Что такое язык ассемблера и для чего он используется. Как выглядит синтаксис ассемблера. Из каких основных частей состоит программа на ассемблере. Какие инструменты нужны для разработки на ассемблере. Как написать и скомпилировать простейшую программу «Hello World» на ассемблере.
Что такое язык ассемблера
Ассемблер — это низкоуровневый язык программирования, который имеет прямое соответствие с машинным кодом конкретного процессора. Основные особенности ассемблера:
- Для каждой архитектуры процессора существует свой ассемблер
- Программист работает напрямую с регистрами и памятью процессора
- Команды ассемблера (мнемоники) преобразуются в машинные инструкции процессора
- Позволяет создавать очень эффективный код, но сложен в разработке
- Используется, когда важна максимальная производительность программы
Для эффективного программирования на ассемблере необходимо хорошо знать архитектуру целевого процессора и компьютера в целом.
Синтаксис языка ассемблера
Программа на ассемблере состоит из отдельных строк, каждая из которых имеет следующий общий формат:

[метка:] [мнемоника] [операнды] [; комментарий]
Где:
- Метка — необязательное символьное имя строки кода
- Мнемоника — название команды процессора
- Операнды — аргументы команды (регистры, адреса памяти, константы)
- Комментарий — пояснения к коду (после символа 😉
Не все поля обязательны в каждой строке. Команды и операнды зависят от конкретной архитектуры процессора.
Структура программы на ассемблере
Типичная программа на ассемблере для x86 процессоров состоит из следующих основных частей:
- Директивы ассемблера (модель памяти, размер стека и т.д.)
- Сегмент данных (.data) — для объявления переменных
- Сегмент кода (.code) — содержит исполняемый код программы
- Сегмент стека (.stack) — для выделения памяти под стек
- Точка входа в программу
Сегменты позволяют разделить код, данные и стек программы в памяти. Модель памяти определяет, как именно они будут размещены.
Инструменты для разработки на ассемблере
Для создания программ на ассемблере требуются следующие инструменты:
- Ассемблер — транслирует исходный код в объектные файлы (например, TASM, NASM)
- Компоновщик — связывает объектные файлы в исполняемую программу (например, TLINK)
- Текстовый редактор — для написания исходного кода
- Отладчик — для пошаговой отладки программы (например, TD)
Существуют также интегрированные среды разработки (IDE), объединяющие все эти инструменты.

Пример простой программы на ассемблере
Рассмотрим классическую программу «Hello World» на ассемблере для DOS:
.model small
.stack 100h
.data
hello db 'Hello, World!$'
.code
start:
mov ax, @data
mov ds, ax
mov ah, 09h
mov dx, offset hello
int 21h
mov ax, 4C00h
int 21h
end start
Эта программа выводит на экран строку «Hello, World!» с помощью функции DOS. Основные шаги:
- Объявление модели памяти и размера стека
- Определение строки в сегменте данных
- Инициализация сегментного регистра DS
- Вызов функции DOS для вывода строки
- Завершение программы
Основные регистры процессора x86
Процессоры x86 имеют следующие основные регистры:
- Регистры общего назначения: AX, BX, CX, DX
- Индексные регистры: SI, DI
- Указатели: SP (стек), BP (кадр стека)
- Сегментные регистры: CS, DS, SS, ES
- Регистр флагов: FLAGS
- Счетчик команд: IP
Понимание назначения и использования этих регистров критически важно для программирования на ассемблере.
Способы адресации в ассемблере
Ассемблер x86 поддерживает различные способы адресации операндов:
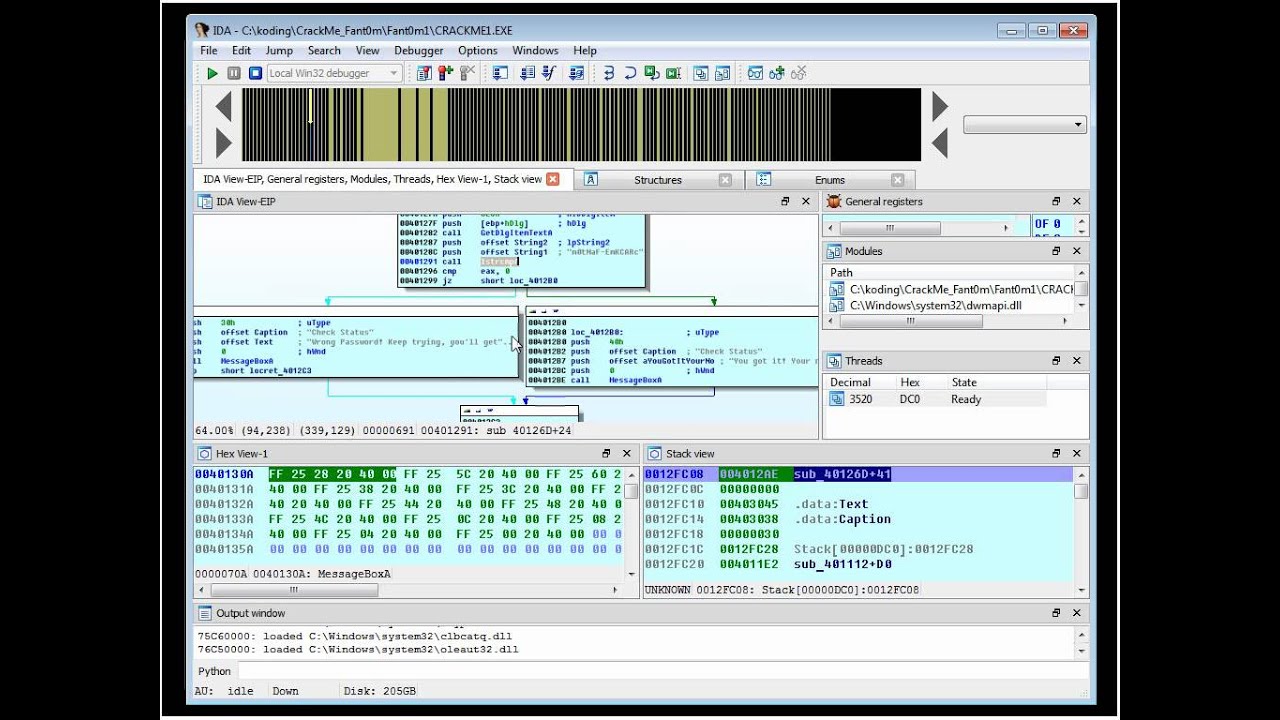
- Регистровая адресация — операнд находится в регистре
- Непосредственная адресация — операнд задан в самой команде
- Прямая адресация — адрес операнда задан в команде
- Косвенная адресация — адрес операнда вычисляется во время выполнения
- Базовая адресация — адрес вычисляется относительно базового регистра
- Индексная адресация — используется индексный регистр
Правильный выбор способа адресации может значительно повлиять на эффективность кода.
Основные команды ассемблера x86
Некоторые часто используемые команды ассемблера x86:
- MOV — копирование данных
- ADD, SUB — сложение и вычитание
- INC, DEC — увеличение и уменьшение на 1
- CMP — сравнение
- JMP — безусловный переход
- Jcc — условные переходы (JE, JNE, JG и т.д.)
- CALL, RET — вызов и возврат из подпрограммы
- PUSH, POP — работа со стеком
Каждая команда имеет свои особенности использования и влияния на флаги процессора.
Заключение
Ассемблер — мощный инструмент для создания высокоэффективного кода, но требует глубокого понимания архитектуры процессора и компьютера в целом. Несмотря на сложность, навыки программирования на ассемблере могут быть полезны даже при работе с высокоуровневыми языками, особенно при оптимизации критических участков кода.
2.2. Псевдо-инструкции
2.2. Псевдо-инструкции
Псевдо-инструкции не являются реальными
инструкциями х86 процессора, но все равно
помещаются в поле инструкций, т.к. это наиболее
подходящее место для них. Текущими псевдо-инструкциями
являются
DB, DW,
DD, DQ, DT, DDQ и DO,
их копии для работы с неинициализированной
памятью RESB, RESW,
RESD, RESQ, REST, RESDDQ и RESO, команды INCBIN, EQU и префикс TIMES.
2.2.1.
DB и ее друзья: Объявление
инициализированных данных
DB, DW, DD, DQ, DT,
DDQ и DO используются для
объявления инициализированных данных в
выходном файле. Они могут использоваться
достаточно многими способами:
db 0x55 ; просто байт 0x55
db 0x55,0x56,0x57 ; последовательно 3 байта
db 'a',0x55 ; символьная константа
db 'hello',13,10,'$' ; это строковая константа
dw 0x1234 ; 0x34 0x12
dw 'a' ; 0x41 0x00 (это просто число)
dw 'ab' ; 0x41 0x42 (символьная константа)
dw 'abc' ; 0x41 0x42 0x43 0x00 (строка)
dd 0x12345678 ; 0x78 0x56 0x34 0x12
dq 0x1122334455667788 ;0x88 0x77 0x66 0x55 0x44 0x33 0x22 0x11
ddq 0x112233445566778899aabbccddeeff00
; 0x00 0xff 0xee 0xdd 0xcc 0xbb 0xaa 0x99
; 0x88 0x77 0x66 0x55 0x44 0x33 0x22 0x11
do 0x112233445566778899aabbccddeeff00 ;то же самое как предыдущий
dd 1.
234567e20 ; константа с плавающей точкой
dq 1.234567e20 ; двойной точности
dt 1.234567e20 ; расширенной точности
DT не допускает в качестве операндов
числовые
константы, а DDQ — констант с
плавающей запятой. Любой размер больше чем
DD не
допускает строк в качестве операндов.
2.2.2.
RESB и ее друзья: Объявление
неинициализированных данных
RESB, RESW, RESD,
RESQ, REST, RESDQ и RESO
разработаны для использования в BSS-секции
модуля: они объявляют неинициализированное
пространство для хранения данных. Каждая
принимает один операнд, являющийся числом
резервируемых байт, слов, двойных слов и т.д. NASM
не поддерживает синтаксис резервирования
неинициализированного пространства,
реализованный в MASM/TASM, где можно делать DW ? или подобные вещи: это заменено
полностью. Операнд псевдо-инструкций класса
Операнд псевдо-инструкций класса
RESB является критическим выражением: см.
Раздел 2.8.
Например:
buffer: resb 64 ; резервирование 64 байт wordvar: resw 1 ; резервирование слова realarray resq 10 ; массив из 10 чисел с плавающей точкой
2.2.3.
INCBIN: Включение внешних бинарных
файлов
INCBIN
дословно включает бинарный файл в выходной файл.
Это может быть полезно (например) для включения
картинок и
музыки
непосредственно в исполняемый файл игрушки.
Однако, это рекомендуется делать только для
_небольших_ порции данных. Эта псевдо-инструкция
может быть вызвана тремя разными способами:
incbin "file.dat" ; включение файла целиком
incbin "file.dat",1024 ; пропуск первых 1024 байт
incbin "file.dat",1024,512 ; пропуск первых 1024 и
; включение следующих 512 байт
2.
 2.4.
2.4.
EQU: Определение констант
EQU определяет символ для указанного
константного значения: если используется EQU, в этой строке кода должна
присутствовать метка. Смысл `EQU`— связать имя
метки со значением ее (только) операнда. Данное
определение абсолютно и не может быть позднее
изменено. Например,
message db 'Привет, фуфел' msglen equ $-message
определяет msglen как константу 13.
msglen не может быть позднее
переопределено. Это не определение препроцессора: значение
msglen обрабатывается здесь только один раз при помощи
значения $ (что такое $ – см. Раздел 2.6) в месте определения,
вместо того, чтобы обрабатыватся везде, где на
это ссылаются, при помощи значения $ в месте ссылки. Имейте в виду, что
операнд EQU также является критическим
выражением (Раздел 2.8).
2.2.5.
TIMES: Повторение инструкций или
данных
Префикс Данная псевдо-инструкция отчасти
представляет NASM-эквивалент синтаксиса
DUP,
поддерживающегося MASM-совместимыми
ассемблерами. Вы можете написать, например
zerobuf: times 64 db 0
или что-то подобное; однако TIMES
более разносторонняя инструкция. Аргумент
TIMES — не просто числовая
константа, а числовое выражение, поэтому вы можете
писать следующие вещи:
buffer: db 'Привет, фуфел'
times 64-$+buffer db ' '
При этом будет резервироваться строго
определенное пространство, чтобы сделать полную
длину buffer до 64 байт. Наконец,
TIMES может использоваться в
обычных инструкциях, так что вы можете писать
тривиальные развернутые циклы:
times 100 movsb
Заметим, что нет никакой принципиальной
разницы между times 100 resb 1 и resb 100 за исключением того, что последняя
инструкция будет обрабатываться примерно в 100
раз быстрее из-за внутренней структуры
ассемблера.
Операнд псевдо-инструкции TIMES,
подобно EQU, RESB и
ее друзьям, является критическим выражением
(Раздел 2.8).
Имейте также в виду, что TIMES не
применима в макросах: причиной служит то, что
TIMES обрабатывается после
макро-фазы, позволяющей аргументу TIMES содержать выражение, подобное
64-$+buffer. Для повторения более
одной строки кода или в сложных макросах
используйте директиву препроцессора %rep.
TASM
Разработка и отладка программ на языке Ассемблера
Изучение языка ассемблера целесообразнее всего начать с разработки простой программы, например, такой:
text segment ;(1)Начало сегмента команд
assume CS:text,DS:data ;(2)Сегментный регистр CS будет указывать на сегмент
;команд, а сегментный регистр DS - на сегмент данных
begin: mov AX,data ;(3)Адрес сегмента данных сначала загрузим в АХ,
mov DS,AX ;(4)а затем перенесем из АХ в DS
mov AH,09h ;(5)Функция DOS 9h вывода на экран
mov DX,offset mesg ;(6)Адрес выводимого сообщения должен быть в DX
int 21h ;(7)Вызов DOS
mov AH,4Ch ;(8)Функция 4Ch завершения программы
mov AL, 0 ;(9)Код 0 успешного завершения
int 21h ;(10)Вызов DOS
text ends ;(11)Конец сегмента команд
data segment ;(12)Начало сегмента данных
mesg db 'Начинаем!$' ;(13)Выводимый текст
data ends ;(14)Конец сегмента данных
stk segment stack ;(15)Начало сегмента стека
db 256 dup (0) ;(16)Резервируем 256 байт для стека
stk ends ;(17)Конец сегмента стека
end begin ;(18)Конец текста программы с точкой входа
Данная программа ничего не вычисляет и не обрабатывает, а всего лишь выводит на экран терминала
строку с фразой «Начинаем!».
Чтобы создать такую программу и увидеть, как она работает, на компьютере должен быть установлен набор программ Turbo Assembler, позволяющий создавать из представленного исходного текста программы исполнимый файл, представляющий собой готовую программу, которую можно запускать на исполнение. Обычно такой набор программ расположен в каталоге TASM. Если на вашем компьютере такого набора нет его можно скачать здесь. Данный файл представляет собой архив, содержащий каталог, в котором находится требуемый набор программ. Разверните этот каталог на вашем компьютере в удобном для вас месте. Используя Блокнот создайте в этом каталоге файл, содержащий представленную программу и сохраните его с прозвольным именем и расширением asm.
Следует заметить, что при вводе исходного текста программы с клавиатуры можно использовать как прописные, так и строчные буквы: транслятор воспринимает их одинаково.
Содержимое строк достаточно вводить до точки с запятой, означающих начало комментария.
Прежде чем продолжить работу с программой внимательно прочтите следующее краткое описание того, как работает данная программа.
Программа содержит 18 строк-предложений языка ассемблера. Первое предложение с помощью оператора segment открывает сегмент команд программы. Сегменту дается произвольное имя text. В конце предложения после точки с запятой располагается комментарий. Предложение языка ассемблера может состоять из четырех полей: имени, оператора, операндов и комментария, располагаемых в перечисленном порядке. Не все поля обязательны; так, в предложении 1 есть только имя, оператор и комментарий, а операнды отсутствуют; предложение 3 включает все 4 компонента: имя begin, оператор (команда процессора) mov, операнды этой команды АХ и data и, наконец, после точки с запятой комментарий; в предложении 4 (и многих последующих) отсутствует имя.
Любая программа должна обязательно состоять из сегментов — без сегментов
программ не бывает. Обычно в программе задаются три сегмента: команд, данных и стека.
В сегменте команд располагается собственно программа, т. е. описание (с помощью
команд процессора) последовательности требуемых действий. В сегменте данных
описываются данные, с которыми должна работать программа; в нашем примере это
строка текста. Назначение сегмента стека будет описано ниже.
Обычно в программе задаются три сегмента: команд, данных и стека.
В сегменте команд располагается собственно программа, т. е. описание (с помощью
команд процессора) последовательности требуемых действий. В сегменте данных
описываются данные, с которыми должна работать программа; в нашем примере это
строка текста. Назначение сегмента стека будет описано ниже.
В предложении 2 с помощью оператора assume сообщается ассемблеру
(ассемблером называется программа-транслятор, преобразующая исходный текст
программы в коды команд процессора), что сегментный регистр CS будет указывать
на сегмент команд text, а сегментный регистр DS — на сегмент данных data.
Сегментные регистры (а всего их в процессоре 4) играют очень важную роль. Когда
программа загружается в память и становится известно, по каким адресам памяти она
располагается, в сегментные регистры заносятся начальные адреса закрепленных за
ними сегментов. В дальнейшем любые обращения к ячейкам программы
осуществляются путем указания сегмента, в котором находится интересующая нас ячейка, а
также номера того байта внутри сегмента, к которому мы хотим обратиться. Этот
номер носит название относительного адреса или смещения. Транслятор должен знать
заранее, через какие сегментные регистры будут адресоваться ячейки программы, и мы
сообщаем ему об этом с помощью оператора assume (assume — предположим). При
этом в регистр CS адрес начала сегмента будет загружен автоматически, а регистр DS
нам придется инициализировать вручную. Обращение к стеку осуществляется особым
образом, и ставить ему в соответствие сегментный регистр (конкретно — сегментный
регистр SS) нет необходимости.
Этот
номер носит название относительного адреса или смещения. Транслятор должен знать
заранее, через какие сегментные регистры будут адресоваться ячейки программы, и мы
сообщаем ему об этом с помощью оператора assume (assume — предположим). При
этом в регистр CS адрес начала сегмента будет загружен автоматически, а регистр DS
нам придется инициализировать вручную. Обращение к стеку осуществляется особым
образом, и ставить ему в соответствие сегментный регистр (конкретно — сегментный
регистр SS) нет необходимости.
Первые два предложения программы служат для передачи служебной информации
программе ассемблера. Ассемблер воспринимает и запоминает эту информацию и
пользуется ею в своей дальнейшей работе. Однако в состав выполнимой программы, состоящей из
машинных кодов, эти строки не попадут, так как процессору, выполняющему программу,
они не нужны. Другими словами, операторы segment и assume не транслируются в
машинные коды, а используются лишь самим ассемблером на этапе трансляции программы. Такие
нетранслируемые операторы иногда называют псевдооператорами или директивами
ассемблера в отличие от истинных операторов — команд языка.
