Что такое дискретные и непрерывные данные. Как их различать и использовать. Какие особенности нужно учитывать при работе с дискретными и непрерывными величинами. Примеры дискретных и непрерывных данных в статистике и аналитике.
Что такое дискретные и непрерывные данные
Дискретные и непрерывные данные — это два основных типа количественных данных в статистике и анализе данных. Понимание их различий критически важно для правильной обработки и интерпретации информации.
Определение дискретных данных
Дискретные данные — это данные, которые могут принимать только определенные значения из конечного или счетного множества. Они представляют собой отдельные, различимые значения, между которыми нет промежуточных значений.
Ключевые признаки дискретных данных:
- Принимают только целые значения
- Могут быть подсчитаны
- Имеют разрывы между значениями
- Часто представляют количество чего-либо
Определение непрерывных данных
Непрерывные данные — это данные, которые могут принимать любые значения в определенном диапазоне. Они представляют измерения и могут включать дробные части.

Основные характеристики непрерывных данных:
- Могут принимать любые значения в заданном интервале
- Измеряются, а не подсчитываются
- Не имеют разрывов между значениями
- Часто представляют измерения величин
Ключевые различия между дискретными и непрерывными данными
Понимание разницы между дискретными и непрерывными данными критически важно для правильного анализа и интерпретации результатов. Рассмотрим основные отличия:
Природа значений
- Дискретные данные: принимают только определенные значения (обычно целые числа)
- Непрерывные данные: могут принимать любые значения в заданном диапазоне
Метод получения
- Дискретные данные: обычно получаются путем подсчета
- Непрерывные данные: получаются путем измерения
Промежуточные значения
- Дискретные данные: между значениями существуют разрывы
- Непрерывные данные: между любыми двумя значениями всегда есть промежуточные значения
Графическое представление
- Дискретные данные: обычно представляются столбчатыми диаграммами или точечными графиками
- Непрерывные данные: представляются гистограммами или линейными графиками
Примеры дискретных и непрерывных данных
Для лучшего понимания различий между дискретными и непрерывными данными рассмотрим конкретные примеры:
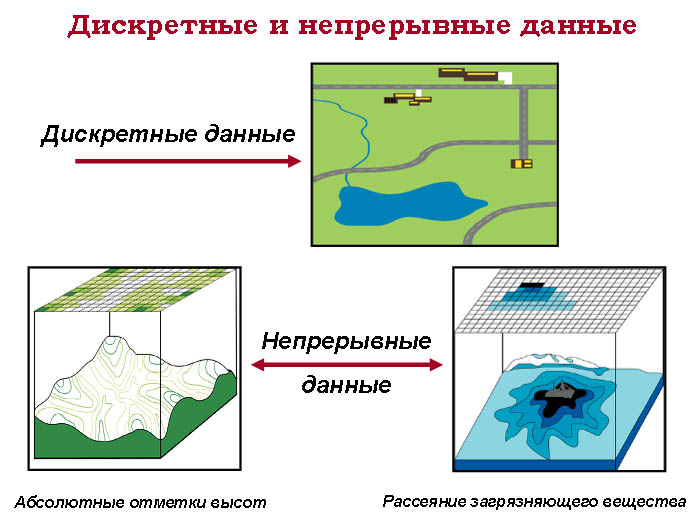
Примеры дискретных данных:
- Количество детей в семье
- Число страниц в книге
- Количество проданных товаров
- Число студентов в классе
- Количество попыток в тесте
Примеры непрерывных данных:
- Рост человека
- Температура воздуха
- Время выполнения задачи
- Скорость автомобиля
- Вес продукта
Особенности анализа дискретных и непрерывных данных
При работе с дискретными и непрерывными данными важно учитывать их особенности для корректного анализа:
Анализ дискретных данных
- Используются методы описательной статистики для дискретных величин (мода, медиана)
- Применяются специальные распределения вероятностей (биномиальное, пуассоновское)
- Часто используются методы непараметрической статистики
Анализ непрерывных данных
- Применяются методы описательной статистики для непрерывных величин (среднее, стандартное отклонение)
- Используются распределения для непрерывных величин (нормальное, экспоненциальное)
- Часто применяются параметрические статистические методы
Выбор между дискретным и непрерывным представлением данных
В некоторых случаях данные могут быть представлены как в дискретной, так и в непрерывной форме. Выбор зависит от целей анализа и природы данных:
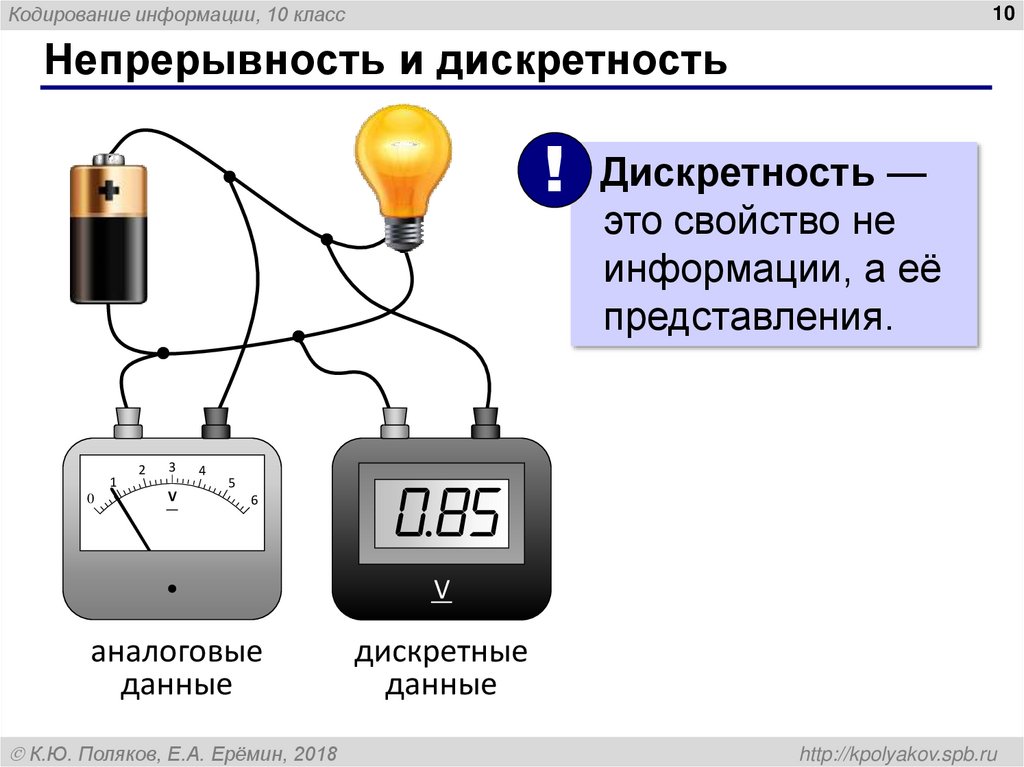
Когда выбирать дискретное представление:
- Данные естественным образом дискретны (например, количество людей)
- Требуется точный подсчет
- Анализ фокусируется на отдельных категориях или группах
Когда выбирать непрерывное представление:
- Данные измеряются с высокой точностью
- Важны промежуточные значения
- Анализ включает математические операции, требующие непрерывности
Практическое применение знаний о дискретных и непрерывных данных
Понимание различий между дискретными и непрерывными данными имеет важное практическое значение в различных областях:
В статистике и анализе данных
- Выбор правильных статистических методов
- Корректная интерпретация результатов анализа
- Определение подходящих графических представлений
В машинном обучении
- Выбор алгоритмов, подходящих для типа данных
- Правильная предобработка данных
- Оценка эффективности моделей
В бизнес-аналитике
- Корректный анализ показателей эффективности
- Правильное построение прогнозных моделей
- Точная сегментация клиентов
Заключение
Понимание различий между дискретными и непрерывными данными является фундаментальным навыком для любого специалиста, работающего с данными. Это знание позволяет:
- Правильно интерпретировать информацию
- Выбирать подходящие методы анализа
- Корректно представлять результаты
- Принимать обоснованные решения на основе данных
Важно помнить, что в реальном мире граница между дискретными и непрерывными данными может быть размытой, и выбор подхода часто зависит от контекста и целей анализа. Глубокое понимание природы данных позволяет специалистам по анализу данных и статистике принимать обоснованные решения и получать надежные результаты.
Дискретные и непрерывные данные – в чем разница?
Дискретные и непрерывные данные – в чем разница? Для такого простого слова «данные» – довольно сложная тема. Например, «любовь» или «новости». Есть структурированные и неструктурированные данные. Тогда у вас есть качественные и количественные данные. Теперь мы хотели бы изучить еще два типа данных – дискретный и непрерывный – и помочь вам понять разницу. (Тогда ваша организация может использовать статистическое программное обеспечение, чтобы получить представление о обоих типах.)Загрузить программу ВІ
Демонстрации решений
Оглавление
Для такого простого слова «данные» – довольно сложная тема. Например, «любовь» или «новости». Есть структурированные и неструктурированные данные. Тогда у вас есть качественные и количественные данные.
Теперь мы хотели бы изучить еще два типа данных – дискретный и непрерывный – и помочь вам понять разницу.
Посмотреть самое простое в использовании программное обеспечение для статистического анализа →
Чем больше вы понимаете об этих уникальных типах данных, тем больше вы сможете определить возможности, в которых каждый из них может пригодиться. Затем вы можете использовать эту информацию, чтобы принести пользу своему бренду, независимо от того, являетесь ли вы специалистом по обработке данных, аналитиком данных, инженером по обработке данных – или просто поклонником цифр.
Дискретные и непрерывные данные
При рассмотрении набора чисел они обычно являются дискретными (счетными) переменными или непрерывными (измеряемыми) переменными. То, как вы изучаете эти данные, должно отличаться в зависимости от того, к какой группе они относятся. Это, безусловно, повлияет и на то, как это будет измеряться.
В чем разница между дискретными и непрерывными данными?
Дискретные данные включают в себя круглые конкретные числа, которые определяются путем подсчета. Непрерывные данные включают комплексные числа, которые измеряются в течение определенного интервала времени.
Простой способ описать разницу между ними – визуализировать график точечной диаграммы в сравнении с линейным графиком.
Непрерывные данные включают комплексные числа, которые измеряются в течение определенного интервала времени.
Простой способ описать разницу между ними – визуализировать график точечной диаграммы в сравнении с линейным графиком.
Когда вы соберете набор круглых определенных чисел, они окажутся на своем месте на графике, похожем на те, что показаны слева. Дискретные данные относятся к отдельным счетным предметам.
Когда вы измеряете определенный поток данных со сложным диапазоном результатов, эти результаты будут обозначены линией в виде диапазона данных (см. Графики справа). Непрерывные данные относятся к изменениям с течением времени, включая концепции, которые не просто подсчитать, но требуют подробных измерений.
Подождите, пока мы немного раскроем эти термины для лучшего понимания.
Что такое дискретные данные?
Некоторые синонимы слова «дискретный» включают: разъединенный, отдельный и отдельный. Их можно легко применить к идее дискретных данных.
Мы собираем данные, чтобы найти взаимосвязи, тенденции и другие концепции. Например, если вы отслеживаете количество отжиманий, которые вы делаете каждый день в течение месяца, основной целью является оценка вашего прогресса и скорости улучшения.
С учетом сказанного, ваш дневной счет – это дискретное, изолированное число. Нет четкого диапазона того, сколько вы можете сделать за один день, поэтому отношения остаются неопределенными. Чем больше информации вы собираете с течением времени, тем больше идей вы можете сделать, например, что среднее количество отжиманий, которые вы делали на прошлой неделе, составляло 15 отжиманий в день, что на 5 отжиманий в день больше, чем неделей ранее. Между тем, сами числа отжиманий – это целые, круглые числа, которые нельзя разбить на более мелкие части.
Забавное практическое правило состоит в том, что во многих случаях дискретным данным может предшествовать «количество».
Примеры дискретных данных
Некоторые примеры дискретных данных, которые можно собрать:
- Количество клиентов, купивших разные товары
- Количество компьютеров в каждом отделе
- Количество товаров, которые вы покупаете в продуктовом магазине каждую неделю.

Дискретные данные также могут быть качественными. Национальность, которую вы выбираете в форме, – это отдельные данные. Национальность каждого на вашей работе, если сгруппировать вместе с помощью программного обеспечения для работы с электронными таблицами, может быть ценной информацией при оценке вашей практики найма.
Посмотреть бесплатное программное обеспечение для электронных таблиц с самым высоким рейтингом →
Национальная перепись состоит из дискретных данных, как качественных, так и количественных. Подсчет и сбор этой идентифицирующей информации углубляет наше понимание населения. Это помогает нам делать прогнозы о будущем, документируя историю. Это отличный пример силы дискретных данных.
Что такое непрерывные данные?
Непрерывные данные относятся к нефиксированному количеству возможных измерений между двумя реалистичными точками.
Эти числа не всегда чистые и аккуратные, как те, которые содержатся в дискретных данных, поскольку они обычно собираются на основе точных измерений. Со временем измерение определенного объекта позволяет нам создать определенный диапазон, в соответствии с которым мы можем разумно ожидать сбора большего количества данных.
Со временем измерение определенного объекта позволяет нам создать определенный диапазон, в соответствии с которым мы можем разумно ожидать сбора большего количества данных.
Непрерывные данные – это все о точности. Переменные в этих наборах данных часто имеют десятичные точки, а число справа растянуто, насколько это возможно. Этот уровень детализации имеет первостепенное значение для ученых, врачей и производителей, и это лишь некоторые из них.
Примеры непрерывных данных
Некоторые примеры непрерывных данных включают:
- Вес новорожденных малышей
- Суточная скорость ветра
- Температура морозильной камеры
Когда вы думаете об экспериментах или исследованиях, включающих постоянные измерения, они, вероятно, в некоторой степени связаны с непрерывными переменными. Если где-нибудь в таблице у вас есть число вроде «2,86290», это не то число, которое вы могли бы легко вычислить сами – подумайте об измерительных устройствах, таких как секундомеры, весы, термометры и тому подобное.
