Как создать и запустить ускоритель машинного обучения на ПЛИС. Какие шаги нужно выполнить для разработки с Tensil и PYNQ. Как настроить среду разработки для ПЛИС-систем.
Настройка среды PYNQ для работы с Tensil
Теперь, когда мы подготовили все необходимые файлы, приступим к настройке среды PYNQ для запуска нашего ускорителя Tensil. Выполните следующие шаги:
- Скопируйте битовый поток и файл аппаратной передачи на плату PYNQ:
scp tensil_pynqz1_wrapper.bit [email protected]: scp tensil_pynqz1_wrapper.hwh [email protected]:
- Скопируйте скомпилированные файлы модели на плату:
scp resnet20v2_cifar_onnx_pynqz1.tmodel [email protected]: scp resnet20v2_cifar_onnx_pynqz1.tprog [email protected]: scp resnet20v2_cifar_onnx_pynqz1.tdata [email protected]:
- Подключитесь к консоли платы PYNQ по SSH:
- Установите необходимые зависимости Python:
pip3 install numpy pillow
Запуск ускорителя Tensil на PYNQ
Теперь мы готовы запустить наш ускоритель на плате PYNQ. Для этого выполните следующие действия:
- Откройте веб-интерфейс Jupyter на вашей плате PYNQ.
- Создайте новый блокнот Python 3.
- Вставьте следующий код в ячейку блокнота:
import numpy as np from PIL import Image from pynq import Overlay from tcu_pynq.driver import Driver # Загрузка битового потока overlay = Overlay(‘tensil_pynqz1_wrapper.bit’) # Инициализация драйвера driver = Driver(overlay) # Загрузка модели driver.load_model(‘resnet20v2_cifar_onnx_pynqz1.tmodel’) driver.load_program(‘resnet20v2_cifar_onnx_pynqz1.tprog’) driver.load_data(‘resnet20v2_cifar_onnx_pynqz1.tdata’) # Подготовка входных данных image = Image.open(‘sample_image.jpg’) image = image.resize((32, 32)) input_data = np.array(image).astype(np.float32) / 255.0 input_data = input_data.transpose(2, 0, 1).reshape(1, 3, 32, 32) # Запуск вывода модели output = driver.run(input_data) # Вывод результата print(f»Predicted class: {np.argmax(output)}»)
Анализ производительности ускорителя Tensil
После успешного запуска ускорителя важно оценить его производительность. Для этого можно использовать встроенные средства измерения времени выполнения в Python:

import time start_time = time.time() output = driver.run(input_data) end_time = time.time() inference_time = end_time — start_time print(f»Inference time: {inference_time:.4f} seconds»)
Этот код измерит время выполнения вывода модели на ускорителе Tensil. Сравните полученное время с выполнением той же модели на CPU для оценки ускорения.
Оптимизация архитектуры Tensil для PYNQ Z1
Если вы хотите оптимизировать производительность ускорителя Tensil для вашей конкретной задачи, можно экспериментировать с параметрами архитектуры в файле .tarch. Вот несколько советов по оптимизации:
- Увеличение размера массива (array_size) может повысить производительность за счет большего параллелизма, но также увеличит использование ресурсов ПЛИС.
- Настройка глубины памяти (dram0_depth, dram1_depth, local_depth, accumulator_depth) влияет на объем данных, который может обрабатываться за одну итерацию.
- Изменение типа данных (data_type) может повлиять на точность и производительность. FP16BP8 обеспечивает хороший баланс между точностью и эффективностью для многих задач.
Интеграция ускорителя Tensil в реальные приложения
После успешного запуска и оптимизации ускорителя Tensil на PYNQ Z1, следующим шагом будет интеграция его в реальные приложения. Вот несколько идей для применения:
- Системы компьютерного зрения для распознавания объектов в реальном времени
- Обработка естественного языка для анализа текста или генерации контента
- Предиктивное техническое обслуживание на основе анализа данных с датчиков
- Системы рекомендаций для персонализации контента
При интеграции ускорителя Tensil в ваше приложение, обратите внимание на следующие аспекты:
- Предобработка данных: Убедитесь, что входные данные правильно форматированы и нормализованы перед подачей в ускоритель.
- Постобработка результатов: Интерпретируйте выходные данные ускорителя в соответствии с требованиями вашего приложения.
- Обработка ошибок: Реализуйте механизмы обработки ошибок для обеспечения надежности системы.
- Оптимизация производительности: Рассмотрите возможность пакетной обработки данных для повышения эффективности.
Сравнение Tensil с другими решениями для ускорения ML на ПЛИС
Tensil — не единственное решение для ускорения машинного обучения на ПЛИС. Давайте сравним его с некоторыми альтернативами:

- hls4ml: Инструмент от CERN для синтеза моделей машинного обучения в HDL. Преимущество — тесная интеграция с научными инструментами, но может быть сложнее в использовании для начинающих.
- FINN: Фреймворк от Xilinx для развертывания квантованных нейронных сетей. Отлично подходит для сетей с низкой точностью, но может быть менее гибким для других типов моделей.
- LeFlow: Инструмент для преобразования моделей TensorFlow в VHDL. Прост в использовании, но может иметь ограничения по поддерживаемым операциям.
Tensil выделяется своей гибкостью и простотой использования, особенно для разработчиков, знакомых с Python и фреймворками глубокого обучения. Однако выбор инструмента зависит от конкретных требований проекта и опыта команды.
Перспективы развития Tensil и ускорения ML на ПЛИС
Технология ускорения машинного обучения на ПЛИС быстро развивается. Вот некоторые тренды и перспективы в этой области:
- Повышение энергоэффективности: Ожидается дальнейшая оптимизация энергопотребления ускорителей ML на ПЛИС.
- Улучшение инструментов разработки: Упрощение процесса разработки и развертывания моделей на ПЛИС.
- Поддержка более сложных архитектур: Реализация поддержки трансформеров и других современных архитектур нейронных сетей.
- Интеграция с облачными платформами: Упрощение развертывания и масштабирования решений на базе ПЛИС в облачных средах.
Tensil, как открытый проект, имеет хорошие перспективы для развития в этих направлениях. Сообщество разработчиков может внести свой вклад в улучшение инструмента и расширение его возможностей.