Такие
нетранслируемые операторы иногда называют псевдооператорами или директивами
ассемблера в отличие от истинных операторов — команд языка.
Предложение 3, начинающееся с метки begin, является первой выполнимой строкой программы. Для того чтобы процессор знал, с какого предложения начать выполнять программу после ее загрузки в память, начальная метка программы указывается в качестве операнда самого последнего оператора программы end (см. предложение 18).
Начиная от точки входа программа выполняется строка за строкой точно в том порядке, в каком эти строки написаны программистом.
В предложениях 3 и 4 выполняется инициализация сегментного регистра DS.
Сначала значение имени text (т. е. адрес сегмента text) загружается командой mov (от
move — переместить) в регистр общего назначения процессора АХ, а затем из регистра’
АХ переносится в регистр DS. Такая двухступенчатая операция нужна потому, что
процессор в силу некоторых особенностей своей архитектуры не может выполнить
команду непосредственной загрузки адреса в сегментный регистр.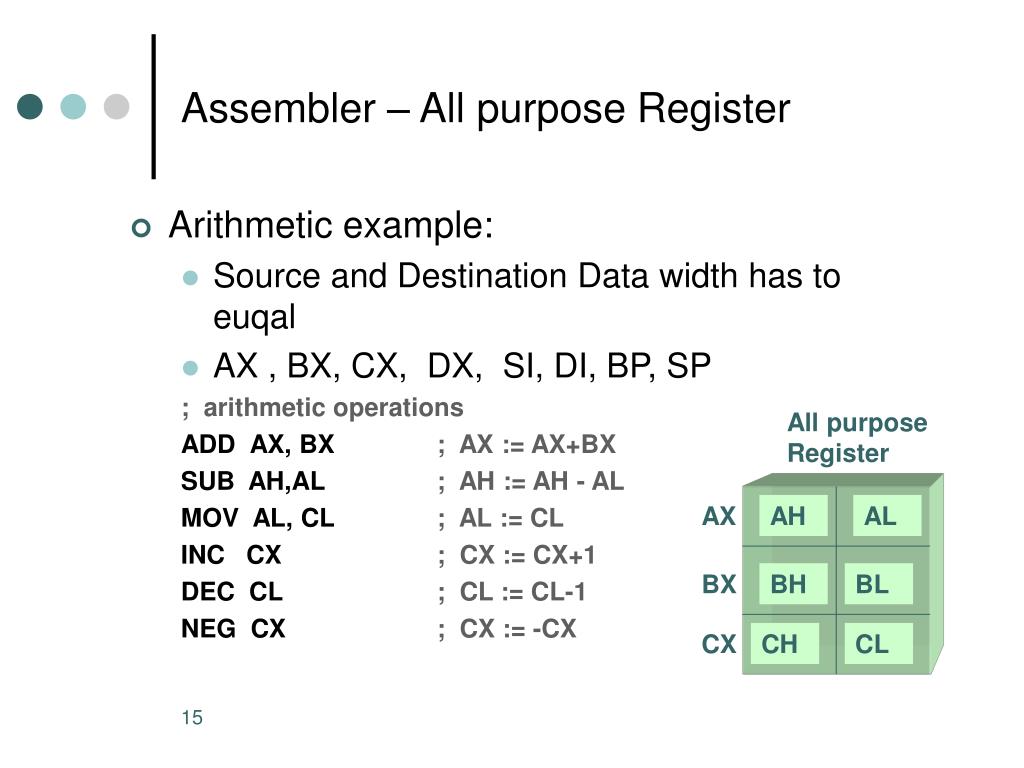 Приходится
пользоваться регистром АХ в качестве «перевалочного пункта».
Приходится
пользоваться регистром АХ в качестве «перевалочного пункта».
Предложения 5, 6 и 7 реализуют существо программы — вывод на экран строки
текста. Делается это не непосредственно, а путем обращения к служебным
программам операционной системы MS-DOS. Дело в том, что в составе команд процессора и,
соответственно, операторов языка ассемблера нет команд вывода данных на экран
(как и команд ввода с клавиатуры, записи в файл на диске и т. д.).
Вывод даже одного символа на экран в действительности представляет собой довольно сложную операцию, для выполнения
которой требуется длинная последовательность команд процессора. Конечно, эту
последовательность команд можно было бы включить в нашу программу, однако гораздо
проще обратиться за помощью к операционной системе. В состав DOS входит большое
количество программ, осуществляющих стандартные и часто требуемые функции — вывод
на экран и ввод с клавиатуры, запись в файл и чтение из файла, чтение или установка
текущего времени, выделение или освобождение памяти и многие другие.
Для того чтобы обратиться к DOS, надо загрузить в регистр общего назначения АН номер требуемой функции, в другие регистры — исходные данные для выполнения этой функции, после чего выполнить команду int 2lh, (int — от interrupt — прерывание), которая передаст управление DOS. Вывод на экран строки текста можно осуществить с помощью различных функций DOS; мы воспользовались функцией 09h, которая требует, чтобы в регистре DX содержался адрес выводимой строки. В предложении 6 адрес строки mesg загружается в регистр DX, а в предложении 7 осуществляется вызов DOS.
В предложениях 5 и 7 указанные в тексте программы числа сопровождаются знаком h. Таким образом в языке ассемблера обозначаются шестнадцатеричные (далее — 16-ричные) числа, в отличие от десятичных, которые никакого завершающего знака не требуют.
После окончания работы программы DOS должна
выполнить некоторые служебные действия. Надо освободить занимаемую нашей
программой память, чтобы туда можно было загрузить следующую программу. Надо
вызвать компонент операционной системы, который выведет на экран запрос DOS (как
правило, в виде символа >, предваряемого именем текущего каталога) и будет ждать
следующей команды оператора. Все эти действия выполняет функция DOS с номером
4Ch. Эта функция предполагает, что в регистре AL находится код завершения нашей
программы, который она передаст DOS. Если программа завершилась успешно, код завершения
должен быть равен нулю, поэтому в предложении 9 мы загружаем 0 в регистр AL и
вызываем DOS уже знакомой нам командой int 21h. Поскольку выполняемая часть
программы на этом закончилась, можно (и нужно) закрыть сегмент команд, что
выполняется с помощью директивы ends (от end segment, конец сегмента), перед
которой для наглядности обычно указывается имя закрываемого сегмента, в данном
случае сегмента text.
Надо
вызвать компонент операционной системы, который выведет на экран запрос DOS (как
правило, в виде символа >, предваряемого именем текущего каталога) и будет ждать
следующей команды оператора. Все эти действия выполняет функция DOS с номером
4Ch. Эта функция предполагает, что в регистре AL находится код завершения нашей
программы, который она передаст DOS. Если программа завершилась успешно, код завершения
должен быть равен нулю, поэтому в предложении 9 мы загружаем 0 в регистр AL и
вызываем DOS уже знакомой нам командой int 21h. Поскольку выполняемая часть
программы на этом закончилась, можно (и нужно) закрыть сегмент команд, что
выполняется с помощью директивы ends (от end segment, конец сегмента), перед
которой для наглядности обычно указывается имя закрываемого сегмента, в данном
случае сегмента text.
Вслед за сегментом команд описывается сегмент данных. Он, как и сегмент
команд, начинается директивой segment, предваряемой произвольным именем нашего
сегмента, и заканчивается директивой ends. У нас в качестве данных выступает строка
текста. Текстовые строки вводятся в программу с помощью директивы ассемблера db
(от define byte, определить байт) и заключаются в апострофы или в кавычки. Для того
чтобы в программе можно было обращаться к данным, поля данных, как правило,
предваряются именами. В нашем случае таким именем является вполне произвольное
обозначение mesg (от message, сообщение), с которого начинается предложение 13.
У нас в качестве данных выступает строка
текста. Текстовые строки вводятся в программу с помощью директивы ассемблера db
(от define byte, определить байт) и заключаются в апострофы или в кавычки. Для того
чтобы в программе можно было обращаться к данным, поля данных, как правило,
предваряются именами. В нашем случае таким именем является вполне произвольное
обозначение mesg (от message, сообщение), с которого начинается предложение 13.
Выше, в предложении 6, мы через регистр DX передали DOS адрес начала
выводимой на экран строки текста. Но как DOS определит, где эта строка закончилась?
Хотя нам конец строки в программе отчетливо виден, однако в машинных кодах, из
которых состоит выполнимая программа, он никак не отмечен, и DOS, выведя ча экран
последний символ строки — восклицательный знак, продолжит вывод байтов памяти,
расположенных за фразой «Начинаем!». Поэтому DOS следует передать информацию о
том, где кончается строка текста. Некоторые функции DOS требуют указания в одном
из регистров длины выводимой строки, однако функция 09h работает иначе. Она
выводит текст до знака доллара ($), которым мы и завершили нашу фразу.
Некоторые функции DOS требуют указания в одном
из регистров длины выводимой строки, однако функция 09h работает иначе. Она
выводит текст до знака доллара ($), которым мы и завершили нашу фразу.
Сегмент стека, которому мы дали произвольное имя stk, начинается, как и остальные сегменты, оператором segment и заканчивается оператором ends. Стек представляет собой отдельный сегмент обычно небольшого объема, в котором просто резервируется определенное количество пустых байтов. Для выделения в программе группы байтов используется конструкция
db размер dup (заполнитель)
В нашем примере для стека выделено 256 байт, заполненных нулями.
Оператор segment, начинающий сегмент стека, имеет описатель stack. Указание
этого обозначения приводит к тому, что при загрузке программы в память регистры
процессора, используемые для работы со стеком, инициализируются системой
должным образом. Конкретно, сегментный регистр стека SS будет настроен на начало
сегмента стека, а указатель стека SP — на его конец (стек
заполняется данными от конца к началу).
Последняя строка программы содержит директиву end, которая говорит программе ассемблера, что закончился вообще весь текст программы и больше ничего транслировать не нужно. В качестве операнда этой директивы, как уже отмечалось, обычно указывается точка входа в программу, т. е. адрес первой выполнимой программной строки. В нашем случае это метка begin.
Введение в язык Ассемблера | Assembler | Статьи | Программирование Realcoding.Net
<!—StartFragment —>Автор: Бардин П.Б., http://proger.ru
mailto:[email protected]
8 октября 2003 г.
Что такое Ассемблер
Ассемблер — низкоуровневый язык программирования. Для каждого процессора существует свой ассемблер. Программируя на ассемблере вы непосредственно работаете с аппаратурой компьютера. Исходный текст на языке ассемблера состоит из команд (мнемоник), которые после компиляции преобразуются в коды команд процессора.
Разработка программ на ассемблере — очень
тяжёлая штука. Взамен потраченному времени
вы получаете эффективную программу.
Программы на ассемблере пишут, когда важен
каждый такт процессора. На ассемблере вы
даёте конкретные команды процессору и
никакого лишнего мусора. Этим и достигается
высокая скорость выполнения вашей
программы.
Взамен потраченному времени
вы получаете эффективную программу.
Программы на ассемблере пишут, когда важен
каждый такт процессора. На ассемблере вы
даёте конкретные команды процессору и
никакого лишнего мусора. Этим и достигается
высокая скорость выполнения вашей
программы.
Чтобы грамотно использовать ассемблер необходимо знать программную модель микропроцессорной системы. С точки зрения программиста микропроцессорная система состоит из:
- Микропроцессора
- Памяти
- Устройств ввода/вывода.
Программная модель хорошо описана в литературе [1].
Синтаксис Ассемблера
Общий формат строки программы на ассемблере
<Метка>: <Оператор> <Операнды> ; <Комментарий>
Поле метки. Метка может состоять из символов и знаков подчёркивания. Метки используются в операциях условного и безусловного перехода.
Поле оператора. В этом поле содержится мнемоника команды. Например мнемоника mov
Поле операндов. Операнды могут
присутствовать только если присутствует
Оператор (поле оператора). Операндов может
не быть, а может быть несколько. Операндами
могут быть данные, над которыми необходимо
выполнить какие-то действия (переслать,
сложить и т.д.).
Операнды могут
присутствовать только если присутствует
Оператор (поле оператора). Операндов может
не быть, а может быть несколько. Операндами
могут быть данные, над которыми необходимо
выполнить какие-то действия (переслать,
сложить и т.д.).
Поле комментария. Комментарий нужен для словесного сопровождения программы. Всё, что стоит за символом ; считается комментарием.
Первая программа на языке Ассемблера
В этой статье будет использоваться ассемблер для i80x86 процессора и использоваться следующее программное обеспечение:
- TASM — Borland Turbo Assembler — компилятор
- TLINK — Borland Turbo Linker — редактор связей ( компоновщик )
Если быть конкретным, то Tasm 2.0.
По традиции наша первая программа будет выводить строку «Hello world!» на экран.
Файл sample.asm
.model small ; Модель памяти .stack 100h ; Установка размера стека .data ; Начало сегмента данных программы HelloMsg DB "Hello World!",13,10,"$" .code ; Начало сегмента кода mov ax,@DATA ; Пересылаем адрес сегмента данных в регистр AX mov ds,ax ; Установка регистра DS на сегмент данных mov ah,09h ; DOS функция вывода строки на экран mov dx,offset HelloMsg ; Задаём смещение к началу строки int 21h ; Выводим строку mov ax,4C00h ; DOS функция выхода из программы int 21h ; Выход из программы end
Как вы могли заметить, что программа разделена на сегменты: сегмент данных, сегмент кода и есть ещё стековый сегмент.
Рассмотрим всё по порядку.
Директива .model small задаёт модель памяти. Модель small — это 1 сегмент для кода, 1 сегмент для данных и стека т.е. данные и стек находятся в одном сегменте. Бывают и другие модели памяти, например: tiny, medium, compact. В зависимости от выбранной вами модели памяти сегменты вашей программы могут перекрываться или могут иметь отдельные сегменты в памяти.
Директива .stack 100h задаёт размер стека. Стек
необходим для сохранения некоторой
информации с последующим её
восстановлением. В частности стек
используется при прерываниях. В этом случае
содержимое регистра флагов FLAGS, регистра CS и
регистра IP сохраняются в стеке. Далее идёт
выполнение прерывающей программы, а потом
идёт восстановление значений этих
регистров.
В частности стек
используется при прерываниях. В этом случае
содержимое регистра флагов FLAGS, регистра CS и
регистра IP сохраняются в стеке. Далее идёт
выполнение прерывающей программы, а потом
идёт восстановление значений этих
регистров.
- Регистр флагов FLAGS содержит признаки, которые формируются после выполнения команды процессором.
- Регистр CS (Code Segment) содержит адрес сегмента кода.
- Регистр IP (Instruction Pointer) — указатель команд. Он содержит адрес команды, которая должная выполниться следующей (Адрес относительно сегмента кода CS).
Более подробное описание выходит за рамки простой статьи.
Директива .data определяет начало сегмента
данных вашей программы. В сегменте данных
определяются «переменные» т.е. идёт
резервирование памяти под необходимые
данные. После .data идёт строка
HelloMsg DB «Hello World!»,13,10,»$»
Здесь HelloMsg — это символьное имя, которое
соответствует началу строки «Hello World!» (без
кавычек). То есть это адрес первого символа
нашей строки относительно сегмента данных.
Директива DB (Define Byte) определяет область
памяти доступную по-байтно. 13,10 — коды
символов Новая строка и Возврат каретки, а
символ $ необходим для корректной работы DOS
функции 09h. Итак, наша строка будет занимать
в памяти 15 байт.
То есть это адрес первого символа
нашей строки относительно сегмента данных.
Директива DB (Define Byte) определяет область
памяти доступную по-байтно. 13,10 — коды
символов Новая строка и Возврат каретки, а
символ $ необходим для корректной работы DOS
функции 09h. Итак, наша строка будет занимать
в памяти 15 байт.
Директива .code определяет начало сегмента кода (CS — Code Segment) программы. Далее идут строки программы содержащие мнемоники команд.
Расскажу о команде mov.
mov <приёмник>, <источник>
Команда mov — команда пересылки. Она пересылает содержимое источника в приёмник. Пересылки могут быть регистр-регистр, регистр-память, память-регистр, а вот пересылки память-память нет т.е. всё проходит через регистры процессора.
Чтобы работать с данными необходимо
настроить регистр сегмента данных.
Настройка состоит в том, что мы записываем
адрес сегмента данных @DATA в регистр DS (Data
Segment). Непосредственно записать адрес в этот
регистр нельзя — такова архитектура,
поэтому мы используем регистр AX. В AX мы
записываем адрес сегмента кода
В AX мы
записываем адрес сегмента кода
mov ax,@DATA
а потом пересылаем содержимое регистра AX в регистр DS.
mov ds, ax
После этого регистр DS будет содержать адрес начала сегмента данных. По адресу DS:0000h будет содержаться символ H. Я предполагаю, что вы знаете о сегментах и смещениях.
Адрес состоит из двух составляющих <Сегмент>:<Смещение>, где Сегмент это 2 байта и смещение — 2 байта. Получается 4 байта для доступа к любой ячейке памяти.
Далее мы видим:
mov ah,09h
mov dx,offset HelloMsg
int 21h
Тут мы в регистр AH записываем число 09h — номер функции 21-го прерывания, которая выводит строку на экран.
В следующей строке мы в регистр DX записываем адрес(смущение) к началу нашей строки.
Далее мы вызываем прерывание 21h — это прерывание функций DOS. Прерывание — когда выполняющаяся программа прерывается и начинает выполнятся прерывающая программа. По номеру прерывания определяется адрес подпрограммы DOS, которая выводит строку символов на экран.
У вас наверняка возникнет вопрос: А почему
мы записываем номер функции 09h в регистр AH ?
И почему смещение к строке записываем в
регистр DX ?
Ответ простой: для каждой функции
определены конкретные регистры, которые
содержат входные данные для этой функции.
Посмотреть какие регистры нужны конкретным
функциям вы можете в help’е.
Идём дальше:
mov ax,4C00h
int 21h
end
mov ax,4C00h — пересылаем номер функции в регистр AX. Функция 4C00h — выход из программы.
int 21h — выполняем прерывание (собственно выходим)
end — конец программы.
После директивы end компилятор всё игнорирует, поэтому можете там писать всё, что угодно 🙂
Если вы дочитали до конца, то вы герой!
Рекомендуемая литература
[1]. Майко Г.В. Ассемблер для IBM PC: — М.: «Бизнес-Информ», «Сирин» 1999 г. — 212 с.
Ассемблер-EQU вычислить что? — CodeRoad
В следующем коде:
section .data
sa db ’abxdefghxl’,0
la EQU $ - sa
sb db ’abcdexghil’,0
section .text
Как я видел в своей программе, когда я делаю mov ecx, la-тогда я получаю число 11 в ECX.
Я не понял почему-число abxdefghxl не равно 10. Мы тоже считаем 0?