Задача с использованием этих инструментов, вероятно, применима к непрерывным данным. Например, если мы отслеживаем каждого бегуна на Олимпийских играх, время будет отображаться на графике вдоль соответствующей линии. Несмотря на то, что с годами наши спортсмены становятся быстрее и сильнее, никогда не должно быть выбросов, искажающих остальные данные. (Даже Усэйн Болт всего на пару секунд быстрее, чем историческое поле, если говорить об этом.)
На этой линии есть бесконечные возможности (например, 5,77 секунды, 5,772 секунды, 5,7699 секунды и т. Д.), Но каждое новое измерение будет постоянно находиться где-то в пределах диапазона.
Не каждый пример непрерывных данных будет аккуратно попадать в прямую линию, но со временем диапазон станет более очевидным, и вы можете сделать ставку на новые точки данных, застрявшие внутри этих параметров.
Важность как непрерывных, так и дискретных данных
Тот факт, что мы поставили «против» в заголовке этого блога, не означает, что это соревнование (хотя мы не остановим вас от создания футболок «Team Discrete» или «Team Continuous»).
Дело в том, что оба типа одинаково ценны для сборщиков данных, и каждый день вы будете сталкиваться с моментами, которые приводят к измерениям, которые могут по праву способствовать любому типу данных. Любое всестороннее исследование формируется за счет объединения этих двух уникальных групп данных.
Почитать еще
Введение в анализ временных рядов
Хотя для анализа данных используются все многочисленные передовые инструменты и методы, такие как наука о
История развития моделей данных
Итак, прыгайте на борт и наслаждайтесь путешествиями во времени наших попыток справиться с временностью в
Машинное обучение
Глубокое обучение – это продвинутая форма машинного обучения. Глубокое обучение относится к способности компьютерных систем, известных
Правила эффективного прогнозирования
Интуиция очень важна. С ее помощью было создано большое количество хороших прогнозов. Но нужно всегда
С ее помощью было создано большое количество хороших прогнозов. Но нужно всегда
Выборка. Типы выборок
Суммарная численность объектов наблюдения (люди, домохозяйства, предприятия, населенные пункты и т.д.), обладающих определенным набором признаков
Обзор самых популярных алгоритмов машинного обучения
Существует такое понятие, как «No Free Lunch» теорема. Её суть заключается в том, что нет
Обзор основных видов сегментации
Загрузить программу ВІ Демонстрации решений Аналитика бизнеса Оглавление Сегментация бренда Сегментация помогает принимать более эффективные
Алгоритмы машинного обучения
В одной из статей мы познакомились с основами машинного обученияи, хотя кратко, но очень лаконично, мы
Полное руководство по анализу текста
Напоминание – это количество правильных результатов, разделенное на количество результатов, которые должны были быть возвращены. Загрузить
Загрузить
Читайте о всех решениях
Какие бы задачи перед Вами не стояли, мы сможем предложить лучшие инструменты и решения
Смотреть
Несколько видео о наших продуктах
Проиграть видео
Презентация аналитической платформы Tibco Spotfire
Проиграть видео
Отличительные особенности Tibco Spotfire 10X
Проиграть видео
Как аналитика данных помогает менеджерам компании
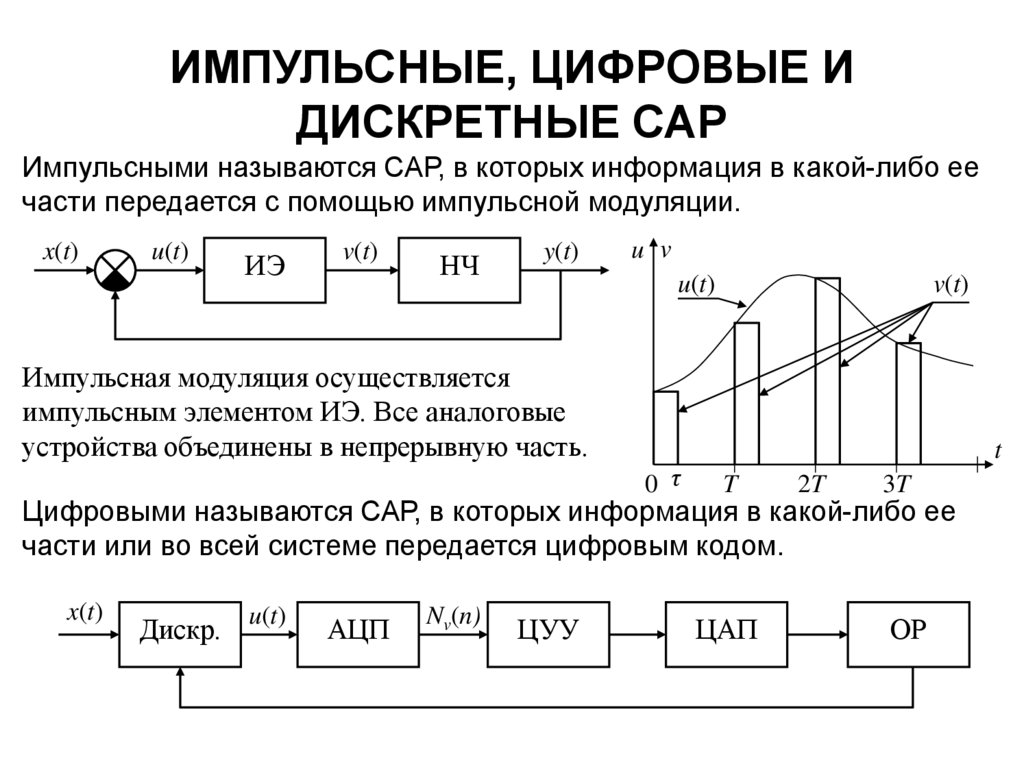
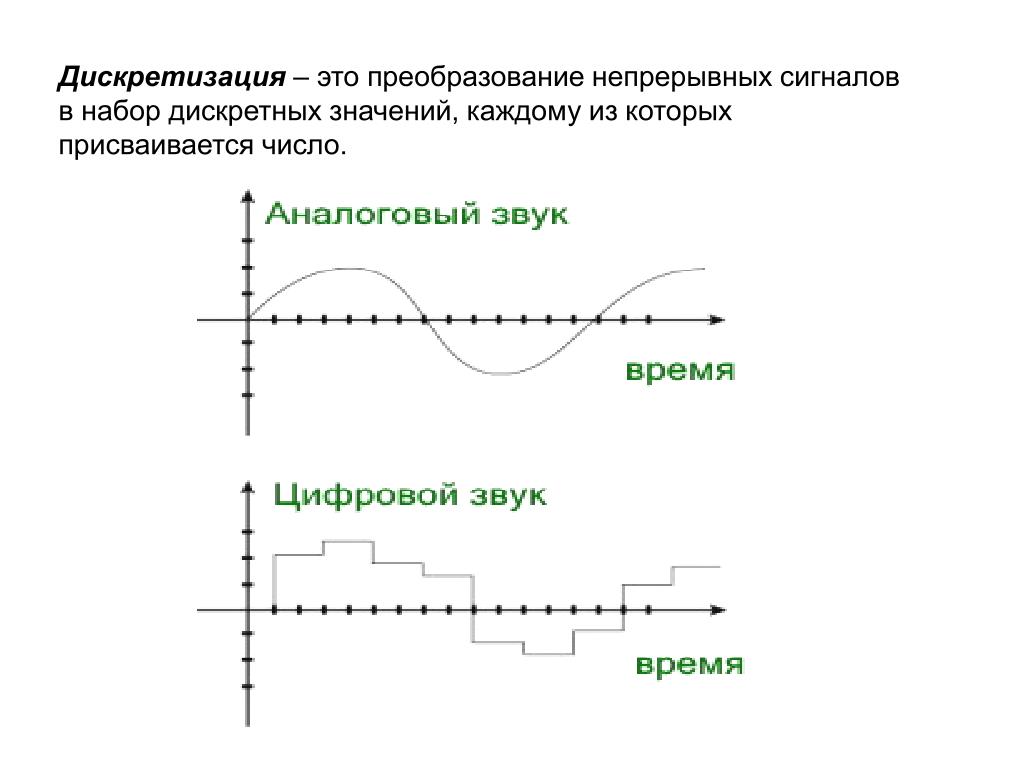
vladimjh3021-03-16T15:33:58+02:00Инициализируйте сигналы и дискретные состояния
Инициализируйте сигналы и дискретные состояния
Simulink® позволяет вам задавать начальные значения сигналов и дискретных состояний, т.е. значений сигналов и дискретных состояний в симуляции. Можно использовать объекты сигнала, чтобы задать начальные значения любого или дискретного состояния сигнала в модели. Кроме того, для некоторых блоков, например, Outport, Data Store Memory или Memory, можно использовать или объект сигнала или параметры блоков или обоих, чтобы задать начальное значение состояния блока или вывести. В таких случаях, Simulink Check, чтобы гарантировать, что значения, заданные объектом сигнала и параметром, сопоставимы. Для получения информации об инициализации сигналов шины смотрите, Задают Начальные условия для Элементов Шины
Кроме того, для некоторых блоков, например, Outport, Data Store Memory или Memory, можно использовать или объект сигнала или параметры блоков или обоих, чтобы задать начальное значение состояния блока или вывести. В таких случаях, Simulink Check, чтобы гарантировать, что значения, заданные объектом сигнала и параметром, сопоставимы. Для получения информации об инициализации сигналов шины смотрите, Задают Начальные условия для Элементов Шины
Когда вы задаете объект сигнала для инициализации или дискретного состояния сигнала или переменную как значение параметров блоков, Simulink разрешает имя, которое вы задаете к соответствующему объекту или переменной, как описано в Разрешении Символа.
Данный сигнал может быть сопоставлен с самое большее одним объектом сигнала при любых обстоятельствах. Сигнал может относиться к объекту несколько раз, но каждая ссылка должна решить к точно тому же объекту. Различный объект сигнала, который имеет точно те же свойства, не удовлетворит требование для уникальности. Ошибка времени компиляции происходит, если модель сопоставляет больше чем один объект сигнала с каким-либо сигналом. Для получения дополнительной информации смотрите
Ошибка времени компиляции происходит, если модель сопоставляет больше чем один объект сигнала с каким-либо сигналом. Для получения дополнительной информации смотрите Simulink.Signal и блок Merge.
Используя параметры блоков, чтобы инициализировать сигналы и дискретные состояния
Для блоков, которые имеют начальное значение или начальный параметр условия, можно использовать тот параметр, чтобы инициализировать сигнал. Например, следующее диалоговое окно Block Parameters инициализирует сигнал для блока Unit Delay с начальным условием 0.
Чтобы получить доступ к этим параметрам блоков, выберите один из этих методов:
Используйте Model Data Editor (на вкладке Modeling, нажмите Model Data Editor) сконфигурировать несколько сигналов и состояний с доступной для поиска, поддающейся сортировке таблицей. Чтобы инициализировать состояние блока или хранилище данных, можно использовать соответствующую вкладку (States или Data Stores).
 Чтобы инициализировать сигнал, состояние или хранилище данных, можно использовать вкладку Parameters и найти строку, которая соответствует соответствующим параметрам блоков.
Чтобы инициализировать сигнал, состояние или хранилище данных, можно использовать вкладку Parameters и найти строку, которая соответствует соответствующим параметрам блоков.Используйте Property Inspector (на вкладке Modeling, под Design, click Property Inspector), чтобы сконфигурировать один сигнал или утвердить за один раз. Выберите блок, который обеспечивает целевое состояние или генерирует целевой сигнал, и найдите соответствующие параметры блоков.
Используйте диалоговое окно параметров блоков. Используйте этот метод, чтобы сконфигурировать один сигнал или состояние за один раз или сравнить настройки нескольких сигналов или состояний рядом друг с другом.
Для получения дополнительной информации о методах, чтобы получить доступ к параметрам блоков (включая параметры, что управляющий сигнал и инициализация состояния), смотрите Set Properties и Параметры.
Используйте объекты сигнала, чтобы инициализировать сигналы и дискретные состояния
Можно использовать объекты сигнала, которые имеют класс памяти кроме 'auto' или, когда вы устанавливаете класс памяти по умолчанию соответствующей категории данных к Default (настройка по умолчанию) в Коде, Сопоставляющем Редактор, 'Model default' инициализировать:
Чтобы задать начальное значение, используйте Model Explorer или MATLAB® команды, чтобы сделать следующее:
Создайте объект сигнала.

На панели инструментов Model Explorer выберите > . Объект сигнала появляется в базовом рабочем пространстве с именем по умолчанию. Переименуйте объект как
S1. В качестве альтернативы используйте эту команду в командной строке:S1 = Simulink.Signal;
Имя объекта сигнала должно совпасть с именем сигнала, что объект инициализирует. Несмотря на то, что не требуемый, рассмотрите установку опции Signal name must resolve to Simulink signal object в диалоговом окне Signal Properties. Эта установка делает объекты сигнала в рабочем пространстве MATLAB сопоставимыми с сигналами, которые появляются в вашей модели.
Рассмотрите использование Мастера Объекта данных, чтобы создать объекты сигнала. Мастер Объекта данных ищет модель сигналы, для которых не существуют объекты сигнала. Можно затем выборочно создать объекты сигнала для нескольких сигналов, перечисленных в результатах поиска с одной операцией. Для получения дополнительной информации о Мастере Объекта данных, смотрите, Создают Объекты данных для Модели Используя Мастер Объекта данных.

Установите класс хранения объектов сигнала на значение кроме
AutoилиModel default. В панели Contents Model Explorer выберите объект сигнала. В Диалоговой панели, набор Storage class кExportedGlobal. В качестве альтернативы используйте эту команду в командной строке:S1.CoderInfo.StorageClass = 'ExportedGlobal';
Установите начальное значение. Можно задать выражение MATLAB, включая имя переменной рабочей области, которая оценивает к значению числового скаляра или массиву.
