Что такое ПЛИС и как она работает. Какие бывают типы логических элементов в ПЛИС. Как реализуются мультиплексоры разных видов в ПЛИС. Какие особенности нужно учитывать при проектировании схем на ПЛИС.
Что такое ПЛИС и каковы ее основные компоненты
ПЛИС (программируемая логическая интегральная схема) — это специализированная микросхема, архитектура которой может быть изменена путем программирования. Основными компонентами ПЛИС являются:
- Конфигурируемые логические блоки (CLB) — выполняют логические операции
- Программируемые межсоединения — обеспечивают связи между логическими блоками
- Блоки ввода-вывода — осуществляют взаимодействие с внешними устройствами
- Специализированные блоки (память, DSP и др.) — расширяют функциональность
Главное преимущество ПЛИС — возможность реализации сложных цифровых схем путем программирования, без физического изменения микросхемы. Это обеспечивает гибкость и снижает стоимость разработки по сравнению с заказными ASIC.

Типы логических элементов в ПЛИС
Базовым строительным блоком ПЛИС является логический элемент (LE). Существует несколько типов LE, отличающихся сложностью и функциональностью:
LUT (Look-Up Table)
LUT — это таблица истинности, реализующая произвольную логическую функцию от нескольких входов. Наиболее распространены 4-входовые и 6-входовые LUT. LUT позволяет эффективно реализовывать комбинационную логику.
Триггеры
Триггеры используются для хранения состояния и реализации последовательностных схем. Обычно в состав LE входит D-триггер, работающий по фронту тактового сигнала.
Мультиплексоры
Мультиплексоры позволяют выбирать один из нескольких входных сигналов. Они часто используются для реализации сложных функций и оптимизации использования ресурсов ПЛИС.
Реализация мультиплексоров в ПЛИС
Мультиплексоры играют важную роль в архитектуре ПЛИС. Рассмотрим основные виды мультиплексоров и особенности их реализации:
Бинарные мультиплексоры
Бинарные мультиплексоры выбирают один из входов на основе двоичного кода на управляющих входах. Простейший 2:1 мультиплексор описывается выражением:

Y = !S * A + S * B
где S — управляющий сигнал, A и B — информационные входы.
Для реализации бинарного мультиплексора 4:1 в ПЛИС с 4-входовыми LUT требуется 2 логических элемента.
Мультиплексоры-селекторы
В мультиплексорах-селекторах каждому входу соответствует отдельная управляющая линия. Активным может быть только один управляющий сигнал. Такие мультиплексоры менее эффективны в ПЛИС, так как требуют больше ресурсов.
Приоритетные мультиплексоры
Приоритетные мультиплексоры выбирают вход на основе заданного приоритета управляющих сигналов. Они часто реализуются с помощью операторов if-else. При большом числе входов могут возникать проблемы с задержками из-за каскадного соединения мультиплексоров.
Особенности проектирования схем на ПЛИС
При разработке цифровых схем для реализации в ПЛИС следует учитывать ряд важных моментов:
Оптимизация использования ресурсов
Необходимо стремиться к максимально эффективному использованию логических элементов ПЛИС. Например, при реализации мультиплексоров следует отдавать предпочтение бинарным схемам вместо селекторных, если это возможно.
Учет задержек распространения сигналов
В сложных схемах с большим числом уровней логики могут возникать существенные задержки. Следует анализировать критические пути и при необходимости оптимизировать структуру схемы.
Использование специализированных блоков
Современные ПЛИС содержат встроенные блоки памяти, умножители, PLL и другие специализированные модули. Их применение позволяет повысить производительность и снизить нагрузку на программируемую логику.
Синхронное проектирование
Рекомендуется использовать синхронные схемы с единым тактовым сигналом. Это упрощает временной анализ и повышает надежность работы устройства.
Языки описания аппаратуры для проектирования ПЛИС
Для разработки цифровых схем на ПЛИС широко применяются языки описания аппаратуры (HDL). Наиболее популярны:
- Verilog — C-подобный синтаксис, широкие возможности
- VHDL — строго типизированный язык, хорошо подходит для больших проектов
- SystemVerilog — расширенная версия Verilog с дополнительными возможностями
Выбор языка зависит от предпочтений разработчика и требований проекта. Многие САПР поддерживают смешанное использование языков в одном проекте.

Средства разработки и отладки проектов на ПЛИС
Для создания проектов на ПЛИС используются специализированные системы автоматизированного проектирования (САПР). Основные функции САПР ПЛИС:
- Ввод проекта (схемный и текстовый редакторы)
- Синтез логики
- Размещение и трассировка
- Временной анализ
- Программирование и конфигурирование ПЛИС
- Функциональное моделирование
Популярные САПР для разработки ПЛИС: Quartus (Intel/Altera), Vivado (Xilinx), Libero (Microsemi).
Перспективы развития технологий ПЛИС
Технология ПЛИС продолжает активно развиваться. Основные тенденции:
- Увеличение степени интеграции и производительности
- Снижение энергопотребления
- Интеграция процессорных ядер и специализированных блоков
- Развитие средств проектирования на основе высокоуровневого синтеза
- Применение ПЛИС в системах искусственного интеллекта и машинного обучения
ПЛИС остаются одним из ключевых инструментов для быстрой разработки и прототипирования цифровых устройств. Гибкость и возможность реконфигурации обеспечивают их широкое применение в различных областях электроники.

Архитектура ПЛИС (FPGA)

FPGA – это сокращение от английского словосочетания Field Programmable Gate Array.
ПЛИС – это сокращение от словосочетания «Программируемая Логическая Интегральная Схема». Слово ПЛИС встречается в русскоязычных документациях и описаниях вместо слова FPGA. Далее по тексту в основном будет использоваться этот термин — ПЛИС.
ПЛИС и FPGA – это аббревиатуры, обозначающие один и тот же класс электронных компонентов, микросхем. Это микросхемы, применяемые для создания собственной структуры цифровых интегральных схем.
Логика работы ПЛИС определяется не на фабрике изготовителем микросхемы, а путем дополнительного программирования (в полевых условиях, field-programmable) с помощью специальных средств: программаторов и программного обеспечения.
Микросхемы ПЛИС – это не микропроцессоры, в которых пользовательская программа выполняется последовательно, команда за командой. В ПЛИС реализуется именно электронная схема, состоящая из логики и триггеров.
Проект для ПЛИС может быть разработан, например, в виде принципиальной схемы. Еще существуют специальные языки описания аппаратуры типа Verilog или VHDL.
В любом случае, и графическое и текстовое описание проекта реализует цифровую электронную схему, которая в конечном счете будет «встроена» в ПЛИС.
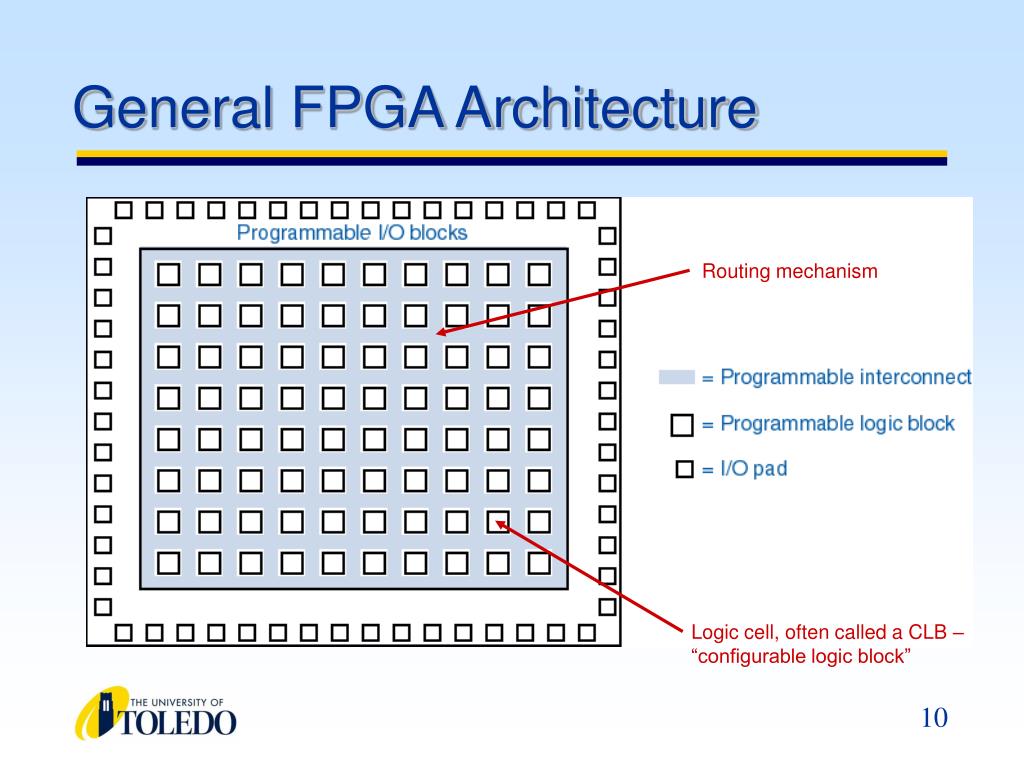
Обычно, сама микросхема ПЛИС состоит из:
- конфигурируемых логических блоков, реализующих требуемую логическую функцию;
- программируемых электронных связей между конфигурируемыми логическими блоками;
- программируемых блоков ввода/вывода, обеспечивающих связь внешнего вывода микросхемы с внутренней логикой.
