Что такое номинальная мощность электроприбора. Как рассчитать номинальную мощность двигателя. Чем отличается номинальная мощность от максимальной. Для чего нужно знать номинальную мощность устройства.
Содержание
Что такое номинальная мощность
Номинальная мощность — это значение мощности, указанное производителем для нормальных условий эксплуатации устройства. Это оптимальный уровень мощности, при котором прибор может работать длительное время без перегрева и повреждений.
Основные особенности номинальной мощности:
Указывается производителем на корпусе или в паспорте устройства
Измеряется в ваттах (Вт) или киловаттах (кВт)
Достигается при номинальных значениях напряжения, тока и других параметров
Обеспечивает длительную стабильную работу без перегрузок
Учитывает КПД и потери энергии в устройстве
Чем отличается номинальная мощность от максимальной
Номинальная и максимальная мощность — это разные характеристики устройства:
Номинальная мощность — оптимальная для длительной работы
Максимальная мощность — пиковая, кратковременная
Номинальная мощность всегда ниже максимальной
Превышение номинальной мощности допустимо на короткое время
Работа на максимальной мощности возможна лишь несколько минут
Например, для электродвигателя номинальная мощность может составлять 1000 Вт, а максимальная (пусковая) — 1500 Вт.
Как рассчитать номинальную мощность
Существует несколько способов определения номинальной мощности электрического устройства:
1. По паспортным данным
Самый простой способ — посмотреть значение на корпусе прибора или в технической документации. Производители всегда указывают номинальную мощность.
2. Расчет по формуле
Для электродвигателей номинальную мощность можно рассчитать по формуле:
P = U * I * cosφ
Где: P — номинальная мощность (Вт) U — номинальное напряжение (В)
I — номинальный ток (А) cosφ — коэффициент мощности
3. Метод эквивалентного тока
Применяется формула:
P ≥ Iэк * Uном * cosφном
Где: Iэк — эквивалентный ток Uном — номинальное напряжение cosφном — номинальный коэффициент мощности
4. Метод эквивалентного момента
Расчет по формуле:
P = M * ω
Где: M — вращающий момент ω — угловая скорость вращения
Для чего нужно знать номинальную мощность
Понимание номинальной мощности устройства важно по нескольким причинам:
Позволяет правильно подобрать прибор под конкретные задачи
Помогает избежать перегрузок и поломок оборудования
Дает возможность рассчитать энергопотребление
Необходимо для проектирования электрических сетей
Требуется при выборе защитных устройств
Номинальная мощность различных устройств
Рассмотрим типичные значения номинальной мощности бытовых приборов:
Лампа накаливания: 40-100 Вт
Светодиодная лампа: 5-15 Вт
Холодильник: 150-300 Вт
Стиральная машина: 2000-2500 Вт
Электрочайник: 1500-2200 Вт
Микроволновая печь: 700-1200 Вт
Пылесос: 1500-2000 Вт
Как измерить фактическую мощность прибора
Для определения реальной потребляемой мощности устройства можно использовать следующие методы:
Измерение специальным прибором — ваттметром
Использование бытового счетчика электроэнергии
Применение мультиметра с функцией измерения мощности
Расчет по показаниям амперметра и вольтметра
Важно помнить, что измеренная мощность может отличаться от номинальной в зависимости от режима работы устройства.
Номинальная мощность и энергоэффективность
Номинальная мощность напрямую связана с энергоэффективностью прибора. Чем ниже номинальная мощность при тех же функциональных возможностях, тем эффективнее устройство расходует энергию.
При выборе бытовой техники стоит обращать внимание на:
Класс энергоэффективности (A+++, A++, A+ и т.д.)
Годовое энергопотребление
Соотношение номинальной мощности и производительности
Использование энергоэффективных приборов с оптимальной номинальной мощностью позволяет существенно снизить расходы на электроэнергию.
Заключение
Номинальная мощность — важная характеристика любого электрического устройства. Она определяет оптимальный режим работы прибора и позволяет правильно его эксплуатировать. Знание номинальной мощности необходимо как для бытового применения, так и для профессионального использования электрооборудования.
Статьи
Что такое номинальная мощность?
С термином «номинальная мощность» мы сталкиваемся практически ежедневно. Выбираем ли электрический чайник или лампу накаливания – везде указано это значение. Единицей измерения являются ватты или киловатты. Казалось бы – что может быть проще в этом вопросе? Ведь еще со школьного курса физики всем известно, что для определения мощности (P) достаточно перемножить значения тока и напряжения. Но что скрывается за словами «номинальная мощность»? Под термином «номинальный» понимают определенное значение чего-либо, не учитывающее внешних корректирующих факторов. Таким образом, номинальная мощность – указанное производителем значение, которое может быть получено только при предусмотренных расчетных параметрах. Это общее понятие. В каждом же конкретном случае необходимо учитывать свои специфичные особенности. Приведем пример с лампой накаливания. На ее стеклянной колбе отмечено: 230 В, 100 Вт. То есть, 100 Вт может быть достигнуто только при напряжении в 230 В. Номинальная мощность – это те самые 100 Вт. Ее значение уменьшается со снижением напряжения и увеличивается с повышением так как эти параметры находятся в прямой зависимости друг от друга (P=I*U).
Как правило, для большинства электроприборов есть ограничение по верхней границе, обычно 5-10%. Другими словами, допустима работа при 230 В + 23 В = 253 В. Нижний предел может не указываться, как в случае с лампой. Более сложное оборудование ограничено по паспортным параметрам как сверху, так и снизу. К примеру, как понять термин «номинальная мощность двигателя»? Существует два равноправных определения – одно с точки зрения электричества, а другое исходя из расчетной механической нагрузки на валу. Хотя они непосредственно взаимосвязаны, второе более простое для понимания. Мы приведем оба. На табличке с паспортными данными всегда указано значение мощности. Она численно равна потребляемой из электрической сети при расчетной механической нагрузке, причем температура корпуса должна находиться в допустимых пределах (подразумевается продолжительный режим работы). То есть, можно считать, что паспортное значение равно номинальному. Если же электропривод работает в повторно-кратковременном режиме (ПВ не равно 100%), то такое соответствие не выполняется, так как времени работы недостаточно для перехода в установившийся режим, когда увеличение нагрева компенсируется температурой окружающего воздуха. В этом случае потребуется нагрузочный график: номинальная мощность будет равна произведению паспортного значения P и корня квадратного из подобранного по графику коэффициента. Все вышесказанное верно для электрической составляющей.
Согласно другому определению, номинальная мощность принимается равной механической, развиваемой двигателем при расчетном значении напряжения и температурном режиме, соответствующем паспортному. Таким образом, если напряжение (U) уменьшается, то изменяется и момент силы, хотя скорость вращения вала может остаться прежней. Как было сказано, производителем закладывается в изделие определенный «запас прочности»: колебания U в пределах +-5% позволяет двигателю развивать расчетный момент (при неизменности частоты сети). Для частоты такой запас составляет всего 2,5%. А вот номинальная мощность трансформатора учитывает только температурный режим. Если посмотреть в паспорт устройства, то там указаны две температуры: номинальная и окружающего воздуха. Если при работе первая не превышает своего расчетного значения, а вторая отличается от паспортных данных незначительно, то в этом режиме трансформатор выдает номинальную мощность. Любое повышение электрической нагрузки вызывает рост тока и температуры, поэтому вполне достаточно контроля последней. Как и в случае с двигателями, допускается небольшое превышение.
Выбор генератора по мощности
Выбирая генератор, потребитель обращает внимание на различные параметры установки – вес, запас моторесурса, мобильность, наличие дополнительного функционала, цену, и т.д. Но в первую очередь необходимо выбирать установку, ориентируясь на ее мощность. Как правильно рассчитать этот показатель и на что обратить внимание?
Чтобы было понятней, разберем эту ситуацию на простом примере. Допустим, в нашем пользовании имеются такие бытовые приборы: пылесос, калорифер, морозильник. Мощность этих бытовых приборов составляет соответственно 1 кВт, 2 кВт и 0,3 кВт. Получается, чтобы обеспечить работу этих приборов, нам необходим генератор мощностью не менее 3 кВт. Чтобы понять это, разберемся в таком понятии, как номинальная мощность генератора.
Номинальная, или, как ее еще называют, реальная мощность установки, существенно отличается от максимальной. В технической документации производители чаще всего указывают именно максимальные показатели по мощности для данной модели генератора. Стоит отметить, что с такой нагрузкой установка без критических последствий может работать очень непродолжительное время – в некоторых случаях это секунды, иногда 1-2 минуты. В то же время реальная, или номинальная мощность несколько ниже максимального показателя. Для ее расчета необходим коэффициент мощности cos φ. Этот показатель определяется отношением активной мощности к полной.
Пример
Допустим, в нашем распоряжении генератор с показателями мощности в 3 кВА и cos φ, равным 0,8. В таком случае номинальная мощность данной установки будет равна:
3 кВА х 0,8=2,4 (кВт)
Теперь можно понять, почему мощность может указываться в тех или иных единицах измерения, в ваттах (Вт) или Вольт Амперах (ВА). Некоторые производители, чтобы избавить потребителя от необходимости проведения вычислений, просто указывают в сопроводительной документации оба значения мощности – номинальной и максимальной. Встречаются также варианты, когда производителем указывается только одна из мощностей и приводится значение коэффициента мощности. Некоторые недобросовестные компании могут скрывать коэффициент мощности от потребителя. Это делается с целью выдать генератор за более мощную, чем на самом деле, установку.
Учет вида нагрузки
Для бытовых электроприборов характерны два вида нагрузки:
Активная;
Реактивная.
Активная (омическая) нагрузка потребляется приборами, которые преобразуют получаемую энергию в тепло. Это электрическая плита, утюг, фен, калориферы и т.д. Реактивную нагрузку потребляют остальные электроприборы, преобразующие в тепло только незначительную часть энергии. Основная часть потребляемой энергии используется с другой целью. Примерами таких приборов могут быть холодильник, пылесос, телевизор, компьютер и т.д.
Если вам нужна помощь в выборе мощности генератора для вашего дома, производственного цеха или любого другого объекта, обратитесь за квалифицированной консультацией к нашим специалистам.
Номинальная мощность — это… Что такое Номинальная мощность?