Механизм Simulink преобразует начальное значение так тип, сложность, и размерность сопоставима с соответствующим значением параметров блоков. Если вы задаете недопустимое значение или выражение, сообщение об ошибке появляется, когда вы обновляете модель.
В Диалоговой панели Model Explorer, набор Initial value к
0.5. В качестве альтернативы используйте эту команду в командной строке:S1.
 InitialValue = '0.5'
InitialValue = '0.5'Если можно также использовать параметры блоков, чтобы установить начальное значение сигнала или состояния, необходимо установить параметр любой, чтобы опустеть (
[]) или к тому же значению как начальное значение объекта сигнала. Если вы устанавливаете значение параметров пустеть, Simulink использует значение, заданное объектом сигнала инициализировать сигнал или состояние. Если вы устанавливаете параметр на значение, Simulink сравнивает значение параметров с объектным значением сигнала и отображает ошибку, если они отличаются.Следующий пример показывает объект сигнала, задающий начальный выход активированной подсистемы.
sсигналаинициализируется к 4,5. Чтобы избежать ошибки непротиворечивости, начальным значением активированного блока Outport подсистемы должен быть[]или 4.5.Если вам нужны объект сигнала и его установка начального значения, чтобы сохраниться через сеансы Simulink, смотрите, Создают Персистентные Объекты данных.
Некоторые настройки начального значения могут зависеть от режима инициализации. Для получения дополнительной информации смотрите обнаружение инициализации Underspecified.
Classic initialization mode: В этом режиме, настройках начального значения для объектов сигнала, которые представляют следующие сигналы и состояния, заменяет соответствующие начальные значения параметров блоков, если неопределенный (задал как []):
Simplified initialization mode: В этом режиме, начальных значениях объектов сигнала, сопоставленных с выходом следующих блоков, проигнорирован. Начальные значения соответствующих блоков используются вместо этого.
Использование объектов сигнала, чтобы настроить начальные значения
Simulink позволяет вам использовать объекты сигнала как альтернативу объектам параметра (см. Simulink.Parameter) настроить начальные значения блока выходные параметры и состояния, которые могут быть заданы через настраиваемый параметр. Чтобы использовать объект сигнала, чтобы настроить начальное значение, создайте объект сигнала с тем же именем как сигнал или состояние и установите объектное начальное значение сигнала к выражению, которое включает переменную, заданную в рабочее пространство MATLAB. Можно затем настроить начальное значение путем изменения значения соответствующей переменной рабочей области во время симуляции.
Чтобы использовать объект сигнала, чтобы настроить начальное значение, создайте объект сигнала с тем же именем как сигнал или состояние и установите объектное начальное значение сигнала к выражению, которое включает переменную, заданную в рабочее пространство MATLAB. Можно затем настроить начальное значение путем изменения значения соответствующей переменной рабочей области во время симуляции.
Например, предположите, что вы хотите настроить начальное значение состояния блока Memory под названием M1. Для этого вы можете создать объект сигнала под названием M1, установите его класс памяти на 'ExportedGlobal', установите его начальное значение к K (M1.InitialValue='K'), где K переменная рабочей области в рабочем пространстве MATLAB и устанавливает соответствующий начальный параметр условия блока Memory к [] избегать ошибок непротиворечивости. Вы могли затем изменить начальное значение состояния блока Memory любое время во время симуляции путем изменения значения K в командной строке MATLAB и обновлении блок-схемы (например, путем ввода Ctrl+D).
Сводные данные поведения инициализации для объектов сигнала
Следующие различные типы модели и таблицы show сигналов и дискретных состояний, которые можно инициализировать и поведение симуляции, которое заканчивается для каждого.
| Или дискретное состояние сигнала | Описание | Поведение |
|---|---|---|
| S1 | Корневой входной порт |
|
| X1 | Блок Unit Delay — Блок с дискретным состоянием, которое имеет начальное условие |
|
| X2 | Блок Data Store Memory |
|
| S2 | Выход активированной подсистемы |
|
| S3 | Персистентные сигналы |
|
 InitialValue
InitialValue
 InitialValue
InitialValueПохожие темы
- Используя инициализируют, сброс и оконечные функции
- Установите значения параметров блоков
- Задайте начальные условия для элементов шины
- Основы сигнала
- Исследуйте значения сигналов
Становимся специалистами по Tableau Desktop – Часть 4. Дискретные и непрерывные, агрегированные и деагрегированные.
Дискретный против непрерывного
Зеленые и синие таблетки
Прежде всего, я хочу прояснить недоразумение, относительно того, что зеленые таблетки указывают меры, а синие – измерения. Дело в том, что зеленые таблетки обозначают непрерывные переменные, а синие таблетки – дискретные. Путаница вызвана настройкой Tableau по умолчанию, согласно которой мера классифицируется как непрерывная, а измерение – как дискретное. Но вы можете преобразовать каждое дискретное (числовое) измерение в непрерывное измерение, а каждую меру – в дискретную меру.
Путаница вызвана настройкой Tableau по умолчанию, согласно которой мера классифицируется как непрерывная, а измерение – как дискретное. Но вы можете преобразовать каждое дискретное (числовое) измерение в непрерывное измерение, а каждую меру – в дискретную меру.
Итак, теперь мы знаем правильное значение цветов и, кроме того, таблетки меры могут быть зеленого и синего цвета, а это означает, что мера может быть непрерывной и дискретной. То же относится и к числовым измерениям.
Непрерывные и дискретные даты
Самый впечатляющий пример – переменная даты. Если вы установите свою дату как дискретную, то создадите заголовки, которые можно сортировать. Если вы переключитесь на непрерывный режим, то создадите ось, которая сортирует даты в хронологическом порядке. (Обратите внимание на цвет таблеток в этом примере!)
Дискретный и непрерывный в Tableau
Что касается прошлой недели, и месяца (MONTH) (Дата заказа) – это измерение в представлении, независимая переменная. На первом графике у нас есть дискретное измерение, сумма прибыли вычисляется для каждого месяца за все годы. Второй график вычисляет сумму прибыли за каждый месяц каждого года для непрерывного измерения. Если вы щелкнете по заголовку внизу первого графика, то сможете просто отформатировать заголовки. На втором графике вы можете отформатировать и отредактировать ось.
На первом графике у нас есть дискретное измерение, сумма прибыли вычисляется для каждого месяца за все годы. Второй график вычисляет сумму прибыли за каждый месяц каждого года для непрерывного измерения. Если вы щелкнете по заголовку внизу первого графика, то сможете просто отформатировать заголовки. На втором графике вы можете отформатировать и отредактировать ось.
Что касается разницы между дискретным и непрерывным, мне очень понравилось такое объяснение на веб-сайте Tableau:
«Непрерывный означает формирование непрерывного целого без перерывов; дискретные средства индивидуально разделены».
Источники:
- Синие и зеленые таблетки – что они означают? от Тимоти Мэннинг
- Основы Tableau: дискретный или непрерывный? от Райана Слипера
- Таблетки в Tableau: непрерывные и дискретные, от Майкла Тредвелла
Надеюсь, что вы получили хорошее представление о «дискретном и непрерывном», поэтому теперь мы можем перейти к «агрегированному и деагрегированному».
Агрегированное и деагрегированное
Руководство по подготовке к экзамену хочет, чтобы мы знали, почему Tableau агрегирует меры. Это хороший вопрос. Многие веб-сайты объясняют, что по умолчанию Tableau агрегирует показатели, но не упоминают почему. К счастью, я нашел обсуждение на форуме сообщества Tableau.
Почему Tableau агрегирует по умолчанию?
Позвольте мне обобщить ответы из ветки для вас. Одним из аргументов такой: меры в большинстве случаев являются более значимыми, когда они являются совокупностью. Лей Чен иллюстрирует это следующим примером:
В чем разница между этими двумя графиками? На первом графике у нас есть сумма продаж и только одна отметка в представлении:
Для второго графика я снял флажок «Aggregate Measures» (Совокупные показатели) в разделе «Analysis» (Анализ)…
… и получить одну оценку за каждую запись в моем источнике данных.
Другой ответ дал Махфудж Хан. Он объяснил, что меры будут агрегатами, потому что они являются зависимыми переменными. Это ссылка на то, что мы узнали на прошлой неделе о мерах и измерениях. В большинстве случаев измерение является независимой переменной и определяет уровень детализации в визуализации. Это также означает, что он устанавливает уровень агрегации.
В нашем первом примере у нас были только продажи, если теперь мы добавим, например, «Segment» (Сегмент) к представлению, то получим три столбца или три отметки, по одной для каждого элемента измерения «Segment» (Сегмент):
Другими словами: больше измерений создает больше детализации и вызывает меньше агрегации. Снова посмотрите наш пример после ввода Категорий и Подкатегорий. Теперь у нас есть 51 оценка в представлении. (Количество меток в представлении рассчитывается с помощью функции size(); вы также можете увидеть эту информацию в левой нижней части окна. )
)
Настройка агрегации по умолчанию
Как уже упоминалось ранее, показатели агрегируют по умолчанию. Функция агрегации по умолчанию в большинстве случаев является функцией суммы, но, конечно, есть и другие возможные агрегации. Вспомните вторую статью из этой серии, в которой я говорил об управлении свойствами данных. Это место, где вы также можете определить функцию агрегирования по умолчанию для каждой меры.
Более того, можно агрегировать измерения. Вы можете выбрать между Min, Max, Count и Count (Distinct). В следующем примере я подсчитываю различное количество клиентов для каждого сегмента, категории и подкатегории.
Собираем все вместе
Подводя итог: вы должны знать, что для ваших полей данных существует множество возможных комбинаций. Ваши меры могут быть …
- …непрерывные и агрегированные
- …дискретные и агрегированные
- …непрерывные и деагрегированные
- …дискретные и деагрегированные
То же самое касается измерений, они также могут быть . ..
..
- …непрерывные и агрегированные
- …дискретные и агрегированные
- …непрерывные и деагрегированные
- …дискретные и деагрегированные
Убедитесь, что вы знаете, какую комбинацию использовать при переносе ваших полей данных в вашу визуализацию.
Подводим итог
Фундаментальные концепции Tableau действительно важны. Я много читал об этом, но для меня все встало на свои места только после просмотра бесплатного обучающего видео с сайта Tableau, где они указали, что…
«То, как Tableau считает, зависит от агрегации данных, поэтому зависит от степени детализации представления».
Основы дискретной математики / Хабр
Привет, хабр. В преддверии старта базового курса «Математика для Data Science» делимся с вами переводом еще одного полезного материала.
Об этой статье
Эта статья содержит лишь малую часть информации по заявленной теме. Рассматривайте ее как вводный курс перед началом всестороннего изучения предмета. Надеюсь, вы найдете в ней полезную информацию. Знание дискретной математики помогает описывать объекты и задачи в информатике, особенно когда дело касается алгоритмов, языков программирования, баз данных и криптографии. В дальнейшем я планирую подробнее раскрыть темы, затронутые в этой статье. Приятного чтения!
ЧТО ТАКОЕ ДИСКРЕТНАЯ МАТЕМАТИКА?
Это область математики, изучающая объекты, которые могут принимать только уникальные отдельные значения.
Мы рассмотрим пять основных разделов в следующем порядке.
Логика
Теория множеств
Отношения
Функции
Комбинаторика
Графы
ЛОГИКА
Что такое логика?
Это наука о корректных рассуждениях. Мы будем использовать приемы идеализации и формализации. Неформальная логика изучает использование аргументов в естественном языке.
Формальная логика анализирует выводы с чисто формальным содержанием. Примерами формальной логики являются символическая логика и силлогистическая логика (о которой писал Аристотель).
Начнем с азов. Рассмотрим следующее высказывание на естественном языке:
«Если я голоден, я ем».
Пусть «голоден» будет посылкой A, а «ем» — следствием B. Попробуем формализовать:
A => B (то есть из A следует B)
NB. Посылка и следствие являются суждениями.
Логические выражения
Для нас важна форма, а НЕ содержание. Значение будет истинным, если оно соответствует форме.
Например, 10 < 4 — ЛОЖЬ, а 10 > 4 — ИСТИНА.
Логические операции
Суждение P — это утверждение, которое может быть как истинным, так и ложным.
Обозначим истинное значение P единицей (1), а ложное значение P нулем (0).
Существует другое суждение; обозначим истинное значение Q единицей (1), а ложное значение Q нулем (0).
Рассмотрим логические операции с суждениями, значение которых истинно. Они могут сами образовывать истинные значения путем выполнения соответствующих операций над истинными значениями.
Отрицание
ИЛИ
И
Эквивалентность
Импликация
Исключающее ИЛИ
Три закона
Теперь введем суждение R — утверждение, которое может быть как истинным, так и ложным.
Обозначим истинное значение R единицей (1), а ложное значение R нулем (0).
Закон ассоциативности
Закон дистрибутивности
Законы де Моргана
Логическая формула
Включает суждения, выражения в скобках и следующие символы:
Квантификаторы
Что такое квантификатор? Квантификатор в естественном языке — это слово, которое используется для обозначения количественных отношений (сколько). Например: все, несколько, много, мало, большинство и нисколько.
ТЕОРИЯ МНОЖЕСТВ
Что такое множество?
Это набор данных. Эти данные называются элементами (множества). Элементы во множестве не дублируются. Важным свойством множества является его неупорядоченность, то есть при изменении порядка следования элементов суть множества не меняется.
Например, если A = {1, 2, 3, 4} и B = {2, 4, 1, 3} и порядок неважен, то A = B
Разобравшись в этом, мы можем дать более точное определение множества — это коллекция различных, строго определенных объектов.
Иногда нам нужно определить бесконечное множество. Проблема очевидна: мы не сможем записать все его элементы. Значит, мы можем определить множество с помощью характерных признаков всех его элементов.
Операции над множествами
Подмножество
Количество элементов
Объединение
Пересечение
Дополнение
ОТНОШЕНИЯ
Логика отношений изучает отношения между математическими объектами. Мы можем установить связь с N элементами (где N — положительное натуральное число).
