Как правильно форматировать текст в Telegram. Какие стили шрифтов доступны в мессенджере. Как использовать форматирование для улучшения читаемости сообщений. Какие способы форматирования существуют в Telegram. Как применять разные стили к тексту в Telegram.
Доступные стили форматирования текста в Telegram
Telegram предлагает пользователям несколько базовых стилей форматирования текста, которые позволяют сделать сообщения более структурированными и читабельными:
- Обычный текст (Regular) — стандартное отображение без дополнительных эффектов
- Полужирный (Bold) — выделение текста жирным начертанием
- Курсив (Italic) — наклонное начертание текста
- Подчеркнутый (Underline) — подчеркивание текста линией снизу
- Зачеркнутый (Strikethrough) — перечеркивание текста линией посередине
- Моноширинный (Monospace) — текст фиксированной ширины, имитирующий печатную машинку
Комбинируя эти базовые стили, можно добиться наиболее подходящего оформления для любого типа сообщений — от обычных чатов до информационных каналов.

Способы форматирования текста в Telegram
Существует три основных способа применить форматирование к тексту в Telegram:
1. Контекстное меню форматирования
Этот способ работает как на мобильных устройствах, так и в десктопной версии:
- Выделите нужный фрагмент текста
- В появившемся меню выберите пункт «Форматирование»
- Выберите нужный стиль из списка
Преимущество этого метода в том, что он интуитивно понятен и не требует запоминания специальных символов или сочетаний клавиш.
2. Горячие клавиши
При работе с Telegram на компьютере удобно использовать сочетания клавиш:
- Жирный — Ctrl (Cmd) + B
- Курсив — Ctrl (Cmd) + I
- Подчеркнутый — Ctrl (Cmd) + U
- Зачеркнутый — Ctrl (Cmd) + Shift + X
- Моноширинный — Ctrl (Cmd) + Shift + M
Этот метод позволяет быстро форматировать текст, не отрывая рук от клавиатуры.
3. Специальные символы
Можно использовать специальные символы для обрамления текста:
- Жирный — две звездочки с обеих сторон: **текст**
- Курсив — два знака подчеркивания с обеих сторон: __текст__
- Моноширинный — три обратных апострофа с обеих сторон: «`текст«`
Этот способ особенно удобен при наборе текста на мобильных устройствах.

Практические примеры использования форматирования в Telegram
Рассмотрим несколько ситуаций, где форматирование текста может быть особенно полезным:
Структурирование длинных сообщений
Для улучшения читабельности длинных текстов можно использовать следующие приемы:
- Выделять заголовки жирным шрифтом
- Использовать курсив для цитат или примечаний
- Применять подчеркивание для ключевых фраз или ссылок
Оформление списков
При составлении списков удобно использовать различные стили:
- Маркированные списки с жирными маркерами
- Нумерованные списки с подчеркнутыми номерами
- Вложенные списки с разными стилями для разных уровней
Выделение важной информации
Для акцентирования внимания на ключевых моментах можно:
- Использовать жирный шрифт для самых важных фраз
- Применять курсив для дополнительных пояснений
- Комбинировать стили, например, жирный курсив для особо важных заметок
Форматирование кода в Telegram
Для программистов и технических специалистов Telegram предлагает удобный способ оформления кода с помощью моноширинного шрифта:
- Однострочный код можно выделить с помощью одинарных обратных апострофов: `code`
- Многострочные блоки кода оформляются тройными обратными апострофами: «`code block«`
Такое форматирование улучшает читабельность кода и предотвращает случайное изменение его структуры при копировании.
Особенности форматирования в Telegram-каналах
При ведении информационного канала в Telegram грамотное форматирование текста особенно важно:
- Используйте жирный шрифт для заголовков постов
- Выделяйте курсивом важные цитаты или комментарии
- Применяйте подчеркивание для ссылок на источники или дополнительные материалы
- Используйте моноширинный шрифт для технических терминов или команд
Правильное форматирование поможет сделать ваши посты более привлекательными и удобными для чтения.
Ограничения форматирования в Telegram
При использовании форматирования в Telegram следует учитывать некоторые ограничения:
- Нельзя применять разные цвета к тексту
- Отсутствует возможность изменения размера шрифта
- Нет встроенных возможностей для создания таблиц
- Некоторые стили могут некорректно отображаться в старых версиях приложения
Несмотря на эти ограничения, доступных инструментов форматирования вполне достаточно для создания хорошо структурированных и читабельных сообщений.

Советы по эффективному использованию форматирования в Telegram
Чтобы максимально эффективно использовать возможности форматирования в Telegram, придерживайтесь следующих рекомендаций:
- Не злоупотребляйте форматированием — избыток стилей может затруднить чтение
- Используйте единообразное форматирование в рамках одного чата или канала
- Комбинируйте разные стили для создания визуальной иерархии информации
- Учитывайте, что некоторые пользователи могут использовать режим для людей с нарушениями зрения
- Регулярно практикуйтесь в использовании разных способов форматирования для повышения скорости набора
Следуя этим советам, вы сможете сделать ваши сообщения в Telegram более понятными и привлекательными для читателей.
Как форматировать текст в Телеграме
Составила для вас шпаргалку по форматированию текста в Telegram: какие здесь есть стили шрифта и как применять их, чтобы было красиво и полезно. В конце покажу небольшой лайфхак с одним из стилей, который сделает ваш канал более удобным для подписчиков.
- Форматирование текста в Телеграме: какое бывает
- С помощью чего можно форматировать текст
- Меню редактирования
- Горячие клавиши
- Памятка по форматированию текста в Телеграме
- Контекстное меню
- Горячие клавиши
- Спецсимволы
Форматирование текста в Телеграме: какое бывает
По умолчанию все сообщения в Telegram пишутся regular стилем: обычный шрифт без наклона, подчеркивания и так далее. Но при необходимости стиль можно поменять, например, если нужно выделить слово или фразу в тексте.
Какие опции есть:
- курсив,
- полужирный,
- моноширинный,
- подчеркнутый,
- зачеркнутый.

Вот пример уместного форматирования текста в Telegram канале: заголовок поста выделен полужирным, акцент во втором абзаце — курсивом.
Пример разного выделения текста в посте на телеграм-каналеСтатья по теме: «Как вести Telegram канал правильно».
С помощью чего можно форматировать текст
В зависимости от того, на каком устройстве вы используете Telegram, есть три основных способа отформатировать текст — контекстное меню редактирования, спецсимволы и сочетания горячих клавиш.
Меню редактирования
Этот способ работает для мобильных телефонов и десктопа. Выделяете нужный фрагмент текста, всплывает небольшое меню — в нем выбираете раздел с форматированием и нужный стиль шрифта. В этом же меню можно повесить ссылку на текст.
Покажу на примере телефона на Android. Выделяем нужный текст, во всплывающем меню жмем на три точки. Открывается список всех доступных опций форматирования — кроме стилей, здесь также есть опции копирования, вставки и создания гиперссылки.
Этот способ работает аналогично на всех устройствах, различается лишь вид всплывающего меню.
Горячие клавиши
Если пользуетесь Telegram c компьютера, будет удобно использовать для форматирования сочетания клавиш. Их легко запомнить, а использовать быстрее, чем вызывать меню.
Вот сочетания для разных типов форматирования текста в Telegram. Если работаете на Windows, используйте клавишу Ctrl, если на MacOS — клавишу Cmd.
- Жирный — Ctrl (Cmd) + B
- Курсив
- Подчеркнутый — Ctrl (Cmd) + U
Зачеркнутый— Ctrl (Cmd) + Shift + XМоноширинный— Ctrl (Cmd) + Shift + M- Гиперссылка — Ctrl (Cmd) + K
Символы
Последний способ — при наборе обернуть нужный текст в специальные символы. Так можно применить только три стиля: полужирный, курсив и моноширинный.
- Для полужирного нужны две звездочки слева и справа от фрагмента.
 **text** → text
**text** → text - Для курсива понадобятся по два знака нижнего подчеркивания слева и справа. __text__ → text
- Чтобы сделать текст моноширинным, оберните его в тройные апострофы. “`text“`→
text
Откройте для себя чат-бота
Выстраивайте автоворонки продаж и отвечайте на вопросы пользователей с помощью чат-бота в Facebook, VK и Telegram.
Создать чат-бота
Лайфхак: быстрое копирование с помощью шрифта
Кроме выделения смысловых акцентов, форматирование текста в Telegram можно использовать для практической цели. Если фрагмент текста в сообщении выделен моноширинным шрифтом, то он скопируется при одном нажатии. Не нужно будет выделять нужный текст и искать функцию копирования во всплывающем меню. Функция работает только на мобильных устройствах и планшетах.
Как работает быстрое копирование моноширинного текстаВыделяйте моноширинным шрифтом текст, который понадобится скопировать:
- номер телефона или email,
- фрагмент кода,
- длинные банковские реквизиты и так далее.

Вот живой пример — канал про работу с Google Таблицами использует моноширинный шрифт, чтобы выделить формулы. Подписчики могут легко скопировать нужные строки.
Статья по теме: «Как раскрутить Telegram канал с нуля и наращивать аудиторию подписчиков в будущем».
Форматирование текста пригодится, если вы ведете канал в Telegram или просто много переписываетесь с коллегами и друзьями. Используйте стили, чтобы выделять нужное и структурировать свои сообщения. Ниже — памятка, как использовать три способа форматирования текста в Telegram, сохраните и используйте при необходимости.
А чтобы сэкономить время на общение с клиентами в Telegram, создайте чат-бота с помощью SendPulse. Автоматизируйте рутину в бизнес-процессах и запускайте рассылки на нужную аудиторию — бесплатно.
Памятка по форматированию текста в Телеграме
Контекстное меню
Выделить текст — кликнуть правой кнопкой (на десктопе) — выбрать форматирование текста в появившемся меню — выбрать нужный стиль.