Номинальная мощность
4а. Номинальный ток светового прибора
Ток, указанный изготовителем на световом приборе
3.2 номинальная мощность: Мощность, указанная на изделии, а также в технической документации, входящая в номинальные параметры и понимаемая в следующем смысле:
а) для автомобильных генераторов — максимальная полезная мощность, определяемая как произведение номинального напряжения на максимальный ток и измеряемая в ваттах;
б) для тракторных и мотоциклетных генераторов — мощность, определяемая как произведение номинального напряжения на номинальный ток и измеряемая в ваттах;
в) для мотоциклетных и мопедных генераторов с параметрическим регулированием — суммарная мощность потребителей электроэнергии на мотоцикле или мопеде;
г) для стартеров — наибольшая полезная мощность на валу, выраженная в ваттах или киловаттах;
д) для электродвигателей — полезная мощность при номинальном напряжении с номинальным моментом нагрузки на валу, выраженная в ваттах;
е) для всех остальных потребителей электроэнергии — потребляемая электрическая мощность на входных зажимах изделия, вычисляемая, если нет особых указаний, как произведение номинального напряжения на номинальный ток и измеряемая в ваттах.
3.12 номинальная мощность: Установленная предприятием-изготовителем мощность при полной нагрузке и номинальной частоте вращения коленчатого вала двигателя, изготовленного, отрегулированного и обкатанного в соответствии с технической документацией.
2.4 номинальная мощность: Мощность, маркируемая на лампе.
3.5 номинальная мощность (rated wattage): Мощность, маркируемая на лампе.
6. номинальная мощность: Мощность, маркируемая на лампе.
1.3.5 номинальная мощность : Мощность, маркируемая на лампе.
1.3.6 номинальная мощность: Мощность, указанная в соответствующем стандарте на лампу или установленная изготовителем или ответственным поставщиком.
1.5.11 номинальная мощность (rated wattage): Мощность, заданная в соответствии с настоящим стандартом.
3.23 номинальная мощность: Номинальное значение отдаваемой мощности источника питания исходя из номинального рабочего тока и напряжения.
3.3 номинальная мощность (rated output): Числовое значение выходной мощности, включенное в номинальные данные.
3.3 номинальная мощность (rated power): Потребляемая мощность, указанная для прибора производителем.
1.3.6 номинальная мощность (rated wattage): Мощность, заданная в соответствии с настоящим стандартом.
3.12 номинальная мощность (rated power): Величина мощности, объявленная производителем и соответствующая указанным режимам эксплуатации устройства или оборудования.
Примечание — Номинальная мощность — величина максимальной непрерывной электрической мощности, выдаваемой в режиме нормальной эксплуатации и при нормальных внешних условиях, которая была задана в процессе проектирования ВЭУ.
3.14 номинальная мощность (rated power), QH (QN): Реактивная мощность реактора, заданная для работы при номинальных напряжении и частоте.
1.3.6 номинальная мощность (rated wattage): Мощность, маркируемая на лампе.
3.3 номинальная мощность (rated wattage): Мощность, маркируемая на лампе.
2.3. Номинальная мощность — числовое значение мощности, отнесенное к номинальным данным.
Номинальная мощность
Длительная эффективная мощность двигателя, назначаемая и гарантируемая изготовителем при заданной частоте вращения двигателя, заданных окружающих условиях, полной комплектности и рабочих условиях, для которых предназначен дизель, с учетом возможности развития максимальной мощности
13. номинальная мощность: Мощность, маркируемая на лампе.
3.10 номинальная мощность: Величина мощности, как правило, указываемая разработчиком, для определенных условий эксплуатации узла, устройства, машины или оборудования. Для ВЭУ: это наибольшая мощность, которую она вырабатывает, находясь в длительном режиме работы при номинальных значениях исходных параметров (скорость ветра, влажность, температура, плотность воздуха).
Смотри также родственные термины:
3.14 номинальная мощность (для ВЭУ) [rated power (for wind turbines)]: Максимальная непрерывная электрическая выходная мощность ВЭУ, достижимая при условиях нормальной эксплуатации.
3.33 номинальная мощность (компрессора): Максимальная мощность компрессора и любых дополнительных частей с приводом от вала, необходимых для конкретных условий работы.
Примечания
1 В номинальную мощность включена мощность такого оборудования, как устройства подавления пульсации, трубопроводная обвязка, промежуточные холодильники и сепараторы.
2 Потери в системе трансмиссии и привода не включаются в номинальную мощность компрессора. Потери, происходящие в наружных подшипниках (например, используемых для поддержки крупных маховиков), включаются в номинальную мощность.
1.5.11 номинальная мощность (последовательно соединенной RC-сборки) (rated power (of a series RC-unit): Максимальная мощность, которую может рассеивать RC-сборка при номинальной температуре в течение длительной работы.
3.5 номинальная мощность PN (rated output): Числовое значение выходной мощности, включенное в номинальные данные.
Определения термина из разных документов: номинальная мощность PN
9.2.5. Номинальная мощность автотрансформатора
Номинальная проходная мощность обмоток, имеющих общую часть.
Примечание. Под обмотками понимаются обмотки высшего и низшего напряжения в двухобмоточном и обмотки высшего и среднего напряжения в трехобмоточном автотрансформаторе
3.2.8 номинальная мощность ВА:
20. Номинальная мощность высокочастотного вакуумного выключателя (переключателя)
Номинальная мощность
Максимальная мощность, пропускаемая в течение установленной наработки через замкнутые контакты электрической цепи высокочастотного вакуумного выключателя (переключателя) в условиях, указанных в нормативно-технической документации
3.16 номинальная мощность гидроагрегата :
Активная электрическая мощность на выводах генератора, соответствующая номинальному режиму работы электрической машины
3.10 номинальная мощность ГТУ в станционных условиях: Электрическая мощность на клеммах электрогенератора, определяемая для заданных станционных условий.
9.2.3. Номинальная мощность двухобмоточного трансформатора*
Номинальная мощность каждой из обмоток трансформатора.
Примечание. В трансформаторе с расщепленной обмоткой номинальная мощность — эта мощность нерасщепленной обмотки или равная ей суммарная мощность частей расщепленной обмотки
Номинальная мощность дизель-генератора
Длительная мощность на клеммах дизель-генератора, назначенная и гарантируемая изготовителем при заданной частоте вращения дизеля и заданных окружающих условиях
1.3.21 номинальная мощность конденсатора QN (rated output of a capacitor): Реактивная мощность, получаемая при номинальных значениях емкости, частоты и напряжения (или тока).
Определения термина из разных документов: номинальная мощность конденсатора QN
33. Номинальная мощность облучателя радиационно-технологической установки с закрытым радионуклидным источником ионизирующего излучения
Номинальная мощность облучателя РТУ
Мощность облучателя радиационно-технологической установки с закрытым радионуклидным источником ионизирующего излучения, необходимая для обеспечения заданной производительности установки
9.2.2. Номинальная мощность обмотка (ответвления обмотки)
Указанное на паспортной табличке трансформатора значение полной мощности на основном (данном) ответвлении, гарантированное изготовителем в номинальных условиях места установки и охлаждающей среды при номинальной частоте и номинальном напряжении обмотки (ответвления).
Примечание. Если на паспортной табличке трансформатора указаны несколько мощностей, соответствующих различным способам охлаждения, то за номинальную принимают наибольшую из этих мощностей
3.3 номинальная мощность при конденсационном режиме: Величина полезной мощности, объявленная изготовителем, кВт, соответствующая эксплуатации котла в режиме температур воды 50 °C/30 °C.
2.7 номинальная мощность рассеивания колодок выводов для плавких вставок (rated power dissipation value of a fuse terminal block): Максимальная мощность рассеивания в случае, когда колодка выводов для плавких предохранителей находится при длительной нагрузке в условиях, установленных для держателя плавкой вставки и собственно плавкой вставки.
45. Номинальная мощность рассеяния резистора
Номинальная мощность рассеяния
D. Nennleistung
E. Rated dissipation
F. Dissipation nominale
Наибольшая мощность, которую резистор может рассеивать в заданных условиях в течение срока службы с сохранением параметров в допускаемых пределах
99. Номинальная мощность трансформатора малой мощности
Номинальная мощность трансформатора
D. Neunleistung des Kleintransformators
E. Transformer power rating
F. Puissance nominale du transformateur
Сумма мощностей вторичных обмоток трансформатора малой мощности, в котором мощность каждой обмотки определяется произведением номинального тока на номинальное напряжение
3.1.11 номинальная мощность трансформатора напряжения : Значение полной мощности, указанное на паспортной табличке трансформатора напряжения, которую он отдает во вторичную цепь при номинальном вторичном напряжении с обеспечением соответствующих классов точности.
9.2.4. Номинальная мощность трехобмоточного трансформатора*
Наибольшая из номинальных мощностей отдельных обмоток трансформатора
55. Номинальная мощность электроагрегата (электростанции)
Номинальная мощность
D. Nennleistung
E. Rated power
Мощность, развиваемая электроагрегатом (электростанцией) без ограничения времени работы при номинальных значениях напряжения, тока, частоты вращения, частоты переменного тока, коэффициента мощности и при номинальных условиях эксплуатации, с учетом возможности развития максимальной мощности
3.13 номинальная мощность электродвигателя : Полезная механическая мощность на валу, выраженная в ваттах (Вт) или киловаттах (кВт).
Номинальная мощность электродвигателя (электродвигателей)
1.7
По ГОСТ 10512-78
Номинальная мощность электродвигателя (электродвигателей)
1.7
По ГОСТ 10512-78
3.21 номинальная мощность электронагревательной секции: Мощность (в ваттах), используемая в расчетах при определении линейного или поверхностного тепловыделения.
75. Номинальная мощность электропечи
Номинальная мощность
Мощность электропечи для осуществления электронагрева загрузки
6. Номинальная мощность электроприбора
Мощность, на которую рассчитан электроприбор и которая указывается на электроприборе
С термином «номинальная мощность» мы сталкиваемся практически ежедневно. Выбираем ли электрический чайник или лампу накаливания – везде указано это значение. Единицей измерения являются ватты или киловатты. Казалось бы – что может быть проще в этом вопросе? Ведь еще со школьного курса физики всем известно, что для определения мощности (P) достаточно перемножить значения тока и напряжения. Но что скрывается за словами «номинальная мощность»?
Под термином «номинальный» понимают определенное значение чего-либо, не учитывающее внешних корректирующих факторов. Таким образом, номинальная мощность – указанное производителем значение, которое может быть получено только при предусмотренных расчетных параметрах. Это общее понятие. В каждом же конкретном случае необходимо учитывать свои специфичные особенности. Приведем пример с лампой накаливания. На ее стеклянной колбе отмечено: 230 В, 100 Вт. То есть, 100 Вт может быть достигнуто только при напряжении в 230 В. Номинальная мощность – это те самые 100 Вт. Ее значение уменьшается со снижением напряжения и увеличивается с повышением так как эти параметры находятся в прямой зависимости друг от друга (P=I*U).
