Поделиться ссылкой: |
|
Цифровая интегральная микросхема ТТЛ логики, производства советских времен. Широко применялась в бытовой аппаратуре. Часто использовалась радиолюбителями при создании различных устройств на основе цифровых микросхем. Содержит 4 логических элемента (вентиля) 2И-НЕ, в корпусе DIP-14 Микросхема К155ЛА3 имеет тип корпуса — 201.14-1 — пластиковый, с массой не более 1г. А для КМ155ЛА3 тип корпуса 201.14-8 — металлокерамический, с массой не более 2г., соответственно имеет расширенные температурные характеристики. Нумерация ног начинается от ключа на корпусе против часовой стрелки.
Аналоги К155ЛА3 — SN7400N, SN7400J (полностью совпадают по цоколевке и характеристикам) Параметры К155ЛА3 :
Таблица истинности К155ЛА3:
Схема одного элемента микросхемы: Анекдот:
Предложила мужу поиграть в ролевую игру «Девочка по вызову». |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Полевые транзисторы Содержимое 2 Транзисторы GBT Содержимое 3 Цифровые микросхемы Аналоговые микросхемы Содержимое 5 Конденсаторы Содержимое 7 |
Устроства для начинающих Электроника для авто Устройства для дома Источники питания Устройства на микроконтроллерах Ремонт бытовой аппаратуры Содержимое 6 Разное Содержимое 7 |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Здесь может быть Ваша реклама |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||

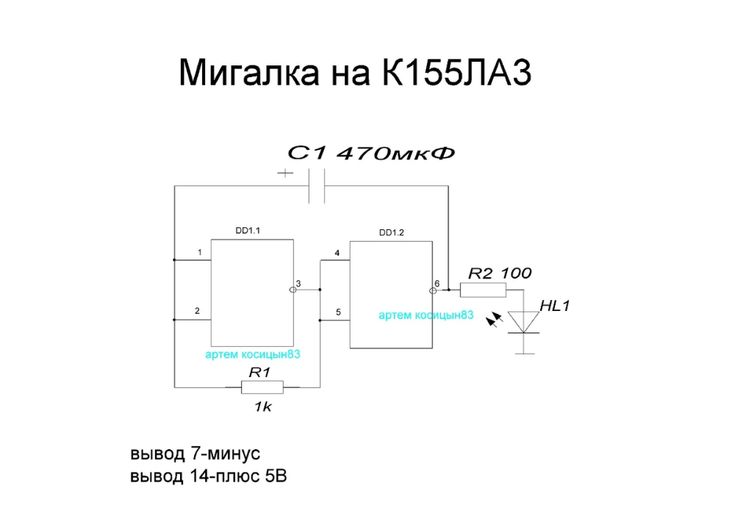
 «0»
«0»
Принципиальные схемы генераторов на микросхеме К155ЛА3
На микросхемах серии K155ЛA3 можно собирать низкочастотные и высокочастотные генераторы небольших размеров, которые могут быть полезны при проверке, ремонте и налаживании различной радиоэлектронной аппаратуры.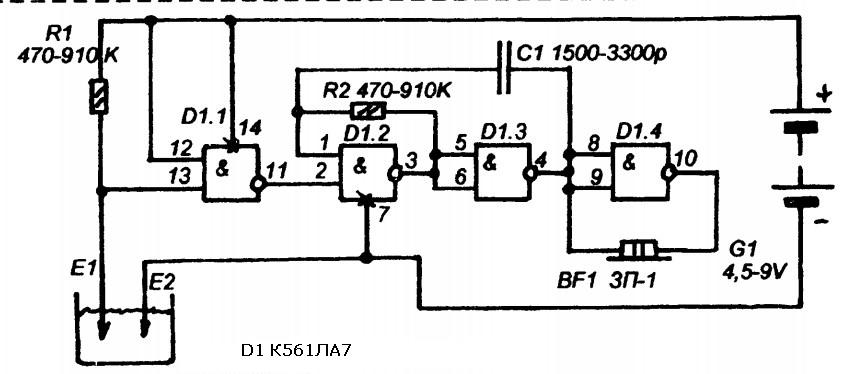 Рассмотрим принцип действия ВЧ генератора, собранного на трех инверторах (1).
Рассмотрим принцип действия ВЧ генератора, собранного на трех инверторах (1).
Структурная схема
Конденсатор С1 обеспечивает положительную обратную связь между выходом второго и входом первого инвертора необходимую для возбуждения генератора.
Резистор R1 обеспечивает необходимое смещение по постоянному току, а также позволяет осуществлять небольшую отрицательную обратную связь на частоте генератора.