Работает на:
- Android
- iOS
- Windows
- MacOS
- Linux
Горячие клавиши
Выделить текст и нажать нужное сочетание:
- Жирный — Ctrl (Cmd) + B
- Курсив — Ctrl (Cmd) + I
- Подчеркнутый — Ctrl (Cmd) + U
Зачеркнутый— Ctrl (Cmd) + Shift + X- Моноширинный — Ctrl (Cmd) + Shift + M
- Гиперссылка — Ctrl (Cmd) + K
Работает на:
- веб-версии
- Windows
- MacOS
- Linux
Спецсимволы
- Жирный — **text** → text
- Курсив — __text__ → text
- Моноширинный — “`text“` →
text
Работает на:
- Android
- iOS
- Windows
- MacOS
- Linux
3д неоновый текст конструктор красивых шрифтов и надписей с эффектами онлайн
Выбирай ниже эффекты шрифтов, логотипов для редактирования:
Еще больше разных текстовых эффектов доступны в центре загрузок переходи, скачивай и импортируй для редактирования
СКАЧАТЬ СТИЛЬ
- ВСЕ
-
3D НАДПИСИ
-
НЕОНОВЫЙ ТЕКСТ
-
ГЛИТЧ ТЕКСТ
-
СТИКЕР НАДПИСИ
-
ЛИНИИ КОНТУР
-
РАЗНЫЕ, НАДПИСИ С ТЕКСТУРАМИ
-
РЕТРО 80S VHS
-
ИГРОВЫЕ
-
КИБЕРПАНК
-
ТАТУ
-
ПРОСТЫЕ
-
ДЕКОРАТИВНЫЕ
-
МЕТАЛЛ ЗОЛОТО
-
КАМЕНЬ
-
ЛЕД, СНЕГ
-
КИНО, СУПЕРГЕРОЙСКИЕ
-
КОСМИЧЕСКИЕ
-
ДЫМ
-
ТОК
-
СПОРТ, КОМАНДА
-
БРЕНДОВЫЕ
-
ПЛАТНЫЕ
ПОДСКАЗКИ ИНСТРУКЦИИ
МАГАЗИН ЭФФЕКТОВ
Создать надпись с геймплей эффектом Шрифт в стиле Game play
Создать светящуюся магическую надпись Шрифт в стиле заклинания
Конструктор шрифтов с неоновым эффектом Добавить шрифту неоновый эффект
Конструктор Glitch надписей из гличт шрифта Сделать глитч текст в стиле неона
Конструктор красивых retrowave шрифтов Шрифт в стиле retrowave
Генератор стикер надписей из красивых шрифтов Создать надпись эффект стикера
Конструктор неоновых надписей со свечением Добавить шрифту неоновый эффект
Генератор каллиграфических надписей Шрифт в каллиграфическом стиле
Генератор шрифтовых эффектов RedLine Добавить шрифту стиль RedLine
Создать металлическую космическую надпись Шрифт с космическим ORBIT эффектом
Шрифт с ярким стикер эффектом Создать яркую стикер надпись
Создать магическую объемную надпись Шрифт в магическом стиле
Конструктор киберпанк текста онлайн Добавить шрифту Cyberpunk эффект
Красивый текст эффектом тени Добавить шрифту объемную тень
Генератор надписей с эффектом светящихся контуров Добавить шрифту неоновые контуры
Создать надпись с золотым эффектом Добавить шрифту золотой эффект
Генератор крутых надписей с Дино эффектом Добавить шрифту дино эффект
Редактор красивых объемных надписей Красивый шрифт в ярком арт стиле
Конструктор киберпанк надписи онлайн Неоновый Cyberpunk шрифт
Конструктор объемных ярких шрифтов онлайн Добавить шрифту show эффект
Конструктор шрифтов с nature эффектом Создать надпись nature эффект
Конструктор надписей в Drive стиле Добавить шрифту драйв эффект
Красивый текст из камня с магическим эффектом Добавить шрифту каменный эффект
Конструктор объемных многослойных надписей Шрифт с эффектом многослойности
3д надпись в классическом стиле Создать белый объемный 3д текст
Создавай объемные тексты с двойным 3Д эффектом Добавить к шрифту двойной 3д эффект
Генератор киберпанк надписи онлайн Красивый Cyberpunk шрифт
Надутые градиент надписи из красивых шрифтов Создать надпись эффект градиента
Конструктор красивых шрифтов с градиентом Шрифт в стиле virtual градиент
Создавай объемные надписи с 3Д эффектом 3D Конструктор надписей
Редактор 3д текстов с эффектом градиент свечения Создать 3д текст светящийся градиент
Генератор многослойного неонового текста Красивый неоновый шрифт
Генератор надписей с glitch эффектом Добавить шрифту глитч эффект
Конструктор wizard надписи онлайн Добавить шрифту стикер эффект
Генератор красивых светящихся надписей Шрифт в стиле неонового короба
Создать надпись с объемным эффектом Добавить шрифту прикольный эффект
Конструктор красивых объемных шрифтов Шрифт в стиле объемного текста
Редактор текстов с 3д эффектом из разных шрифтов 3д текст с объемным эффектом
Конструктор крутых надписей с градиентом Шрифт с градиент 3д эффектом
3д шрифт с эффектом неонового контура Создать 3д текст неоновый контур
Конструктор красивых надписей в стиле cloud Красивый шрифт с эффектом cloud
Создать надпись с эффектом изогнутой дуги Добавить шрифту изогнутый эффект
Добавить к шрифту яркий сочный эффект Создать яркий текст juice эффект
Конструктор объемных неоновых HD надписей Добавить шрифту неоновый эффект
Конструктор текста в стиле алюминиевого корпуса Создать надпись в алюминиевом корпусе
Создать надпись с трещинами осколками Добавить шрифту эффект разрушения
Генератор фиктивного текста Lorem Ipsum
Что означает Lorem ipsum dolor?
Lorem ipsum dolor sit amet . Графические и типографические операторы хорошо это знают, на самом деле все профессии, имеющие дело со вселенной коммуникации, имеют устойчивую связь с этими словами, но что это такое? Lorem ipsum — это фиктивный текст без всякого смысла.
Графические и типографические операторы хорошо это знают, на самом деле все профессии, имеющие дело со вселенной коммуникации, имеют устойчивую связь с этими словами, но что это такое? Lorem ipsum — это фиктивный текст без всякого смысла.
Это последовательность латинских слов , которые в зависимости от расположения , не составляйте предложения с полным смыслом, но оживляйте тестовый текст, полезный для заполнения пробелов, которые впоследствии будут заняты специальными текстами, составленными профессионалами в области коммуникации.
Это, безусловно, самый известный текст-заполнитель , даже если есть разные версии, отличные от порядка, в котором повторяются латинские слова.
Lorem ipsum содержит гарнитуры , которые больше используются, аспект который позволяет получить обзор отображения текста с точки зрения выбора шрифта и d размер шрифта .
При ссылке на Lorem ipsum используются разные выражения, а именно заполнить текст , фиктивный текст , скрытый текст или текст-заполнитель : короче говоря, его значение также может быть нулевым, но его полезность настолько очевидна, что проходит сквозь века и сопротивляется ироническим и современным версиям, которые пришли с появлением Интернета ».
Самая используемая версия Lorem Ipsum?
« Lorem ipsum dolor sit amet, consectetur adipisci elit, sed eiusmod tempor incidunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrum exercitationem ullam corporis suscipit laboriosam, nisi ut aliquid ex ea commodi consequatur. Quis aute iure reprehenderit in voluptate velit esse cillum dolore eu fugiat nulla pariatur. Excepteur sint obcaecat cupiditat non proident, sunt in culpa qui officia deserunt mollit anim id est laborum. »
Генератор текста Lorem Ipsum безопасен для SEO!
С помощью нашего инструмента создания текста для заполнения , помимо настройки текста с помощью элементов HTML , у вас есть возможность создать новый, начиная непосредственно с вашего текста!
Таким образом вы избежите индексации веб-сайта с помощью ключевых слов , содержащихся в классическом Lorem Ipsum.
С помощью инструмента Lorem Ipzum , вы можете вставлять тексты непосредственно с ключевыми словами, которые будут использоваться для индексации вашего веб-сайта. Попробуйте!
Используйте онлайн-генератор текста,чтобы настроить тексты!
Почему вы используете?
Заполняющий текст Lorem ipum используется графическими дизайнерами, программистами и полиграфистами с целью занять пространство веб-сайта, рекламного продукта или редакционной продукции, окончательный текст которой еще не готов.
Этот прием позволяет получить представление о готовом продукте, который вскоре будет напечатан или распространен по цифровым каналам.
Чтобы получить результат, который больше соответствовал конечному результату, графические дизайнеры, дизайнеры или типографы сообщают о тексте Lorem ipsum по двум основным аспектам, а именно по удобочитаемости и редакционным требованиям.
Выбор шрифта и размера шрифта, с которым воспроизводится Lorem ipsum, отвечает конкретным потребностям, выходящим за рамки простых и простое заполнение пространств, предназначенных для приема реальных текстов и позволяющих получить в руки рекламный / издательский продукт, как веб, так и бумажный, в соответствии с реальностью.
Его бессмыслица позволяет глазу сосредоточиться только на графическом макете, объективно оцениваемом учитывая стилистический выбор проекта, поэтому он устанавливается во многие графические программы на многих программных платформах «персональных публикаций» и систем управления контентом ».
Каково происхождение Lorem Ipsum?
Вопреки тому, что можно было подумать, текст Lorem ipsum, несмотря на свою бессмысленность, имеет благородное происхождение.
Объективно составленный из не связанных между собой слов, Lorem ipsum своим существованием обязан Марко Туллио Цицероне и некоторые шаги его De finibus bonorum et malorum (Высшее добро и высшее зло), написанного в 45 г. до н.э. , классика латинской литературы, датируемого более чем 2000 лет назад.
Открытие было сделано Ричардом МакКлинтоком , профессором латыни в Хэмпден-Сиднейском колледже в Вирджинии, который столкнулся со стремительным повторением темного слова conctetur в тексте Lorem ipsum исследовал его происхождение, чтобы идентифицировать его в разделах 1. 10.32 и 1.10.33 вышеупомянутого философского труда Цицерона.
10.32 и 1.10.33 вышеупомянутого философского труда Цицерона.
Слова взяты из поэтому один из диалогов, содержащихся в De finibus , является частью самого известного бессмысленного текста в мире.
Открытие, которое придает большее значение Lorem ipsum, который остается на гребне волны с 500 г., когда, по словам профессора Ричарда МакКлинтока, его использование распространилось среди печатников того времени.
Конечно, мы знаем, что большинство людей узнало об этом благодаря рекламе шестидесятых годов, когда передаваемые листы символов Letraset: прозрачные клейкие листы, на которых был отпечатан текст Lorem ipsum, легко переносились на редакционные продукты. до появления компьютера.
«Sed ut perspiciatis unde omnis iste natus error sit voluptatem accusantium doloremque laudantium, totam rem aperiam eaque ipsa, quae ab illo inventore veritatis et quasi architecto beatae vitae dicta sunt, explicabo. Nemo enim ipsam voluptatem, quia voluptas sit, aspernatur aut odit aut fugit, sed quia consequuntur magni dolores eos, qui ratione voluptatem sequi nesciunt, neque porro quisquam est, qui dolorem ipsum, quia dolor sit, amet, consectetur, adipisci velit, sed quia non numquam eius modi tempora incidunt, ut labore et dolore magnam aliquam quaerat voluptatem. Ut enim ad minima veniam, quis nostrum exercitationem ullam corporis suscipit laboriosam, nisi ut aliquid ex ea commodi consequatur? Quis autem vel eum iure reprehenderit, qui in ea voluptate velit esse, quam nihil molestiae consequatur, vel illum, qui dolorem eum fugiat, quo voluptas nulla pariatur? [33] At vero eos et accusamus et iusto odio dignissimos ducimus, qui blanditiis praesentium voluptatum deleniti atque corrupti, quos dolores et quas molestias excepturi sint, obcaecati cupiditate non provident, similique sunt in culpa, qui officia deserunt mollitia animi, id est laborum et dolorum fuga. Et harum quidem rerum facilis est et expedita distinctio. Nam libero tempore, cum soluta nobis est eligendi optio, cumque nihil impedit, quo minus id, quod maxime placeat, facere possimus, omnis voluptas assumenda est, omnis dolor repellendus.