Как правило, для большинства электроприборов есть ограничение по верхней границе, обычно 5-10%. Другими словами, допустима работа при 230 В + 23 В = 253 В. Нижний предел может не указываться, как в случае с лампой. Более сложное оборудование ограничено по паспортным параметрам как сверху, так и снизу.
К примеру, как понять термин «номинальная мощность двигателя»? Существует два равноправных определения – одно с точки зрения электричества, а другое исходя из расчетной механической нагрузки на валу. Хотя они непосредственно взаимосвязаны, второе более простое для понимания. Мы приведем оба. На табличке с паспортными данными всегда указано значение мощности. Она численно равна потребляемой из электрической сети при расчетной механической нагрузке, причем температура корпуса должна находиться в допустимых пределах (подразумевается продолжительный режим работы). То есть, можно считать, что паспортное значение равно номинальному. Если же электропривод работает в повторно-кратковременном режиме (ПВ не равно 100%), то такое соответствие не выполняется, так как времени работы недостаточно для перехода в установившийся режим, когда увеличение нагрева компенсируется температурой окружающего воздуха. В этом случае потребуется нагрузочный график: номинальная мощность будет равна произведению паспортного значения P и корня квадратного из подобранного по графику коэффициента. Все вышесказанное верно для электрической составляющей.
Согласно другому определению, номинальная мощность принимается равной механической, развиваемой двигателем при расчетном значении напряжения и температурном режиме, соответствующем паспортному. Таким образом, если напряжение (U) уменьшается, то изменяется и момент силы, хотя скорость вращения вала может остаться прежней. Как было сказано, производителем закладывается в изделие определенный «запас прочности»: колебания U в пределах +-5% позволяет двигателю развивать расчетный момент (при неизменности частоты сети). Для частоты такой запас составляет всего 2,5%.
А вот номинальная мощность трансформатора учитывает только температурный режим. Если посмотреть в паспорт устройства, то там указаны две температуры: номинальная и окружающего воздуха. Если при работе первая не превышает своего расчетного значения, а вторая отличается от паспортных данных незначительно, то в этом режиме трансформатор выдает номинальную мощность. Любое повышение электрической нагрузки вызывает рост тока и температуры, поэтому вполне достаточно контроля последней. Как и в случае с двигателями, допускается небольшое превышение.
Максимальная и номинальная мощность квт. Что такое номинальная мощность электродвигателя и как она расчитывается
Одна из естественных характеристик электродвигателя – его номинальная (эффективная) мощность (Pном ), которая для машин переменного и постоянного тока является механической мощностью на валу.
Это мощность двигателя, с которой он мог бы работать в номинальном режиме — режиме эффективной работы на протяжении длительного времени (не менее нескольких часов). Номинальная мощность измеряется в Вт (кВт) или лошадиных силах (л.с.) и указывается на щитке электрической машины вместе с остальными основными характеристиками.
, мощность двигателя развивается в полной мере. При загрузке двигателя до номинальной мощности на сравнительно короткий промежуток времени, можно считать, что он не используется в полную силу. В такой ситуации бывает целесообразна его кратковременная перегрузка, предел которой определяется перегрузочной мощностью двигателя.
В паспорте электродвигателя заводом-изготовителем всегда указываются номинальные величины мощности Pном , напряжения Uном , коэффициента мощности cosϕном , номинальная угловая скорость двигателя ωном .
Расчет номинальной мощности
Метод эквивалентного тока
Применим для расчета номинальной мощности при обязательном соблюдении во время работы неизменности показателей мощности потерь в обмотках двигателя, складывающейся из постоянной и переменной величин мощности, сопротивлений обмоток ротора и статора, потерь на механическое трение. Зная номинальный коэффициент мощности, показатели эквивалентного тока и номинального напряжения, возможно рассчитать номинальную мощность электродвигателя:
Pном ≥ Iэк ∙ Uном ∙cosϕном,
где Iэк – показатель эквивалентного тока,
Uном – номинальное напряжение,
cosϕном – номинальный коэффициент мощности, повышающийся с увеличением мощности и номинальной угловой скорости вращения ротора, а также зависящий от нагрузки. Для большинства электродвигателей составляет 0,8-0,9.
Метод эквивалентного момента
Электродвигатели любого типа имеют пропорциональный произведению тока и величине магнитного потока вращающий момент. Метод эквивалентного момента для расчета номинальной мощности используется в тех случаях, когда условия применяемой нагрузки определяют непосредственно требуемый от двигателя момент, а не ток. Для синхронных и асинхронных машин переменного тока, коэффициент мощности cosϕ приближенно принимается за постоянную величину:
Pном = Мвр ∙ ωном,
где Мвр – значение вращающего момента,
ωном – номинальная угловая скорость двигателя.
Определение номинальной мощности опытным путем
Указанная в паспорте или щитке устройства номинальная мощность будет равна этому значению только при оптимальной нагрузке на вал, определяемой заводом-изготовителем для номинального режима. На что ориентироваться, если по каким-то причинам не сохранился паспорт или стерлись надписи на табличке?
Помогут практические измерения и :
Необходимо полностью отключить все прочие источники потребления электроэнергии: освещение, электроприборы и т.д.
В случае использования электронного счетчика, следует подключить двигатель под нагрузкой на 5-6 минут, на электронном дисплее отобразиться величина нагрузки в кВт.
Дисковый счетчик проводит измерения в кВт∙час. Следует записать последние показания и включить двигатель на 10 минут с точностью до секунды. После остановки электромашины, отнять из полученного значения записанные показания и умножить на 6. Полученное число и будет являться активной механической мощностью двигателя.
При использовании этого метода важно правильно подобрать нагрузку, поскольку при ее недостаточности или перегрузке, определяемый показатель будет далек от номинальной мощности электродвигателя.
Пишите комментарии, дополнения к статье, может я что-то пропустил. Загляните на карту сайта , буду рад, если вы найдете на моем еще что-нибудь полезное. Всего доброго.
Это мощность двигателя, с которой он мог бы работать в номинальном режиме — режиме эффективной работы на протяжении длительного времени (не менее нескольких часов). Номинальная мощность измеряется в Вт (кВт) или лошадиных силах (л.с.) и указывается на щитке электрической машины вместе с остальными основными характеристиками.
При нагрузках, меньших P ном, мощность двигателя развивается в полной мере. При загрузке двигателя до номинальной мощно
что это и как ее подбирают?
При выборе акустической системы покупатель зачастую ориентируется на указанные производителем параметры мощности. Что означают эти величины и как их правильно подобрать, мы расскажем в нашей статье.
Содержание статьи
Что такое номинальная мощность?
Это параметр, который показывает, в каких пределах сигнала акустика может работать стабильно и с оптимальным звучанием в течение всего срока эксплуатации.
ВАЖНО. Термин как таковой характеризует не громкость звука, а надежность функционирования АС.
Номинальный показатель ограничивается нелинейными звуковыми искажениями, в их стандартном диапазоне. Такие колебания человеческое ухо не слышит, они появляются на выходе из колонок (усилителя), но отсутствуют в источнике звука. Иными словами, данная величина напрямую зависит от объема нелинейных искажений и поэтому ее реальное число значительно меньше, например, максимальной мощности аппаратуры.
Есть другое определение термина: это значение, вырабатываемое в среднем положении регулятора громкости сабвуфера.
Недобросовестные производители зачастую используют рекламный трюк: маскируют под стандартным числом другие цифры (пиковая величина и т.д). В бюджетной аппаратуре, как правило, сложно найти правильный показатель.
В России в качестве основных величин акустики используются номинальная и синусоидальная мощности. Последний параметр указывает реальное значение сигнала, при котором сохраняется длительная и стабильная работоспособность акустики. Синусоидальный показатель повсеместно вытесняет номинальные значения, он указывается в наименовании колонок и в паспортных данных.
НА ЗАМЕТКУ. Европейские стандарты вместо номинального уровня используют термин DIN, это аналог синусоидальной величины.
Что такое пиковая мощность и мощность RMS
Наряду с номинальным показателем, эти два параметра объективно характеризуют реальные возможности вашей акустической системы. Иные термины (суммарные и др.) имеют вторичное значение.
Пиковая мощность PMPO обозначает способность аппаратуры выдержать определенный звуковой предел, не получая повреждений. Действие пика с частотой 100 Гц длится при испытаниях до 1 секунды. Нелинейные искажения при расчете игнорируются.
Например, в паспорте указано 450 Вт (PMPO). Это значит, что после воздействия сигнала такой величины динамические головки сохранили полную работоспособность.
Максимальная (или предельная) мощность RMS показывает, на каком уровне сигнала система может работать в течение часа без поломок. Показатель замеряется при подаче звука частотой 1000 Гц, при этом нелинейные колебания держатся в определенных границах.
Например, в инструкции указано 20 Вт (RMS). Это значит, что колонки при этом значении способны транслировать сигнал длительное время, сохраняя работоспособность динамических головок.
Можно встретить завышенные данные RMS в паспорте к устройству. Это объясняется тем, что при испытаниях используются завышенные искажения, при которых звук превращается в набор хрипов. Такие ложные сведения остаются на совести производителя.
Надеемся, что наша статья помогла вам разобраться, что такое мощность колонок и как правильно понимать ее указанные значения.
Подпишитесь на наши Социальные сети
Номинальная мощность — это… Что такое Номинальная мощность?
Номинальная мощность
мощность, установленная паспортом на оборудование или проектом для данного оборудования или АС; в случае ее непревышения обеспечивается длительная работа.
