Как рассчитать класс точности прибора. Что такое абсолютная и относительная погрешность измерений. Как оценить точность результатов измерений. Какие бывают виды погрешностей измерительных приборов.
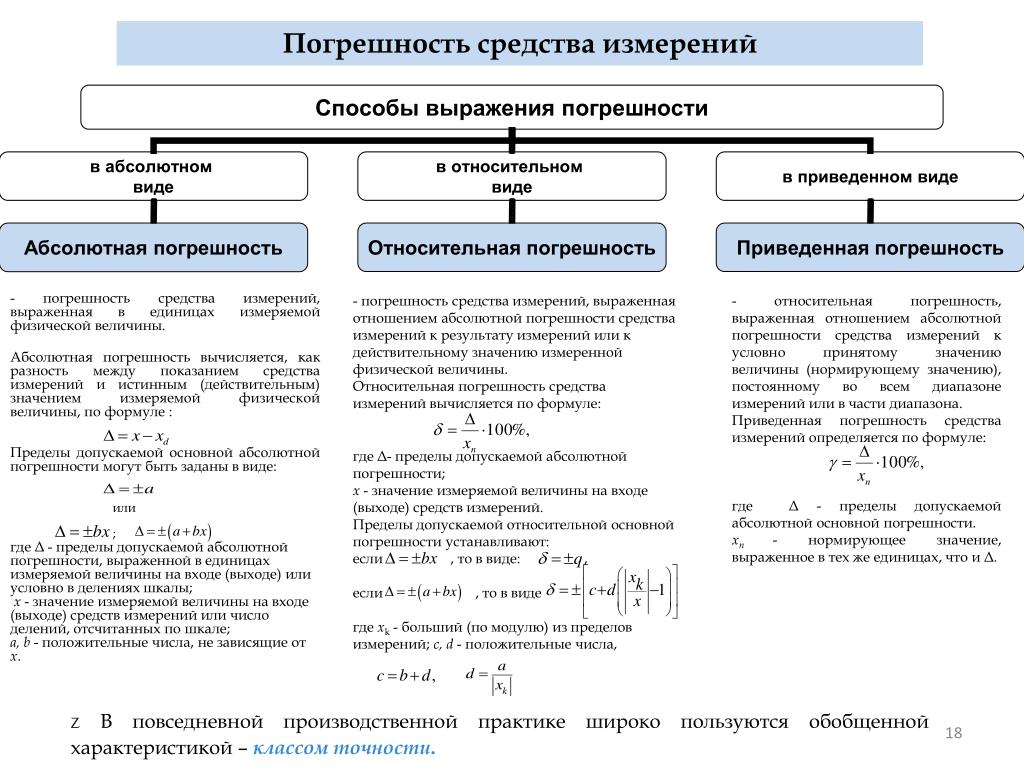
Основные понятия точности измерений
При проведении любых измерений важно понимать, насколько точны полученные результаты. Для оценки точности измерений используются следующие ключевые понятия:
- Абсолютная погрешность — отклонение измеренного значения от истинного, выраженное в единицах измеряемой величины
- Относительная погрешность — отношение абсолютной погрешности к истинному значению, выраженное в процентах
- Приведенная погрешность — отношение абсолютной погрешности к нормирующему значению (обычно верхнему пределу измерений)
- Класс точности прибора — обобщенная характеристика точности, выражаемая пределом допускаемой основной погрешности
Понимание этих понятий позволяет корректно оценивать точность измерений и выбирать подходящие приборы для конкретных задач.
Расчет абсолютной и относительной погрешности
Абсолютная погрешность Δx рассчитывается как разница между измеренным xизм и истинным xист значениями:
Δx = |xизм — xист|
Относительная погрешность δ определяется по формуле:
δ = (Δx / xист) * 100%
Например, если при измерении напряжения 220 В вольтметр показал 218 В, то:
Абсолютная погрешность: Δx = |218 — 220| = 2 В
Относительная погрешность: δ = (2 / 220) * 100% = 0.91%
Классы точности измерительных приборов
Класс точности — это обобщенная характеристика точности средства измерений, выражаемая пределами допускаемых основных и дополнительных погрешностей. Классы точности обозначаются числами или буквами латинского алфавита.
Для большинства электроизмерительных приборов класс точности определяется пределом допускаемой приведенной погрешности γ:
γ = (Δx max / xN) * 100%
где Δxmax — предел допускаемой абсолютной погрешности, xN — нормирующее значение (обычно верхний предел измерений).
Стандартные классы точности: 0.05; 0.1; 0.2; 0.5; 1.0; 1.5; 2.5; 4.0.

Методы оценки погрешностей измерений
Существует несколько основных методов оценки погрешностей результатов измерений:
- Метод границ — оценка максимально возможной погрешности
- Статистический метод — обработка результатов многократных измерений
- Метод попарного сравнения — сравнение результатов измерений двумя приборами
Выбор метода зависит от вида измерений, требуемой точности и имеющихся средств измерений. Наиболее универсальным является статистический метод.
Влияние различных факторов на точность измерений
На точность результатов измерений могут влиять различные факторы:
- Систематические погрешности приборов
- Случайные погрешности
- Влияние внешних условий (температура, влажность и др.)
- Квалификация оператора
- Методика проведения измерений
Для повышения точности важно учитывать и по возможности минимизировать влияние всех значимых факторов. Особое внимание следует уделять систематическим погрешностям.
Выбор средств измерений с учетом требуемой точности
При выборе измерительных приборов необходимо учитывать следующие факторы:

- Диапазон измерений
- Требуемая точность результата
- Условия проведения измерений
- Стоимость оборудования
Класс точности прибора должен быть как минимум в 3-4 раза выше требуемой точности результата. Например, для измерения напряжения с погрешностью не более 1% подойдет вольтметр класса точности 0.2 или 0.5.
Обработка результатов многократных измерений
При проведении многократных измерений одной величины используется следующий алгоритм обработки результатов:
- Вычисление среднего арифметического значения
- Определение среднеквадратического отклонения
- Исключение грубых погрешностей
- Оценка случайной погрешности
- Оценка неисключенной систематической погрешности
- Определение доверительных границ погрешности результата
Такой подход позволяет получить наиболее достоверную оценку измеряемой величины и погрешности измерений.
Нормирование точности измерений
Нормирование точности измерений включает:
- Установление допустимых погрешностей
- Выбор методов и средств измерений
- Определение условий измерений
- Установление правил обработки результатов
Нормы точности измерений устанавливаются в стандартах, технических условиях и других нормативных документах. Это обеспечивает единство измерений и требуемое качество продукции.

Заключение
Оценка точности измерений играет важнейшую роль в метрологии и обеспечении качества. Правильное понимание и применение методов оценки погрешностей позволяет получать достоверные результаты измерений и обоснованно выбирать средства измерений. Регулярный контроль и повышение точности измерений необходимы для развития науки и техники.
Предельной основной относительной — Студопедия.Нет
допускаемой приведенной
основной абсолютной
дополнительной суммарной
Знак «0,5» на шкале прибора означает, что класс точности определяется по _________ погрешности.
Приведенной
относительной
абсолютной
суммарной
Класс точности магнитоэлектрического миллиамперметра с конечным значением шкалы Iк = 0,5 мА для измерения тока I = 0,1 … 0,5 мА с относительной погрешностью измерения тока δI, не превышающей 1%, равен …
1,0
0,5
1,5
0,1
Если при поверке вольтметра с пределом измерения 500 В в точках 100, 200, 300, 400, 500 В получили соответственно следующие показания образцового прибора: 99,4; 200,7; 301,5; 400,8; 499,95, то класс точности вольтметра равен …0,2
1,5
1,0
0,1
Если при измерении электрического тока амперметром класса точности 1,5 с диапазоном измерения от 0 до 10 А температура окружающего воздуха составляет 10ºС, то предельная допускаемая абсолютная погрешность будет равна _____ А.
± 0,3
± 0,15
± 0,2
± 0,5
Если при измерении мощности ваттметром класса точности 1,0 с диапазоном измерения от 0 до 500 Вт показание прибора равно 245 Вт, погрешность градуировки шкалы составляет + 4 Вт, а температура окружающего воздуха 15º С, а то результат измерения должен быть представлен в виде…
(241 ± 7) Вт
(245 ± 5) Вт
(245 ± 8) Вт
Амперметр, имеющий класс точности 1,0 и предел измерения 5 А, измерит ток 3,5 А с относительной погрешностью не более ____ %.
1,4
1,5
0,05
1,0
Амперметр с классом точности 0,5 и пределом измерения 10 А измеряет ток 8 А с относительной погрешностью, не более ____ %.