Ut enim ad minima veniam, quis nostrum exercitationem ullam corporis suscipit laboriosam, nisi ut aliquid ex ea commodi consequatur? Quis autem vel eum iure reprehenderit, qui in ea voluptate velit esse, quam nihil molestiae consequatur, vel illum, qui dolorem eum fugiat, quo voluptas nulla pariatur? [33] At vero eos et accusamus et iusto odio dignissimos ducimus, qui blanditiis praesentium voluptatum deleniti atque corrupti, quos dolores et quas molestias excepturi sint, obcaecati cupiditate non provident, similique sunt in culpa, qui officia deserunt mollitia animi, id est laborum et dolorum fuga. Et harum quidem rerum facilis est et expedita distinctio. Nam libero tempore, cum soluta nobis est eligendi optio, cumque nihil impedit, quo minus id, quod maxime placeat, facere possimus, omnis voluptas assumenda est, omnis dolor repellendus. Temporibus autem quibusdam et aut officiis debitis aut rerum necessitatibus saepe eveniet, ut et voluptates repudiandae sint et molestiae non recusandae. Itaque earum rerum hic tenetur a sapiente delectus, ut aut reiciendis voluptatibus maiores alias consequatur aut perferendis doloribus asperiores repellat.»
Temporibus autem quibusdam et aut officiis debitis aut rerum necessitatibus saepe eveniet, ut et voluptates repudiandae sint et molestiae non recusandae. Itaque earum rerum hic tenetur a sapiente delectus, ut aut reiciendis voluptatibus maiores alias consequatur aut perferendis doloribus asperiores repellat.»
«Но я должен объяснить вам, как родилась вся эта ошибочная идея отрицания удовольствия и восхваления боли, и я дам вам полный отчет о системе и излагаю фактические учения великого исследователя истины, Создатель человеческого счастья. Никто не отвергает, не любит и не избегает удовольствия как такового, потому что это удовольствие, а потому, что те, кто не знает, как стремиться к удовольствию, сталкиваются с чрезвычайно болезненными последствиями. преследует или желает получить боль сама по себе, потому что это боль, но иногда возникают обстоятельства, в которых тяжелый труд и боль могут доставить ему большое удовольствие. Возьмем тривиальный пример: кто из нас когда-либо предпринимает кропотливые физические упражнения, кроме как для получения некоторого преимущества Но кто имеет право придираться к мужчине, который предпочитает наслаждаться удовольствием, не имеющим неприятных последствий, или к тому, кто избегает боли, которая не приносит в результате удовольствия?
С другой стороны, мы осуждаем с праведным негодованием и неприязнью людей, которые настолько обмануты и деморализованы прелестями удовольствия момента, настолько ослеплены желанием, что они не могут предвидеть боль и неприятности, которые неизбежно последуют; и такая же вина принадлежит тем, кто не выполняет свой долг из-за слабости воли, что равносильно тому, чтобы сказать, уклонившись от тяжелого труда и боли. Эти случаи совершенно просты и легко различимы. В свободный час, когда наша свобода выбора ничем не ограничена и когда ничто не мешает нам делать то, что нам больше всего нравится, нужно приветствовать любое удовольствие и избегать любой боли. Но при определенных обстоятельствах и из-за требований долга или деловых обязательств часто будет случаться так, что от удовольствий придется отказываться от удовольствий и принимать неприятности. Поэтому мудрый человек в этих вопросах всегда придерживается этого принципа отбора: он отвергает удовольствия, чтобы получить другие большие удовольствия, или же он терпит боль, чтобы избежать худших страданий.»
Эти случаи совершенно просты и легко различимы. В свободный час, когда наша свобода выбора ничем не ограничена и когда ничто не мешает нам делать то, что нам больше всего нравится, нужно приветствовать любое удовольствие и избегать любой боли. Но при определенных обстоятельствах и из-за требований долга или деловых обязательств часто будет случаться так, что от удовольствий придется отказываться от удовольствий и принимать неприятности. Поэтому мудрый человек в этих вопросах всегда придерживается этого принципа отбора: он отвергает удовольствия, чтобы получить другие большие удовольствия, или же он терпит боль, чтобы избежать худших страданий.»
Какие другие версии поддельного текста lorem ipsum копировать?
Существует бесчисленное множество версий lorem ipsum, самого известного фальшивого текста в мире. Версии lorem ipsum различаются порядком повторения латинских слов или их вырезания.
Loren ipsun dolor sit anet, consectetur adipisci elit, sed eiusnod tenpor incidunt ut labore et dolore nagna aliqua. Ut enin ad ninin venian, quis nostrun exercitationen ullan corporis suscipit laboriosan, nisi ut aliquid ex ea connodi consequatur. Quis aute iure reprehenderit in voluptate velit esse cillun dolore eu fugiat nulla pariatur. Excepteur sint obcaecat cupiditat non proident, sunt in culpa qui officia deserunt nollit anin id est laborun.
Ut enin ad ninin venian, quis nostrun exercitationen ullan corporis suscipit laboriosan, nisi ut aliquid ex ea connodi consequatur. Quis aute iure reprehenderit in voluptate velit esse cillun dolore eu fugiat nulla pariatur. Excepteur sint obcaecat cupiditat non proident, sunt in culpa qui officia deserunt nollit anin id est laborun.
Lorean ipsun dolor sit aneat, conseacteatur adipisci ealit, sead eaiusnod teanpor incidunt ut laborea eat dolorea nagna aliqua. Ut eanin ad ninin veanian, quis nostrun eaxearcitationean ullan corporis suscipit laboriosan, nisi ut aliquid eax eaa connodi conseaquatur. Quis autea iurea reapreaheandearit in voluptatea vealit eassea cillun dolorea eau fugiat nulla pariatur. eaxceapteaur sint obcaeacat cupiditat non proideant, sunt in culpa qui officia deasearunt nollit anin id east laborun.
Lorem ips dolor sit amet, consectetur adipisci elit, sed eiusmod tempor incidunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostr exercitationem ullam corporis suscipit laboriosam, nisi ut aliquid ex ea commodi consequatur. Quis aute iure reprehenderit in voluptate velit esse cill dolore eu fugiat nulla pariatur. Excepteur sint obcaecat cupiditat non proident, sunt in culpa qui officia deserunt mollit anim id est labor.
Ut enim ad minim veniam, quis nostr exercitationem ullam corporis suscipit laboriosam, nisi ut aliquid ex ea commodi consequatur. Quis aute iure reprehenderit in voluptate velit esse cill dolore eu fugiat nulla pariatur. Excepteur sint obcaecat cupiditat non proident, sunt in culpa qui officia deserunt mollit anim id est labor.
Lorem pisum dolor sit amet, consectetur adpisci elit, sed eiusmod tempor incidunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrum exercitationem ullam corporis suscpit laboriosam, nisi ut aliquid ex ea commodi consequatur. Quis aute iure reprehenderit in voluptate velit esse cillum dolore eu fugiat nulla pariatur. Excepteur sint obcaecat cupiditat non proident, sunt in culpa qui officia deserunt mollit anim id est laborum.
Lorem ipsum dolor sit amet, consectetur adipisci elit, sed diam nonummy nibh euismod tincidunt ut laoreet dolore. Ut enim ad minim veniam, quis nostrum exercitationem ullam corporis suscipit laboriosam, nisi ut aliquid ex ea commodi consequatur. Quis aute iure reprehenderit in voluptate velit esse cillum dolore eu fugiat nulla pariatur. Excepteur sint obcaecat cupiditat non proident, sunt in culpa qui officia deserunt mollit anim id est laborum.
Quis aute iure reprehenderit in voluptate velit esse cillum dolore eu fugiat nulla pariatur. Excepteur sint obcaecat cupiditat non proident, sunt in culpa qui officia deserunt mollit anim id est laborum.
Аналитика зашумленных неструктурированных текстовых данных I (искусственный интеллект)
ВВЕДЕНИЕ
К сожалению, вычислительные системы еще не настолько умны, как человеческий разум. За последние пару лет значительное число исследователей сосредоточилось на анализе зашумленного текста. Зашумленные текстовые данные встречаются в неформальной обстановке (онлайн-чаты, SMS, электронная почта, доски объявлений и т. д.) и в текстах, созданных с помощью автоматизированных систем распознавания речи или оптических систем распознавания символов. Шум может снизить производительность других алгоритмов обработки информации, таких как классификация, кластеризация, суммирование и извлечение информации. Мы определим некоторые из ключевых областей исследования зашумленного текста и дадим краткий обзор современного состояния дел. Этими областями будут: (i) классификация зашумленного текста, (ii) исправление зашумленного текста, (iii) извлечение информации из зашумленного текста. Мы рассмотрим первый из них в этой главе, а два последних — в следующей.
Этими областями будут: (i) классификация зашумленного текста, (ii) исправление зашумленного текста, (iii) извлечение информации из зашумленного текста. Мы рассмотрим первый из них в этой главе, а два последних — в следующей.
Мы определяем шум в тексте как любое отличие внешней формы электронного текста от предполагаемого, правильного или исходного текста. Мы видим такой шумный текст каждый день в различных формах. Каждый из них имеет уникальные характеристики и, следовательно, требует особого обращения. В этом разделе мы вводим некоторые такие формы зашумленных текстовых данных.
Зашумленные онлайн-документы: Электронная почта, журналы чатов, записи в записках, сообщения групп новостей, обсуждения на дискуссионных форумах, блоги и т. д. попадают в эту категорию. Люди, как правило, меньше заботятся о здравомыслии письменного содержания в таких неформальных формах общения. Для них характерны частые орфографические ошибки, употребительные и не очень часто используемые аббревиатуры, неполные предложения, пропущенные знаки препинания и так далее. Почти всегда шумные документы понятны человеку, если не всем, то, по крайней мере, предполагаемым читателям.
Почти всегда шумные документы понятны человеку, если не всем, то, по крайней мере, предполагаемым читателям.
SMS: Услуги коротких сообщений становятся все более и более распространенными. Использование языка в тексте SMS значительно отличается от стандартной формы языка. Стремление к сокращению длины сообщения, что способствует более быстрому набору текста, и потребность в семантической ясности формируют структуру этой нестандартной формы, известной как текстовый язык (Чоудхури и др., 2007).
