующие этим параметрам фильтрации. Успешные вызовы filter() каждый раз сокращают выборку объектов, но для множественных связей, они применяются каждый раз ко всем связанным объектам, а не только к объектам отфильтрованным предыдущим вызовом filter().
Звучит немного непонятно, но пример должен все прояснить. Для выбора всех блогов, содержащих записи и с «Lennon» в заголовке и опубликованные в 2008 (запись должна удовлетворять оба условия), мы будем использовать такой код:
Blog.objects.filter(entry__headline__contains='Lennon', entry__pub_date__year=2008)
Для выбора блогов с записями, у которых заголовок содержит «Lennon», а также с записями опубликованными в 2008, мы напишем:
Blog.objects.filter(entry__headline__contains='Lennon').filter(entry__pub_date__year=2008)
Предположим, существует только один блог, и в нем есть записи со словом «Lennon» и записи 2008-го года, но ни одна запись 2008-го не содержит слово «Lennon». Первый запрос вернет пустой ответ, второй запрос — один блог.
В этом примере, первый фильтр ограничит выборку блогами со связанными записями содержащими «Lennon» в заголовке. Второй фильтр далее ограничит выборку блогами с записями, опубликованными в 2008. Записи выбранные вторым фильтром могут быть такими же, как и из первого фильтра, а могут и не быть. Мы фильтруем объекты Blog с каждым вызовом filter(), а не объекты Entry.
Примечание
Поведение exclude() при запросе, который использует множественную связь, отличается от аналогичных запросов с filter(), поведение которых описано выше. Несколько условий в одном вызове exclude() не обязательно будут применяться к одной записи.
Например, следующий запрос исключит блоги, с записями, у которых заголовок содержит «Lennon», а также с записями опубликованными в 2008:
Blog.objects.exclude(
entry__headline__contains='Lennon',
entry__pub_date__year=2008,
)
Однако, в отличии от filter(), этот запрос не отфильтрует блоги по записям, которые удовлетворяют двум условиям. Для того, чтобы выбрать все блоги, которые не содержат записи с «Lennon» и опубликованные в 2008, необходимо сделать два запроса:
Blog.objects.exclude(
entry__in=Entry.objects.filter(
headline__contains='Lennon',
pub_date__year=2008,
),
)
Фильтры могут ссылаться на поля модели
В примерах выше мы использовали фильтры, которые сравнивали поля с определенными значениями(константами). Но что, если вы хотите сравнить одно поле с другим полем одной модели?
Django предоставляет класс F для таких сравнений. Экземпляр F() рассматривается как ссылка на другое поле модели. Эти ссылки могут быть использованы для сравнения значений двух разных полей одного объекта модели.
Например, чтобы выбрать все записи, у которых количество комментариев больше, чем «pingback», мы создаем объект F() с ссылкой на поле «pingback», и используем этот объект F() в запросе:
>>> from django.db.models import F
>>> Entry.objects.filter(number_of_comments__gt=F('number_of_pingbacks'))
Django поддерживает операции суммирования, вычитания, умножения, деления и арифметический модуль для объектов F(), с константами или другими объектами F(). Чтобы найти все записи с количеством комментариев в два раза больше чем «pingbacks», используем такой запрос:
>>> Entry.objects.filter(number_of_comments__gt=F('number_of_pingbacks') * 2)
Чтобы найти все записи с рейтингом ниже суммы «pingback» и количества комментариев, необходимо выполнить такой запрос:
>>> Entry.objects.filter(rating__lt=F('number_of_comments') + F('number_of_pingbacks'))
Вы можете использовать два нижних подчеркивания для использования полей связанных объектов в F(). Объект F() с двойным нижним подчеркиванием обеспечит все необходимые JOIN для получения необходимых связанных объектов. Например, чтобы получить все записи, у которых имя автора совпадает с названием блога, нужно выполнить такой запрос:
>>> Entry.objects.filter(authors__name=F('blog__name'))
Для полей даты и времени вы можете использовать сумму или разницу объектов timedelta. Этот код вернет все записи, которые были отредактированы через 3 дня после публикации:
>>> from datetime import timedelta
>>> Entry.objects.filter(mod_date__gt=F('pub_date') + timedelta(days=3))
The F() objects support bitwise operations by .bitand(), .bitor(),
.bitrightshift(), and .bitleftshift(). For example:
>>> F('somefield').bitand(16)
The
pk lookup shortcut
Для удобства, Django предоставляет специальный фильтр pk для работы с первичным ключом.
Например, первичный ключ модели Blog – поле id. Эти три запроса идентичны:
>>> Blog.objects.get(id__exact=14) # Explicit form >>> Blog.objects.get(id=14) # __exact is implied >>> Blog.objects.get(pk=14) # pk implies id__exact
Использование pk не ограничено только фильтром __exact – любой фильтр может быть использован с pk:
# Get blogs entries with id 1, 4 and 7 >>> Blog.objects.filter(pk__in=[1,4,7]) # Get all blog entries with id > 14 >>> Blog.objects.filter(pk__gt=14)
pk работает также и для связей. Например, эти три запроса идентичны:
>>> Entry.objects.filter(blog__id__exact=3) # Explicit form >>> Entry.objects.filter(blog__id=3) # __exact is implied >>> Entry.objects.filter(blog__pk=3) # __pk implies __id__exact
Escaping percent signs and underscores in
LIKE statements
Фильтры, эквивалентные оператору LIKE в SQL(iexact, contains, icontains, startswith, istartswith, endswith и iendswith), автоматически экранируют два символа, используемых оператором LIKE – знак процента и нижнего подчеркивания. (В операторе LIKE, знак процента означает «wildcard» из нескольких символов, нижнего подчеркивания — односимвольный «wildcard».)
This means things should work intuitively, so the abstraction doesn’t leak. For example, to retrieve all the entries that contain a percent sign, use the percent sign as any other character:
>>> Entry.objects.filter(headline__contains='%')
Django самостоятельно позаботится об экранировании; полученный SQL будет выглядеть приблизительно вот так:
SELECT ... WHERE headline LIKE '%\%%';
Также работает и символ нижнего подчеркивания. Оба, знак процента и нижнего подчеркивания, обрабатываются автоматически, прозрачно для вас.
Caching and
QuerySets
Каждый QuerySet содержит кэш, для уменьшения количества запросов. Очень важно знать как он работает для эффективного использования Django.
В только что созданном QuerySet кеш пустой. После вычисления QuerySet и будет выполнен запрос к базе данных – Django сохраняет результат запроса в кеше QuerySet и возвращает необходимый результат (например, следующий элемент при итерации по QuerySet). Последующие вычисления QuerySet используют кеш.
Помните о кэшировании, чтобы использовать QuerySet правильно. Например, этот код создаст два экземпляра QuerySet и вычислит их не сохраняя:
>>> print([e.headline for e in Entry.objects.all()]) >>> print([e.pub_date for e in Entry.objects.all()])
Это означает, что один и тот же запрос будет выполнен дважды, удваивая нагрузку на базу данных. Также, есть вероятность, что списки могут содержать разные результаты, потому что запись Entry может быть добавлена или удалена в доли секунды между запросами.
To avoid this problem, save the QuerySet and
reuse it:
>>> queryset = Entry.objects.all() >>> print([p.headline for p in queryset]) # Evaluate the query set. >>> print([p.pub_date for p in queryset]) # Re-use the cache from the evaluation.
When
QuerySets are not cached
Queryset не всегда кэширует результаты. При выполнении только части queryset-а, кэш проверяется, но если кэш пустой, выполняется запрос без сохранения его результата в кэш. Это значит, что ограничение выборки, используя индекс или срез, как при использовании списков, не заполнит кэш.
Например, при получении объекта по индексу несколько раз будет каждый раз выполнять запрос к базе данных:
>>> queryset = Entry.objects.all() >>> print(queryset[5]) # Queries the database >>> print(queryset[5]) # Queries the database again
Однако, если уже был загружен весь queryset, он будет использоваться для получения значения:
>>> queryset = Entry.objects.all() >>> [entry for entry in queryset] # Queries the database >>> print(queryset[5]) # Uses cache >>> print(queryset[5]) # Uses cache
Еще несколько примеров, когда загружается весь queryset и результат сохраняется в кэше:
>>> [entry for entry in queryset] >>> bool(queryset) >>> entry in queryset >>> list(queryset)
Примечание
Использование print с queryset не заполнит кэш т.к. будет вызван __repr__(), который показывает только часть объектов.
Complex lookups with
Q objects
Именованные аргументы функции filter() и др. – объединяются оператором «AND». Если вам нужны более сложные запросы (например, запросы с оператором OR), вы можете использовать объекты Q.
Объект Q (django.db.models.Q) – объект, используемый для инкапсуляции множества именованных аргументов для фильтрации. Аргументы определяются так же, как и в примерах выше.