0,625
0,5
0,05
1,0
Ваттметр, имеющий предел измерения 600 Вт, при измерении мощности 475 Вт с погрешностью не более 1,3% должен иметь класс точности …
1,0
1,5
0,5
2,5
Миллиамперметр при измерении силы тока показал значение 12,35 мА с погрешность ±0,115 мА. Согласно правилам округления, результат измерения должен быть представлен в виде …
Согласно правилам округления, результат измерения должен быть представлен в виде …
(12,35 ± 0,12) мА
(12,35 ± 0,1) мА
(12,4 ± 0,1) мА
(12 ± 0,1) Ма
Если при измерении электрического напряжения цифровым вольтметром получили значение 245,86 В, а погрешность составила ±3,75 В, то согласно правилам округления результат измерения должен быть представлен в виде …
(246 ± 4) В
(245 ± 3) В
(245,9 ± 3,8) В
(246 ± 3,8) В
Результат обработки многократных измерений мощности W = 350,458 Вт и ∆ = 0,613 Вт после округления примет вид …
(350,5 ± 0,6) Вт
(350,4 ± 0,6) Вт
(350 ± 1) Вт
(350,46 ± 0,61) Вт
Проведены 11 равноточных измерений мощности. Результаты следующие: 130,2; 130,3; 130,2; 130,3; 130,2; 129,6; 129,8; 129,9; 130,1; 129,9; 129,3 Вт. Результаты измерений распределены нормально, дисперсия неизвестна. Оцените доверительный интервал истинного значения для вероятности 0,99 (tР = 3,169).
Для измерения тока 10 мА использованы два прибора, имеющие пределы измерения 15 мА и 100 мА, класс точности 0,1. Абсолютные погрешности миллиамперметров будут равны _____ мА.
±0,015 и ±0,1
±0,5 и ±0,1
±0,015 и ±0,01
±0,25 и ±0,5
При измерении электрического напряжения вольтметром со шкалой от 0 до 300 В рабочий участок должен быть в пределах _____ В.
100 – 300
200 – 300
150 – 300
50 – 250
При измерениях рабочий участок шкалы SI должен выбираться по правилу: относительная погрешность в пределах рабочего участка шкалы SI не должна превышать приведенную погрешность более чем в ___ раз(а).
3
2
5
6
Если при проведении 8 измерений напряжения получены результаты: 267, 265, 269, 259, 270, 268, 263, 275 В, то среднеквадратическая погрешность результата единичных измерений в ряду измерений будет равна ___ В.
4,6
2,5
1,5
3,8
Если при измерении электрического напряжения вольтметром класса точности 1,5 с диапазоном измрения от 0 до 100В прибор показал 75В, а погрешность градуировки шкалы составляет + 2В, то результат измерения должен быть представлен в виде …
(73,0 ±1,5) В
(75.0 ±1,5) В
(77,0 ±1,5) В
(73 ±2) В
Точность измерения сопротивления 570 Ом с погрешностью 0,01 составляет …
100
5,7
5700
0,01
Для измерения тока использованы четыре прибора, имеющие следующие характеристики: первый – класса точности 0,1 с пределом измерения 15 мА; второй – класса точности 0,1 с пределом измерения 100 мА; третий – класса точности 0,5 с пределом измерения 15 мА; четвертый – класса точности 0,5 с пределом измерения 30 мА. Наибольшую точность измерения тока 10 мА обеспечит миллиамперметр …
1
2
3
4
При измерении напряжения U = 310 В вольтметром класса точности 0,4/0,2 с пределом измерения 450 В относительная погрешность будет равна _____ %.
±0,49
±0,6
±0,25
±0,15
Наибольшая возможная разница показаний при измерении напряжения вольтметрами класса точности 1,0 и 0,5 и пределами измерения 150 В и 300 В соответственно равна …
3
1,5
2,5
0,
Если необходимо контролировать силу электрического тока с точностью до 0,1 А, то амперметр следует выбирать с ценой деления ______ А.
0,1
0,01
0,05
1,0
Определенный интеграл вида называют …
Функцией Лапласа
неравенством Чебышева
нормальным законом распределения
равномерным распределением
Квантиль Лапласа обозначается буквой …
z
σ
D
χ2
Определить границы доверительного интервала для выборочного среднего арифметического значения измеряемой величины при нормальном законе распределения результатов измерений и известной дисперсии можно с помощью …
Распределения Лапласа
неравенства Чебышева
распределения Стьюдента
распределения Пирсона
Доверительный интервал для выборочного среднего арифметического значения измеряемой величины при неизвестном законе распределения результатов измерения и известной дисперсии можно оценить с помощью …
Неравенства Чебышева
распределения Лапласа
распределения Стьюдента
распределения Пирсона
Функция треугольного закона распределения (Симпсона) имеет вид …
Среднеквадратическая погрешность результата измерений среднего арифметического вычисляется по формуле …
Приведенная погрешность выражается отношением …
Любой член арифметической прогрессии можно вычислить по формуле …
Любой член геометрической прогрессии можно вычислить по формуле …
При бесконечном числе испытаний случайная величина может принимать любые значения, называемые …
Генеральной совокупностью
выборкой объема n
дисперсией
математическим ожиданием
В процедуру обработки однократных измерений не входит операция …
Гудков М В
1. Определить класс точности
магнитоэлектрического миллиамперметра
с конечным значением шкалы Iном
= 0,5 мА для
измерения тока от 0,1
до 0,5
мА так, чтобы относительная погрешность
измерения тока не превышала 1
%.
Определить класс точности
магнитоэлектрического миллиамперметра
с конечным значением шкалы Iном
= 0,5 мА для
измерения тока от 0,1
до 0,5
мА так, чтобы относительная погрешность
измерения тока не превышала 1
%.
2. В результате проверки амперметра установлено, что 80 % погрешностей результатов измерений, произведенных с его помощью, не превосходят 20 мА. Считая, что погрешности распределены по нормальному закону с нулевым математическим ожиданием, найти вероятность того, что погрешность результата измерения превзойдёт 40 мА.
3.
Известны математические ожидания и
средние квадратичные отклонения
сопротивлений R1
и R2:
m1=10
Ом, m2=20
Ом, 1=0,10
Ом, 2=0,14
Ом. Найти математическое ожидание и
среднеквадратичное отклонение отношения
сопротивлений последовательного
соединения сопротивлений R1
и R2
и параллельного R1║R2.
4
. К генератору гармонического напряжения с ЭДС E=1,000 В и частотой f=1,170 кГц подключена RC-цепь (R=10 кОм). Напряжение на конденсаторе измеряют вольтметром с входным сопротивлением Rвх=1 МОм и входной емкостью Cвх=120 пФ (рис.). Показания вольтметра U=0,686 В, его относительная погрешность может быть рассчитана по формуле U =0,2+0,02U0/U. U0 = 1 В. Записать результат измерений, если параметры E, f, R заданы с пределом допускаемой погрешности 0,1 %.5. Измерения амплитуды переменного напряжения U (В) на выходе трансформатора дали следующие результаты:
¦28.53¦27.73¦28.31¦28.50¦30.18¦29.13¦27.39¦28.26¦30.17¦29.82¦30.12¦28.16¦28.85¦29.58¦28. 70¦29.19¦29.47¦
29.04¦29.76¦28.42
70¦29.19¦29.47¦
29.04¦29.76¦28.42
5.1. Найти точечную оценку амплитуды переменного напряжения.
5.2. Построить доверительные интервалы при доверительной вероятности pd = 80 %, 90 %, 95 % для значения амплитуды переменного напряжения (t19 = 0.692, 2.120, 2.977 соответственно) и для дисперсии 2 (и = 11.651 и 27.204; 10.117 и 30.144; 8.907 и 32.852 соответственно).
5.3. При уровнях значимости q =20 %, 10 %, 5 % проверить гипотезы о равенстве значения амплитуды напряжения на выходе трансформатора U = 29.1, 29.25, 28.6 В.
6. Измерения этой же амплитуды напряжения другим способом дали следующие результаты:
28.56¦28.95¦29.00¦28.43¦28.74¦28.79¦28.01¦29.43¦28.72¦29.30¦30.42¦29.66¦29.39¦28.15¦28.85¦28.35¦29.39¦ 27.83¦ 28.97¦29.08¦29.21¦28.13¦29.64¦28.96¦29.30.
Для
уровней значимости q
= 10 %, 5 % и 1 %
проверить гипотезу о равенстве дисперсий
в задачах 5 и 6, если процентили Фишера
соответственно равны F19,24
= 1. 79, 2.11 и
2.92.