Строго говоря это не полный список. В современных ПЛИС часто бывают встроены дополнительно блоки памяти, блоки DSP или умножители, PLL и другие компоненты. Здесь, в этой статье я их рассматривать не буду.
Разработчик проекта для ПЛИС обычно абстрагируется от внутреннего устройства конкретной микросхемы. Он просто описывает желаемую логику работы «своей» будещей микросхемы в виде схемы или текста на Verilog/ VHDL. Компилятор, зная внутреннее устройство ПЛИС сам пытается разместить требуемую схему по имеющимся конфигурируемым логическим блокам и пытается соединить эти блоки с помощью имеющихся программируемых электронных связей. В общем случае размещение и трассировка связей между логическими блоками в ПЛИС остается за компилятором.
Классификация ПЛИС по типу хранения конфигурации.
SRAM-Based.
Это одна из самых распространенных разновидностей ПЛИС. Конфигурация ПЛИС хранится ячейках статической памяти, изготовленной по стандартной технологии CMOS.
Достоинство этой технологии – возможность многократного перепрограммирования ПЛИС. Недостатки – не самое высокое быстродействие, после включения питания прошивку нужно вновь загружать. Значит на плате должен еще стоять загрузчик, специальная микросхема FLASH или микроконтроллер – все это удорожает конечное изделие.
Flash-based.
В таких микросхемах хранение конфигурации происходит во внутренней FLASH памяти или памяти типа EEPROM. Такие ПЛИС лучше тем, что при выключении питания прошивка не пропадает. После подачи питания микросхема опять готова к работе. Однако, у этого типа ПЛИС есть и свои недостатки. Реализация FLASH памяти внутри CMOS микросхемы – это не очень просто. Требуется совместить два разных техпроцесса для производства таких микросхем. Значит они получаются дороже. Кроме того, такие микросхемы, как правило, имеют ограниченное количество циклов перезаписи конфигурации.
Архитектура ПЛИС (FPGA)
FPGA – это сокращение от английского словосочетания Field Programmable Gate Array.
ПЛИС – это сокращение от словосочетания «Программируемая Логическая Интегральная Схема». Слово ПЛИС встречается в русскоязычных документациях и описаниях вместо слова FPGA. Далее по тексту в основном будет использоваться этот термин — ПЛИС.
ПЛИС и FPGA – это аббревиатуры, обозначающие один и тот же класс электронных компонентов, микросхем. Это микросхемы, применяемые для создания собственной структуры цифровых интегральных схем.
Логика работы ПЛИС определяется не на фабрике изготовителем микросхемы, а путем дополнительного программирования (в полевых условиях, field-programmable) с помощью специальных средств: программаторов и программного обеспечения.
Микросхемы ПЛИС – это не микропроцессоры, в которых пользовательская программа выполняется последовательно, команда за командой. В ПЛИС реализуется именно электронная схема, состоящая из логики и триггеров.
Проект для ПЛИС может быть разработан, например, в виде принципиальной схемы. Еще существуют специальные языки описания аппаратуры типа Verilog или VHDL.
В любом случае, и графическое и текстовое описание проекта реализует цифровую электронную схему, которая в конечном счете будет «встроена» в ПЛИС.
Обычно, сама микросхема ПЛИС состоит из:
- конфигурируемых логических блоков, реализующих требуемую логическую функцию;
- программируемых электронных связей между конфигурируемыми логическими блоками;
- программируемых блоков ввода/вывода, обеспечивающих связь внешнего вывода микросхемы с внутренней логикой.
Строго говоря это не полный список. В современных ПЛИС часто бывают встроены дополнительно блоки памяти, блоки DSP или умножители, PLL и другие компоненты. Здесь, в этой статье я их рассматривать не буду.
Разработчик проекта для ПЛИС обычно абстрагируется от внутреннего устройства конкретной микросхемы. Он просто описывает желаемую логику работы «своей» будещей микросхемы в виде схемы или текста на Verilog/ VHDL. Компилятор, зная внутреннее устройство ПЛИС сам пытается разместить требуемую схему по имеющимся конфигурируемым логическим блокам и пытается соединить эти блоки с помощью имеющихся программируемых электронных связей. В общем случае размещение и трассировка связей между логическими блоками в ПЛИС остается за компилятором.
Классификация ПЛИС по типу хранения конфигурации.
SRAM-Based.
Это одна из самых распространенных разновидностей ПЛИС. Конфигурация ПЛИС хранится ячейках статической памяти, изготовленной по стандартной технологии CMOS.
Достоинство этой технологии – возможность многократного перепрограммирования ПЛИС. Недостатки – не самое высокое быстродействие, после включения питания прошивку нужно вновь загружать. Значит на плате должен еще стоять загрузчик, специальная микросхема FLASH или микроконтроллер – все это удорожает конечное изделие.
Flash-based.
В таких микросхемах хранение конфигурации происходит во внутренней FLASH памяти или памяти типа EEPROM. Такие ПЛИС лучше тем, что при выключении питания прошивка не пропадает. После подачи питания микросхема опять готова к работе. Однако, у этого типа ПЛИС есть и свои недостатки. Реализация FLASH памяти внутри CMOS микросхемы – это не очень просто. Требуется совместить два разных техпроцесса для производства таких микросхем. Значит они получаются дороже. Кроме того, такие микросхемы, как правило, имеют ограниченное количество циклов перезаписи конфигурации.
Antifuse.
Специальная технология по которой выполняются однократно программируемые ПЛИС. Программирование такой ПЛИС з
Архитектура ПЛИС. Часть 2. Мультиплексор
Шауэрман Александр А. [email protected]
Первая статья цикла: Архитектура ПЛИС. Часть 1. Логический элемент
Для многих проектов на ПЛИС значительную часть используемых логических ячеек занимают мультиплексоры (Multiplexer – MUX). Всем известно, что мультиплексор представляет собой комбинационное устройство, коммутирующее несколько входов на один выход. Выбор входа определяют управляющие сигналы. При оптимизации логики вашего мультиплексора, вы сможете максимально эффективно реализовать его в ПЛИС Altera. В этом разделе рассмотрим основные проблемы и дадим решения для достижения оптимального использования ресурсов.
Для тех, кто перешел на язык описания схем после проектирования на дискретной логике, мультиплексор представляется неким фиксированным электронным компонентом: такой микросхемой, переключающей цифровые потоки. Однако при HDL описании схемы, особенно если это Verilog HDL, роль мультиплексора значительно шире и его можно встретить в не всегда ожидаемых местах. Если вы в своем коде используете оператор case, if или тернарный оператор выбора, будьте уверены, вы используете мультиплексор. Поэтому разберемся с основными типами мультиплексоров, встречающихся в Verilog описании схем и некоторыми особенностями их синтеза.
При аппаратном синтезе в ПЛИС выделяют несколько типов мультиплексоров: бинарные мультиплексоры, мультиплексоры селекторы и приоритетные мультиплексоры. Понимание того, как мультиплексоры создаются из HDL кода, и как они могут быть реализованы в ходе синтеза, является первым шагом на пути к оптимизации структуры мультиплексора для получения наилучших результатов.
Бинарные мультиплексоры
Бинарные мультиплексоры – это мультиплексоры, которые содержат дешифратор; они выбирают вход, основываясь на значении управляющих сигналов, представленных в виде двоичного позиционного кода. Простейший такой мультиплексор имеет два информационных входа и один управляющий.
Рисунок 1 – Таблица истинности и обозначение мультиплексора 2:1 на функциональных схемах
Аналитически такой мультиплексор описывается формулой:
(1)
Такой мультиплексор создается при однократном использовании оператора if или тернарного оператора выбора:
always @ * // Если y – это reg
if(c0) y = d1;
else y = d0;
Или так:
assign y = c0 ? d1 : d0; // Если y – это wire
Для синтеза этого мультиплексора понадобится одна ячейка 4-х входового LUT. Однако бинарный мультиплексор 4 в 1 имеет уже 6 входов (4 информационных и два управляющих) и не может быть синтезирован непосредственно на 4-LUT. В этом отношении серии ПЛИС с 6-и входовыми LUT находятся в более выигрышном положении, но в нашем Cyclone IV для увеличения коммутируемых каналов (входов) придется использовать каскадную структуру.
Рисунок 2 – Каскадное объединение мультиплексоров
Если реализовывать каскадное включение из трех мультиплексоров «в лоб», то для этого понадобится 3 LUT, при этом у каждого LUT останется неиспользованный вход. На практике для полного использования ресурса применяется взаимное вложение мультиплексоров. Такой подход интересен тем, что на выходе первой LUT (сигнал z, рисунок 3) в зависимости от значения c1 коммутируются либо информационные входы d0, d1, либо управляющий сигнал c0. В результате достигается полная утилизация ресурсов.