Например, этот объект Q определяет запрос LIKE:
from django.db.models import Q Q(question__startswith='What')
Объекты Q могут быть объединены операторами & и |, при этом будет создан новый объект Q.
Например, это определение представляет объект Q, который представляет операцию «OR» двух фильтров с "question__startswith":
Q(question__startswith='Who') | Q(question__startswith='What')
Этот фильтр равнозначен такому оператору SQL WHERE:
WHERE question LIKE 'Who%' OR question LIKE 'What%'
Вы можете комбинировать различные объекты Q с операторами & и | и использовать скобки. Можно использовать оператор ~ для отрицания(NOT) в запросе:
Q(question__startswith='Who') | ~Q(pub_date__year=2005)
Каждый метод для фильтрации, который принимает именованные аргументы (например, filter(), exclude(), get()get()) также может принимать объекты Q. Если вы передадите несколько объектов Q как аргументы, они будут объединены оператором «AND». Например:
Poll.objects.get(
Q(question__startswith='Who'),
Q(pub_date=date(2005, 5, 2)) | Q(pub_date=date(2005, 5, 6))
)
… roughly translates into the SQL:
SELECT * from polls WHERE question LIKE 'Who%'
AND (pub_date = '2005-05-02' OR pub_date = '2005-05-06')
Вы можете использовать одновременно объекты Q и именованные аргументы. Все аргументы(будь то именованные аргументы или объекты Q) объединяются оператором «AND». Однако, если присутствует объект Q, он должен следовать перед именованными аргументами. Например:
Poll.objects.get(
Q(pub_date=date(2005, 5, 2)) | Q(pub_date=date(2005, 5, 6)),
question__startswith='Who',
)
… правильный запрос, идентичный предыдущему примеру; но:
# INVALID QUERY
Poll.objects.get(
question__startswith='Who',
Q(pub_date=date(2005, 5, 2)) | Q(pub_date=date(2005, 5, 6))
)
… будет неправильный`(Вообще Django здесь не причем. Синтаксис Python не позволяет передавать именованные аргументы перед позиционными – прим. переводчика)`.
Удаление объектов
Метод удаления соответственно называется delete(). Этот метод сразу удаляет объект и возвращает количество удаленных объектов, и словарь с количеством удаленных объектов для каждого типа. Например:
>>> e.delete()
(1, {'weblog.Entry': 1})
Можно также удалить несколько объектов сразу. Каждый QuerySet имеет метод delete(), который удаляет все объекты из QuerySet.
Например, этот код удаляет все объекты Entry с годом pub_date равным 2005:
>>> Entry.objects.filter(pub_date__year=2005).delete()
(5, {'webapp.Entry': 5})
Учтите, что при любой возможности будет использован непосредственно SQL запрос, то есть метод delete() объекта может и не использоваться при удалении. Если вы переопределяете метод delete() модели и хотите быть уверенным, что он будет вызван, вы должны «самостоятельно» удалить объект модели (например, использовать цикл по QuerySet и вызывать метод delete() для каждого объекта) не используя метод delete() QuerySet.
При удалении Django повторяет поведение SQL выражения ON DELETE CASCADE – другими словами, каждый объект, имеющий связь(ForeignKey) с удаляемым объектом, будет также удален. Например:
b = Blog.objects.get(pk=1) # This will delete the Blog and all of its Entry objects. b.delete()
Это поведение можно изменить, определив аргумент on_delete поля ForeignKey.
Метод delete() содержится только в QuerySet и не существует в Manager. Это сделано, чтобы вы случайно не выполнили Entry.objects.delete(), и не удалили все записи. Если вы на самом деле хотите удалить все объекты, сначала явно получите QuerySet, содержащий все записи:
Entry.objects.all().delete()
Изменение нескольких объектов
Если вам понадобиться установить значение поля для всех объектов в QuerySet, используйте метод update(). Например:
# Update all the headlines with pub_date in 2007. Entry.objects.filter(pub_date__year=2007).update(headline='Everything is the same')
Вы можете изменить только обычные поля или ForeignKey, используя этот метод. Для обычных полей просто определите новое значение как константу. Чтобы обновить ForeignKey, укажите объект связанной модели. Например:
>>> b = Blog.objects.get(pk=1) # Change every Entry so that it belongs to this Blog. >>> Entry.objects.all().update(blog=b)
Метод update() применяется мгновенно и возвращает количество записей, удовлетворяющих запросу(что может быть не равно количеству обновленных записей, если они уже содержат новые значения). Единственное ограничение для изменяемого QuerySet – он может изменять только одну таблицу в базе данных: главную таблицу модели. Вы можете использовать фильтры по связанным полям, но вы можете изменять поля только таблицы изменяемой модели. Например:
>>> b = Blog.objects.get(pk=1) # Update all the headlines belonging to this Blog. >>> Entry.objects.select_related().filter(blog=b).update(headline='Everything is the same')
Be aware that the update() method is converted directly to an SQL
statement. It is a bulk operation for direct updates. It doesn’t run any
save() methods on your models, or emit the
pre_save or post_save signals (which are a consequence of calling
save()), or honor the
auto_now field option.
If you want to save every item in a QuerySet
and make sure that the save() method is called on
each instance, you don’t need any special function to handle that. Loop over
them and call save():
for item in my_queryset:
item.save()
Метод update() может использовать объект F для обновления одного поля значением другого поля модели. Это особенно полезно для изменения счетчика. Например, увеличить значение n_pingbacks на один для каждой записи:
>>> Entry.objects.all().update(number_of_pingbacks=F('number_of_pingbacks') + 1)
Однако, в отличии от использования объектов F() в методах filter() и exclude(), вы не можете использовать связанные поля при обновлении. Если вы будете использовать связанное поле в объекте F(), буде вызвано исключение FieldError:
# This will raise a FieldError
>>> Entry.objects.update(headline=F('blog__name'))
Связанные объекты
Используя связанные объекты в модели (например, ForeignKey, OneToOneField или ManyToManyField), в объект модели будет добавлен API для работы со связанными объектами.
Используя модели из примеров выше, например, объект e модели Entry, может получить связанные объекты Blog используя атрибут blog: e.blog.
(Это все работает благодаря дескрипторам Python. Это совсем не важно и упоминается для любознательных.)
Django также предоставляет доступ к связанным объектам с «другой» стороны – ссылка с связанного объекта на объект, который определяет связь. Например, объект b модели Blog имеет доступ ко всем связанным объектам Entry через атрибут entry_set: b.entry_set.all().
Все примеры в этом разделе используют вышеупомянутые модели Blog, Author и Entry.
Связь один-к-многим
Прямая
If a model has a ForeignKey, instances of that model
will have access to the related (foreign) object via an attribute of the model.
Например:
>>> e = Entry.objects.get(id=2) >>> e.blog # Returns the related Blog object.
Вы можете получить и изменить его через атрибут внешнего ключа. Как вы можете предполагать, изменения не будут сохранены в базу данных, пока не будет вызван метод save(). Например:
>>> e = Entry.objects.get(id=2) >>> e.blog = some_blog >>> e.save()
Если поле ForeignKey содержит null=True (то есть разрешено значение NULL), вы можете указать None для этого поля. Например:
>>> e = Entry.objects.get(id=2) >>> e.blog = None >>> e.save() # "UPDATE blog_entry SET blog_id = NULL ...;"
Прямой доступ для связи один-ко-многим кэширует полученное значение при первом обращении. Последующие обращения к внешнему ключу этого же объекта будут использовать кэшированное значение. Например:
>>> e = Entry.objects.get(id=2) >>> print(e.blog) # Hits the database to retrieve the associated Blog. >>> print(e.blog) # Doesn't hit the database; uses cached version.
Запомните, что вызов метода select_related() QuerySet рекурсивно заполняет кэш значениями для всех связей один-ко-многим. Например:
>>> e = Entry.objects.select_related().get(id=2) >>> print(e.blog) # Doesn't hit the database; uses cached version. >>> print(e.blog) # Doesn't hit the database; uses cached version.
«Обратная» связь
Если модель содержит ForeignKey, будет содержать Manager, который вернет все связанные объекты первой модели. По-умолчанию, этот Manager называется FOO_set, где FOO название основной модели в нижнем регистре. Этот Manager возвращает QuerySets, который может быть отфильтрован и изменен как было описано в разделе «Получение объектов».