В результате преобладания положительной обратной связи над отрицательной на выходе генератора получается напряжение прямоугольной формы.
Изменение частоты генератора в широких пределах производится подбором емкости СІ и сопротивления резистора R1. Генерируемая частота равна fген = 1/(С1 * R1). С понижением питания эта частота уменьшается. По аналогичной схеме собирается и НЧ генератор подбором соответствующим образом С1 и R1.
Рис. 1. Структурная схема генератора на логической микросхеме.
Схема универсального генератора
Исходя из вышеизложенного, на рис.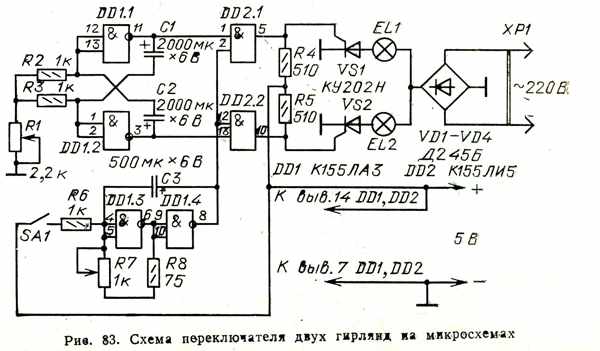 2 представлена принципиальная схема универсального генератора, собранная на двух микросхемах типа K155ЛA3. Генератор позволяет получить три диапазона частот: 120…500 кГц (длинные волны), 400…1600 кГц (средние волны), 2,5…10 МГц (короткие волны) и фиксированную частоту 1000 Гц.
2 представлена принципиальная схема универсального генератора, собранная на двух микросхемах типа K155ЛA3. Генератор позволяет получить три диапазона частот: 120…500 кГц (длинные волны), 400…1600 кГц (средние волны), 2,5…10 МГц (короткие волны) и фиксированную частоту 1000 Гц.
На микросхеме DD2 собран генератор низкой частоты, частота генерации которого составляет примерно 1000 Гц. В качестве буферного каскада между генератором и внешней нагрузкой используется инвертор DD2.4.
Низкочастотный генератор включается выключателем SA2, о чем свидетельствует красное свечение светодиода VD1. Плавное изменение выходного сигнала генератора НЧ производится переменным резистором R10. Частота генерируемых колебаний устанавливается грубо подбором емкости конденсатора С4, а точно — подбором сопротивления резистора R3.
Рис. 2. Принципиальная схема генератора на микросхемах К155ЛА3.
Детали
Генератор ВЧ собран на элементах DD1.1…DD1.3. В зависимости от подключаемых конденсаторов С1.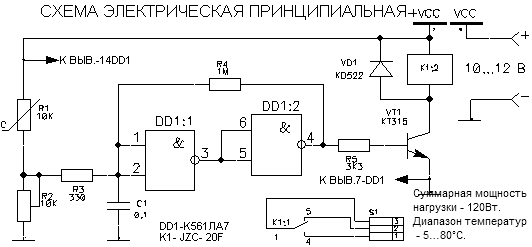 ..C3 генератор выдает колебания соответствующие КВ, СВ или ДВ.
..C3 генератор выдает колебания соответствующие КВ, СВ или ДВ.
Переменным резистором R2 производится плавное изменение частоты высокочастотных колебаний в любом поддиапазоне выбранных частот. На входы инвертора 12 и 13 элемента DD1.4 подаются колебания ВЧ и НЧ. В результате чего на выходе 11 элемента DD1.4 получаются модулированные высокочастотные колебания.
Плавное регулирование уровня промодулированных высокочастотных колебаний производится переменным резистором R6. С помощью делителя R7…R9 выходной сигнал можно изменить скачкообразно в 10 раз и 100 раз. Питается генератор от стабилизированного источника напряжением 5 В, при подключении которого загорается светодиод VD2 зеленого свечения.
В универсальном генераторе используются постоянные резисторы типа МЛТ-0,125, переменные — СП-1. Конденсаторы С1…C3 — КСО, С4 и С6 — К53-1, С5 — МБМ. Вместо указанной серии микросхем на схеме можно использовать микросхемы серии К133. Все детали генератора монтируют на печатной плате.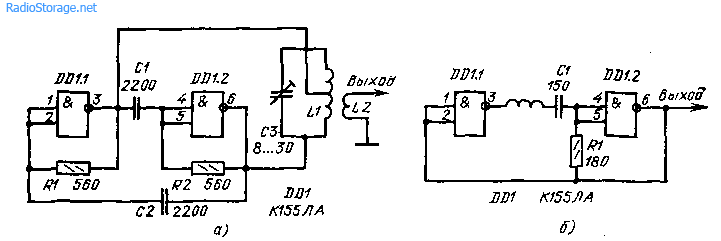 Конструктивно генератор выполняется исходя из вкусов радиолюбителя.