Рисунок 3 – Взаимное вложение мультиплексоров для синтеза на LUT
(2)
(3)
Таким образом, для ПЛИС, у которых LE основан на 4-LUT, мультиплексор 4:1 эффективно строится на двух LUT. Мультиплексор с большим количеством входов при синтезе разбивается на блоки 4-х входовых мультиплексоров, при необходимости в завершении ставится мультиплексор 2:1.
Пример Verilog модуля бинарного мультиплексора 4:1 (занимает две LUT):
Бинарный мультиплексор 4:1. Verilogmodule multiplexer
(
input d3,d2,d1,d0, // data
input c1,c0, // control
output reg y
);
always @*
case ({c1, c0})
2'b00: y = d0;
2'b01: y = d1;
2'b10: y = d2;
2'b11: y = d3;
endcase
endmodule
Язык Verilog позволяет обратится отдельно к каждому биту в векторе по его номеру. Эта возможность даст еще одну реализацию бинарного мультиплексора.
Бинарный мультиплексор 4:1. Verilog. Реализация с объединением входовmodule binary_mux ( input [3:0] din, // Вход input [1:0] sel, // Управление output dout // Выход ); assign dout = din[sel]; endmodule
В отличии от предыдущих реализаций информационные и управляющие входы объединены в вектор. При использовании такого модуля в экземпляре используется конкатенация (объединение):
binary_mux mux_inst
(
.din({d3, d2, d1, d0}),
.sel({c1, c0}),
.dout(y)
);
На практике удобно использовать универсальные модули, где основные свойства задаются через параметр. Это позволяет использовать одну реализацию в различных задачах. В последнем примере бинарного мультиплексора легко перейти к параметризируемой модели и управлять числом коммутируемых входов:
Бинарный мультиплексор 4:1. Verilog. Параметризируемая модельmodule binary_mux #( parameter SEL_WIDTH = 3, // разрядность управляющего вектора parameter TOTAL_DAT = 1 << SEL_WIDTH // максимальное число входов ) ( input [TOTAL_DAT-1:0] din, input [SEL_WIDTH-1:0] sel, output dout ); assign dout = din[sel]; endmodule
При использовании модуля параметр SEL_WIDTH можно установить в заголовке экземпляра модуля:
binary_mux #(.SEL_WIDTH(2)) mux_inst
(
.din({d3, d2, d1, d0}),
.sel({c1, c0}),
.dout(y)
);
Легко убедится, что при одинаковом числе коммутируемых входов на уровне RTL все варианты описания мультиплексора дают одинаковую схему.
Мультиплексор-селектор
Мультиплексор-селектор не имеет дешифратора: для каждого входа предназначена отдельная управляющая линия. Одновременно только на одной линии управления может быть установлена единица. Несмотря на простоту реализации на дискретных элементах на каждый вход ставится элемент 2-И, с выхода которых сигнал подается на элемент ИЛИ. При реализации в ПЛИС такой мультиплексор намного менее эффективен, чем двоичный. Из-за того, что на каждый вход требуется управляющая линия, для 4-х канального мультиплексора понадобится уже три 4-LUT.
Мультиплексор-селектор 4:1. Verilogmodule selector_multiplexer
(
input d3,d2,d1,d0, // data
input c3,c2,c1,c0, // control
output reg y
);
always @*
case ({c3, c2, c1, c0})
2'b0001: y = d0;
2'b0010: y = d1;
2'b0100: y = d2;
2'b1000: y = d3;
default: y = 0;
endcase
endmodule
Однако в некоторых случаях управляющие сигналы – это выход декодера, тогда компилятор попытается объединить селектор и дешифратор в двоичный мультиплексор.
Приоритетный мультиплексор
Судя по названию, в приоритетном мультиплексоре логика выбора подразумевает приоритет. Варианты для выбора правильного элемента должна быть проверена в определенном порядке на основе приоритета сигнала. Такая структура в Verilog в основном определяется операторами if, else, casex и ?: .
Например, такой модуль:
Приоритетный мультиплексор 4:1. Verilog. Реализация на ifmodule priority_multiplexer ( input d3,d2,d1,d0, // data input c2,c1,c0, // control output reg y ); always @* if (c0) y = d0; else if (c1) y = d1; else if (c2) y = d2; else y = d3; endmodule
на уровне RTL (Register transfer level – уровень регистровых взаимодействий) будет иметь вид:
Рисунок 4 – Структура приоритетного мультиплексора на уровне RTL
Очевидно, что путь прохождения сигнала со входа d3 на выход y будет отличаться от пути с входа d0 на выход y. И в зависимости от числа мультиплексоров в цепи временная задержка при прохождении через такую цепь может стать слишком большой, особенно для ПЛИС с 4-LUT. Однако все не настолько плохо: при компиляции Quartus II стремится преобразовать структуру к древовидному виду, при этом использует прием взаимного вложения, как это было при синтезе бинарного мультиплексора 4:1. В результате технологическая карта (Technology Map) модуля из примера будет иметь вид:
Рисунок 5 – Структура приоритетного мультиплексора 4:1 на уровне Technology Map
Из рисунка 5 видно, что по прежнему самые длинные пути это d3→y и d2→y, но включают в себя не три, а два LUT. В этом случае, быстродействие схемы будет таким же, как и в аналогичном бинарном мультиплексоре, но при этом используется три LUT против двух у бинарного. Очевидно, что при увеличении числа коммутируемых входов у бинарного мультиплексора выигрыш в быстродействии и в занимаемых ресурсах будет увеличиваться, поэтому стоит избегать приоритетных мультиплексоров там, где приоритет не требуется. Если порядок выбора не важен, можно использовать case для построения бинарного мультиплексора. Если в проекте избежать приоритетного выбора нельзя, а задержки становятся критичными, можно постараться изменить логику работы, что бы уменьшить число логических уровней, особенно вдоль критического пути.
И напоследок, точно такой же по функционалу и реализации модуль может быть записан с использованием оператора casex следующим образом:
module priority_multiplexer
(
input d3,d2,d1,d0, // data
input c2,c1,c0, // control
output reg y
);
always @*
casex ({c2, c1, c0})
3'b??1: y = d0;
3'b?10: y = d1;
3'b100: y = d2;
3'b000: y = d3;
endcase
endmodule
У такой записи помимо наглядности есть еще одно маленькое преимущество, в конструкции casex легко определить значение по умолчанию и тем самым избежать ряд неприятностей, но об этом речь пойдет в следующей главе.
Неявный default
Часто бывает, что применение оператора if удобнее чем case. Однако, использование if может привести в результате к сложному дереву мультиплексоров, которые не могут быть легко оптимизированы инструментами синтеза. В частности, каждый if имеет неявный else, даже когда он не указан и компилятор будет обязан отработать эту ветвь. Такое неявное умолчание может стать причиной дополнительного усложнения синтеза мультиплексора, а в худших случаях привезти к синтезу Latch.
Рассмотрим пример приоритетного мультиплексора, но «упростим» схему, «забудем» последнюю ветвь else:
module priority_multiplexer_bad ( input d3,d2,d1,d0, // data input c2,c1,c0, // control output reg y ); always @* if (c0) y = d0; else if (c1) y = d1; else if (c2) y = d2; // else // y = d3; endmodule
При компиляции такой модуль вместо 3 LUT занимает уже 4 LUT, а Quartus выдал следующие предупреждения:
Warning (332060): Node: c0 was determined to be a clock but was found without an associated clock assignment. Warning (335093): TimeQuest Timing Analyzer is analyzing 1 combinational loops as latches.
Что-то пошло не так. Вход c0 компилятор воспринял как вход тактирования (это в комбинационной-то схеме!) и добавил петлю обратной связи, создав Latch. При этом компилятор реализовал лишь то, что хотел от него программист. Если значение переменной c0 равно единице, то на вход поступает d0; если c0 равно нулю, а c1 равно единице, то на выходе будет d1; если и c0, и c1 – нули, а c1 – единица, то на выходе – d2. Но что должно быть на выходе, если все управляющие сигналы равны нулю? Компилятор делает единственно верный вывод – нужно сохранить предыдущее значение, а для этого синтезировать асинхронный (одноступенчатый) триггер, или, как его по другому называют, защелку (Latch).
Рисунок 6 – Структура полученного мультиплексора на уровне RTL
Рисунок 7 – Структура полученного мультиплексора на уровне Technology Map
На технологической карте последняя (крайняя правая) LUT охвачена петлей обратной связи – это и есть Latch. В отечественной литературе выделяют целое семейство таких устройств, их называют асинхронными триггерами, одноступенчатыми триггерами, или триггерами-защелками. Такие устройства имеют ограниченную поддержку в инструментах проверки и анализа, например, TimeQuest (встроенная в Quartus утилита для временного анализа, оценивает задержки распространения) интерпретирует Latch, как синхронный триггер, работающий по спадающему фронту, что является весьма грубым допущением. Поэтому схем с защелками нужно избегать, а использование такого мультиплексора является крайне неудачным решением.