79, 2.11 и
2.92.
7. Проверить по критериям 3 и Грэббса (для уровней значимости q = 0.01, 0.05 и 0.1 величины vq,N = 3.2, 2.88 и 2.718 соответственно), есть ли в приведенных данных измерения постоянного тока I (мА) в цепи грубые ошибки.
58.82¦57.66¦57.98¦57.78¦57.69¦58.01¦59.12¦57.78¦56.83¦57.56¦57.40¦57.97¦57.97¦58.43¦58.29¦58.95¦58.34¦ 57.67¦57.75¦57.68¦57.88¦56.82¦57.82¦57.75¦57.51
8. Милливольтметр магнитоэлектрической системы с верхним пределом измерения 75 мВ имеет внутреннее сопротивление 15 Ом. Рассчитайте сопротивление шунта, необходимого для использования прибора в качестве амперметра с верхним пределом I=15 А, и величину добавочного сопротивления для использования прибора в качестве вольтметра на 150 В. Приведите схемы включения.
9.
Определить показания электродинамического
A1
и электромагнитного A2
амперметров, включенных в последовательную
цепь RL
(R=18
Ом, L=13
мГн), если
напряжение на входе цепи изменяется по
закону u(t)
= 100+ 21sin3t
+15sin5t. Начертить схему включения приборов и
построить график зависимости показаний
приборов от частоты. На какой частоте
показания амперметров будут составлять
80 % от максимально возможного значения.
Начертить схему включения приборов и
построить график зависимости показаний
приборов от частоты. На какой частоте
показания амперметров будут составлять
80 % от максимально возможного значения.
1
0. Требуется измерить сопротивление, приближенно равное 5 Ом, с погрешностью не более 0,2 %. По какой схеме надо производить измерение (рис.) с помощью амперметра и вольтметра и какое сопротивление должен иметь прибор для выполнения указанных условий?11. Для измерения индуктивности катушки используется мост переменного тока с образцовой катушкой индуктивности, параметры которой 120 мГн и 25 Ом. Чему должно быть равно активное сопротивление, и в какое плечо моста (последовательно с образцовой или измеряемой катушкой) его необходимо включить для достижения равновесия моста, если параметры измеряемой катушки 400 мГн и 75 Ом?
12. Определить параметры подаваемого от
генератора на последовательную RC-цепочку
(10 кОм, 0,1мкФ) синусоидального сигнала,
напряжением которого осуществлена
развертка. Диаметр круговой развертки
равен шести делениям, коэффициенты
отклонения луча вертикального и
горизонтального каналов составляют 5
В/дел. Шкала вольтметра генератора
отградуирована в действующих значениях
синусоидального сигнала.
Диаметр круговой развертки
равен шести делениям, коэффициенты
отклонения луча вертикального и
горизонтального каналов составляют 5
В/дел. Шкала вольтметра генератора
отградуирована в действующих значениях
синусоидального сигнала.
13. К входу анализатора спектра одновременного анализа подведено гармоническое напряжение с неизвестной амплитудой, не совпадающее по частоте ни с резонансной частотой ни одного из фильтров. На экране получено несколько выбросов разной высоты. Составить уравнение для расчета точного значения частоты сигнала, если фильтры имеют одинаковую известную добротность Q, а высота выбросов , где , K – постоянный коэффициент, зависящий от амплитуды сигнала, fs – частота сигнала, fri – резонансная частота контура, i – номер наблюдаемого выброса. Сколько выбросов необходимо измерить?
14. Определить показания электродинамического
вольтметра, если измеряемое напряжение
имеет форму кривой, изображённой на
рис. Погрешностями прибора пренебречь.
Погрешностями прибора пренебречь.
Решение
Для магнитоэлектрического миллиамперметра класс точности определяется
значением максимальной приведенной погрешности, т.е. = ±2,5 %.
Так как
,
то предел инструментальной абсолютной погрешности
(мА).
Миллиамперметр имеет равномерную шкалу с нулем в начале шкалы. Поэтому
XN = 25 (мА),
.
Предел инструментальной относительной погрешности
.
Задача № 35
Выбрать
магнитоэлектрический вольтметр или
амперметр со стандартными пределами
измерения и классом точности при условии,
что результат измерения напряжения или
тока должен отличаться от действительного
значения Q не более чем на
. Стандартные пределы измерения для
вольтметра …10, 30, 100, 300 В, для амперметра
– … 10 , 30 , 100 , 300 , 1000 мА. Выбор необходимого
предела измерения и класса точности
обосновать. Данные о значениях Q иприведены в таблице 6.
Стандартные пределы измерения для
вольтметра …10, 30, 100, 300 В, для амперметра
– … 10 , 30 , 100 , 300 , 1000 мА. Выбор необходимого
предела измерения и класса точности
обосновать. Данные о значениях Q иприведены в таблице 6.
Ток I = Q2 =36 мА, допустимое предельное отклонение результата 2=1,2 мА.
Решение
Для магнитоэлектрического миллиамперметра класс точности определяется
значением максимальной приведенной погрешности
Найдем предел относительной погрешности
= ±(/I)100 %=±(1.2/36)100 %=3.33 %
Относительна погрешность не должна превышать 3,33%
Примем класс точности 1.0
Так как максимальная приведенная погрешность
,
Определим предел измерения
Выберем
стандартное значение предела измерения
XN=300
мА.
Для измерения тока 36мА с допустимым предельным отклонением 1,2мА, используем магнитоэлектрический миллиамперметр класса 1,0 с пределом 300 мА.
Задача № 47
Сигнал синусоидальной формы после мостового выпрямителя, характеризующийся коэффициентами амплитуды Ка = 1,41 и формы Кф = 1,11, подан в положительной полярности на вольтметр с классом точности . Значение приведено в таблице 10. =0,2
B
задачах 45–47 необходимо определить
пиковое Um, среднее квадратическое Uск
и средневыпрямленное UСВ
значения напряжения, поданного на вход
электронного вольтметра с пиковым
детектором, закрытым входом, со шкалой,
проградуированной проградуированной
в среднеквадратических значениях
синусоидального напряжения. Показание
вольтметра U=8,0
(таблица 10). Оценить также пределы
основных инструментальных абсолютной
и относительной погрешностей измерения
U, выбрав необходимый предел измерения
из ряда предпочтительных чисел . .. 3; 10;
30; 100 … В.
.. 3; 10;
30; 100 … В.
Решение
Поскольку вид измеряемого напряжения определяется типом детектора, то можно сделать вывод, что вольтметр измеряет пиковое значение входного напряжения. Однако шкала вольтметра проградуирована в среднеквадратических значениях синусоидального напряжения. В этом случае мы должны показания вольтметра умножить на градуировочный коэффициент, определяемый как отношение параметра напряжения, в значениях которого проградуирована шкала, к параметру напряжения, соответствующего типу детектора.
Пиковое значение напряжения
Um = 1,41U=1,418=11,28 В.
Известно что коэффициент амплитуды
КА = Um/Uск,
Следовательно среднеквадраческое значение
Uск = Um/КА=11,28/1,41= 8 В
Коэффициент формы определяется по формуле
КФ = Uск/Uсв,
Средневыпрямленное значении напряжения
Uсв = Uск/ КФ = 8/1,11=7,207 В
Предел относительной погрешности измерения:
=±(/U)100 %
Для вольтметра с классом точности 0,2 %, предел инструментальной абсолютной погрешности
=±(U)/100
%=±0,28/100=0,016
В.
Определим предел измерения
Выберем стандартный предел 10В. Предел приведенной погрешности для этого предела В. Относительная погрешность
= ±(0,02/8)100 %=0,25%.
Точность, точность, отзывчивость и оценка F1: интерпретация показателей производительности
Как оценить производительность модели в Azure ML и понять «метрики путаницы»
В этом блоге показано, как оценить производительность модели с помощью показателей Accuracy, Precision, Recall и F1 Score в Azure ML, а также дается краткое объяснение «метрик путаницы». В этом эксперименте я использовал двухклассовый алгоритм ускоренного дерева решений, и моя цель — предсказать выживаемость пассажиров на Титанике.
После того, как вы построили свою модель, возникает самый важный вопрос: насколько хороша ваша модель? Итак, оценка вашей модели — самая важная задача в проекте по науке о данных, который определяет, насколько хороши ваши прогнозы.
На следующем рисунке показаны результаты модели, которую я построил для проекта, над которым я работал во время моей стажировки в Exsilio Consulting этим летом.