Конструктивно генератор выполняется исходя из вкусов радиолюбителя.
Настройка
Настройку генератора при отсутствии ГСС производят по радиовещательному радиоприемнику, имеющему диапазоны волн: КВ, СВ и ДВ. С этой целью устанавливают приемник на обзорный КВ диапазон.
Установив переключатель SA1 генератора в положение КВ, подают на антенный вход приемника сигнал. Вращая ручку настройки приемника пытаются найти сигнал генератора.
На шкале приемника будет прослушиваться несколько сигналов, выбирают наиболее громкий. Это будет первая гармоника. Подбирая конденсатор С1, добиваются приема сигнала генератора на волне 30 м, что соответствует частоте 10 МГц.
Затем устанавливают переключатель SA1 генератора в положение СВ, а приемник переключают на средневолновый диапазон. Подбирая конденсатор С2, добиваются прослушивания сигнала генератора на метке шкалы приемника соответствующей волне 180 м.
Аналогично производят настройку генератора в диапазоне ДВ. Изменяют емкость конденсатора C3 таким образом, чтобы сигнал генератора прослушивался на конце средневолнового диапазона приемника, отметка 600 м.
Аналогичным способом производится градуировка шкалы переменного резистора R2. Для градуировки генератора, а также его проверки, должны быть включены оба выключатели SA2 и SA3.
Литература: В.М. Пестриков. — Энциклопедия радиолюбителя.
Создание робота с голосовым управлением с помощью Tensil и Arty A7 — Часть II
Введение
Это часть II учебного пособия, состоящего из двух частей, в котором мы продолжим изучать, как создать робота, управляемого голосом, с использованием среды ускорения машинного обучения (ML) Tensil с открытым исходным кодом, платы Digilent Arty A7-100T FPGA и шасси Pololu Romi. В части I мы сосредоточились на распознавании речевых команд через микрофон. Часть II будет посвящена преобразованию команд в поведение робота и интеграции с шасси Romi.
Архитектура системы
Давайте начнем с рассмотрения архитектуры системы, которую мы представили в части I. Мы представили два высокоуровневых компонента: Sensor Pipeline и State Machine . Sensor Pipeline непрерывно получает сигнал микрофона в качестве входных данных и выводит события, представляющие одну из четырех команд. State Machine получает командное событие и соответствующим образом изменяет свое состояние. Это состояние представляет собой то, что робот делает в данный момент, и используется для управления двигателем.
Мы представили два высокоуровневых компонента: Sensor Pipeline и State Machine . Sensor Pipeline непрерывно получает сигнал микрофона в качестве входных данных и выводит события, представляющие одну из четырех команд. State Machine получает командное событие и соответствующим образом изменяет свое состояние. Это состояние представляет собой то, что робот делает в данный момент, и используется для управления двигателем.
Сначала мы займемся государственной машиной и управлением моторами. После этого мы свяжем все это вместе и соберем робота на шасси.
Конечный автомат отвечает за управление текущим состоянием двигателей. Он получает командные события и в зависимости от команды изменяет состояние двигателя. Например, когда он получает «вперед!» команда поворачивает оба мотора вперед; когда оно получает «право!» команда поворачивает правый двигатель назад, а левый вперед.
Конвейер датчиков создает события, содержащие команду и вероятность ее предсказания. Как мы упоминали ранее, модель ML способна предсказывать 12 классов команд, из которых наш робот использует только 4. Итак, во-первых, мы фильтруем события для известных команд. Во-вторых, мы используем пороговое значение для каждой команды для фильтрации с достаточной вероятностью. Во время тестирования эти пороги можно настроить, чтобы найти наилучший баланс между ложными отрицательными и ложными положительными результатами для каждой команды.
Как мы упоминали ранее, модель ML способна предсказывать 12 классов команд, из которых наш робот использует только 4. Итак, во-первых, мы фильтруем события для известных команд. Во-вторых, мы используем пороговое значение для каждой команды для фильтрации с достаточной вероятностью. Во время тестирования эти пороги можно настроить, чтобы найти наилучший баланс между ложными отрицательными и ложными положительными результатами для каждой команды.
Экспериментируя с Sensor Pipeline, мы видим, что он может генерировать несколько событий для одной и той же голосовой команды. Обычно серия этих экземпляров включает одну и ту же прогнозируемую команду. Это происходит потому, что распознавание происходит в скользящем окне, где звуковой образ может быть включен в несколько последовательных окон. Иногда серия начинается с правильно распознанной команды, за которой следует неправильная. Это происходит, когда усеченный звуковой образец в последнем окне неправильно предсказан. Чтобы сгладить эти эффекты, мы вводим состояние «устранения дребезга».