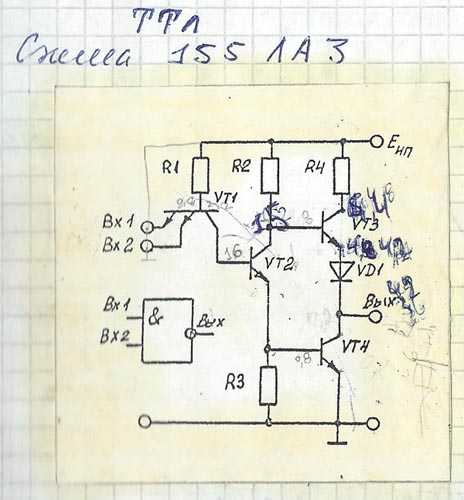
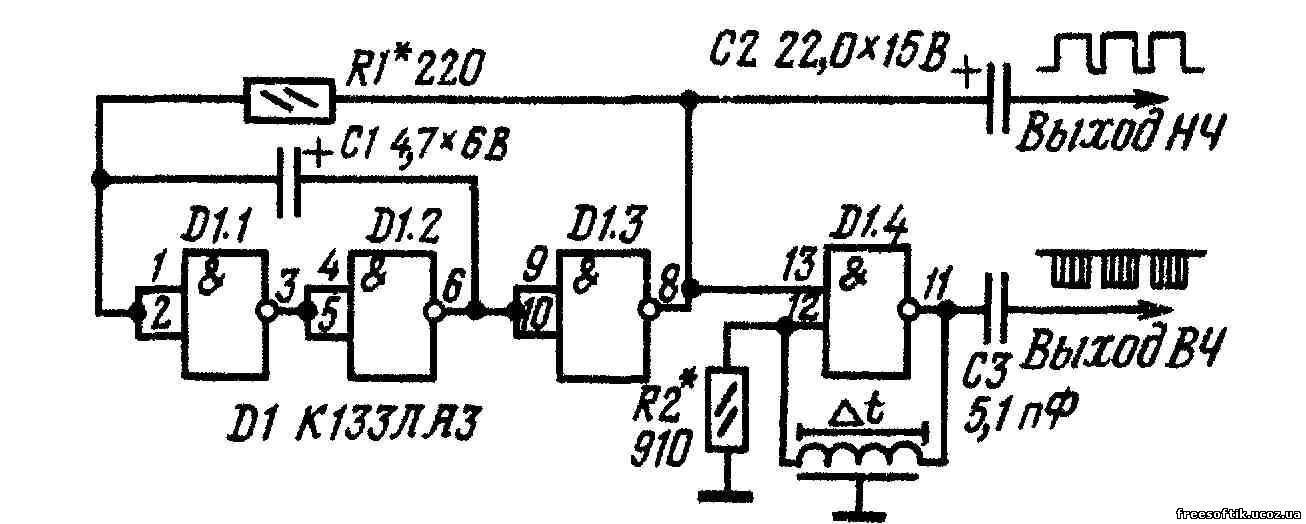
Исследование универсальных логических элементов «И-НЕ». Схема включения ЛЭ К155ЛА3 (а) и схема подачи питания
Санкт-Петербургский государственный горный институт им. Г.В. Плеханова
(технический университет)
Кафедра автоматизации производственных процессов
Лабораторная работа № 8
«Исследование логических интегральных микросхем»
Санкт-Петербург
2002
Цель работы
1. Исследование универсальных логических элементов «И-НЕ».
2. Ознакомление с конструкцией и электрической схемой интегральных микросхем типа К155ЛА3(К133ЛА3).
3. Составление из универсальных логических ИМС схемы для реализации различных логических функций.
Описание лабораторной установки
Рис 1. Схема включения ЛЭ К155ЛА3 (а) и схема подачи питания
Исследование ЛЭ производится на специальном макете. Схема включения ЛЭ К155Ла3 и цепи его питания изображены на лицевой панели макета
и приведены на рис. 1а, б.
Схема включения ЛЭ К155Ла3 и цепи его питания изображены на лицевой панели макета
и приведены на рис. 1а, б.
Микросхема К155ЛА3 (она находится в левой части макета) имеет четыре одинаковых функционально независимых элемента типа «2И-НЕ», объединенных общим питанием клеммы +Eпит и –Eпит (рис. 1а).
Макет напитывается от источника питания УИП-2 напряжением Eпит = 5 В, подаваемым на клеммы «+» и «-» Eпит вспомогательной цепи (рис. 1), находящейся в правой части макета. Подача питания на микросхему (рис.1а) осуществляется от клемм m’ и m’’ вспомогательной цепи (рис. 1 б) соединительными проводами.
Внимание! В течение всей работы цепь питания не менять!
Контроль входного и выходного
напряжений ИМС при снятии передаточной характеристики, а также определения
состояния схемы («0» или «1») в соответствующих точках производится с помощью двух
универсальных вольтметров, например В7-17, на пределе измерения (на шкале) +10
В.
К клеммам Y1 микросхемы и «1» вспомогательной цепи присоединить вольтметр V2. Принципиальная схема установки показана на рис. 2.
Рис. 2. Принципиальная схема установки
Входное напряжение Uвхизменять потенциометром R от 0 до 5В через 0,5 В. результаты измерений записать в таблицу 1.
Таблица 1
|
Uвх |
0 |
0.5 |
1.0 |
1.5 |
2.0 |
2. |
3.0 |
3.5 |
4.0 |
4.5 |
5.0 |
|
Uвых |
|
 5
52. Построить график передаточной характеристики Uвых = f(Uвх) и по ней определить уровень
напряжения (2-5) В, принимаемый в дальнейшем за логическую «1» и уровень (0-1)
В – за логический «0»
Построить график передаточной характеристики Uвых = f(Uвх) и по ней определить уровень
напряжения (2-5) В, принимаемый в дальнейшем за логическую «1» и уровень (0-1)
В – за логический «0»
3. Реализовать логическую НЕ, используя один из ЛЭ. Схема исследования представлена на рис. 3.
Рис. 3. Схема реализации «НЕ»
Входы X1 и X2 соединить, на них поочередно подавать входные сигналы с клемм «1» и «0», вспомогательной цепи. Выходные сигналы регистрировать с учетом п. 2. Результаты занести в таблицу 2.
Таблица 2
|
X1=X2 |
Y1 |
Uвых, В |
|
0 1 |
4. ». Входные сигналы «0» и «1» от вспомогательной цепи подавать
на входы X1 и X2 в соответствие с таблицей 3.