Смотреть что такое «Номинальная мощность» в других словарях:
Номинальная мощность — 4а. Номинальный ток светового прибора Ток, указанный изготовителем на световом приборе Источник: ГОСТ 16703 79: Приборы и комплексы световые. Термины и определения оригинал документа … Словарь-справочник терминов нормативно-технической документации
номинальная мощность — номинальная мощность; номинаьная производительность максимальное длительно допустимое значение мощности (производительности) объекта при расчетных (проектных) условиях его работы … Политехнический терминологический толковый словарь
номинальная мощность — [Интент] Тематики электротехника, основные понятия EN name plate ratingnominal powerpower ratingrated burdenrated capacityrated outputrated powerrating … Справочник технического переводчика
номинальная мощность в л. с. — номинальная мощность в л. с. — [Я.Н.Лугинский, М.С.Фези Жилинская, Ю.С.Кабиров. Англо русский словарь по электротехнике и электроэнергетике, Москва, 1999] Тематики электротехника, основные понятия EN horse power rating … Справочник технического переводчика
номинальная мощность — vardinė galia statusas T sritis automatika atitikmenys: angl. nominal power; rated power vok. Bemessungsleistung, f; Nennausgangsleistung, f; Nennbelastbarkeit, f; Nennleistung, f; Nominalleistung, f rus. номинальная мощность, f pranc. puissance… … Automatikos terminų žodynas
номинальная мощность — vardinė galia statusas T sritis Standartizacija ir metrologija apibrėžtis Galia, kurią nurodo aparato, įrenginio ar įtaiso gamintojas. atitikmenys: angl. nominal power; rated power vok. Nennleistung, f rus. номинальная мощность, f pranc.… … Penkiakalbis aiškinamasis metrologijos terminų žodynas
номинальная мощность — vardinė galia statusas T sritis fizika atitikmenys: angl. nominal power; rated power vok. Nennleistung, f; Nominalleistung, f rus. номинальная мощность, f pranc. puissance assignée, f; puissance nominale, f … Fizikos terminų žodynas
номинальная мощность PN — 3.5 номинальная мощность PN (rated output): Числовое значение выходной мощности, включенное в номинальные данные. Источник … Словарь-справочник терминов нормативно-технической документации
номинальная мощность ВА — 3.2.8 номинальная мощность ВА: Источник: ГОСТ Р 51237 98: Нетрадиционная энергетика. Ветроэнергетика. Термины и определения оригинал документа … Словарь-справочник терминов нормативно-технической документации
номинальная мощность — [rated power, rating] расчетная мощность электропечной установки, указанная, в техническом паспорте, определяется при номинальном напряжении питающей электрической сети и при номинальном электрическом режиме ее эксплуатации. Фактическая мощность… … Энциклопедический словарь по металлургии
МОЩНОСТЬ НОМИНАЛЬНАЯ — это… Что такое МОЩНОСТЬ НОМИНАЛЬНАЯ?
МОЩНОСТЬ НОМИНАЛЬНАЯ
МОЩНОСТЬ НОМИНАЛЬНАЯ
(Nominal power) — придается на машиностроительных заводах наименованиям выпускаемых из производства типов двигателей и служит вернее признаком различных типов, нежели целям характеристики истинной мощности двигателя. Номинальная лошадиная сила (Nominal horse power) — число, условное обозначение, изменяющееся в пределах от 1/4 до 1/8 HP и нисколько не характеризующее мощности механизмов. Термин этот встречается иногда в судовых регистрах.
Номинальной мощностью электрических машин называется указываемая на щитке машины мощность, которую машина должна развивать или отдавать при своем номинальном режиме. Номинальной мощностью электродвигателей называется механическая мощность на валу машины, выражаемая в л. с. или квт.
Самойлов К. И.
Морской словарь. — М.-Л.: Государственное Военно-морское Издательство НКВМФ Союза ССР,
1941
.
МОЩНОСТЬ НА ВАЛУ
МОЩНОСТЬ ПАРОВЫХ ТУРБИН
Смотреть что такое «МОЩНОСТЬ НОМИНАЛЬНАЯ» в других словарях:
номинальная полная мощность (номинальная отдаваемая мощность) — 3.1.1 номинальная полная мощность (номинальная отдаваемая мощность) [rated output (rated apparent power)]; Sr: Полная электрическая мощность на выводах, выражаемая в вольт амперах (В · А) непосредственно или в виде произведения значащих чисел на… … Словарь-справочник терминов нормативно-технической документации
длительная мощность (номинальная мощность) — 3.18 длительная мощность (номинальная мощность): Мощность, которую двигатель может развивать без ограничения времени в период между техническими обслуживаниями, указанный изготовителем, при заданных частоте вращения и окружающих условиях при… … Словарь-справочник терминов нормативно-технической документации
номинальная выходная мощность — номинальная отдаваемая мощность — [Я.Н.Лугинский, М.С.Фези Жилинская, Ю.С.Кабиров. Англо русский словарь по электротехнике и электроэнергетике, Москва, 1999] Тематики электротехника, основные понятия Синонимы номинальная отдаваемая мощность … Справочник технического переводчика
Номинальная потребляемая мощность — 2.2.4. Номинальная потребляемая мощность потребляемая мощность при номинальном напряжении, указанная для машины изготовителем. Источник: ГОСТ 12.2.013 … Словарь-справочник терминов нормативно-технической документации
номинальная скорость — 3.46 номинальная скорость: Скорость движения кабины, на которую рассчитан лифт. Источник: ГОСТ Р 53780 2010: Лифты. Общие требования безопасности к устройству и установке оригинал документа … Словарь-справочник терминов нормативно-технической документации
номинальная скорость движения — 3.7 номинальная скорость движения: Скорость движения АТС на данной передаче, соответствующая номинальной частоте вращения коленчатого вала (ротора) двигателя, при которой он развивает свою номинальную мощность. Примечание В случае если… … Словарь-справочник терминов нормативно-технической документации
Мощность — [power; capacity] физическая величина, измеряющая количеством работы в единицу времени. В теплотехнике применяют понятие «тепловая мощность» в качестве теплотехнического параметра печи Рп, характеризующего максимальное количество теплоты,… … Энциклопедический словарь по металлургии
мощность излучения — [radiation intensity] отношение количества энергии, излучаемого телом, к отрезку времени, в течение которого продолжалось излучение. Смотри также: Мощность установленная мощность номинальная мощность … Энциклопедический словарь по металлургии
Номинальная мощность — 4а. Номинальный ток светового прибора Ток, указанный изготовителем на световом приборе Источник: ГОСТ 16703 79: Приборы и комплексы световые. Термины и определения оригинал документа … Словарь-справочник терминов нормативно-технической документации
номинальная мощность светового прибора — номинальная мощность Суммарная номинальная мощность ламп, на которую рассчитан световой прибор. [ГОСТ 16703 79] Тематики лампы, светильники, приборы и комплексы световые Синонимы номинальная мощность … Справочник технического переводчика
90000 Adam — latest trends in deep learning optimization. | by Vitaly Bushaev 90001 90002 90003 Adam [1] is an adaptive learning rate optimization algorithm that’s been designed specifically for training deep neural networks. First published in 2014 року, Adam was presented at a very prestigious conference for deep learning practitioners — ICLR 2015. The paper contained some very promising diagrams, showing huge performance gains in terms of speed of training. However, after a while people started noticing, that in some cases Adam actually finds worse solution than stochastic gradient descent.A lot of research has been done to address the problems of Adam. 90004 90003 The algorithms leverages the power of adaptive learning rates methods to find individual learning rates for each parameter. It also has advantages of Adagrad [10], which works really well in settings with sparse gradients, but struggles in non-convex optimization of neural networks, and RMSprop [11], which tackles to resolve some of the problems of Adagrad and works really well in on-line settings. Adam has been raising in popularity exponentially according to ‘A Peek at Trends in Machine Learning’ article from Andrej Karpathy.90004 90003 In this post, I first introduce Adam algorithm as presented in the original paper, and then walk through latest research around it that demonstrates some potential reasons why the algorithms works worse than classic SGD in some areas and provides several solutions, that narrow the gap between SGD and Adam. 90004 90003 Adam can be looked at as a combination of RMSprop and Stochastic Gradient Descent with momentum. It uses the squared gradients to scale the learning rate like RMSprop and it takes advantage of momentum by using moving average of the gradient instead of gradient itself like SGD with momentum.Let’s take a closer look at how it works. 90004 90003 Adam is an adaptive learning rate method, which means, it computes individual learning rates for different parameters. Its name is derived from adaptive moment estimation, and the reason it’s called that is because Adam uses estimations of first and second moments of gradient to adapt the learning rate for each weight of the neural network. Now, what is moment? N-th moment of a random variable is defined as the expected value of that variable to the power of n.More formally: 90004 m — moment, X -random variable. 90003 It can be pretty difficult to grasp that idea for the first time, so if you do not understand it fully, you should still carry on, you’ll be able to understand how algorithms works anyway. Note, that gradient of the cost function of neural network can be considered a random variable, since it usually evaluated on some small random batch of data. The first moment is mean, and the second moment is uncentered variance (meaning we do not subtract the mean during variance calculation).We will see later how we use these values, right now, we have to decide on how to get them. To estimates the moments, Adam utilizes exponentially moving averages, computed on the gradient evaluated on a current mini-batch: 90004 Moving averages of gradient and squared gradient. 90003 Where m and v are moving averages, g is gradient on current mini-batch, and betas — new introduced hyper-parameters of the algorithm. They have really good default values of 0.9 and 0.999 respectively. Almost no one ever changes these values.The vectors of moving averages are initialized with zeros at the first iteration. 90004 90003 To see how these values correlate with the moment, defined as in first equation, let’s take look at expected values of our moving averages. Since m and v are estimates of first and second moments, we want to have the following property: 90004 90003 Expected values of the estimators should equal the parameter we’re trying to estimate, as it happens, the parameter in our case is also the expected value.If these properties held true, that would mean, that we have 90020 unbiased estimators 90021. (To learn more about statistical properties of different estimators, refer to Ian Goodfellow’s Deep Learning book, Chapter 5 on machine learning basics). Now, we will see that these do not hold true for the our moving averages. Because we initialize averages with zeros, the estimators are biased towards zero. Let’s prove that for m (the proof for v would be analogous). To prove that we need to formula for m to the very first gradient.Let’s try to unroll a couple values of m to see he pattern we’re going to use: 90004 90003 As you can see, the ‘further’ we go expanding the value of m, the less first values of gradients contribute to the overall value , as they get multiplied by smaller and smaller beta. Capturing this patter, we can rewrite the formula for our moving average: 90004 90003 Now, let’s take a look at the expected value of m, to see how it relates to the true first moment, so we can correct for the discrepancy of the two : 90004 Bias correction for the first momentum estimator 90003 In the first row, we use our new formula for moving average to expand m.Next, we approximate g [i] with g [t]. Now we can take it out of sum, since it does not now depend on i. Because the approximation is taking place, the error C emerge in the formula. In the last line we just use the formula for the sum of a finite geometric series. There are two things we should note from that equation. 