Рис. Результаты оценки классификационной модели
Давайте углубимся во все параметры, показанные на рисунке выше.
Первое, что вы увидите здесь, это кривая ROC, и мы можем определить, является ли наша кривая ROC хорошей или нет, посмотрев на AUC (площадь под кривой) и другие параметры, которые также называются метриками путаницы. Матрица неточностей — это таблица, которая часто используется для описания производительности модели классификации на наборе тестовых данных, истинные значения которых известны. Все показатели, кроме AUC, можно рассчитать с использованием крайних левых четырех параметров. Итак, давайте сначала поговорим об этих четырех параметрах.
Истинно положительные и истинно отрицательные наблюдения — это правильно предсказанные наблюдения, которые показаны зеленым цветом. Мы хотим свести к минимуму ложные срабатывания и ложные отрицания, чтобы они отображались красным цветом. Эти термины немного сбивают с толку. Итак, давайте рассмотрим каждый термин один за другим и поймем его полностью.
Мы хотим свести к минимуму ложные срабатывания и ложные отрицания, чтобы они отображались красным цветом. Эти термины немного сбивают с толку. Итак, давайте рассмотрим каждый термин один за другим и поймем его полностью.
Истинные положительные (TP) — это правильно спрогнозированные положительные значения, которые означают, что значение фактического класса — да, а значение прогнозируемого класса — также да.Например. если фактическое значение класса указывает, что этот пассажир выжил, и предсказанный класс говорит вам то же самое.
Истинные отрицательные значения (TN) — Это правильно спрогнозированные отрицательные значения, что означает, что значение фактического класса равно «нет», а значение предсказанного класса также равно «нет». Например. если фактический класс говорит, что этот пассажир не выжил, а предсказанный класс говорит вам то же самое.
Ложные срабатывания и ложные отрицания, эти значения возникают, когда ваш фактический класс противоречит предсказанному классу.
Ложные срабатывания (FP) — Когда фактический класс — нет, а прогнозируемый — да. Например. если фактический класс говорит, что этот пассажир не выжил, но предсказанный класс говорит вам, что этот пассажир выживет.
Ложноотрицательные (FN) — Когда фактический класс — да, а прогнозируемый класс — нет. Например. если фактическое значение класса указывает, что этот пассажир выжил, а прогнозируемый класс говорит вам, что пассажир умрет.
Как только вы поймете эти четыре параметра, мы сможем рассчитать точность, точность, отзыв и оценку F1.
Точность — Точность является наиболее интуитивно понятным показателем производительности и представляет собой просто отношение правильно спрогнозированного наблюдения к общему количеству наблюдений. Можно подумать, что если у нас высокая точность, то наша модель лучше всего. Да, точность — отличный показатель, но только когда у вас есть симметричные наборы данных, в которых значения ложноположительных и ложноотрицательных результатов почти одинаковы. Следовательно, вам нужно посмотреть на другие параметры, чтобы оценить производительность вашей модели. Для нашей модели у нас 0.803, что означает, что наша модель прибл. 80% точность.
Следовательно, вам нужно посмотреть на другие параметры, чтобы оценить производительность вашей модели. Для нашей модели у нас 0.803, что означает, что наша модель прибл. 80% точность.
Точность = TP + TN / TP + FP + FN + TN
Точность — Точность — это отношение правильно предсказанных положительных наблюдений к общему количеству предсказанных положительных наблюдений. Вопрос в том, что этот метрический ответ касается всех пассажиров, помеченных как выжившие, сколько на самом деле выжило? Высокая точность связана с низким уровнем ложных срабатываний. У нас точность 0,788, что очень хорошо.
Точность = TP / TP + FP
Отзыв (Чувствительность) — Отзыв — это отношение правильно предсказанных положительных наблюдений ко всем наблюдениям в реальном классе — да.Ответ на этот вопрос: сколько пассажиров мы пометили? У нас есть отзыв 0,631, что хорошо для этой модели, так как оно выше 0,5.
Отзыв = TP / TP + FN
Оценка F1 — Оценка F1 представляет собой средневзвешенное значение точности и запоминания. Таким образом, эта оценка учитывает как ложные срабатывания, так и ложные отрицательные результаты. Интуитивно это не так просто понять, как точность, но F1 обычно более полезен, чем точность, особенно если у вас неравномерное распределение классов.Точность работает лучше всего, если ложные срабатывания и ложные отрицания имеют одинаковую стоимость. Если стоимость ложных срабатываний и ложноотрицательных результатов сильно различается, лучше смотреть как на точность, так и на отзыв. В нашем случае оценка F1 составляет 0,701.
Таким образом, эта оценка учитывает как ложные срабатывания, так и ложные отрицательные результаты. Интуитивно это не так просто понять, как точность, но F1 обычно более полезен, чем точность, особенно если у вас неравномерное распределение классов.Точность работает лучше всего, если ложные срабатывания и ложные отрицания имеют одинаковую стоимость. Если стоимость ложных срабатываний и ложноотрицательных результатов сильно различается, лучше смотреть как на точность, так и на отзыв. В нашем случае оценка F1 составляет 0,701.
Оценка F1 = 2 * (отзыв * точность) / (отзыв + точность)
Итак, всякий раз, когда вы строите модель, эта статья должна помочь вам выяснить, что означают эти параметры и насколько хорошо ваша модель работает.
Надеюсь, этот блог был вам полезен.Пожалуйста, оставьте комментарии или отправьте мне электронное письмо, если вы считаете, что я пропустил какие-либо важные детали, или если у вас есть другие вопросы или отзывы по этой теме.
** Обратите внимание, что приведенные выше результаты и анализ чисел основаны на модели Титаника. Ваши числа и результаты могут отличаться в зависимости от модели, над которой вы работаете, и вашего конкретного бизнес-варианта использования.
Ваши числа и результаты могут отличаться в зависимости от модели, над которой вы работаете, и вашего конкретного бизнес-варианта использования.
Видео по теме: https://www.youtube.com/channel/UC9jOb7yEfGwxjjdpWMjmKJA
Автор: Ренука Джоши (стажер в Exsilio)
Исправление ошибок | TeachingEnglish | British Council
Опасность чрезмерного исправления заключается в том, что учащиеся потеряют мотивацию, и вы даже можете нарушить ход занятия или деятельности, вмешиваясь и исправляя каждую ошибку.Другая крайность — позволить разговору течь и не исправлять ошибок. Бывают случаи, когда это уместно, но большинство студентов действительно хотят, чтобы некоторые их ошибки были исправлены, поскольку это дает им основу для совершенствования.
Итак, вопрос: Когда и как нужно исправлять своих учеников?
У каждого учителя будут разные взгляды на это и разные способы исправления своих учеников, и это тот случай, когда нужно выяснить, что и вам, и вашим ученикам удобно. Я хотел бы предложить несколько идей, как это сделать.
Я хотел бы предложить несколько идей, как это сделать.
Спросите учащихся, как они хотят, чтобы их исправили
- Звучит очевидно, но это легко не заметить. Поговорите со своими учениками об исправлении ошибок и узнайте у них, как они хотят, чтобы их исправляли. Часто у студентов есть четкое представление о том, как они хотели бы, чтобы вы их исправили. В больших группах вам, возможно, придется пойти с большинством, но если у вас небольшая группа, вы можете удовлетворить индивидуальные потребности.
- Один из способов дать учащимся возможность выбора того, насколько они хотят, чтобы их исправляли в конкретном классе или конкретном мероприятии, — это поставить светофор на свои парты. Полоска карточки с тремя кружками (один красный, один оранжевый и один зеленый), сложенная в треугольник с небольшим количеством скотча, делает свое дело. Учащиеся указывают кружком на вас, чтобы указать, хотят они исправления или нет:
o Красный = меня вообще не поправляют (возможно, у них был тяжелый день или они устали!)
o Оранжевый = исправляйте то, что действительно важно, или то, что я должен знать.
o Зеленый = исправьте как можно больше, пожалуйста.
Вы работаете над точностью или беглостью?
- Перед тем, как начать какое-либо занятие, помните, уделяете ли вы внимание точности или беглости. Например, для обсуждения в классе подойдет беглость. Важно то, что ученики выражают себя и думают на ногах. Однако, если у студентов было время подготовить ролевую игру, а затем они собираются ее провести, вы можете поощрять точность.Четко сформулируйте цели задания и убедитесь, что учащиеся осознают, чего вы от них ожидаете. Не представляйте занятие как задание на беглость, а затем отбирайте его после каждой ошибки.