Поделиться Источник Adam Sh 24 марта 2012 в 11:30
2 ответа
-
Assembly 8086 EQU директива
У меня возникли проблемы с тем, чтобы просто прояснить директиву EQU в ассемблере (8086). abc EQU xyz Действительно ли EQU буквально меняет местами abc, когда встречается в коде с xyz, независимо от того, что представляет xyz, значение и т. д.? то есть могу ли я писать? varA EQU [bp+4] mov ax,…
-
Ассемблер sysTime выдает ошибку при выполнении
я изучаю ассемблер (Nasm, Linux, Ubuntu 16.4, x86_64) и получаю проблемы с использованием вызова sys_time (mov eax, 13). section .bss time: resb 30; section .data msg: db The Time is:; msgLen: equ $-msg; blank: db 0x0a; blankLen: equ $-blank; section .text global _start: _start: mov eax, 13; mov…
2
Предположим, что sa начинается с 0x400 . Вы определили 10 ( abxdefghxl ) плюс 1 ( 0 в конце ) И, следовательно, la wwould start at 0x40B . $ представляет текущий адрес инструкции/директивы. Следовательно, $-sa = 0xB или 11
Поделиться Pavan Manjunath 24 марта 2012 в 11:39
1
$ представляет текущую позицию. И поскольку текущая позиция находится после полного объявления «sa», выражение $-sa равно 11. Помните, что в assembly нет такой вещи, как тип данных «string», «sa»-это просто набор байтов.
Поделиться Ville Krumlinde 24 марта 2012 в 11:37
Похожие вопросы:
Создавая простые двоичные данные (не ELF, таблицы символов и т. д.), Используя ассемблер
Я хочу превратить входной файл только для данных, то есть что-то вроде этого: .data .org 0 .equ foo, 42 .asciz foo label: .long 0xffffffff .long 0x12345678 .byte foo .long label .long bar .equ bar,…
ассемблер avr: #define против .equ, это одно и то же?
Это команда avr-c #define baudrate 9600 то же самое, что и команда avr-asm .equ BAUD = 9600 ??
Что EQU делает функционально в этом коде?
Я пытаюсь расшифровать, что на самом деле делает этот файл в старой программе DOS. IDATE EQU I/1/8/0 Date : MM/DD/YY ITIME EQU I/9/8/0 Time : HH:MM:SS IUSER EQU I/17/6/0 User ID : XXX999 ITERM EQU…
Assembly 8086 EQU директива
У меня возникли проблемы с тем, чтобы просто прояснить директиву EQU в ассемблере (8086). abc EQU xyz Действительно ли EQU буквально меняет местами abc, когда встречается в коде с xyz, независимо от…
Ассемблер sysTime выдает ошибку при выполнении
я изучаю ассемблер (Nasm, Linux, Ubuntu 16.4, x86_64) и получаю проблемы с использованием вызова sys_time (mov eax, 13). section .bss time: resb 30; section .data msg: db The Time is:; msgLen: equ…
Как я могу использовать внешний EQU в выражении в MASM 5.10
Я пытаюсь разбить очень большой файл .ASM на несколько внешних библиотек, оставив только мою основную программу в main.asm. Это игра,поэтому я надеялся разделить код ввода с клавиатуры на input.asm,…
Экспресс-константа с плавающей запятой из символического имени EQU
Я программирую в ARM assembly в DS-5 5.28, нацеливаясь на cortex-a8 с плавающей точкой и неоном. При выражении констант с помощью EQU, например M EQU 5 тогда я могу использовать константу в rest…
Что означает «000000q»?
Я изучаю x86_64 ассемблер ( yasm ) с этим учебником. Там я встретил следующие строки, которые определяют флаги доступа к файлам: O_RDONLY equ 000000q O_WRONLY equ 000001q O_RDWR equ 000002q Вопрос в…
Что означают L EQU 0AH и T EQU 09H в assembly?
Может ли кто-нибудь объяснить,что означает каждое выражение(L Equ 0AH и T equ 09h) в assembly, пожалуйста?
Сохраняет ли EQU в 68K что-нибудь в памяти?
Я делаю задание, где я должен нарисовать карту памяти, и она говорит C EQU 4, я знаю, что EQU присваивает значение 4 C, но что это на самом деле помещает в память?
Atmel AVR Assembler
Atmel AVR AssemblerСодержание:
Исходные коды
Компилятор работает с исходными файлами, содержащими инструкции, метки и директивы. Инструкции и директивы, как правило, имеют один или несколько операндов.
Строка кода не должна быть длиннее 120 символов.
Любая строка может начинаться с метки, которая является набором символов заканчивающимся двоеточием. Метки используются для указания места, в которое передаётся управление при переходах, а также для задания имён переменных.
Входная строка может иметь одну из четырёх форм:
[метка:] директива [операнды] [Комментарий]
[метка:] инструкция [операнды] [Комментарий]
Комментарий
Пустая строка
Комментарий имеет следующую форму:
; [Текст]
Позиции в квадратных скобках необязательны. Текст после точки с запятой (;) и до конца строки игнорируется компилятором. Метки, инструкции и директивы более детально описываются ниже.
Примеры:
label:════ .EQU var1=100 ; Устанавливает var1 равным 100 (Это директива)
══════════ .EQU var2=200 ; Устанавливает var2 равным 200test:═════ rjmp test════ ; Бесконечный цикл (Это инструкция)
════════════════════════ ; Строка с одним только комментарием════════════════════════ ; Ещё одна строка с комментарием
Компилятор не требует чтобы метки, директивы, комментарии или инструкции находились в определённой колонке строки.
═Инструкции процессоров AVR
Ниже приведен набор команд
процессоров AVR, более детальное
описание их можно найти в AVR Data Book.
═
Арифметические и логические инструкции
| Мнемоника | Операнды | Описание | Операция | Флаги | Циклы |
| ADD═ | Rd,Rr═ | Суммирование без переноса | Rd = Rd + Rr═ | Z,C,N,V,H,S═ | 1 |
| ADC | Rd,Rr | Суммирование с переносом | Rd = Rd + Rr + C | Z,C,N,V,H,S | 1 |
| SUB | Rd,Rr | Вычитание без переноса | Rd = Rd — Rr | Z,C,N,V,H,S | 1 |
| SUBI | Rd,K8 | Вычитание константы | Rd = Rd — K8 | Z,C,N,V,H,S | 1 |
| SBC | Rd,Rr | Вычитание с переносом | Rd = Rd — Rr - C | Z,C,N,V,H,S | 1 |
| SBCI | Rd,K8 | Вычитание константы с переносом | Rd = Rd — K8 - C | Z,C,N,V,H,S | 1 |
| AND | Rd,Rr | Логическое И | Rd = Rd ╥ Rr | Z,N,V,S═ | 1 |
| ANDI | Rd,K8 | Логическое И с константой | Rd = Rd ╥ K8 | Z,N,V,S | 1 |
| OR | Rd,Rr | Логическое ИЛИ | Rd = Rd V Rr | Z,N,V,S | 1 |
| ORI | Rd,K8 | Логическое ИЛИ с константой | Rd = Rd V K8 | Z,N,V,S | 1 |
| EOR | Rd,Rr | Логическое исключающее ИЛИ | Rd = Rd EOR Rr | Z,N,V,S | 1 |
| COM | Rd | Побитная Инверсия | Rd = $FF — Rd | Z,C,N,V,S | 1 |
| NEG | Rd | Изменение знака (Доп. код) | Rd = $00 — Rd | Z,C,N,V,H,S | 1 |
| SBR | Rd,K8 | Установить бит (биты) в регистре | Rd = Rd V K8 | Z,C,N,V,S | 1 |
| CBR | Rd,K8 | Сбросить бит (биты) в регистре | Rd = Rd ╥ ($FF — K8) | Z,C,N,V,S | 1 |
| INC | Rd | Инкрементировать значение регистра | Rd = Rd + 1 | Z,N,V,S | 1 |
| DEC | Rd | Декрементировать значение регистра | Rd = Rd -1 | Z,N,V,S | 1 |
| TST | Rd | Проверка на ноль либо отрицательность | Rd = Rd ╥ Rd | Z,C,N,V,S | 1 |
| CLR | Rd | Очистить регистр | Rd = 0 | Z,C,N,V,S | 1 |
| SER | Rd | Установить регистр | Rd = $FF | None | 1 |
| ADIW | Rdl,K6 | Сложить константу и слово | Rdh:Rdl = Rdh:Rdl + K6═ | Z,C,N,V,S | 2 |
| SBIW | Rdl,K6 | Вычесть константу из слова | Rdh:Rdl = Rdh:Rdl — K 6 | Z,C,N,V,S | 2 |
| MUL | Rd,Rr | Умножение чисел без знака | R1:R0 = Rd * Rr | Z,C | 2 |
| MULS | Rd,Rr | Умножение чисел со знаком | R1:R0 = Rd * Rr | Z,C | 2 |
| MULSU | Rd,Rr | Умножение числа со знаком с числом без знака | R1:R0 = Rd * Rr | Z,C | 2 |
| FMUL | Rd,Rr | Умножение дробных чисел без знака | R1:R0 = (Rd * Rr) << 1 | Z,C | 2 |
| FMULS | Rd,Rr | Умножение дробных чисел со знаком | R1:R0 = (Rd *Rr) << 1 | Z,C | 2 |
| FMULSU | Rd,Rr | Умножение дробного числа со знаком с числом без знака | R1:R0 = (Rd * Rr) << 1 | Z,C | 2 |
═
Инструкции ветвления
| Мнемоника | Операнды | Описание | Операция | Флаги | Циклы |
| RJMP | k | Относительный переход | PC = PC + k +1 | None | 2 |
| IJMP | Нет | Косвенный переход на (Z) | PC = Z | None | 2 |
| EIJMP | Нет | Расширенный косвенный переход на (Z) | STACK = PC+1, PC(15:0) = Z, PC(21:16) = EIND | None | 2 |
| JMP | k | Переход | PC = k | None | 3 |
| RCALL | k | Относительный вызов подпрограммы | STACK = PC+1, PC = PC + k + 1 | None | 3/4* |
| ICALL | Нет | Косвенный вызов (Z) | STACK = PC+1, PC = Z═ | None | 3/4* |
| EICALL | Нет | Расширенный косвенный вызов (Z) | STACK = PC+1, PC(15:0) = Z, PC(21:16) =EIND | None | 4* |
| CALL | k | Вызов подпрограммы | STACK = PC+2, PC = k | None | 4/5* |
| RET | Нет | Возврат из подпрограммы | PC = STACK | None | 4/5* |
| RETI | Нет | Возврат из прерывания | PC = STACK | I | 4/5* |
| CPSE | Rd,Rr | Сравнить, пропустить если равны═ | if (Rd ==Rr) PC = PC 2 or 3 | None | 1/2/3 |
| CP | Rd,Rr | Сравнить | Rd -Rr | Z,C,N,V,H,S | 1 |
| CPC | Rd,Rr | Сравнить с переносом | Rd — Rr — C | Z,C,N,V,H,S | 1 |
| CPI | Rd,K8 | Сравнить с константой | Rd — K | Z,C,N,V,H,S | 1 |
| SBRC | Rr,b | Пропустить если бит в регистре очищен | if(Rr(b)==0) PC = PC + 2 or 3 | None | 1/2/3 |
| SBRS | Rr,b | Пропустить если бит в регистре установлен | if(Rr(b)==1) PC = PC + 2 or 3 | None | 1/2/3 |
| SBIC | P,b | Пропустить если бит в порту очищен | if(I/O(P,b)==0) PC = PC + 2 or 3 | None | 1/2/3 |
| SBIS | P,b | Пропустить если бит в порту установлен | if(I/O(P,b)==1) PC = PC + 2 or 3 | None | 1/2/3 |
| BRBC | s,k | Перейти если флаг в SREG очищен | if(SREG(s)==0) PC = PC + k + 1 | None | 1/2 |
| BRBS | s,k | Перейти если флаг в SREG установлен | if(SREG(s)==1) PC = PC + k + 1 | None | 1/2 |
| BREQ | k | Перейти если равно | if(Z==1) PC = PC + k + 1 | None | 1/2 |
| BRNE | k | Перейти если не равно | if(Z==0) PC = PC + k + 1 | None | 1/2 |
| BRCS | k | Перейти если перенос установлен | if(C==1) PC = PC + k + 1 | None | 1/2 |
| BRCC | k | Перейти если перенос очищен | if(C==0) PC = PC + k + 1 | None | 1/2 |
| BRSH | k | Перейти если равно или больше | if(C==0) PC = PC + k + 1 | None | 1/2 |
| BRLO | k | Перейти если меньше | if(C==1) PC = PC + k + 1 | None | 1/2 |
| BRMI | k | Перейти если минус | if(N==1) PC = PC + k + 1 | None | 1/2 |
| BRPL | k | Перейти если плюс | if(N==0) PC = PC + k + 1 | None | 1/2 |
| BRGE | k | Перейти если больше или равно (со знаком) | if(S==0) PC = PC + k + 1 | None | 1/2 |
| BRLT | k | Перейти если меньше (со знаком) | if(S==1) PC = PC + k + 1 | None | 1/2 |
| BRHS | k | Перейти если флаг внутреннего переноса установлен | if(H==1) PC = PC + k + 1 | None | 1/2 |
| BRHC | k | Перейти если флаг внутреннего переноса очищен | if(H==0) PC = PC + k + 1 | None | 1/2 |
| BRTS | k | Перейти если флаг T установлен | if(T==1) PC = PC + k + 1 | None | 1/2 |
| BRTC | k | Перейти если флаг T очищен | if(T==0) PC = PC + k + 1 | None | 1/2 |
| BRVS | k | Перейти если флаг переполнения установлен | if(V==1) PC = PC + k + 1 | None | 1/2 |
| BRVC | k | Перейти если флаг переполнения очищен | if(V==0) PC = PC + k + 1 | None | 1/2 |
| BRIE | k | Перейти если прерывания разрешены | if(I==1) PC = PC + k + 1 | None | 1/2 |
| BRID | k | Перейти если прерывания запрещены | if(I==0) PC = PC + k + 1 | None | 1/2 |
* Для операций доступа к данным количество циклов указано при условии доступа к внутренней памяти данных, и не корректно при работе с внешним ОЗУ. Для инструкций CALL, ICALL, EICALL, RCALL, RET и RETI, необходимо добавить три цикла плюс по два цикла для каждого ожидания в контроллерах с PC меньшим 16 бит (128KB памяти программ). Для устройств с памятью программ свыше 128KB , добавьте пять циклов плюс по три цикла на каждое ожидание.
Инструкции передачи данных
| Мнемоника | Операнды | Описание | Операция | Флаги | Циклы |
| MOV | Rd,Rr | Скопировать регистр | Rd = Rr | None | 1 |
| MOVW | Rd,Rr | Скопировать пару регистров | Rd+1:Rd = Rr+1:Rr, r,d even | None | 1 |
| LDI | Rd,K8 | Загрузить константу | Rd = K | None | 1 |
| LDS | Rd,k | Прямая загрузка | Rd = (k) | None | 2* |
| LD | Rd,X | Косвенная загрузка | Rd = (X) | None | 2* |
| LD | Rd,X+ | Косвенная загрузка с пост-инкрементом | Rd = (X), X=X+1 | None | 2* |
| LD | Rd,-X | Косвенная загрузка с пре-декрементом | X=X-1, Rd = (X) | None | 2* |
| LD | Rd,Y | Косвенная загрузка | Rd = (Y) | None | 2* |
| LD | Rd,Y+ | Косвенная загрузка с пост-инкрементом | Rd = (Y), Y=Y+1 | None | 2* |
| LD | Rd,-Y | Косвенная загрузка с пре-декрементом | Y=Y-1, Rd = (Y) | None | 2* |
| LDD | Rd,Y+q | Косвенная загрузка с замещением | Rd = (Y+q) | None | 2* |
| LD | Rd,Z | Косвенная загрузка | Rd = (Z) | None | 2* |
| LD | Rd,Z+ | Косвенная загрузка с пост-инкрементом | Rd = (Z), Z=Z+1 | None | 2* |
| LD | Rd,-Z | Косвенная загрузка с пре-декрементом | Z=Z-1, Rd = (Z) | None | 2* |
| LDD | Rd,Z+q | Косвенная загрузка с замещением | Rd = (Z+q) | None | 2* |
| STS | k,Rr | Прямое сохранение | (k) = Rr | None | 2* |
| ST | X,Rr | Косвенное сохранение | (X) = Rr | None | 2* |
| ST | X+,Rr | Косвенное сохранение с пост-инкрементом | (X) = Rr, X=X+1 | None | 2* |
| ST | -X,Rr | Косвенное сохранение с пре-декрементом | X=X-1, (X)=Rr | None | 2* |
| ST | Y,Rr | Косвенное сохранение | (Y) = Rr | None | 2* |
| ST | Y+,Rr | Косвенное сохранение с пост-инкрементом | (Y) = Rr, Y=Y+1 | None | 2 |
| ST | -Y,Rr | Косвенное сохранение с пре-декрементом | Y=Y-1, (Y) = Rr | None | 2 |
| ST | Y+q,Rr | Косвенное сохранение с замещением | (Y+q) = Rr | None | 2 |
| ST | Z,Rr | Косвенное сохранение | (Z) = Rr | None | 2 |
| ST | Z+,Rr | Косвенное сохранение с пост-инкрементом | (Z) = Rr, Z=Z+1 | None | 2 |
| ST | -Z,Rr | Косвенное сохранение с пре-декрементом | Z=Z-1, (Z) = Rr | None | 2 |
| ST | Z+q,Rr | Косвенное сохранение с замещением | (Z+q) = Rr | None | 2 |
| LPM | Нет | Загрузка из программной памяти | R0 = (Z) | None | 3 |
| LPM | Rd,Z | Загрузка из программной памяти | Rd = (Z) | None | 3 |
| LPM | Rd,Z+ | Загрузка из программной памяти с пост-инкрементом | Rd = (Z), Z=Z+1 | None | 3 |
| ELPM | Нет | Расширенная загрузка из программной памяти | R0 = (RAMPZ:Z) | None | 3 |
| ELPM | Rd,Z | Расширенная загрузка из программной памяти | Rd = (RAMPZ:Z) | None | 3 |
| ELPM | Rd,Z+ | Расширенная загрузка из программной памяти с пост-инкрементом | Rd = (RAMPZ:Z), Z = Z+1 | None | 3 |
| SPM | Нет | Сохранение в программной памяти | (Z) = R1:R0 | None | — |
| ESPM | Нет | Расширенное сохранение в программной памяти | (RAMPZ:Z) = R1:R0 | None | — |
| IN | Rd,P | Чтение порта | Rd = P | None | 1 |
| OUT | P,Rr | Запись в порт | P = Rr | None | 1 |
| PUSH | Rr | Занесение регистра в стек | STACK = Rr | None | 2 |
| POP | Rd | Извлечение регистра из стека | Rd = STACK | None | 2 |
* Для операций доступа к данным количество циклов указано при условии доступа к внутренней памяти данных, и не корректно при работе с внешним ОЗУ. Для инструкций LD, ST, LDD, STD, LDS, STS, PUSH и POP, необходимо добавить один цикл плюс по одному циклу для каждого ожидания.