Например:
>>> b = Blog.objects.get(id=1) >>> b.entry_set.all() # Returns all Entry objects related to Blog. # b.entry_set is a Manager that returns QuerySets. >>> b.entry_set.filter(headline__contains='Lennon') >>> b.entry_set.count()
Вы можете переопределить название FOO_set, установив параметр related_name при определении ForeignKey. Например, если бы модель Entry содержала blog = ForeignKey(Blog, on_delete=models.CASCADE, related_name='entries'), пример выше выглядел бы как:
>>> b = Blog.objects.get(id=1) >>> b.entries.all() # Returns all Entry objects related to Blog. # b.entries is a Manager that returns QuerySets. >>> b.entries.filter(headline__contains='Lennon') >>> b.entries.count()
Использование своего менеджера для обратных связей
По умолчанию для обратных связей используется менеджер RelatedManager, который является дочерним классом менеджера по умолчанию модели. Чтобы указать свой менеджер, используйте следующий подход:
from django.db import models
class Entry(models.Model):
#...
objects = models.Manager() # Default Manager
entries = EntryManager() # Custom Manager
b = Blog.objects.get(id=1)
b.entry_set(manager='entries').all()
Если EntryManager выполняет фильтрацию в методе get_queryset(), она будет выполнена и при вызове all().
Также вы можете вызывать методы указанного менеджера:
b.entry_set(manager='entries').is_published()
Связь многие-ко-многим
Both ends of a many-to-many relationship get automatic API access to the other end. The API works similar to a «backward» one-to-many relationship, above.
One difference is in the attribute naming: The model that defines the
ManyToManyField uses the attribute name of that
field itself, whereas the «reverse» model uses the lowercased model name of the
original model, plus '_set' (just like reverse one-to-many relationships).
Пример все разъяснит:
e = Entry.objects.get(id=3) e.authors.all() # Returns all Author objects for this Entry. e.authors.count() e.authors.filter(name__contains='John') a = Author.objects.get(id=5) a.entry_set.all() # Returns all Entry objects for this Author.
Так же, как и ForeignKey, ManyToManyField позволяет определить related_name. В примере выше, если поле ManyToManyField модели Entry содержит related_name='entries', тогда каждый объект модели Author будет с атрибутом entries вместо entry_set.
Another difference from one-to-many relationships is that in addition to model
instances, the add(), set(), and remove() methods on many-to-many
relationships accept primary key values. For example, if e1 and e2 are
Entry instances, then these set() calls work identically:
a = Author.objects.get(id=5) a.entry_set.set([e1, e2]) a.entry_set.set([e1.pk, e2.pk])
Связь один-к-одному
One-to-one relationships are very similar to many-to-one relationships. If you
define a OneToOneField on your model, instances of
that model will have access to the related object via an attribute of the
model.
Например:
class EntryDetail(models.Model):
entry = models.OneToOneField(Entry, on_delete=models.CASCADE)
details = models.TextField()
ed = EntryDetail.objects.get(id=2)
ed.entry # Returns the related Entry object.
Разница в обратной связи. Связанная модель также имеет доступ к объекту Manager, но Manager представляет один объект, а не множество объектов:
e = Entry.objects.get(id=2) e.entrydetail # returns the related EntryDetail object
Если ни один объект не добавлен в связь, Django вызовет исключение DoesNotExist.
Объект может быть назначен через обратную связь так же, как и через прямую:
Как работает обратная связь?
Другие ORM требуют определять связь с обеих сторон. Разработчики Django считают, что это противоречит принципу DRY (Don’t Repeat Yourself — не повторяй себя), по этому принципу Django требует определить связь только для одной модели.
Но как это возможно, учитывая, что модель не знает, какие другие модели связаны с ней, пока классы этих моделей не будут загружены?
Все происходит при регистрации приложений. Когда запускается Django, происходит импорт всех приложений из INSTALLED_APPS, далее импорт модуля models этих приложений. Когда создается класс модели, Django добавляет обратные связи для всех связанных моделей. Если связанная модель еще не импортирована, Django запоминает эту модель и добавит связь при ее импорте.
Поэтому важно, чтобы все модели, которые вы используете, находились в приложениях из INSTALLED_APPS. Иначе связи не будут работать.
Сглаживающие фильтры. Емкостной и индуктивный фильтры. Сложные фильтры
~ ЛЕКЦИЯ 29 ~
Сглаживающие фильтры
Сглаживающие фильтры служат для уменьшения пульсаций напряжения на нагрузке.
Отношение коэффициента пульсаций на выходе выпрямителя q к коэффициенту пульсаций на нагрузке q1 определяет степень сглаживания выпрямленного напряжения и называется коэффициентом сглаживания фильтра:
S = q / q1.
Расчет коэффициента сглаживания по первой (основной) гармонике проводят по формуле :
,
где Ud1m и Udн1m — амплитуды пульсаций первых гармоник напряжения на входе и выходе фильтра; Udср и Udнср — постоянные составляющие напряжения на входе и выходе фильтра.
Если принять, что потери в фильтре отсутствуют:
DUф = Udср — Udнср = 0,
то коэффициент сглаживания S1 можно определить из выражения:
S1 = Ud1m / Udн1m.
Сглаживающие фильтры бывают простые и сложные. К простым относятся емкостной и индуктивный фильтры (рис. 2.8, 2.9), к сложным фильтрам относятся: Г-образные и П-образные фильтры. Г-образные фильтры — это RC- и LC-фильтры (рис. 2.10, 2.11). П-образные фильтры представлены CRC- и CLC-фильтрами (рис. 2.12, 2.13).
Для достижения большей степени сглаживания из Г-образных фильтров собирают многозвенные фильтры. Применение в преобразовательной технике нашли и транзисторные фильтры.
Емкостной фильтр
Использованный в емкостном фильтре конденсатор является реактивным элементом, оказывает малое сопротивление переменному току и большое — постоянному. В связи с этим его включают параллельно нагрузке (рис. 2.8). Сглаживающий фильтр совместно с внешней нагрузкой определяют вид нагрузки выпрямителя. Так, при включении емкостного фильтра между нагрузкой и выпрямителем общая нагрузка выпрямителя носит активно-емкостной характер. Выбор конденсатора для емкостного фильтра основывается на соотношении:
,
где d1 — круговая частота сигнала основной гармоники.
Рис.2.8. Простой емкостной фильтр.
При таком включении конденсатор шунтирует (закорачивает) нагрузку по переменной составляющей выпрямленного тока и падение напряжения на нагрузке обусловлено протеканием постоянной составляющей Id выпрямленного тока.
Коэффициент сглаживания емкостного фильтра:
S1 = d1 Cф Rн .
Индуктивный фильтр
Индуктивный фильтр (рис. 2.9) в выпрямителе включают последовательно с нагрузкой, так как он оказывает большое сопротивление переменной составляющей протекающего тока.
Рис. 2.9. Простой индуктивный фильтр.
При включении индуктивного фильтра нагрузка носит активно-индукционный характер. Выбор индуктивности для фильтра осуществляют исходя из соотношения:
d1 Lф >> Rн
Это позволяет выделить падение напряжения от переменной составляющей выпрямленного тока на Lф, на Rн будет происходить падение напряжения от постоянной составляющей Id выпрямленного тока.
Коэффициент сглаживания индуктивного фильтра:
где с — частота сигнала питающей сети.
Сложные фильтры
Рассмотрим Г-образный RC-фильтр (рис. 2.10). Параметры этого фильтра выбираются исходя из условия:
.
Коэффициент сглаживания RC- фильтра:
.
Рис. 2.10. Г-образный RC-фильтр.
Недостаток RC-фильтра — потеря мощности на сопротивлении R.
Г-образный LC-фильтр (рис. 2.11) одновременно должен удовлетворять следующим условиям:
Достаточным считается, если:
Рис. 2.11. Г-образный LC-фильтр.
Коэффициент сглаживания Г-образного LC-фильтра:
S1 =ω d12 LфСф — 1 =
ωc2 m2 LфСф — 1.
Из этого выражения, задавшись коэффициентом сглаживания S1, круговой частотой Wd1 и числом фаз выпрямления, можно определить произведение Lф Сф:
Рис. 2.12. П-образный CRC-фильтр.
П-образные фильтры обеспечивают высокое качество сглаживания. Например, коэффициент сглаживания S1П П-образного CRC-фильтра (рис. 2.12) определится произведением коэффициента сглаживания S1 фильтра Сф1 и коэффициента сглаживания S1Г Г-образного фильтра RCф2 :
S1n = S1S1Г.
П-образный CLC-фильтр (рис. 2.13) имеет большие габариты и вес, чем CRC-фильтр, но обеспечивает высокое качество сглаживания.
Рис. 2.13. П-образный CLC-фильтр.
Пример многозвенного фильтра приведен на рис. 2.14. Расчет коэффициента сглаживания многозвенного фильтра осуществляют перемножением коэффициентов сглаживания отдельных звеньев:
S1 = S1I· S1II· S1III · … · S1n .
Рис. 2.14. Многозвенный LC-фильтр.
Кроме пассивных фильтров на элементах С, L, R применяют электронные сглаживающие фильтры на транзисторах. Использование транзисторов обусловлено тем, что сопротивление промежутка коллектор-эмиттер постоянному току (статическое сопротивление), определяемое как Uкэо/Iко в режиме покоя, на 2-3 порядка меньше сопротивления того же промежутка переменному току, равного 1/h2,2.