Текст, созданный устройствами ASR: ASR — это процесс преобразования речевого сигнала в последовательность слов. Система ASR принимает речевой сигнал, такой как монологи, дискуссии между людьми, телефонные разговоры и т. д., в качестве входных данных и создает строку слов, обычно не разделенных пунктуацией, в качестве расшифровок. Система ASR состоит из акустической модели, языковой модели и алгоритма декодирования. Акустическая модель обучается на речевых данных и соответствующих им ручных расшифровках. Языковая модель обучается на большом одноязычном корпусе. ASR преобразует аудио в текст путем поиска акустической модели и пространства языковой модели с использованием алгоритма декодирования. Сегодня большинство разговоров в контакт-центрах между агентами и клиентами записываются. Чтобы выполнить какую-либо обработку этих данных для получения информации о клиентах, необходимо преобразовать аудио в текст.
Языковая модель обучается на большом одноязычном корпусе. ASR преобразует аудио в текст путем поиска акустической модели и пространства языковой модели с использованием алгоритма декодирования. Сегодня большинство разговоров в контакт-центрах между агентами и клиентами записываются. Чтобы выполнить какую-либо обработку этих данных для получения информации о клиентах, необходимо преобразовать аудио в текст.
Текст, сгенерированный устройствами оптического распознавания символов: оптическое распознавание символов, или OCR, — это технология, позволяющая преобразовывать цифровые изображения печатного или рукописного текста в редактируемый текстовый документ. Он делает снимок текста и переводит текст в Unicode или ASCII. . Для оптического распознавания рукописных символов скорость распознавания составляет от 80% до 90% при чистом почерке.
Журналы вызовов в контакт-центрах: Современные контакт-центры (также известные как колл-центры, BPO, KPO) производят огромное количество неструктурированных данных в виде журналов вызовов, помимо электронных писем, расшифровок вызовов, SMS, расшифровок чатов и т. д. Агенты ожидается, что они подведут итог взаимодействия, как только они закончат его, и прежде чем приступить к следующему. Поскольку агенты работают в условиях огромного дефицита времени, сводные журналы написаны очень плохо и иногда даже трудно интерпретируются человеком. Анализ таких журналов вызовов важен для выявления проблемных областей, производительности агента, возникающих проблем и т. д.
д. Агенты ожидается, что они подведут итог взаимодействия, как только они закончат его, и прежде чем приступить к следующему. Поскольку агенты работают в условиях огромного дефицита времени, сводные журналы написаны очень плохо и иногда даже трудно интерпретируются человеком. Анализ таких журналов вызовов важен для выявления проблемных областей, производительности агента, возникающих проблем и т. д.
В этой главе мы сосредоточимся на автоматической классификации зашумленного текста. Автоматическая классификация текста относится к разделению документов по разным темам в зависимости от содержания. Например, категоризация электронных писем клиентов в соответствии с такими темами, как проблемы с выставлением счетов, изменение адреса, запрос продукта и т. д. Он имеет важные приложения в области категоризации электронной почты, создания и обслуживания веб-каталогов, например. DMoz, спам-фильтр, автоматическая маршрутизация звонков и электронной почты в контакт-центре, фильтр порнографических материалов и так далее.
КАТЕГОРИЗАЦИЯ ЗАШУМНОГО ТЕКСТА
Задача классификации текста является одной из моделей обучения для данного набора классов и применения этих моделей к новым невидимым документам для назначения класса. Это важный компонент во многих задачах извлечения знаний; сортировка электронной почты или файлов в режиме реального времени по иерархии папок, идентификация тем для поддержки операций обработки по конкретным темам, структурированный поиск и/или просмотр или поиск документов, соответствующих долгосрочным интересам или более динамичным интересам, основанным на задачах. Обычно обычно встречаются два типа классификаторов, а именно. статистические классификаторы и классификаторы на основе правил.
В статистических методах модель обычно обучается на корпусе размеченных данных, и после обучения система может использоваться для автоматического присвоения невидимых данных. Обзор классификации текстов можно найти в работе Ааса и Эйквиля (Aas & Eikvil, 1999). Учитывая набор обучающих документов D = {d1, d2,….., dM} с истинными классами {y1, y2, ….., yM}, задача состоит в том, чтобы изучить модель.
Учитывая набор обучающих документов D = {d1, d2,….., dM} с истинными классами {y1, y2, ….., yM}, задача состоит в том, чтобы изучить модель.
Эта модель используется для категоризации нового немаркированного документа du. Обычно слова, встречающиеся в тексте, используются в качестве признаков. Другие приложения, включая поиск, в значительной степени зависят от разметки или структуры ссылок документов, но классификаторы зависят только от содержания документов или набора слов, присутствующих в документах. После извлечения признаков из документов каждый документ преобразуется в вектор документа. Документы представлены в векторном пространстве; каждое измерение этого пространства представляет собой один объект, и важность этого объекта в этом документе дает точное расстояние от начала координат. В простейшем представлении векторов документов используется модель бинарных событий, где, если признак j e K появляется в документе di, то j-й компонент di равен 1, в противном случае он равен 0. Один из самых популярных методов статистической классификации — наивный байесовский метод (McCallum, 19).98). В наивном байесовском методе вероятность того, что документ di принадлежит классу c, вычисляется как: признаки считаются условно независимыми, учитывая переменную класса.
Один из самых популярных методов статистической классификации — наивный байесовский метод (McCallum, 19).98). В наивном байесовском методе вероятность того, что документ di принадлежит классу c, вычисляется как: признаки считаются условно независимыми, учитывая переменную класса.
Системы обучения на основе правил были приняты для решения проблемы классификации документов, поскольку она имеет значительную привлекательность. Они хорошо справляются с поиском простых границ, параллельных осям. Типичная схема классификации на основе правил для категории, скажем, C, имеет вид:
Присвоить категорию C ifantecedent или Не назначать категорию C ifantecedent или
Предшественник в посылке правила обычно включает некоторое сравнение значений признаков . Говорят, что правило охватывает документ, или говорят, что документ удовлетворяет правилу, если все сравнения значений признаков в антецеденте правила верны для документа. Одной из хорошо известных работ в области классификации текстов на основе правил является RIPPER. Подобно стандартному алгоритму «разделяй и властвуй», он создает набор правил постепенно. Когда правило найдено, все документы, на которые распространяется правило, отбрасываются, включая положительные и отрицательные документы. Затем правило добавляется в набор правил. Оставшиеся документы используются для построения других правил в следующей итерации.
Подобно стандартному алгоритму «разделяй и властвуй», он создает набор правил постепенно. Когда правило найдено, все документы, на которые распространяется правило, отбрасываются, включая положительные и отрицательные документы. Затем правило добавляется в набор правил. Оставшиеся документы используются для построения других правил в следующей итерации.
Как в статистических, так и в основанных на правилах методах классификации текста содержание текста является единственным определяющим фактором присваиваемой категории. Однако шум в тексте искажает содержание, и, следовательно, читатели могут ожидать, что шум в тексте повлияет на эффективность категоризации. Классификаторы в основном обучены определять корреляцию между извлеченными функциями (словами) с различными категориями, которые впоследствии можно использовать для классификации новых документов. Например, такие слова, как интересное предложение, получите бесплатный ноутбук, могут иметь более сильную корреляцию с электронными письмами со спамом категории, чем с электронными письмами, не являющимися спамом. Шум в тексте искажает это пространство функций. Захватывающее предложение получить бесплатный ноутбук будет новым набором функций, и классификатор не сможет связать его с категорией спам-писем. Пространство функций расширяется, поскольку одна и та же функция может появляться в разных формах из-за орфографических ошибок, плохого распознавания, неправильной транскрипции и т. д. В оставшейся части этого раздела мы дадим обзор того, как люди подошли к проблеме категоризации зашумленного текста.
Шум в тексте искажает это пространство функций. Захватывающее предложение получить бесплатный ноутбук будет новым набором функций, и классификатор не сможет связать его с категорией спам-писем. Пространство функций расширяется, поскольку одна и та же функция может появляться в разных формах из-за орфографических ошибок, плохого распознавания, неправильной транскрипции и т. д. В оставшейся части этого раздела мы дадим обзор того, как люди подошли к проблеме категоризации зашумленного текста.
Категоризация документов с OCR
Электронно распознанные рукописные документы и документы, сгенерированные с помощью процесса OCR , являются типичными примерами зашумленного текста из-за ошибок, внесенных в процессе распознавания. Винчиарелли (Vinciarelli, 2004) изучил характеристики шума, присутствующего в таких данных, и его влияние на точность категоризации. Было взято подмножество документов из набора данных классификации текстов Reuters-21578, и шум был введен двумя способами: сначала подмножество документов было написано вручную и распознано с помощью автономной системы распознавания рукописного ввода. Во втором процесс извлечения на основе OCR моделировался путем случайного изменения определенного процента символов. По их словам, для значений полноты до 60-70 процентов в зависимости от источников система категоризации устойчива к шуму, даже когда коэффициент ошибок терминов превышает 40 процентов. Также было замечено, что результаты рукописных данных оказались ниже результатов, полученных при моделировании OCR. Были предложены общие системы категоризации текстов, основанные на статистическом анализе репрезентативных корпусов текстов (Bayer et. al., 19).98). Особенности извлекаются из обучающих текстов путем выбора подстрок из реальных словоформ и применения статистической информации и общих лингвистических знаний с последующим уменьшением размерности путем линейного преобразования. Фактическая система категоризации основана на минимальном подходе наименьших квадратов. Система оценивается по задачам категоризации рефератов бумажных немецких технических отчетов и деловых писем, касающихся жалоб.
Во втором процесс извлечения на основе OCR моделировался путем случайного изменения определенного процента символов. По их словам, для значений полноты до 60-70 процентов в зависимости от источников система категоризации устойчива к шуму, даже когда коэффициент ошибок терминов превышает 40 процентов. Также было замечено, что результаты рукописных данных оказались ниже результатов, полученных при моделировании OCR. Были предложены общие системы категоризации текстов, основанные на статистическом анализе репрезентативных корпусов текстов (Bayer et. al., 19).98). Особенности извлекаются из обучающих текстов путем выбора подстрок из реальных словоформ и применения статистической информации и общих лингвистических знаний с последующим уменьшением размерности путем линейного преобразования. Фактическая система категоризации основана на минимальном подходе наименьших квадратов. Система оценивается по задачам категоризации рефератов бумажных немецких технических отчетов и деловых писем, касающихся жалоб. Достигается точность классификации примерно 80%, и видно, что система очень устойчива к ошибкам распознавания или ввода.
Достигается точность классификации примерно 80%, и видно, что система очень устойчива к ошибкам распознавания или ввода.
Вопросы категоризации документов, подвергнутых распознаванию текста, также обсуждаются многими другими авторами (Brooks & Teahan, 2007), (Hoch, 1994) и (Taghva et. al., 2001).
Категоризация документов ASRed
Автоматическое распознавание речи (ASR) — это просто процесс преобразования акустического сигнала в последовательность слов. Исследователи предложили различные методы для задач распознавания речи, основанные на скрытой марковской модели (HMM), нейронных сетях, динамической деформации времени (DTW) (Trentin & Gori, 2001). Производительность системы ASR обычно измеряется с точки зрения частоты ошибок в словах (WER), которая выводится из расстояния Левенштейна и работает на уровне слов, а не символов. WER можно рассчитать как
где S — количество замен, D — количество удалений, I — количество вставок и N — количество слов в ссылке. Бахл и др. (Bahl et. al. 1995) построили систему ASR и продемонстрировали ее возможности на эталонных наборах данных.