Инструкции работы с битами
| Мнемоника | Операнды | Описание | Операция | Флаги | Циклы |
| LSL | Rd | Логический сдвиг влево | Rd(n+1)=Rd(n), Rd(0)=0, C=Rd(7) | Z,C,N,V,H,S | 1 |
| LSR | Rd | Логический сдвиг вправо | Rd(n)=Rd(n+1), Rd(7)=0, C=Rd(0) | Z,C,N,V,S | 1 |
| ROL | Rd | Циклический сдвиг влево через C | Rd(0)=C, Rd(n+1)=Rd(n), C=Rd(7) | Z,C,N,V,H,S | 1 |
| ROR | Rd | Циклический сдвиг вправо через C | Rd(7)=C, Rd(n)=Rd(n+1), C=Rd(0) | Z,C,N,V,S | 1 |
| ASR | Rd | Арифметический сдвиг вправо | Rd(n)=Rd(n+1), n=0,…,6 | Z,C,N,V,S | 1 |
| SWAP | Rd | Перестановка тетрад | Rd(3..0) = Rd(7..4), Rd(7..4) = Rd(3..0) | None | 1 |
| BSET═ | s | Установка флага | SREG(s) = 1 | SREG(s) | 1 |
| BCLR | s | Очистка флага | SREG(s) = 0 | SREG(s) | 1 |
| SBI | P,b | Установить бит в порту | I/O(P,b) = 1 | None | 2 |
| CBI | P,b | Очистить бит в порту | I/O(P,b) = 0 | None | 2 |
| BST | Rr,b | Сохранить бит из регистра в T | T = Rr(b) | T | 1 |
| BLD | Rd,b | Загрузить бит из T в регистр | Rd(b) = T | None | 1 |
| SEC | Нет | Установить флаг переноса | C =1 | C | 1 |
| CLC | Нет | Очистить флаг переноса | C = 0 | C | 1 |
| SEN | Нет | Установить флаг отрицательного числа | N = 1 | N | 1 |
| CLN | Нет | Очистить флаг отрицательного числа | N = 0 | N | 1 |
| SEZ | Нет | Установить флаг нуля | Z = 1 | Z | 1 |
| CLZ | Нет | Очистить флаг нуля | Z = 0 | Z | 1 |
| SEI | Нет | Установить флаг прерываний | I = 1 | I | 1 |
| CLI | Нет | Очистить флаг прерываний | I = 0 | I | 1 |
| SES | Нет | Установить флаг числа со знаком | S = 1 | S | 1 |
| CLN | Нет | Очистить флаг числа со знаком | S = 0 | S | 1 |
| SEV | Нет | Установить флаг переполнения | V = 1 | V | 1 |
| CLV | Нет | Очистить флаг переполнения | V = 0 | V | 1 |
| SET | Нет | Установить флаг T | T = 1 | T | 1 |
| CLT | Нет | Очистить флаг T | T = 0 | T | 1 |
| SEH | Нет | Установить флаг внутреннего переноса | H = 1 | H | 1 |
| CLH | Нет | Очистить флаг внутреннего переноса | H = 0 | H | 1 |
| NOP | Нет | Нет операции | Нет | None | 1 |
| SLEEP | Нет | Спать (уменьшить энергопотребление) | Смотрите описание инструкции | None | 1 |
| WDR | Нет | Сброс сторожевого таймера | Смотрите описание инструкции | None | 1 |
═
Ассемблер не различает регистр
символов.
Операнды могут быть таких видов:
Rd: Результирующий (и исходный) регистр в регистровом файле
Rr: Исходный регистр в регистровом файле
b: Константа (3 бита), может быть константное выражение
s: Константа (3 бита), может быть константное выражение
P: Константа (5-6 бит), может быть константное выражение
K6; Константа (6 бит), может быть константное выражение
K8: Константа (8 бит), может быть константное выражение
k: Константа (размер зависит от инструкции), может быть константное выражение
q: Константа (6 бит), может быть константное выражение
Rdl:═ R24, R26, R28, R30. Для инструкций ADIW и SBIW
X,Y,Z: Регистры косвенной адресации (X=R27:R26, Y=R29:R28, Z=R31:R30)
Директивы ассемблера
Компилятор поддерживает ряд
директив. Директивы не
транслируются непосредственно в
код. Вместо этого они используются
для указания положения в
программной памяти, определения
макросов, инициализации памяти и
т.д. Список директив приведён в
следующей таблице.
═
Все директивы предваряются точкой.
BYTE - Зарезервировать байты в ОЗУ
Директива BYTE резервирует байты в ОЗУ. Если вы хотите иметь возможность ссылаться на выделенную область памяти, то директива BYTE должна быть предварена меткой. Директива принимает один обязательный параметр, который указывает количество выделяемых байт. Эта директива может использоваться только в сегменте данных(смотреть директивы CSEG и DSEG). Выделенные байты не инициализируются.
Синтаксис:
МЕТКА: .BYTE выражение
Пример:
.DSEG
var1:═══ .BYTE 1═══════════ ;
резервирует 1 байт для var1
table:══ .BYTE tab_size════ ; резервирует
tab_size байт
.CSEG
════════ ldi r30,low(var1)═ ; Загружает
младший байт регистра Z
════════ ldi r31,high(var1) ; Загружает
старший байт регистра Z
════════ ld r1,Z═══════════ ;
Загружает VAR1 в регистр 1
CSEG - Программный сегмент
Директива CSEG определяет начало программного сегмента. Исходный файл может состоять из нескольких программных сегментов, которые объединяются в один программный сегмент при компиляции. Программный сегмент является сегментом по умолчанию. Программные сегменты имеют свои собственные счётчики положения которые считают не побайтно, а по словно. Директива ORG может быть использована для размещения кода и констант в необходимом месте сегмента. Директива CSEG не имеет параметров.
Синтаксис:
.CSEG
Пример:
.DSEG══════════════════════ ;
Начало сегмента данных
vartab: .BYTE 4════════════ ;
Резервирует 4 байта в ОЗУ
.CSEG══════════════════════ ;
Начало кодового сегмента
const:═ .DW 2══════════════ ;
Разместить константу 0x0002 в памяти
программ
═══════ mov r1,r0══════════ ;
Выполнить действия
DB — Определить байты во флэш или EEPROM
Директива DB резервирует необходимое количество байт в памяти программ или в EEPROM. Если вы хотите иметь возможность ссылаться на выделенную область памяти, то директива DB должна быть предварена меткой. Директива DB должна иметь хотя бы один параметр. Данная директива может быть размещена только в сегменте программ (CSEG) или в сегменте EEPROM (ESEG).
Параметры передаваемые директиве — это последовательность выражений разделённых запятыми. Каждое выражение должно быть или числом в диапазоне (-128..255), или в результате вычисления должно давать результат в этом же диапазоне, в противном случае число усекается до байта, причём БЕЗ выдачи предупреждений.
Если директива получает более одного параметра и текущим является программный сегмент, то параметры упаковываются в слова (первый параметр — младший байт), и если число параметров нечётно, то последнее выражение будет усечено до байта и записано как слово со старшим байтом равным нулю, даже если далее идет ещё одна директива DB.
Синтаксис:
МЕТКА:═ .DB список_выражений
Пример:
.CSEG
consts: .DB 0, 255, 0b01010101, -128, 0xaa
.ESEG
const2: .DB 1,2,3
DEF - Назначить регистру символическое имя
Директива DEF позволяет ссылаться на регистр через некоторое символическое имя. Назначенное имя может использоваться во всей нижеследующей части программы для обращений к данному регистру. Регистр может иметь несколько различных имен. Символическое имя может быть переназначено позднее в программе.
Синтаксис:
.DEF Символическое_имя = Регистр
Пример:
.DEF temp=R16
.DEF ior=R0
.CSEG
═ldi temp,0xf0═ ; Загрузить 0xf0 в регистр
temp (R16)
═in ior,0x3f═ ; Прочитать SREG в регистр
ior (R0)
═eor temp,ior═ ; Регистры temp и ior
складываются по исключающему или
DEVICE — Определить устройство для которого компилируется программа
Директива DEVICE позволяет указать для какого устройства компилируется программа. При использовании данной директивы компилятор выдаст предупреждение, если будет найдена инструкция, которую не поддерживает данный микроконтроллер. Также будет выдано предупреждение, если программный сегмент, либо сегмент EEPROM превысят размер допускаемый устройством. Если же директива не используется то все инструкции считаются допустимыми, и отсутствуют ограничения на размер сегментов.
Синтаксис:
.DEVICE AT90S1200 |AT90S2313 | AT90S2323 | AT90S2333 |
AT90S2343 | AT90S4414 | AT90S4433 | AT90S4434 | AT90S8515 |
AT90S8534 | AT90S8535 | ATtiny11 | ATtiny12 | ATtiny22 |
ATmega603 | ATmega103
Пример:
.DEVICE AT90S1200═ ; Используется AT90S1200
.CSEG
═══════ push r30══ ; Эта инструкция
вызовет предупреждение
══════════════════ ; поскольку
AT90S1200 её не имеет
DSEG — Сегмент данных
Директива DSEG определяет начало сегмента данных. Исходный файл может состоять из нескольких сегментов данных, которые объединяются в один сегмент при компиляции. Сегмент данных обычно состоит только из директив BYTE и меток. Сегменты данных имеют свои собственные побайтные счётчики положения. Директива ORG может быть использована для размещения переменных в необходимом месте ОЗУ. Директива не имеет параметров.
Синтаксис:
.DSEG═
Пример:
.DSEG═══════════════════════ ;
Начало сегмента данных
var1:═ .BYTE 1══════════════ ;
зарезервировать 1 байт для var1
table:═ .BYTE tab_size══════ ;
зарезервировать tab_size байт.
.CSEG
═══════ ldi r30,low(var1)═══ ; Загрузить
младший байт регистра Z
═══════ ldi r31,high(var1)══ ; Загрузить
старший байт регистра Z
═══════ ld r1,Z═════════════ ;
Загрузить var1 в регистр r1
DW — Определить слова во флэш или EEPROM
Директива DW резервирует необходимое количество слов в памяти программ или в EEPROM. Если вы хотите иметь возможность ссылаться на выделенную область памяти, то директива DW должна быть предварена меткой. Директива DW должна иметь хотя бы один параметр. Данная директива может быть размещена только в сегменте программ (CSEG) или в сегменте EEPROM (ESEG).
Параметры передаваемые директиве — это последовательность выражений разделённых запятыми. Каждое выражение должно быть или числом в диапазоне (-32768..65535), или в результате вычисления должно давать результат в этом же диапазоне, в противном случае число усекается до слова, причем БЕЗ выдачи предупреждений.
Синтаксис:
МЕТКА: .DW expressionlist
Пример:
.CSEG
varlist:═ .DW 0, 0xffff, 0b1001110001010101, -32768, 65535
.ESEG
eevarlst: .DW 0,0xffff,10
ENDMACRO — Конец макроса
Директива определяет конец макроопределения, и не принимает никаких параметров. Для информации по определению макросов смотрите директиву MACRO.
Синтаксис:
.ENDMACRO═
Пример:
.MACRO SUBI16══════════════ ; Начало
определения макроса
═══════ subi r16,low(@0)═══ ; Вычесть
младший байт первого параметра
═══════ sbci r17,high(@0)══ ; Вычесть
старший байт первого параметра
.ENDMACRO
EQU - Установить постоянное выражение
Директива EQU присваивает метке значение. Эта метка может позднее использоваться в выражениях. Метка которой присвоено значение данной директивой не может быть переназначена и её значение не может быть изменено.
Синтаксис:
.EQU метка = выражение
Пример:
.EQU io_offset = 0x23
.EQU porta════ = io_offset + 2
.CSEG════════════════ ; Начало
сегмента данных
═══════ clr r2═══════ ; Очистить
регистр r2
═══════ out porta,r2═ ; Записать в порт
A
ESEG — Сегмент EEPROM
Директива ESEG определяет начало сегмента EEPROM. Исходный файл может состоять из нескольких сегментов EEPROM, которые объединяются в один сегмент при компиляции. Сегмент EEPROM обычно состоит только из директив DB, DW и меток. Сегменты EEPROM имеют свои собственные побайтные счётчики положения. Директива ORG может быть использована для размещения переменных в необходимом месте EEPROM. Директива не имеет параметров.
Синтаксис:
.ESEG═══
Пример:
.DSEG═══════════════════ ; Начало
сегмента данных
var1:══ .BYTE 1═════════ ;
зарезервировать 1 байт для var1
table:═ .BYTE tab_size══ ; зарезервировать
tab_size байт.
.ESEG
eevar1: .DW 0xffff═══════ ;
проинициализировать 1 слово в EEPROM
EXIT — Выйти из файла
Встретив директиву EXIT компилятор прекращает компиляцию данного файла. Если директива использована во вложенном файле (см. директиву INCLUDE), то компиляция продолжается со строки следующей после директивы INCLUDE. Если же файл не является вложенным, то компиляция прекращается.
Синтаксис:
.EXIT
Пример:
.EXIT═ ; Выйти из данного файла
INCLUDE - Вложить другой файл
Встретив директиву INCLUDE компилятор открывает указанный в ней файл, компилирует его пока файл не закончится или не встретится директива EXIT, после этого продолжает компиляцию начального файла со строки следующей за директивой INCLUDE. Вложенный файл может также содержать директивы INCLUDE.
Синтаксис:
.INCLUDE «имя_файла»
Пример:
; файл iodefs.asm:
.EQU sreg══ = 0x3f════ ; Регистр статуса
.EQU sphigh = 0x3e════ ; Старший байт
указателя стека
.EQU splow═ = 0x3d════ ; Младший байт
указателя стека
; файл incdemo.asm
.INCLUDE iodefs.asm═══ ; Вложить
определения портов
═══════ in r0,sreg════ ; Прочитать
регистр статуса
LIST - Включить генерацию листинга
Директива LIST указывает компилятору на необходимость создания листинга. Листинг представляет из себя комбинацию ассемблерного кода, адресов и кодов операций. По умолчанию генерация листинга включена, однако данная директива используется совместно с директивой NOLIST для получения листингов отдельных частей исходных файлов.
Синтаксис:
.LIST
Пример:
.NOLIST═══════════════ ; Отключить
генерацию листинга
.INCLUDE «macro.inc»══ ; Вложенные
файлы не будут
.INCLUDE «const.def»══ ; отображены в
листинге
.LIST═════════════════ ; Включить
генерацию листинга
LISTMAC - Включить разворачивание макросов в листинге
После директивы LISTMAC компилятор будет показывать в листинге содержимое макроса. По умолчанию в листинге показывается только вызов макроса и передаваемые параметры.
Синтаксис:
.LISTMAC
Пример:
.MACRO MACX════════ ; Определение
макроса
═══════ add═ r0,@0═ ; Тело макроса
═══════ eor═ r1,@1═
.ENDMACRO══════════ ; Конец
макроопределения
.LISTMAC═══════════ ; Включить
разворачивание макросов
═══════ MACX r2,r1═ ; Вызов макроса (в
листинге будет показано тело
макроса)
MACRO — Начало макроса
С директивы MACRO начинается определение макроса. В качестве параметра директиве передаётся имя макроса. При встрече имени макроса позднее в тексте программы, компилятор заменяет это имя на тело макроса. Макрос может иметь до 10 параметров, к которым в его теле обращаются через @0-@9. При вызове параметры перечисляются через запятые. Определение макроса заканчивается директивой ENDMACRO.
По умолчанию в листинг включается
только вызов макроса, для
разворачивания макроса необходимо
использовать директиву LISTMAC.
Макрос в листинге показывается
знаком +.
═
Синтаксис:
.MACRO макроимя
Пример:
.MACRO SUBI16══════════════════ ;
Начало макроопределения
═══════ subi @1,low(@0)════════ ;
Вычесть младший байт параметра 0 из
параметра 1
═══════ sbci @2,high(@0)═══════ ;
Вычесть старший байт параметра 0 из
параметра 2
.ENDMACRO══════════════════════ ;
Конец макроопределения
.CSEG══════════════════════════
; Начало программного сегмента
═══════ SUBI16 0x1234,r16,r17══ ; Вычесть
0x1234 из r17:r16
NOLIST - Выключить генерацию листинга
Директива NOLIST указывает компилятору на необходимость прекращения генерации листинга. Листинг представляет из себя комбинацию ассемблерного кода, адресов и кодов операций. По умолчанию генерация листинга включена, однако может быть отключена данной директивой. Кроме того данная директива может быть использована совместно с директивой LIST для получения листингов отдельных частей исходных файлов
Синтаксис:
.NOLIST
Пример:
.NOLIST═══════════════ ; Отключить
генерацию листинга
.INCLUDE «macro.inc»══ ; Вложенные
файлы не будут
.INCLUDE «const.def»══ ; отображены в
листинге
.LIST═════════════════ ; Включить
генерацию листинга
ORG - Установить положение в сегменте
Директива ORG устанавливает счётчик положения равным заданной величине, которая передаётся как параметр. Для сегмента данных она устанавливает счётчик положения в SRAM (ОЗУ), для сегмента программ это программный счётчик, а для сегмента EEPROM это положение в EEPROM. Если директиве предшествует метка (в той же строке) то метка размещается по адресу указанному в параметре директивы. Перед началом компиляции программный счётчик и счётчик EEPROM равны нулю, а счётчик ОЗУ равен 32 (поскольку адреса 0-31 заняты регистрами). Обратите внимание что для ОЗУ и EEPROM используются побайтные счётчики а для программного сегмента - пословный.
Синтаксис:
.ORG выражение
Пример:
.DSEG═══════════════ ; Начало
сегмента данных
.ORG 0x37═══════════ ; Установить
адрес SRAM равным 0x37
variable: .BYTE 1═══ ; Зарезервировать
байт по адресу 0x37H
.CSEG
.ORG 0x10═══════════ ; Установить
программный счётчик равным 0x10
═════════ mov r0,r1═ ; Данная команда
будет размещена по адресу 0x10
SET - Установить переменный символический эквивалент выражения
Директива SET присваивает имени некоторое значение. Это имя позднее может быть использовано в выражениях. Причем в отличии от директивы EQU значение имени может быть изменено другой директивой SET.
Синтаксис:
.SET имя = выражение
Пример:
.SET io_offset = 0x23
.SET porta════ = io_offset + 2
.CSEG════════════════ ; Начало
кодового сегмента
═══════ clr r2═══════ ; Очистить
регистр 2
═══════ out porta,r2═ ; Записать в порт
A
Выражения
Компилятор позволяет использовать в программе выражения которые могут состоять операндов, знаков операций и функций. Все выражения являются 32-битными.
Операнды
Могут быть использованы следующие операнды:
- Метки определённые пользователем (дают значение своего положения).