Бинарное отношение — это отношение между двумя элементами (объектами). Формально мы можем записать любое отношение между x и y так: x ~ y
Например, 4 < 8 или «Я студент по отношению к моему преподавателю».
Свойства бинарных отношений
Числовые множества
ФУНКЦИИ
Функция — это отношение, которое присваивает переменным новые значения. То есть это отношение между множеством А и множеством В.
Свойства
Функциональная композиция
Это точечное использование функции, результатом которого является другая функция.
КОМБИНАТОРИКА
Простыми словами, это наука о счете.
Перестановки
Это упорядочение уникальных объектов, при котором важен порядок следования.
Комбинации
Это упорядочение уникальных объектов, при котором не важен порядок следования.
Блок-схема алгоритма
ГРАФЫ
Что такое граф?
Это коллекция точек, которые называются узлами или вершинами, и линий между этими точками, которые называются ребрами. Ребро соединяет только два узла. Ребро может быть ориентированным, если ему присвоено направление, или неориентированным.
Если вам понравилась эта статья, приглашаю почитать также мой блог:
www.quantq8.com
Успеть на курс по специальной цене
Читать ещё:
Роль математики в машинном обучении
Content Types (Data Mining) | Microsoft Learn
- Статья
- Чтение занимает 6 мин
Applies to: SQL Server 2019 and earlier Analysis Services Azure Analysis Services Power BI Premium
Important
Data mining was deprecated in SQL Server 2017 Analysis Services and now discontinued in SQL Server 2022 Analysis Services. Documentation is not updated for deprecated and discontinued features. To learn more, see Analysis Services backward compatibility.
Documentation is not updated for deprecated and discontinued features. To learn more, see Analysis Services backward compatibility.
In Microsoft SQL Server SQL Server Analysis Services, you can define the both the physical data type for a column in a mining structure, and a logical content type for the column when used in a model,
The data type determines how algorithms process the data in those columns when you create mining models. Defining the data type of a column gives the algorithm information about the type of data in the columns, and how to process the data. Each data type in SQL Server Analysis Services supports one or more content types for data mining.
The content type describes the behavior of the content that the column contains. For example, if the content in a column repeats in a specific interval, such as days of the week, you can specify the content type of that column as cyclical.
Some algorithms require specific data types and specific content types to be able to function correctly. For example, the Microsoft Naive Bayes algorithm cannot use continuous columns as input, and cannot predict continuous values. Some content types, such as Key Sequence, are used only by a specific algorithm. For a list of the algorithms and the content types that each supports, see Data Mining Algorithms (Analysis Services — Data Mining).
For example, the Microsoft Naive Bayes algorithm cannot use continuous columns as input, and cannot predict continuous values. Some content types, such as Key Sequence, are used only by a specific algorithm. For a list of the algorithms and the content types that each supports, see Data Mining Algorithms (Analysis Services — Data Mining).
The following list describes the content types that are used in data mining, and identifies the data types that support each type.
Discrete
Discrete means that the column contains a finite number of values with no continuum between values. For example, a gender column is a typical discrete attribute column, in that the data represents a specific number of categories.
The values in a discrete attribute column cannot imply ordering, even if the values are numeric. Moreover, even if the values used for the discrete column are numeric, fractional values cannot be calculated. Telephone area codes are a good example of discrete data that is numeric.
The Discrete content type is supported by all data mining data types.
Continuous
Continuous means that the column contains values that represent numeric data on a scale that allows interim values. Unlike a discrete column, which represents finite, countable data, a continuous column represents scalable measurements, and it is possible for the data to contain an infinite number of fractional values. A column of temperatures is an example of a continuous attribute column.
When a column contains continuous numeric data, and you know how the data should be distributed, you can potentially improve the accuracy of the analysis by specifying the expected distribution of values. You specify the column distribution at the level of the mining structure. Therefore, the setting applies to all models that are based on the structure, For more information, see Column Distributions (Data Mining).
The Continuous content type is supported by the following data types: Date, Double, and Long.
Discretized
Discretization is the process of putting values of a continuous set of data into buckets so that there are a limited number of possible values. You can discretize only numeric data.
Thus, the discretized content type indicates that the column contains values that represent groups, or buckets, of values that are derived from a continuous column. The buckets are treated as ordered and discrete values.
You can discretize your data manually, to ensure that you get the buckets you want, or you can use the discretization methods provided in SQL Server Analysis Services. Some algorithms perform discretization automatically. For more information, see Change the Discretization of a Column in a Mining Model.
The Discretized content type is supported by the following data types: Date, Double, Long, and Text.
Key
The key content type means that the column uniquely identifies a row. In a case table, typically the key column is a numeric or text identifier. You set the content type to key to indicate that the column should not be used for analysis, only for tracking records.
In a case table, typically the key column is a numeric or text identifier. You set the content type to key to indicate that the column should not be used for analysis, only for tracking records.
Nested tables also have keys, but the usage of the nested table key is a little different. You set the content type to key in a nested table if the column is the attribute that you want to analyze. The values in the nested table key must be unique for each case but there can be duplicates across the entire set of cases.
For example, if you are analyzing the products that customers purchase, you would set content type to key for the CustomerID column in the case table, and set content type to key again for the PurchasedProducts column in the nested table.
Note
Nested tables are available only if you use data from an external data source that has been defined as an Analysis services data source view.
This content type is supported by the following data types: Date, Double, Long, and Text.
Key Sequence
The key sequence content type can only be used in sequence clustering models. When you set content type to key sequence, it indicates that the column contains values that represent a sequence of events. The values are ordered, but do not have to be an equal distance apart.
This content type is supported by the following data types: Double, Long, Text, and Date.
Key Time
The key time content type can only be used in time series models. When you set content type to key time, it indicates that the values are ordered and represent a time scale.
This content type is supported by the following data types: Double, Long, and Date.
Table
The table content type indicates that the column contains another data table, with one or more columns and one or more rows. For any particular row in the case table, this column can contain multiple values, all related to the parent case record. For example, if the main case table contains a listing of customers, you could have several columns that contain nested tables, such as a ProductsPurchased column, where the nested table lists products bought by this customer in the past, and a Hobbies column that lists the interests of the customer.
For any particular row in the case table, this column can contain multiple values, all related to the parent case record. For example, if the main case table contains a listing of customers, you could have several columns that contain nested tables, such as a ProductsPurchased column, where the nested table lists products bought by this customer in the past, and a Hobbies column that lists the interests of the customer.
The data type of this column is always Table.
Cyclical
The cyclical content type means that the column contains values that represent a cyclical ordered set. For example, the numbered days of the week is a cyclical ordered set, because day number one follows day number seven.
Cyclical columns are considered both ordered and discrete in terms of content type.
This content type is supported by all the data mining data types in SQL Server Analysis Services. However, most algorithms treat cyclical values as discrete values and do not perform special processing.
Ordered
The Ordered content type also indicates that the column contains values that define a sequence or order. However, in this content type the values used for ordering do not imply any distance or magnitude relationship between values in the set. For example, if an ordered attribute column contains information about skill levels in rank order from one to five, there is no implied information in the distance between skill levels; a skill level of five is not necessarily five times better than a skill level of one.
Ordered attribute columns are considered to be discrete in terms of content type.
This content type is supported by all the data mining data types in SQL Server Analysis Services. However, however, most algorithms treat ordered values as discrete values and do not perform special processing.
Classified
In addition to the preceding content types that are in common use with all models, for some data types you can use classified columns to define content types. For more information about classified columns, see Classified Columns (Data Mining).
For more information about classified columns, see Classified Columns (Data Mining).
See Also
Content Types (DMX)
Data Types (Data Mining)
Data Types (DMX)
Change the Properties of a Mining Structure
Mining Structure Columns
Распределение дискретных вероятностей с Python
Автор оригинала: Robin Andrews.
В этой статье мы собираемся исследовать вероятность с Python с особым акцентом на Дискретные случайные переменные Отказ
Дискретные значения – это те, которые могут быть Считается в отличие от Измеряется Отказ Это фундаментальное различие в математике. То, что не все понимают о измерениях, состоит в том, что они никогда не могут быть полностью точными. Например, если я скажу вам, что рост человека – 1,77 м Эта стоимость округла до двух десятичных знаков. Если бы я был измерен точнее, высота может оказаться 1.77132M до пяти десятичных знаков. Это вполне точнее, но в теории точность может быть улучшена AD Infinitum.
Это не так с дискретных значений. Они всегда представляют точное число. Это означает, что в некотором смысле их легче работать.
Дискретные случайные переменные
А дискретная случайная вариабельная является переменным, которая принимает только дискретные значения, определяемые результатом какого-либо случайного явления. Дискретная случайная переменная часто обозначается заглавной буквой (например, x , y , z ). Вероятность каждого значения дискретной случайной переменной происходит между 0 и 1 и сумма всех вероятностей равна 1 Отказ
Некоторые примеры дискретных случайных величин являются:
- Итоги переворачивания монеты
- Результат прокатки
- Количество пассажиров домохозяйства
- Количество студентов в классе
- Отмечает на экзамене
- Количество претендентов на работу.
Распределение дискретных вероятностей
Случайная величина может принимать разные значения в разное время. Во многих ситуациях некоторые значения будут встречаться чаще, чем другие. Описание вероятности каждого возможного значения, что дискретная случайная величина может принять, называется Дискретное распределение вероятностей. Техническое название для сопоставления функций определенное значение дискретной случайной переменной к ней связанной вероятности является Функция массы вероятности (PMF) Отказ
Во многих ситуациях некоторые значения будут встречаться чаще, чем другие. Описание вероятности каждого возможного значения, что дискретная случайная величина может принять, называется Дискретное распределение вероятностей. Техническое название для сопоставления функций определенное значение дискретной случайной переменной к ней связанной вероятности является Функция массы вероятности (PMF) Отказ
Смущено всей терминологией? Не волнуйся. Теперь мы посмотрим на некоторые примеры и используем Python, чтобы помочь нам понять дискретные распределения вероятностей.
Листинг кода Python для распределения дискретных вероятностей
Проверьте этот пример. Вам может потребоваться установить некоторые модули, если вы еще этого не сделали. Если вы не знакомы с Numpy, Matplotlib и Meanborn, позвольте мне представить вас …
import numpy as np import matplotlib.pyplot as plt import seaborn as sns NUM_ROLLS = 1000 values = [1, 2, 3, 4, 5, 6] sample = np.random.choice(values, NUM_ROLLS) # Numpy arrays containing counts for each side side, count = np.unique(sample, return_counts=True) probs = count / len(sample) # Plot the results sns.barplot(side, probs) plt.title( f"Discrete Probability Distribution for Fair 6-Sided Die ({NUM_ROLLS} rolls)") plt.ylabel("Probability") plt.xlabel("Outcome") plt.show()
В этом примере есть подразумеваемая случайная переменная (давайте назовем ее x ), что может принимать значения 1, 2, 3, 4, 5 или 6 Отказ Образец Num_roll Размер генерируется и результаты построены с использованием морской и Матплотлиб Отказ
Код использует numpy создать образец, а морской Чтобы легко создать визуально чистый и приятный барный участок.
Имитация смещенного умирает с Python
Код выше может быть изменен чуть незначительно для получения и отображения образца для взвешенного (предвзятого). Здесь
Здесь 6 Сторона имеет вероятность 0,5 в то время как для всех остальных сторон это 0,1 Отказ
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
NUM_ROLLS = 1000
values = [1, 2, 3, 4, 5, 6]
probs = [0.1, 0.1, 0.1, 0.1, 0.1, 0.5]
# Draw a weighted sample
sample = np.random.choice(values, NUM_ROLLS, p=probs)
# Numpy arrays containing counts for each side
side, count = np.unique(sample, return_counts=True)
probs = count / len(sample)
# Plot the results
sns.barplot(side, probs)
plt.title(
f"Discrete Probability Distribution for Biased 6-Sided Die ({NUM_ROLLS} rolls)")
plt.ylabel("Probability")
plt. xlabel("Outcome")
plt.show()
xlabel("Outcome")
plt.show()
Дискретное нормальное распределение размеров обуви с Python
Наконец, давайте посмотрим, как мы можем создать нормальное распределение и построить его с помощью Python, Numpy и Meanborn.
Позвольте сказать, что мы изучаем женскую обувь в конкретном населении имеют средний размер 5 со стандартным отклонением 1 Отказ Мы можем использовать тот же код, что и прежде чем построить распределение, за исключением того, что мы создаем наш образец со следующими двумя строками вместо образец.random.Choice (значения, num_rolls,) :
sample = np.random.normal(loc=5, scale=1, size=NUM_ROLLS) sample = np.round(sample).astype(int) # Convert to integers
Вот результат – сдержанное нормальное распределение для женских размеров обуви:
В этой статье мы посмотрели, как создавать и построить дискретные распределения вероятностей с Python. Я надеюсь, что вы нашли это интересно и полезно.
Счастливые вычисления!
Дискретные и непрерывные данные: в чем разница? | Блог
Иногда мы создаем данные, даже не осознавая этого — отправляя текстовое сообщение, публикуя фото в Instagram или просто просматривая различные веб-сайты. Для сравнения, в 2020 году люди генерировали 2,5 квинтиллиона данных каждую секунду. Как и многие способы создания данных, существует множество различных типов данных. Есть структурированные и неструктурированные данные. Затем идут качественные и количественные данные. И, наконец, существуют дискретные и непрерывные данные, которые являются основой для каждого человека, работающего с бизнесом.
Содержание
- Что такое числовые данные?
- Основы дискретных данных
- Непрерывные данные — все дело в точности
- Дискретные и непрерывные данные — сравнение
- Важность дискретных и непрерывных данных
- Как собирать и агрегировать числовые данные
- Нижняя строка
Изучение различий между дискретными и непрерывными данными и вариантов их использования может показаться непосильным. Тем не менее, понимание, основанное на данных, играет важную роль в успехе бизнеса. Профессионалы, которые разбираются в этих уникальных типах данных, могут определить возможности, в которых данные могут пригодиться. Специалисты по маркетингу могут использовать эту информацию для улучшения своих стратегий и оптимизации рекламных кампаний.