Бахл и др. (Bahl et. al. 1995) построили систему ASR и продемонстрировали ее возможности на эталонных наборах данных.
Системы ASR приводят к замене слов, удалениям и вставкам, в то время как системы OCR производят в основном замены слов. Более того, системы ASR ограничены лексиконом и могут выдавать на выходе только принадлежащие ему слова, тогда как системы OCR могут работать без лексикона (это соответствует возможности расшифровки любой строки символов) и могут выводить последовательности символов, не обязательно соответствующие фактические слова. Ожидается, что такие различия окажут сильное влияние на производительность систем, предназначенных для категоризации документов с ASR, по сравнению с категоризацией документов с OCR. Много работы по автоматической классификации типов вызовов с целью классификации вызовов (Tang et al., 2003), маршрутизации вызовов (Kuo and Lee, 2003; Haffner et al., 2003), получения сводок журнала вызовов (Douglas et al. , 2005), помощь агентов и мониторинг (Mishne et al. , 2005) появились в прошлом. Здесь крики классифицируются на основе транскрипции из системы ASR. Одна интересная работа по изучению влияния шума ASR на классификацию текста была проведена на подмножестве эталонного набора данных классификации текстов Re-uters-2 1 5 782 (Agarwal et. al., 2007). Они прочитали и автоматически расшифровали 200 документов и применили текстовый классификатор, обученный на чистом учебном корпусе Reuters-215783. Удивительно, но, несмотря на высокий уровень шума, они не наблюдали большого ухудшения точности.
, 2005) появились в прошлом. Здесь крики классифицируются на основе транскрипции из системы ASR. Одна интересная работа по изучению влияния шума ASR на классификацию текста была проведена на подмножестве эталонного набора данных классификации текстов Re-uters-2 1 5 782 (Agarwal et. al., 2007). Они прочитали и автоматически расшифровали 200 документов и применили текстовый классификатор, обученный на чистом учебном корпусе Reuters-215783. Удивительно, но, несмотря на высокий уровень шума, они не наблюдали большого ухудшения точности.
Влияние орфографических ошибок на категоризацию
Орфографические ошибки являются неотъемлемой частью письменного текста — как электронного, так и неэлектронного. Каждый читатель, читающий эту тему, должно быть, был отруган своим учителем в школе за неправильное написание слов! В эпоху электронного текста люди стали менее осторожны при написании в результате плохо написанного текста, содержащего аббревиатуры, короткие формы, акронимы, неправильное написание. Такие электронные текстовые документы, включая электронную почту, журнал чатов, сообщения, SMS, иногда трудно интерпретировать даже людям. Само собой разумеется, что текстовая аналитика на таких зашумленных данных — нетривиальная задача.
Такие электронные текстовые документы, включая электронную почту, журнал чатов, сообщения, SMS, иногда трудно интерпретировать даже людям. Само собой разумеется, что текстовая аналитика на таких зашумленных данных — нетривиальная задача.
Неправильное написание может по-разному повлиять на эффективность автоматической классификации в зависимости от характера используемого метода классификации. В случае статистических методов различия в правописании искажают пространство признаков. Если обучение, а также корпус тестовых данных зашумлены, при обучении модели классификатор будет рассматривать варианты одних и тех же слов как разные признаки. В результате наблюдаемое совместное распределение вероятностей будет отличаться от фактического распределения. Если доля неправильно написанных слов высока, то искажение может быть значительным и повредит точности результирующего классификатора. Однако, если классификатор обучен на чистом корпусе, а тестовые документы зашумлены, то неправильно написанные слова будут рассматриваться как невидимые слова и не помогут в классификации. В маловероятной ситуации неправильно написанное слово, присутствующее в тестовом документе, может стать другим допустимым признаком и, что еще хуже, может стать допустимым ориентировочным признаком другого класса. Стандартным методом в процессе классификации текста является выбор признаков, который происходит после извлечения признаков и перед обучением. Выбор признаков обычно использует некоторые статистические измерения по обучающему корпусу и ранжирует признаки в порядке количества информации (корреляции), которую они имеют по отношению к меткам классов рассматриваемой задачи классификации. После ранжирования набора функций несколько лучших функций сохраняются (обычно порядка сотен или нескольких тысяч), а остальные отбрасываются. Выбор признаков должен быть в состоянии устранить неправильно написанные слова, присутствующие в обучающих данных, при условии, что (i) доля неправильно написанных слов не очень велика и (ii) нет регулярной закономерности в орфографических ошибках4. Однако было замечено, что даже при высокой степени орфографических ошибок точность классификации не сильно страдает (Agarwal et al.
В маловероятной ситуации неправильно написанное слово, присутствующее в тестовом документе, может стать другим допустимым признаком и, что еще хуже, может стать допустимым ориентировочным признаком другого класса. Стандартным методом в процессе классификации текста является выбор признаков, который происходит после извлечения признаков и перед обучением. Выбор признаков обычно использует некоторые статистические измерения по обучающему корпусу и ранжирует признаки в порядке количества информации (корреляции), которую они имеют по отношению к меткам классов рассматриваемой задачи классификации. После ранжирования набора функций несколько лучших функций сохраняются (обычно порядка сотен или нескольких тысяч), а остальные отбрасываются. Выбор признаков должен быть в состоянии устранить неправильно написанные слова, присутствующие в обучающих данных, при условии, что (i) доля неправильно написанных слов не очень велика и (ii) нет регулярной закономерности в орфографических ошибках4. Однако было замечено, что даже при высокой степени орфографических ошибок точность классификации не сильно страдает (Agarwal et al. , 2007).
, 2007).
Методы классификации, основанные на правилах, также страдают от орфографических ошибок. Если обучающие данные содержат орфографические ошибки, то некоторые правила могут не получить требуемой статистической значимости. Из-за орфографических ошибок, присутствующих в тестовых данных, действительное правило может не сработать, и, что еще хуже, может сработать недопустимое правило, что приведет к неправильной категоризации. Предположим, что RIPPER изучил набор правил, например:
Назначить категорию «спорт» ЕСЛИ (документ содержит {\it спорт}) ИЛИ (документ содержит {\it упражнения} И {\it на открытом воздухе}) ИЛИ
(документ содержит {\it упражнение}, но не {\it домашнее задание} {\it экзамен}) ИЛИ
(документ содержит {\it play} И {\it правило}) ИЛИ
Гипотетический тестовый документ, содержащий повторяющиеся случаи упражнений, но каждый раз неправильно написанный как exarcise, не будет отнесен к спортивной категории и, следовательно, приведет к неправильной классификации.
ЗАКЛЮЧЕНИЕ
В этой главе мы рассмотрели анализ зашумленного текста. Эта тема приобретает все большее значение, поскольку все больше и больше зашумленных данных генерируются и нуждаются в обработке. В частности, мы рассмотрели методы исправления зашумленного текста и выполнения классификации. Мы представили обзор существующих методов в этой области и показали, что, хотя это трудная проблема, ее можно решить с помощью сочетания новых и существующих методов.
КЛЮЧЕВЫЕ ТЕРМИНЫ
Автоматическое распознавание речи: Машинное распознавание и преобразование произносимых слов в текст.
Интеллектуальный анализ данных: Применение аналитических методов и инструментов к данным с целью выявления закономерностей, взаимосвязей или получения систем, выполняющих полезные задачи, такие как классификация, предсказание, оценка или группировка по сходству.
Извлечение информации: Автоматическое извлечение структурированных знаний из неструктурированных документов.
Зашумленный текст: Текст с любыми отличиями формы поверхности от задуманного, правильного или исходного текста.
Оптическое распознавание символов: Преобразование изображений рукописного или машинописного текста (обычно снятого сканером) в редактируемый компьютером текст.
Индукция правила: Процесс изучения на основе случаев или примеров отношений правила «если-то», состоящих из антецедента (если-часть, определяющая предварительные условия или покрытие правила) и следствия (тог-часть, устанавливающая классификация, предсказание или другое выражение свойства, которое имеет место для случаев, определенных в антецеденте).
TextAnalytics: Процесс извлечения полезных и структурированных знаний из неструктурированных документов для поиска полезных ассоциаций и идей.
Классификация текста (или категоризация текста): Задача изучения моделей для заданного набора классов и применения этих моделей к новым невидимым документам для назначения класса.
Нормализация зашумленных текстовых данных Научно-исследовательская работа по теме «Компьютерные и информационные науки»
Доступно на сайте www.sciencedirect.com
ScienceDirect ProC6d ¡0
Информатика
Procedia Computer Science 45 (2015) 127 — 132
Международная конференция по передовым вычислительным технологиям и приложениям (ICACTA-
Нормализация зашумленных текстовых данных, Procedia Meera
7 Narvekarb
a Инженерный колледж им. Д.Дж. Сангхви, Мумбаи 400056 и почтовый индекс, Индия b Инженерный колледж им.0007
Влияние социальных сетей и SMS на нашу повседневную жизнь возрастает. Эти источники предоставляют аналитикам большой объем текстовых данных для интеллектуального анализа данных и поиска закономерностей. Тем не менее, эти данные, как известно, зашумлены, поскольку люди используют много сокращений, что снижает их полезность для анализа. Следовательно, важно преобразовать этот зашумленный текст в стандартный английский язык. В этой статье мы нацелены на слова, не входящие в словарь (NIV), присутствующие в этих источниках, и предлагаем метод для идентификации и нормализации этих слов NIV. Соблюдаемые базы данных и контекст используются для замены неправильно сформированных слов и выбора наилучшего возможного исправления для этого слова. Этот метод также может заменить интернет-сленг на чистый английский и в некоторой степени исправить допущенные орфографические ошибки.
В этой статье мы нацелены на слова, не входящие в словарь (NIV), присутствующие в этих источниках, и предлагаем метод для идентификации и нормализации этих слов NIV. Соблюдаемые базы данных и контекст используются для замены неправильно сформированных слов и выбора наилучшего возможного исправления для этого слова. Этот метод также может заменить интернет-сленг на чистый английский и в некоторой степени исправить допущенные орфографические ошибки.
© 2015 Опубликовано Elsevier B.V. Это статья в открытом доступе по лицензии CC BY-NC-ND (http://creativecommons.Org/licenses/by-nc-nd/4.0/).
Рецензирование под ответственность научного комитета Международной конференции по передовым вычислительным технологиям и приложениям (ICACTA-2015).