Самокоррекция / Коррекция сверстников
- Первым портом захода при исправлении могут быть сами студенты. Студенты часто могут исправить себя, когда понимают, что сделали ошибку. Иногда ошибка — это просто «промах», и они знают правильную версию.Дайте студентам шанс и время исправить себя.
 Часто, просто поднимая брови или повторяя ошибку, ученики поймут, что вы имеете в виду, и вернутся, чтобы исправить ошибку самостоятельно. Некоторые учителя создают всевозможные жесты руками, чтобы обозначить тип ошибки. Указывать назад — это классический способ указать учащимся, что им следовало использовать прошедшее время. Если это работает для вас и ваших учеников, создайте свои собственные индикаторы коррекции.
Часто, просто поднимая брови или повторяя ошибку, ученики поймут, что вы имеете в виду, и вернутся, чтобы исправить ошибку самостоятельно. Некоторые учителя создают всевозможные жесты руками, чтобы обозначить тип ошибки. Указывать назад — это классический способ указать учащимся, что им следовало использовать прошедшее время. Если это работает для вас и ваших учеников, создайте свои собственные индикаторы коррекции. - Студенты также могут поправлять друг друга.Коррекция сверстников часто помогает создать позитивную атмосферу в классе, так как ученики понимают, что вы не единственный источник исправления ошибок, и они могут многому научиться друг у друга.
Пазы для коррекции
- Один из способов сосредоточить внимание на ошибках учащихся — взять «перерыв» в работе и посмотреть на ошибки в группе. Когда учащиеся выполняют задание на устную речь в парах или группах, я часто наблюдаю за учащимися и слушаю, что они говорят. Студенты привыкнут к тому, что вы парите вокруг них, хотя, если это не ваш обычный стиль наблюдения, они могут сначала задаться вопросом, чем вы занимаетесь! Я записываю ошибки, которые слышу; будь то произношение, грамматика или лексика.
 Я собираю их ошибки и прекращаю работу. Я записываю на доске подборку ошибок и прошу студентов исправить их. Если ученики работают в парах, а у вас есть оставшийся ученик, почему бы не назначить им роль помощников учителя? У них может быть блокнот и ручка, и они могут записывать ошибки, которые слышат. Если они будут хорошо выполнять свою работу, они могут даже запустить исправление своих ошибок вместо вас. Обычно большинство ошибок студенты могут исправить самостоятельно.
Я собираю их ошибки и прекращаю работу. Я записываю на доске подборку ошибок и прошу студентов исправить их. Если ученики работают в парах, а у вас есть оставшийся ученик, почему бы не назначить им роль помощников учителя? У них может быть блокнот и ручка, и они могут записывать ошибки, которые слышат. Если они будут хорошо выполнять свою работу, они могут даже запустить исправление своих ошибок вместо вас. Обычно большинство ошибок студенты могут исправить самостоятельно.
Коррекция на месте
- Исправление ошибок сразу после того, как они были сделаны, имеет то преимущество, что вам не нужно останавливать деятельность, как в случае со слотом для исправления. Студенты часто ценят мгновенную коррекцию. Подумайте, что это за вид деятельности, прежде чем решать, стоит ли исправлять на месте. Вы не хотите мешать выполнению задачи, вмешиваясь в нее. Студенты также могут нести ответственность за исправление на месте, если их поощряют замечать ошибки друг друга.

Новые ошибки или те же старые?
- Я всегда напоминаю студентам, что если они постоянно совершают новые ошибки, это нормально. Новые ошибки обычно являются признаком того, что они изучают новые способы использования языка или экспериментируют с новым словарным запасом, но если они всегда повторяют одни и те же ошибки, это не такой уж хороший знак! Отмечая свои ошибки, учащиеся фиксируют свой прогресс и могут избежать повторения одних и тех же ошибок снова и снова. Было бы неплохо иметь в их блокнотах место для записи ошибок и правильной версии.Один из способов сделать это — разделить страницу на три столбца:
| Ошибка | Поправка | Примечание |
| Зависит от погоды | Зависит от погоды | Не то же самое, что на испанском |
| Я живу в Барселоне шесть лет | Я живу в Барселоне шесть лет |
С — для моментов времени За — За периоды |
- Иногда полезно провести небольшие тесты, основанные на классических ошибках, которые ученики совершают в классе.
 Он побуждает студентов просматривать свои записи и пытаться извлечь из них уроки.
Он побуждает студентов просматривать свои записи и пытаться извлечь из них уроки.
Заключение
- Каким бы способом вы ни исправляли своих учеников, постарайтесь, чтобы этот опыт оставался положительным для учащихся. Постоянные исправления могут действительно демотивировать, как знает каждый изучающий язык. Когда вы прислушиваетесь к ошибкам своих учеников, убедитесь, что вы также прислушиваетесь к действительно хорошему использованию языка, и подчеркните их также в группе.Что касается изучения языка, я действительно верю классической поговорке: «Вы учитесь на своих ошибках».
Полезные ссылки:
http://www.teachingenglish.org.uk/article/error-correction-1
http://www.teachingenglish.org.uk/article/error-correction-2
https: / /www.teachingenglish.org.uk/article/writing-correction-code
Впервые опубликовано в 2008 году.
Общие сведения о параметрах LightGBM (и как их настраивать)
Я использую lightGBM уже некоторое время. Это был мой алгоритм решения большинства проблем с табличными данными. Список замечательных функций велик, и я предлагаю вам взглянуть, если вы еще этого не сделали.
Это был мой алгоритм решения большинства проблем с табличными данными. Список замечательных функций велик, и я предлагаю вам взглянуть, если вы еще этого не сделали.
Но мне всегда было интересно понять, какие параметры имеют наибольшее влияние на производительность и как мне настроить параметры lightGBM, чтобы получить от этого максимальную отдачу.
Я решил, что мне нужно провести небольшое исследование, узнать больше о параметрах LightGBM… и поделиться своим опытом.
Конкретно I:
По мере того, как я делал это, я получил гораздо больше знаний о параметрах lightGBM.Надеюсь, что после прочтения этой статьи вы сможете ответить на следующие вопросы:
- Какие методы повышения градиента реализованы в LightGBM и в чем их отличия?
- Какие параметры в целом важны?
- Какие параметры регуляризации необходимо настроить?
- Как настроить параметры lightGBM в Python?
Методы усиления градиента
С LightGBM вы можете запускать различные типы методов повышения градиента. У вас есть: GBDT, DART и GOSS, которые можно указать с помощью параметра
У вас есть: GBDT, DART и GOSS, которые можно указать с помощью параметра boost .
В следующих разделах я объясню и сравню эти методы друг с другом.
lgbm gbdt (деревья решений с градиентным усилением)
Этот метод представляет собой традиционное дерево решений градиентного усиления, которое было впервые предложено в этой статье и является алгоритмом, лежащим в основе некоторых замечательных библиотек, таких как XGBoost и pGBRT.
В наши дни gbdt широко используется из-за его точности, эффективности и стабильности.Вы, наверное, знаете, что gbdt представляет собой ансамблевую модель деревьев решений, но что именно это означает?
СВЯЗАННЫЕ С
Общие сведения об отсечении градиентов (и способах устранения проблемы с растущими градиентами)
Позвольте мне рассказать вам суть.
Он основан на трех важных принципах:
- Слабые ученики (деревья решений)
- Оптимизация градиента
- Техника усиления
Итак, в методе gbdt у нас есть много деревьев решений (слабые ученики). Эти деревья строятся последовательно:
Эти деревья строятся последовательно:
- первое дерево учится соответствовать целевой переменной
- второе дерево учится соответствовать остатку (разнице) между предсказаниями первого дерева и основной истиной
- Третье дерево учится соответствовать остаткам второе дерево и так далее.
Все эти деревья обучаются путем распространения градиентов ошибок по всей системе.
Главный недостаток gbdt заключается в том, что поиск лучших точек разбиения в каждом узле дерева требует много времени и памяти, и другие методы повышения уровня пытаются решить эту проблему.
дротиковое повышение градиента
В этой выдающейся статье вы можете узнать все о повышении градиента DART, которое представляет собой метод, использующий выпадение, стандартный в нейронных сетях, для улучшения регуляризации модели и решения некоторых других менее очевидных проблем.
А именно, gbdt страдает излишней специализацией, что означает, что деревья, добавленные на более поздних итерациях, имеют тенденцию влиять на прогноз только нескольких экземпляров и вносить незначительный вклад в оставшиеся экземпляры. Добавление исключения затрудняет специализацию деревьев на более поздних итерациях на этих нескольких выборках и, следовательно, повышает производительность.