90004 90029 90030 We have biased estimator. This is not just true for Adam only, the same holds for algorithms, using moving averages (SGD with momentum, RMSprop, etc.). 90031 90030 It will not have much effect unless it’s the begging of the training, because the value beta to the power of t is quickly going towards zero.90031 90034 90003 Now we need to correct the estimator, so that the expected value is the one we want. This step is usually referred to as bias correction. The final formulas for our estimator will be as follows: 90004 Bias corrected estimators for the first and second moments. 90003 The only thing left to do is to use those moving averages to scale learning rate individually for each parameter. The way it’s done in Adam is very simple, to perform weight update we do the following: 90004 90003 Where w is model weights, eta (look like the letter n) is the step size (it can depend on iteration).And that’s it, that’s the update rule for Adam. For some people it can be easier to understand such concepts in code, so here’s possible implementation of Adam in python: 90004 90003 There are two small variations on Adam that I do not see much in practice, but they’re implemented in major deep learning frameworks, so it’s worth to briefly mention them. 90004 90003 First one, called 90020 Adamax 90021 was introduced by the authors of Adam in the same paper. The idea with Adamax is to look at the value v as the L2 norm of the individual current and past gradients.We can generalize it to Lp update rule, but it gets pretty unstable for large values of p. But if we use the special case of L-infinity norm, it results in a surprisingly stable and well-performing algorithm. Here’s how to implement Adamax with python: 90004 90003 Second one is a bit harder to understand, called 90020 Nadam 90021 [6]. 90020 90021 Nadam was published by Timothy Dozat in the paper ‘Incorporating Nesterov Momentum into Adam’. As name suggests the idea is to use Nesterov momentum term for the first moving averages.Let’s take a look at update rule of the SGD with momentum: 90004 SGD with momentum update rule 90003 As shown above, the update rule is equivalent to taking a step in the direction of momentum vector and then taking a step in the direction of gradient. However, the momentum step does not depend on the current gradient, so we can get a higher-quality gradient step direction by updating the parameters with the momentum step before computing the gradient. To achieve that, we modify the update as follows: 90004 f — loss function to optimize.90003 So, with Nesterov accelerated momentum we first make make a big jump in the direction of the previous accumulated gradient and then measure the gradient where we ended up to make a correction. There’s a great visualization from cs231n lecture notes: 90004 sourec: cs231n lecture notes. 90003 The same method can be incorporated into Adam, by changing the first moving average to a Nesterov accelerated momentum. One computation trick can be applied here: instead of updating the parameters to make momentum step and changing back again, we can achieve the same effect by applying the momentum step of time step t + 1 only once, during the update of the previous time step t instead of t + 1.Using this trick, the implementation of Nadam may look like this: 90004 90003 Here I list some of the properties of Adam, for proof that these are true refer to the paper. 90004 90029 90030 Actual step size taken by the Adam in each iteration is approximately bounded the step size hyper-parameter. This property add intuitive understanding to previous unintuitive learning rate hyper-parameter. 90031 90030 Step size of Adam update rule is invariant to the magnitude of the gradient, which helps a lot when going through areas with tiny gradients (such as saddle points or ravines).In these areas SGD struggles to quickly navigate through them. 90031 90030 Adam was designed to combine the advantages of Adagrad, which works well with sparse gradients, and RMSprop, which works well in on-line settings. Having both of these enables us to use Adam for broader range of tasks. Adam can also be looked at as the combination of RMSprop and SGD with momentum. 90031 90034 90003 When Adam was first introduced, people got very excited about its power. Paper contained some very optimistic charts, showing huge performance gains in terms of speed of training: 90004 source: original Adam paper 90003 Then, Nadam paper presented diagrams that showed even better results: 90004 source: Nadam paper 90003 However, after a while people started noticing that despite superior training time, Adam in some areas does not converge to an optimal solution, so for some tasks (such as image classification on popular CIFAR datasets) state-of-the-art results are still only achieved by applying SGD with momentum .More than that Wilson et. al [9] showed in their paper ‘The marginal value of adaptive gradient methods in machine learning’ that adaptive methods (such as Adam or Adadelta) do not generalize as well as SGD with momentum when tested on a diverse set of deep learning tasks, discouraging people to use popular optimization algorithms. A lot of research has been done since to analyze the poor generalization of Adam trying to get it to close the gap with SGD. 90004 90003 Nitish Shirish Keskar and Richard Socher in their paper ‘Improving Generalization Performance by Switching from Adam to SGD’ [5] also showed that by switching to SGD during training training they’ve been able to obtain better generalization power than when using Adam alone .They proposed a simple fix which uses a very simple idea. They’ve noticed that in earlier stages of training Adam still outperforms SGD but later the learning saturates. They proposed simple strategy which they called 90020 SWATS 90021 in which they start training deep neural network with Adam but then switch to SGD when certain criteria hits. They managed to achieve results comparable to SGD with momentum. 90004 90003 One big thing with figuring out what’s wrong with Adam was analyzing it’s convergence.The authors proved that Adam converges to the global minimum in the convex settings in their original paper, however, several papers later found out that their proof contained a few mistakes. Block et. al [7] claimed that they have spotted errors in the original convergence analysis, but still proved that the algorithm converges and provided proof in their paper. Another recent article from Google employees was presented at ICLR 2018 and even won best paper award. To go deeper to their paper I should first describe the framework used by Adam authors for proving that it converges for convex functions.90004 90003 In 2003 Martin Zinkevich introduced Online Convex Programming problem [8]. In the presented settings, we have a sequence of convex functions c1, c2, etc (Loss function executed in ith mini-batch in the case of deep learning optimization). The algorithm, that solves the problem (Adam) in each timestamp t chooses a point x [t] (parameters of the model) and then receives the loss function c for the current timestamp. This setting translates to a lot of real world problems, for examples read the introduction of the paper.For understanding how good the algorithm works, the value of regret of the algorithm after T rounds is defined as follows: 90004 Regret of the algorithm in the online convex programming 90003 where R is regret, c is the loss function on tth mini batch, w is vector of model parameters (weights), and w star is optimal value of weight vector. Our goal is to prove that the regret of algorithm is R (T) = O (T) or less, which means that on average the model converges to an optimal solution. Martin Zinkevich in his paper proved that gradient descent converges to optimal solutions in this setting, using the property of the convex functions: 90004 Well-known property of convex functions.90003 The same approach and framework used Adam authors to prove that their algorithm converges to an optimal solutions. Reddi et al. [3] spotted several mistakes in their proof, the main one lying in the value, which appears in both Adam and Improving Adam’s proof of convergence papers: 90004 90003 Where V is defined as an abstract function that scales learning rate for parameters which differs for each individual algorithms. For Adam it’s the moving averages of past squared gradients, for Adagrad it’s the sum of all past and current gradients, for SGD it’s just 1.The authors found that in order for proof to work, this value has to be positive. It’s easy to see, that for SGD and Adagrad it’s always positive, however, for Adam (or RMSprop), the value of V can act unexpectedly. They also presented an example in which Adam fails to converge: 90004 Adam fails on this sequence 90003 For this sequence, it’s easy to see that the optimal solution is x = -1, however, how authors show, Adam converges to highly sub-optimal value of x = 1. The algorithm obtains the large gradient C once every 3 steps, and while the other 2 steps it observes the gradient -1, which moves the algorithm in the wrong direction.Since values of step size are often decreasing over time, they proposed a fix of keeping the maximum of values V and use it instead of the moving average to update parameters. The resulting algorithm is called 90020 Amsgrad. 90021 We can confirm their experiment with this short notebook I created, which shows different algorithms converge on the function sequence defined above. 90004 Amsgrad without bias correction 90003 How much does it help in practice with real-world data? Sadly, I have not seen one case where it would help get better results than Adam.Filip Korzeniowski in his post describes experiments with Amsgrad, which show similar results to Adam. Sylvain Gugger and Jeremy Howard in their post show that in their experiments Amsgrad actually performs even worse that Adam. Some reviewers of the paper also pointed out that the issue may lie not in Adam itself but in framework, which I described above, for convergence analysis, which does not allow for much hyper-parameter tuning. 