- Переменные определённые директивой SET
- Константы определённые директивой EQU
- Числа заданные в формате:
- Десятичном (принят по умолчанию): 10, 255
- Шестнадцатеричном (два варианта записи): 0x0a, $0a, 0xff, $ff
- Двоичном: 0b00001010, 0b11111111
- Восьмеричном (начинаются с нуля): 010, 077
- PC — текущее значение программного счётчика (Programm Counter)
Операции
Компилятор поддерживает ряд операций, которые перечислены в таблице (чем выше положение в таблице, тем выше приоритет операции). Выражения могут заключаться в круглые скобки, такие выражения вычисляются перед выражениями за скобками.
Логическое отрицание
Символ: !
Описание:
Возвращает 1 если выражение равно 0,
и наоборот
Приоритет: 14
Пример: ldi r16, !0xf0═ ; В
r16 загрузить 0x00
Побитное отрицание
Символ: ~
Описание:
Возвращает выражение в котором все
биты проинвертированы
Приоритет: 14
Пример: ldi r16, ~0xf0═ ; В
r16 загрузить 0x0f
Минус
Символ: —
Описание:
Возвращает арифметическое
отрицание выражения
Приоритет: 14
Пример: ldi r16,-2═ ;
Загрузить -2(0xfe) в r16
Умножение
Символ: *
Описание:
Возвращает результат умножения
двух выражений
Приоритет: 13
Пример: ldi r30, label*2
Деление
Символ: /
Описание:
Возвращает целую часть результата
деления левого выражения на правое
Приоритет: 13
Пример: ldi r30, label/2
Суммирование
Символ: +
Описание:
Возвращает сумму двух выражений
Приоритет: 12
Пример: ldi r30, c1+c2
Вычитание
Символ: —
Описание:
Возвращает результат вычитания
правого выражения из левого
Приоритет: 12
Пример: ldi r17, c1-c2
Сдвиг влево
Символ: <<
Описание:
Возвращает левое выражение
сдвинутое влево на число бит
указанное справа
Приоритет: 11
Пример: ldi r17,
1<<bitmask═ ; В r17 загрузить 1
сдвинутую влево bitmask раз
Сдвиг вправо
Символ: >>
Описание:
Возвращает левое выражение
сдвинутое вправо на число бит
указанное справа
Приоритет: 11
Пример: ldi r17,
c1>>c2═ ; В r17 загрузить c1 сдвинутое
вправо c2 раз
Меньше чем
Символ: <
Описание:
Возвращает 1 если левое выражение
меньше чем правое (учитывается
знак), и 0 в противном случае
Приоритет: 10
Пример: ori r18,
bitmask*(c1<c2)+1
Меньше или равно
Символ: <=
Описание:
Возвращает 1 если левое выражение
меньше или равно чем правое
(учитывается знак), и 0 в противном
случае
Приоритет: 10
Пример: ori r18,
bitmask*(c1<=c2)+1
Больше чем
Символ: >
Описание:
Возвращает 1 если левое выражение
больше чем правое (учитывается
знак), и 0 в противном случае
Приоритет: 10
Пример: ori r18,
bitmask*(c1>c2)+1
Больше или равно
Символ: >=
Описание:
Возвращает 1 если левое выражение
больше или равно чем правое
(учитывается знак), и 0 в противном
случае
Приоритет: 10
Пример: ori r18,
bitmask*(c1>=c2)+1
Равно
Символ: ==
Описание:
Возвращает 1 если левое выражение
равно правому (учитывается знак), и 0
в противном случае
Приоритет: 9
Пример: andi r19,
bitmask*(c1==c2)+1
Не равно
Символ: !=
Описание:
Возвращает 1 если левое выражение
не равно правому (учитывается знак),
и 0 в противном случае
Приоритет: 9
Пример: .c2)
Побитное ИЛИ
Символ: |
Описание:
Возвращает результат побитового
ИЛИ выражений
Приоритет: 6
Пример: ldi r18, Low(c1|c2)
Логическое И
Символ: &&
Описание:
Возвращает 1 если оба выражения не
равны нулю, и 0 в противном случае
Приоритет: 5
Пример: ldi r18,
Low(c1&&c2)
Логическое ИЛИ
Символ: ||
Описание:
Возвращает 1 если хотя бы одно
выражение не равно нулю, и 0 в
противном случае
Приоритет: 4
Пример: ldi r18, Low(c1||c2)
Функции
Определены следующие функции:
- LOW(выражение) возвращает младший байт выражения
- HIGH(выражение) возвращает второй байт выражения
- BYTE2(выражение) то же что и функция HIGH
- BYTE3(выражение) возвращает третий байт выражения
- BYTE4(выражение) возвращает четвёртый байт выражения
- LWRD(выражение) возвращает биты 0-15 выражения
- HWRD(выражение) возвращает биты 16-31 выражения
- PAGE(выражение) возвращает биты 16-21 выражения
- EXP2(выражение) возвращает 2 в степени (выражение)
- LOG2(выражение) возвращает целую часть log2(выражение)
Использование программы
Этот раздел описывает использование компилятора и встроенного редактора
Открытие файлов
В WAVRASM могут быть открыты как новые так и существующие файлы. Количество открытых файлов ограничено размером памяти, однако объём одного файла не может превышать 28 килобайт (в связи с ограничением MS-Windows). Компиляция файлов большего размера возможна, но они не могут быть редактируемы встроенным редактором. Каждый файл открывается в отдельном окне.
Сообщения об ошибках
После компиляции программы появляется окно сообщений. Все обнаруженные компилятором ошибки будут перечислены в этом окне. При выборе строки с сообщением о ошибке, строка исходного файла, в которой найдена ошибка, становится красной. Если же ошибка находится во вложенном файле, то этого подсвечивания не произойдёт.
Если по строке в окне сообщений клацнуть дважды, то окно файла с указанной ошибкой становится активным, и курсор помещается в начале строки содержащей ошибку. Если же файл с ошибкой не открыт (например это вложенный файл) то он будет автоматически открыт.
Учтите, что если вы внесли изменения в исходные тексты (добавили или удалили строки), то информация о номерах строк в окне сообщений не является корректной.
Опции
Некоторые установки программы могут быть изменены через пункт меню «Options».
В поле ввода, озаглавленном «List-file extension», вводится расширение, используемое для файла листинга, а в поле «Output-file extension» находится расширение для файлов с результатом компиляции программы. В прямоугольнике «Output file format» можно выбрать формат выходного файла (как правило используется интеловский). Однако это не влияет на объектный файл (используемый AVR Studio), который всегда имеет один и тот же формат, и расширение OBJ. Если в исходном файле присутствует сегмент EEPROM то будет также создан файл с расширением EEP. Установки заданные в данном окне запоминаются на постоянно, и при следующем запуске программы, их нет необходимости переустанавливать.
Опция «Wrap relative jumps» даёт возможность «заворачивать» адреса. Эта опция может быть использована только на чипах с объёмом программной памяти 4К слов (8К байт), при этом становится возможным делать относительные переходы (rjmp) и вызовы подпрограмм (rcall) по всей памяти.
Опция «Save before assemble» указывает программе на необходимость автоматического сохранения активного окна (и только его) перед компиляцией.
Если вы хотите, чтобы при закрытии программы закрывались все открытые окна, то поставьте галочку в поле «Close all windows before exit».
Atmel, AVR являются зарегистрированными товарными знаками фирмы Atmel Corporation
Перевод выполнил Руслан Шимкевич, [email protected]
|
Новости
Программы Turbo Pascal Игры Документация Странности FAQ Ссылки Форум Гостевая книга Рассылка Благодарности Об авторе
|
Директивы ассемблера
Встроенный ассемблер Borland Pascal поддерживает три дирек-
тивы ассемблера: DB (определить байт), DW (определить слово) и DD
(определить двойное слово). Каждая из них генерирует данные, со-
ответствующие разделенным запятым операндам, которые следуют за
директивой.
Директива DB генерирует последовательность байт. Каждый опе-
ранд может представлять собой выражение-константу со значением от
-128 до 255, или строку символов любой длины. Выражение-константа
генерирует 1 байт кода, а строки генерируют последовательность
байт со значениями, соответствующим коду ASCII каждого символа.
Директива DW генерирует последовательность слов. Каждый опе-
ранд может представлять собой выражение-константу со значением от
-32768 до 65535, или адресное выражение. Для адресного выражения
встроенный ассемблер генерирует указатель ближнего типа, что есть
слово, содержащие смещения адреса.
Директива DD генерирует последовательность двойных слов.
Каждый операнд может представлять собой выражение-константу со
значением от -2147483648 до 4294967295 или адресное выражение.
Для адресного выражения встроенный ассемблер генерирует указатель
дальнего типа, что есть слово, содержащие смещения адреса, за ко-
торым следует слово, содержащее сегментную часть адреса.
Данные, генерируемые по директивам DB, DW и DD, всегда запи-
сываются в сегмент кода, аналогично коду, генерируемому другими
операторами встроенного ассемблера. Чтобы сгенерировать инициали-
зированные или неинициализированные данные в сегменте данных, вам
следует использовать обычные описания Паскаля типа var или const.
Приведем некоторые примеры директив DB, DW и DD:
asm
DB 00FH { 1 байт }
DB 0,99 { 2 байта }
DB 'A' { Ord('A) }
DB 'Пример',0DH,OAH { строка, за которой
следуют возврат каретки и перевод строки }
B.Pascal 7 & Objects/LR - 416 -
DB 12,"Borland Pascal" { строка Паскаля }
DW 0FFFFH { 1 слово }
DW 0,9999 { 2 слова }
DW 'A' { эквивалентно DB 'A',0 }
DW 'BA' { эквивалентно DB 'A','B' }
DW MyVar { смещение MyVar }
DW MyProc { смещение MyProc }
DD 0FFFFFFFH { 1 двойное слово }
DD 0,99999999 { 2 двойных слова }
DD 'A' { эквивалентно DB 'A',0,0,0 }
DD 'DBCA' { эквивалентно DS 'A','B','C','D' }
DD MyVar { указатель на MyVar }
DD MyProc { указатель на MyProc }
end;
В Турбо Ассемблере, когда перед идентификатором указывается
DB, DW или DD, это приводит к генерации в том месте, где указана
директива, переменной размером в байт, слово или двойное слово.
Например, Турбо Ассемблер допускает следующее:
ByteVar DB ?
WordVar DW ?
.
.
.
mov al,ByteVar
mov bx,WordVar
Встроенный ассемблер не поддерживает такие описания перемен-
ных. В Borland Pascal единственным видом идентификатора, который
можно определить в операторе встроенного ассемблера, является
метка. Все переменные должны описываться с помощью синтаксиса
Паскаля, и предыдущая конструкция соответствует следующему:
var
ByteVar: Byte;
WordWat: Word;
.
.
.
asm
mov al,ByteVar
mov bx,WordVar
end;
|
Лекция 10. Массивы. — Системное программирование
массив — структурированный тип данных, состоящий из некоторого числа элементов одного типа.
Для того чтобы разобраться в возможностях и особенностях обработки массивов в программах на ассемблере, нужно ответить на следующие вопросы:
· Как описать массивв программе?
· Как инициализировать массив, то есть как задать начальные значения его элементов?
· Как организовать доступк элементам массива?
· Как организовать массивыс размерностью более одной?
· Как организовать выполнениетиповых операций с массивами?
Описание и инициализация массива в программе
Специальных средств описания массивов в программах ассемблера, конечно, нет. При необходимости использовать массив в программе его нужно моделировать одним из следующих способов:
1. Перечислением элементов массива в поле операндов одной из директив описания данных. При перечислении элементы разделяются запятыми. К примеру:
|
;массив из 5 элементов.Размер каждого элемента 4 байта: mas dd 1,2,3,4,5 |
2. Используя оператор повторения dup. К примеру:
|
;массив из 5 нулевых элементов. ;Размер каждого элемента 2 байта: mas dw 5 dup (0) |
Такой способ определения используется для резервирования памяти с целью размещения и инициализации элементов массива.
3. Используя директивы labelиrept. Пара этих директив может облегчить описание больших массивов в памяти и повысить наглядность такого описания. Директиваreptотносится к макросредствам языка ассемблера и вызывает повторение указанное число раз строк, заключенных между директивой и строкой endm. К примеру, определим массив байт в области памяти, обозначенной идентификаторомmas_b. В данном случае директиваlabelопределяет символическое имяmas_b, аналогично тому, как это делают директивы резервирования и инициализации памяти. Достоинство директивыlabelв том, что она не резервирует память, а лишь определяет характеристики объекта. В данном случае объект — это ячейка памяти. Используя несколько директивlabel, записанных одна за другой, можно присвоить одной и той же области памяти разные имена и разный тип, что и сделано в следующем фрагменте:
|
… n=0 … mas_b label byte mas_w label word rept 4 dw 0f1f0h endm |
В результате в памяти будет создана последовательность из четырех слов f1f0. Эту последовательность можно трактовать как массив байт или слов в зависимости от того, какое имя области мы будем использовать в программе —mas_bилиmas_w.
4. Использование цикла для инициализации значениями области памяти, которую можно будет впоследствии трактовать как массив.
5. Посмотрим на примере листинга 2, каким образом это делается.
|
Листинг 2 Инициализация массива в цикле ;prg_12_1.asm MASM MODEL small STACK 256 .data mes db 0ah,0dh,’Массив- ‘,’$’ mas db 10 dup (?) ;исходный массив i db 0 .code main: mov ax,@data mov ds,ax xor ax,ax ;обнуление ax mov cx,10 ;значение счетчика цикла в cx mov si,0 ;индекс начального элемента в cx go: ;цикл инициализации mov bh,i ;i в bh mov mas[si],bh ;запись в массив i inc i ;инкремент i inc si ;продвижение к следующему элементу массива loop go ;повторить цикл ;вывод на экран получившегося массива mov cx,10 mov si,0 mov ah,09h lea dx,mes int 21h show: mov ah,02h ;функция вывода значения из al на экран mov dl,mas[si] add dl,30h ;преобразование числа в символ int 21h inc si loop show exit: mov ax,4c00h ;стандартный выход int 21h end main ;конец программы |
При работе с массивами необходимо четко представлять себе, что все элементы массива располагаются в памяти компьютера последовательно.
Само по себе такое расположение ничего не говорит о назначении и порядке использования этих элементов. И только лишь программист с помощью составленного им алгоритма обработки определяет, как нужно трактовать эту последовательность байт, составляющих массив. Так, одну и ту же область памяти можно трактовать как одномерный массив, и одновременно те же самые данные могут трактоваться как двухмерный массив. Все зависит только от алгоритма обработки этих данных в конкретной программе. Сами по себе данные не несут никакой информации о своем “смысловом”, или логическом, типе. Помните об этом принципиальном моменте.
Эти же соображения можно распространить и на индексы элементов массива. Ассемблер не подозревает об их существовании и ему абсолютно все равно, каковы их численные смысловые значения.
Для того чтобы локализовать определенный элемент массива, к его имени нужно добавить индекс. Так как мы моделируем массив, то должны позаботиться и о моделировании индекса. В языке ассемблера индексы массивов — это обычные адреса, но с ними работают особым образом. Другими словами, когда при программировании на ассемблере мы говорим об индексе, то скорее подразумеваем под этим не номер элемента в массиве, а некоторый адрес.
Давайте еще раз обратимся к описанию массива. К примеру, в программе статически определена последовательность данных:
Пусть эта последовательность чисел трактуется как одномерный массив. Размерность каждого элемента определяется директивой dw, то есть она равна2байта. Чтобы получить доступ к третьему элементу, нужно к адресу массива прибавить6. Нумерация элементов массива в ассемблере начинается с нуля.
То есть в нашем случае речь, фактически, идет о 4-м элементе массива — 3, но об этом знает только программист; микропроцессору в данном случае все равно — ему нужен только адрес.
В общем случае для получения адреса элемента в массиве необходимо начальный (базовый) адрес массива сложить с произведением индекса (номер элемента минус единица) этого элемента на размер элемента массива:
база + (индекс*размер элемента)
Архитектура микропроцессора предоставляет достаточно удобные программно-аппаратные средства для работы с массивами. К ним относятся базовые и индексные регистры, позволяющие реализовать несколько режимов адресации данных. Используя данные режимы адресации, можно организовать эффективную работу с массивами в памяти. Вспомним эти режимы:
· индексная адресация со смещением — режим адресации, при котором эффективный адрес формируется из двух компонентов:
o постоянного (базового)— указанием прямого адреса массива в виде имени идентификатора, обозначающего начало массива;
o переменного (индексного)— указанием имени индексного регистра.
o К примеру:
|
mas dw 0,1,2,3,4,5 … mov si,4 ;поместить 3-й элемент массива mas в регистр ax: mov ax,mas[si] |
· базовая индексная адресация со смещением — режим адресации, при котором эффективный адрес формируется максимум из трех компонентов:
o постоянного(необязательный компонент), в качестве которой может выступать прямой адрес массива в виде имени идентификатора, обозначающего начало массива, или непосредственное значение;
o переменного (базового)— указанием имени базового регистра;
o переменного (индексного)— указанием имени индексного регистра.
Этот вид адресации удобно использовать при обработке двухмерных массивов. Пример использования этой адресации мы рассмотрим далее при изучении особенностей работы с двухмерными массивами.
Напомним, что в качестве базового регистра может использоваться любой из восьми регистров общего назначения. В качестве индексного регистра также можно использовать любой регистр общего назначения, за исключением esp/sp.
Микропроцессор позволяет масштабировать индекс. Это означает, что если указать после имени индексного регистра знак умножения “*” с последующей цифрой 2, 4 или 8, то содержимое индексного регистра будет умножаться на 2, 4 или 8, то есть масштабироваться.
Применение масштабирования облегчает работу с массивами, которые имеют размер элементов, равный 2, 4 или 8 байт, так как микропроцессор сам производит коррекцию индекса для получения адреса очередного элемента массива. Нам нужно лишь загрузить в индексный регистр значение требуемого индекса (считая от 0). Кстати сказать, возможность масштабирования появилась в микропроцессорах Intel, начиная с модели i486. По этой причине в рассматриваемом здесь примере программы стоит директива .486. Ее назначение, как и ранее использовавшейся директивы.386, в том, чтобы указать ассемблеру при формировании машинных команд на необходимость учета и использования дополнительных возможностей системы команд новых моделей микропроцессоров.