Добавление исключения затрудняет специализацию деревьев на более поздних итерациях на этих нескольких выборках и, следовательно, повышает производительность.
lgbm goss (односторонняя выборка на основе градиента)
Фактически, наиболее важной причиной для наименования этого метода lightgbm является использование метода Госса, основанного на этой статье. Goss — это более новая и легкая реализация gbdt (отсюда «легкий» gbm).
Стандартный gbdt надежен, но недостаточно быстр для больших наборов данных.Следовательно, goss предлагает метод выборки, основанный на градиенте, чтобы избежать поиска всего пространства поиска. Мы знаем, что для каждого экземпляра данных, когда градиент мал, это означает, что данные не о чем беспокоятся, а когда градиент большой, их следует повторно обучать. Итак, у нас есть с двух сторон, здесь, экземпляры данных с большим и малым градиентами. Таким образом, goss сохраняет все данные с большим градиентом и выполняет случайную выборку (, поэтому она называется односторонней выборкой ) для данных с небольшим градиентом. Это делает пространство поиска меньше, и споры могут сходиться быстрее. Наконец, чтобы получить больше информации о goss, вы можете проверить это сообщение в блоге.
Это делает пространство поиска меньше, и споры могут сходиться быстрее. Наконец, чтобы получить больше информации о goss, вы можете проверить это сообщение в блоге.
Сведем эти различия в таблицу:
| Методы | Примечание | Необходимо изменить эти параметры | Преимущество | Недостаток |
|---|---|---|---|---|
| ЛГБМ ГБДТ | Это тип повышения по умолчанию. | Поскольку gbdt является параметром по умолчанию для lgbm, вам не нужно изменять значение остальных параметров для него.(все-таки тюнинг необходим!) | Стабильный и надежный | Чрезмерная специализация Требует много времени Потребляет память |
| Дротик ЛГБМ | Попытайтесь решить проблему сверхспециализации в gbdt | drop_seed: случайное начальное число для выбора моделей отбрасыванияUniform_dro: установите значение true, если вы хотите использовать равномерное dropxgboost_dart_mode: установите значение true, если вы хотите использовать режим xgboost dartskip_drop: вероятность пропуска процедуры исключения во время итерации повышения max_dropdrop_rate: dropout процент: доля предыдущих деревьев, которые выпадают во время выпадения | Лучше точность | Слишком много настроек |
| ЛГБМ Госс | Goss предоставляет новый метод выборки для GBDT, разделяя эти экземпляры более крупными градиентами. |
top_rate: коэффициент удержания данных большого градиента; other_rate: коэффициент удержания данных малого градиента | Быстрая сходимость | Переоснащение, когда набор данных SMA |
Примечание:
Если вы установите усиление как RF, тогда алгоритм lightgbm ведет себя как случайный лес, а не деревья с усилением! Согласно документации, чтобы использовать RF, вы должны использовать bagging_fraction и feature_fraction меньше 1.
Регуляризация
В этом разделе я расскажу о некоторых важных параметрах регуляризации lightgbm. Очевидно, что это те параметры, которые вам нужно настроить, чтобы бороться с переобучением.
Вы должны знать, что для небольших наборов данных (<10000 записей) lightGBM может быть не лучшим выбором. Настройка параметров lightgbm может вам не помочь.
Кроме того, lightgbm использует алгоритм роста дерева по листьям, а XGBoost использует рост дерева по глубине.Листовой метод позволяет деревьям сходиться быстрее, но увеличивается вероятность перегиба.
Возможно, этот доклад на одной из конференций PyData даст вам больше информации о Xgboost и Lightgbm. Стоит посмотреть!
Примечание:
Если кто-то спросит, в чем основное отличие LightGBM от XGBoost? Вы легко можете сказать, их отличие в том, как они реализованы.
Согласно документации lightGBM, когда вы сталкиваетесь с переоборудованием, вы можете захотеть выполнить следующую настройку параметров:
- Используйте small max_bin
- Используйте small num_leaves
- Используйте min_data_in_leaf и min_sum_hessian_in_leaf
- Используйте упаковку с помощью set bagging_fraction и bagging_freq
- Используйте подвыборку функции с помощью set feature_fraction
- Используйте большие обучающие данные lambda_fraction
- Используйте большие обучающие данные регуляризация
- Попробуйте max_depth, чтобы избежать роста глубокого дерева
В следующих разделах я объясню каждый из этих параметров более подробно.
лямбда_l1
Lambda_l1 (и lambda_l2) контролирует l1 / l2 и вместе с min_gain_to_split используются для борьбы с переоснащением . Я настоятельно рекомендую вам использовать настройку параметров (рассмотренную в следующем разделе), чтобы найти наилучшие значения для этих параметров.
число_листов
Несомненно, num_leaves — один из наиболее важных параметров, который контролирует сложность модели.(max_depth) , однако, учитывая, что в lightgbm листовое дерево глубже, чем дерево по уровням, вы должны быть осторожны с переобучением! В результате необходимо настроить num_leaves вместе с max_depth .
подвыборка
С помощью subsample (или bagging_fraction) вы можете указать процент строк, используемых на итерацию построения дерева. Это означает, что некоторые строки будут случайным образом выбраны для соответствия каждому учащемуся (дереву).Это улучшило обобщение, но также улучшило скорость обучения.
Это означает, что некоторые строки будут случайным образом выбраны для соответствия каждому учащемуся (дереву).Это улучшило обобщение, но также улучшило скорость обучения.
Я предлагаю использовать меньшие значения подвыборки для базовых моделей и позже увеличивать это значение, когда вы закончите с другими экспериментами (другой выбор функций, другая древовидная архитектура).
feature_fraction
Доля функций или sub_feature связана с выборкой столбцов, LightGBM будет случайным образом выбирать подмножество функций на каждой итерации (дереве). Например, если вы установите его на 0.6, LightGBM выберет 60% функций перед обучением каждого дерева.
Для этой функции есть два использования:
- Можно использовать для ускорения обучения
- Можно использовать при переобучении
макс_глубина
Этот параметр управляет максимальной глубиной каждого обученного дерева и влияет на:
- Наилучшее значение для параметра num_leaves
- Производительность модели
- Время обучения
Обратите внимание Если вы используете большое значение max_depth , ваша модель, вероятно, будет на больше , чем для набора поездов.
макс_бин
Биннинг — это метод представления данных в дискретном виде (гистограмма). Lightgbm использует алгоритм на основе гистограммы, чтобы найти оптимальную точку разделения при создании слабого ученика. Следовательно, каждую непрерывную числовую функцию (например, количество просмотров видео) следует разделить на отдельные ячейки.
Кроме того, в этом репозитории GitHub вы можете найти несколько комплексных экспериментов, которые полностью объясняют влияние изменения max_bin на CPU и GPU.
Если вы определяете max_bin 255, это означает, что у нас может быть максимум 255 уникальных значений для каждой функции. Тогда маленький max_bin вызывает более высокую скорость, а большое значение повышает точность.
Параметры обучения
Время обучения! Если вы хотите обучить свою модель с помощью lightgbm, некоторые типичные проблемы, которые могут возникнуть при обучении моделей lightgbm:
- Обучение — это трудоемкий процесс
- Работа с вычислительной сложностью (ограничения ОЗУ ЦП / ГП)
- Работа с категориальными характеристиками
- Несбалансированный набор данных
- Потребность в пользовательских метриках
- Необходимые корректировки для Проблемы классификации или регрессии
В этом разделе мы постараемся подробно объяснить эти моменты.
число_тераций
Num_iterations указывает количество итераций повышения (деревья для построения). Чем больше деревьев вы построите, тем более точной будет ваша модель по цене:
.- Более длительное время обучения
- Более высокая вероятность переобучения
Начните с меньшего количества деревьев, чтобы построить базовую линию, и увеличивайте ее позже, когда вы хотите выжать последний% из вашей модели.
Рекомендуется использовать меньшую скорость обучения с большим числом итераций .Кроме того, вы должны использовать early_stopping_rounds, если вы выбираете более высокие num_iterations, чтобы остановить свое обучение, когда оно не изучает ничего полезного.
Early_stopping_rounds
Этот параметр остановит обучение , если метрика проверки не улучшится после последнего раунда ранней остановки. Это должно быть определено в паре с номером итераций . Если вы установите его слишком большим, вы увеличите изменение по сравнению с (но ваша модель может быть лучше).
Если вы установите его слишком большим, вы увеличите изменение по сравнению с (но ваша модель может быть лучше).
Практическое правило — иметь его на уровне 10% от ваших num_iterations.