». Входные сигналы «0» и «1» от вспомогательной цепи подавать
на входы X1 и X2 в соответствие с таблицей 3.
Таблица 3
|
X1 |
X2 |
Y1 |
Y2 |
Uвых, В |
|
0 |
0 |
|||
|
1 |
0 |
|||
|
0 |
1 |
|||
|
1 |
1 |
5. . Сигналы «0» и «1» подавать
от вспомогательной цепи в соответствие с таблицей 4.
. Сигналы «0» и «1» подавать
от вспомогательной цепи в соответствие с таблицей 4.
Рис. 3. Схема реализации «НЕ»
Таблица 3
|
A |
B |
Y3 |
Uвых, В |
|
0 |
0 |
||
|
1 |
0 |
||
|
0 |
1 |
||
|
1 |
1 |
6. Реализовать логическую операцию
2ИЛИ-НЕ или 4И-НЕ. Для этого составить схему из четырех элементов и собрать её.
Собранную схему зарисовать, нарисовать и заполнить таблицу истинности. Измерить
с помощью вольтметра напряжения на выходе и занести их в таблицу истинности.
Реализовать логическую операцию
2ИЛИ-НЕ или 4И-НЕ. Для этого составить схему из четырех элементов и собрать её.
Собранную схему зарисовать, нарисовать и заполнить таблицу истинности. Измерить
с помощью вольтметра напряжения на выходе и занести их в таблицу истинности.
1. Принципиальная электрическая схема базового элемента.
2. Передаточная характеристика инвертора.
3. Схемы для реализации логических операций в соответствие с п. 3-6, уравнения логических функций, таблицы истинности.
К155ЛА3 (SN7400N) чотири логічних елемента 2И-НЕ, цена 10.50 грн — Prom.ua (ID#53187784)
К155ЛА3 (SN7400N) четыре логических элемента 2И-НЕК155ЛА3
Интегральная микросхема серии ТТЛ.
Микросхемы К155ЛА3 представляют собой 4 логических элемента 2И-НЕ.
Содержат 56 интегральных элементов.
Корпус типа 201.14-1, масса не более 1 г.
Предельно допустимые режимы эксплуатации К155ЛА3:
— Напряжение питания ……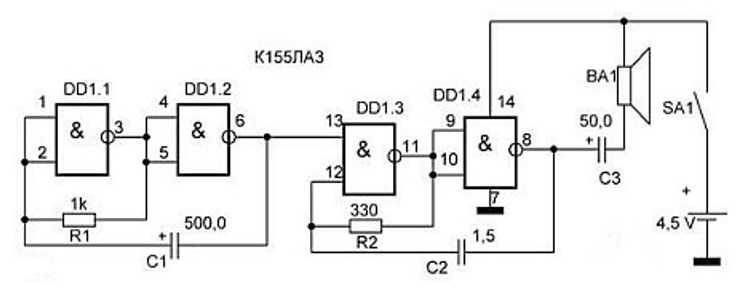 …. 4,75 — 5,25 В
…. 4,75 — 5,25 В
— Входное напряжение низкого уровня ………. < 0,4 В
— Входное напряжение высокого уровня ………. > 2,4 В
— Входной ток низкого уровня ………. < 16 мА
— Выходной ток высокого уровня ………. < -0,8 мА
— Емкость нагрузки ………. < 15 пФ
— Длительность фронта и среза входного импульса < 150 нс
— Температура окружающей среды:
— К155 ………. -10 + 70 °С
— КМ155 ……… — 45 + 85 °С
Корпус К155ЛА3 типа 201.14-1, масса не более 1 г и у
КМ155ЛА3 типа 201.14-8, масса не более 2,2 г.
Корпус ИМС К155ЛА3Корпус ИМС КМ155ЛА3
Условное графическое обозначение
1,2,4,5,9,10,12,13 ― входы X1-X8;
3 ― выход Y1;
6 ― выход Y2;
7 ― общий;
8 ― выход Y3;
11 ― выход Y4;
14 ― напряжение питания;
Электрические параметры
| 1 | Номинальное напряжение питания | 5 В 5 % |
| 2 | Выходное напряжение низкого уровня | не более 0,4 В |
| 3 | Выходное напряжение высокого уровня | не менее 2,4 В |
| 4 | Напряжение на антизвонном диоде | не менее -1,5 В |
| 5 | Входной ток низкого уровня | не более -1,6 мА |
| 6 | Входной ток высокого уровня | не более 0,04 мА |
| 7 | Входной пробивной ток | не более 1 мА |
| 8 | Ток короткого замыкания | -18. ..-55 мА ..-55 мА |
| 9 | Ток потребления при низком уровне выходного напряжения | не более 22 мА |
| 10 | Ток потребления при высоком уровне выходного напряжения | не более 8 мА |
| 11 | Потребляемая статическая мощность на один логический элемент | не более 19,7 мВт |
| 12 | Время задержки распространения при включении | не более 15 нс |
| 13 | Время задержки распространения при выключении | не более 22 нс |
Зарубежные аналоги
SN7400N, SN7400J
Общая информация
| Наименование | К155ЛА3 DIP14 Микросхема |
| Торговая марка | ПО ДНЕПР, Херсон |
| Страна происхождения | Україна |
| ТУ | БКО 034.80. 06-01 ТУ |
| Вид приемки | «1» |
| Масса изделия, гр. | 0,78 |
| Дата выпуска | 01. 01.1981 01.1981 |
| Транслитерация | K155LA3 |
| Состояние упаковки | самоупаковка |
Основные параметры
| Функциональная группа | Стандартная логика |
| Функциональный тип | 8И-НЕ |
| Типоразмер корпуса отечественный | 201.14-8 |
| Типоразмер корпуса | DIP14 |
| Материал корпуса | пластмасса |
| Цвет изделия | коричневый |
| Габаритные размеры L*W*H | 19х8х6 |
| Высота корпуса | 4 mm |
Технические характеристики
| Напряжение питания | 5 V |
| Выходное напряжение | низкого уровня не более 0,4 V; высокого уровня не менее 2,4 V |
| Диапазон напряжения | ±5 % |
| Входной ток | низкого уровня не более -1,6 mA; высокого уровня не более 0,04 mA |
| Ток потребления | при высоком уровне не более 8 mA, при низком уровне не более 22 mA |
| Время задержки распространения | при включении 15 ns; при выключении 22 ns |
| Входной ток | низкого уровня не более -1,6 mA; высокого уровня не более 0,04 mA |
Условия эксплуатации
| Интервал рабочих температур | от -10 до +70°C |
| Примечание | (1981-1988гг. ) ) |
Микросхема К155ЛА3 — В состав этих микросхем входит 56 интегральных элементов. Представляет собой четыре логических элемента 2И-НЕ.