В качестве примера использования масштабирования рассмотрим листинг 3, в котором просматривается массив, состоящий из слов, и производится сравнение этих элементов с нулем. Выводится соответствующее сообщение.
|
Листинг 3. Просмотр массива слов с использованием масштабирования ;prg_12_2.asm MASM MODEL small STACK 256 .data ;начало сегмента данных ;тексты сообщений: mes1 db ‘не равен 0!$’,0ah,0dh mes2 db ‘равен 0!$’,0ah,0dh mes3 db 0ah,0dh,’Элемент $’ mas dw 2,7,0,0,1,9,3,6,0,8 ;исходный массив .code .486 ;это обязательно main: mov ax,@data mov ds,ax ;связка ds с сегментом данных xor ax,ax ;обнуление ax prepare: mov cx,10 ;значение счетчика цикла в cx mov esi,0 ;индекс в esi compare: mov dx,mas[esi*2] ;первый элемент массива в dx cmp dx,0 ;сравнение dx c 0 je equal ;переход, если равно not_equal: ;не равно mov ah,09h ;вывод сообщения на экран lea dx,mes3 int 21h mov ah,02h ;вывод номера элемента массива на экран mov dx,si add dl,30h int 21h mov ah,09h lea dx,mes1 int 21h inc esi ;на следующий элемент dec cx ;условие для выхода из цикла jcxz exit ;cx=0? Если да — на выход jmp compare ;нет — повторить цикл equal: ;равно 0 mov ah,09h ;вывод сообщения mes3 на экран lea dx,mes3 int 21h mov ah,02h mov dx,si add dl,30h int 21h mov ah,09h ;вывод сообщения mes2 на экран lea dx,mes2 int 21h inc esi ;на следующий элемент dec cx ;все элементы обработаны? jcxz exit jmp compare exit: mov ax,4c00h ;стандартный выход int 21h end main ;конец программы |
Еще несколько слов о соглашениях:
· Если для описания адреса используется только один регистр, то речь идет о базовой адресациии этот регистр рассматривается какбазовый:
|
;переслать байт из области данных, адрес которой находится в регистре ebx: mov al,[ebx] |
· Если для задания адреса в команде используется прямая адресация(в виде идентификатора) в сочетании с одним регистром, то речь идет обиндексной адресации. Регистр считаетсяиндексным, и поэтому можно использовать масштабирование для получения адреса нужного элемента массива:
|
add eax,mas[ebx*4] ;сложить содержимое eax с двойным словом в памяти ;по адресу mas + (ebx)*4 |
· Если для описания адреса используются два регистра, то речь идет о базово-индексной адресации. Левый регистр рассматривается как базовый, а правый — как индексный. В общем случае это не принципиально, но если мы используем масштабирование с одним из регистров, то он всегда являетсяиндексным. Но лучше придерживаться определенных соглашений.
· Помните, что применение регистров ebp/bpиesp/spпо умолчанию подразумевает, что сегментная составляющая адреса находится в регистреss.
Заметим, что базово-индексную адресацию не возбраняется сочетать с прямой адресацией или указанием непосредственного значения. Адрес тогда будет формироваться как сумма всех компонентов.
К примеру:
|
mov ax,mas[ebx][ecx*2] ;адрес операнда равен [mas+(ebx)+(ecx)*2] … sub dx,[ebx+8][ecx*4] ;адрес операнда равен [(ebx)+8+(ecx)*4] |
Но имейте в виду, что масштабирование эффективно лишь тогда, когда размерность элементов массива равна 2, 4 или 8 байт. Если же размерность элементов другая, то организовывать обращение к элементам массива нужно обычным способом, как описано ранее.
Рассмотрим пример работы с массивом из пяти трехбайтовых элементов (листинг 4). Младший байт в каждом из этих элементов представляет собой некий счетчик, а старшие два байта — что-то еще, для нас не имеющее никакого значения. Необходимо последовательно обработать элементы данного массива, увеличив значения счетчиков на единицу.
|
Листинг 4. Обработка массива элементов с нечетной длиной ;prg_11_3.asm MASM MODEL small ;модель памяти STACK 256 ;размер стека .data ;начало сегмента данных N=5 ;количество элементов массива mas db 5 dup (3 dup (0)) .code ;сегмент кода main: ;точка входа в программу mov ax,@data mov ds,ax xor ax,ax ;обнуление ax mov si,0 ;0 в si mov cx,N ;N в cx go: mov dl,mas[si] ;первый байт поля в dl inc dl ;увеличение dl на 1 (по условию) mov mas[si],dl ;заслать обратно в массив add si,3 ;сдвиг на следующий элемент массива loop go ;повтор цикла mov si,0 ;подготовка к выводу на экран mov cx,N show: ;вывод на экран содержимого ;первых байт полей mov dl,mas[si] add dl,30h mov ah,02h int 21h loop show exit: mov ax,4c00h ;стандартный выход int 21h end main ;конец программы |
Сборка
— Как работает БД? Разве это не байты выходного кода ассемблера?
Всем программам требуются данные:
- небольших констант, таких как 1, обычно могут быть встроены в инструкции машинного кода, которые их используют
- больших констант иногда не соответствуют форме машинного кода, поэтому перейдите в данные и на них ссылается код . Программы
- часто используют строковые литералы для имен файлов и путей, подсказок и т. Д.
- буферов хранения как пространство для чтения пользовательского ввода или из файла
- глобальных переменных, инициализированных нулем или другими
- констант с плавающей запятой хранятся в памяти, поскольку они обычно слишком велики, чтобы уместиться непосредственно в инструкции машинного кода.
Как упоминалось выше, в некоторых случаях данные могут быть встроены в инструкции машинного кода, как то, что называется немедленным, краткосрочным для режима немедленной адресации. Но во многих других случаях константы представляют собой данные, на которые ссылается машинный код, а не встроены в машинный код — адрес данных встроен в машинный код (с использованием некоторого режима адресации).
Короче говоря, нам нужно иметь возможность объявлять данные на языке ассемблера точно так же, как нам нужно иметь возможность объявлять данные на всех других языках.Также должен быть способ, чтобы программные файлы могли захватывать этот код и его данные.
Если вы помечаете данные, вы можете использовать (сделать ссылку) эту метку из вашего кода и данных.
У большинства ассемблеров также есть понятие отдельных разделов кода и данных. Директива .data (или то, что подходит для этого ассемблера) укажет ассемблеру собрать последующие объявления данных вместе в раздел данных вывода ассемблера и компоновщика.Обычно в исходном коде сборки мы можем переключаться между разделами кода и данных, чтобы хранить данные, относящиеся к коду, поблизости в источнике, но, возможно, собирать отдельно в созданном программном файле в соответствии с тем, как определены программные файлы.
Z80 — Директивы ассемблера
Ассемблер Z80 — Директивы ассемблераdb, defb, dm или defm
db означает «определить байт», dm — «определить сообщение». Это позволяет определение
одного или нескольких буквальных байтов, а также строк байтов.Все определения
следует разделять запятыми. Строки байтов должны быть между двойными
Котировки. Пример кода:
label: equ 20
defb "Это текст", label / 2, "Это еще текст", 10, 0
dw или defw
dw означает «определение слова». Это удобная директива для определения
младший байт первых двух байтовых слов, поскольку Z80 их использует. Несколько
могут быть указаны выражения, разделенные запятыми. Пример:
org 0x8000
pointertable: defw sub1, sub2
sub1: sub b
ret nz
sub2: ld h, 0
ret
ds или defs
ds означает «определить пространство».Требуется один или два аргумента, num и
вал . Он резервирует num байтов и инициализирует их для
вал . Если val опущено, по умолчанию используется 0. Пример:
буфер: defs 20
семерки: defs 10, 7
конец
В конце программы можно использовать директиву «end». Там в этом нет необходимости. Все, что находится после этой директивы, игнорируется. Это может можно использовать для добавления комментариев в конце.
org
Устанавливает представление ассемблера о текущем адресе. Требуется один аргумент, который должен оцениваться как значение в первом проходе (он не может использовать метки, которые будут определены позже).
Вначале текущий адрес установлен на 0. Обычно первый директива в программе — org, чтобы установить начальный адрес.
Использование этой директивы более одного раза может быть полезно для создания кода, который выполняться по тому же адресу, например, при отображении памяти.На начало каждой страницы, код может установить начальный адрес для сопоставления адрес. Ранее определенные страницы не перезаписываются.
Обратите внимание, что эта директива не генерирует код, поэтому, если байты заполнения
требуется, они должны быть вставлены с помощью defs. Org меняет только ассемблер
представление о том, «где» это. В следующем примере вывод содержит 4 байта:
23, 12, 00, 00.
first_label: defw second_label
org 0x1234
second_label: defw first_label
искать
Люди запросили возможность перезаписать сгенерированный вывод.Это для чего нужен поиск. Он будет искать в выходном файле и начинать перезапись предыдущий вывод. В основном это полезно в сочетании с incbin. Это позволяет включенный двоичный файл должен быть «исправлен».
Если аргумент поиска больше, чем текущий размер вывода, файл дополнен нулями.
включает
Как и в C (но без символа #), сюда входит другой исходный файл. Нет
замена вообще выполняется в имени файла, что означает, что ~ не может быть
используется для обозначения домашнего каталога.Практически любой
имя возможно без escape-символов из-за правил кавычек. В
первый непробельный символ после директивы include считается
начальная цитата. Затем читается имя файла до последней кавычки, которая
то же, что и начальная цитата. Пример:
include 'math.asm'
include -file 'с "кавычками" .asm-
включить zletter в качестве кавычек и пробелов в name.asmz
incbin
Incbin означает «включать двоичный файл». Это позволяет любым двоичным данным быть дословно включается в вывод.Аргумент приводится так же, как для включения.
if, else, endif
С помощью этих условных операторов можно опустить части кода.
иначе можно повторять сколько угодно раз. Код, который не собран,
проверил правильность команды. В противном случае его не трогают, а это значит, что
если вы используете эти директивы, успешное выполнение ассемблера не подразумевает
что весь код правильный. Пример:
org 0x8000
включает "math.asm"
, если $ <0x9000; Сделайте следующее, только если математика.asm достаточно мал
ld a, 3
else
ld a, 6
else
; он также собирается, только если math.asm достаточно мал
ld h, 8
endif
; он всегда собирается
call math_init
макрос, endm
С помощью этих директив можно определить новые команды, которые будут выводить определенный код. также могут быть приведены аргументы. Пример:
callf: слот макроса, адрес
rst 0x30
слот db
адрес DW
конец
После этого определения можно использовать макрос, например:
callf 0x8b, 0x4000
8086 Учебник по ассемблеру для начинающих (часть 3)
8086 Учебник по ассемблеру для начинающих (часть 3)8086 Учебник ассемблера для начинающих (часть 3)
Переменные
Переменная — это ячейка памяти.Программисту гораздо проще иметь значение будет сохранено в переменной с именем « var1 «, затем по адресу 5A73: 235B, особенно когда у вас 10 или более переменных.Наш компилятор поддерживает два типа переменных: BYTE и WORD .
|
Синтаксис для объявления переменной: имя DB значение имя DW значение DB — остается для 9014fine D yte. имя — может быть любое сочетание букв или цифр, хотя он должен начинаться с буквы. Можно объявить безымянные переменные без указания имени (эта переменная будет иметь адрес, но не имя). значение — может быть любым числовым значением в любом поддерживаемом система счисления (шестнадцатеричная, двоичная или десятичная), или символ «? » для переменных, которые не инициализирован. |
Как вы, наверное, знаете из , часть 2 этого руководства,
MOV Инструкция используется для копирования значений из источника в место назначения.
Давайте посмотрим на другой пример с инструкцией MOV :
ORG 100ч MOV AL, var1 MOV BX, var2 RET; останавливает программу. VAR1 DB 7 var2 DW 1234h |
Скопируйте приведенный выше код в редактор исходного кода и нажмите клавишу F5 , чтобы скомпилируйте его и загрузите в эмулятор.У вас должно получиться что-то вроде:
Как видите, это очень похоже на наш пример, за исключением того, что переменные заменены с фактическими ячейками памяти. Когда компилятор создает машинный код, он автоматически заменяет все имена переменных на их смещения . По умолчанию сегмент загружается в регистр DS (при загрузке файлов COM значение регистра DS устанавливается на то же значение, что и регистр CS — сегмент кода).
В списке памяти первая строка — это смещение , вторая строка — это шестнадцатеричное значение , третья строка — десятичное значение , а последняя строка — значение символа ASCII .
Компилятор не чувствителен к регистру, поэтому « VAR1 » и « var1 » относятся к одной и той же переменной.
Смещение VAR1 — 0108h , а полный адрес — 0B56: 0108 .
Смещение var2 — 0109h , а полный адрес — 0B56: 0109 , эта переменная — WORD , поэтому она занимает 2 БАЙТА . Предполагается, что младший байт хранится по младшему адресу, поэтому 34h находится перед 12h .
Вы можете видеть, что есть некоторые другие инструкции после RET
инструкция
это происходит потому, что дизассемблер не знает, где начинаются данные,
он просто обрабатывает значения в памяти и понимает их как
действующие инструкции 8086 (мы узнаем их позже).
Вы даже можете написать ту же программу, используя только директиву DB :
ORG 100ч DB 0A0h DB 08h DB 01h DB 8Bh DB 1Eh DB 09h DB 01h DB 0C3h DB 7 DB 34h DB 12h |
Скопируйте приведенный выше код в редактор исходного кода и нажмите клавишу F5 , чтобы скомпилировать и загрузить в эмулятор.У вас должен получиться такой же дизассемблированный код, и такой же функционал!
Как вы можете догадаться, компилятор просто преобразует исходный код программы в набор байтов, этот набор называется , машинный код , процессор понимает машинный код и выполняет его.
ORG 100h — директива компилятора (сообщает компилятору, как
обрабатывать исходный код). Эта директива очень важна, когда вы
работать с переменными. Он сообщает компилятору, что исполняемый файл
будет загружен со смещением из 100h (256 байт), поэтому компилятор
должен вычислить правильный адрес для всех переменных, когда
он заменяет имена переменных их смещениями .Директивы никогда не преобразуются в настоящий машинный код .
Почему исполняемый файл загружается со смещением из 100h ? Операционная
система хранит некоторые данные о программе в первых 256 байтах
CS (сегмент кода), такие как параметры командной строки и т. д.
Хотя это верно только для файлов COM , загружаются файлы EXE
со смещением 0000 , и обычно используйте специальный сегмент для переменных.
Возможно, мы поговорим подробнее о файлах EXE позже.
Массивы
Массивы можно рассматривать как цепочки переменных. Текстовая строка является примером байтовый массив, каждый символ представлен в виде значения кода ASCII (0..255).
Вот несколько примеров определения массива:
a DB 48h, 65h, 6Ch, 6Ch, 6Fh, 00h
b DB 'Hello', 0
b является точной копией массива a , когда компилятор видит строка внутри кавычек автоматически преобразует ее в набор байтов. Этот На диаграмме показана часть памяти, в которой объявлены эти массивы:
Вы можете получить доступ к значению любого элемента в массиве, используя квадратные скобки,
например:
MOV AL, a [3]
Также можно использовать любой из индексных регистров памяти BX, SI, DI, BP ,
например:
MOV SI, 3
MOV AL, a [SI]
Если вам нужно объявить большой массив, вы можете использовать оператор DUP .
Синтаксис для DUP :
номер DUP ( значение (я) )
число — количество дубликатов, которое нужно сделать (любое постоянное значение).
значение — выражение, которое DUP будет дублировать.
например:
c DB 5 DUP (9)
— альтернативный способ объявления:
в DB 9, 9, 9, 9, 9
еще один пример:
d DB 5 DUP (1, 2)
— альтернативный способ объявления:
г DB 1, 2, 1, 2, 1, 2, 1, 2, 1, 2
Конечно, вы можете использовать DW вместо DB , если необходимо сохранить значения больше 255 или меньше -128. DW нельзя использовать объявить строки.
Получение адреса переменной
Имеется инструкция LEA (Загрузить эффективный адрес) и
альтернативный оператор OFFSET . Оба OFFSET и
LEA может использоваться для получения адреса смещения переменной.
LEA более мощный, потому что он также позволяет получить адрес
индексированные переменные. Получение адреса переменной может быть очень полезным
в некоторых ситуациях, например, когда вам нужно передать параметры в процедуру.
Напоминание:
Чтобы сообщить компилятору о типе данных,
следует использовать следующие префиксы:
BYTE PTR — для байта.
WORD PTR — для слова (два байта).
Например:
BYTE PTR [BX]; байтовый доступ.
или же
WORD PTR [BX]; слово доступ.
Ассемблер поддерживает также более короткие префиксы: b. — для BYTE PTR
w. — для WORD PTR
в некоторых случаях ассемблер может вычислить тип данных автоматически.
Вот первый пример:
ORG 100ч MOV AL, VAR1; проверьте значение VAR1, переместив его в AL. LEA BX, VAR1; получить адрес VAR1 в BX. MOV BYTE PTR [BX], 44ч; изменить содержимое VAR1. MOV AL, VAR1; проверьте значение VAR1, переместив его в AL. RET VAR1 DB 22ч КОНЕЦ |
Вот еще один пример, в котором используется OFFSET вместо LEA :
ORG 100ч MOV AL, VAR1; проверьте значение VAR1, переместив его в AL.MOV BX, СМЕЩЕНИЕ VAR1; получить адрес VAR1 в BX. MOV BYTE PTR [BX], 44ч; изменить содержимое VAR1. MOV AL, VAR1; проверьте значение VAR1, переместив его в AL. RET VAR1 DB 22ч КОНЕЦ |
Оба примера имеют одинаковую функциональность.
Эти строки:
LEA BX, VAR1
MOV BX, OFFSET VAR1
даже скомпилированы в один и тот же машинный код: MOV BX, num
num — это 16-битное значение переменной смещения.
Обратите внимание, что можно использовать только эти регистры.
внутри квадратных скобок (как указатели на память):
BX, SI, DI, BP !
(см. Предыдущую часть учебника).
Константы
Константы похожи на переменные, но они существуют только до тех пор, пока ваша программа компилируется (собирается). После определения константы ее значение не может быть изменен. Для определения констант используется директива EQU :
name EQU <любое выражение>
Например:
Функционально приведенный выше пример идентичен коду:
Вы можете просматривать переменные во время выполнения программы, выбрав « Variables » из меню эмулятора « View ».
Для просмотра массивов необходимо щелкнуть по переменной и установить свойство Elements к размеру массива. В ассемблере нет строгих типов данных, поэтому любая переменная можно представить в виде массива.
Переменную можно просмотреть в любой системе счисления:
- HEX — шестнадцатеричный (основание 16).
- БИН — двоичный (по основанию 2).
- OCT — восьмеричный (основание 8).
- SIGNED — десятичное число со знаком (основание 10).
- UNSIGNED — десятичное без знака (основание 10).
- CHAR — код символа ASCII (всего 256 символов, некоторые символы невидимы).
Вы можете редактировать значение переменной во время работы вашей программы, просто дважды щелкните по ней, или выберите его и нажмите кнопку Изменить .
Можно вводить числа в любой системе, шестнадцатеричные числа должны иметь
Суффикс « h », двоичный суффикс « b », восьмеричный суффикс « o », десятичные числа
не требует суффикса.Строку можно ввести следующим образом:
‘hello world’, 0
(эта строка заканчивается нулем).
Массивы можно ввести следующим образом:
1, 2, 3, 4, 5
(массив может быть массивом байтов или слов, это зависит от того, выбрано BYTE или WORD
для редактируемой переменной).
Выражения преобразуются автоматически, например:
при вводе этого выражения:
5 + 2
оно будет преобразовано в 7 и т. Д…
<<< предыдущая часть <<< >>> Следующая часть >>>
Использование REPT и IRP
Использование REPT и IRPДиректива REPT будет повторять блок кода указанное количество раз. REPT не имеет имени, поэтому его нельзя вызывать как макрос. Тем не мение, поместив REPT внутрь макроса, можно создать тот же эффект.