световой гигабайт category_feature
Одним из преимуществ использования lightgbm является то, что он очень хорошо справляется с категориальными функциями. Да, этот алгоритм очень мощный, но вы должны быть осторожны с его параметрами. lightgbm использует специальный метод с целочисленным кодированием (предложенный Fisher ) для обработки категориальных признаков
Эксперименты показывают, что этот метод обеспечивает лучшую производительность, чем часто используемый метод с горячим кодированием .
Значение по умолчанию для него — «auto», что означает: пусть lightgbm решает, что означает, что lightgbm будет определять, какие функции являются категориальными.
Это не всегда работает хорошо (некоторые эксперименты показывают, почему здесь и здесь), и я настоятельно рекомендую вам установить категориальную функцию вручную, просто с помощью этого кода
cat_col = имя_набора данных.select_dtypes («объект»). Columns.tolist ()
Но что происходит за кулисами и как lightgbm справляется с категориальными функциями?
Согласно документации lightgbm, мы знаем, что древовидные ученики не могут хорошо работать с одним методом горячего кодирования, потому что они растут глубоко в дереве.(k-1) — 1 возможное разбиение и с помощью метода Фишера, который может улучшить до k * log (k) , найдя лучший способ разбиения на отсортированной гистограмме значений в категориальной характеристике.
lightgbm is_unbalance vs scale_pos_weight
Одна из проблем, с которыми вы можете столкнуться в задачах двоичной классификации , заключается в том, как работать с несбалансированными наборами данных . Очевидно, вам нужно сбалансировать положительные / отрицательные образцы, но как именно это можно сделать в lightgbm?
Очевидно, вам нужно сбалансировать положительные / отрицательные образцы, но как именно это можно сделать в lightgbm?
В lightgbm есть два параметра, которые позволяют решить эту проблему: is_unbalance и scale_pos_weight , но в чем разница между ними и как их использовать?
- Когда вы устанавливаете Is_unbalace: True, алгоритм будет пытаться автоматически сбалансировать вес доминируемой метки (с долей pos / neg в наборе поездов)
- Если вы хотите изменить scale_pos_weight (по умолчанию 1, что означает Предположим, что и положительная, и отрицательная метка равны) в случае набора данных дисбаланса вы можете использовать следующую формулу (на основе этой проблемы в репозитории lightgbm), чтобы установить ее правильно
sample_pos_weight = количество отрицательных образцов / количество положительных образцов
лгбм feval
Иногда вы хотите определить пользовательскую функцию оценки для измерения производительности вашей модели, вам нужно создать функцию feval .
Функция Feval должна принимать два параметра:
и возврат
- eval_name
- eval_result
- is_higher_better
Давайте шаг за шагом создадим функцию пользовательских показателей.
Определите отдельную функцию Python
def feval_func (пред., Train_data):
return ('feval_func_name', eval_result, False)
Используйте эту функцию как параметр:
print ('Начать обучение... ')
lgb_train = lgb.train (...,
метрика = Нет,
feval = feval_func)
Примечание:
Чтобы использовать функцию feval вместо метрики, необходимо установить параметр метрики «None».
параметры классификации и параметры регрессии
Большинство вещей, о которых я упоминал ранее, справедливы как для классификации, так и для регрессии, но есть вещи, которые необходимо скорректировать.
Конкретно вам следует:
| Название параметра | Примечание к классификации | Примечание для регрессии |
|---|---|---|
| объектив | Установить двоичный или мультикласс | Установить регрессию |
| метрическая | Binary_logloss или AUC и т. Д. | RMSE или mean_absolute_error и т. Д. |
| is_unbalance | Верно или неверно | – |
| scale_pos_weight | используется только в двоичных и мультиклассовых приложениях | – |
| num_class | используется только в мультиклассовой классификации | – |
| reg_sqrt | – | Используется для размещения sqrt (метка) вместо исходных значений для метки большого диапазона |
Наиболее важные параметры lightgbm
Мы рассмотрели и немного узнали о параметрах lightgbm в предыдущих разделах, но ни одна статья о расширенных деревьях не будет полной без упоминания невероятных тестов от Laurae 🙂
Вы можете узнать о лучших параметрах по умолчанию для многих проблем как для lightGBM, так и для XGBoost.
Вы можете проверить это здесь, но некоторые наиболее важные выводы:
| Название параметра | Значение по умолчанию | Диапазоны | Тип параметра | Псевдонимы | Ограничение или примечание | Используется для |
|---|---|---|---|---|---|---|
| объектив | регрессия | Регрессия, двоичная | перечисление | Objective_type, приложение | При изменении влияет на другие параметры | Укажите тип ML модель |
| метрическая | null | +20 разных показателей | мульти-перечисление | метрик, metric_types | Нулевой означает, что будет использоваться метрика, соответствующая указанной цели. | Укажите метрическую систему.Поддержка нескольких показателей, |
| повышающий | gbdt | гбдт, рф, дротик, госс | перечисление | boosting_type | Если вы установите RF, это будет подход с упаковкой | Способ повышения |
| лямбда_l1 | 0,0 | [0, ∞] | двойной | reg_alpha | лямбда_l1> = 0,0 | регуляризация |
| bagging_fraction | 1. 0 0 |
[0, 1] | двойной | Подвыборка | 0,0 <фракция мешков <= 1,0 | случайным образом выбрать часть данных без повторной выборки |
| bagging_freq | 0,0 | [0, ∞] | внутр | subsample_freq | , чтобы включить упаковку в мешки, для bagging_fraction также должно быть установлено значение меньше 1.0 | 0 означает отключение упаковки; k означает выполнять упаковку на каждой k итерации |
| num_leaves | 31 | [1, ∞] | внутр | num_leaf | 1 | максимальное количество листьев на одном дереве |
|
| feature_fraction | 1.0 | [0, 1] | двойной | sub_feature | 0,0 | , если вы установите его на 0,8, LightGBM выберет 80% функций |
|
| макс_глубина | –1 | [-1, ∞] | внутр | макс_глубина | Чем больше, тем лучше, но скорость переобучения увеличивается. |
ограничение максимальной глубины Forr tree model |
| max_bin | 255 | [2, ∞] | внутр | Биннинг гистограммы | max_bin> 1 | eal с накладкой |
| num_iterations | 100 | [1, ∞] | внутр | Num_boost_round, n_iter | число_итераций> = 0 | количество итераций повышения |
| скорость обучения | 0.1 | [0 1] | двойной | эта | скорость_обучения> 0,0Типичный: 0,05. | в дротике, это также влияет на нормализацию веса упавших деревьев |
| Early_stopping_round | 0 | [0, ∞] | двойной | early_stopping_rounds | прекратит обучение, если проверка не улучшится за последний период Early_stopping_round | Производительность модели, количество итераций, время обучения |
| category_feature | Пустая строка | Укажите число для индекса столбца | multi-int или строка | cat_feature | Обработка категориальных характеристик | |
| bagging_freq | 0. 0 0 |
[0, ∞] | внутр | subsample_freq | 0 означает отключение упаковки; k означает выполнять упаковку на каждой k итерации | , чтобы включить упаковку в мешки, для bagging_fraction также должно быть установлено значение меньше 1.0 |
| многословие | 0 | [-∞, ∞] | внутр | подробный | <0: фатальный, = 0: ошибка (предупреждение), = 1: информация,> 1: отладка | Полезно для дебага |
| min_data_in_leaf | 20 | min_data | внутр | min_data | min_data_in_leaf> = 0 | Может использоваться для переоборудования |
Примечание:
Никогда не следует принимать какие-либо значения параметров как должное и корректировать их в зависимости от вашей проблемы. Тем не менее, эти параметры являются отличной отправной точкой для ваших алгоритмов настройки гиперпараметров
Тем не менее, эти параметры являются отличной отправной точкой для ваших алгоритмов настройки гиперпараметров
СМОТРИ ТАКЖЕ
➡️ Лучшие инструменты для визуализации показателей и гиперпараметров экспериментов по машинному обучению
➡️ Настройка гиперпараметров в Python: полное руководство 2020
Пример настройки параметров Lightgbm в Python (настройка lightgbm)
Наконец, после объяснения всех важных параметров, пора провести несколько экспериментов!
Я буду использовать один из популярных конкурсов Kaggle: предсказание клиентских транзакций Santander.
Я буду использовать эту статью, в которой объясняется, как запустить настройку гиперпараметров в Python для любого скрипта.
Стоит прочитать!
Прежде чем мы начнем, один важный вопрос! Какие параметры настраивать?
- Обратите внимание на проблему, которую вы хотите решить, например, набор данных Santander сильно несбалансирован , и следует учитывать это при настройке! Laurae2, один из разработчиков lightgbm, хорошо объяснила здесь.