Ключевые слова: слова, не входящие в словарь; неправильные слова; levenshtein Distance
CrossMark
1. Введение
Веб-сайты социальных сетей, блоги, SMS, чаты являются привлекательным источником данных для интеллектуального анализа данных, поскольку они предлагают большое количество данных в режиме реального времени. Но качество данных обычно не подходит для анализа, так как они содержат много сленга, специальных сокращений, фонетических замен, неструктурированной грамматики и т. д. Например, ввод i reli lyk ur new fone (мне очень нравится ваш новый телефон ) нельзя использовать для анализа, так как он не на стандартном английском языке и может привести к ограничениям для различных инструментов анализа. Это также затрудняет их обработку инструментами обработки текста. В этой статье мы стремимся нормализовать эти зашумленные данные в свободные от шума данные на английском языке.
Но качество данных обычно не подходит для анализа, так как они содержат много сленга, специальных сокращений, фонетических замен, неструктурированной грамматики и т. д. Например, ввод i reli lyk ur new fone (мне очень нравится ваш новый телефон ) нельзя использовать для анализа, так как он не на стандартном английском языке и может привести к ограничениям для различных инструментов анализа. Это также затрудняет их обработку инструментами обработки текста. В этой статье мы стремимся нормализовать эти зашумленные данные в свободные от шума данные на английском языке.
* Нилмей Десаи. Тел.: +91-96-99812291. Адрес электронной почты: [email protected]
1877-0509 © 2015 Опубликовано Elsevier B.V. Это статья в открытом доступе по лицензии CC BY-NC-ND (http://creativecommons.Org/licenses). /by-nc-nd/4.0/).
Рецензирование под ответственностью научного комитета Международной конференции по передовым вычислительным технологиям и приложениям
(ICACTA-2015).![]()
doi:10.1016/j.procs.2015.03.104
Шум возникает непреднамеренно из-за человеческих ошибок (орфографических ошибок) и т. д. Такой шум можно уменьшить с помощью различных доступных средств проверки орфографии и грамматики, таких как средство проверки орфографии и грамматики MS Слово. Шум также может быть введен намеренно с использованием сокращений и сленга, поскольку максимальное количество символов в SMS или твите составляет 160 символов. Например, в (How r u) слова «r» и «u» введены намеренно, чтобы уменьшить количество символов в предложении в целом. Таким образом, исправление выходит за рамки проверки орфографии, и наша цель будет состоять в том, чтобы заменить все неправильно сформированные слова на стандартный английский язык.
Согласно нашему анализу, простого поиска в словаре недостаточно для всех случаев1. В остальных случаях важна систематическая обработка и пошаговая коррекция.
2. Связанная работа
Некоторые исследователи использовали метод распознавания речи для нормализации текста. Например, Кобус и др. (2008)2 сначала преобразовали введенные текстовые токены в фонетические, а затем вернули их обратно в слова путем поиска в фонетическом словаре. Бофорт и др. (2010)3 использовали методы с конечным числом состояний для выполнения французской нормализации SMS, сочетая преимущества SMT и модели зашумленного канала. Кауфманн (2010)4 использует подход машинного перевода с препроцессором для синтаксической (а не лексической) нормализации. Брилл и Мур (2000) 5 характеризуют модель ошибок, вычисляя произведение вероятностей срабатывания на послойное редактирование строки.
Например, Кобус и др. (2008)2 сначала преобразовали введенные текстовые токены в фонетические, а затем вернули их обратно в слова путем поиска в фонетическом словаре. Бофорт и др. (2010)3 использовали методы с конечным числом состояний для выполнения французской нормализации SMS, сочетая преимущества SMT и модели зашумленного канала. Кауфманн (2010)4 использует подход машинного перевода с препроцессором для синтаксической (а не лексической) нормализации. Брилл и Мур (2000) 5 характеризуют модель ошибок, вычисляя произведение вероятностей срабатывания на послойное редактирование строки.
Доступны онлайн-инструменты, такие как transl8it.com6, lingo2text.com7 и т. д. Нам нужно добавить текстовые данные для обработки. Затем он выдаст результат на стандартном английском языке. Однако иногда результаты не зависят от контекста. Кроме того, ненужные слова часто нормализуются и дают нежелательные результаты.
Наша модель предотвращает все подобные проблемы. Мы не используем машинный перевод, так как это занимает больше времени и утомительнее8. Наша модель не требует фонетического перевода, занимающего слишком много памяти. Предлагаемый нами метод описан ниже.
Наша модель не требует фонетического перевода, занимающего слишком много памяти. Предлагаемый нами метод описан ниже.
3. Предлагаемый нами метод
Необходимо, чтобы инструменты нормализации текста давали точные результаты. Только тогда анализирующие инструменты смогут анализировать текст. Предлагаемый метод преодолеет ограничения более ранних моделей и даст точные результаты. Целевые данные, подлежащие обработке, подразделяются на различные типы. Типы, которые нуждаются в обработке, приведены ниже.
3.1. Типы данных
«Письмо» относится к типу, в котором слова намеренно или непреднамеренно расположены не на своем месте. Этот тип является наиболее распространенным типом шума, встречающимся в Твиттере и SMS. Например, использование «shud» вместо «should»
«Замена чисел» относится к типу, в котором числа заменяются фонетически подобными словами. Например, использование «2» вместо «кому»
«Сленг» относится к типу, в котором пользователи используют интернет-сленг или сокращения. Например, использование «кстати» вместо «кстати». Эти сленги обычно используются для уменьшения количества символов.
Например, использование «кстати» вместо «кстати». Эти сленги обычно используются для уменьшения количества символов.
«Буква и цифра» относится к типу, в котором пользователи используют как цифры, так и буквы для замены фонетически похожего слова. Например, использование «2moro» вместо «завтра»
Подробное распределение типов приведено в Таблице 1. Из таблицы видно, что «Письмо» содержит максимальную долю слов NIV, что формирует нашу стратегию нормализации.
Таблица 1: Тип и распределение 8
Акция распределения типа
Буква 72,44%
Замена числа 2,76%
Slang 12,2%
Letter & Number 2,36%
10,24%
. Определите не-в-в-в-в-ресурсы (NV ) слов
Обработка NIV слов
— Алгоритм сокращения слов
— Замена общих слов
— Лексическое сопоставление
Рис. 1. Наш подход
В предлагаемом методе мы ориентируемся на слова NIV из зашумленных текстовых данных, которые являются нашими входными данными. Данные должны обрабатываться по-разному в зависимости от их типа.
Данные должны обрабатываться по-разному в зависимости от их типа.
Предлагаемый метод нормализации включает четыре основных этапа: (1) определение слов NIV; (2) обработка слов NIV; (3) Поиск наиболее подходящей замены: (4) Применение исправления и перефразирования предложения. Этапы предлагаемого метода показаны на рисунке 1.9.0007
3.2. Определите слова, не входящие в словарь (NIV)
Слова NIV — это слова, которых нет в словаре английского языка. Необходимо отделить слова NIV для обработки от заданных входных данных. Мы используем PyEnchant Library9 для Python, которая использует стандартный словарь en_US для отделения слов NIV от слов IV (In Vocabulary). Специальные функции, такие как упоминания (@name), хэш-теги (#футбол) и т. д. в твиттере не учитываются при обработке.
3.3. Обработка слов NIV
Во-первых, любое слово, которое удлиняется из-за ненужного повторения букв, укорачивается. Любой алфавит, повторяющийся более трех раз, сокращается до двух повторений. Например, «хорошо» становится «хорошо». Такие удлиненные слова, используемые для более четкого выражения эмоций, часто приводят к нейтральным результатам сентиментального анализа. Во-вторых, обнаруженные слова NIV ищутся в базе данных слов (более 5000 слов NIV) и заменяются
Например, «хорошо» становится «хорошо». Такие удлиненные слова, используемые для более четкого выражения эмоций, часто приводят к нейтральным результатам сентиментального анализа. Во-вторых, обнаруженные слова NIV ищутся в базе данных слов (более 5000 слов NIV) и заменяются
соответствующими правильными словами. Поиск сленга осуществляется путем сравнения с интернет-сленгом, полученным с «noslang.com»10.
В-третьих, чтобы найти орфографические ошибки или непреднамеренный шум, мы используем лексическое сопоставление. Расстояние Левенштейна11 между любыми двумя строками определяется как минимальное количество правок, которое мы можем сделать, чтобы преобразовать одну строку в другую. Все операции редактирования, которые можно выполнить, это вставка, удаление и обновление. Например, расстояние Левенштейна между «kittan» и «kitten» равно 1. (Замена «e» на «a»). Найдено минимальное расстояние Левенштейна для конкретного слова, и слово NIV заменяется соответствующим словом.
3.![]() 4. Поиск наиболее вероятной коррекции
4. Поиск наиболее вероятной коррекции
После обработки выбирается наиболее вероятное решение для конкретной НИВ. Например, если доступна замена слова из базы данных, она становится наиболее вероятным решением для данной NIV.
3.5. Применение исправления и перефразирование предложения
Затем правильное решение заменяется в предложении. Замененное предложение находится на стандартном английском языке после обработки.
4. Сложность реализации и времени
Для хранения входных данных, обработки и хранения выходных данных используется база данных SQL. Программирование базы данных и связывание будут выполняться с использованием платформы MySQL. Для внешнего интерфейса модели программирование проектирования будет выполнено в среде VB.NET (Visual Basic).
Временная сложность алгоритма поиска слов NIV из набора данных составляет O(log2N), где N — количество словарных слов в библиотеке PyEnchant9.
Алгоритм сокращения слов — O (m), где «m» — номер алфавита в конкретном NIV. Если есть «n» слов NIV, общая временная сложность становится O (n.m).
Если есть «n» слов NIV, общая временная сложность становится O (n.m).
Сопоставление и замена слов осуществляется с помощью хэш-карт. Временная сложность при использовании хэш-карт составляет O (1). Таким образом, временная сложность системы, использующей вышеупомянутые алгоритмы, определяется следующим образом: Временная сложность = O (log2N + nm + 1), где
N = количество слов в библиотеке PyEnchant. n = количество слов NIV. m = количество алфавитов в слове NIV.
5. Сравнение с другими моделями
Мы сравниваем нашу модель с традиционным переводчиком текстовых сообщений — Transl8it6. Он доступен на сайте transl8it.com. Переведи! (trans-late-it) — это простой онлайн-инструмент, который преобразует разговоры в чатах и интернет-сленг в стандартный английский язык. Текст необходимо ввести, чтобы он был преобразован, и Transl8it выдаст результат на стандартном английском языке.
Мы столкнулись с несколькими случаями, когда перевод, заданный командой transl8it, не нужен (например, ’12’ в дюжину). В нашей модели не делается ненужных переходов конкретного слова и выдаются соответствующие результаты.
В нашей модели не делается ненужных переходов конкретного слова и выдаются соответствующие результаты.
Например, шумный текст:
1)»Нет лека? Я свободен с 12:00″
Transl8it — Know lec? Я свободен от дюжины утра.
Lingo2Text — Нет лека? Я свободен от десятка утраты.
Наша модель — Без лекций? Я свободен с 12 часов.
2) «кстати, я просто сделал это, братан».