Рис. 2.15. Схема транзисторного фильтра.
Таким образом, действие транзисторного фильтра (рис. 2.15) аналогично действию индуктивного фильтра, и его включают в схему сглаживающего П-образного фильтра вместо катушки Lф.
Резисторы R1 и R2 необходимы для выбора рабочего режима транзистора. Такой фильтр снижает пульсацию на 2-3 порядка.
Фильтры | Creatio Academy
В Creatio реализована возможность фильтровать записи в реестре разделов и деталей. Для поиска и фильтрации записей в разделах предусмотрены следующие инструменты:
-
Быстрый фильтр;
-
Стандартный фильтр;
-
Расширенный фильтр.
Для фильтрации записей на деталях используется только стандартный фильтр.
Элементы управления фильтрами отображаются в верхней части разделов системы (Рис. 1) или непосредственно на деталях.
Управление стандартным и расширенным фильтрами в разделах осуществляется в меню Фильтр. Изменить параметры установленного фильтра в разделе или на детали можно, кликнув по нему и изменив нужные поля в области настройки фильтров.
Настроенные вами фильтры сохраняются при обновлении страницы, переходе между разделами и при повторном входе в систему. Чтобы отменить один из установленных фильтров, нажмите кнопку в его правой части (Рис. 2).
На заметку. В меню Фильтр также осуществляется управление группами. Если какие-либо группы были отмечены как избранные, их список будет отображен в меню Фильтр. Подробнее читайте в статье “Группы”.
Быстрый фильтр
Быстрый фильтр отображается в некоторых разделах Creatio и используется для фильтрации данных по наиболее часто используемым параметрам (Рис. 3).
Например, быстрый фильтр присутствует в разделе Активности, т.к. чаще всего нужно просматривать активности одного сотрудника за указанный период времени. Быстрые фильтры в разделах по умолчанию активны. При этом набор полей для фильтрации в различных разделах может отличаться.
Быстрый фильтр по периоду
Вы можете использовать фильтры по периоду, например, чтобы отобразить активности за текущую или прошлую неделю.
В системе есть три вида быстрых фильтров по периоду:
-
— отображает записи текущего дня.
-
— отображает записи текущей недели.
-
— отображает записи стандартного периода, например, “Вчера”, “Текущая неделя”, “Следующая неделя”, “Прошлый месяц” и т. п. Вы также можете установить произвольный период, указав даты его начала и завершения при помощи встроенного календаря.
На заметку. Прошлой, текущей и следующей неделей или месяцем считается календарный период. Например, если прошлый месяц — декабрь, то в разделе Активности при выборе периода “Прошлый месяц” будут отображены активности за период с 1 по 31 декабря.
Чтобы отобразить в реестре записи за квартал, полугодие или другие стандартные периоды, используйте фильтрацию по периоду расширенного фильтра.
Для установки произвольного периода фильтрации выберите дату начала и дату завершения периода во встроенном календаре фильтра. Календарь открывается при нажатии на дату начала или завершения периода (Рис. 4).
Быстрый фильтр по ответственному
Фильтр по ответственному используется, чтобы отобразить записи по одному или нескольким ответственным по записям, а в разделе Активности — по участникам. В разделе Активности фильтр называется По сотруднику.
Для просмотра данных по конкретному пользователю выберите его имя в меню фильтра . Для просмотра данных по нескольким ответственным выберите в меню команду Добавить ответственного или Добавить сотрудника и в открывшемся окне укажите необходимого пользователя.
Для отмены фильтрации по ответственным в меню фильтра выберите команду Очистить.
Стандартный фильтр
Стандартный фильтр используется для поиска записей в разделах системы или на деталях по указанным значениям одной или нескольких колонок. Например, если необходимо найти всех контрагентов заданного типа или отобрать активности в заданном состоянии и определенного приоритета.
Установить стандартный фильтр в разделе
-
В меню Фильтр выберите команду Добавить условие (Рис. 6).
- В появившихся полях укажите условие фильтрации. Выберите из списка колонку, по которой необходимо осуществить поиск, и укажите значение колонки (целиком или его фрагмент). Для применения условия фильтрации нажмите кнопку (Рис. 7).
В результате в разделе будут отображены только те записи, которые соответствуют примененному фильтру.
Установить несколько стандартных фильтров в разделе
В одном разделе могут быть применены сразу несколько стандартных фильтров. Для этого после установки первого фильтра еще раз выберите команду Добавить условие в меню Фильтр и укажите новое условие фильтрации. После установки нескольких стандартных фильтров в разделе будут отображены только те записи, которые соответствуют всем указанным условиям.
Установить стандартный фильтр на детали
-
В меню кнопки выберите команду Установить фильтр (Рис. 8).
-
В появившихся полях укажите условие фильтрации. Выберите из списка колонку, по которой необходимо осуществить поиск, и укажите значение колонки (целиком или его фрагмент). Для применения условия фильтрации нажмите кнопку (Рис. 9).
В результате на детали будут отображены только те записи, которые соответствуют указанному фильтру.
На заметку. Установка фильтрации возможна только на деталях с реестром.
Установить несколько стандартных фильтров на детали
На одной детали могут быть применены сразу несколько стандартных фильтров. Для этого после установки первого фильтра нажмите кнопку и укажите новое условие фильтрации. После установки нескольких стандартных фильтров на детали будут отображены только те записи, которые соответствуют всем указанным условиям.
Скрыть панель фильтрации на детали
Панель фильтрации на детали скрывается автоматически после обновления страницы. Чтобы скрыть панель вручную, в меню кнопки выберите действие Скрыть фильтр (Рис. 10).
Важно. Действие доступно, когда на детали не установлены условия фильтрации.
На заметку. Вы можете сворачивать и разворачивать деталь по кнопке без потери настроенных условий фильтрации.
Расширенный фильтр
Если к записям необходимо применить более сложный фильтр, состоящий из нескольких параметров и условий поиска, то используйте расширенный фильтр. Например, при помощи расширенной фильтрации вы можете отобразить в разделе Активности все встречи по новым клиентам.
Для установки расширенного фильтра используется команда Перейти в расширенный режим меню Фильтр (Рис. 11).
Установить фильтр по колонкам объекта
Вы можете настроить фильтр по колонкам текущего объекта (например, колонка Дата завершения объекта “Активность” или колонка Должность объекта “Контакт”).
Например, чтобы в разделе Активности отобрать незавершенные активности, которые были изменены за последние две недели:
-
Откройте раздел Активности. В меню Фильтр выберите команду Перейти в расширенный режим.
-
В области настройки фильтров нажмите на ссылку <Добавить условие>.
-
В открывшемся окне в поле Колонка выберите интересующую колонку, например, Состояние, и нажмите кнопку Выбрать (Рис. 12).
-
На странице настройки фильтров установите необходимые параметры условия:
-
Выберите тип условия, кликнув по его символу, например, “=”.
-
Нажмите на ссылку <?>. В открывшемся окне отметьте необходимые значения для выбранной колонки, например, “Не начата” и “В работе”. Нажмите кнопку Выбрать (Рис. 13).
-
-
Повторите предыдущие пункты, чтобы добавить другие необходимые условия. Например, установите пороговые значения для даты изменения записей.
-
Установите логический оператор для заданных условий, например, “И”, кликнув по нему (Рис. 14).
На заметку. По умолчанию область условий фильтра содержит одну пустую корневую группу с логическим оператором “И”. Логический оператор “И” используется, если необходимо, чтобы искомая запись соответствовала всем условиям группы. Если запись должна соответствовать хотя бы одному из условий группы, выберите логический оператор “ИЛИ”.
При использовании условия “≠” учитываются записи, у которых выбранное поле не заполнено. -
Нажмите кнопку Применить.
В результате в разделе Активности будут отображены только незавершенные активности, которые были изменены в течение указанного периода.
Установить фильтр по колонкам связанных объектов
Вы можете отфильтровать записи не только по колонкам текущего объекта, но и по колонкам связанных с ним объектов. Например, для объекта “Активность” можно отфильтровать записи по колонке Тип связанного объекта “Контрагент”. Например, чтобы в разделе Активности отобрать активности только по компаниям определенного типа:
- Откройте раздел Активности. В меню Фильтр выберите команду Перейти в расширенный режим.
- Нажмите на ссылку <Добавить условие>.
- На открывшейся странице выбора колонки:
-
Нажмите кнопку возле наименования объекта.
-
В добавившемся поле выберите связанный объект, например, “Контрагент”.
-
В поле Колонка укажите колонку связанного объекта, например, “Тип”.
-
Нажмите кнопку Выбрать (Рис. 15).
-
-
В области настройки фильтров установите необходимые параметры условия:
-
Выберите тип условия, кликнув по его символу. По умолчанию указано условие “=”.