REPT, который действует как dup
Поместив этот REPT в файл.Сегмент DATA, можно выделить память.
ПОВТОР 10 db 0 конец
Это сгенерирует 10 байтов со значением 0. Однако это не очень интересно, так как это то же самое, что db 10 dup (0) .
REPT для размещения и инициализации данных с разными значения
Используя = для создания переменной ассемблера, можно создать и инициализировать байты разными значениями.
значение = 0 ПОВТОР 10 значение db значение = значение + 1 конец
Теперь это создаст блок из десяти байтов, инициализированный значениями 0 .. 9.
Этот REPT можно использовать внутри сегмента данных следующим образом
список байтов метки значение = 0 ПОВТОР 4 значение db значение = значение + 1 конец
И будет генерировать операторы ассемблера
список байтов метки db 0 дб 1 db 2 дб 3
Важно, чтобы метка не входила в REPT, иначе каждый db будет иметь такую же метку.
REPT для присвоения каждому байту уникальной метки
Можно пометить каждую базу данных другой меткой, добавив номер к названию метки.
список байтов метки значение = 0 ПОВТОР 4 список и значение значение db значение = значение + 1 конец
Это сгенерирует следующий ассемблер
список байтов метки list0 db 0 list1 db 1 list2 db 2 list3 db 3
Размещение REPT внутри макроса
Чтобы сделать это еще более полезным, поместите REPT в макрос, чтобы он мог звонить повторно.
определить количество макросов значение = 0 Количество повторов значение db значение = значение + 1 конец конец
Теперь это можно вызывать несколько раз.
список байтов метки определить 4 определить 3
Это сгенерирует следующий ассемблер
список байтов метки db 0 дб 1 db 2 дб 3 db 0 дб 1 db 2
IRP для распределения и инициализации данных с разными значения
IRP похож на REPT, за исключением того, что IRP перебирает значения, которые вы его отправляете. Если вы отправите четыре элемента, IRP будет повторяться 4 раза. Здесь тот же макрос, что и выше, с использованием IRP вместо REPT
IRP arg,db arg конец
Это называлось бы как REPT
список байтов метки IRP arg, <0,1,2,3> db arg конец
Это сгенерирует тот же ассемблер, что и выше.
список байтов метки db 0 дб 1 db 2 дб 3
Кажется, нужно больше работать, чтобы заставить это работать, так как каждое значение должно быть указано внутри <>. Однако у IRP больше гибкости, чем у REPT. REPT — это ограничивается инициализациями, которые могут быть сгенерированы формулой, тогда как IRP может повторяться над произвольными значениями. Следующее нельзя было сделать с помощью ПОВТОР
IRP arg, <5,15,8,2> db arg конец
Это сгенерирует
дБ 5 дб 15 дб 8 db 2
Размещение IRP внутри макроса
Чтобы сделать IRP более универсальным, поместите его в макрос
создать макрос argList IRP arg,db arg конец конец
Затем позвоните несколько раз.Вы можете вызвать макрос define , который использует REPT тоже.
байт метки таблицы создать <0,5,8> определить 3 создать <10,15,3,7>
Что сгенерирует
байт метки таблицы db 0 дб 5 дб 8 db 0 дб 1 дб 3 дб 10 дб 15 дб 3 дб 7
Цикл for с использованием IRP
Это макрос, который был разработан на странице макросов. Здесь стойка расширяется с помощью IRP, так что можно включить более одного оператора в макросе.
forloop макрос start, stop, incr, statementList местный топ, готово толкать топор mov ax, start вверху: cmp ax, stop jge сделано Заявление IRP,утверждение конец добавить топор, incr jmp top Выполнено: топор конец
Теперь его можно было вызвать с помощью более чем одного оператора. Это добавит петлю контролируйте переменную в bx и вычтите ее в cx.
xor bx, bx xor cx, cx forloop 20,5, -4, << добавить bx, ax>, >
Это сгенерирует
толкающий топор мов топор, 20 top1: cmp ax, 5 jge done1 добавить bx, ax sub cx, ax добавить топор, -4 jmp top1 done1: топор
Используя оператор продолжения инструкции \, можно сделать назовите более читабельным.
xor bx, bx xor cx, cx forloop 20,5, -4, \ <\ <добавить bx, ax>, \ \ >
3.2. Псевдо-инструкции
3.2. Псевдо-инструкции
Псевдо-инструкции — это вещи, которые, хотя и не являются настоящими машинными инструкциями x86,
в любом случае используется в поле инструкции, потому что это наиболее удобное место для размещения
их. Текущие псевдо-инструкции: DB , DW , DD , DQ ,
DT , DDQ , DO , их неинициализированные аналоги RESB ,
RESW , RESD , RESQ , REST , RESDDQ и RESO , команда INCBIN , команда EQU и
TIMES префикс.
3.2.1.
DB и друзья: объявление инициализированных данных
DB , DW , DD , DQ , DT ,
DDQ и DO используются для объявления инициализированных данных в
выходной файл. Их можно вызывать разными способами:
db 0x55; просто байт 0x55
db 0x55,0x56,0x57; три байта подряд
db 'a', 0x55; символьные константы в порядке
db 'привет', 13,10, '$'; так строковые константы
dw 0x1234; 0x34 0x12
dw 'a'; 0x41 0x00 (это просто число)
dw 'ab'; 0x41 0x42 (символьная константа)
dw 'abc'; 0x41 0x42 0x43 0x00 (строка)
dd 0x12345678; 0x78 0x56 0x34 0x12
dq 0x1122334455667788; 0x88 0x77 0x66 0x55 0x44 0x33 0x22 0x11
ddq 0x112233445566778899aabbccddeeff00
; 0x00 0xff 0xee 0xdd 0xcc 0xbb 0xaa 0x99
; 0x88 0x77 0x66 0x55 0x44 0x33 0x22 0x11
сделать 0x112233445566778899aabbccddeeff00; такой же, как и предыдущий
дд 1.234567e20; константа с плавающей запятой
dq 1.234567e20; поплавок двойной точности
dt 1.234567e20; поплавок повышенной точности
DT не принимает числовые константы в качестве операндов, а DDQ не принимает числа с плавающей запятой.
константы как операнды. Любой размер больше DD не принимает строки как
операнды.
3.2.2.
RESB и друзья: Объявление
Неинициализированные данные
RESB , RESW , RESD ,
RESQ , REST , RESDQ и RESO являются
предназначены для использования в разделе BSS модуля: они объявляют неинициализированного пространства для хранения .Каждый принимает один операнд,
который представляет собой количество байтов, слов, двойных слов или чего-то еще, что нужно зарезервировать. NASM не
поддерживать синтаксис MASM / TASM для резервирования неинициализированного пространства путем записи DW? или подобные вещи: это то, что он делает вместо этого. Операнд для
Псевдо-инструкция RESB типа является критическим выражением : см. Раздел 3.8.
Например:
буфер: resb 64; зарезервировать 64 байта wordvar: resw 1; зарезервировать слово realarray resq 10; массив из десяти реалов
3.2.3.
INCBIN : включая внешние
Двоичные файлы
INCBIN включает
двоичный файл дословно в выходной файл. Это может быть удобно (например) для включения
графические и звуковые данные прямо в игру
запускаемый файл. Однако рекомендуется использовать это только для небольших фрагментов данных. Его можно назвать одним из этих трех
способы:
incbin "file.dat"; включить весь файл
incbin "file.dat", 1024; пропустить первые 1024 байта
incbin "файл.dat ", 1024 512; пропустить первые 1024 и
; фактически включает не более 512
3.2.4.
EQU : Определение констант
EQU определяет символ для данного постоянного значения: когда используется EQU , исходная строка должна содержать метку. Действие
EQU определяет имя данной метки для значения ее
(только) операнд. Это определение является абсолютным и не может быть изменено позже. Таким образом, для
например,
message db 'привет, мир' msglen equ $ -сообщение
определяет msglen как константу 12. msglen не может быть переопределен позже. Это тоже не определение препроцессора:
значение msglen оценивается один раз в , используя значение $ (см.
Раздел 3.6 для
объяснение $ ) в пункте определения, а не
оценивается везде, где на него ссылаются, и использует значение $ в качестве ориентира. Обратите внимание, что операнд для EQU также является критическим выражением (раздел 3.8).
3.2.5.
РАЗ : Повторение
Инструкции или данные
Префикс TIMES вызывает
инструкция собирать несколько раз. Это частично присутствует в NASM
эквивалент синтаксиса DUP , поддерживаемого MASM-совместимым
ассемблеры, в которых вы можете кодировать
zerobuf: раз 64 дБ 0
или аналогичные вещи; но TIMES более универсален, чем это.
Аргумент TIMES — это не просто числовая константа, а
числовое выражение , поэтому вы можете делать такие вещи, как
буфер: db 'привет, мир'
раз 64 - $ + буфер db ''
, который будет хранить ровно столько места, чтобы сделать общую длину буфера до 64.Наконец, РАЗ может быть
применяется к обычным инструкциям, поэтому вы можете закодировать в нем тривиальные развернутые циклы:
умножить на 100 мовсб
Обратите внимание, что нет эффективной разницы между , умноженной на 100.
resb 1 и resb 100 , за исключением того, что последний будет
собирается примерно в 100 раз быстрее за счет внутреннего устройства ассемблера.
Операнд для TIMES , как и для EQU , а также для RESB и других, является
критическое выражение (раздел 3.8).
Обратите внимание, что TIMES нельзя применять к макросам: причина в том, что
TIMES обрабатывается после макро фазы, что позволяет
аргумент TIMES , чтобы содержать такие выражения, как
64 - $ + буфер , как указано выше. Чтобы повторить более одной строки кода,
или сложный макрос, используйте директиву препроцессора % rep .
NASM Руководство
NASMСледующая глава | Предыдущая глава | Содержание | Индекс
3.1 Схема исходной строки NASM
Как и большинство ассемблеров, каждая строка исходного кода NASM содержит (если это не макрос, директива препроцессора или директива ассемблера: см. глава 4 и глава 5) некоторая комбинация четырех полей
метка: операнды инструкции; комментарий
Как обычно, большинство этих полей являются необязательными; наличие или отсутствие Допускается любое сочетание метки, инструкции и комментария. Из конечно, поле операнда либо требуется, либо запрещено из-за наличия и характер поля инструкции.
NASM использует обратную косую черту (\) в качестве символа продолжения строки; если линия заканчивается обратной косой чертой, следующая строка считается частью Линия с обратной косой чертой.
NASM не накладывает ограничений на пробелы в строке: метки могут
перед ними должен быть пробел, или в инструкциях может не быть пробела перед
их или что-нибудь. Двоеточие после метки также необязательно. (Обратите внимание, что
это означает, что если вы собираетесь кодировать только lodsb
на линии, а набери случайно lodab , то
это все еще действительная исходная строка, которая ничего не делает, кроме определения метки.Запуск NASM с параметром командной строки
-w + orphan-labels заставит вас предупредить вас, если вы
определить только метку в строке без конечного двоеточия.)
Допустимые символы на этикетках: буквы, цифры,
_ , $ ,
# , @ ,
~ , . и
? . Единственные символы, которые могут использоваться в качестве
первые символов идентификатора — буквы,
. (со специальным значением: см.
Раздел 3.9), _ и
? . Идентификатор также может иметь префикс
$ , чтобы указать, что его следует читать как
идентификатор, а не зарезервированное слово; таким образом, если какой-то другой модуль вы
связывание с определяет символ под названием eax , вы можете
см. $ eax в коде NASM, чтобы различать
символ из реестра.
Поле инструкций может содержать любую машинную инструкцию: Pentium и
Инструкции P6, инструкции FPU, инструкции MMX и даже недокументированные
все инструкции поддерживаются.Инструкция может иметь префикс
ЗАМОК , REP ,
REPE / REPZ или
REPNE / REPNZ , в
обычный способ. Явные префиксы размера адреса и размера операнда
A16 , A32 ,
O16 и O32 являются
при условии — один пример их использования приведен в
глава 9. Вы также можете использовать имя
сегментный регистр как префикс инструкции: кодирование
es mov [bx], ax эквивалентно кодированию
mov [es: bx], ax .Мы рекомендуем последний синтаксис,
поскольку это согласуется с другими синтаксическими особенностями языка, но
для таких инструкций, как LODSB , в котором нет
операндов, но при этом может потребоваться переопределение сегмента, нет чистого
синтаксический способ исходить кроме es lodsb .
Для использования префикса инструкция не требуется: префиксы, такие как
CS , A32 ,
LOCK или REPE могут появиться
в отдельной строке, и NASM просто сгенерирует байты префикса.
Помимо собственно машинных инструкций, NASM также поддерживает ряд псевдо-инструкций, описанных в разделе 3.2.
Командные операнды могут принимать различные формы: они могут быть регистрами,
описывается просто именем регистра (например, ax ,
BP , EBX ,
cr0 : NASM не использует
gas — стиль синтаксиса, в котором имена регистров должны быть
с префиксом % ), или они могут быть эффективными
адреса (см. раздел 3.3), константы
(раздел 3.4) или выражения
(раздел 3.5).
Для инструкций с плавающей запятой NASM принимает широкий спектр синтаксисов: вы можете использовать формы с двумя операндами, такие как MASM, или вы можете использовать NASM в большинстве случаев нативные формы с одним операндом. Подробная информация обо всех формах каждого поддерживаемые инструкции приведены в приложении B. Например, вы можете закодировать:
fadd st1; это устанавливает st0: = st0 + st1
fadd st0, st1; так делает это
fadd st1, st0; это устанавливает st1: = st1 + st0
fadd to st1; так делает это
Практически любая инструкция с плавающей запятой, которая ссылается на память, должна использовать
один из префиксов DWORD ,
QWORD или TWORD до
указать, к какому размеру операнда памяти он относится.
3.2 Псевдо-инструкции
Псевдо-инструкции — это вещи, которые, хотя и не являются реальной машиной x86.
инструкции, в любом случае используются в поле инструкции, потому что это
самое удобное место для их размещения. Текущие псевдо-инструкции
DB , DW ,
DD , DQ и
DT , их неинициализированные аналоги
RESB , RESW ,
RESD , RESQ и
REST , INCBIN
команда, команда EQU и
TIMES префикс.
3.2.1
DB и другие: объявление инициализированных данных
DB , DW ,
DD , DQ и
DT используются, как и в MASM, для объявления
инициализированные данные в выходном файле. Их можно вызывать в широком диапазоне
способы:
db 0x55; просто байт 0x55
db 0x55,0x56,0x57; три байта подряд
db 'a', 0x55; символьные константы в порядке
db 'привет', 13,10, '$'; так строковые константы
dw 0x1234; 0x34 0x12
dw 'a'; 0x41 0x00 (это просто число)
dw 'ab'; 0x41 0x42 (символьная константа)
dw 'abc'; 0x41 0x42 0x43 0x00 (строка)
dd 0x12345678; 0x78 0x56 0x34 0x12
дд 1.234567e20; константа с плавающей запятой
dq 1.234567e20; поплавок двойной точности
dt 1.234567e20; поплавок повышенной точности
DQ и DT не
принимать числовые константы или строковые константы в качестве операндов.
3.2.2
RESB и друзья: Объявление неинициализированных данных
РЕСБ , РЕСВ ,
RESD , RESQ и
REST предназначены для использования в секции BSS
модуля: они объявляют неинициализированных дисковых пространств.Каждый берет
одиночный операнд, который представляет собой количество байтов, слов, двойных слов или
все, что нужно зарезервировать. Как указано в
раздел 2.2.7, NASM не
поддерживать синтаксис MASM / TASM для резервирования неинициализированного пространства путем записи
DW? или похожие вещи: вот что он делает
вместо. Операнд типа RESB
псевдо-инструкция — это критическое выражение : см.
раздел 3.8.
Например:
буфер: resb 64; зарезервировать 64 байта wordvar: resw 1; зарезервировать слово realarray resq 10; массив из десяти реалов
3.2.3
INCBIN : включая внешние двоичные файлы
INCBIN заимствован у старой Амиги
Ассемблер DevPac: он дословно включает двоичный файл в выходной файл.
Это может быть удобно (например) для включения графических и звуковых данных.
прямо в исполняемый файл игры. Его можно назвать одним из этих
три способа:
incbin "file.dat"; включить весь файл
incbin "file.dat", 1024; пропустить первые 1024 байта
incbin "файл.dat ", 1024 512; пропустить первые 1024 и
; фактически включает не более 512
3.2.4
EQU : Определение констант
EQU определяет символ для данной константы
значение: при использовании EQU исходная строка должна
содержать метку. Действие EQU заключается в определении
данное имя метки равняется значению его (единственного) операнда. Это определение
абсолютный и не может быть изменен позже. Так, например,
message db 'привет, мир' msglen equ $ -сообщение
определяет msglen как константу 12. msglen не может быть переопределен позже. Это
не определение препроцессора: значение
msglen оценивается один раз , используя
стоимость $ (см. раздел
3.5 для объяснения $ ) в пункте
определение, а не оцениваться везде, где на него ссылаются, и с использованием
стоимость $ в точке отсчета. Примечание
что операнд для EQU также является критическим
выражение (раздел 3.8).
3.2.5
TIMES : повторение инструкций или данных
Префикс TIMES заставляет инструкцию быть
собран несколько раз. Это частично присутствует как эквивалент NASM
синтаксис DUP , поддерживаемый MASM-совместимым
ассемблеры, в которых вы можете кодировать
zerobuf: раз 64 дБ 0
или аналогичные вещи; а вот TIMES универсальнее
чем это. Аргумент TIMES — это не просто
числовая константа, но числовое выражение , так что вы можете что-то делать
нравиться
буфер: db 'привет, мир'
раз 64 - $ + буфер db ''
, в котором будет ровно столько места, чтобы обеспечить общую длину
буфер до 64.Ну наконец то,
TIMES может применяться к обычным инструкциям, поэтому
вы можете закодировать в нем тривиальные развернутые циклы:
умножить на 100 мовсб
Обратите внимание, что нет эффективной разницы между
раз 100 resb 1 и
resb 100 , разве что последний будет
собирается примерно в 100 раз быстрее за счет внутренней структуры
ассемблер.
Операнд для TIMES , как и для
EQU и RESB
и друзья, это критическое выражение (раздел
3.8).
Обратите внимание, что TIMES нельзя применить к
макросы: причина в том, что РАЗ
обрабатывается после макро-фазы, что позволяет аргументу
TIMES , чтобы содержать такие выражения, как
64 - $ + буфер , как указано выше. Чтобы повторить более одного
строка кода или сложный макрос, используйте препроцессор
% rep директива.
3.3 Действующие адреса
Эффективный адрес — это любой операнд инструкции, которая ссылается на объем памяти.У эффективных адресов в NASM очень простой синтаксис: они состоят из выражения, оценивающего желаемый адрес, заключенного в квадратных скобках. Например:
wordvar dw 123
mov ax, [wordvar]
mov ax, [wordvar + 1]
mov ax, [es: wordvar + bx]
Все, что не соответствует этой простой системе, не является допустимой памятью.