Тем не менее, понимание, основанное на данных, играет важную роль в успехе бизнеса. Профессионалы, которые разбираются в этих уникальных типах данных, могут определить возможности, в которых данные могут пригодиться. Специалисты по маркетингу могут использовать эту информацию для улучшения своих стратегий и оптимизации рекламных кампаний.
Что такое числовые данные?
Числовые данные, также известные как количественные, представляют собой тип данных, выражаемый числами, а не естественным языком. Числовые данные отличаются от других типов данных числовых форм своей способностью выполнять арифметические операции с этими числами.
Количественные данные делятся на два типа данных: дискретные, которые представляют собой исчисляемые элементы. И непрерывные данные, которые описывают измерение данных. Непрерывные числовые данные далее подразделяются на интервальные и относительные данные, известные для измерения определенных элементов.
Основы дискретных данных
Дискретные данные — это счет, который включает целые числа — возможно только ограниченное количество значений. Этот тип данных не может быть разделен на разные части. Дискретные данные включают дискретные переменные, которые являются конечными, числовыми, счетными и неотрицательными целыми числами. Во многих случаях перед дискретными данными может стоять префикс «количество». Например:
Этот тип данных не может быть разделен на разные части. Дискретные данные включают дискретные переменные, которые являются конечными, числовыми, счетными и неотрицательными целыми числами. Во многих случаях перед дискретными данными может стоять префикс «количество». Например:
- Количество учащихся, посетивших занятие;
- Количество клиентов, купивших разные товары;
- Количество продуктов, которые люди покупают каждый день;
Этот тип данных в основном используется для простого статистического анализа, поскольку его легко суммировать и вычислять. В большинстве случаев дискретные данные отображаются в виде столбчатых диаграмм, диаграмм «стебли и листья» и круговых диаграмм.
Непрерывные данные — все дело в точности
Непрерывные данные считаются полной противоположностью дискретных данных. Это тип числовых данных, который относится к неопределенному количеству возможных измерений между двумя предполагаемыми точками.
Числа непрерывных данных не всегда являются чистыми и целыми числами, поскольку они обычно собираются из очень точных измерений. Измерение конкретного субъекта позволяет создать определенный диапазон для сбора большего количества данных.
Переменные в непрерывных наборах данных часто содержат десятичные точки, при этом число растягивается настолько, насколько это возможно. Как правило, она меняется со временем. Он может иметь совершенно разные значения в разные промежутки времени, которые не всегда могут быть целыми числами. Вот несколько примеров:
- Погодная температура;
- Скорость ветра;
- Вес детей;
Непрерывные данные можно измерять с помощью специальных инструментов и отображать в виде линейных графиков, наклонов и гистограмм.
Дискретные и непрерывные данные — сравнение
Оба типа данных важны для статистического анализа. Тем не менее, прежде чем делать какие-либо выводы или принимать решения, необходимо отметить некоторые основные различия.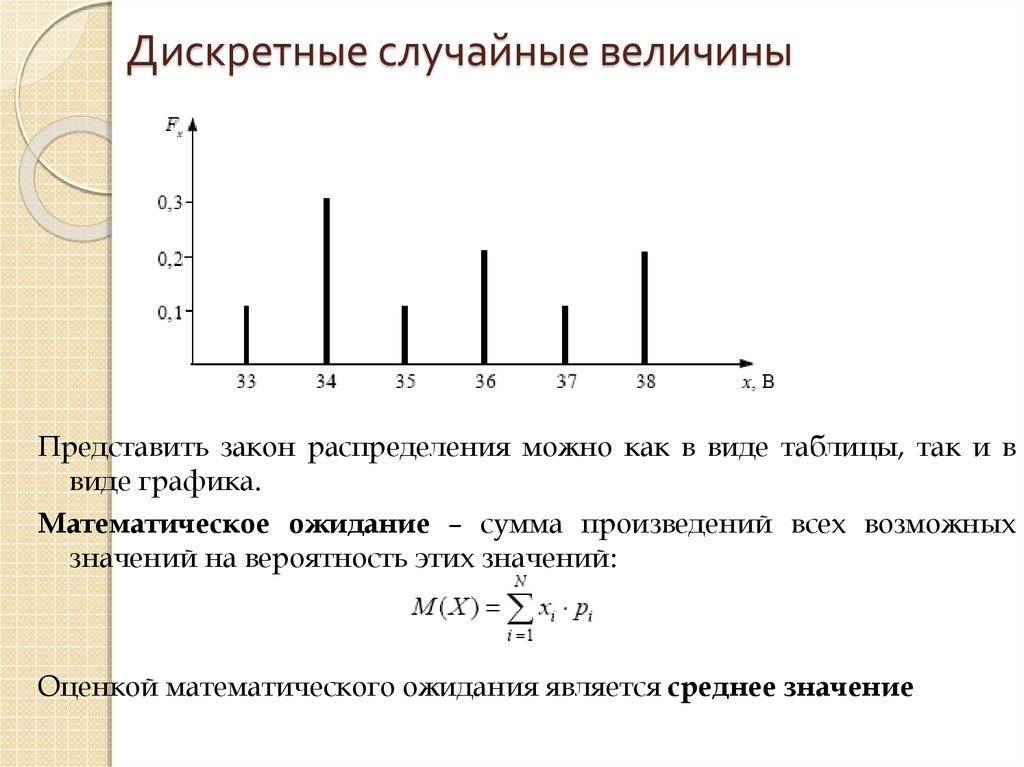 Основные отличия:
Основные отличия:
- Дискретные данные — это тип данных, между значениями которых есть пустые промежутки. Непрерывные данные — это данные, которые попадают в постоянную последовательность.
- Дискретные данные счетны, а непрерывные — измеримы.
- Для точного представления дискретных данных используется гистограмма. Гистограммы или линейные графики используются для графического представления непрерывных данных. Диаграмма дискретной функции показывает отдельную точку, которая остается несвязанной. В то время как на графике непрерывной функции точки соединяются непрерывной линией.
- Дискретные данные содержат различные или отдельные значения. Непрерывные данные включают любое значение в пределах предпочтительного диапазона.
Важность дискретных и непрерывных данных
Как дискретные, так и непрерывные данные полезны для всех видов решений, основанных на данных. Ценные исследования и идеи получаются путем объединения обоих наборов данных. Вот несколько примеров использования дискретных и непрерывных данных:
Ценные исследования и идеи получаются путем объединения обоих наборов данных. Вот несколько примеров использования дискретных и непрерывных данных:
- Маркетинг и реклама. Прежде чем участвовать в какой-либо маркетинговой или рекламной кампании, компаниям необходимо проанализировать внутренние и внешние факторы, которые могут повлиять на маркетинговые кампании. В большинстве случаев специалисты по маркетингу используют SWOT-анализ. SWOT-анализ — это совокупность сильных и слабых сторон бизнеса, возможностей и угроз. Основная цель этого анализа — помочь компаниям полностью осознать все факторы, связанные с принятием решений на основе данных.
- Исследования. Числовые типы данных популярны среди исследователей из-за их совместимости с большинством статистических методов. Дискретные и непрерывные данные помогают облегчить процесс исследования.
- Популяционный анализ. Используя анализ тенденций, исследователи собирают данные о различных показателях в стране или регионе за определенный период и предсказывают будущее население.
 Это может включать рождаемость, смертность, популярность языков и так далее. Прогнозирование демографии страны играет жизненно важную роль в экономике.
Это может включать рождаемость, смертность, популярность языков и так далее. Прогнозирование демографии страны играет жизненно важную роль в экономике. - Разработка продукта. Исследователи продуктов используют общий недублированный анализ охвата и частоты (TURF), чтобы выяснить, будет ли новый продукт или услуга иметь спрос и будет ли он хорошо воспринят на целевом рынке на этапе разработки продукта.
Однако реализация дискретных или непрерывных данных может не всегда давать точные результаты, поскольку существуют проблемы, связанные только с анализом числовых данных. Например:
- Дискретные или непрерывные исследования данных могут быть ограничены в поиске статистических взаимосвязей. Это может привести к тому, что исследователи упустят ценные сведения. Сосредоточившись исключительно на цифрах, аналитик рискует упустить общую картину, которая может принести пользу бизнесу.
- При проведении исследований аналитикам необходимо разработать гипотезу и настроить модель сбора и анализа данных.
 Любые ошибки в настройке, предвзятость со стороны аналитиков или ошибки исполнения могут исказить результаты. Иногда даже выдвижение гипотезы может быть субъективным, особенно если есть конкретный вопрос, на который нужно ответить и доказать не только числовыми данными.
Любые ошибки в настройке, предвзятость со стороны аналитиков или ошибки исполнения могут исказить результаты. Иногда даже выдвижение гипотезы может быть субъективным, особенно если есть конкретный вопрос, на который нужно ответить и доказать не только числовыми данными.
Как собирать и агрегировать числовые данные
Какими бы сложными ни были дискретные и непрерывные данные, они наиболее полезны в статистическом анализе. Числовые данные позволяют компаниям принимать решения на основе данных и искать информацию, которая помогает ускорить рост бизнеса. Информация, полученная из дискретных и непрерывных данных, также позволяет маркетологам измерять эффективность своих маркетинговых усилий и внедрять более эффективные стратегии в будущем.
Whatagraph может пригодиться и облегчить трудоемкий процесс сбора и агрегирования данных. Инструмент отчетности автоматически собирает данные из разных источников и представляет их в визуальном отчете. Собранные данные могут отображаться в различных диаграммах и графиках, включая круговые диаграммы для дискретных данных и линейные графики для непрерывных данных.
Итог
Отсюда совершенно ясно, что два типа данных различаются в пояснениях и примерах. Дискретные данные представляют собой определенное количество изолированных значений. Напротив, непрерывные данные показывают любое значение из заданного диапазона.
Понимание числовых данных и различий между дискретными и непрерывными данными может быть затруднено на начальном этапе. Однако после обработки данных специалисты по маркетингу смогут подкрепить свои выводы об эффективности фактическими и точными данными.
В чем разница между дискретными данными и непрерывными данными?
Спросил
Изменено 2 года, 7 месяцев назад
Просмотрено 1,1 м раз
$\begingroup$
В чем разница между дискретными данными и непрерывными данными?
- непрерывные данные
- дискретные данные
$\endgroup$
6
$\begingroup$
Дискретные данные могут принимать только определенные значения. Потенциально может быть бесконечное количество этих значений, но каждое из них отличается, и между ними нет серой области. Дискретные данные могут быть числовыми — например, количество яблок — но также могут быть и категориальными — например, красное или синее, мужское или женское, хорошее или плохое.
Потенциально может быть бесконечное количество этих значений, но каждое из них отличается, и между ними нет серой области. Дискретные данные могут быть числовыми — например, количество яблок — но также могут быть и категориальными — например, красное или синее, мужское или женское, хорошее или плохое.
Непрерывные данные не ограничиваются определенными отдельными значениями, но могут занимать любое значение в непрерывном диапазоне. Между любыми двумя непрерывными значениями данных может быть бесконечное количество других. Непрерывные данные всегда по существу являются числовыми.
Иногда имеет смысл рассматривать дискретные данные как непрерывные и наоборот :
-
Например, что-то вроде высота является непрерывным, но часто мы на самом деле не слишком заботьтесь о крошечных различиях и вместо этого группируйте высоты в число дискретных бинов — т.е. только измерение сантиметры —.
-
И наоборот, если мы подсчитываем большое количество какой-то дискретной сущности
— т. е. рисовых зерен, термитов или пенни в экономике — мы можем не думать о 2 000 006 и 2 000 008 как о принципиально разных значениях, а вместо этого как близкие точки на приблизительном континууме
е. рисовых зерен, термитов или пенни в экономике — мы можем не думать о 2 000 006 и 2 000 008 как о принципиально разных значениях, а вместо этого как близкие точки на приблизительном континууме
.
Иногда может быть полезно, чтобы рассматривал числовые данные как категориальные , например: недостаточный вес, нормальный вес, ожирение. Обычно это просто еще один вид биннинга.
Редко имеет смысл рассматривать категориальные данные как непрерывные.
$\endgroup$
5
$\begingroup$
Данные всегда дискретны. Учитывая выборку из n значений переменной, максимальное количество различных значений, которые может принимать переменная, равно n . Смотрите эту цитату
Все фактические выборочные пространства дискретны, и все наблюдаемые случайные переменные имеют дискретное распределение.
Непрерывное распределение математическая конструкция, пригодная для математической обработки, но практически не наблюдается. Э.Дж.Г. Питман (1979, с. 1).
Обычно предполагается, что данные о переменной берутся из случайной величины. Случайная величина является непрерывной в диапазоне, если существует бесконечное число возможных значений, которые переменная может принимать между любыми двумя разными точками в диапазоне. Например, рост, вес и время обычно считаются непрерывными. Конечно, любое измерение этих переменных будет конечно точным и в некоторых случаях смысл дискретный.
Полезно различать упорядоченные (т. е. порядковые), неупорядоченные (т. е. номинальные),
и двоичные дискретные переменные.
Некоторые вводные учебники путают непрерывную переменную с числовой переменной. Например, счет в компьютерной игре является дискретным, хотя и числовым.
Некоторые вводные учебники путают переменную отношения с непрерывными переменными. Переменная count — это переменная отношения, но она не является непрерывной.
Переменная count — это переменная отношения, но она не является непрерывной.
На практике переменная часто считается непрерывной, если она может принимать достаточно большое количество различных значений.
Ссылки
- Pitman, EJG 1979. Некоторые основы теории статистического вывода. Лондон: Чепмен и Холл. Примечание: Я нашел эту цитату во введении к главе 2 книги Мюррея Эйткина Статистический вывод: комплексный байесовский подход/подход правдоподобия
$\endgroup$
3
$\begingroup$
Температуры непрерывны. Это может быть 23 градуса, 23,1 градуса, 23,100004 градуса.