Еще один эффект, наблюдаемый при использовании Sensor Pipeline, заключается в том, что в самом начале буферы сбора данных и спектрограммы частично пусты (заполнены нулями). Иногда это приводит к неверным предсказаниям сразу после инициализации. Поэтому будет полезно войти в состояние устранения дребезга сразу после инициализации.
Устранение дребезга реализовано в State Machine путем введения эквивалента настенных часов. Часы представлены счетчиком тиков внутри структуры состояния. Этот счетчик сбрасывается до максимума при каждом изменении состояния двигателя и уменьшается при каждой итерации основного цикла. Как только часы обнуляются, конечный автомат выходит из состояния устранения дребезга и начинает принимать новые команды.
Вы можете посмотреть на реализацию конечного автомата в исходном коде речевого робота.
Управление двигателем
Для того, чтобы двигатели вращались, к его клеммам M- ( M1 ) и M+ ( M2 ) должна быть приложена разность потенциалов (напряжения). Сила и полярность этого напряжения определяют скорость и направление движения.
Мы используем PMOD HB3 для управления этим напряжением с помощью цифровых сигналов.
Полярность контролируется одним цифровым проводом. Это значение для левого и правого двигателей создается компонентом Xilinx AXI GPIO и подключается к контактам MOTOR_DIR[1:0] на модулях PMOD. Конечный автомат отвечает за установку битов направления через регистр AXI GPIO.
Сила напряжения регулируется формой волны ШИМ. Этот сигнал имеет фиксированную частоту (2 кГц) и использует соотношение между высокой и низкой частями периода (рабочий цикл), чтобы указать долю максимального напряжения, подаваемого на двигатель. Следующая диаграмма из справочного руководства HB3 показывает, как это работает.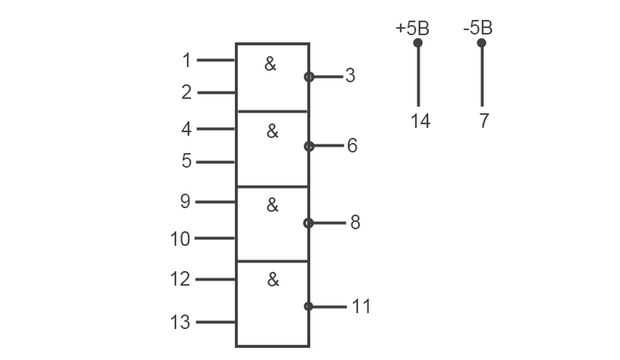
Для генерации сигнала ШИМ мы используем Xilinx AXI Timer. Мы использовали специальный экземпляр таймера для каждого двигателя, чтобы обеспечить независимое управление скоростью. Выход AXI Timer pwm подключен к выводу MOTOR_EN на модулях PMOD. Конечный автомат отвечает за установку общего и высокого периодов сигнала через драйвер AXI Timer от Xilinx.
Вы можете посмотреть на реализацию управления двигателем в исходном коде речевого робота.
Сборка шасси
В качестве механической платформы для речевого робота мы выбрали Pololu Romi. Это шасси простое, легкое в сборке и недорогое. Он также имеет встроенный батарейный отсек для 6 батареек типа АА, а также хороший распределительный щит, который выдает напряжение, достаточное для питания двигателей и платы Arty A7. Pololu также предоставляет расширительную пластину для шасси, чтобы удобно разместить плату Arty A7.