-
Нажмите на ссылку <?>. В открывшемся окне отметьте необходимое значение для выбранной колонки, например, “Клиент”. Нажмите кнопку Выбрать.
-
-
Нажмите кнопку Применить (Рис. 16).
В результате в разделе будут отображены только активности по контрагентам, которые относятся к типу “Клиент”.
На заметку. В данном примере при установке фильтра <Контрагент.Тип ≠ Клиент> в разделе будут отображены как активности по тем контрагентам, которые не являются клиентами, так и по тем, у которых тип не указан.
Если данные, полученные в результате фильтрации, вы используете регулярно, то создайте по настроенному фильтру динамическую группу, нажав кнопку Сохранить как.
Установить фильтр с группировкой условий фильтрации
Рассмотрим последовательность построения расширенного фильтра, для которого необходимо использовать несколько логических операторов. Например, чтобы в разделе Контрагенты отобразить всех клиентов, для которых или указан город “Москва”, или город не указан:
-
Откройте раздел Контрагенты. В меню Фильтр выберите команду Перейти в расширенный режим.
-
Для установки условия “Тип = Клиент”:
-
Нажмите на ссылку <Добавить условие>.
-
В открывшемся окне выберите колонку контрагента, например, “Тип”. Нажмите кнопку Выбрать.
-
В области настройки фильтров нажмите на ссылку <?>. В открывшемся окне отметьте необходимое значение для выбранной колонки, например, “Клиент”. Нажмите кнопку Выбрать.
-
-
Аналогичным образом добавьте условие “Город = Москва”.
-
Для установки условия “Город не заполнено”:
-
Нажмите на ссылку <Добавить условие>.
-
В открывшемся окне выберите колонку “Город”. Нажмите кнопку Выбрать.
-
В области настройки фильтров кликните по типу условия и в открывшемся списке выберите “Не заполнено”.
-
-
Сгруппируйте необходимые условия и установите для них логический оператор:
-
Удерживая клавишу Ctrl, выделите мышью те условия, которые необходимо сгруппировать для установки другого логического оператора (Рис. 17).
-
В меню кнопки Действия выберите команду Группировать (Рис. 18).
-
Кликнув по заголовку логического оператора, установите основной оператор “И” и оператор для созданной группы — “ИЛИ” (Рис. 19).
-
-
Нажмите кнопку Применить.
В результате в разделе будут отображены контрагенты с типом “Клиент”, для которых в поле Город либо указано “Москва”, либо нет значения.
Установить агрегирующий фильтр
Агрегирующий фильтр позволяет отфильтровать записи одного объекта по связанным с ними записям в объекте с обратной связью. Существует несколько доступных условий фильтрации с использованием агрегирующего фильтра.
-
Количество — для фильтруемых записей существует определенное количество связанных записей в объекте с обратной связью. Например, можно отфильтровать сотрудников, являющихся ответственными по пяти и более контрагентам.
-
Максимум / Минимум — для фильтруемых записей в объекте с обратной связью есть связанные записи с определенным максимальным (минимальным) значением в числовой колонке или в колонке даты. Например, вы можете выбрать сотрудников, последняя задача которых была выполнена на прошлой неделе.
-
Сумма, Среднее — для фильтруемых записей в объекте с обратной связью есть связанные записи с определенной суммой значений или средним значением в числовой колонке. Например, можно отфильтровать сотрудников, у которых средняя продолжительность задач превышает 2 часа.
Процесс построения агрегирующего фильтра аналогичен процессу построения фильтра по колонкам связанных объектов. Например, необходимо получить список пользователей, которые являются ответственными по контрагентам с типом “Клиент”. Такой список можно получить при помощи агрегирующего фильтра:
- Откройте раздел, записи которого необходимо отфильтровать, например, Контакты. В меню Фильтр выберите команду Перейти в расширенный режим.
- Нажмите на ссылку <Добавить условие>.
- В открывшемся окне выбора колонки (Рис. 20):
- Нажмите кнопку возле наименования объекта.
- В добавившемся поле выберите объект с обратной связью. Например, чтобы построить агрегирующий фильтр по колонке Ответственный раздела Контрагенты, выберите “Контрагент (по колонке Ответственный)”.
-
В поле Колонка укажите колонку объекта с обратной связью, например, “Количество”.
-
Нажмите кнопку Выбрать.
-
В области настройки фильтров (Рис. 21):
-
Укажите условие фильтра, в данном случае, “Количество > 0”.
-
Установите дополнительные параметры фильтра. Например, если необходимо, чтобы отображались только ответственные по контрагентам с типом “Клиент”, добавьте это условие в фильтр.
-
-
Нажмите кнопку Применить.
В результате запись будет отображена в разделе Контакты только в том случае, если существует контрагент, у которого данный пользователь указан в поле Ответственный.
Установить фильтр по периоду
Вы можете настроить фильтрацию записей по определенному периоду или точной дате. Например, отобразить все данные, добавленные в раздел за прошедшую неделю.
В Creatio доступны следующие виды фильтров по периоду:
Настроить фильтр по точной дате
Для отображения данных, относящихся в определенному периоду, укажите интересующий период в условиях фильтра. Например, если необходимо просмотреть активности за период командировки, в которой вы были три недели назад.
- Перейдите в раздел Активности.
- В меню Фильтр выберите команду Перейти в расширенный режим (Рис. 22).
В появившейся области фильтрации укажите начало периода, за который вы хотите отобразить записи в разделе. Для этого:
-
Нажмите на ссылку <Добавить условие> (Рис. 23) и в открывшемся окне выберите необходимую колонку даты, например, “Начало”, чтобы отфильтровать активности по дате их начала.
-
Выберите тип условия напротив добавленной колонки (Рис. 24), например, “≥” (больше или равно), чтобы дата начала периода фильтрации включала этот период.
-
- В меню ссылки <?> выберите команду Указать точную дату (Рис. 25).
- В появившемся поле отобразите при помощи кнопки встроенный календарь фильтра и выберите в нем необходимую дату (Рис. 26).
-
Аналогично укажите конечную дату периода фильтрации:
-
Добавьте в условие фильтрации колонку “Начало”, чтобы отфильтровать активности по дате их начала.
-
Выберите для нее тип условия “≤” (меньше или равно).
-
Выберите дату во встроенном календаре.
-
- Убедитесь, что для добавленных условий фильтрации установлен логический оператор “И”.
- Примените установленный фильтр, используя кнопку Применить фильтра.
В результате в разделе Активности будут отображены активности, начало которых входит в установленный в фильтре период.
Настроить стандартные периоды фильтрации
Для удобства работы с фильтром используйте стандартные периоды фильтрации. Например, вы можете быстро отобразить записи за предыдущую, текущую или следующую неделю.
Стандартные периоды доступны в меню ссылки <?> условия фильтра (Рис. 28).
Час
Меню содержит команды, позволяющие отображать записи раздела за предыдущий, текущий или следующий час, а также за определенное количество предыдущих или следующих часов. Вы также можете указать в качестве значения фильтра точное время до минуты.
Чтобы указать точное время, выберите команду Точное время и в появившемся поле введите необходимое значение времени в формате Ч:ММ, например, “14:43”. Используйте стандартные значения времени, доступные для выбора в поле.
Чтобы указать количество предыдущих или следующих часов, выберите команду Предыдущих часов или Следующих часов соответственно и в появившемся поле введите необходимое значение. Вы можете ввести только целое число.
Обратите внимание, что предыдущим, текущим или следующим часом считается полный час с первой по 60-ю минуту, например, с 13:00 по 13:59 включительно, а не час относительно текущего момента времени. Например, если текущее время 14:34, то следующим часом будет считаться период с 15:00 по 15:59 включительно, а не с 14:34 по 15:33.
День
Меню содержит команды, позволяющие отображать записи раздела за вчерашний, сегодняшний или завтрашний день, а также за определенное количество предыдущих или следующих дней. Вы также можете указать в качестве значения фильтра определенный день месяца или день недели.
Чтобы указать в качестве значения фильтра определенный день месяца, выберите команду День месяца и в появившейся строке введите число месяца.
Чтобы указать определенный день недели, выберите в меню День —> День недели —> необходимый день недели, например, “Пн”, “Вт”.
Неделя
Меню содержит команды, позволяющие отображать записи раздела за предыдущую, текущую и следующую неделю.
Предыдущей, текущей или следующей неделей считается календарный период с понедельника по воскресенье, а не семидневный период относительно текущего момента времени. Например, если сегодня среда, то следующей неделей будет считаться период с ближайшего понедельника по воскресенье, а не следующие семь дней начиная с текущей даты.
Месяц
Меню содержит команды, позволяющие отображать записи раздела за предыдущий, текущий и следующий месяц. Вы также можете указать в качестве значения фильтра определенный месяц.
Чтобы указать определенный месяц, выберите его в меню Месяц —> Месяц, например, “Декабрь”.