При описании сложного мультиплексора с разветвленной иерархией на операторах if—else бывает трудно отследить все ветви, а код становится трудным для восприятия. В этом случае можно рекомендовать изменить структуру мультиплексора и попытаться реализовать его в качестве бинарного, используя оператор case. Однако и в бинарном мультиплексоре легко допустить ошибку. Достаточно «забыть» указать один из вариантов выбора.
Например так:
Бинарный мультиплексор с ошибкой. Verilogmodule multiplexer_bad
(
input d3,d2,d1,d0, // data
input c1,c0, // control
output reg y
);
always @*
case ({c1, c0})
2'b00: y = d0;
2'b01: y = d1;
2'b10: y = d2;
// 2'b11: y = d3;
endcase
endmodule
Как результат, при синтезе получим увеличение числа логических элементов, Latch и плохую предсказуемость при временном и функциональном анализе. Когда в мультиплексоре используется всего 4 варианта выбора, то, в принципе, легко проследить все варианты, но задача усложняется экспоненциально при увеличении числа коммутируемых входов, тем более, если не все сочетания управляющих сигналов функционально возможны или достаточно редко происходят. Спецификация Verilog имеет решение на этот случай, оператор case включает в себя обработку значения по умолчанию, для этого используется ключевое слово default. Перепишем предыдущий модуль следующим способом:
module multiplexer_bad
(
input d3,d2,d1,d0, // data
input c1,c0, // control
output reg y
);
always @*
case ({c1, c0})
2'b00: y = d0;
2'b01: y = d1;
2'b10: y = d2;
// 2'b11: y = d3;
default : y = 0;
endcase
endmodule
Даже если будет закомментирован любой другой случай, или два случая, компилятор реализует корректную схему без защелок. Поэтому хорошим тоном программирования является добавления default даже для бинарного мультиплексора с полным набором описанных вариантов.
Описание ветви default является особенно важным в мультиплексора-селекторах, где по определению в векторе управляющих сигналов заложена избыточность. Определяя явно значение default, мы даем компилятору информацию о том, как синтезировать эти случаи.
Многоразрядный мультиплексор
Под многоразрядными мультиплексорами мы будем подразумевать мультиплексоры, коммутирующие многоразрядные данные (вектора). Так как в подобном устройстве все разряды не связаны между собой, при построении в ПЛИС на уровне логического блока не будут задействованы цепи переноса, а устройство в целом представляет собой несколько одноразрядных мультиплексоров, включенных параллельно, у которых управляющие входы объединены. Поэтому все показанные выше методы описания мультиплексоров актуальны и при многоразрядных значениях входных данных. Например, для того, чтобы превратить бинарный мультиплексор в N-разрядный, достаточно информационные входы и выход объявить как N-разрядные вектора, управляющие сигналы останутся без изменения:
N-разрядный бинарный мультиплексор. Verilogmodule multiplexer
#( parameter N = 8)
(
input [N-1:0] d3,d2,d1,d0, // data
input c1,c0, // control
output reg [N-1:0] y
);
always @*
case ({c1, c0})
2'b00: y = d0;
2'b01: y = d1;
2'b10: y = d2;
2'b11: y = d3;
endcase
endmodule
При такой реализации единственный настраиваемый параметр – это N, разрядность входных и выходных данных. Количество входов остается фиксированным, что неудобно, в сложном проекте придется держать множество модулей. Гораздо большим потенциалом в плане параметризации обладает модель бинарного мультиплексора с объединением входов. Ниже приведен модуль многоразрядного настраиваемого мультиплексора, построенный в соответствии с рекомендациями Altera.
Настраиваемый модуль мультиплексора. Verilogmodule bus_mux #( parameter DAT_WIDTH = 2, parameter SEL_WIDTH = 3, parameter TOTAL_DAT = DAT_WIDTH << SEL_WIDTH ) ( input [TOTAL_DAT-1:0] din, input [SEL_WIDTH-1:0] sel, output [DAT_WIDTH-1:0] dout ); localparam NUM_WORDS = (1 << SEL_WIDTH); genvar i,k; generate for (k=0; k < DAT_WIDTH; k=k+1) begin : out wire [NUM_WORDS-1:0] tmp; for (i=0; i < NUM_WORDS; i=i+1) begin : mx assign tmp [i] = din[k+i*DAT_WIDTH]; end assign dout[k] = tmp[sel]; end endgenerate endmodule
Рисунок поясняет принцип работы модуля. Для примера выбрана ширина входных данных 4, количество входов 4, а ширина управляющего вектора – 2. В цикле генерации формируем временный вектор tmp, из которого одноразрядным мультиплексором выбираем нужное значение.
Рисунок 8 – Принцип работы модуля многоразрядного коммутатора
Экспериментальное исследование
Несмотря на то, что рассмотренные в этой статье модели достаточно простые и для того, чтобы оценить корректность работы достаточно взглянуть на схему в RTL Viewer и Technology Map, можно провести экспериментальное исследование непосредственно на ПЛИС. С некоторого времени у меня под рукой отладочная плата LESO2, версия с Cyclone IV на борту. Восьми тумблеров хватит для формирования информационных и управляющих сигналов одноразрядного мультиплексора. Ниже приведен листинг модуля верхнего уровня.
Модуль верхнего уровня. Verilogmodule demo_mux ( (* chip_pin = "65" *) input d0, //sb8 тумблер (* chip_pin = "64" *) input d1, //sb7 тумблер (* chip_pin = "60" *) input d2, //sb6 тумблер (* chip_pin = "59" *) input d3, //sb5 тумблер (* chip_pin = "52" *) input d4, //sw кнопка (с инверсией) (* chip_pin = "58" *) input c0, //sb4 (* chip_pin = "55" *) input c1, //sb3 (* chip_pin = "54" *) input c2, //sb2 (* chip_pin = "53" *) input c3, //sb1 (* chip_pin = "11, 10, 8, 7, 6, 3, 2, 1" *) output [7:0] led_o ); wire y; // Экземпляр исследуемого модуля: multiplexer mult_inst ( .d3(d3), .d2(d2), .d1(d1), .d0(d0), // data .c1(c1), .c0(c0), // control .y(y) ); // назначаем выход модуля на светодиод assign led_o [0] = y; endmodule
В листинге для примера установлен экземпляр одноразрядного бинарного мультиплексора. При исследовании многоразрядных мультиплексоров на информационные входы можно подать константы. В качестве дополнительного информационного входа (в листинге обозначен как d4) можно использовать тактовую кнопку.
Создаем проект в Quartus II, настраиваем на генерацию rbf-файла. Подробнее о создании и настройки проекта можно узнать из статьи «Пишем «демку» для LESO2 на Verilog». Использовать Pin Planer или Assigment Editor нет необходимости, все порты модуля верхнего уровня назначены непосредственно в тексте программы при объявлении портов с помощью специальной директивы. Компилируем проект, с помощью утилиты l2flash загружаем rbf-файл в ПЛИС. Исследуем схему.
Рекомендации и выводы
1. На ПЛИС с 4-х входовыми LUT оптимальным образом строятся бинарные мультиплексоры 4:1. При описании мультиплексоров с большим числом входов для сохранения общего быстродействия схемы рекомендуется использовать конвейер.
2. Мультиплексор-селектор не дает преимущества ни по скорости, ни по занимаемым ресурсам. Можно рекомендовать использовать его только совместно с дешифратором.
3. Приоритетный мультиплексор нужно использовать с осторожностью и только там, где он действительно нужен. При увеличении количества входов задержка распространения сигнала вдоль критического пути значительно возрастает.
4. Все ветви мультиплексора должны быть описаны. Для каждого if должен быть свой else, если использование case (или casex) сложно, то следует использовать default для ветви, исполняемой по умолчанию.
Литература
Quartus Prime Standard Edition Handbook Volume 1: Design and Synthesis
Advanced Synthesis Cookbook
Первая статья цикла: Архитектура ПЛИС. Часть 1. Логический элемент
ПЛИС (FPGA) и микроконтроллер. В чем разница? — МикроПрогер
Altera-Cyclone and Arduino
Каждый начинающий микропрогер на определенном этапе своего развития задается вопросом в чем же разница между ПЛИС (фирм Altera или Xilinx) и микроконтроллером (микропроцессором)?
Читаешь форумы — знатоки дела пишут, что это совершенно разные вещи, которые нельзя сравнить, аргументируя это тем, что у них разная архитектура. Читаешь мануал по Verilog или C++ — и тот и другой используют похожие операторы со схожим функционалом, даже синтаксис похож, а почему разные? Заходишь на марсоход — там светодиодами (или даже просто лампочками) с помощью FPGA моргают, смотришь проекты на Arduino — там роботами управляют. СтОп!
А вот теперь остановимся и спросим себя: почему с ПЛИС — тупо лампочка, а Ардуино — умно робот? Ведь и первый и второй вроде как программируемое устройство, неужели у ПЛИС возможностей для робота не хватает?
В какой-то степени суть вопроса «В чем разница между ПЛИС и микроконтроллером?» раскрывается именно на таком примере.