Ниже приводится перечень материалов для всех необходимых компонентов от Pololu.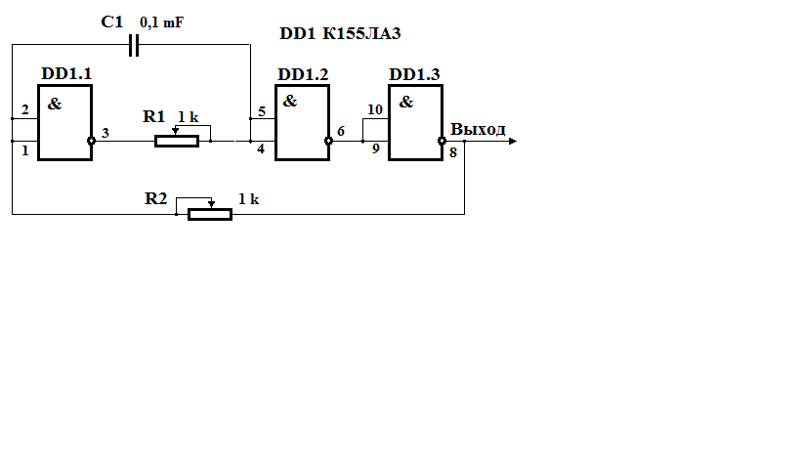
| Деталь | Количество |
|---|---|
| Комплект шасси Romi | 1 |
| Плата распределения питания для шасси Romi | 1 |
| Комплект пар энкодера Romi, 12 CPR, 3,5–18 В | 1 |
| Плата расширения шасси Romi | 2 |
| Алюминиевая стойка: длина 1-1/2 дюйма, резьба 2-56, M-F (4 шт. в упаковке) | 1 |
| Крепежный винт: № 2-56, длина 5/16″, крестообразный (25 шт. в упаковке) | 1 |
| Гайка с шестигранной головкой: #2-56 (25 шт. в упаковке) | 1 |
| 0,100” (2,54 мм) разъемная вилка: 1×40-контактный, прямой, черный | 1 |
| Проволочная перемычка Premium, 50 шт., набор из 10 цветов, F-F 6 дюймов | 1 |
| Проволочная перемычка Premium, 50 шт., набор из 10 цветов, M–F 6 дюймов | 1 |
Pololu содержит потрясающее видео, в котором подробно описан процесс сборки корпуса. Обязательно посмотрите, прежде чем начинать паять плату распределения питания!
Обязательно посмотрите, прежде чем начинать паять плату распределения питания!
Перед тем, как установить плату распределения питания, пришло время прогреть паяльник. Припаяйте два разъема 8×1 к клеммам VBAT, VRP, VSW и земле. Вы можете использовать малярную ленту, чтобы зафиксировать разъемы на месте во время пайки.
Затем поместите плату распределения питания на шасси так, чтобы клеммы аккумулятора выступали из соответствующих отверстий. Используйте винты, чтобы закрепить его. Теперь припаиваем клеммы к плате.
Вставьте батарейки и нажмите кнопку питания. Синий светодиод должен загореться.
Затем припаяйте разъемы 6×1 к каждой из плат энкодера двигателя (Примечание! Используйте тот же разъемный штыревой разъем, который используется с платой распределения питания, а не тот, который входит в комплект поставки энкодера). Затем поместите плату энкодера на каждый двигатель, чтобы двигатель клеммы высовываются через отверстия и припаиваются к ним.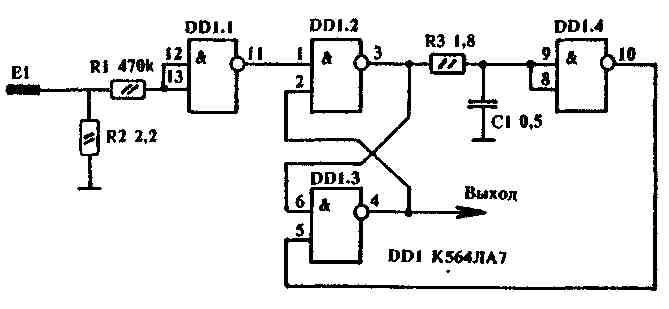
Наконец, вставьте двигатели в шасси и подключите их к HB3 PMOD (соедините M- с M1 и M+ с M2 ). Подключите HB3 PMOD VM к одной из клемм VSW и GND к GND на распределительном щите. Подключите плату Arty A7 и протестируйте все вместе!
Если все работает, продолжаем финальную сборку. Соедините две пластины расширения с помощью 2 винтов и закрепите их на шасси с помощью 4 стоек. Установите колеса и шариковый ролик. Поместите плату Arty A7 и PMOD HB3 поверх поверхности, образованной двумя удлинительными пластинами. Вы можете использовать двусторонний клей, чтобы держать их на месте. Мы предлагаем использовать провод калибра 18, чтобы поднять PMOD MIC3 над шасси, чтобы избежать влияния шума двигателей на микрофон.
Заключение
Во второй части руководства мы узнали, как спроектировать конечный автомат для речевого робота и как взаимодействовать с драйверами двигателей. Затем мы интегрировали все детали в шасси Pololu Romi. Теперь, когда у вас есть функционирующий робот, который подчиняется вашим командам, мы предлагаем вам расширить его и использовать оставшиеся 6 команд, которые может предсказать наша модель машинного обучения!
Затем мы интегрировали все детали в шасси Pololu Romi. Теперь, когда у вас есть функционирующий робот, который подчиняется вашим командам, мы предлагаем вам расширить его и использовать оставшиеся 6 команд, которые может предсказать наша модель машинного обучения!