Transl8it — между прочим, я только что сделал это, брат. Lingo2Text — между мной jus donw with dat, брат.
Наша модель — кстати, на этом я закончил, брат.
6. Приложения
6.1 Анализ настроений
Текстовые данные, используемые для анализа настроений, должны быть на стандартном английском языке. Если данные зашумлены, инструмент анализа не будет эффективно обрабатывать информацию и может дать нейтральный результат. Наша модель может использоваться для преобразования зашумленных данных в стандартный английский язык, который затем можно легко проанализировать с помощью инструментов анализа.
6.2 Считыватели текста для слепых
Зашумленные данные нельзя использовать для программ чтения текста, которыми пользуются слепые. Зашумленные данные могут привести к ошибочным результатам в фонетическом и вербальном отношении. Чтобы устранить эту двусмысленность, можно использовать нашу модель для удаления шума из зашумленных данных и обеспечения лучшего ввода для программного обеспечения для чтения текста, чтобы оно могло дать наилучший вывод для слепых.
7. Будущая работа
Предлагаемая модель является частью проекта по анализу тенденций. В дальнейшем мы будем улучшать нашу модель в различных направлениях. Некоторые из запланированных усовершенствований включают улучшенное обнаружение слов NIV.
Область действия может быть расширена за счет имен собственных, характерных для конкретной страны, таких как MRT (это автобусная система в Сингапуре, а «магнитно-резонансная терапия» — в США).
Его также можно использовать в различных чат-приложениях, использующих графические компоненты, такие как стикеры, смайлики и т. д. Кроме того, для сопоставления слов будет использоваться большее количество распространенных интернет-сленгов.
д. Кроме того, для сопоставления слов будет использоваться большее количество распространенных интернет-сленгов.
Кроме того, мы намерены уменьшить количество зашумленных контекстов с помощью подхода начальной загрузки, при котором слова NIV с высокой достоверностью и меньшей неоднозначностью будут быстрее заменяться их стандартными формами и передаваться в модель нормализации в качестве новых обучающих данных.
8. Заключение
В этой статье мы представили различные типы шума, который возникает в SMS и интернет-данных. Мы обсудили проделанную работу в этом направлении. Мы обнаружили некоторые ограничения, связанные с этими методами, такие как несоответствие контекста, ненужные замены и т. д. Мы предложили метод, который преодолевает эти проблемы. Предлагаемое нами решение также подробно описано.
В предлагаемом методе мы нацелились на слова NIV и успешно преобразовали их в слова стандартного английского языка. Мы сравнили нашу модель с другими традиционными моделями и обнаружили, что наша модель может давать лучшие результаты, чем традиционные.
Ссылки
1. Гурприт Сингх Хануджа и Сачин Ядав, «Нормализация текста SMS», конференция IIT Kanpur НЛП; Апрель 2013
2. Екатерина Кобус, «Нормализация СМС: две метафоры лучше одной?»; 2008
3. Бофорт, Р., Рукхаут, С., Куньон, Л. А., Фэрон, К.: «Гибридная модель с конечным состоянием на основе правил и моделей для нормализации сообщений SMS
»; ACL (2010) 770-779
4. Кауфманн, М.: «Синтаксическая нормализация сообщений Twitter», 8-я Международная конференция по обработке естественного языка. (2010)
5. Брилл и Мур, «Улучшенная модель ошибок для коррекции орфографии зашумленных каналов», ACL ’00 Proceedings of the 38th Annual Meeting on Association for Computational Linguistics, 2000; Страницы 286-293.
6. http://www.transl8it.com
7. http://www.lingo2text.com
8. Бо Хан и Тимоти Болдуин, «Лексическая нормализация коротких текстовых сообщений: Makn Sens a #twitter» , Материалы 49-го ежегодного собрания Ассоциации компьютерной лингвистики, стр. 368-378, Портленд, Орегон; 19 июня-24, 2011.
368-378, Портленд, Орегон; 19 июня-24, 2011.
9. Библиотека с открытым исходным кодом PyEnchant of Python
10. http://www.noslang.com
11. http://www.stackoverflow.com для определений
12. Картик Рагунатан, Стефан Кравчик и Кристофер Мэннинг, «Нормализация текста SMS с использованием SMT», факультет НЛП Стэнфордского университета; Standford Projects, 2012 г. Авторы: Чао Цзя и Йинфей Ян, инженеры-программисты, Google Research
Изучение хороших визуальных представлений и представлений на языке зрения имеет решающее значение для решения проблем компьютерного зрения — поиска изображений, классификации изображений, понимания видео — и может способствовать разработке инструментов и продуктов, которые меняют повседневную жизнь людей. Например, хорошая модель сопоставления зрения и языка может помочь пользователям находить наиболее релевантные изображения с учетом текстового описания или введенного изображения, а такие инструменты, как Google Lens, — находить более подробную информацию об изображении.
Чтобы изучить такие представления, современные визуальные модели и модели языка видения в значительной степени полагаются на тщательно подобранные обучающие наборы данных, которые требуют экспертных знаний и обширных меток. Для приложений технического зрения представления в основном изучаются на крупномасштабных наборах данных с явными метками классов, таких как ImageNet, OpenImages и JFT-300M. Для приложений с визуальным языком популярные наборы данных для предварительного обучения, такие как концептуальные подписи и плотные подписи визуального генома, требуют нетривиальных шагов по сбору и очистке данных, что ограничивает размер наборов данных и, таким образом, препятствует масштабированию обученных моделей. Напротив, модели обработки естественного языка (NLP) достигли производительности SotA в тестах GLUE и SuperGLUE за счет использования крупномасштабного предварительного обучения на необработанном тексте 9.0373 без человеческих меток .
В статье «Увеличение масштабов обучения визуальному и зрительно-языковому представлению с помощью наблюдения за зашумленным текстом», которая появится на ICML 2021, мы предлагаем преодолеть этот пробел с помощью общедоступных данных альтернативного текста изображения (письменная копия, которая появляется вместо изображения на веб-странице, если изображение не загружается на экран пользователя) для обучения более крупных современных моделей зрения и языка зрения. С этой целью мы используем зашумленный набор данных из более чем одного миллиарда пар изображений и замещающего текста, полученных без дорогостоящих этапов фильтрации или постобработки в наборе данных Conceptual Captions. Мы показываем, что масштаб нашего корпуса может компенсировать зашумленные данные и приводит к представлению SotA, а также обеспечивает высокую производительность при переносе на задачи классификации, такие как ImageNet и VTAB. Выровненные визуальные и языковые представления также устанавливают новые результаты SotA в тестах Flickr30K и MS-COCO, даже по сравнению с более сложными моделями перекрестного внимания, и обеспечивают нулевую классификацию изображений и кросс-модальный поиск со сложными запросами текста и текста + изображения. .
С этой целью мы используем зашумленный набор данных из более чем одного миллиарда пар изображений и замещающего текста, полученных без дорогостоящих этапов фильтрации или постобработки в наборе данных Conceptual Captions. Мы показываем, что масштаб нашего корпуса может компенсировать зашумленные данные и приводит к представлению SotA, а также обеспечивает высокую производительность при переносе на задачи классификации, такие как ImageNet и VTAB. Выровненные визуальные и языковые представления также устанавливают новые результаты SotA в тестах Flickr30K и MS-COCO, даже по сравнению с более сложными моделями перекрестного внимания, и обеспечивают нулевую классификацию изображений и кросс-модальный поиск со сложными запросами текста и текста + изображения. .
Создание набора данных.
Пример пар изображение-текст, случайно выбранных из обучающего набора данных ALIGN. Одна явно зашумленная текстовая метка выделена курсивом. |
В этой работе мы следуем методологии построения набора данных Conceptual Captions, чтобы получить версию необработанных данных альтернативного текста на английском языке (пары изображения и альтернативного текста). В то время как набор данных Conceptual Captions был очищен с помощью жесткой фильтрации и постобработки, эта работа увеличивает масштабы обучения визуальному представлению и визуальному языку, упрощая большинство шагов очистки в исходной работе. Вместо этого мы применяем только минимальную частотную фильтрацию. В результате получается гораздо больший, но более зашумленный набор данных из 1,8 млрд пар изображение-текст.
ВЫРАВНИВАНИЕ: крупномасштабное встраивание изображений и зашумленного текста
Для простого создания более крупных и мощных моделей мы используем простую архитектуру с двойным кодировщиком, которая учится выравнивать визуальные и языковые представления пар изображения и текста. Кодировщики изображений и текста изучаются с помощью контрастивной потери (сформулированной как нормализованный softmax), которая объединяет встраивания совпадающих пар изображение-текст и раздвигает вложения несовпадающих пар изображение-текст (в пределах одного пакета). Крупномасштабный набор данных позволяет нам увеличить размер модели до размеров EfficientNet-L2 (кодировщик изображений) и BERT-large (кодировщик текста), обученных с нуля. Выученное представление можно использовать для следующих визуальных и языковых задач.
Крупномасштабный набор данных позволяет нам увеличить размер модели до размеров EfficientNet-L2 (кодировщик изображений) и BERT-large (кодировщик текста), обученных с нуля. Выученное представление можно использовать для следующих визуальных и языковых задач.
| Показатель ImageNet (Крижевский и др., 2012) и VTAB (Чжай и др., 2019) |
Полученное представление может быть использовано для передачи задач только для зрения или для передачи задачи на языке зрения. Без какой-либо тонкой настройки ALIGN обеспечивает кросс-модальный поиск — поиск изображения в тексте, поиск текста в изображении и даже поиск с объединенными запросами изображения и текста, примеры ниже.