Отметим сразу. Функционал ПЛИС изначально не уступает микроконтроллеру (и микропроцессору, кстати, тоже), точнее — основные функции у одного и второго по сути идентичны — выдавать логические 0 или 1 при определенных условиях, а если говорить о быстродействии, количестве выводов(ножек) и возможностях конвейерной обработки, то микроконтроллеру до ПЛИСа вообще далеко. Но есть одно «но». Время на разработку одного и того же программного алгоритма на двух разных устройствах (ПЛИС и микроконтроллер) различается в разы, а то и в десятки раз. Именно ПЛИС здесь в 99% случаев сильно уступает МК. И дело вовсе не в замороченности языков Verilog, VHDL или AHDL, а в устройстве самой ПЛИС.
FPGA: в ПЛИС и нет сложных автоматизированных цепочек(делающих часть работы за вас). Есть только железные проводные трассы и магистрали, входы, выходы, логические блоки и блоки памяти. Среди трасс есть особый класс — трасса для тактирования(привязанная к определенным ножкам, через которые рекомендуется проводить тактовую частоту).
Основной состав:
Трасса — металл, напаянный на слои микросхемы, является проводником электричества между блоками.
Блоки — отдельные места в плате, состоящие из ячеек. Блоки служат для запоминания информации, умножения, сложения и логических операций над сигналами вообще.
Ячейки — группы от нескольких единиц до нескольких десятков транзисторов.
Транзистор — основной элемент ТТЛ логики.
Выводы (ножки микросхемы) — через них происходит обмен ПЛИС с окружающим миром. Есть ножки специального назначения, предназначенные для прошивки, приема тактовой частоты, питания, а так же ножки, назначение которых устанавливаются пользователем в программе. И их, как правило, гораздо больше, чем у микроконтроллера.
Тактовый генератор — внешняя микросхема, вырабатывающая тактовые импульсы, на которых основывается большая часть работы ПЛИС.
Трассы подключаются к блокам с помощью специальных КМОП-транзисторов. Эти транзисторы способны сохранять свое состояние(открытое или закрытое) на протяжении длительного периода времени. Изменяется состояние транзистора при подаче сигнала по определенной трассе, которая используется только при программировании ПЛИС. Т.е., в момент прошивки осуществляется именно подача напряжения на некоторый набор КМОП-транзисторов. Этот набор определяется прошивочной программой. Таким образом происходит сложное построение огромной сети трасс и магистралей внутри ПЛИС, связывающей сложным образом между собой огромное количество логических блоков. В программе вы описываете какой именно алгоритм нужно выполнять, а прошивка соединяет между собой элементы, выполняющие функции, которые вы описываете в программе. Сигналы бегают по трассе от блока к блоку. А сложный маршрут задается программой.
Архитектура ПЛИС (FPGA)
В этом элементе ТТЛ логики все операции по обработкам отдельных сигнальчиков проводятся независимо от вас. Вы лишь указываете что делать с тем или иным набором принятых сигналов и куда выдавать те сигналы, которые нужно передать. Архитектура микроконтроллера состоит совсем из других блоков, нежели ПЛИС. И связи между блоками осуществляются по постоянным магистралям(а не перепрошиваемым). Среди блоков МК можно выделить основные:
Постоянная память (ПЗУ) — память, в которой хранится ваша программа. В нее входят алгоритмы действий и константы. А так же библиотеки(наборы) команд и алгоритмов.
Оперативная память (ОЗУ) — память, используемая микроконтроллером для временного хранения данных(как триггеры в ПЛИС). Например, при вычислении в несколько действий. Допустим, нужно умножить первое пришедшее число на второе(1-е действие), затем третье на четвертое(2 действие) и сложить результат(3 действие). В оперативную память при этом занесется результат 1 действия на время выполнения второго, затем внесется результат 2 действия. А затем оба этих результата пойдут из оперативной памяти на вычисление 3 действия.
Процессор — это калькулятор микроконтроллера. Он общается с оперативной памятью, а так же с постоянной. С оперативной происходит обмен вычислениями. Из постоянной процессор получает команды, которые заставляют процессор выполнять определенные алгоритмы и действия с сигналами на входах.
Средства (порты) ввода-вывода и последовательные порты ввода-вывода — ножки микроконтроллера, предназначенные для взаимодействия с внешним миром.
Таймеры — блоки, предназначенные для подсчета количества циклов при выполнении алгоритмов.
Контроллер шины — блок, контролирующий обмен между всем блоками в микроконтроллере. Он обрабатывает запросы, посылает управляющие команды, организовывает и упорядочивает общение внутри кристалла.
Контроллер прерываний — блок, принимающий запросы на прерывание от внешних устройств. Запрос на прерывание — сигнал от внешнего устройства, информирующий о том, что ему необходимо совершить обмен какой-либо информацией с микроконтроллером.
Внутренние магистрали — трассы, проложенные внутри микроконтроллера для информационного обмена между блоками.
Тактовый генератор — внешняя микросхема, вырабатывающая тактовые импульсы, на которых основывается вся работа микроконтроллера.
В микроконтроллере, в отличии от ПЛИС, работа происходит между вышеперечисленными блоками, имеющими сложную архитектуру, облегчающую процесс разработки программ. При прошивке вы изменяете только постоянную память, на которую опирается вся работа МК.
Архитектура микроконтроллера
ПЛИС прошивается на уровне железа, практически по всей площади кристалла. Сигналы проходят через сложные цепочки транзисторов. Микропроцессор же прошивается на уровне программы для железа, сигналы проходят группами, от блока к блоку — от памяти к процессору, к оперативной памяти, от оперативной к процессору, от процессору к портам ввода-вывода, от портов ввода-вывода к оперативной памяти, от оперативной памяти… и так далее. Вывод: за счет архитектуры ПЛИС выигрывает в быстродействии и более широких возможностях конвеерной обработки, МК выигрывает в простоте написания алгоритмов. За счет более простого способа описания программ, фантазия разработчика Микроконтроллера менее скованна временем на отладку и разработку, и, таким образом, время на программирование того же робота на МК и ПЛИС будет отличаться во многие и многие разы. Однако робот, работающий на ПЛИС будет гораздо шустрее, точнее и проворнее.
В ПЛИС всю работу нужно делать самому, вручную: для того, чтобы реализовать какую-либо программу на ПЛИС, нужно отследить каждый сигнальчик по каждому проводку, приходящему в ПЛИС, расположить какие-то сигнальчики в ячейки памяти, позаботиться о том, чтобы в нужный момент именно к этим ячейкам памяти обратился другой сигнальчик, который вы так же отслеживаете или даже генерируете, и в итоге набор сигнальчиков, задержанный в памяти задействовал нужный вам сигнальчик, который, например, пойдет на определенную выходную ножку и включит светодиодик, который к ней подключен. Часть сигнальчиков идет не в память, а например на запуск определенной части алгоритма(программы). То есть, говоря языком микропрогера, эти ножки являются адресными. Например, имеем на нашей плате в нашей программе три адресные ножки для включения неких не связанных(или связанных) друг с другом алгоритмов, которые мы реализовали на языке Verilog в ПЛИС. Также в программе, кроме трех адресных ножек, у нас есть еще например 20 информационных ножек, по которым приходит набор входных сигнальчиков(например с разных датчиков) с какой-либо информацией (например температура воды в аквариуме с датчика температуры воды в аквариуме). 20 ножек = 20 бит. 3 ножки -3 бита. Когда приходит адресный сигнал 001(с трех ножек адреса) — запускаем первый алгоритм, который записывает 20 информационных сигнальчиков в 20 ячеек памяти(20 триггеров), затем следующие 20 сигнальчиков умножаем на полученные ранее 20, а результат умножения записываем в память, а потом отсылаем по другим ножкам например в терморегулятор воды в аквариуме. Но Отошлем мы этот результат только тогда, когда на наши адресные ножки придет код например 011 и запустит алгоритм считывания и передачи. Ну, естественно «отсылаем», «считываем» и еще что-то прописываем в ручную. Ведем каждый сигнальчик в каждый такт работы ПЛИС по определенному пути, не теряем. Обрабатываем или записываем. Складываем или умножаем. Не забываем записать. Не забываем принять следующий сигнал и записать в другие триггеры. Еще добавьте сюда работу, привязанную к тактовой частоте, синхронизацию (которая так же реализуется вручную), неизбежные ошибки на этапах разработки и отладки и кучу других проблем, которые в данной статье рассматривать просто бессмысленно. Трудно. Долго. Но зато на выходе работает супер оперативно, без глюков и тормозов. Железно!
Теперь микроконтроллер. 20 ножек на прием информации — для большинства микроконтроллеров физически невозможная задача. А вот 8 или 16 — да пожалуйста! 3 информационных — в легкую! Программа? По адресу 001 умножить первое пришедшее число на второе, по адресу 011 отсылай результат в терморегулятор. Все! Быстро. Легко. Не супер, но оперативно. Если очень грамотно написать программу- без глюков и тормозов. Программно!
Железо и Программа! Вот главное отличие между ПЛИС и Микроконтроллером.