Учебное пособие по Tensil для Ultra96 V2
Введение
В этом руководстве будет использоваться Avnet Ultra96 V2 и ускоритель логических выводов Tensil с открытым исходным кодом, чтобы показать, как запускать модели машинного обучения (ML) на FPGA. Мы будем использовать ResNet-20, обученный набору данных CIFAR. Эти шаги должны работать для любой поддерживаемой модели ML — в настоящее время поддерживаются все распространенные современные сверточные нейронные сети. Попробуйте на своей модели!
Мы предоставим подробное сквозное покрытие, за которым легко следить. Кроме того, мы включаем подробные объяснения, чтобы получить хорошее представление о технологии, стоящей за всем этим, включая цепочки инструментов Tensil и Xilinx Vivado и структуру PYNQ.
Если вы застряли или обнаружили ошибку, вы можете задать вопрос в нашем Discord или отправить электронное письмо по адресу [email protected].
Обзор
Прежде чем мы начнем, давайте посмотрим на поток инструментов Tensil, чтобы получить общее представление о том, чего мы хотим достичь. Мы выполним следующие шаги:
- Получить Тенсил
- Выберите архитектуру
- Создание проекта ускорителя TCU (код RTL)
- Синтез для Ultra96
- Компиляция модели ML для TCU
- Выполнить с помощью PYNQ
1. Получите Тенсил
Во-первых, нам нужно получить набор инструментов Tensil. Самый простой способ — вытащить док-контейнер Tensil из Docker Hub. Следующая команда извлечет образ, а затем запустит контейнер.
docker pull натяжение/натяжение
докер запустить \
-u $(id -u ${ПОЛЬЗОВАТЕЛЬ}):$(id -g ${ПОЛЬЗОВАТЕЛЬ}) \
-v $(пароль):/работа \
-w / работа \
-it tensilai/тенсил\
бить
2.
 Выберите архитектуру
Сила
Выберите архитектуру
Сила Tensil заключается в возможности персонализации, что делает его пригодным для очень широкого спектра применений. Файл определения архитектуры Tensil (.tarch) указывает параметры архитектуры, которые необходимо реализовать. Именно эти параметры делают Tensil достаточно гибким для работы как с небольшими встраиваемыми ПЛИС, так и с ПЛИС крупных центров обработки данных. В нашем примере будут выбраны параметры, обеспечивающие максимальное использование ресурсов части ZU3EG FPGA в ядре Ultra9.6 доска. Образ контейнера удобно включает файл архитектуры для платы разработки Ultra96 по адресу /demo/arch/ultra96v2.tarch . Давайте посмотрим, что внутри.
{
"тип_данных": "FP16BP8",
"размер_массива": 16,
"драм0_глубина": 2097152,
"драм1_глубина": 2097152,
"локальная_глубина": 20480,
"глубина_аккумулятора": 4096,
"simd_registers_depth": 1,
"шаг0_глубина": 8,
"шаг1_глубина": 8
}
Файл содержит объект JSON с несколькими параметрами.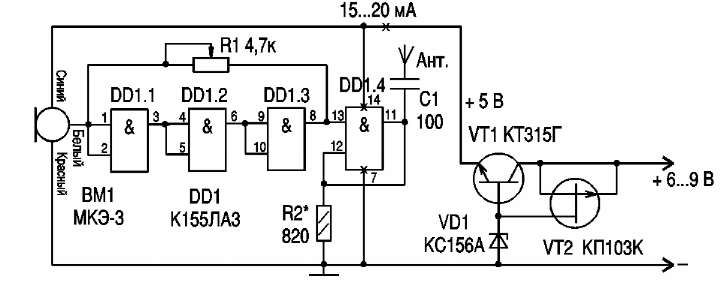 Первый,
Первый, data_type определяет тип данных, используемый в Tensor Compute Unit (TCU), включая систолический массив, SIMD ALU, аккумуляторы и локальную память. Мы будем использовать 16-битную фиксированную точку с 8-битной базовой точкой ( FP16BP8 ), что в большинстве случаев позволяет простое округление 32-битных моделей с плавающей запятой без необходимости квантования. Далее, array_size определяет систолический размер массива 16×16, что приводит к 256 параллельным единицам умножения-накопления (MAC). Это число было выбрано для максимального использования модулей DSP, доступных на ZU3EG, но если вам нужно было использовать несколько DSP для другого приложения параллельно, вы можете уменьшить его, чтобы освободить часть.
С помощью dram0_depth и dram1_depth мы определяем размер буферов памяти DRAM0 и DRAM1 на стороне хоста. Эти буферы подают в TCU веса и входные данные модели, а также хранят промежуточные результаты и выходные данные. Обратите внимание, что эти размеры памяти выражены в количестве векторов, что означает размер массива (16), умноженный на размер типа данных (16 бит), что в сумме составляет 256 бит на вектор.