Учебное пособие по растяжению для PYNQ Z1
Введение
В этом учебном пособии будет использоваться плата разработки PYNQ Z1 и ускоритель логических выводов с открытым исходным кодом Tensil, чтобы показать, как запускать модели машинного обучения (ML) на FPGA. Мы будем использовать ResNet-20, обученный набору данных CIFAR. Эти шаги должны работать для любой поддерживаемой модели ML — в настоящее время поддерживаются все распространенные современные сверточные нейронные сети. Попробуйте на своей модели!
Мы предоставим подробное сквозное покрытие, за которым легко следить. Кроме того, мы включаем подробные объяснения, чтобы получить хорошее представление о технологии, стоящей за всем этим, включая цепочки инструментов Tensil и Xilinx Vivado и структуру PYNQ.
Если вы застряли или обнаружили ошибку, вы можете задать вопрос в нашем Discord или отправить электронное письмо по адресу support@tensil. ai.
ai.
Обзор
Прежде чем мы начнем, давайте посмотрим на поток инструментов Tensil, чтобы получить общее представление о том, чего мы хотим достичь. Мы выполним следующие шаги:
- Получить Тенсил
- Выберите архитектуру
- Создать проект ускорителя TCU (код RTL)
- Синтез для PYNQ Z1
- Компиляция модели ML для TCU
- Выполнить с помощью PYNQ
1. Получите Тенсил
Во-первых, нам нужно получить набор инструментов Tensil. Самый простой способ — вытащить док-контейнер Tensil из Docker Hub. Следующая команда извлечет образ, а затем запустит контейнер.
docker pull натяжение/натяжение
докер запустить \
-u $(id -u ${ПОЛЬЗОВАТЕЛЬ}):$(id -g ${ПОЛЬЗОВАТЕЛЬ}) \
-v $(пароль):/работа \
-w / работа \
-it tensilai/тенсил\
бить
2. Выберите архитектуру
Сила Tensil заключается в возможности персонализации, что делает его пригодным для очень широкого спектра применений. Файл определения архитектуры Tensil (.tarch) указывает параметры архитектуры, которые необходимо реализовать. Именно эти параметры делают Tensil достаточно гибким для работы как с небольшими встраиваемыми ПЛИС, так и с ПЛИС крупных центров обработки данных. В нашем примере будут выбраны параметры, обеспечивающие максимальное использование ресурсов на части FPGA XC7Z020 в ядре платы PYNQ Z1. Образ контейнера удобно включает в себя файл архитектуры для платы разработки PYNQ Z1 в
Файл определения архитектуры Tensil (.tarch) указывает параметры архитектуры, которые необходимо реализовать. Именно эти параметры делают Tensil достаточно гибким для работы как с небольшими встраиваемыми ПЛИС, так и с ПЛИС крупных центров обработки данных. В нашем примере будут выбраны параметры, обеспечивающие максимальное использование ресурсов на части FPGA XC7Z020 в ядре платы PYNQ Z1. Образ контейнера удобно включает в себя файл архитектуры для платы разработки PYNQ Z1 в /demo/arch/pynqz1.tarch . Давайте посмотрим, что внутри.
{
"тип_данных": "FP16BP8",
"размер_массива": 8,
"драм0_глубина": 1048576,
"драм1_глубина": 1048576,
"локальная_глубина": 8192,
"глубина_аккумулятора": 2048,
"simd_registers_depth": 1,
"шаг0_глубина": 8,
"шаг1_глубина": 8
}
Файл содержит объект JSON с несколькими параметрами. Первый, data_type , определяет тип данных, используемый в Tensor Compute Unit (TCU), включая систолический массив, SIMD ALU, аккумуляторы и локальную память. Мы будем использовать 16-битную фиксированную точку с 8-битной базовой точкой (
Мы будем использовать 16-битную фиксированную точку с 8-битной базовой точкой ( FP16BP8 ), который в большинстве случаев позволяет выполнять простое округление 32-битных моделей с плавающей запятой без необходимости квантования. Затем array_size определяет систолический размер массива 8×8, что дает 64 параллельных единицы умножения-накопления (MAC). Это число было выбрано, чтобы сбалансировать использование блоков DSP, доступных на XC7Z020, на случай, если вам нужно будет использовать несколько DSP для другого приложения параллельно, но вы можете увеличить его для более высокой производительности TCU.
С dram0_depth и dram1_depth мы определяем размер буферов памяти DRAM0 и DRAM1 на стороне хоста. Эти буферы подают в TCU веса и входные данные модели, а также хранят промежуточные результаты и выходные данные. Обратите внимание, что эти размеры памяти указаны в количестве векторов, что означает размер массива (8), умноженный на размер типа данных (16 бит), что в сумме составляет 128 бит на вектор.
Затем мы определяем размер локальной памяти и накопителя памяти, которые будут реализованы на самой фабрике FPGA. Разница между аккумуляторами и локальной памятью заключается в том, что аккумуляторы могут выполнять операцию записи-накопления, при которой ввод добавляется к уже сохраненным данным, а не просто перезаписывается. Общий размер аккумуляторов плюс локальная память снова выбирается, чтобы сбалансировать использование ресурсов BRAM на XC7Z020 на случай, если ресурсы потребуются где-то еще.