Пол дискретен. Вы можете быть только мужчиной или женщиной (во всяком случае, в классическом мышлении). Что-то, что вы можете представить целым числом, например 1, 2 и т. д.
Разница важна, поскольку многие статистические алгоритмы и алгоритмы интеллектуального анализа данных могут работать с одним типом, но не с другим. Например, в обычной регрессии Y должен быть непрерывным. В логистической регрессии Y является дискретным.
Например, в обычной регрессии Y должен быть непрерывным. В логистической регрессии Y является дискретным.
$\endgroup$
1
$\begingroup$
Дискретные данные могут принимать только определенные значения.
Пример: количество учеников в классе (не может быть половина ученика).
Непрерывные данные — это данные, которые могут принимать любое значение (в пределах диапазона)
Примеры:
- Рост человека: может быть любым значением (в пределах диапазона человеческого роста), а не только определенным фиксированным ростом,
- Время в гонке: его можно измерить даже до долей секунды,
- Вес собаки, 9 г.0008
- Длина листа,
- Вес человека,
$\endgroup$
2
$\begingroup$
В случае базы данных мы всегда будем хранить данные в дискретном виде, даже если природа данных непрерывна. Почему я должен подчеркивать природу данных? Мы должны взять распределение данных, которое могло бы помочь нам проанализировать данные. ЕСЛИ природа данных непрерывна, я предлагаю вам использовать их путем непрерывного анализа.
Почему я должен подчеркивать природу данных? Мы должны взять распределение данных, которое могло бы помочь нам проанализировать данные. ЕСЛИ природа данных непрерывна, я предлагаю вам использовать их путем непрерывного анализа.
Возьмем пример непрерывного и дискретного: MP3. Даже тип «звука» аналогичен, если сохранен в цифровом формате. Мы всегда должны анализировать это по аналогии.
$\endgroup$
$\begingroup$
С одной стороны, с практической точки зрения я согласен с ответом Джероми Энглима. В конце концов, большую часть времени мы имеем дело с дискретными переменными — хотя с теоретической точки зрения они непрерывны — и это оказывает реальное влияние, например, на классификацию. Вспомните статью Стробла, в которой указывалось, что Random Forests предвзято относятся к переменным с несколькими точками отсечения (более высокая точность, но потенциально схожая природа). По моему личному опыту, вероятностные нейронные сети могут давать смещение, когда переменные представляют разную точность, если только они не одного типа (т. е. непрерывные). С другой стороны, с теоретической точки зрения классическая классификация (например, непрерывная, дискретная, номинальная и т. д.) ИМХО верна. В соответствии с этим я думаю, что исходное название статьи Куинлана, описывающей алгоритм M5, который является «регрессором», является отличным выбором. Таким образом, определение и последствия непрерывного или дискретного измерения актуальны в зависимости от «окружающей среды».
е. непрерывные). С другой стороны, с теоретической точки зрения классическая классификация (например, непрерывная, дискретная, номинальная и т. д.) ИМХО верна. В соответствии с этим я думаю, что исходное название статьи Куинлана, описывающей алгоритм M5, который является «регрессором», является отличным выбором. Таким образом, определение и последствия непрерывного или дискретного измерения актуальны в зависимости от «окружающей среды».
Ссылки:
Куинлан Дж. Р. (1992). Обучение с непрерывными классами. В: 5-я Австралийская совместная конференция по ИИ. Сидней (Австралия), 343–348.
Стробл К., Булестейкс А.-Л., Зейлейс А. и Хотхорн Т. (2007). Систематическая ошибка в показателях важности переменных случайного леса: иллюстрации, источники и решение. BMC Bioinformatics, 8, 25. doi: 10.1186/1471-2105-8-25
$\endgroup$
$\begingroup$
Дискретные данные принимают определенные значения, в то время как непрерывные данные не ограничиваются отдельными значениями.
Дискретные данные различны, и между ними нет серой области, в то время как непрерывные данные занимают любое значение, превышающее значение непрерывных данных.
$\endgroup$
$\begingroup$
Дискретные данные Они могут принимать определенные значения. Они числовые.
$\endgroup$
1
$\begingroup$
Дискретные данные могут принимать только целочисленные значения, тогда как непрерывные данные могут принимать любые значения. Например, количество больных раком, ежегодно лечащихся в больнице, дискретно, а ваш вес непрерывен. Некоторые данные являются непрерывными, но измеряются дискретно, например. ваш возраст. Обычно ваш возраст указывается, скажем, 31 год.
$\endgroup$
1
$\begingroup$
Дискретные данные конкретно говорят о конечных значениях, а непрерывные данные говорят о бесконечных значениях.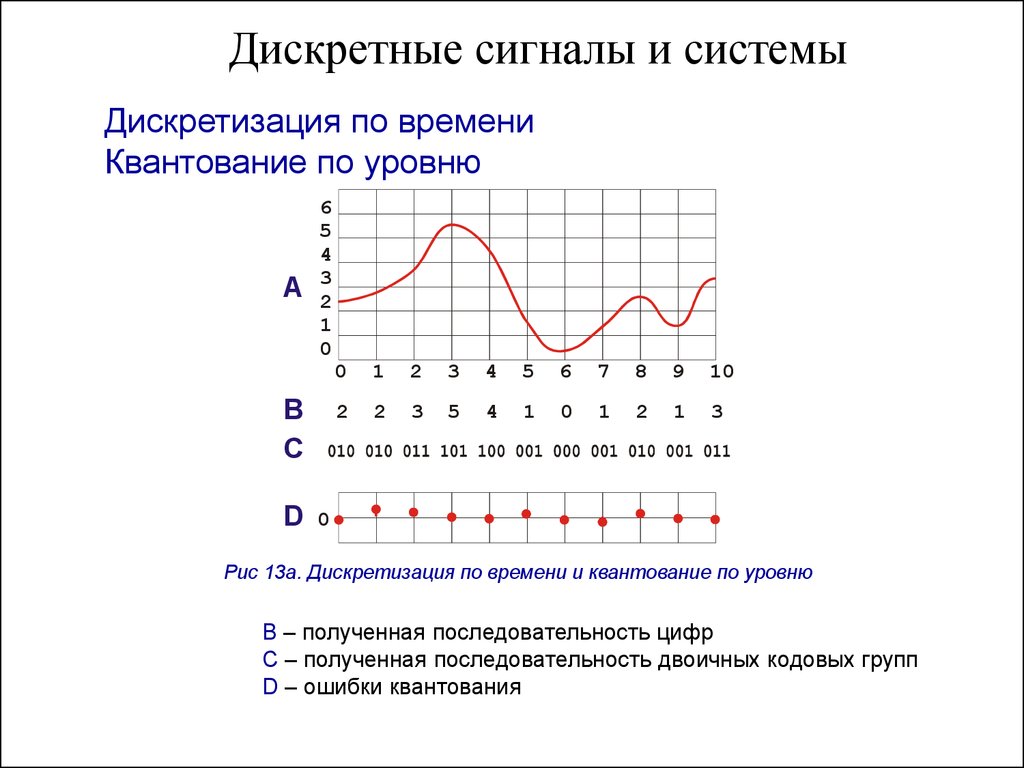 ….
….
$\endgroup$
1
Дискретные и непрерывные данные – определения, примеры, вопросы и ответы
В целях анализа данные представлены в виде фактов и цифр, собранных вместе. Он подразделяется на две широкие категории: качественные данные и количественные данные. Качественные данные невозможно измерить с точки зрения чисел, и они подразделяются на номинальные и порядковые данные. С другой стороны, количественные данные содержат числовые значения и используют область действия. Далее они подразделяются на дискретные данные и непрерывные данные.
Что такое дискретные данные?
Данные, которые могут принимать только определенные значения, являются дискретными данными. Эти значения не обязательно должны быть полными числами, но они являются фиксированными значениями. Он содержит только конечные значения, подразделение которых невозможно. Он включает только те значения, которые являются отдельными и могут быть подсчитаны только целыми числами или целыми числами, что означает, что данные не могут быть разбиты на дроби или десятичные дроби.
Он включает только те значения, которые являются отдельными и могут быть подсчитаны только целыми числами или целыми числами, что означает, что данные не могут быть разбиты на дроби или десятичные дроби.
Примеры дискретных данных: количество учеников в классе, количество конфет в пакете, количество струн на гитаре, количество рыб в аквариуме и т. д.
Что такое непрерывные данные?
Непрерывные данные — это данные, которые могут иметь любое значение. Со временем некоторые непрерывные данные могут измениться. Он может принимать любое числовое значение в потенциальном диапазоне значений конечного или бесконечного. Непрерывные данные могут быть разбиты на дроби и десятичные знаки, т. е. по точности измерения могут быть значительно подразделены на более мелкие участки.
Непрерывные данные Примеры: Измерение роста и веса учащегося, Ежедневное измерение температуры в помещении, Ежедневное измерение скорости ветра и т. д.
Дискретные и непрерывные примеры
Высота непрерывна, но иногда мы не слишком беспокоимся о незначительных вариациях и высотах клюшки в виде набора дискретных данных.
С другой стороны, если мы посчитаем большое количество любого дискретного объекта. Мы можем предпочесть не думать о 10,00,100 и 10,00,102 как о принципиально разных значениях, а о ближайших точках на приблизительном континууме.
Разница между непрерывными и дискретными данными
| Дискретные данные | Непрерывные данные |
| Тип данных со свободными пробелами между значениями — это дискретные данные. | Непрерывная информация — это информация, которая попадает в непрерывный ряд. |
| Дискретные данные счетны. | Непрерывные данные поддаются измерению |
| В дискретных данных имеются различные значения. | Каждое значение в диапазоне включается в непрерывные данные. |
| Гистограмма используется для графического представления дискретных данных. | Гистограмма используется для графического представления непрерывных данных. |
| Разгруппированное частотное распределение дискретных данных выполняется по одному значению | Групповое распределение частот табулирования непрерывных данных выполняется по группе значений. |
| Точки на графике дискретной функции остаются несвязанными. | Точки связаны непрерывной линией. |

Вопросы по дискретным данным Непрерывные данные
Вопрос: Классифицируйте следующее как дискретные и непрерывные данные
-
Утки в пруду.
-
Рост учащегося от 5 до 15 лет.
-
Количество животных в зоопарке.
-
Результат броска игральной кости.
-
Количество книг в стеллаже.
Ответ: Утки в пруду — это дискретные данные, потому что количество уток — конечное число.
-
Рост учащегося в возрасте от 5 до 15 лет представляет собой непрерывные данные, поскольку рост постоянно меняется в возрасте от 5 до 15 лет, что не является постоянным в течение 10 лет.
-
Количество животных в зоопарке является постоянными данными, поскольку количество животных ежегодно меняется в зависимости от размножения новых животных или прибытия новых животных.

-
Результатом броска кубика является 1, 2, 3, 4, 5, 6, 7 и 8. Следовательно, это дискретные данные.
-
Количество книг на полке — конечное счетное число. Следовательно, это дискретные данные.
-
Количество книг на полке — конечное счетное число. Следовательно, это дискретные данные.
Советы и рекомендации по изучению дискретных и непрерывных данных
Статистика — довольно сложный предмет, но для тех, кто знает, как использовать свой разум, это лучший предмет для них, поскольку он требует больше практических знаний и концептуального обучения. И именно по этой причине большинство студентов находят этот предмет интересным.
Известно, что в сегодняшние переменчивые времена карьера в этой области предоставляет одни из самых востребованных профессиональных возможностей. Однако студенты должны понимать, что для них важно осознавать свои интересы и, исходя из этого, выбирать наилучший карьерный путь. Статистика включает в себя организацию, анализ, интерпретацию и представление данных.
Однако студенты должны понимать, что для них важно осознавать свои интересы и, исходя из этого, выбирать наилучший карьерный путь. Статистика включает в себя организацию, анализ, интерпретацию и представление данных.
Некоторым учащимся это может показаться трудным, так как требует логического мышления и математики, но это отличный вариант для тех, кто любит решать и направлять свои мысли на логику.
Вот несколько шагов, чтобы хорошо подготовиться к экзамену, в рамках курса которого есть статистика.
Давайте разберемся с ними.
Было бы здорово, если бы у вас уже было немного знаний о курсе, прежде чем выбрать его. Например, в случае со статистикой алгебра — хороший вариант для изучения перед началом курса статистики. Это поможет вам сэкономить время позже, поскольку у вас уже есть некоторые знания об алгебре. Многие другие курсы доступны онлайн, чтобы овладеть базовыми знаниями, которые могут помочь вам позже. Другой пример — научиться пользоваться калькуляторами. Существуют специальные калькуляторы для различных экзаменов по статистике, и было бы здорово иметь хорошие знания об их использовании и реализации.
Существуют специальные калькуляторы для различных экзаменов по статистике, и было бы здорово иметь хорошие знания об их использовании и реализации.
Больше работайте над основами, так как они формируют основу для многих других концепций. Как только вы поймете основную концепцию, вы сможете легко понять дополнительные концепции. Превосходство ваших базовых знаний по предмету способствует концептуальному обучению, и, следовательно, вы также можете легко ознакомиться с новыми концепциями.
Все мы знаем, что время очень важно, оно никого не ждет. Так обстоит дело и со статистикой. Вы должны знать, как управлять своим временем и использовать его наилучшим образом. Прокрастинация — не последний вариант, если вы готовитесь к экзамену по статистике. Вы должны быть посвящены. Составление расписания или совместное обучение со сверстниками может помочь вам сосредоточиться и оставаться активным.