В микроконтроллере большинство замороченных, но часто используемых алгоритмов уже вшиты железо(в кристалл). Нужно лишь вызвать программным способом нужную библиотеку, в которой этот алгоритм хранится, назвать его по имени и он будет делать всю грязную работу за вас. С одной стороны это удобно, требует меньшего количества знаний о внутреннем устройстве микросхемы. Микрик берет на себя заботу об отслеживании принятых, генерируемых и результирующих сигналов, об их складировании, обработке, задержке. Все делает сам. В большинстве микропрогерских задач это то, что нужно. Но если безграмотно использовать все эти удобства, то возникает вероятность некорректной работы. Железо и Программа!
Заключение
Современные разработчики процессоров и микропроцессоров изначально разрабатывают свои устройства на ПЛИС. Да-да, вы правильно догадываетесь: сначала они имитируют создаваемую архитектуру микроконтроллера с помощью разработки и прошивки программы на ПЛИС, а затем измеряют скорость выполнения алгоритмов при том или ином расположении имитируемых блоков МК и том или ином наборе функционала каждого блока отдельно.
По характеристикам выдаваемого сигнала, ПЛИС чаще всего рассчитана на 3,3В, 20мА, Микроконтроллер на 5В, 20мА.
Под микроконтроллер AVR, успешно внедренный в платформу Arduino, написано множество открытых программ, разработано великое множество примочек в виде датчиков, двигателей, мониторчиков, да всего, чего только душе угодно! Arduino в настоящее время больше похож на игровой конструктор для детей и взрослых. Однако не стоит забывать, что ядро этого конструктора управляет «умными домами», современной бытовой электроникой, техникой, автомобилями, самолетами, оружием и даже космическими аппаратами. Несомненно, такой конструктор будет являться одним из лучших подарков для любого представителя сильной половины человечества.
В принципе, все просто!
Остались вопросы? Напишите комментарий. Мы ответим и поможем разобраться =)
Автор публикации
не в сети 4 недели
wandrys
877 Комментарии: 0Публикации: 27Регистрация: 17-03-2016FPGA – Программируемые логические интегральные схемы / Хабр
Вы хотите узнать, как получить работу по проектированию электроники космического корабля? Мне надавно пришло предложение поинтервьироваться на позицию FPGA designer для Blue Origin (см. выше). Лично мне такая позиция не нужна (у меня уже есть позиция ASIC designer-а в другой компании), но я отметил, что технические требования к претендентам в Blue Origin точно совпадают с содержанием семинара для школьников и младших студентов, который пройдет 15-17 сентября на выставке ChipEXPO в Сколково, с поддержкой от РОСНАНО. Хотя разумеется на семинаре мы коснемся технологий Verilog и FPGA только на самом начальном уровне: базовые концепции и простые, но уже интересные, примеры. Чтобы устроится после этого в Blue Origin, вам все-же потребуется несколько лет учебы и работы.
Из-за короновируса семинар будет удаленный, поэтому принять участие смогут не только школьники и студенты Москвы, но и всей России, Украины, Казахстана, Калифорнии и других стран и регионов. Физически проводить лекции и удаленно помогать участникам будут преподаватели и инженеры МИЭТ, ВШЭ МИЭМ, МФТИ, Черниговского Политеха, Самарского университета, IVA Technologies и fpga-systems.ru.
Для участия сначала, еще до семинара, нужно пройти три части теоретического курса от РОСНАНО, под общим названием «Как работают создатели умных наночипов»: «От транзистора до микросхемы», «Логическая сторона цифровой схемотехники», «Физическая сторона цифровой схемотехники». Этот курс необходим, чтобы вы понимали, что вы делаете, по время практического семинара. По получению сертификата окончания теоретического онлайн-курса, вы можете зайти в офис РОСНАНО в Москве и получить бесплатную плату для практического семинара (если они останутся, преимущество имеют школьники). С этой платой вы можете работать дома, до, во время и после семинара в Сколково.
Как получить плату, подготовится к семинару и что на нем будет:
Цифровая фильтрация на ПЛИС – Часть 1 / Хабр
Всем привет!Давно хотел начать цикл статей, посвященных цифровой обработке сигналов на ПЛИС, но по разным причинам так и не мог к этому приступить. К счастью, в распоряжении появилось немного свободного времени, поэтому периодически я буду публиковать материалы, в которых отражены различные аспекты, связанные с ЦОС на ПЛИС.
В этих статьях я постараюсь минимизировать теоретическое описание тех или иных алгоритмов и большую часть материала посвятить практическим тонкостям, с которыми столкнулся лично я и мои коллеги, и знакомые, так или иначе связанные с разработкой на ПЛИС. Надеюсь, данный цикл статей принесет пользу, как начинающим инженерам, так и матёрым разработчикам.
Часть 1: CIC фильтр
В первой части рассмотрим простейший CIC фильтр. CIC – «cascaded integral-comb», по-русски – каскадный интегрально-гребенчатый фильтр типа БИХ (с бесконечной импульсной характеристикой). Класс таких фильтров широко используется в задачах, где требуется работа на нескольких скоростях передачи данных. CIC фильтры активно применяются для децимации и интерполяции, то есть для понижения и повышения частоты дискретизации. CIC фильтр сам по себе есть не что иное, как фильтр нижних частот (ФНЧ). То есть такой фильтр пропускает нижние частоты спектра, обрубая верхние за частотой среза. АЧХ фильтра строится по закону ~sin(x)/x. Главное преимущество CIC фильтров состоит в том, что они совсем не требуют операций умножения (в отличие от другого типа фильтров, например, КИХ).
Введение
Из названия можно догадаться, что в основе CIC фильтра лежит два базовых блока: интегратор и гребенчатый фильтр (дифференциатор). Интегрирующее звено (int) представляет собой обычный БИХ-фильтр первого порядка, выполненный как самый простой аккумулятор. Гребенчатый фильтр (comb) является КИХ-фильтром первого порядка.
Между интегратором и гребенчатым фильтром часто ставится узел повышения или понижения частоты дискретизации в целое число раз — R.
- В случае понижения частоты дискретизации из входной последовательности выбирается каждый R-отсчет, образуя прореженную выходную последовательность.
- В случае повышения частоты дискретизации между отсчетами входной последовательности просто вставляются нули, которые затем сглаживаются в интегрирующей секции, образуя последовательность на увеличенной частоте дискретизации.
Формулы для передаточной и амплитудно-частотной характеристик приведены ниже:
Более подробно со всеми математическими выкладками обо всех аспектах децимации и интерполяции можно почитать в других источниках, на которые в конце статьи я приведу ссылки.
Дециматор
Если CIC-фильтр используется для понижения частоты дискретизации, то он называется дециматором. В таком случае первым звеном идет интегратор, затем происходит понижение частоты дискретизации и, наконец, идет звено дифференцирующего фильтра.
Интерполятор
Если CIC-фильтр используется для повышения частоты дискретизации, то он называется интерполятором. В таком случае дифференцирующее звено стоит на первом месте, затем происходит повышение частоты дискретизации и, наконец, идет звено интегрирующего фильтра.
В зависимости от задержки входного сигнала в дифференцирующем звене, можно получать различные частотные характеристики фильтра. Известно, что при увеличении параметра задержки D, увеличивается количество «нулей» амплитудно-частотной характеристики (АЧХ) фильтра.
Заметим, что для связки интегратора и гребенчатого фильтра (CIC фильтра) при увеличении параметра D в дифференцирующей секции нули АЧХ смещаются к центру – изменяется частота среза фильтра Fc = 2 pi / D.
Каскадное соединение интегратора и гребенчатого фильтра без операций децимации и интерполяции называется фильтром «скользящего среднего». Уровень первого бокового лепестка такого фильтра составляет всего -13 дБ, что достаточно мало для серьезных задач ЦОС.
В силу линейности математических операций, происходящих в CIC фильтре возможно каскадное соединение нескольких фильтров подряд. Это дает пропорциональное уменьшение уровня боковых лепестков, но также увеличивает завал главного лепестка спектра (под спектром я часто буду понимать АЧХ фильтра). Таким образом, при N-каскадном соединении однотипных CIC фильтров происходит перемножение идентичных передаточных характеристик. Как правило, секции интеграторов и гребенчатых фильтров объединяются вместе по типу. Например, сначала последовательно ставится N секций однотипных интеграторов, затем N секций однотипных дифференцирующих фильтров.
На следующем рисунке приведена АЧХ фильтра при различных параметрах коэффициента дискретизации R (расчет сделан в MathCAD 14).
АЧХ CIC фильтра полностью эквивалентна частотной характеристике FIR фильтра с прямоугольной импульсной характеристикой (ИХ). Общая ИХ фильтра определяется как свертка всех импульсных характеристик каскадов связки интегратора и гребенчатого фильтра. С ростом порядка CIC фильтра, его ИХ интегрируется соответствующее число раз. Таким образом, для CIC фильтра первого порядка ИХ – прямоугольник, для фильтра второго порядка ИХ – равнобедренный треугольник, для третьего порядка ИХ – парабола и т.д.