С помощью simd_registers_depth мы указываем количество регистров, включенных в каждое SIMD ALU, которые могут выполнять операции SIMD над сохраненными векторами, используемыми для операций ML, таких как активация ReLU. Увеличение этого числа необходимо только в редких случаях, чтобы помочь вычислить специальные функции активации. Наконец, stride0_depth и stride1_depth задают количество битов, используемых для включения «шагового» чтения и записи памяти.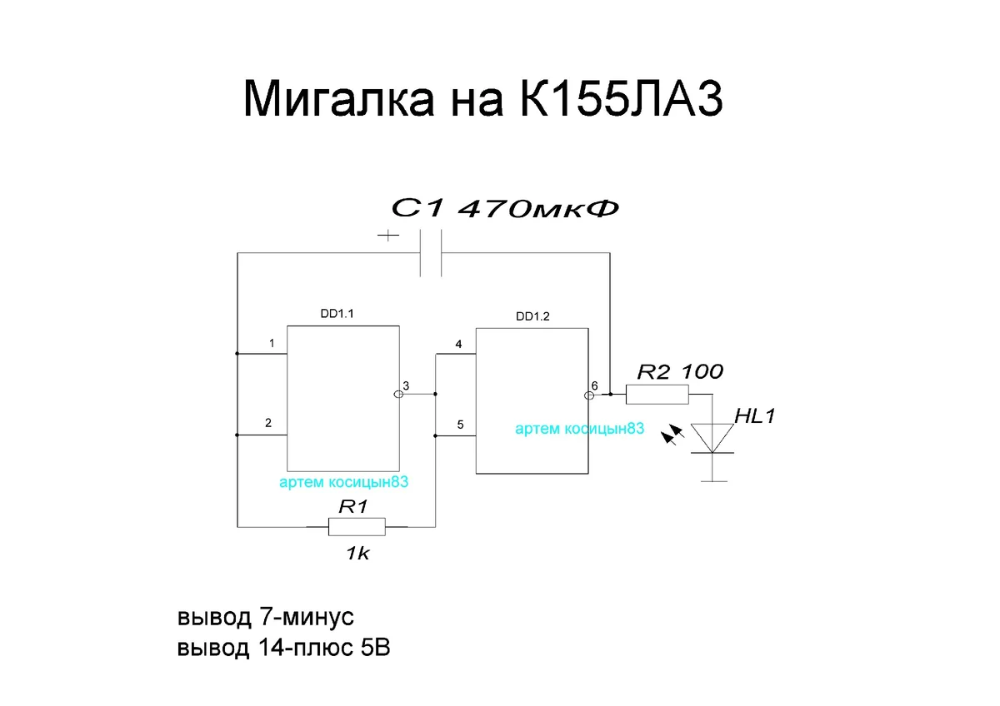 Маловероятно, что вам когда-нибудь понадобится изменить этот параметр.
Маловероятно, что вам когда-нибудь понадобится изменить этот параметр.
Теперь, когда мы выбрали нашу архитектуру, пришло время запустить генератор Tensil RTL. RTL означает «Уровень передачи регистров» — это тип кода, который определяет элементы цифровой логики, такие как провода, регистры и низкоуровневая логика. Специальные инструменты, такие как Xilinx Vivado или yosys, могут синтезировать RTL для FPGA и даже ASIC.
Чтобы сгенерировать проект с использованием выбранной нами архитектуры, выполните следующую команду внутри контейнера докера Tensil toolchain:
tensil rtl -a /demo/arch/pynqz1.tarch -s true
Эта команда создаст несколько файлов Verilog, перечисленных в таблице ARTIFACTS , распечатанной в конце. Он также распечатывает таблицу RTL SUMMARY с некоторыми основными параметрами результирующего RTL.
-------------------------------------------------- --------------------- РЕЗЮМЕ RTL -------------------------------------------------- -------------------- Тип данных: FP16BP8 Размер массива: 8 Размер постоянной памяти (векторы/скаляры/биты): 1 048 576 8 388 608 20 Размер памяти Vars (векторы/скаляры/биты): 1 048 576 8 388 608 20 Размер локальной памяти (векторы/скаляры/биты): 8,192 65 536 13 Объем памяти аккумулятора (векторы/скаляры/биты): 2 048 16 384 11 Размер шага #0 (биты): 3 Размер шага №1 (бит): 3 Размер операнда #0 (бит): 16 Размер операнда №1 (бит): 24 Размер операнда № 2 (бит): 16 Размер инструкции (байт): 8 -------------------------------------------------- --------------------
4.
 Синтез для PYNQ Z1
Синтез для PYNQ Z1Пришло время запустить Xilinx Vivado. Я буду использовать версию 2021.2, которую вы можете бесплатно скачать (для прототипирования) на веб-сайте Xilinx.
Прежде чем создавать новый проект Vivado, вам необходимо загрузить файлы определения платы PYNQ Z1 отсюда. Распакуйте и поместите их в /tools/Xilinx/Vivado/2021.2/data/boards/board_files/ . (Обратите внимание, что этот путь включает версию Vivado.) После распаковки вам нужно будет добавить путь к файлам платы в Инструменты -> Настройки -> Репозиторий платы.
Сначала создайте новый проект RTL с именем tensil-pynqz1 и добавьте файлы Verilog, сгенерированные инструментом Tensil RTL.
Выберите доски и найдите PYNQ. Выберите PYNQ-Z1 с версией файла 1.0.
В разделе IP INTEGRATOR щелкните Создать блочный проект.
Перетащите top_pynqz1 с вкладки «Источники» на блок-схему. Вы должны увидеть блок Tensil RTL с его интерфейсами.
Затем нажмите кнопку плюс + на панели инструментов блок-схемы (вверху слева) и выберите «Система обработки ZYNQ7» (возможно, вам потребуется использовать окно поиска). Сделайте то же самое для «Сброс системы процессора». Блок Zynq представляет собой «жесткую» часть платформы Xilinx, которая включает в себя процессоры ARM, интерфейсы DDR и многое другое. Сброс системы процессора — это служебный блок, который обеспечивает проект правильно синхронизированными сигналами сброса.
Нажмите «Запустить автоматизацию блока» и «Запустить автоматизацию подключения». Установите флажок «Вся автоматизация».
Дважды щелкните Система обработки ZYNQ7. Во-первых, перейдите в раздел «Конфигурация часов» и убедитесь, что для часов PL Fabric Clock установлен флажок FCLK_CLK0 и установлено значение 50 МГц.
Затем перейдите к конфигурации PS-PL. Проверьте S AXI HP0 FPD , S AXI HP1 FPD и S AXI HP2 FPD . Эти изменения настроят все необходимые интерфейсы между системой обработки (PS) и программируемой логикой (PL), необходимые для нашего проекта.
Эти изменения настроят все необходимые интерфейсы между системой обработки (PS) и программируемой логикой (PL), необходимые для нашего проекта.