Оценка извлечения и представления
Обученная модель ALIGN с BERT-Large и EfficientNet-L2 в качестве магистралей кодировщика текста и изображения обеспечивает производительность SotA при выполнении нескольких задач извлечения изображения-текста (Flickr30K и MS-COCO) как в нулевом, так и в точном настройки, как показано ниже.
| Flickr30K (тестовый набор 1K) R@1 | MS-COCO (тестовый набор 5K) R@1 | ||||
| Настройка | Модель | изображение → текст | текст → изображение | изображение → текст | текст → изображение |
| Нулевой выстрел | ИмиджБЕРТ | 70,7 | 54,3 | 44,0 | 32,3 |
| ЮНИТЕР | 83,6 | 68,7 | — | — | |
| ЗАЖИМ | 88,0 | 68,7 | 58,4 | 37,8 | |
| ВЫРАВНИВАНИЕ | 88,6 | 75,7 | 58,6 | 45,6 | |
| Тонкая настройка | объект групповой политики | 88,7 | 76,1 | 68,1 | 52,7 |
| ЮНИТЕР | 87,3 | 75,6 | 65,7 | 52,9 | |
| ЭРНИ-ВИЛ | 88,1 | 76,7 | — | — | |
| ВИЛЛА | 87,9 | 76,3 | — | — | |
| Оскар | — | — | 73,5 | 57,5 | |
| ВЫРАВНИВАНИЕ | 95,3 | 84,9 | 77,0 | 59,9 | |
Результаты поиска изображения и текста (отзыв@1) в наборах данных Flickr30K и MS-COCO (как нулевых, так и точных). ALIGN значительно превосходит существующие методы, включая кросс-модальные модели внимания, которые слишком дороги для крупномасштабных поисковых приложений. ALIGN значительно превосходит существующие методы, включая кросс-модальные модели внимания, которые слишком дороги для крупномасштабных поисковых приложений. |
ALIGN также является надежной моделью представления изображений. Как показано ниже, с замороженными элементами, ALIGN немного превосходит CLIP и достигает результата SotA с точностью 85,5%, занимающей первое место в ImageNet. При тонкой настройке ALIGN достигает более высокой точности, чем большинство универсальных моделей, таких как BiT и ViT, и хуже, чем мета-псевдометки, которые требуют более глубокого взаимодействия между обучением ImageNet и крупномасштабными немаркированными данными.
| Модель (основная) | Acc@1 с замороженными функциями | Акк@ 1 | Акк@5 |
| WSL (ResNeXt-101 32x48d) | 83,6 | 85,4 | 97,6 |
| ЗАЖИМ (ViT-L/14) | 85,4 | — | — |
| Бит (ResNet152 x 4) | — | 87,54 | 98,46 |
| NoisyStudent (EfficientNet-L2) | — | 88,4 | 98,7 |
| ВиТ (ВиТ-Н/14) | — | 88,55 | — |
| Мета-псевдо-метки (EfficientNet-L2) | — | 90,2 | 98,8 |
| ВЫРАВНИВАНИЕ (EfficientNet-L2) | 85,5 | 88,64 | 98,67 |
Сравнение результатов классификации ImageNet с контролируемым обучением (тонкая настройка). |
Классификация изображений Zero-Shot
Традиционно задачи классификации изображений рассматривают каждый класс как независимый идентификатор, и люди должны обучать слои классификации, по крайней мере, с несколькими снимками размеченных данных для каждого класса. Имена классов на самом деле также являются фразами на естественном языке, поэтому мы можем естественным образом расширить возможности поиска изображения и текста в ALIGN для классификации изображений.0373 без обучающих данных .
| Предварительно обученный кодировщик изображений и текста можно напрямую использовать для классификации изображения по набору классов путем извлечения ближайшего имени класса в выровненном пространстве встраивания. Этот подход не требует никаких обучающих данных для определенного пространства классов. |
В проверочном наборе данных ImageNet ALIGN достигает 76,4% точности нулевого выстрела в топ-1 и демонстрирует высокую надежность в различных вариантах ImageNet со сдвигами распределения, аналогично параллельной работе CLIP. Мы также используем ту же разработку и компоновку текстовых подсказок, что и в CLIP.
Мы также используем ту же разработку и компоновку текстовых подсказок, что и в CLIP.
| ImageNet | ImageNet-R | ImageNet-A | ImageNet-V2 | |
| ЗАЖИМ | 76,2 | 88,9 | 77,2 | 70,1 |
| ВЫРАВНИВАНИЕ | 76,4 | 92,2 | 75,8 | 70,1 |
| Лучшая точность классификации нулевого выстрела в ImageNet и ее вариантах. |
Применение в поиске изображений
Чтобы проиллюстрировать приведенные выше количественные результаты, мы создаем простую систему поиска изображений с вложениями, обученными с помощью ALIGN, и показываем 1 лучший результат поиска преобразования текста в изображение для нескольких текстовых запросов из 160 миллионного пула изображений. . ALIGN может извлекать точные изображения с подробным описанием сцены или детализированные концепции или концепции уровня экземпляра, такие как ориентиры и произведения искусства. Эти примеры демонстрируют, что модель ALIGN может выравнивать изображения и тексты с похожей семантикой и что ALIGN может обобщать новые сложные понятия.
. ALIGN может извлекать точные изображения с подробным описанием сцены или детализированные концепции или концепции уровня экземпляра, такие как ориентиры и произведения искусства. Эти примеры демонстрируют, что модель ALIGN может выравнивать изображения и тексты с похожей семантикой и что ALIGN может обобщать новые сложные понятия.
| Извлечение изображений с помощью подробных текстовых запросов с использованием вложений ALIGN. |
Мультимодальный (изображение+текст) запрос для поиска изображений
Удивительным свойством векторов слов является то, что аналогии слов часто могут быть решены с помощью векторной арифметики. Распространенный пример: «король – мужчина + женщина = королева». Такие линейные отношения между встраиванием изображения и текста также появляются в ALIGN.
В частности, учитывая изображение запроса и текстовую строку, мы добавляем их вложения ALIGN вместе и используем их для извлечения соответствующих изображений с использованием косинусного сходства, как показано ниже. Эти примеры не только демонстрируют композиционность вложений ALIGN в областях зрения и языка, но также показывают возможность поиска с помощью мультимодального запроса. Например, теперь можно найти «австралийский» или «мадагаскарский» эквивалент панд или превратить пару черных туфель в такие же бежевые туфли. Кроме того, можно удалить объекты/атрибуты из сцены, выполнив вычитание в пространстве встраивания, как показано ниже.
Эти примеры не только демонстрируют композиционность вложений ALIGN в областях зрения и языка, но также показывают возможность поиска с помощью мультимодального запроса. Например, теперь можно найти «австралийский» или «мадагаскарский» эквивалент панд или превратить пару черных туфель в такие же бежевые туфли. Кроме того, можно удалить объекты/атрибуты из сцены, выполнив вычитание в пространстве встраивания, как показано ниже.
| Поиск изображений с текстовыми запросами изображений. Добавляя или удаляя встраивание текстового запроса, ALIGN извлекает соответствующие изображения. |
Социальное влияние и работа на будущее
Хотя эта работа показывает многообещающие результаты с точки зрения методологии с помощью простого метода сбора данных, перед ответственным использованием модели на практике необходим дополнительный анализ данных и полученной модели. Например, следует учитывать возможность использования вредоносных текстовых данных в альтернативных текстах для усиления такого вреда. Что касается справедливости, могут потребоваться усилия по балансировке данных, чтобы предотвратить усиление стереотипов из веб-данных. Необходимо провести дополнительное тестирование и обучение по конфиденциальным религиозным или культурным объектам, чтобы понять и смягчить последствия возможно неправильно маркированных данных.
Например, следует учитывать возможность использования вредоносных текстовых данных в альтернативных текстах для усиления такого вреда. Что касается справедливости, могут потребоваться усилия по балансировке данных, чтобы предотвратить усиление стереотипов из веб-данных. Необходимо провести дополнительное тестирование и обучение по конфиденциальным религиозным или культурным объектам, чтобы понять и смягчить последствия возможно неправильно маркированных данных.
Также необходимо провести дополнительный анализ, чтобы убедиться, что демографическое распределение людей и связанных с ними культурных объектов, таких как одежда, еда и искусство, не вызывает перекосов в работе модели. Если такие модели будут использоваться в производстве, потребуются анализ и балансировка.
Заключение
Мы представили простой метод использования крупномасштабных зашумленных изображений и текстовых данных для масштабирования обучения визуальному представлению и языковому представлению.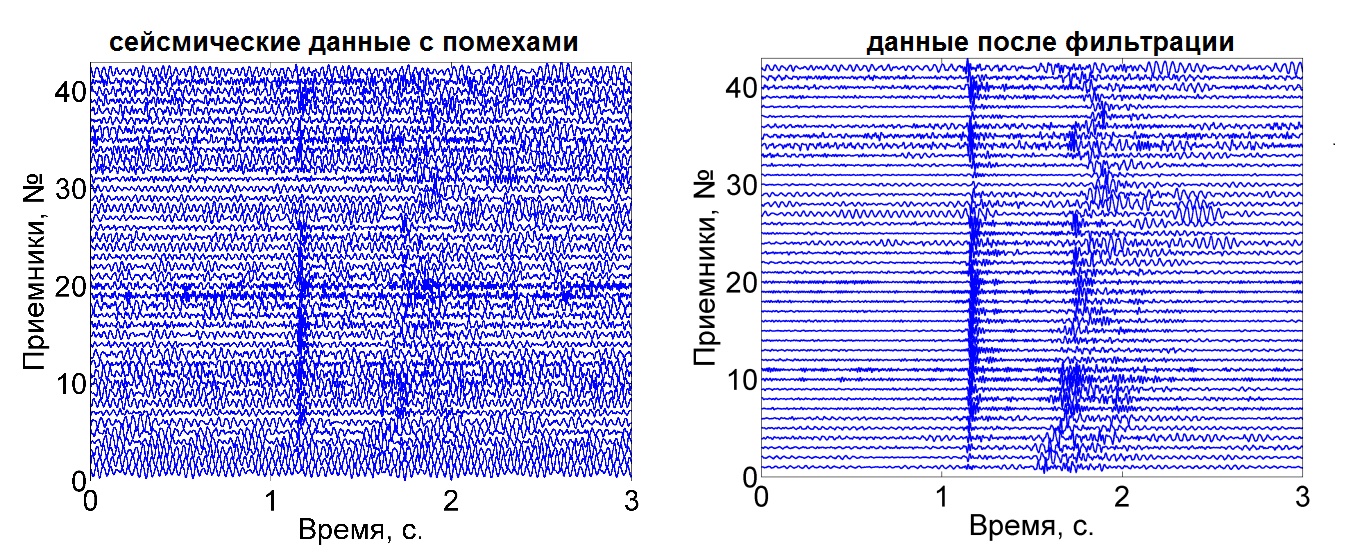 Полученная в результате модель ALIGN способна выполнять межмодальный поиск и значительно превосходит модели SotA. В задачах, связанных только с визуальными эффектами, ALIGN также сравним или превосходит модели SotA, обученные на крупномасштабных размеченных данных.
Полученная в результате модель ALIGN способна выполнять межмодальный поиск и значительно превосходит модели SotA. В задачах, связанных только с визуальными эффектами, ALIGN также сравним или превосходит модели SotA, обученные на крупномасштабных размеченных данных.
Благодарность
Мы хотели бы поблагодарить наших соавторов в Google Research: Ye Xia, Yi-Ting Chen, Zarana Parekh, Hieu Pham, Quoc V. Le, Yunhsuan Sung, Zhen Li, Tom Duerig. Эта работа также была проделана с неоценимой помощью других коллег из Google. Мы хотели бы поблагодарить Яна Длабала и Чжэ Ли за постоянную поддержку инфраструктуры обучения, Саймона Корнблита за построение оценки модели нулевого выстрела и надежности для вариантов ImageNet, Сяохуа Чжай за помощь в проведении оценки VTAB, Мингсин Тан и Макса Мороза за предложения по Обучение EfficientNet, Алексей Тимофеев за раннюю идею мультимодального поиска запросов, Аарон Мишелони и Каушал Патель за их раннюю работу по генерации данных, а также Сергей Иоффе, Джейсон Болдридж и Кришна Шринивасан за полезные отзывы и обсуждение.