Обратите внимание, что предыдущим, текущим или следующим месяцем считается календарный период. Например, если прошлый месяц — декабрь, то в разделе при применении периода фильтрации “Прошлый месяц” будут отображены записи за период с 1 по 31 декабря.
Квартал
Меню содержит команды, позволяющие отображать записи раздела за предыдущий, текущий и следующий квартал.
Предыдущим, текущим или следующим кварталом считается период в три месяца: I квартал включает в себя первый, второй и третий месяцы года (январь, февраль, март), II квартал — следующие три месяца (апрель, май, июнь) и т. д. Например, если сейчас август, то следующим кварталом будет считаться период, включающий в себя октябрь, ноябрь и декабрь (IV квартал).
Полугодие
Меню содержит команды, позволяющие отображать записи раздела за предыдущее, текущее и следующее полугодие.
Предыдущим, текущим или следующим полугодием считается период в шесть месяцев: I полугодие включает в себя месяцы с января по июнь, II полугодие — с июля по декабрь. Например, если сейчас август (входит во II полугодие), то следующим полугодием будет считаться период с января по июнь следующего года.
Год
Меню содержит команды, позволяющие отображать записи раздела за предыдущий, текущий и следующий год. Вы также можете указать в качестве значения фильтра определенный год.
Предыдущим, текущим или следующим годом считается календарный период. Например, если сейчас август 2020 года, то следующим годом будет считаться период с января по декабрь 2021 года включительно, а не следующие двенадцать месяцев начиная с августа 2020 года.
Настроить фильтр по ежегодным событиям
В отличие от стандартных периодов фильтрации, фильтр по ежегодным событиям учитывает только день и месяц дат, по которым производится отбор. Такой фильтр удобно использовать, например, для отслеживания знаменательных событий контактов.
Фильтр по ежегодным событиям доступен в меню ссылки <?> условия фильтра (Рис. 29).
Меню содержит команды, позволяющие отображать записи раздела за день, а также за определенное количество предыдущих или следующих дней.
-
Ежегодно, сегодня. Условие позволяет отобразить список записей, дата которых совпадает с текущей, без учета года.
-
Ежегодно, через дней <?>. Условие позволяет отобразить список записей, дата которых, без учета года, наступит через указанное количество дней.
-
Ежегодно, следующих дней <?>. Условие позволяет отобразить список записей, дата которых, без учета года, попадает в один из нескольких следующих дней.
-
Ежегодно, предыдущих дней <?>. Условие позволяет отобразить список записей, дата которых, без учета года, попадает в один из нескольких предыдущих дней.
, где нижние индексы $ _R $ и $ _I $ обозначают действительную и мнимую части соответственно. Из $ (4) $ вы видите, что вам нужно реализовать два фильтра, один с импульсной характеристикой $ h_R [n] $, а другой с импульсной характеристикой $ h_I [n] $, и что вам также нужно отфильтровать реальную часть как мнимая часть входного сигнала с обоими фильтрами.
Что касается приложений в цифровой связи, везде, где у вас есть синфазные и квадратурные компоненты, вы можете смоделировать эти два сигнала как сложный сигнал, и любая фильтрация этого сложного сигнала требует сложного фильтра (или, по крайней мере, фильтра с комплексный ввод и вывод).Однако на практике чаще всего встречаются два особых случая:
-
Фильтр на самом деле является вещественным, но имеет сложный вход и выход, т.е. вы просто фильтруете действительную и мнимую части входного сигнала независимо с помощью одного и того же фильтра. В уравнении. $ (4) $, что означает, что $ h_I [n] = 0 $. Это тот случай, когда вы применяете фильтр нижних частот после сложной демодуляции.
-
Фильтр является комплексным, но входной сигнал является действительным, поэтому вы фильтруете один (действительный) сигнал с помощью двух фильтров (действительной и мнимой частей импульсной характеристики).В уравнении. $ (4) $, что означает, что $ x_I [n] = 0 $. Это происходит, когда вы фильтруете сигнал полосы пропускания с действительным знаком с помощью аналитического полосового фильтра перед комплексной демодуляцией . (Обратите внимание, что здесь фильтр полосовой, а не низкочастотный).
Полная операция комплексной фильтрации с комплексными входами и выходами, и сложная импульсная характеристика (как определено уравнением $ (4) $) используется для моделирования цифровой системы связи с использованием эквивалентного дискретного канала основной полосы частот. .Соответствующий фильтр канала основной полосы частот обычно является комплексным.
цифровая связь — сложные фильтры, используемые в аналоговой области
Векторные модуляторы и микшер с одной боковой полосой (преобразователь частоты) являются обычным и относительно простым аналоговым компонентом для подавления сигнала изображения.
Верхняя блок-схема в этом посте представляет собой архитектуру векторного модулятора и смесителя с одной боковой полосой и более подробно объясняет, как она обеспечивает отклонение изображения с использованием сложной передачи сигналов.
Сдвиг частоты квадратурного смешанного сигнала
Обычно мы видим эти компоненты с реальным входом, где внутренний 90-градусный разветвитель немедленно преобразует входной сигнал в сложный сигнал, а затем он подвергается дальнейшей обработке. Однако нет причин, по которым они не могут использоваться идентичным образом с квадратурным делителем, обойденным в случае, если сигнал IQ с низкой ПЧ уже существует.
Это предпочтительный подход для устранения сигнала изображения.
Однако, чтобы реализовать общий комплексный фильтр в аналоговой области, вам нужно будет сделать следующее с четырьмя реальными фильтрами, как показано на диаграмме ниже.Это связано с выполнением полного комплексного умножения с реальными сигналами, как указано в:
$$ (s_I + js_Q) (c_I-jc_Q) $$ $$ = (s_Ic_I + s_Qc_Q) + j (s_Ic_Q-s_Qc_I) $$
Соответствует умножению сигнала (ов) на коэффициент, такой как в КИХ-фильтре (c), показывающий, что у нас есть вход I и Q, умноженный на и I коэффициент Q, в результате получается I (действительная часть, определяемая как $ s_Ic_I + s_Qc_Q $) и Q (Мнимая часть, заданная s_Ic_Q-s_Qc_I).
Эквивалентно сложная аналоговая фильтрация (фильтрация сложного входа со сложной импульсной характеристикой) формируется с помощью четырех реальных фильтров, как показано на рисунке ниже.Каждый фильтр имеет реальную импульсную характеристику, задаваемую $ h_i (t) $ или $ h_q (t) $, соответствующими действительной и мнимой части желаемой комплексной импульсной характеристики.
Кроме того, я наткнулся на это: https://ieeexplore.ieee.org/abstract/document/4151912
Обратите внимание, что фильтры на ПАВ являются аналоговым эквивалентом КИХ-фильтра (фильтр «все = ноль» с бесконечно удаленными полюсами, сформированный суммированием взвешенных задержек)
Реальных выходов сложных фильтров
Реальных выходов сложных фильтровДалее: Проектирование фильтров Up: Проектирование фильтров Предыдущая: Составные фильтры Содержание Индекс
В большинстве приложений мы начинаем с сигнала с действительным знаком для фильтрации, и нам нужно вывод с действительным знаком, но, как правило, составной фильтр с переносом функция, как указано выше, даст комплексный результат.Однако мы можем создавать фильтры с не действительными коэффициентами, которые, тем не менее, дают выходы с действительными значениями, так что анализ, который мы проводим с использованием сложных числа могут использоваться для прогнозирования, объяснения и управления выходными данными с действительными значениями сигналы. Мы делаем это, объединяя каждый элементарный фильтр (с коэффициентом, скажем) с другим, имеющим в качестве коэффициента комплексно сопряженное .
Например, поставив два фильтра без рециркуляции, с коэффициентами и
, последовательно дает передаточную функцию, равную:
который обладает свойством:
Теперь, если мы поместим любую синусоиду с действительным знаком:
выходим:
Здесь мы используем два свойства комплексных конъюгатов.Во-первых, вы можете складывайте и умножайте их по желанию:
и, во-вторых, все, что угодно, плюс его комплексное сопряжение, реально, и на самом деле вдвое больше его реальной части:
Приведенный выше результат для двух конъюгированных фильтров распространяется на любой составной фильтр; в В общем, мы всегда получаем результат с действительным знаком из ввода с действительным знаком, если мы сделайте так, чтобы каждый коэффициент и в составном фильтре либо с действительным знаком, либо в паре со своим комплексно сопряженным.