Снова нажмите плюс + на панели инструментов блок-схемы и выберите «AXI SmartConnect». Нам понадобится 4 экземпляра SmartConnect. Первые 3 экземпляра (от smartconnect_0 до smartconnect_2 ) необходимы для преобразования интерфейсов AXI версии 4 TCU и блока DMA инструкций в AXI версии 3 на PS. smartconnect_3 необходим для предоставления доступа к регистрам управления DMA ЦП Zynq, что позволит программному обеспечению управлять транзакциями DMA. Дважды щелкните каждый и установите «Количество ведомых и главных интерфейсов» на 1.
Теперь подключите m_axi_dram0 и m_axi_dram1 порты на блоке Tensil к S00_AXI на smartconnect_0 и smartconnect_1 соответственно. Затем подключите порты SmartConnect M00_AXI к S_AXI_HP0 и S_AXI_HP2 на блоке Zynq соответственно. TCU имеет два банка DRAM для обеспечения их параллельной работы за счет использования портов PS с выделенным подключением к памяти.
TCU имеет два банка DRAM для обеспечения их параллельной работы за счет использования портов PS с выделенным подключением к памяти.
Затем нажмите кнопку плюс + на панели инструментов блок-схемы и выберите «Прямой доступ к памяти AXI» (DMA). Блок DMA используется для организации подачи программы Tensil на TCU без загрузки процессора PS ARM.
Дважды щелкните его. Отключите «Scatter Gather Engine» и «Write Channel». Измените «Ширина регистра длины буфера» на 26 бит. Выберите «Ширина данных карты памяти» и «Ширина данных потока» на 64 бита. Измените «Максимальный размер пакета» на 256.
Соедините порт инструкции в верхнем блоке Tensil с портом M_AXIS_MM2S в блоке AXI DMA. Затем подключите M_AXI_MM2S блока AXI DMA к порту S00_AXI блока smartconnect_2 и, наконец, подключите порт smartconnect_2 M00_AXI к порту S_AXI_HP1 блока Zynq. 42.
42.
Соедините M00_AXI на smartconnect_3 с S_AXI_LITE на блоке AXI DMA. Подключить S00_AXI в AXI SmartConnect до M_AXI_GP0 в блоке Zynq.
Наконец, нажмите «Запустить автоматизацию подключения» и установите флажок «Вся автоматизация». Тем самым подключаем все часы и ресеты. Нажмите кнопку «Regenerate Layout» на панели инструментов Block Diagram, чтобы схема выглядела красиво.
Далее перейдите на вкладку «Редактор адресов». Нажмите кнопку «Назначить все» на панели инструментов. Делая это, мы назначаем адресные пространства различным интерфейсам AXI. Например, инструкция DMA ( axi_dma_0 ) и Tensil ( m_axi_dram0 и m_axi_dram1 ) получают доступ ко всему адресному пространству на плате PYNQ Z1. PS получает доступ к управляющим регистрам для инструкции DMA.
Вернувшись на вкладку «Блок-схема», нажмите кнопку «Проверить проект» (или F6). Вы должны увидеть сообщение об успешной проверке! Теперь вы можете закрыть дизайн блока, щелкнув
Вы должны увидеть сообщение об успешной проверке! Теперь вы можете закрыть дизайн блока, щелкнув x в правом верхнем углу.
Последним шагом является создание оболочки HDL для нашего проекта, которая свяжет все воедино и позволит осуществить синтез и реализацию. Щелкните правой кнопкой мыши tensil_pynqz1 на вкладке «Источники» и выберите «Создать HDL-оболочку». Оставьте выбранным «Разрешить Vivado управлять оболочкой и автообновлением». Дождитесь полного обновления дерева Sources и щелкните правой кнопкой мыши tensil_pynqz1_wrapper . Выберите «Сделать верхним».
Теперь пришло время позволить Vivado выполнить синтез и реализацию и записать результирующий битовый поток. На боковой панели Flow Navigator нажмите «Создать битовый поток» и нажмите «ОК». Vivado начнет синтезировать наш дизайн Tensil — это может занять около 15 минут. Когда закончите, вы сможете увидеть некоторые важные статистические данные в сводке проекта. Во-первых, посмотрите на использование, которое показывает, какой процент каждого ресурса FPGA использует наш проект. Обратите внимание, как мы сохранили использование BRAM и DSP на достаточно низком уровне.
Обратите внимание, как мы сохранили использование BRAM и DSP на достаточно низком уровне.
Второй параметр — время, которое говорит нам о том, сколько времени требуется сигналам для распространения в нашей программируемой логике (PL). Положительное значение «наихудшего отрицательного резерва» является хорошей новостью: наш дизайн соответствует ограничениям распространения для всех цепей на указанной тактовой частоте!
5. Компилировать модель ML для TCU
Вторая ветвь цепочки инструментов Tensil заключается в компиляции модели машинного обучения в двоичный файл Tensil, состоящий из инструкций TCU, которые выполняются аппаратным обеспечением TCU напрямую. В этом руководстве мы будем использовать ResNet20, обученную набору данных CIFAR. Модель включена в образ докера Tensil на странице 9.0041 /demo/models/resnet20v2_cifar.onnx . Из контейнера докера Tensil выполните следующую команду.
растягивающая компиляция \
-a /demo/arch/pynqz1. tarch \
-m /demo/models/resnet20v2_cifar.onnx \
-o "Идентификация: 0" \
-правда
tarch \
-m /demo/models/resnet20v2_cifar.onnx \
-o "Идентификация: 0" \
-правда
Мы используем версию модели ONNX, но компилятор Tensil также поддерживает TensorFlow, что вы можете попробовать, скомпилировав ту же модель в форме замороженного графа TensorFlow по адресу /demo/models/resnet20v2_cifar.pb .
растягивающая компиляция \
-a /demo/arch/pynqz1.tarch \
-m /demo/models/resnet20v2_cifar.pb \
-o "Идентификация" \
-правда
Полученные скомпилированные файлы перечислены в таблице ARTIFACTS . Манифест ( tmodel ) представляет собой простое текстовое описание скомпилированной модели в формате JSON. Программа Tensil ( tprog ) и данные о весе ( tdata ) являются двоичными файлами, которые будут использоваться TCU во время выполнения. Компилятор Tensil также печатает COMPILER SUMMARY таблица с интересной статистикой как по архитектуре TCU, так и по модели.