Рост разрядности данных
К несчастью, увеличение величины задержки D в гребенчатой структуре и увеличение порядка фильтра N приводят к росту коэффициента передачи. Это в свою очередь приводит к увеличению разрядности на выходе фильтра. В задачах ЦОС, где применяются CIC фильтры нужно всегда об этом помнить и следить, чтобы передаваемые сигналы не выходили за используемую разрядную сетку. К примеру, негативный эффект роста разрядности проявляется в значительном увеличении используемых ресурсов кристалла ПЛИС.
Интерполятор: использование ограниченной точности не влияет на внутреннюю разрядность регистров, масштабируется только последний выходной каскад. Существенный рост разрядности данных происходит в секциях интеграторов.
Дециматор: CIC фильтр-дециматор очень чувствителен к параметрам D, R и N, от которых зависит разрядность промежуточных и выходных данных. И дифференцирующее звено, и интегратор влияют на конечную разрядность выходного сигнала.
В этих формулах: B — разрядность входных данных, Bmax — разрядность выходных данных, R — коэффициент дискретизации, D — параметр задержки, N — порядок фильтра (количество каскадов).
Замечание! В статье Хогенауэра описаны принципы выбора разрядности для каждого каскада дециматора. Xilinx и Altera при реализации своих фильтров учитывают негативный эффект роста разрядности фильтра и борятся с этим явлением методами, описанными в статье.
Xilinx CIC Filter
Так как я моя работа на 99% связана с микросхемами фирмы Xilinx, я приведу описание IP-ядра фильтра для этого вендора. Но смею вас заверить, что для Altera все практически аналогично.
Для того, чтобы создать CIC фильтр, необходимо зайти в приложение CORE Generator и создать новый проект, в котором указать тип используемого кристалла ПЛИС и различные другие несущественные в данном случае настройки.
CIC Compiler — Вкладка 1:
Component name имя компонента (используются латинские буквы a-z, цифры 0-9 и символ «_»).
Filter Specification:
- Filter type — тип фильтра: интерполирующий / децимирующий.
- Number of stages — количество каскадов интеграторов и гребенчатых фильтров: 3-6.
- Differential delay — задержка в дифференциальных ячейках фильтра: 1-2.
- Number of channels — количество независимых каналов: 1-16.
Sample Rate Change Specification:
- Fixed / Programmable — тип коэффициента дискретизации R: постоянный / программируемый.
- Fixed or Initial Rate — значение коэффициента дискретизации R: 4..8192.
- Minimum Rate — минимальное значение коэффициента дискретизации R: 4..8.
- Maximum Rate — максимальное значение коэффициента дискретизации R: 8..8192.
Hardware Oversampling Specification: эти параметры влияют на выходную частоту дискретизации, количество тактов, требуемых для обработки данных. От этих параметров также зависит уровень параллелизма внутри ядра и количество занимаемых ресурсов.
- Select format — выбор частотных соотношений фильтра: Frequency Specification / Sample period.
- Frequency Specification — Частотная спецификация: пользователь задает частоту дискретизации и частоту обработки данных.
- Sample period — Тактовая спецификация: пользователь задает отношение частоты обработки к тактовой частоте данных.
- Input Sampling Frequency — входная частота дискретизации: *.
- Clock frequency — частота обработки фильтра: *.
- Input Sampling period — отношение частоты обработки к частоте входного тактового сигнала: *.
* — диапазон зависит от общих настроек и коэффициента дискретизации R.
CIC Compiler — Вкладка 2:
Numerical Precision:
- Input Data Width — разрядность входных данных: 2..20.
- Quantization — округление выходных данных: полная точность / округление разрядной сетки.
- Output Data Width — разрядность выходных данных, диапазон зависит от коэффициентов N, D и R (максимальное значение — 48 битов).
Optional:
- Use Xtreme DSP Slice — использовать встроенные DSP-блоки для реализации фильтра.
- Use Streaming Interface — использовать потоковый интерфейс для многоканальной реализации фильтра.
Control Options:
- ND — «New data», входной сигнал, определяющий поступление данных на вход фильтра.
- SCLR — синхронный сброс фильтра (логическая единица на этом входе производит сброс).
- CE — «Clock Enable», сигнал разрешения тактирования фильтра.
CIC Compiler — Вкладка 3:
Summary — эта вкладка в виде списка отражает конечные настройки фильтра (количество каскадов, параметры частот, разрядность входных, выходных и промежуточных данных, задержка в фильтре и т.д.).
В левой части окна CIC Compiler есть три полезные дополнительные вкладки:
- IP-symbol — схематичный вид IP-блока с активными портами ввода/вывода.
- Freq. response — передаточная характеристика CIC-фильтра.
- Resource estimate — оценка занимаемых ресурсов.
После установки всех настроек необходимо нажать на кнопку Generate. В результате приложение CORE Generator через какое-то время выдаст целый набор файлов, из которых нам нужны самые основные:
- *.VHD (или *.V) — файл исходных кодов для моделирования на VHDL или Verilog.
- *.VHO — бесполезный файл, но из него можно взять описание компонента и портирование для вставки в проект.
- *.NGC — файл списка соединений. Содержит описание архитектуры IP-ядра (используемые компоненты и связи сигналов между ними) для выбранного кристалла ПЛИС.
- *.XCO — лог-файл, в котором хранятся все параметры и настройки IP-ядра. Полезный файл при работе в среде Xilinx ISE Design Suite.
Если вы работаете в среде ISE Design Suite, то CORE Generator автоматически создаст нужные файлы в рабочем каталоге. Для других средств разработки (типа Modelsim или Aldec Active-HDL) необходимо перенести нужные файлы в соответствующий рабочий каталог.
CIC Filter in MATLAB
Пример 1: Для моделирования очень удобным средством является программа MATLAB. Для примера возьмем модель CIC-фильтра 4 порядка, сделанного на логических элементах из System Generator Toolbox от Xilinx. Децимация и интерполяция не используется (CIC вырождается в фильтр скользящего среднего с окном 16). Параметры фильтра: R = 1, N = 4, D = 16. На следующем рисунке приведена модель одного каскада в среде MATLAB.
Посмотрим, как выглядит импульсная характеристика после каждого каскада фильтра, для этого подадим на вход системы периодический единичный импульс.
Видно, что сигнал на выходе первого звена образует прямоугольный импульс длительностью = D, на выходе второго звена — треугольный сигнал длительностью 2D, на выходе третьего звена — параболический импульс, на выходе третьего — кубическая парабола. Результат полностью согласуется с теорией.
Пример 2: непосредственно IP-ядро CIC фильтра. Параметры: N = 3, R = 4, D = 1. На следующем рисунке представлена модель фильтра.
Если на вход такого фильтра подать единичный импульс длительностью несколько тактов (например 32), то на выходе образуется сигнал параболической формы, напоминающий ИХ фильтра скользящего среднего третьего порядка.
Резюме
На этом хотелось бы подвести итог. CIC фильтры используются во многих задачах, где требуется изменить частоту дискретизации. CIC фильтры применяются в системах, работающих на нескольких частотах дискретизации (multirate processing), например, в аудио-технике для изменения бит-рейта (из 44.1кГц в 48кГц и обратно). CIC фильтры применяются в системах связи для реализации DDC (digital down converter) и DUC (digital up converters). Пример использования CIC-фильтров: микросхема цифрового приема AD6620 от Analog Devices.
Реализация собственного фильтра на ПЛИС на HDL языках часто не требуется, и можно смело пользоваться готовыми ядрами от вендоров, либо готовыми opensource-проектами. Если все же возникла необходимость в реализации собственного CIC фильтра для прикладной задачи, то нужно помнить следующие принципы.
CIC фильтры обладают рядом особенностей:
- Простые в реализации и не требуют операций умножения.
- Децимация и интерполяция на CIC фильтрах используется повсеместно для быстрого изменения частоты дискретизации, как в целое, так и в дробное число раз.
- С ростом порядка фильтра N и величины задержки D увеличивается разрядность промежуточных и выходных данных.
- С ростом порядка фильтра N увеличивается подавление боковых лепестков и увеличивается неравномерность главного лепестка АЧХ.
- Рекомендуется использовать фильтры порядка не более 6-8, т.к. с увеличением порядка усложняется реализация, увеличивается объем занимаемых ресурсов, а также происходят искажения АЧХ фильтра в пределах полосы пропускания.
- С ростом параметра задержки D гребенчатого фильтра изменяется частота среза фильтра, но в практических целях при каскадном соединении параметр D < 3.
- При децимации в R раз существенно увеличивается разрядность на выходе фильтра.
- При интерполяции основной вклад в разрядность промежуточных и выходных данных вносят только интегрирующие звенья.
- АЧХ CIC фильтра эквивалентна АЧХ FIR фильтра с прямоугольной импульсной характеристикой. Общая ИХ фильтра определяется как свертка всех импульсных характеристик каскадов связки интегратора и гребенчатого фильтра.
- При изменении частоты на выходе фильтра в ПЛИС используют сигнал разрешения «clock enable», а частоту обработки не изменяют.
- Если отношение «частота обработки / частота дискретизации» >> 1, в ПЛИС возможно повторно использовать ресурсы фильтра, тем самым для многоканальной системы реализовать обработку с минимальной затратой ресурсов кристалла.