90004 90003 One paper that actually turned out to help Adam is ‘Fixing Weight Decay Regularization in Adam’ [4] by Ilya Loshchilov and Frank Hutter.This paper contains a lot of contributions and insights into Adam and weight decay. First, they show that despite common belief L2 regularization is not the same as weight decay, though it is equivalent for stochastic gradient descent. The way weight decay was introduced back in 1988 is: 90004 90003 Where lambda is weight decay hyper parameter to tune. I changed notation a little bit to stay consistent with the rest of the post. As defined above, weight decay is applied in the last step, when making the weight update, penalizing large weights.The way it’s been traditionally implemented for SGD is through L2 regularization in which we modify the cost function to contain the L2 norm of the weight vector: 90004 90003 Historically, stochastic gradient descent methods inherited this way of implementing the weight decay regularization and so did Adam . However, L2 regularization is not equivalent to weight decay for Adam. When using L2 regularization the penalty we use for large weights gets scaled by moving average of the past and current squared gradients and therefore weights with large typical gradient magnitude are regularized by a smaller relative amount than other weights.In contrast, weight decay regularizes all weights by the same factor. To use weight decay with Adam we need to modify the update rule as follows: 90004 Adam update rule with weight decay 90003 Having show that these types of regularization differ for Adam, authors continue to show how well it works with both of them. The difference in results is shown very well with the diagram from the paper: 90004 The Top-1 test error of ResNet on CIFAR-10 measured after 100 epochs 90003 These diagrams show relation between learning rate and regularization method.The color represent high low the test error is for this pair of hyper parameters. As we can see above not only Adam with weight decay gets much lower test error it actually helps in decoupling learning rate and regularization hyper-parameter. On the left picture we can the that if we change of the parameters, say learning rate, then in order to achieve optimal point again we’d need to change L2 factor as well, showing that these two parameters are interdependent. This dependency contributes to the fact hyper-parameter tuning is a very difficult task sometimes.On the right picture we can see that as long as we stay in some range of optimal values for one the parameter, we can change another one independently. 90004 90003 Another contribution by the author of the paper shows that optimal value to use for weight decay actually depends on number of iteration during training. To deal with this fact they proposed a simple adaptive formula for setting weight decay: 90004 90003 where b is batch size, B is the total number of training points per epoch and T is the total number of epochs.This replaces the lambda hyper-parameter lambda by the new one lambda normalized. 90004 90003 The authors did not even stop there, after fixing weight decay they tried to apply the learning rate schedule with warm restarts with new version of Adam. Warm restarts helped a great deal for stochastic gradient descent, I talk more about it in my post ‘Improving the way we work with learning rate’. But previously Adam was a lot behind SGD. With new weight decay Adam got much better results with restarts, but it’s still not as good as SGDR.90004 90003 One more attempt at fixing Adam, that I have not seen much in practice is proposed by Zhang et. al in their paper ‘Normalized Direction-preserving Adam’ [2]. The paper notices two problems with Adam that may cause worse generalization: 90004 90029 90030 The updates of SGD lie in the span of historical gradients, whereas it is not the case for Adam. This difference has also been observed in already mentioned paper [9]. 90031 90030 Second, while the magnitudes of Adam parameter updates are invariant to descaling of the gradient, the effect of the updates on the same overall network function still varies with the magnitudes of parameters.90031 90034 90003 To address these problems the authors propose the algorithm they call Normalized direction-preserving Adam. The algorithms tweaks Adam in the following ways. First, instead of estimating the average gradient magnitude for each individ 90004.90000 Finance English practice: Unit 44 — Exchange Rates 90001 90002 Why exchange rates change 90003 90004 90002 key words 90003 90007 90004 90009 exchange rate ○ purchasing power parity ○ depreciate ○ currency speculation ○ appreciates ○ speculative 90010 90007 90004 An is the price at which one currency can be exchanged for another (eg how many yen are needed to buy a euro). In theory, exchange rates should be at the level that gives (PPP).This means that the cost of a given selection of goods and services (e.g. a loaf of bread, a kilowatt of electricity) would be the same in different countries. So if the price level in a country increases because of inflation, its currency should — its exchange rate should go down in order to return to PPP. For example, if inflation increases in the US, the dollar exchange rate should go down so that it takes more dollars to buy the same products in other countries. 90007 90004 In fact, PPP does not work, as exchange rates can change due to — buying currencies in the hope of making a profit.Financial institutions, companies and rich individuals all buy currencies, looking for high interest rates or short-term capital gains if a currency increases in value or. This means exchange rates change due to speculation rather than PPP. Over 95% of the world’s currency transactions are purely, and not related to trade. Banks and currency traders make considerable profits from the spread between a currency’s buying and selling prices. 90007 90004 90002 Fixed and floating rates 90003 90007 90004 90002 key words 90003 90007 90004 90009 fixed ○ pegged against ○ gold convertibility ○ floating exchange rates ○ freely floating exchange rate ○ market forces ○ common currency 90010 90007 90004 For 25 years after World War II, the levels of most major currencies were determined by governments.They were or the US dollar (e.g. from 1646-67, one pound was worth $ 2.28), and the dollar was pegged against gold. One dollar was worth one thirty-fifth of an ounce of gold, and US Federal Reserve guaranteed that they could exchange an ounce of gold for $ 35. This system was known as. These fixed exchange rates could only be adjusted if the International Monetary Fund agreed. Pegging against the dollar ended in 1971, because following inflation in the USA, the Federal Reserve did not have enough gold to guarantee the American currency.90007 90004 Since the early 1970, there has been a system of in most western countries. This means that exchange rates are determined by people buying and selling currencies in the foreign exchange markets. A means one which is determined by: the level of supply and demand. If there are more buyers of a currency than sellers, its price will rise; if there are more sellers, it will fall. 90007 90004 Since the introduction of a in 2002 fluctuating exchange rates among many European countries are no longer a problem.But the euro continues to fluctuate against the US dollar, the Japanese yen and other currencies. 90007 90004 90002 Government intervention 90003 90007 90004 90002 key words 90003 90007 90004 90009 intervene ○ exchange markets ○ reserves ○ managed 90010 90007 90004 Government and central banks sometimes try to change the value of their currency. They in, using foreign currency to buy their own currency — in order to raise its value — or selling to lower it.The resulting rates are known as floating exchange rates. But speculators generally have a lot more money than a government gas in its reserves of foreign currency, so central banks or government only have limited power to influence exchange rates. 90007 90048.90000 Best Graphics Cards 2020 року — Top Gaming GPUs for the Money 90001
90002 Getting the best graphics card for your gaming PC can yield buttery smooth framerates, but there’s no single solution that’s right for everyone. Some want the fastest graphics card, others the best value, and many are looking for the best card at a given price. Balancing performance, price, features, and efficiency is important because no other component impacts your gaming experience as much as the graphics card. 90003 90002 We test and review all the major GPUs, and we’ve ranked every graphics card in our GPU hierarchy based on performance.We’ve also done extensive testing of graphics card power consumption, using proper hardware, and we’ve looked at the broader AMD vs Nvidia GPUs breakdown. Here we cut things down to a succinct list of the best graphics cards you can currently buy. 90003 90002 We’ve provided 10 options for the best graphics cards, recognizing that there’s plenty of overlap. Is the RX 5700 XT better than the RTX 2060 Super? We think so, though it’s less of a decisive win when looking at RX 5600 XT vs RTX 2060. Individual preference definitely plays a role, and we’ve included many options on this list catering to all budgets.90003 90002 Looking forward, Nvidia revealed its Ampere GA100 GPU on May 14, but it’s clearly a data center part. What does that mean for the rest of the Ampere lineup? Here’s everything we know about the RTX 3080 and Ampere, along with AMD’s Big Navi and Intel’s Xe Graphics. There’s a lot going on in 2020 with upcoming GPUs, so unless you absolute have to buy a new GPU 90009 right now 90010, waiting for the next GPU architectures to come out is a good plan. 90003 90002 It’s not just upcoming GPUs, however.Prices are on the rise, likely related to COVID-19 shortages. Paying more today for hardware that’s soon to be outdated is a double whammy. Our current recommendations reflect the changing GPU market, factoring all of the above. The GPUs are ordered mostly by performance, but price, features, and efficiency are still factors so in a few cases a slightly slower card may be ranked higher. 90003 90002 When buying a graphics card, consider the following: 90003 90002 90017 • Resolution 90018: The more pixels you’re pushing, the more performance you need.You do not need a top-of-the-line GPU to game at 1080p. 90019 90017 • PSU 90018: Make sure that your power supply has enough juice and the right 6 and / or 8-pin connector (s). For example, Nvidia recommends a 650-watt PSU for the RTX 2070 Super, and you’ll need two 8-pin and / or 6-pin PEG connectors. 90019 90017 • Video Memory 90018: A 4GB card is the minimum right now, 6GB models are better, and 8GB or more is strongly recommended. 90019 90017 • FreeSync 90018 or 90017 G-Sync 90018? Either variable refresh rate technology will synchronize your GPU’s frame rate with your screen’s refresh rate.If your monitor supports G-Sync tech (for recommendations, see our Best Gaming Monitors list), you’ll need a GeForce GPU. AMD’s FreeSync tech works with Radeon cards, and Nvidia has certified some FreeSync displays as being G-Sync Compatible. 90003 90031
90032 The Best Graphics Cards Shortlist 90033