При соединении рециркуляционных элементарных фильтров можно избежать
вычисление одного из каждой пары, пока входные данные являются действительными (и, таким образом,
выход тоже.Предположим, что вход представляет собой реальную синусоиду вида:
применяем единый рециркуляционный фильтр с коэффициентом. Сдача обозначим действительную часть вывода, имеем:
(На втором этапе мы использовали тот факт, что вы можете спрягать все или часть выражение, не меняя результата, если вы просто собираетесь взять настоящий все равно расстаться. Четвертый шаг сделал то же самое в обратном порядке.) Сравнение ввода на выход мы видим, что эффект прохождения реального сигнала через сложный однополюсный фильтр, принимающий действительную часть, эквивалентен пропусканию сигнала через двухполюсный фильтр с одним нулем с передаточной функцией, равной:
С этим определением мы можем переписать:
Аналогичный расчет показывает, что взятие мнимой части дает результат:
с передаточной функцией:
Таким образом, если взять реальную или мнимую часть выходного сигнала однополюсного фильтра, то получим фильтры с двумя полюсами на конъюгатах.Мы можем объединить эти два способа особым образом, чтобы получить простейший из возможных числитель единицы:
Это передаточная функция для двух последовательно соединенных сопряженных рециркуляционных фильтров, Итак, мы показали, что можем просто пропустить сигнал через один из этапов и объедините реальную и мнимую части, чтобы получить тот же результат. Эта техника (называемые частичными дробями ) могут повторяться для любое количество последовательных этапов, пока мы вычисляем соответствующие сочетание реальной и мнимой частей вывода каждого этапа для формируют (реальный) вход следующего этапа.Похоже, что для фильтров без рециркуляции не существует аналогичного ярлыка; в этом случае необходимо вычислить каждый член каждой комплексно-сопряженной пары явно.
Далее: Проектирование фильтров Up: Проектирование фильтров Предыдущая: Составные фильтры Содержание Индекс Миллер Пакетт 2006-03-03
сложный фильтр
сложный фильтр Предыдущая страница ‘Комплекс
Resonator »исследовал, как резонирующий фильтр реагирует на
однократный импульсный ввод.Теперь я хочу узнать, что за
комплексный интегратор работает со сложными синусоидальными входными сигналами. Потом
дальше, я разберусь, что интересного
фильтр
работа может быть выполнена с помощью сложного интегратора на реальном входном сигнале.
Для тестирования сложного интегратора как фильтра я написал отдельный
Объект Max / MSP. Вместо времени затухания пользовательского параметра я вернулся к
более прямой радиус параметра
опять же, потому что некоторые отношения между радиусом и выходной амплитудой должны
быть исследованным.
| |
В качестве сложного тестового сигнала я подаю генерируемый компьютером косинус
а также
синусоидальной волны на соответствующих входах сложного резонатора.Потому что
(сложная) синусоида имеет больше энергии, чем одиночный импульс выборки, она может
Можно предположить, что резонатор будет производить повышенный выходной уровень.
Амплитуду выходного сигнала можно легко вычислить, выполнив Пифагор на
реальный и мнимый выход.
В первом тесте я установил радиус 0,9 и позволил входной частоте совпадать.
центральная частота фильтра на 200 Гц:
| |
Ой, на выходе амплитуда почти 10, а амплитуда 1 равна единице
прирост.Я счастлив, что я еще не включил это в свои колонки.
Увеличение радиуса приводит к дальнейшему росту производительности.
амплитуда. Вот некоторые значения:
радиус 0,9 амплитуда 10
радиус 0,99 амплитуда 100
радиус 0,999 амплитуда 1000
радиус 0,9999 амплитуда 10000
Входная амплитуда кажется увеличенной на:
| |
Позвольте мне сначала сделать что-нибудь с этими сумасшедшими амплитудами.Если я
нормализовать вход, применяя инверсию наблюдаемого усиления
фактор, я ожидаю, что результат будет в пределах
предел единичного усиления:
| |
Это действительно работает. Значения входной выборки умножаются на
коэффициент 1-радиус. В приведенном выше примере это 10, а для большего
радиусы это может означать существенное ослабление входного сигнала. Тем не менее выход
растет до стабильной амплитуды около 1 каждый раз. Это замечательный
явление.Для простоты использования я включил эту нормализацию в
объект.
Теперь, когда вход комплексного интегратора нормализован, отфильтруйте
характеристики можно проверить. Чтобы визуализировать эффекты фильтра, я кормлю
комплексный шум и построить комплексный спектр выходного сигнала. я использую
линейные шкалы для амплитуды и частоты, а также пример с довольно
Центральная частота фильтра высоких частот:
| |
Комплекс
интегратор — полосовой фильтр.Увеличение
радиус, например до 0,999, сделает полосу уже:
| |
В большом радиусе
настройки, интеграция может сделать очень узкие полосовые фильтры. Но есть
нижняя сторона. Мы видели, как входной сигнал должен быть ослаблен в соответствии с
настройка радиуса; коэффициент нормализации в приведенном выше примере равен
0,001. Если ввод так сильно сокращен, это также должно быть так, что
в
интегратору требуется некоторое время, чтобы выйти на полный выходной уровень.Даже если
входящий звук имеет быструю атаку, фильтр не сможет
следите за этим. Ниже приведен пример радиуса 0,999. Вход сигнала и
выход
одной фазы показаны:
| |
При входном затухании с 1 радиусом время нарастания того же порядка
в качестве времени затухания в приведенном выше примере около 25 миллисекунд. Это
лучше всего наблюдаемый
с прямоугольным входом, который эквивалентен входу постоянного тока в рамке:
| |
В
медленное время нарастания в узких резонирующих фильтрах надоедает.Любой пост
атака не пройдет
фильтр. Было бы неплохо, если бы мы могли сделать
этот фильтр работает немного быстрее. Хорошо? На самом деле это можно сделать.
Ниже я использую три сложных фильтра вместо одного. Это означает, что для
каждый момент выборки выполняется три комплексных умножения вместо
один. Это способ передискретизации. Эффект фильтра радиуса 0,999 равен
теперь делается с радиусом 0,99 для каждого фильтра.
| |
Проверка времени нарастания входной частоты в центре фильтра
частота, действительно показывает гораздо более быстрый рост для каскада:
| одиночный интегратор, радиус 0.999 |
каскад, радиус 0,99 |
положительные и отрицательные частоты
Я не сказал, как усложняю шум перед тем, как скармливать его
compole ~. Если честно, мне еще предстоит узнать, как сделать сложный
сигнал. А пока я использую гильберта Max / MSP ~
объект, который выполняет необходимое «преобразование Гильберта». Он имеет наборы
allpass
фильтры с фазовым отклонением среди них, 90 градусов для большинства
частоты, кроме самых низких частот и самой высокой октавы.Я думаю, что преобразование Гильберта должно давать положительные
частоты исключительно.
Ниже вы можете видеть, что hilbert ~ производит отрицательные частоты. Этот
смущал меня много раз. В любом случае, положительные частоты могут быть
производится путем изменения знака мнимой выходной фазы.
| |
Поскольку преобразование Гильберта может создавать сложные сигналы с положительным или
исключительно отрицательные частоты, также можно сделать и то, и другое, но
с разным содержанием и смешайте их в один сложный сигнал.я
сделали это в примере ниже, чтобы произвести странную демонстрацию
спектр, где частоты выше Найквиста не являются псевдонимами тех
ниже Найквиста. Радиус фильтра равен 0, чтобы показать полный вывод:
| |
Комплексный интегратор может отличать положительное от отрицательного
частот, поэтому теперь можно подавить положительные частоты для
Например, и пусть проходит полоса отрицательных частот:
| |
На данный момент у меня нет специального назначения для такой односторонней
фильтрация.Но мне это так здорово, что я просто хотел сделать иллюстрации.
Кстати, подать реальный сигнал в комплексе не проблема.
интегратор и отфильтруйте это:
| |
Когда мы хотим услышать выходной сигнал фильтра, мы должны выбрать один из
фильтровать выходные фазы, так как мы не можем слушать сложный сигнал. Когда
в фильтре был подан реальный сигнал, вроде есть разница в
спектры выходов.Я установил низкое значение радиуса, чтобы его можно было
лучше воспринимается. В первом случае берется реальный выпуск:
| |
Когда берется мнимый выходной сигнал, низкие частоты более
произносится:
| |
Это явление напоминает фильтр переменных состояния, где
он используется для получения высоких, низких и полосовых частот с одного
процесс фильтрации.При сложном интеграторе эффект не может быть
полностью эксплуатируется. Если реальный сигнал отправляется в сложном интеграторе
каскад, спектральная разница между реальным и мнимым выходом при
последний фильтр пропал. Как придешь? Интеграторы стремятся сделать реальный
сигнальный комплекс. А для сложных сигналов комплексный интегратор является
простой полосовой фильтр на обоих выходах.