Обратите внимание, что эти размеры памяти выражены в количестве векторов, что означает размер массива (16), умноженный на размер типа данных (16 бит), что в сумме составляет 256 бит на вектор.
Далее определяем размер локального и аккумулятора памяти, которые будут реализованы на самой фабрике FPGA. Разница между аккумуляторами и локальной памятью заключается в том, что аккумуляторы могут выполнять операцию записи-накопления, при которой ввод добавляется к уже сохраненным данным, а не просто перезаписывается. Общий размер аккумуляторов плюс локальная память снова выбран для максимального использования ресурсов BRAM на ZU3EG, но при необходимости вы можете уменьшить их, чтобы высвободить ресурсы, необходимые в другом месте.
С simd_registers_depth мы указываем количество регистров, включенных в каждое SIMD ALU, которые могут выполнять операции SIMD над сохраненными векторами, используемыми для операций ML, таких как активация ReLU. Увеличение этого числа необходимо только в редких случаях, чтобы помочь вычислить специальные функции активации. Наконец,
Увеличение этого числа необходимо только в редких случаях, чтобы помочь вычислить специальные функции активации. Наконец, stride0_depth и stride1_depth задают количество битов, используемых для включения «шагового» чтения и записи памяти. Маловероятно, что вам когда-нибудь понадобится изменить этот параметр.
Теперь, когда мы выбрали нашу архитектуру, пришло время запустить генератор Tensil RTL. RTL расшифровывается как «Уровень передачи регистров» — это тип кода, который определяет элементы цифровой логики, такие как провода, регистры и низкоуровневая логика. Специальные инструменты, такие как Xilinx Vivado или yosys, могут синтезировать RTL для FPGA и даже ASIC.
Чтобы сгенерировать проект с использованием выбранной нами архитектуры, выполните следующую команду внутри контейнера докера Tensil toolchain:
тенсил rtl -a /demo/arch/ultra96v2.tarch -s правда -d 128
Обратите внимание на параметр -d 128 , который указывает, что сгенерированный RTL будет совместим со 128-битными интерфейсами AXI, поддерживаемыми частью ZU3EG. Эта команда создаст несколько файлов Verilog, перечисленных в таблице
Эта команда создаст несколько файлов Verilog, перечисленных в таблице ARTIFACTS , распечатанной в конце. Он также распечатывает таблицу RTL SUMMARY с некоторыми основными параметрами результирующего RTL.
-------------------------------------------------- ---------------------- РЕЗЮМЕ RTL -------------------------------------------------- --------------------- Тип данных: FP16BP8 Размер массива: 16 Размер постоянной памяти (векторы/скаляры/биты): 2,097 152 33 554 432 21 Размер памяти Vars (векторы/скаляры/биты): 2 097 152 33 554 432 21 Размер локальной памяти (векторы/скаляры/биты): 20 480 327 680 15 Объем памяти аккумулятора (векторы/скаляры/биты): 4 096 65 536 12 Размер шага #0 (биты): 3 Размер шага №1 (бит): 3 Размер операнда #0 (бит): 24 Размер операнда №1 (бит): 24 Размер операнда № 2 (бит): 16 Размер инструкции (байт): 9-------------------------------------------------- ---------------------
4. Синтез для Ultra96
Пришло время запустить Xilinx Vivado.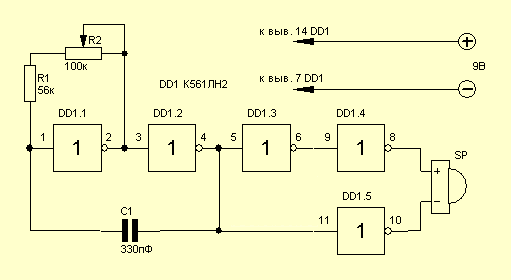 Я буду использовать версию 2021.2, которую вы можете бесплатно скачать (для прототипирования) на веб-сайте Xilinx.
Я буду использовать версию 2021.2, которую вы можете бесплатно скачать (для прототипирования) на веб-сайте Xilinx.
Сначала создайте новый проект RTL с именем tensil-ultra96v2 и добавьте файлы Verilog, сгенерированные инструментом Tensil RTL.
Выберите платы и найдите Ultra96. Выберите Ультра9Одноплатный компьютер 6-V2 с файлом версии 1.2. Возможно, вам потребуется щелкнуть значок «Установить» в столбце «Состояние». (Если вы не нашли доску, нажмите кнопку «Обновить» ниже.)
В разделе IP INTEGRATOR щелкните Создать блочный проект.