90034 90035 90036 GPU 90037 90036 Performance Rank 90037 90036 Value Rank (fps / $) 90037 90042 90043 90044 90035 90046 RTX 2080 Ti 90047 90046 1 (115 fps) 90047 90046 10 ($ 1,140) 90047 90042 90035 90046 RTX 2080 Super 90047 90046 2 ( 102 fps) 90047 90046 9 ($ 700) 90047 90042 90035 90046 RTX 2070 Super 90047 90046 3 (91 fps) 90047 90046 8 ($ 500) 90047 90042 90035 90046 RX 5700 XT 90047 90046 4 (86 fps) 90047 90046 4 ($ 360) 90047 90042 90035 90046 RX 5700 90047 90046 5 (78 fps) 90047 90046 6 ($ 350) 90047 90042 90035 90046 RTX 2060 Super 90047 90046 6 (77 fps) 90047 90046 7 ($ 370) 90047 90042 90035 90046 RX 5600 XT 90047 90046 7 (71 fps) 90047 90046 2 ($ 260) 90047 90042 90035 90046 RTX 2060 90047 90046 8 (68 fps) 90047 90046 5 ($ 295) 90047 90042 90035 90046 GTX 1 660 Super 90047 90046 9 (57 fps) 90047 90046 3 ($ 230) 90047 90042 90035 90046 GTX 1650 Super 90047 90046 10 (43 fps) 90047 90046 1 ($ 160) 90047 90042 90125
90126 90127 Best Graphics Cards for Gaming 2020 90128 90002 90003 (Image credit: Nvidia) 90131 1.RTX 2080 Ti 90132 90002 Best Graphics Card Overall / 4K (When Price Is No Object) 90003 90002 90017 GPU: 90018 Turing (TU102) | 90017 GPU Cores: 90018 4352 | 90017 Boost Clock: 90018 1,545 MHz | 90017 Video RAM: 90018 11GB GDDR6 14 Gbps | 90017 TDP: 90018 250 watts 90003 90002 The fastest non-Titan graphics card 90003 90002 Can legitimately do 4K high / ultra at 60 fps or more 90003 90002 Factory overclocked models are readily available 90003 90002 For most of us, price 90009 is 90010 an object 90003 90002 Card is 18 months old now, so you might as well wait for Ampere 90003 90002 Generally overkill for 1080p displays 90003 90002 If you’re looking for the no-holds-barred champion of graphics cards, right now it’s the 90162 GeForce RTX 2080 Ti 90163.If you’re serious about maxing out all the graphics settings and you want to play at 4K or 1440p, this is the card to get — it’s mostly overkill for 1080p gaming, though enabling all ray tracing effects in games that support the feature makes 1080p still reasonable. Just look at Minecraft RTX performance to see how increased levels of ray tracing can bring even the 2080 Ti to its knees. 90003 90002 Nvidia’s 90162 Turing architecture 90163 is at the heart of the RTX 2080 Ti, boosting performance even if you do not enable ray tracing or DLSS.Concurrent floating-point and integer execution means that even with only moderately higher theoretical performance compared to the previous generation Pascal (GTX 10-series) GPUs like the GTX 1080 Ti, in practice the 2080 Ti is 35-40 percent faster at higher resolutions and settings. 90003 90002 There are three main reasons to not buy the 2080 Ti. First is of course the price — with cards starting at well over $ 1,000, just the graphics card costs more than an entire mid-range gaming PC. On the opposite end of the spectrum, if money is 90009 really 90010 no object, there’s still the 90162 Titan RTX 90163: Double the price for a meager 3-5% increase in performance! Yeah, no thanks.Perhaps most importantly, the RTX 2080 Ti is nearing its two year mark. If you did not buy one in 2019 or 2018, buying now does not make much sense, what with 90162 Nvidia’s Ampere 90163 expected to launch later this year. 90003 90002 90017 Read: 90018 90162 Nvidia GeForce RTX 2080 Ti Review 90163 90003 90002 90003 Nvidia GeForce RTX 2080 Super (Image credit: Nvidia) 90131 2. RTX 2080 Super 90132 90002 Best High-End Graphics Card (at a Much Better Price) 90003 90002 90017 GPU: 90018 Turing (TU104) | 90017 GPU Cores: 90018 3072 | 90017 Boost Clock: 90018 1,815 MHz | 90017 Video RAM: 90018 8GB GDDR6 15 Gbps | 90017 TDP: 90018 250 watts 90003 90002 The second fastest consumer graphics card 90003 90002 Better price to performance ratio than the 2080 Ti 90003 90002 Fastest GDDR6 in a graphics card 90003 90002 Expensive for a minor bump in performance 90003 90002 Can not do 4K ultra in many games at 60 fps 90003 90002 You should wait for Nvidia’s Ampere 7nm GPUs 90003 90002 If your bank account is thinking about going on strike for eyeing the 2080 Ti, stepping down to the 90162 RTX 2080 Super 90163 might help.You’re still getting the second fastest graphics card, saving about 35% on the price, and getting 85-90% of the performance. What’s more, 1440p and 4K gaming are totally possible on the RTX 2080 Super, just not necessarily at maximum quality (especially 4K). The good news is that the difference between ultra and high quality in many games is difficult to see, while the jump in performance can be significant. 90003 90002 There’s still the question of what will happen with ray tracing adoption in the future, of course.The first round of DirectX Raytracing (DXR) games has often seen performance drop by 30-40% when the feature is enabled. DLSS can often make up for that drop, but the implementations of both DXR and DLSS vary by game. If you take a game like 90009 Control 90010, which features ray traced reflections, contact shadows and diffuse lighting — the most complete implementation of ray tracing in a game to date (not counting 90009 Quake II RTX 90010 and 90009 Minecraft RTX 90010, which are special cases of porting an old / simple game to full path tracing) — performance dropped by half, and DLSS 2.0 only mostly recovers the lost fps. 90003 90002 When games in the future start using more ray tracing effects, even the 2080 Super may not keep up. That does not mean you should ignore ray tracing hardware, however. Buying an RTX 2080 Super gets you a graphics card that will handle any current game, and out of the games we tested (see below), it stayed above 60 fps at 1440p ultra in every case. Just be careful about potential buyer’s remorse once Ampere shows up. Current rumors suggest the RTX 3080 will be 30-50% faster than the RTX 2080 Super, though at what price remains cloaked in mystery.90003 90002 90017 Read: 90018 90162 Nvidia GeForce RTX 2080 Super Review 90163 90003 90002 90003 AMD Radeon RX 5700 XT (Image credit: AMD) 90131 3. RX 5700 XT 90132 90002 Best AMD GPU Right Now (at a Great Price) 90003 90002 90017 GPU: 90018 Navi 10 | 90017 GPU Cores: 90018 2560 | 90017 Boost Clock: 90018 1,755 MHz | 90017 Video RAM: 90018 8GB GDDR6 14 Gbps | 90017 TDP: 90018 225 watts 90003 90002 New RDNA architecture provides for better performance and efficiency 90003 90002 The 5700 XT is as fast as the Radeon VII for half the price 90003 90002 Great for 1440p gaming and can do 4K high in a pinch 90003 90002 AMD’s fastest GPU still can not touch Nvidia’s top models 90003 90002 No support for ray tracing, via hardware or software 90003 90002 AMD at 7nm only matches Nvidia efficiency at 12nm 90003 90002 RDNA 2 coming ‘soon-ish’ 90003 90002 not counting Nvidia’s Titan cards , 90162 AMD’s RX 5700 XT 90163 sits in seventh place in our overall GPU hierarchy of performance, but it has other benefits.It’s nearly as fast as the RTX 2070 Super, trailing by just 4% overall, and pricing starts at $ 360 for the least expensive models. We’ve tested several custom 5700 XT cards, like the ASRock RX 5700 XT Taichi, Gigabyte RX 5700 XT, and Sapphire Radeon RX 5700 XT Pulse. Performance typically falls in a narrow range, with aesthetics, cooler size, and price being the main differences. 90003 90002 AMD does not support hardware or software ray tracing, which is certainly a factor, but in traditional rasterization techniques AMD’s RDNA architecture is very competitive.AMD’s GPUs also tend to do better in games that use either DirectX 12 or the Vulkan API, though DX11 games favor Nvidia. Overall, across our test suite, the 5700 XT beats the RTX 2060 Super by about 7% in performance (as well as the earlier RTX 2070 by 4%), and typically costs $ 30 less. There have been some concerns with AMD’s drivers since Navi launched, but the latest updates appear to have addressed the biggest problems. 90003 90002 Compared to AMD’s own previous generation products, the RX 5700 XT also puts up an impressive performance.It basically matches the Radeon VII at 1080p and 1440p, all while using 75W less power. That’s partly the benefit of the 7nm FinFET manufacturing process, something Nvidia will utilize in Ampere, but the foundational RDNA architecture definitely improved resource utilization over the previous GCN architecture cards. Our biggest concern is that AMD’s RDNA 2 will add ray tracing later this year, and apparently 90162 50% higher performance per watt 90163. That’s arguably worth the wait at this point.90003 90002 90017 Read: 90018 90162 AMD Radeon RX 5700 XT Review 90163 90003 90002 90003 Nvidia GeForce RTX 2070 Super (Image credit: Nvidia) 90131 4. RTX 2070 Super 90132 90002 Best Graphics Card for 1440p 90003 90002 90017 GPU: 90018 Turing (TU104 ) | 90017 GPU Cores: 90018 2560 | 90017 Boost Clock: 90018 1,770 MHz | 90017 Video RAM: 90018 8GB GDDR6 14 Gbps | 90017 TDP: 90018 215 watts 90003 90002 Nearly RTX 2080 performance at a significantly lower price 90003 90002 No more Founders Edition price premium 90003 90002 All the ray tracing and deep learning features of the Turing architecture 90003 90002 Nothing new compared to the non-Super RTX cards 90003 90002 Ampere is coming, likely sooner than later 90003 90002 The law of diminishing returns is in full effect as you move up to the top of the GPU hierarchy, which means you’ll pay more for proportionately less performance every additional step.The best way to avoid that is to drop back a few notches, which is where you’ll find the 90162 RTX 2070 Super 90163. 4K gaming is perhaps a stretch, unless you drop down to medium / high quality (in the most demanding games), but 1440p ultra is still viable. 90003 90002 Just as the RTX 2080 Super is a sensible step down from the 2080 Ti, the 2070 Super is only about 10% slower than the 2080 Super but costs almost 30% less. It’s also only a few percent slower than the earlier vanilla 90162 RTX 2080 90163, and you still get 8GB of GDDR6, ray tracing and DLSS, and a card that beats the previous generation GTX 1080 Ti — along with every current AMD GPU.This is all at the same nominal price as the slightly older and slightly slower RTX 2070, and there’s no Founders Edition tax this round. 90003 90002 Whether it’s the latest shooter at maxed out settings, ray tracing games like 90009 Control 90010 or 90009 Deliver Us the Moon 90010, or getting lost in VR with Valve’s 90009 Half-Life: Alyx 90010, the RTX 2070 Super should be able to keep you happily gaming for several years. As with the other Nvidia GPUs, however, Ampere is waiting in the wings and it does not make sense to spend a lot of money right before new graphics cards come out.90003 90002 90017 Read: 90018 90162 Nvidia GeForce RTX 2070 Super Review 90163 90003 90002 90003 AMD Radeon RX 5700 (Image credit: AMD) 90131 5. RX 5700 90132 90002 Best AMD Bang for the Buck 90003 90002 90017 GPU: 90018 Navi 10 | 90017 GPU Cores: 90018 2304 | 90017 Boost Clock: 90018 1,625 MHz | 90017 Video RAM: 90018 8GB GDDR6 14 Gbps | 90017 TDP: 90018 180 watts 90003 90002 Excellent price to performance ratio 90003 90002 Everything good about RDNA and Navi 90003 90002 Arguably the best overall value in GPUs right now 90003 90002 Everything bad about RDNA and Navi as well (eg, no ray tracing or DLSS ) 90003 90002 RDNA 2 and Navi 2x are coming this year 90003 90002 Taking a step down from the fastest AMD GPU often gives you a tremendous amount of performance for less money, and the 90162 Radeon RX 5700 90163 is no exception.Like the 90162 Vega 56 90163 vs. 90162 Vega 64 90163, or 90162 R9 390 vs. R9 390X 90163, the RX 5700 gives you about 93% of the performance of the RX 5700 XT, for about 80% of the price. Originally a $ 350 graphics card, we’re routinely seeing sales and rebates that drop the RX 5700 to around $ 300- $ 310. Given the extra memory and higher performance, it’s an easy pick over the newer RX 5600 XT, as well as Nvidia’s RTX 2060 Super. 