- Некоторые параметры взаимозависимы и должны настраиваться вместе или настраиваться один за другим. Например, min_data_in_leaf зависит от количества обучающих выборок и num_leaves.
Примечание:
Рекомендуется создать два словаря для гиперпараметров: один содержит параметры и значения, которые вы не хотите настраивать, а другой содержит диапазоны параметров и значений, которые вы хотите настроить.
SEARCH_PARAMS = {'learning_rate': 0.4,
'max_depth': 15,
'num_leaves': 20,
'feature_fraction': 0,8,
'подвыборка': 0,2}
FIXED_PARAMS = {'цель': 'двоичный',
'метрика': 'аук',
'is_unbalance': Верно,
'boosting': 'gbdt',
'num_boost_round': 300,
'Early_stopping_rounds': 30}
Таким образом вы сохраняете свои базовые значения отдельно от области поиска!
Итак, вот что мы будем делать.
- Сначала мы генерируем код в Notebook . Он общедоступен, и вы можете его скачать .
- Во-вторых, мы отслеживаем результат каждого эксперимента на Neptune.ai .
ПОЛЕЗНО
Узнайте больше об интеграции Neptune-LightGBM.
Анализ результатов
Если вы проверили предыдущий раздел, то заметили, что я провел более 14 различных экспериментов с набором данных.Здесь я объясню, как шаг за шагом настроить значение гиперпараметров.
Создайте базовый код обучения:
из sklearn.metrics import roc_auc_score, roc_curve
из sklearn.model_selection import train_test_split
импортировать neptunecontrib.monitoring.skopt как sk_utils
импортировать lightgbm как lgb
импортировать панд как pd
импорт нептун
импортный скопт
import sys
импорт ОС
SEARCH_PARAMS = {'скорость_обучения': 0,4,
'max_depth': 15,
'num_leaves': 32,
'feature_fraction': 0. 8,
'подвыборка': 0,2}
FIXED_PARAMS = {'цель': 'двоичный',
'метрика': 'аук',
'is_unbalance': Верно,
'bagging_freq': 5,
'boosting': 'дротик',
'num_boost_round': 300,
'Early_stopping_rounds': 30}
def train_evaluate (search_params):
data = pd.read_csv ("sample_train.csv")
X = data.drop (['ID_code', 'target'], axis = 1)
y = данные ['цель']
X_train, X_valid, y_train, y_valid = train_test_split (X, y, test_size = 0.2, random_state = 1234)
train_data = lgb.Dataset (X_train, label = y_train)
valid_data = lgb.Dataset (X_valid, label = y_valid, reference = train_data)
params = {'метрика': FIXED_PARAMS ['метрика'],
"цель": FIXED_PARAMS ["цель"],
** search_params}
model = lgb.train (params, train_data,
valid_sets = [действительные_данные],
num_boost_round = FIXED_PARAMS ['num_boost_round'],
Early_stopping_rounds = FIXED_PARAMS ['Early_stopping_rounds'],
valid_names = ['действительный'])
оценка = модель.
8,
'подвыборка': 0,2}
FIXED_PARAMS = {'цель': 'двоичный',
'метрика': 'аук',
'is_unbalance': Верно,
'bagging_freq': 5,
'boosting': 'дротик',
'num_boost_round': 300,
'Early_stopping_rounds': 30}
def train_evaluate (search_params):
data = pd.read_csv ("sample_train.csv")
X = data.drop (['ID_code', 'target'], axis = 1)
y = данные ['цель']
X_train, X_valid, y_train, y_valid = train_test_split (X, y, test_size = 0.2, random_state = 1234)
train_data = lgb.Dataset (X_train, label = y_train)
valid_data = lgb.Dataset (X_valid, label = y_valid, reference = train_data)
params = {'метрика': FIXED_PARAMS ['метрика'],
"цель": FIXED_PARAMS ["цель"],
** search_params}
model = lgb.train (params, train_data,
valid_sets = [действительные_данные],
num_boost_round = FIXED_PARAMS ['num_boost_round'],
Early_stopping_rounds = FIXED_PARAMS ['Early_stopping_rounds'],
valid_names = ['действительный'])
оценка = модель. best_score ['действительный'] ['auc']
возвратный счет
best_score ['действительный'] ['auc']
возвратный счет
Используйте библиотеку оптимизации гиперпараметров по вашему выбору (например, scikit-optimize)
neptune.init ('mjbahmani / LightGBM-hyperparameters')
neptune.create_experiment ('lgb-tuning_final', upload_source_files = ['*. *'],
tags = ['lgb-tuning', 'dart'], params = SEARCH_PARAMS)
ПРОБЕЛ = [
skopt.space.Real (0,01, 0,5, name = 'learning_rate', Prior = 'log-uniform'),
skopt.space.Integer (1, 30, name = 'max_depth'),
скопт.space.Integer (10, 200, name = 'num_leaves'),
skopt.space.Real (0.1, 1.0, name = 'feature_fraction', Prior = 'uniform'),
skopt.space.Real (0.1, 1.0, name = 'подвыборка', Prior = 'uniform')
]
@ skopt.utils.use_ named_args (ПРОБЕЛ)
def цель (** параметры):
return -1.0 * train_evaluate (параметры)
монитор = sk_utils.NeptuneMonitor ()
results = skopt.forest_minimize (цель, ПРОБЕЛ,
n_calls = 100, n_random_starts = 10,
callback = [монитор])
sk_utils. log_results (результаты)
Нептун.стоп ()
log_results (результаты)
Нептун.стоп ()
Попробуйте различные типы конфигурации и отслеживайте свои результаты в Neptune
Наконец, в следующей таблице вы можете увидеть, какие изменения произошли в параметрах.
| гиперпараметр | Перед тюнингом | После тюнинга |
|---|---|---|
| скорость обучения | 0,4 | 0,094 |
| макс_глубина | 15 | 10 |
| num_leaves | 32 | 12 |
| feature_fraction | 0.8 | 0,1 |
| подвыборка | 0,2 | 0,75 |
| повышающий | gbdt | дротик |
| Оценка (auc) | 0,8256 | 0,8605 |
Заключительные мысли
Короче говоря, вы узнали:
- , какие основные параметры lightgbm,
- , как создавать собственные метрики с помощью функции feval
- , каковы хорошие значения по умолчанию для основных параметров
- увидел и пример того, как настроить параметры lightgbm для повышения производительности модели
И некоторые прочее 🙂 Для получения более подробной информации обратитесь к ресурсам.
Ресурсы
- Подробное руководство Лауры с хорошими значениями по умолчанию и т. Д.
- https://github.com/microsoft/LightGBM/tree/master/python-package
- https://lightgbm.readthedocs.io/en/latest/index.html
- https://papers.nips.cc/paper/6907-lightgbm-a-highly-efficient-gradient-boosting-decision-tree.pdf
- https://statweb.stanford.edu/~jhf/ftp/trebst .pdf
Специалист по данным и исследователь машинного обучения
ЧИТАТЬ СЛЕДУЮЩИЙ
Отслеживание экспериментов ML: что это такое, почему это важно и как это реализовать
Якуб Чакон | Опубликовано: 26 ноября, 2020
Позвольте мне поделиться историей, которую я слышал слишком много раз.
”… Мы вместе с моей командой разрабатывали модель машинного обучения, мы провели много экспериментов и получили многообещающие результаты…
… к сожалению, мы не могли точно сказать, что работает лучше всего, потому что мы забыли сохранить некоторые параметры модели и версии наборов данных…
… через несколько недель мы даже не были уверены, что мы на самом деле пробовали, и нам нужно было перезапустить почти все »
— неудачный исследователь машинного обучения.

И правда в том, что когда вы разрабатываете модели машинного обучения, вы проводите множество экспериментов.
Эти эксперименты могут:
- используют разные модели и гиперпараметры моделей
- используют разные данные обучения или оценки,
- запускают другой код (включая это небольшое изменение, которое вы хотели быстро протестировать)
- запускают тот же код в другой среде (не зная, какой PyTorch или Была установлена версия Tensorflow)
И в результате они могут выдавать совершенно разные метрики оценки.
Отслеживать всю эту информацию очень быстро становится очень сложно.Особенно, если вы хотите организовать и сравнить эти эксперименты и уверены, что знаете, какая установка дала лучший результат.
Вот где на помощь приходит отслеживание экспериментов машинного обучения.
Читать далее ->Получать уведомления о новых статьях
Отправляя форму, вы даете сконцентрироваться на хранении предоставленной информации и на связи с вами.