- В современных ПЛИС CIC фильтры реализуются на блоках DSP (Xilinx, Altera), но при отсутствии свободных ресурсов возможна реализация на логических ячейках (SLICEs).
- После CIC фильтра рекомендуется ставить умножитель с программируемым коэффициентом усиления (gain multiplier), который будет подстраивать уровень сигнала до нужного динамического диапазона
- CIC фильтры вносят искажение в спектр выходного сигнала, поэтому после CIC фильтра необходимо ставить компенсирующий FIR фильтр (методика расчета представлена в даташите Altera, для расчета необходим MATLAB).
Литература
Продолжение следует…
Бесплатный учебник электроники, архитектуры компьютера и низкоуровневого программирования на русском языке
Господа! Я рад сообщить, что наконец-то все желающие могут загрузить бесплатный учебник на более чем 1600 страниц, над переводом которого работало более полусотни человек из ведущих университетов, институтов и компаний России, Украины, США и Великобритании. Это был реально народный проект и пример международной кооперации.
Учебник Дэвида Харриса и Сары Харрис «Цифровая схемотехника и архитектура компьютера», второе издание, 2012, сводит вместе миры программного обеспечения и аппаратуры, являясь одновременно введением и в разработку микросхем, и в низкоуровневое программирование для студентов младших курсов. Этот учебник превосходит более ранний вводный учебник «Архитектура компьютера и проектирование компьютерных систем» от Дэвида Паттерсона и Джона Хеннесси, причем соавтор предыдущего учебника Дэвид Паттерсон сам рекомендовал учебник от Харрисов как более продвинутый. Следуя новому учебнику, студенты строят реализацию подмножества архитектуры MIPS, используя платы с ПЛИС / FPGA, после чего сравнивают эту реализацию с индустриальными микроконтроллерами Microchip PIC32. Таким образом вводится вместе схемотехника, языки описания аппаратуры Verilog и VHDL, архитектура компьютера, микроархитектура (организация процессорного конвейера) и программирование на ассемблере — в общем все, что находится между физикой и высокоуровневым программированием.
Как загрузить? К сожалению, не одним кликом. Сначало надо зарегистрироваться в пользовательском коммьюнити Imagination Technologies, потом зарегистрироваться в образовательных программах на том же сайте, после чего наконец скачать:
Последовательность регистрации:
1) зарегистрироваться в коммьюнити community.imgtec.com/register
2) подтвердить емейл
3) login в коммьюнити
4) пойти в imagination university program — community.imgtec.com/university/university-registration
5) пойти в меню University | Join IUP
6) заполнить
7) пойти в community.imgtec.com/downloads/digital-design-and-computer-architecture-russian-edition и наконец скачать
Также в поле телефонного кода страны есть баг — вместо «максимум три символа» она требует «минимум три символа», из-за чего в Великобритании сайт работает (+44), а в России и США — нет (код +7 и +1). Напишите туда что-нибудь абстрактное.
К сожалению сайт только начал работать, и регистрация сделана криворуко. Я извиняюсь за такую накладку, это должны поправить скоро.
Cлайды об учебнике — bit.ly/hh3slides
Список участников:
а также Фонд Инфраструктурных и Образовательных Программ РОСНАНО.
Авторы учебника:
Дэвид Харрис:
Сара Харрис:
Американская и санкт-петербургская часть команды переводчиков:
Американская и британская часть команды переводчиков:
Но вообще идея этого перевода появилась на Красной Площади, когда Иван из МИФИ (крайний слева) сказал Юрию из Imagination Technologies (в центре) «а что если организовать перевод Harris & Harris колхозом»?
ДизайнPlus Architecture для собственных офисов
Какую роль играет отделка, когда она находится в собственном офисе архитектора? Отчасти это делается для того, чтобы создать приятное рабочее место для сотрудников, но, конечно, главным преимуществом здесь является живое портфолио, трехмерный интерактивный образец дизайна, который клиенты и потенциальные клиенты могут потрогать и прогуляться. Новое оборудование для офисов Plus Architecture было организовано как внутренний дизайнерский конкурс, в котором приняли участие все сорок сотрудников практики.«Концептуальный дизайн должен был лучше всего отражать то, что вы думаете о Plus, и мы не говорили, что это было», — говорит директор Крейг Йелланд.
Победившая команда состояла из четырех студентов с опытом работы, схема которых была выбрана над концепциями дизайнерами интерьеров и архитекторами проекта и младшими архитекторами. Их темой было «привнести деревья внутрь» — пространство находится в офисном здании на зеленой улице Сент-Килда в Мельбурне.
Смотреть галерею
Треугольные фанерные стены символизируют абстрактные стволы деревьев, переносящие природу в помещение.
Изображение: Плюс Архитектура
Фанерные треугольные стены обозначают лежащие на боках гигантские абстрактные стволы деревьев. Резные пустоты создают зоны для встреч и ожидания, выстланные зеленой панелью EchoPanel в соответствии с темой. «Мы вырвали существующий интерьер, вернули его к основам и отполировали плиту», — говорит Йелланд.
Строительство было завершено персоналом, за исключением некоторых специализированных услуг, таких как водопровод и электричество.В постройке участвовали 18 сотрудников. Это заняло больше времени, чем ожидалось. «У нас была действительно сложная модель ArchiCAD, — говорит Йелланд. «В какой-то момент мы хотели что-то изменить, и это заняло четыре часа компьютерного времени, поэтому вместо этого мы внесли изменения на месте». Ни одна из панелей не была вырезана на компьютере; вся работа была сделана вручную на месте.
Смотреть галерею
Канаты для лазания и резинка были использованы для возведения сложных многогранных фанерных конструкций.
Изображение: Плюс Архитектура
Для создания сложных граненых углов в процессе строительства использовалась оригинальная комбинация веревок для лазания, резинки на поясе и веревки. Между потолком и полом натягивается кусок резинки, а веревка, прикрепленная к кирпичу, вытягивает вершину в нужное место. Затем этот тонкий узор был заменен каркасом из сосны.Паутина линий заполнила рабочее пространство, плотники ныряли и ткали во время работы.
Мне вспоминается художник Фред Сэндбэк и его пространственные инсталляции из струны. Интересно, можно ли было оставить часть веревки где-нибудь, например, трехмерный эскиз в космосе? Возможно, это можно было сделать в собственно «офисной» части, где обстановка становится менее экспериментальной. Существующая пожарная лестница в центре этой рабочей зоны сделала ее логическим центром обслуживания, а в зоне кухни для персонала есть настольный теннис и настольный футбол.
Смотреть галерею
Слово «плюс», нарисованное от руки на фанерной стене, является единственным указателем.
Изображение: Плюс Архитектура
Большая часть усилий и успеха приходится на публичное лицо офиса. Из входного фойе вы видите фанерный каньон, его изгибы и повороты скрывают более прозаические помещения для персонала. На вашем пути по органическому коридору вас простят за то, что вы пропустите зал заседаний и гардероб, скрытый секретными дверями в граненой стене.Йелланд особенно гордится дверью в зал заседаний. «Она не только не квадратная, но и не вертикальная, это секретная дверь с обеих сторон», — говорит он.
Внутри зала заседаний мы видим обратную сторону граненой стены, которая также облицована фанерой. Чтобы проверить прочность отдельно стоящей изогнутой стены с гвоздями без помощи инженера, они попробовали сначала уложить ее и прыгнуть на ней. Стол для зала заседаний также был изготовлен собственными силами, опираясь на фанерный постамент в форме знака «плюс» (единственный слой, вырезанный на компьютере) и опираясь на стальные балки, сваренные одним из сотрудников.Знак «плюс» появляется еще дважды в отделке: маленькая версия, отлитая в бетонную стойку регистрации, как минимальную вывеску, и гигантская версия, вырезанная в каньоне, образуя одну из зон для встреч.
Прогулка по подобному пространству напоминает мне о том, почему мы обычно строим прямые стены. «Пока что только один человек ударился головой о фурнитуру, — уверяет меня Йелланд, — но они отступили». Если смотреть из вестибюля лифта, невозможно принять скульптурное деревянное резное пространство ни за что иное, кроме какого-то конструкторского бюро, поэтому в практике не использовались какие-либо вывески, кроме слова «плюс» в нижнем регистре, нарисованного вручную. длиной около пяти сантиметров, прямо на фанеру.По словам Йелланда, «нам больше не нужно никому рассказывать, что мы делаем».
.A + I (Архитектура плюс информация) | Archinect
10 карьерных возможностей архитектора старшего уровня в Нью-Йорке
9 фирм из Нью-Йорка в настоящее время нанимают архитекторов и дизайнеров старшего уровня
Хотите присоединиться к небольшой или средней фирме? A + I, Kevin Tsai Architecture, StudioSC, LARGE Architecture и Leo Villareal Studio в настоящее время нанимают!
10 рекомендуемых вакансий для архитекторов среднего уровня в Нью-Йорке
Мечтаете о большом яблоке? Вот 9 фирм из Нью-Йорка, которые все еще ищут идеального кандидата
Лучший работодатель Archinect: еженедельный обзор № 4
.