90003 90002 Everything good and bad about the RX 5700 XT also applies here.Efficiency and performance are much better than AMD’s previous generation GCN architecture, but you still do not get ray tracing support. We do wonder if AMD will, like Nvidia, enable DXR support in its drivers once Navi 2x launches later this year, or if Navi 1x will forever remain in the rasterization zone. If the next round or ray tracing cards boosts performance in such calculations by 3-4X compared to Nvidia’s Turing RTX GPUs, it’s probably a moot point. 90003 90002 Prices on the RX 5700 are in flux, so depending on when you look the 5700 XT may be the more sensible choice.For basically the same price as the now-discounted RTX 2060, it remains a good pick. Across our test suite, it ends up 11% faster at 1080p and 1440p compared to Nvidia’s GPU. It’s also tied (1% ahead of) with the RTX 2060 Super, for $ 40- $ 70 less. Plus, let’s be honest: Ray tracing performance should not be the top priority of anyone trying to decide between the 2060 and the 5700. Middling performance in ray tracing versus faster performance everywhere else? The RX 5700 is a great option. 90003 90002 90017 Read: 90018 90162 AMD Radeon RX 5700 Review 90163 90003 90002 90003 Nvidia GeForce RTX 2060 Super (Image credit: Nvidia) 90131 6.RTX 2060 Super 90132 90002 Best Nvidia Card for 1080p Ultra and 1440p High 90003 90002 90017 GPU: 90018 Turing (TU106) | 90017 GPU Cores: 90018 2176 | 90017 Boost Clock: 90018 1,650 MHz | 90017 Video RAM: 90018 8GB GDDR6 14 Gbps | 90017 TDP: 90018 175 watts 90003 90002 It’s basically a cheaper take on the RTX 2070 90003 90002 Plenty fast for 1440p gaming 90003 90002 Nothing new to see here, just RTX 2070 redux 90003 90002 Big step up in price relative to RTX 2060 90003 90002 Again : Ampere is coming 90003 90002 Out of all the Nvidia RTX cards, the 90162 RTX 2060 Super 90163 is the hardest to recommend.It’s not that it’s a bad card — it’s plenty fast and has the same features as other RTX models — but performance and pricing end up being eclipsed by AMD’s 5700 XT, or you can save even more money and still come out barely ahead in performance with the RX 5700. Considering it costs nearly $ 100 more than the 5700, that’s not a great bargain. In a direct 90162 face off between the RX 5700 XT and the RTX 2060 Super 90163, we gave AMD the edge, and lowered AMD prices make things even more weighted in favor of the RX 5700 and 5700 XT now.Still, the 2060 Super handles 1080p and 1440p gaming without difficulty; AMD’s card just costs less. 90003 90002 The good news is that competition from AMD means better pricing for everyone, whether you go with team red or team green. The RTX 2060 Super is nearly the same performance as the earlier 90162 RTX 2070 90163 that we’ve recommended in the past (it’s 4% slower), and it costs $ 100- $ 200 less. Thankfully, like the other RTX Super cards, there’s no Founders Edition ‘tax’ this time. 90003 90002 If you want an 8GB card that can do ray tracing, for the lowest price possible, the RTX 2060 Super fills that niche.The extra memory does actually have an impact on ray tracing performance as well, so there are reasons to spring for the upgrade over the vanilla RTX 2060. Just do not be surprised if an RTX 3060 shows up that performs better and costs less later this year or in early 2021. 90003 90002 90017 Read: 90018 90162 Nvidia GeForce RTX 2060 Super Review 90163 90003 90002 90003 AMD Radeon RX 5600 XT (Image credit: AMD) 90131 7. RX 5600 XT 90132 90002 Best Affordable 1080p Performer (but Get the 14 Gbps Variant) 90003 90002 90017 GPU: 90018 Navi 10 | 90017 GPU Cores: 90018 2304 | 90017 Boost Clock: 90018 1,375 MHz | 90017 Video RAM: 90018 6GB GDDR6 12/14 Gbps | 90017 TDP: 90018 150 watts 90003 90002 Easily beats Nvidia’s GTX 1660 Super and 1660 Ti in performance 90003 90002 AMD’s Navi / RDNA architecture is a welcome improvement over GCN 90003 90002 No support for ray tracing technology 90003 90002 It’s a trimmed down RX 5700, for nearly the same street price 90003 90002 Confusion caused by last-minute BIOS update (avoid the 12 Gbps GDDR6 models) 90003 90002 The 90162 Radeon RX 5600 XT 90163 launch is the perfect showcase for how competitive the mid-range graphics card market has become.Initially intended to compete with the GTX 1660 Ti at the $ 280 price point, it would have easily won that matchup — it’s about 15% faster. Then Nvidia preemptively dropped the price on the 90162 RTX 2060 Founders Edition to $ 299 90163, and worked with EVGA to launch a special 90162 RTX 2060 KO for $ 300 90163 as well, and things got interesting. AMD responded with a last-minute BIOS update that increased clock speeds on the RX 5600 XT, and allowed partners the option to run the memory at 14 Gbps instead of the ‘reference’ 12 Gbps.Needless to say, a 17% increase in memory bandwidth and GPU clocks helps quite a bit. 90003 90002 Now that the dust has settled, most RX 5600 XT models have 14 Gbps BIOS updates available. Prices have also dropped, and cards like this Gigabyte RX 5600 XT OC-6G start at just $ 260- $ 270 (after rebate, and yes it has a 14 Gbps BIOS update). Performance is similar to what you get with a factory overclocked RTX 2060, though Nvidia’s slightly lower power use and features like ray tracing and DLSS still give it the edge.But this is a win by judge’s decision and not a knockout, never mind EVGA’s KO branding, and some people will be happier supporting AMD and saving $ 30 or more. 90003 90002 Our advice for the RX 5600 XT is to pick up a card with 14 Gbps memory, which is most of them. The 14 Gbps update improves performance by at least 5% compared to 12 Gbps memory, and 10-15% compared to the ‘reference’ specs listed above. 90003 90002 90017 Read: 90018 90162 AMD Radeon RX 5600 XT Review 90163 90003 90002 90003 Nvidia GeForce RTX 2060 (Image credit: Nvidia) 90131 8.RTX 2060 90132 90002 Best Entry Level Ray Tracing and Potent 1080p 90003 90002 90017 GPU: 90018 Turing (TU106) | 90017 GPU Cores: 90018 1920 | 90017 Boost Clock: 90018 1,680 MHz | 90017 Video RAM: 90018 6GB GDDR6 14 Gbps | 90017 TDP: 90018 160 watts 90003 90002 Plenty fast with a price cut on some models making it far more palatable 90003 90002 Includes all the latest hardware ray tracing features 90003 90002 Faster than previous generation GTX 1070 Ti 90003 90002 Enabling ray tracing usually requires DLSS ( ie, rendering at 1280×720 and upscaling) 90003 90002 Many models still cost $ 350 or more 90003 90002 6GB VRAM could prove limiting in future games 90003 90002 90162 Nvidia’s RTX 2060 90163 was a decent card when it launched in January 2019, and dropping the price on the Founders Edition one year later keeps it in the running.In a direct head-to-head between ‘reference’ RTX 2060 and RX 5600 XT models, Nvidia eked out a win, but lower prices have now pushed our recommendation back to AMD. A lot of it will depend on current pricing, the features you get, as well as potential factory overclocks. Non-reference RX 5600 XT cards beat the stock 2060 FE, but non-reference RTX 2060 cards like the 90162 EVGA RTX 2060 KO Ultra 90163 swap things back. 90003 90002 For many people, $ 300 is about as much as they’re willing to spend on a graphics card, making this an important part.Sure, the RTX 2080 Ti is almost twice as fast at 4K ultra, but it also costs nearly four times as much. The RTX 2060 is also great for 1080p gaming, averaging 90 fps in our test suite at ultra settings, though 90009 Metro Exodus 90010 and 90009 Red Dead Redemption 2 90010 both fall short of 60 fps at ultra settings. 90003 90002 It’s also good to put things in perspective. The RTX 2060 at $ 300 is nearly 70% faster than the GTX 1060 6GB, and basically twice as fast as the GTX 970. At the same time, today’s RTX 2060 cards are functionally the same as last year’s RTX 2060 cards.We can think of better things to do than waiting a year to save $ 50. But if you’re in the market for a new graphics card today and you do not want to wait around to see what Ampere and Navi 2x have to offer in the fall, this is a great 1080p gaming solution — and it will even handle ray tracing okay, if you enable DLSS. 90003 90002 90017 Read: 90018 90162 Nvidia GeForce RTX 2060 Review 90163 90003 90002 90003 Nvidia GeForce GTX 1660 Super (Image credit: Nvidia) 90131 9. GTX 1660 Super 90132 90002 Best Mainstream Esports / 1080p High Graphics Card 90003 90002 90017 GPU: 90018 Turing (TU116) | 90017 GPU Cores: 90018 1408 | 90017 Boost Clock: 90018 1,785 MHz | 90017 Video RAM: 90018 6GB GDDR6 14 Gbps | 90017 TDP: 90018 125 watts 90003 90002 Nearly as fast as the GTX 1660 Ti, for less money 90003 90002 GDDR6 gives it a healthy performance boost over the vanilla 1660 90003 90002 Turing is very power efficient, even at 12nm 90003 90002 Lots of more expensive models 90003 90002 No hardware ray tracing support 90003 90002 Dipping down closer to $ 200, we’re given the choice between the 90162 GeForce GTX 1660 Super 90163 for $ 230, the vanilla GeForce 90162 GTX 1660 90163 for around $ 200, or the 90162 RX 5500 XT 8GB 90163 starting at around $ 200.They’re all viable candidates, but we’ve done the testing (see below) and the GTX 1660 Super is 15% faster than the regular 1660 and nearly 20% faster than the RX 5500 XT 8GB. We’ve looked at the 90162 GTX 1660 vs. RX 5500 XT 90163 and declared the Nvidia card the winner, but we also think the GTX 1660 Super is better than the GTX 1660 for just $ 20- $ 30 more. 90003 90002 Despite Nvidia’s Turing GPUs still using TSMC 12nm FinFET, actual power use is basically identical to AMD’s Navi 14 chips made using TSMC 7nm FinFET.The fact that Nvidia is faster and draws the same power while using the older manufacturing node says a lot. For $ 230, the GTX 1660 Super basically gets you the same level of performance as the older GTX 1070 in a mo 90003.
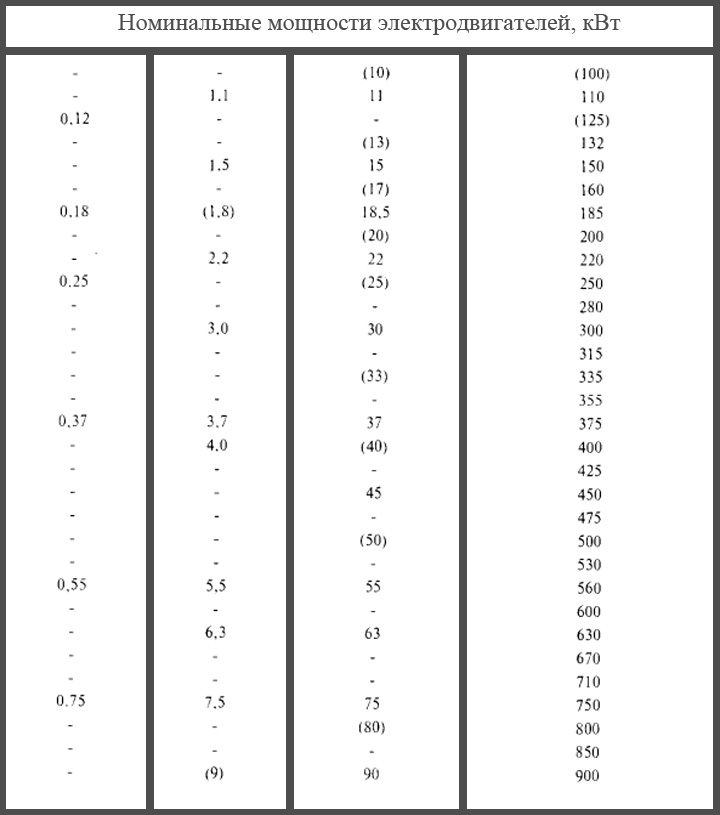

 При выборе акустической системы покупатель зачастую ориентируется на указанные производителем параметры мощности. Что означают эти величины и как их правильно подобрать, мы расскажем в нашей статье.
При выборе акустической системы покупатель зачастую ориентируется на указанные производителем параметры мощности. Что означают эти величины и как их правильно подобрать, мы расскажем в нашей статье. Пиковая мощность PMPO обозначает способность аппаратуры выдержать определенный звуковой предел, не получая повреждений. Действие пика с частотой 100 Гц длится при испытаниях до 1 секунды. Нелинейные искажения при расчете игнорируются.
Пиковая мощность PMPO обозначает способность аппаратуры выдержать определенный звуковой предел, не получая повреждений. Действие пика с частотой 100 Гц длится при испытаниях до 1 секунды. Нелинейные искажения при расчете игнорируются.