Всякий раз, когда вы сталкиваетесь с какой-либо проблемой, лучшим решением является консультация с заинтересованным учителем, вы никогда не должны стесняться спрашивать сомнения.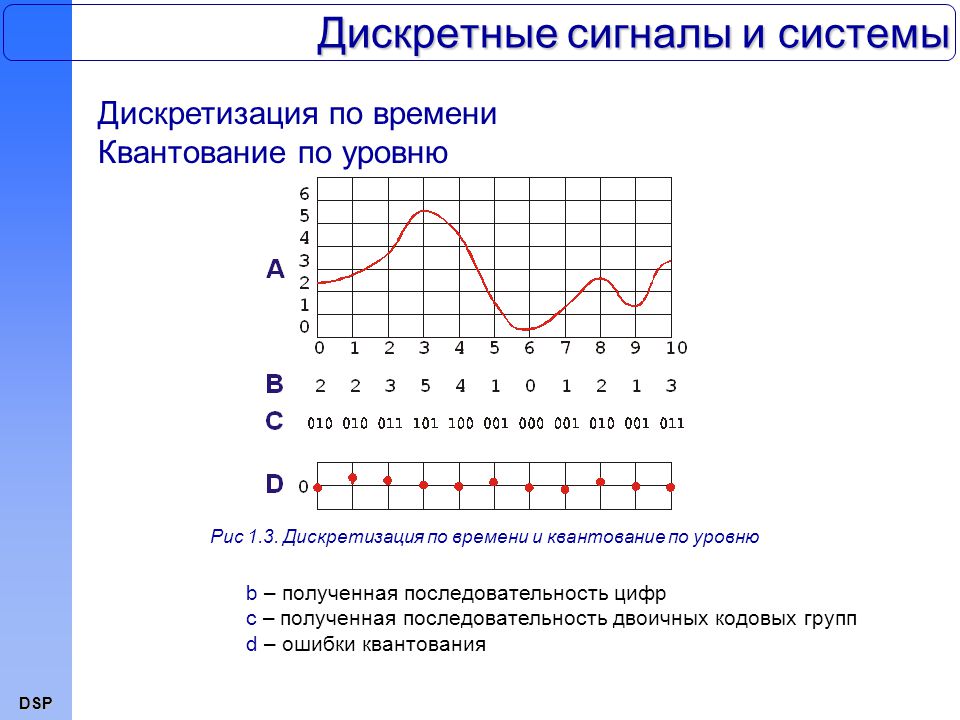 Если вы чувствуете, что ваши сомнения глупы, и вы пропускаете их, а не задаете, это неправильный подход. Вы должны задавать сомнения там, а затем очищать их, анализировать и работать над ними.
Если вы чувствуете, что ваши сомнения глупы, и вы пропускаете их, а не задаете, это неправильный подход. Вы должны задавать сомнения там, а затем очищать их, анализировать и работать над ними.
Это нормально, если вы волнуетесь перед экзаменом, особенно когда речь идет о статистике. Просто знайте, что вы готовились и много работали для этого. Значит, и у вас будет результат! Результаты — это результат наших усилий, и если вы считаете, что приложили все усилия, то наверняка сможете получить хорошие оценки. Понятно, что это, должно быть, заставляет вас нервничать прямо сейчас, но ваши эмоции действительны! Все, что вы можете сделать прямо сейчас, это просто сделать глубокий вдох и поверить в себя! Если вы чувствуете усталость в данный момент, даже это тоже нормально. Выспитесь, это важно. Вы не можете ожидать, что ваш мозг будет хорошо работать с сотнями мыслей, это только создаст беспорядок. Лишение сна бесполезно, вместо этого вы должны вздремнуть, чтобы расслабить нервы своего мозга, чтобы учиться и учиться позже. Это может показаться немного странным, но не обременяйте себя новыми темами перед экзаменом. Вместо этого просто повторите то, что вы уже сделали.
Это может показаться немного странным, но не обременяйте себя новыми темами перед экзаменом. Вместо этого просто повторите то, что вы уже сделали.
Знаете ли вы?
Возраст — это дискретные данные, потому что мы можем быть бесконечно точными и использовать бесконечное число знаков после запятой, в результате делая возраст непрерывным. Однако обычно мы используем возраст как дискретную переменную.
Мои данные непрерывны или дискретны? | Блоги
Просмотреть все блоги
Типы данных
При анализе данных часто нам нужно знать, является ли наш набор данных непрерывным или дискретным. Основная причина этого заключается в том, чтобы определить, какой статистический инструмент или методологию нам нужно использовать для анализа данных. Если набор данных является непрерывным, нам нужно использовать один набор аналитических инструментов или методов, а если данные дискретны, нам придется использовать другой набор инструментов или методов. Я видел несколько мест в литературе, где это определение типа данных сделано неправильно, и в результате к данным был проведен неправильный анализ, что привело к ошибке в анализе и выводах. В этом блоге мы будем различать разные типы данных и, надеюсь, проясним, как вы можете определить тип данных, которые у вас есть.
Я видел несколько мест в литературе, где это определение типа данных сделано неправильно, и в результате к данным был проведен неправильный анализ, что привело к ошибке в анализе и выводах. В этом блоге мы будем различать разные типы данных и, надеюсь, проясним, как вы можете определить тип данных, которые у вас есть.
Что такое данные?
Данные — это любая фактическая информация или измерения, которые собираются и используются для принятия решения, рассуждений или любых расчетов. Нам необходимо обработать данные, чтобы извлечь и понять информацию, которую они нам сообщают. Данные — это язык процесса, который говорит нам, что происходит с процессом.
Различные типы данных
Существуют различные способы классификации данных, но мы будем использовать следующую простую классификацию, показанную на рисунке ниже.
Качественные данные
Данные могут быть как качественными (выраженными в виде текста — пример цвета продукта, описание характеристик продукта), так и количественными (выраженными в виде чисел — количество элементов, выделенных зеленым цветом, равно 4). Например, если мы описываем чашку кофе, качественными данными может быть «кофе имеет прекрасный вкус», а количественными данными могут быть «температура кофе 76 градусов по Цельсию» или «кофе стоит 12,50 долларов».
Например, если мы описываем чашку кофе, качественными данными может быть «кофе имеет прекрасный вкус», а количественными данными могут быть «температура кофе 76 градусов по Цельсию» или «кофе стоит 12,50 долларов».
Большую часть времени, когда мы собираем данные, мы пытаемся собрать количественные данные, чтобы мы могли сделать более точные выводы из данных. Однако в ходе опросов и из других источников мы также собираем качественные данные. Когда мы собираем количественные данные, мы можем дополнительно классифицировать их на два типа: дискретные и непрерывные.
Дискретные данные
Дискретные данные — это данные, для которых невозможны все значения на действительной числовой прямой — возможны только определенные значения. Например, оценка, которую вы получаете на школьном экзамене (A, B, C, D или E), является примером дискретных данных, поскольку ваша оценка может принимать только одно из этих 5 возможных значений и никакое другое. Дискретные данные можно разделить на три категории: двоичные, номинальные и порядковые.
Дискретные данные можно разделить на три категории: двоичные, номинальные и порядковые.
Двоичные данные: Двоичные данные принимают только два возможных значения. Например, лампа горит или не горит, ответ верный или неверный, 0 или 1, да или нет и т. д. Если вы соберете данные о количестве отчетов с ошибкой, это будет пример двоичных данных.
Номинальные данные: Номинальный набор данных может принимать более 2 значений, но эти значения не упорядочены – нет естественного упорядочения или сравнения этих значений. Например, национальность, род занятий, регион, категория дефекта и т. д. Если вы собираете данные о различных типах ошибок, допущенных отделом, это будет пример номинальных данных.
Порядковые данные: Порядковые данные также принимают несколько значений, но они естественным образом упорядочены — можно сделать вывод, что одно лучше другого. Например, оценки на экзамене, результаты забега, результаты опроса клиентов и т. д. Например, если вы проводите опрос и на вопрос опроса есть пять ответов «Плохо», «Ниже среднего», «Средне», « Выше среднего», «Отлично». Эти пять ответов упорядочены, поэтому это будет пример порядковых данных.
д. Например, если вы проводите опрос и на вопрос опроса есть пять ответов «Плохо», «Ниже среднего», «Средне», « Выше среднего», «Отлично». Эти пять ответов упорядочены, поэтому это будет пример порядковых данных.
Непрерывные данные
В непрерывном наборе данных теоретически возможно любое значение. Например, вы можете получить такое значение, как 2,37983. Все значения в строке действительных чисел могут быть возможными значениями данных. Например, длина таблицы может принимать любое значение. Только инструментальное измерение может ограничить количество знаков после запятой, которые мы можем сообщить. Если бы у нас был лучший измерительный прибор, теоретически возможно любое значение. Примерами непрерывных данных являются те, которые обычно измеряются, такие как температура, давление, влажность, длина, время и т. д. Непрерывные данные могут быть дополнительно классифицированы как измеренные на шкале интервалов или шкале отношений.
Интервальная шкала: Интервальная шкала – это те значения, которые не имеют натурального нуля. Вы не можете взять отношение этих чисел — например, температуру в помещении, измеренную в градусах Цельсия.
Шкала отношений: Шкала отношений — это те значения, которые имеют натуральный нуль. Например, температура в помещении измеряется в Кельвинах. Ни одна температура не может опускаться ниже 0 К.
Например, среднее время, необходимое для ответа на анкету опроса клиентов, показанное ниже, является примером непрерывных данных.
Вопросы
Давайте рассмотрим несколько примеров, чтобы увидеть, можем ли мы классифицировать различные типы данных. Классифицируйте следующие данные как непрерывные или дискретные.
- Количество дорожно-транспортных происшествий за месяц в Чикаго
- Результаты опроса об удовлетворенности клиентов (оценка по шкале от 1 до 5)
- Время доставки товара покупателю в днях
- Процент людей, отсутствующих в классе
- Доход от продажи продукта за каждый квартал (измеряется в долларах США)
Ответы на приведенные выше вопросы: а) дискретный, б) дискретный, в) непрерывный, г) дискретный и д) непрерывный. Для количества дорожно-транспортных происшествий оно дискретно, потому что у нас может быть только целое число дорожно-транспортных происшествий. Например, у вас может быть 2 или 3 аварии, но не может быть 2,3 аварии в месяц. Для опроса удовлетворенности клиентов он является дискретным, поскольку вы можете иметь значения только от 1, 2, 3, 4 или 5, но не любое число между ними. Для времени, необходимого для доставки продукта, у вас теоретически может быть 2,3 дня доставки, или возможно любое значение, поэтому оно является непрерывным. Для процента людей, отсутствующих в классе, это отношение двух дискретных чисел, и поэтому его следует рассматривать как дискретное. Все значения невозможны — например, если в классе 10 человек и 1 отсутствует, вы получите 0,1 (10% отсутствующих) или если 2 человека отсутствуют, вы получите 0,2 (20% отсутствующих), вы не можете получить никаких значений. между. Следовательно, это следует строго рассматривать как дискретное. Наконец, для дохода от продаж он измеряется в долларах и, следовательно, должен рассматриваться как непрерывный, любое значение теоретически возможно.
Для количества дорожно-транспортных происшествий оно дискретно, потому что у нас может быть только целое число дорожно-транспортных происшествий. Например, у вас может быть 2 или 3 аварии, но не может быть 2,3 аварии в месяц. Для опроса удовлетворенности клиентов он является дискретным, поскольку вы можете иметь значения только от 1, 2, 3, 4 или 5, но не любое число между ними. Для времени, необходимого для доставки продукта, у вас теоретически может быть 2,3 дня доставки, или возможно любое значение, поэтому оно является непрерывным. Для процента людей, отсутствующих в классе, это отношение двух дискретных чисел, и поэтому его следует рассматривать как дискретное. Все значения невозможны — например, если в классе 10 человек и 1 отсутствует, вы получите 0,1 (10% отсутствующих) или если 2 человека отсутствуют, вы получите 0,2 (20% отсутствующих), вы не можете получить никаких значений. между. Следовательно, это следует строго рассматривать как дискретное. Наконец, для дохода от продаж он измеряется в долларах и, следовательно, должен рассматриваться как непрерывный, любое значение теоретически возможно.
Всегда смотрите на основную природу данных, чтобы определить, является ли набор данных непрерывным или дискретным. Если базовые данные являются дискретными, то данные следует рассматривать как дискретные. Таким образом, отношение двух дискретных чисел следует рассматривать как дискретное, например, % элементов, исправленных с первого раза. Соотношение дискретных и непрерывных значений следует рассматривать как непрерывное, например, среднее время ремонта телевизора.
Подпишитесь на нас в LinkedIn, чтобы получать последние сообщения и обновления.
Дискретные и непрерывные данные — ArcMap | Документация
Доступно с лицензией 3D Analyst.
- Дискретные и непрерывные функции
- Постепенно изменяющиеся непрерывные данные
- Дискретные или непрерывные?
Значения, присвоенные ячейкам поверхности, могут быть представлены либо как дискретные, либо как непрерывные данные. Объекты и поверхности в ArcGIS могут быть представлены либо как дискретные, либо как непрерывные данные.
Объекты и поверхности в ArcGIS могут быть представлены либо как дискретные, либо как непрерывные данные.
Дискретные данные, также известные как категориальные или прерывистые данные, в основном представляют объекты как в пространственных, так и в растровых системах хранения данных. Дискретный объект имеет известные и определяемые границы. Легко точно определить, где объект начинается и заканчивается. Озеро – это отдельный объект в окружающем ландшафте. Где край воды встречается с землей, можно окончательно установить. Другими примерами дискретных объектов являются здания, дороги и земельные участки. Дискретные объекты обычно являются существительными.
Непрерывные данные или непрерывная поверхность представляют явления, где каждое место на поверхности является мерой уровня концентрации или его отношения к фиксированной точке в пространстве или от источника излучения. Непрерывные данные также называются полевыми, недискретными или поверхностными данными.
Один тип непрерывных данных о поверхности получается из тех характеристик, которые определяют поверхность, где каждое местоположение измеряется от фиксированной точки регистрации. К ним относятся высота (фиксированной точкой является уровень моря) и экспозиция (фиксированная точка является направлением: север, восток, юг и запад).
К ним относятся высота (фиксированной точкой является уровень моря) и экспозиция (фиксированная точка является направлением: север, восток, юг и запад).