-------------------------------------------------- ----------------------------------------- ОБЗОР КОМПИЛЯТОРА -------------------------------------------------- ---------------------------------------- Модель: resnet20v2_cifar_onnx_pynqz1 Тип данных: FP16BP8 Размер массива: 8 Размер постоянной памяти (векторы/скаляры/биты): 1 048 576 8 388 608 20 Размер памяти Vars (векторы/скаляры/биты): 1 048 576 8 388 608 20 Размер локальной памяти (векторы/скаляры/биты): 8,192 65 536 13 Объем памяти аккумулятора (векторы/скаляры/биты): 2 048 16 384 11 Размер шага #0 (биты): 3 Размер шага №1 (бит): 3 Размер операнда #0 (бит): 16 Размер операнда №1 (бит): 24 Размер операнда № 2 (бит): 16 Размер инструкции (байт): 8 Максимальное использование памяти Consts (векторы/скаляры): 71 341 570 728 Максимальное использование памяти Vars (векторы/скаляры): 26 624 212,992 Consts совокупное использование памяти (векторы/скаляры): 71 341 570 728 Совокупное использование памяти Vars (векторы/скаляры): 91 170 729 360 Количество слоев: 23 Общее количество инструкций: 258 037 Время компиляции (секунд): 25.487 Истинный скалярный размер const: 568 466 Утилизация констант (%): 97,545 Истинные MAC-адреса (M): 61,476 Эффективность MAC (%): 0,000 -------------------------------------------------- ----------------------------------------
6. Выполнить с помощью PYNQ
Теперь пришло время собрать все вместе на макетной плате. Для этого нам сначала нужно настроить среду PYNQ. Этот процесс начинается с загрузки образа SD-карты для нашей платы разработки. На сайте документации PYNQ есть подробная инструкция по настройке подключения к плате. Вы должны иметь возможность открывать блокноты Jupyter и запускать некоторые примеры.
Теперь, когда PYNQ настроен и работает, следующим шагом будет scp драйвер Tensil для PYNQ. Начните с клонирования репозитория Tensil GitHub на свою рабочую станцию, а затем скопируйте drivers/tcu_pynq в /home/xilinx/tcu_pynq на свою плату.
клон git [email protected]:tensil-ai/tensil.git scp -r тенсил/драйверы/tcu_pynq [email protected]:
Нам также нужно scp битовый поток и артефакты компилятора.
Далее мы скопируем битовый поток, который содержит конфигурацию FPGA, полученную в результате синтеза и реализации Vivado. PYNQ также требуется файл аппаратной передачи, в котором описываются компоненты FPGA, доступные для хоста, такие как DMA. Поместите оба файла в /home/xilinx на макетной плате. Предполагая, что вы находитесь в каталоге проекта Vivado, выполните следующие команды, чтобы скопировать файлы.
scp tensil-pynqz1.runs/impl_1/tensil_pynqz1_wrapper.bit [email protected]:tensil_pynqz1.bit scp tensil-pynqz1.gen/sources_1/bd/tensil_pynqz1/hw_handoff/tensil_pynqz1.hwh [email protected]:
Обратите внимание, что мы переименовали битовый поток, чтобы он соответствовал имени файла аппаратного переключения.
Теперь скопируйте .tmodel , .tprog 9Артефакты 0042 и ., созданные компилятором для 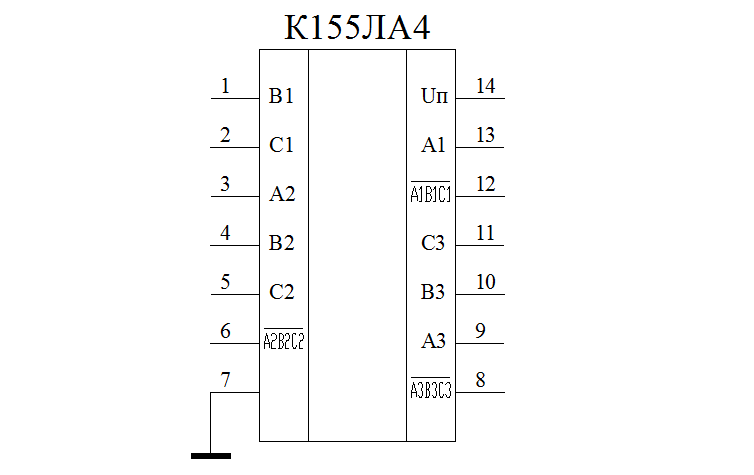 tdata
tdata /home/xilinx на плате.
SCP resnet20v2_cifar_onnx_pynqz1.t* [email protected]:
Последнее, что нужно для запуска нашей модели ResNet, — это набор данных CIFAR. Вы можете получить его из Kaggle или выполнить приведенные ниже команды (поскольку нам нужен только тестовый пакет, мы удаляем обучающие пакеты, чтобы уменьшить размер файла). Поместите эти файлы в /home/xilinx/cifar-10-batches-py/ на макетной плате.
wget http://www.cs.toronto.edu/~kriz/cifar-10-python.tar.gz смола xfvz cifar-10-python.tar.gz rm cifar-10-batches-py/data_batch_* scp -r cifar-10-batches-py [email protected]:
Наконец-то мы готовы запустить ноутбук PYNQ Jupyter и запустить модель ResNet на TCU.
Ноутбук Jupyter
Сначала импортируем драйвер Tensil PYNQ и другие необходимые утилиты.
система импорта
sys.path.append('/home/xilinx')
# Требуется для запуска логического вывода на TCU
время импорта
импортировать numpy как np
импортировать pyq
из наложения импорта pynq
из tcu_pynq. driver импортировать драйвер
из tcu_pynq.architecture импортировать pynqz1
# Нужен для распаковки и отображения данных изображения
%matplotlib встроенный
импортировать matplotlib.pyplot как plt
импортный рассол
driver импортировать драйвер
из tcu_pynq.architecture импортировать pynqz1
# Нужен для распаковки и отображения данных изображения
%matplotlib встроенный
импортировать matplotlib.pyplot как plt
импортный рассол
Теперь инициализируйте наложение PYNQ из потока битов и создайте экземпляр драйвера Tensil, используя архитектуру TCU и конфигурацию DMA наложения. Обратите внимание, что мы передаем объект axi_dma_0 из оверлея — имя соответствует блоку DMA в дизайне Vivado.