Если сложный интегратор стремится сделать реальный сигнал сложным, может ли он
не может использоваться для преобразования Гильберта? Это то, на что я надеялся.К сожалению, это хорошо работает только с настройками большого радиуса, которые
означает узкие полосы фильтра. Вот пример. Круг на x-y
осциллограф демонстрирует ортогональность фаз:
| |
На высоких центральных частотах значение радиуса может быть меньше, и
все равно выходит точный сложный сигнал:
|
|
|
Можно даже преобразовать сигнал 15 кГц из реального в комплексный,
это то, чего не может сделать объект hilbert ~.
|
|
линии представляют собой просто интерполяцию между точками на круг |
Это открывает одну интересную перспективу. Если вам нужно сделать
постоянный банк фильтров Q по любой причине, у вас могут быть сложные выходы
за небольшую дополнительную плату. Но что, если вам нужен сложный сигнал без
эффект фильтра? Я так много написал о сложных сигналах, я действительно
чувствую необходимость выяснить, как можно выполнить преобразование Гильберта, и сделать
солидная иллюстрированная документация по этому поводу.
Интеллектуальная автоматическая статистика со сложными фильтрами | Блог Microsoft Power BI
Мы надеемся, что вам нравится использовать Quick Insights на ваших информационных панелях, и мы рады сообщить, что Quick Insights, ограниченный одной плиткой, стал намного умнее. Это отличная функция для получения более целенаправленной и масштабной аналитической информации о ваших данных. Наше первое обновление месяц назад включало идеи, полученные с помощью простых фильтров. Сейчас мы выпускаем обновление, которое также понимает сложные фильтры.
Что это значит для вашего опыта? Это означает, что вы можете сузить автоматически сгенерированную статистику, добавив более сложные фильтры к визуальному элементу, с которого вы начинаете, чтобы анализ работал лучше для конкретных показателей, которые вам интересны. Или, если у вас уже есть визуальные эффекты со сложными фильтрами , вы получите более целенаправленную и полезную автоматически генерируемую статистику.
В качестве примера представьте, что вы просматриваете данные о продажах за этот год и хотите лучше понять, что происходит в двух конкретных категориях продуктов, которые, похоже, не достигают своей цели: дети и юниоры.Для этого вы дополнительно фильтруете свои данные о продажах, чтобы включить только эти два продукта. Этот вид фильтра является примером сложного фильтра, и у вас, вероятно, уже есть примеры этого на ваших собственных информационных панелях.
На панели инструментов вы можете перейти в режим фокусировки этого визуального элемента, чтобы применить эти фильтры, и нажмите Получить статистику , чтобы узнать больше интересных вещей, отфильтрованных только по этим категориям продуктов. Другими словами, все автоматически созданные визуальные эффекты будут включать только один или оба этих продукта.
В этом примере, когда вы это сделаете, вы обнаружите два магазина, которые имеют наибольшие продажи для этих двух категорий продуктов …
, а также магазин, который имеет наименьшие продажи для этих двух категорий продуктов.
Оба автоматически созданных визуальных элемента полезны для определения проблемы. Теперь вы можете связаться с этими магазинами, чтобы узнать, что они делают по-другому. Вы также можете дополнительно отфильтровать визуальные эффекты по этим магазинам и, возможно, найти новые потенциальные клиенты, которые помогут вам определить правильную область проблемы / улучшения.
Вот несколько примеров сложных фильтров, автоматически сгенерированных Insights, которые понимают:
- Фильтры с , а не
- Фильтры с в и без
- Фильтры с содержат и не содержат
- Фильтры с между и не между
- Фильтры с начинаются с и не начинаются с
- Фильтры с меньше , меньше или равно , больше и т. Д.
- Фильтры для дат с на или после , на или до и т. Д.
- Фильтры для относительной даты и времени, которые устанавливаются через QnA, например, за последние 3 месяца i
- Любая комбинация этих фильтров, простые фильтры и фильтры сбора
Совет: Знаете ли вы, что в режиме фокусировки можно дополнительно фильтровать визуальные элементы? Попробуйте щелкнуть полосу, линию или выбрать элемент из легенды. Когда вы запускаете аналитику после визуальной фильтрации, вы обнаружите вещи, относящиеся к отфильтрованному элементу.
Комплексные фильтры | Документация по продукту
Фильтры, которые являются частью отчета, предоставляют ограниченные возможности, когда дело доходит до выражений, относящихся к иерархиям отчетов. Можно расширить фильтры в вашем отчете, чтобы разрешить общие ссылки на иерархии. Они могут быть, а могут и не быть частью текущих выборок отчетов.
Составные фильтры отчетов
Составная группа фильтров содержит фильтры на уровне иерархии, отличном от уровня (уровней) иерархии, связанных с иерархиями, выбранными в данный момент для полей в отчете.Это расширяет текущие группы фильтров, доступные для отчетов. Например, отчет с одной иерархией с иерархией под названием Моя иерархия в настоящее время может иметь фильтры, относящиеся к иерархии под названием Моя иерархия . С фильтрами составных запросов в отчете могут быть фильтры, ссылающиеся на иерархии, отличные от Моя иерархия .
В качестве другого примера, отчет без каких-либо иерархий может иметь составные фильтры, которые ссылаются на любую доступную иерархию. В этом отчете вывод не отображается в иерархическом формате только потому, что он содержит фильтры иерархии.
Фильтр структур данных
Структуры данных, которые влияют на доступ к фильтрам:
- Группы фильтров — это наборы фильтров, связанных с отчетом
- Макеты отчета — это макеты, содержащие выбор полей и уровни иерархии для отчета
- Фильтр — это объекты, содержащие соединение, имя поля, оператор и уровень иерархии .
В отчете без иерархии есть одна группа фильтров, единый макет отчета, и фильтры не имеют уровня иерархии (точнее, уровень иерархии равен нулю).
В одноуровневом отчете иерархии — обычно отчете типа «родитель-потомок» — есть одна группа фильтров, один макет отчета для каждого уровня иерархии, и каждый фильтр относится к уровню внутри иерархии.
В отчете с несколькими иерархиями одна группа фильтров состоит из набора фильтров для каждого уровня иерархии. Коллекции фильтров сгруппированы по уровню иерархии. Для первой иерархии могут быть фильтры на верхнем уровне. Эти фильтры верхнего уровня распространяются на все другие иерархии до запуска отчета.Для фильтров в иерархиях после первого НЕ могут быть указаны фильтры верхнего уровня иерархии
Пользовательский интерфейс в редакторах отчетов
Пользовательский интерфейс для определения составных фильтров в отчете аналогичен интерфейсу, используемому для отчетов с несколькими иерархиями. Существует флажок Составной фильтр , который включает эту функцию и позволяет определять составные фильтры иерархии на экране.
Результирующая группа фильтров из графического интерфейса пользователя должна быть сгенерирована следующим образом:
- Каждый фильтр может иметь свой собственный уровень иерархии
- Для уровней составной иерархии выбор поля не требуется.
- Для каждой иерархии фильтров фильтры для этой иерархии упорядочены по их положению на экране редактора отчетов, сверху вниз
- Уровень иерархии для составного фильтра может быть любым уровнем в связанной иерархии, включая верхний уровень.
Комплексные фильтры | База знаний RiskVision
Фильтр может быть таким же простым, как Установка равно 1 , но более сложные фильтры могут использоваться в отчетах или для управления доступом.
Встроенный редактор фильтров можно использовать для добавления условий к фильтру по одному. Эти условия фильтрации добавляются с помощью логических операторов И или ИЛИ . По умолчанию оператор И имеет более высокий приоритет, чем оператор ИЛИ .Редактор фильтров не позволяет пользователю изменять приоритет (обычно это делается путем добавления скобок).
Пример
У вас настроен следующий фильтр: Вкладка «Условия» фильтра.
Фильтр в этом примере преобразуется в:
Имя объекта начинается с agl И Тип объекта = Компьютер ИЛИ Тип объекта = Приложение И Имя организации = Acme
Поскольку оператор И имеет более высокий приоритет, чем оператор ИЛИ вышеупомянутый фильтр означает:
(Имя объекта начинается с agl И Тип объекта = Компьютер) ИЛИ (Тип объекта = Приложение И Имя организации = Acme)
То есть сначала выполняются операции И .
Если вы хотите, чтобы этот фильтр оценивался как:
(Имя объекта начинается с agl) И (Тип объекта = Компьютер ИЛИ Тип объекта = Приложение) И (Название организации = Acme)
Это невозможно сделать непосредственно с помощью редактора фильтров. Это необходимо сделать с помощью оператора Matches Filter . Чтобы реализовать указанный выше фильтр, необходимо создать фильтр объектов компьютера или приложения для условия (Тип объекта = Компьютер ИЛИ Тип объекта = Приложение).
Фильтр компьютеров или приложений.
Исходный фильтр будет использовать фильтр «Компьютер или приложение» с помощью оператора Соответствует фильтру .
Сначала добавьте условие Name Equals agl . Используйте оператор Matches Filter , чтобы добавить фильтр Computer или Application Entities. Обратите внимание, что в первом раскрывающемся списке редактора фильтров необходимо выбрать фиктивную запись.