Дискретные и непрерывные объекты
Большинство приложений ArcGIS используют дискретную географическую информацию, такую как землевладение, классификация почв, зонирование и землепользование. Эти типы данных представлены номинальными, порядковыми, интервальными и относительными значениями. Поверхности — это непрерывные данные, такие как высота над уровнем моря, осадки, концентрация загрязнения и уровень грунтовых вод. Эти данные могут быть представлены в виде непрерывной поверхности, как правило, без резких или скачкообразных изменений.
Отдельные функции
Дискретные объекты являются прерывистыми и имеют определенные границы. Например, дорога имеет ширину и длину и представлена на карте в виде линии. Карта землевладения показывает границы между различными участками. Существуют определенные изменения в характеристиках (таких как имя владельца, номер участка и юридическая территория) между каждым объектом на карте.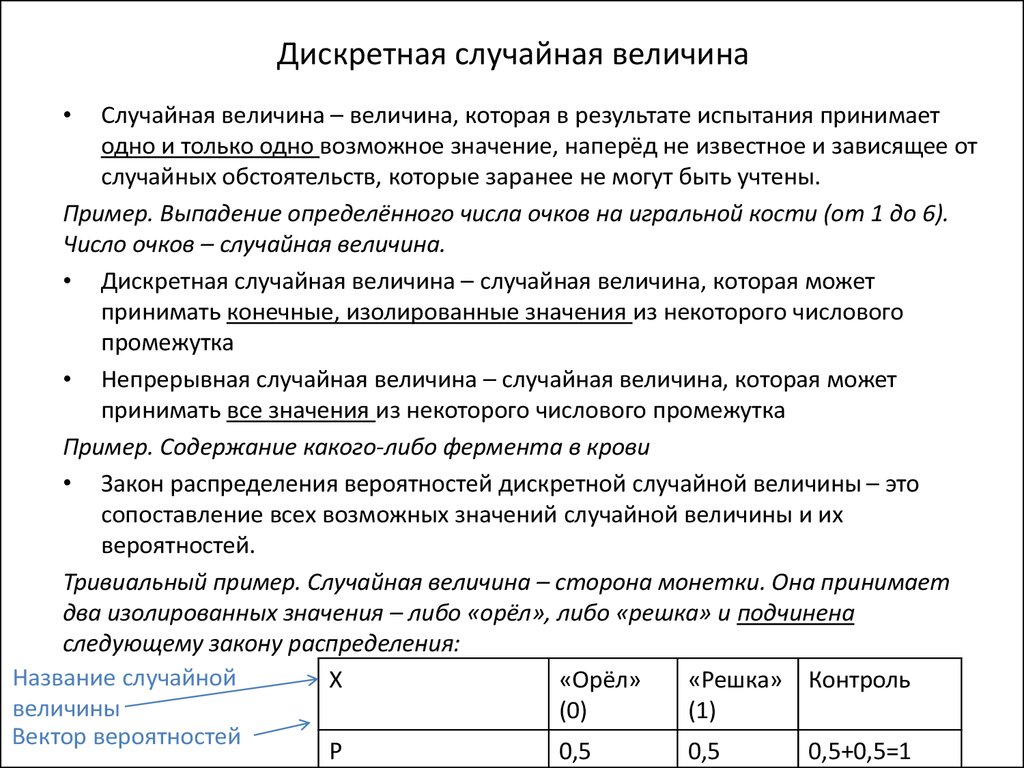
Пример отдельных объектов можно увидеть на этой карте землевладения.
Дискретные объекты карты также можно рассматривать как тематические данные. Эти данные или объекты карты легко представляются на картах в виде точек, линий или областей. К настоящему моменту вы узнали, как структура данных ArcGIS представляет топологические отношения двухмерных объектов. Атрибуты могут быть назначены объектам карты и использованы для их описания, построения, обозначения и маркировки. Кроме того, дальнейший анализ может быть выполнен для определения или идентификации новых взаимосвязей между этими функциями.
Непрерывные объекты
Напротив, непрерывные объекты не являются пространственно дискретными. Как правило, переход между возможными значениями на непрерывной поверхности осуществляется без резких или четко определенных разрывов между значениями. Атрибут поверхности хранится как z-значение, единственная переменная в вертикальном измерении, связанная с данным местоположением x,y. Например, значения высот поверхности непрерывны по всей поверхности. Любое представление поверхности — это просто выборка (подмножество) значений всей поверхности.
Например, значения высот поверхности непрерывны по всей поверхности. Любое представление поверхности — это просто выборка (подмножество) значений всей поверхности.
Постепенно меняющиеся непрерывные данные
Второй тип непрерывных данных о поверхности включает явления, которые постепенно изменяются по мере их перемещения по поверхности от источника. Примерами постоянно меняющихся непрерывных данных о поверхности являются движение жидкости и воздуха. Эти поверхности характеризуются типом или способом движения явления.
Одним из видов движения является диффузия или любая другая локомоция, при которой явления перемещаются из областей с высокой концентрацией в области с меньшей концентрацией, пока уровень концентрации не выровняется. Поверхностные характеристики этого типа движения включают концентрацию соли, движущуюся через землю или воду, разлив нефти и тепло от лесного пожара. В этом типе непрерывной поверхности должен быть источник. Концентрация всегда больше вблизи источника и уменьшается в зависимости от расстояния и среды, в которой движется вещество.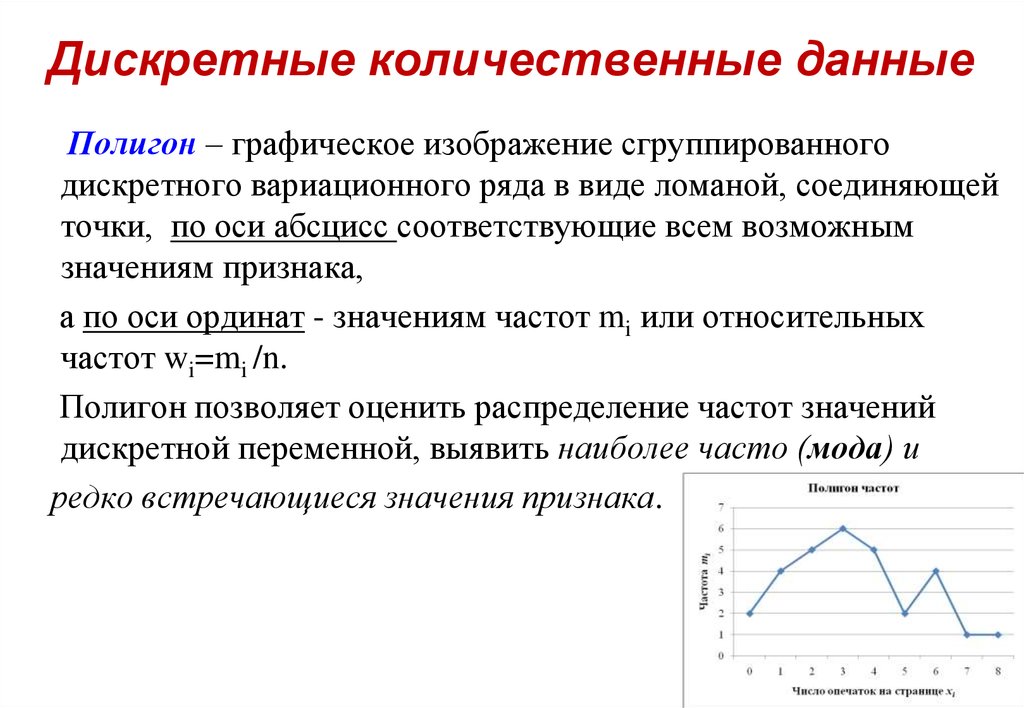
На приведенной выше поверхности концентрации источника концентрация явления в любом месте зависит от способности события перемещаться в среде.
Другой тип движения определяется неотъемлемыми характеристиками движущегося объекта или способом передвижения. Например, движение шума от взрыва бомбы определяется неотъемлемыми характеристиками шума и среды, в которой он движется. Способ передвижения также может ограничивать и напрямую влиять на поверхностную концентрацию признака, как в случае распространения семян с растения. Средства передвижения, будь то пчелы, человек, ветер или вода, влияют на поверхностную концентрацию рассеивания семян растения.
Другие примеры передвижения включают рассредоточение популяций животных, потенциальных покупателей магазина (автомобиль является средством передвижения, а время является ограничивающим фактором) и распространение болезни.
Дискретный или непрерывный?
При представлении и моделировании многих объектов границы не являются четко непрерывными или дискретными. Континуум создается при представлении географических объектов, причем крайностями являются чисто дискретные и чисто непрерывные объекты. Большинство функций находятся где-то между крайностями.
Континуум создается при представлении географических объектов, причем крайностями являются чисто дискретные и чисто непрерывные объекты. Большинство функций находятся где-то между крайностями.
Примерами объектов, попадающих в континуум, являются типы почв, окраины лесов, границы водно-болотных угодий и географические рынки, находящиеся под влиянием телевизионной рекламной кампании. Определяющим фактором того, где объект попадает в спектр от непрерывного к дискретному, является простота определения границ объекта. Независимо от того, где на континууме находится объект, растр может представить его с большей или меньшей точностью.
Важно понимать тип данных, которые вы моделируете, независимо от того, являются ли они дискретными или непрерывными, при принятии решений на основе полученных значений. Точное место для строительства не должно основываться исключительно на карте почв. Площадь леса не может быть основным фактором при определении доступных мест обитания оленей. Кампания по продажам не должна основываться только на географическом влиянии телевизионной рекламы на рынок. Необходимо понимать достоверность и точность границ входных данных.
Необходимо понимать достоверность и точность границ входных данных.
Похожие темы
В чем разница? – Циппия
Дискретный и непрерывный — оба термина используются при обработке данных для описания различных наборов данных и переменных. Оба являются количественными или числовыми данными, что означает, что они представлены числами и могут быть обработаны математически.
Статистика и обработка данных имеют тенденцию приобретать таинственный вид, но как только кто-то объяснит вам основную концепцию того, что делает набор данных дискретным или непрерывным, понять это несложно.
Непрерывные переменные данных обычно используются для измерений, таких как чей-то рост или вес. Это потому, что он включает в себя диапазон — чей-то рост может быть измерен все более и более точно, и, кроме того, он будет меняться со временем.
Для дискретных данных это отдельные числа. Это означает, что он используется для значений, которые можно подсчитать, например, количество автомобилей, которыми владеет домохозяйство. Он также не имеет тенденции меняться со временем — и не будет меняться в течение заданного интервала времени.
Он также не имеет тенденции меняться со временем — и не будет меняться в течение заданного интервала времени.
Ключевые выводы:
| Дискретный | Непрерывный |
|---|---|
| Можно подсчитывать дискретные данные. | Можно измерять непрерывные данные. |
| Дискретные данные визуально представлены в виде диаграмм, таких как гистограммы, круговые диаграммы и точечные диаграммы. Все они показывают индивидуальные значения. | Непрерывные данные обычно представляются визуально в виде гистограмм или линейных диаграмм, которые лучше подходят для демонстрации того, как данные согласуются друг с другом в диапазоне. |
| Некоторыми распространенными примерами дискретных данных являются количество детей в семье, количество игр, выигранных спортивной командой за сезон, или количество участников гонки. | Типичными примерами непрерывных данных являются возраст человека, вес ребенка при рождении и количество времени, которое требуется спринтеру, чтобы пробежать четверть мили. |
| Дискретные данные остаются постоянными в течение определенного интервала времени. | Непрерывные данные будут меняться со временем и иметь разные значения в разное время. |
Что такое дискретные данные?
Дискретные переменные данных всегда фиксированы. Этот тип данных обычно используется в таких ситуациях, как подсчет количества чего-либо, например переписи населения, или количества автомобилей, которыми владеет семья. Невозможно иметь 2,4 автомобиля, а также невозможно уточнить количество автомобилей, которые у них есть.
Это не означает, что в дискретной переменной не может быть десятичной точки. Измерение, такое как чей-то размер обуви, является дискретной переменной, поскольку существует ограниченное количество значений, которые она может содержать. Например, это может быть 10,5, но, поскольку размеры обуви бывают целыми и половинными, существует предел тому, каким он может быть. И это делает дискретные данные менее точными, чем непрерывные данные.
Хотя эти данные могут быть усреднены, откуда и исходит вся идея домохозяйств с 2,3 детьми, на самом деле домохозяйство не может иметь частичного ребенка. Именно это делает данные дискретными — существует конечное число значений, которые можно присвоить.
Дискретные данные чаще всего изображаются с помощью типичных типов графиков, которые вы видите: гистограммы, точечные диаграммы и круговые диаграммы.
Что такое непрерывные данные?
Непрерывные данные — это значение, которое можно найти в диапазоне. Это в значительной степени связано с округлением, поскольку измерения могут выполняться с постоянно возрастающей точностью, в зависимости от инструментов измерения и того, сколько времени вы хотите потратить на заполнение десятичных знаков.
Непрерывными данными будут такие значения, как температура, длина, возраст и вес. Все эти измерения могут быть более точными до бесконечности. Например, если вы хотите измерить вес собаки, вы можете сделать это в стоунах, фунтах или унциях. И тогда вы можете перейти к частичным унциям, приближаясь к истинной точности как к пределу.
И тогда вы можете перейти к частичным унциям, приближаясь к истинной точности как к пределу.
Это делает непрерывные данные более точными, чем дискретные. В то время как непрерывные данные могут быть переданы с еще большей точностью, дискретные данные ограничены одним значением.
Непрерывные данные чаще всего визуально представляются в виде гистограммы или линейной диаграммы, которые показывают непрерывный характер данных. Это не просто одна точка, а диапазон значений, которые подходят друг другу.
Часто задаваемые вопросы о дискретных данных и непрерывных данных
-
Как узнать, является ли переменная дискретной или непрерывной?
Переменная является дискретной, если ее можно посчитать, и непрерывной, если ее можно измерить. Это означает, что количество домашних животных в семье или количество подтягиваний на последней тренировке являются дискретными переменными, в то время как количество галлонов воды в водонапорной башне или ваш точный возраст являются непрерывными переменными.