наложение = наложение ('/home/xilinx/tensil_pynqz1.bit')
tcu = Драйвер (pynqz1, overlay.axi_dma_0)
Драйвер Tensil PYNQ включает определение архитектуры PYNQ Z1. Вот отрывок из Architecture.py : вы можете видеть, что это соответствует архитектуре, которую мы использовали ранее.
pynqz1 = Архитектура(
data_type = DataType.FP16BP8,
размер_массива=8,
драм0_глубина=1048576,
драм1_глубина=1048576,
локальная_глубина=8192,
глубина_аккумулятора=2048,
simd_registers_depth=1,
шаг0_глубина=8,
шаг1_глубина=8,
)
Далее давайте загрузим изображения CIFAR из test_batch .
деф unpickle (файл):
с открытым (файл, 'rb') как fo:
d = pickle.load(fo, encoding='bytes')
вернуть д
cifar = unpickle('/home/xilinx/cifar-10-batches-py/test_batch')
данные = cifar[b'data']
метки = cifar[b'labels']
данные = данные [10:20]
метки = метки[10:20]
data_norm = data.astype('float32') / 255
data_mean = np.mean (data_norm, ось = 0)
data_norm -= данные_среднее
cifar_meta = unpickle('/home/xilinx/cifar-10-batches-py/batches.meta')
label_names = [b.decode() для b в cifar_meta[b'label_names']]
определение show_img (данные, n):
plt.imshow (np.transpose (данные [n]. reshape ((3, 32, 32)), оси = [1, 2, 0]))
def get_img (данные, n):
img = np.transpose (data_norm [n]. reshape ((3, 32, 32)), оси = [1, 2, 0])
img = np.pad (img, [(0, 0), (0, 0), (0, tcu.arch.array_size - 3)], 'константа', Constant_values = 0)
вернуть img.reshape((-1, tcu.arch.array_size))
def get_label (метки, label_names, n):
label_idx = метки[n]
имя = label_names[label_idx]
возврат (label_idx, имя)
Для проверки извлеките одно из изображений.
н = 7 img = get_img (данные, n) label_idx, label = get_label(labels, label_names, n) show_img (данные, п)
Вы должны увидеть изображение.
Затем загрузите в драйвер манифест модели tmodel . Манифест сообщает драйверу, где найти два других двоичных файла (программа и данные о весе).
tcu.load_model('/home/xilinx/resnet20v2_cifar_onnx_pynqz1.tmodel')
Наконец, запустите модель и распечатайте результаты! Звонок на tcu.run(inputs) — вот где происходит волшебство. Мы преобразуем результирующий вектор классификации ResNet в метки CIFAR. Обратите внимание, что если вы используете модель ONNX, вход и выход имеют имена x:0 и Identity:0 соответственно. Для модели TensorFlow они называются x и Identity .
вводов = {'x:0': изображение}
начало = время.время()
выходы = tcu.run (входы)
конец = время. время()
print("Вывод выполнен в {:.4}s".format(конец - начало))
Распечатать()
классы = выходы['Идентификация:0'][:10]
result_idx = np.argmax (классы)
результат = label_names[result_idx]
print("Вывод активаций:")
печать (классы)
Распечатать()
print("Результат: {} (idx = {})".format(result, result_idx))
print("Фактическое: {} (idx = {})".format(label, label_idx))
время()
print("Вывод выполнен в {:.4}s".format(конец - начало))
Распечатать()
классы = выходы['Идентификация:0'][:10]
result_idx = np.argmax (классы)
результат = label_names[result_idx]
print("Вывод активаций:")
печать (классы)
Распечатать()
print("Результат: {} (idx = {})".format(result, result_idx))
print("Фактическое: {} (idx = {})".format(label, label_idx))
Вот ожидаемый результат:
Вывод за 0,1513 с Выходные активации: [-19,49609375 -12,37890625 -8,01953125 -6,01953125 -6,609375 -4,921875 -7,71875 2,0859375 -9,640625 -7,85546875] Результат: лошадь (idx = 7) Фактически: лошадь (idx = 7)
Поздравляем! Вы запустили модель машинного обучения на собственном ускорителе машинного обучения, созданном на собственной рабочей станции! Только представьте, что вы можете с ним сделать…
Подведение итогов
В этом руководстве мы использовали Tensil, чтобы показать, как запускать модели машинного обучения (ML) на FPGA. Мы прошли ряд шагов, чтобы добраться сюда, включая установку Tensil, выбор архитектуры, создание дизайна RTL, синтез дизайна, компиляцию модели ML и, наконец, выполнение модели с использованием PYNQ.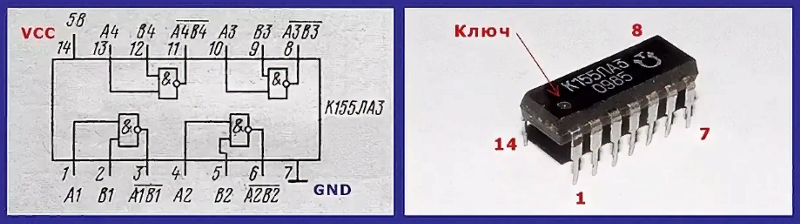
Если вы прошли весь путь, большие поздравления! Вы готовы выйти на новый уровень, опробовав собственную модель и архитектуру. Присоединяйтесь к нам в Discord, чтобы поздороваться и задать вопросы, или отправьте электронное письмо по адресу [email protected].
k155la техническое описание и примечания по применению
k155la техническое описание и примечания по применению - Архив технических описаний| Каталог Технический паспорт | MFG и тип | ПДФ | Теги документов |
|---|---|---|---|
МЗ 74141 Реферат: Тесла каталог MH74S04 MH74188 информационное приложение MH74S287 микроэлектроник RFT CDB404E ucy 74132 MZH 115 | OCR-сканирование | ||
Диод Е1110 Реферат: lN4002 LN4003 ANA 618 20010 TDB 0123 km b3170 E1110 Диод UB8560D MAA723 moc 2030 | OCR-сканирование | ||
К561ЛН2 Резюме: K561LA7 K176LA7 MC14520A K155LA3 K561TM2 K155ID3 TA5971 K561LE5 K155ID1 | Оригинал | К155АГ4 К155ИД1 К155ИД3 К155ИД4 К155ИД7 К155ИЭ10 К155ИЭ2 К155ИЭ4 К155ИЭ5 К155ИЕ6 К561ЛН2 К561ЛА7 К176ЛА7 MC14520A К155ЛА3 К561ТМ2 К155ИД3 ТА5971 К561ЛЕ5 К155ИД1 | |
 org/Product">
org/Product">