ссылка в NASM, например es: wordvar [bx] .
Более сложные эффективные адреса, например, с адресами более один регистр, работают точно так же:
mov eax, [ebx * 2 + ecx + смещение]
mov ax, [bp + di + 8]
NASM может выполнять алгебру по этим эффективным адресам, так что вещи, которые не обязательно выглядят законными, совершенно нормальны:
mov eax, [ebx * 5]; собирается как [ebx * 4 + ebx]
mov eax, [метка1 * 2-метка2]; т.е. [метка1 + (метка1-метка2)]
Некоторые формы действующего адреса имеют более одной собранной формы; в
в большинстве таких случаев NASM генерирует наименьшую возможную форму.Например,
существуют отдельные формы для 32-битных эффективных адресов
[eax * 2 + 0] и
[eax + eax] , и NASM обычно генерирует
последнее на том основании, что для первого требуется четыре байта для хранения нуля
компенсировать.
NASM имеет механизм подсказки, который вызывает
[eax + ebx] и [ebx + eax]
генерировать разные коды операций; это иногда бывает полезно, потому что
[esi + ebp] и [ebp + esi]
имеют разные регистры сегментов по умолчанию.
Однако вы можете заставить NASM сгенерировать эффективный адрес в
конкретная форма с использованием ключевых слов BYTE ,
WORD , DWORD и
НОСПЛИТ . Если тебе надо
[eax + 3] для сборки с использованием двойного слова
поле смещения вместо однобайтового, которое обычно генерирует NASM, вы можете
код [dword eax + 3] . Точно так же вы можете заставить NASM
использовать байтовое смещение для небольшого значения, которого он не видел на первом
пройти (см. раздел 3.8 для примера такого
фрагмент кода) с использованием [байт eax + смещение] . В виде
особые случаи, [byte eax] будет кодировать
[eax + 0] с нулевым байтовым смещением, и
[dword eax] закодирует его двойным словом
смещение нуля. В нормальной форме [eax] будет
кодируется без поля смещения.
Форма, описанная в предыдущем абзаце, также полезна, если вы пытается получить доступ к данным в 32-битном сегменте из 16-битного кода. Для большего информацию об этом см. в разделе об адресации смешанного размера. (раздел 9.2). В частности, если вам необходимо получить доступ к данным с известным смещением, которое больше, чем уместится в 16-битное значение, если вы не укажете, что это смещение двойного слова, nasm будет вызывает потерю старшего слова смещения.
Аналогичным образом NASM разделит [eax * 2] на
[eax + eax] , потому что это позволяет полю смещения
отсутствовать и экономить место; на самом деле, он также разделится
[eax * 2 + смещение] в
[eax + eax + offset] . Вы можете бороться с этим поведением
с помощью ключевого слова NOSPLIT :
[nosplit eax * 2] заставит
[eax * 2 + 0] должно быть сгенерировано буквально.
3,4 Константы
NASM понимает четыре различных типа констант: числовые, символьные, строка и с плавающей точкой.
3.4.1 Числовые константы
Числовая константа — это просто число. NASM позволяет указать
числа в различных основаниях счисления разными способами: вы можете использовать суффикс
H , Q и
B для шестнадцатеричной, восьмеричной и двоичной системы, или вы можете префикс
0x для шестнадцатеричного в стиле C, или вы можете префикс
$ за шестигранник в стиле Borland Pascal.Примечание,
однако префикс $ выполняет двойную функцию
префикс идентификаторов (см. раздел 3.1), поэтому
шестнадцатеричный номер с префиксом $ должен иметь
цифра после $ , а не буква.
Некоторые примеры:
mov ax, 100; десятичный
mov ax, 0a2h; шестнадцатеричный
mov ax, $ 0a2; снова шестнадцатеричный: требуется 0
mov ax, 0xa2; шестнадцатеричный еще раз
mov ax, 777q; восьмеричный
mov ax, 10010011b; двоичный
3.4.2 Символьные константы
Символьная константа состоит до четырех символов, заключенных в одинарные или двойные кавычки. Тип котировки не имеет значения для NASM, за исключением, конечно, того, что константа заключена в одинарные кавычки позволяет использовать двойные кавычки и наоборот.
Символьная константа, содержащая более одного символа, будет упорядочена с порядок обратного порядка байтов: если вы кодируете
mov eax, 'abcd'
, то сгенерированная константа не 0x61626364 ,
но 0x64636261 , так что если бы вы затем хранили
значение в памяти, оно будет читать abcd скорее
чем dcba .Это тоже чувство характера
константы, понимаемые Pentium CPUID
инструкция (см. раздел
В.4.34).
3.4.3 Строковые константы
Строковые константы приемлемы только для некоторых псевдо-инструкций, а именно
семейство DB и
ИНКБИН .
Строковая константа выглядит как символьная константа, только длиннее. это рассматривается как конкатенация символьных констант максимального размера для условия. Таким образом, следующие варианты эквивалентны:
db 'привет'; строковая константа
db 'h', 'e', 'l', 'l', 'о'; эквивалентные символьные константы
И следующие эквиваленты:
dd 'ninechars'; строковая константа двойного слова
dd 'девять', 'char', 's'; становится тремя двойными словами
db 'ninechars', 0,0,0; и действительно так выглядит
Обратите внимание, что при использовании в качестве операнда для db , a
константа типа 'ab' обрабатывается как строка
константа, несмотря на то, что она достаточно короткая, чтобы быть символьной константой, потому что
в противном случае db 'ab' будет иметь тот же эффект, что и
db 'a' , что было бы глупо.По аналогии,
трехсимвольные или четырехсимвольные константы обрабатываются как строки, когда
они операнды на dw .
3.4.4 Константы с плавающей запятой
Константы с плавающей запятой допустимы только в качестве аргументов для
DD , DQ и
ДТ . Они выражаются в традиционной форме:
цифры, затем точка, затем, необязательно, другие цифры, затем необязательно
E , за которым следует показатель степени. Период
обязательно, чтобы NASM мог различать
dd 1 , который объявляет целочисленную константу, и
дд 1.0 , который объявляет константу с плавающей запятой.
Некоторые примеры:
dd 1.2; легкий
dq 1.e10; 10 000 000 000
dq 1.e + 10; синоним 1.e10
dq 1.e-10; 0,000 000 000 1
dt 3.141592653589793238462; Пи
NASM не может выполнять арифметические действия во время компиляции с константами с плавающей запятой. Этот потому что NASM спроектирован так, чтобы быть портативным, хотя он всегда генерирует код для работы на процессорах x86, сам ассемблер может работать в любой системе с компилятором ANSI C.Поэтому ассемблер не может гарантировать наличие блока с плавающей запятой, способного обрабатывать числа Intel форматы, и поэтому для того, чтобы NASM мог выполнять арифметические операции с плавающей запятой, он должен иметь включить собственный полный набор подпрограмм с плавающей запятой, которые значительно увеличить размер ассемблера с очень небольшой выгодой.
3.5 Выражения
Выражения в NASM по синтаксису аналогичны выражениям в C.
NASM не гарантирует размер целых чисел, используемых для оценки выражения во время компиляции: поскольку NASM может компилироваться и работать на 64-битных системы вполне успешно, не предполагайте, что выражения оцениваются в 32-битные регистры и поэтому стараемся сознательно использовать целочисленное переполнение.Это может не всегда работать. NASM гарантирует только то, что гарантировано ANSI C: у вас всегда есть как минимум 32 бита для работы.
NASM поддерживает два специальных токена в выражениях, что позволяет выполнять вычисления.
задействовать текущую позицию сборки: $
и $$ жетонов. $
оценивает позицию сборки в начале строки, содержащей
выражение; поэтому вы можете закодировать бесконечный цикл, используя
JMP руб. $$ оценивается в
начало текущего раздела; так что вы можете сказать, как далеко в
вы используете ($ - $$) . обеспечивает побитовую операцию XOR.
3.5.3
и : побитовый оператор И
и обеспечивают побитовую операцию AND.
3.5.4
<< и >> : Операторы битового сдвига
<< дает битовый сдвиг влево, просто
как и в C. Итак, 5 << 3 оценивается как 5
умножить на 8 или 40. >> дает битовый сдвиг
верно; в NASM такой сдвиг равен , всегда без знака, так что биты
сдвинутые с левого конца, заполняются нулем, а не
знак-расширение предыдущего старшего бита.
3.5.5
+ и - : операторы сложения и вычитания
+ и -
операторы делают совершенно обычное сложение и вычитание.
3.5.6
* , /, // , % и %% : умножение и деление
* - оператор умножения.
/ и // оба являются
операторы деления: / - беззнаковое деление и
// - знаковое деление.По аналогии,
% и %% обеспечивают
беззнаковые и подписанные операторы по модулю соответственно.
NASM, как и ANSI C, не дает никаких гарантий относительно разумной работы подписанного оператора по модулю.
Так как символ % широко используется
препроцессор макроса, вы должны убедиться, что подписанные и неподписанные
За операторами по модулю следует пробел, где бы они ни появлялись.
3.5.7 Унарные операторы:
+ , - , ~ и SEG
Операторы с наивысшим приоритетом в грамматике выражений NASM:
которые применимы только к одному аргументу. - отрицает его
операнд, + ничего не делает (это предусмотрено для
симметрия с - ), ~
вычисляет до единицы своего операнда, и
SEG предоставляет адрес сегмента своего операнда
(более подробно объяснено в разделе 3.6).
3,6
SEG и WRT
При написании больших 16-битных программ, которые нужно разбивать на несколько
сегментов, часто бывает необходимо иметь возможность ссылаться на сегментную часть
адрес символа.NASM поддерживает SEG
оператор для выполнения этой функции.
Оператор SEG возвращает
предпочтительных сегментных оснований символа, определенных как сегментных оснований
относительно которого имеет смысл смещение символа. Итак, код
mov ax, seg symbol
mov es, ax
mov bx, символ
загрузит ES: BX с действительным указателем на
символ символ .
Вещи могут быть более сложными, чем это: поскольку 16-битные сегменты и группы
могут перекрываться, иногда вы можете захотеть сослаться на какой-либо символ, используя
база сегмента отличается от предпочтительной.NASM позволяет сделать это,
использование ключевого слова WRT (со ссылкой на).
Итак, вы можете делать такие вещи, как
mov ax, weird_seg; weird_seg - это база сегмента
mov es, ax
mov bx, символ wrt weird_seg
для загрузки ES: BX с другим, но
функционально эквивалентен, указатель на символ
символ .
NASM поддерживает дальние (межсегментные) вызовы и переходы с помощью синтаксиса
сегмент вызова: смещение , где
сегмент и смещены оба
представляют непосредственные ценности.Итак, чтобы вызвать дальнюю процедуру, вы можете написать код
любой из
вызов (процедура сегмента): процедура
вызов weird_seg: (процедура wrt weird_seg)
(круглые скобки включены для ясности, чтобы показать предполагаемый синтаксический анализ приведенных выше инструкций. На практике они не нужны.)
NASM поддерживает синтаксис , процедура дальнего вызова как
синоним первого из вышеперечисленных употреблений. JMP
работает идентично CALL в этих примерах.
Чтобы объявить дальний указатель на элемент данных в сегменте данных, вы должны закодировать
символ DW, символ seg
NASM не поддерживает удобного синонима для этого, хотя вы всегда можете изобрести один, используя макропроцессор.
3,7
STRICT : запрещающая оптимизация
При сборке с оптимизатором, установленным на уровень 2 или выше (см.
раздел 2.1.16), NASM будет использовать
спецификаторы размера ( BYTE ,
WORD , DWORD ,
QWORD или TWORD ), но
даст им минимально возможный размер.Ключевое слово
STRICT можно использовать для запрета оптимизации и
принудительно передать конкретный операнд в указанном размере. Для
Например, при включенном оптимизаторе и в BITS 16
Режим,
толкнуть dword 33
кодируется тремя байтами 66 6A 21 , тогда как
толкать строгий dword 33
кодируется шестью байтами, с непосредственным операндом полное двойное слово
66 68 21 00 00 00 .
При выключенном оптимизаторе генерируется один и тот же код (шесть байтов) независимо от того,
Ключевое слово STRICT использовалось или нет.
3.8 Критические выражения
Ограничение NASM состоит в том, что это двухпроходный ассемблер; в отличие от TASM и другие, он всегда будет выполнять ровно два прохода сборки. Следовательно, это не может справиться с исходными файлами, которые достаточно сложны, чтобы требовать трех или больше проходов.
Первый проход используется для определения размера всего собранного кода и данные, так что второй проход при генерации всего кода знает все символ адреса, к которому относится код. Итак, одна вещь, с которой NASM не может справиться, - это код, размер которого зависит от значения символа, объявленного после кода в вопрос.Например,
раз (метка- $) db 0
label: db 'Где я?'
Аргумент РАЗ в этом случае мог бы
одинаково юридически оценивать вообще что угодно; NASM отклонит этот пример
потому что он не может определить размер строки TIMES
когда он впервые видит это. Он так же решительно отвергнет слегка
парадоксальный код
раз (метка - $ + 1) db 0
label: db 'ТЕПЕРЬ где я?'
, в котором любое значение для TIMES
аргумент неверен по определению!
NASM отвергает эти примеры с помощью концепции, называемой критической
выражение , которое определяется как выражение, значение которого
требуется, чтобы его можно было вычислить на первом проходе, и который, следовательно, должен
зависят только от определенных перед ним символов.Аргумент против
TIMES - критическое выражение; для
По той же причине аргументы в пользу семейства RESB
псевдо-инструкции также являются критическими выражениями.
Критические выражения могут возникать и в других контекстах: рассмотрите следующий код.
mov ax, symbol1
symbol1 equ symbol2
symbol2:
На первом проходе NASM не может определить значение
символ1 , потому что
символ1 определяется как равное
symbol2 , который NASM еще не видел.На втором
передать, поэтому, когда он встречает строку
mov ax, symbol1 , невозможно сгенерировать код
для этого, потому что он все еще не знает ценности
символ1 . В следующей строке он увидит
EQU снова и сможет определить значение
symbol1 , но тогда будет уже поздно.
NASM избегает этой проблемы, определяя правую часть
EQU как критическое выражение, поэтому
определение символа 1 будет отклонено в
первый проход.
Есть связанная проблема, связанная с прямыми ссылками: рассмотрите это фрагмент кода.
mov eax, [ebx + смещение]
смещение экв 10
NASM на первом проходе должен вычислить размер инструкции
mov eax, [ebx + offset] без знания значения
смещение . Он не может знать, что
смещение достаточно мало, чтобы поместиться в однобайтовый
поле смещения и, следовательно, можно обойтись созданием более короткого
форма кодировки действующего адреса; насколько он знает, в первом проходе,
смещение может быть символом в кодовом сегменте, и
может потребоваться полная четырехбайтовая форма.Поэтому он вынужден вычислять размер
инструкции для размещения четырехбайтовой части адреса. Во втором проходе
приняв это решение, теперь он вынужден соблюдать его и соблюдать
инструкция большая, поэтому код, сгенерированный в этом случае, не такой маленький, как
могло бы быть. Эту проблему можно решить, определив
смещение перед его использованием или путем принудительного изменения размера байта
в действующем адресе по кодировке
[байт EBX + смещение] .
3.9 Местные ярлыки
NASM уделяет особое внимание символам, начинающимся с точки.Этикетка начало с одной точки рассматривается как локальная метка , которая означает, что он связан с предыдущей нелокальной меткой. Таким образом, для пример:
label1; какой-то код
.петля
; еще код
jne .loop
Ret
label2; какой-то код
.петля
; еще код
jne .loop
Ret
В приведенном выше фрагменте кода каждый JNE
инструкция переходит на строку непосредственно перед ней, потому что два
определения .петли разделены на
каждого из них связано с предыдущей нелокальной меткой.
Эта форма локальной обработки меток заимствована из старой Amiga.
ассемблер DevPac; однако NASM идет еще дальше, разрешая доступ
к локальным меткам из других частей кода. Это достигается с помощью
, определяющий локальную метку в терминах предыдущей нелокальной метки:
первое определение .loop , приведенное выше, действительно
определение символа под названием label1.петля , а
второй определяет символ с именем label2.loop . Так,
если вам действительно нужно, вы можете написать
label3; еще код
; и еще немного
jmp label1.loop
Иногда полезно - например, в макросе - иметь возможность определять
метка, на которую можно ссылаться откуда угодно, но которая не мешает
с обычным механизмом локальной метки. Такой ярлык не может быть нелокальным
потому что это помешает последующим определениям и ссылкам
к, местные лейблы; и он не может быть локальным, потому что макрос, который его определил
не знал полного названия лейбла.Поэтому NASM представляет третий тип
метки, что, вероятно, полезно только в определениях макросов: если метка
начинается со специального префикса .. @ , затем
ничего к локальному механизму меток. Итак, вы могли написать код
label1:; нелокальный лейбл
.местный: ; это действительно label1.local
.. @ foo:; это особый символ
label2:; другой нелокальный лейбл
.местный: ; это действительно label2.местный
jmp .. @ foo; это прыгнет на три строчки вверх
NASM может определять другие специальные символы, начинающиеся с
двойной период: например, .. начало используется для
укажите точку входа в формате вывода obj
(см. раздел 6.2.6).
Следующая глава | Предыдущая глава | Содержание | Индекс
404 | Микро Фокус
Сформируйте свою стратегию и преобразуйте гибридную ИТ-среду.
Помогите вам внедрить безопасность в цепочку создания стоимости ИТ и наладить сотрудничество между ИТ-подразделениями, приложениями и службами безопасности.
Помогите вам быстрее реагировать и получить конкурентное преимущество благодаря гибкости предприятия.
Ускорьте получение результатов гибридного облака с помощью услуг по консультированию, трансформации и внедрению.
Службы управления приложениями, которые позволяют поручить управление решениями экспертам, разбирающимся в вашей среде.
Услуги стратегического консалтинга для разработки вашей программы цифровой трансформации.
Полнофункциональное моделирование сценариев использования с предустановленными интеграциями в портфеле программного обеспечения Micro Focus, демонстрирующее реальный сценарий использования
Услуги экспертной аналитики безопасности, которые помогут вам быстро спроектировать, развернуть и проверить реализацию технологии безопасности Micro Focus.
Служба интеграции и управления услугами, которая оптимизирует доставку, гарантии и управление в условиях нескольких поставщиков.
Анализируйте большие данные с помощью аналитики в реальном времени и ищите неструктурированные данные.
Анализируйте большие данные с помощью аналитики в реальном времени и ищите неструктурированные данные.
Анализируйте большие данные с помощью аналитики в реальном времени и ищите неструктурированные данные.
Мобильные услуги, которые обеспечивают производительность и ускоряют вывод на рынок без ущерба для качества.
Анализируйте большие данные с помощью аналитики в реальном времени и ищите неструктурированные данные.