Перетащите top_ultra96v2 с вкладки «Источники» на блок-схему. Вы должны увидеть блок Tensil RTL с его интерфейсами.
Затем нажмите кнопку плюс + на панели инструментов блок-схемы (вверху слева) и выберите «Zynq UltraScale+ MPSoC» (возможно, вам потребуется использовать окно поиска). Сделайте то же самое для «Сброс системы процессора».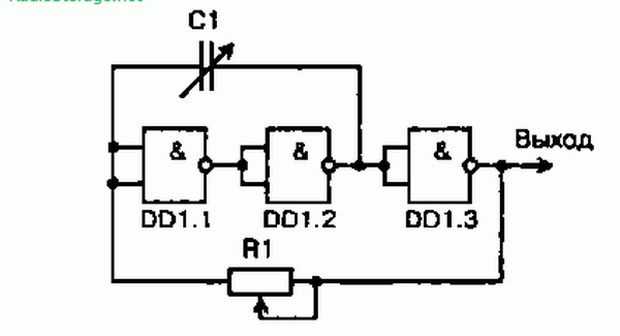 Блок Zynq представляет собой «жесткую» часть платформы Xilinx, которая включает в себя процессоры ARM, интерфейсы DDR и многое другое. Сброс системы процессора — это служебный блок, который обеспечивает проект правильно синхронизированными сигналами сброса.
Блок Zynq представляет собой «жесткую» часть платформы Xilinx, которая включает в себя процессоры ARM, интерфейсы DDR и многое другое. Сброс системы процессора — это служебный блок, который обеспечивает проект правильно синхронизированными сигналами сброса.
Нажмите «Запустить автоматизацию блока» и «Запустить автоматизацию подключения». Установите флажок «Вся автоматизация».
Дважды щелкните Zynq UltraScale+ MPSoC. Во-первых, перейдите в Clock Configuration и убедитесь, что часы PL Fabric имеют PL0 и настроены на 100 МГц.
Затем перейдите к конфигурации PS-PL. Снимите флажок AXI HPM1 FPD и установите флажок AXI HP1 FPD, AXI HP2 FPD и AXI HP3 FPD. Эти изменения настроят все необходимые интерфейсы между системой обработки (PS) и программируемой логикой (PL), необходимые для нашего проекта.
Теперь подключите порты m_axi_dram0 и m_axi_dram1 на блоке Tensil к S_AXI_HP1_FPD и S_AXI_HP2_FPD на блоке Zynq соответственно.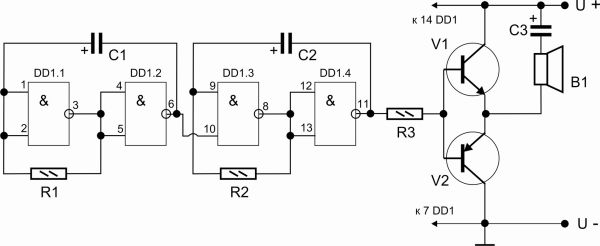 TCU имеет два банка DRAM для обеспечения их параллельной работы за счет использования отдельных портов PS.
TCU имеет два банка DRAM для обеспечения их параллельной работы за счет использования отдельных портов PS.
Затем нажмите кнопку плюс + на панели инструментов блок-схемы и выберите «Прямой доступ к памяти AXI» (DMA). Блок DMA используется для организации подачи программы Tensil на TCU без загрузки процессора PS ARM.
Дважды щелкните его. Отключите «Scatter Gather Engine» и «Write Channel». Измените «Ширина регистра длины буфера» на 26 бит. Выберите «Ширина данных карты памяти» и «Ширина данных потока» на 128 бит. Измените «Максимальный размер пакета» на 256.
Соедините порт инструкции в верхнем блоке Tensil с портом M_AXIS_MM2S в блоке AXI DMA. Затем подключите M_AXI_MM2S в блоке AXI DMA к S_AXI_HP3_FPD в Zynq.
Еще раз нажмите кнопку плюс + на панели инструментов блок-схемы и выберите «AXI SmartConnect. SmartConnect необходим для предоставления ЦП Zynq регистров управления DMA, что позволит программному обеспечению управлять транзакциями DMA. Дважды щелкните его и установите «Количество ведомых и главных интерфейсов» на 1.
Дважды щелкните его и установите «Количество ведомых и главных интерфейсов» на 1.
Соедините M00_AXI в блоке AXI SmartConnect с S_AXI_LITE в блоке AXI DMA. Подключите S00_AXI на AXI SmartConnect к M_AXI_HPM0_FPD в блоке Zynq.
Наконец, нажмите «Запустить автоматизацию подключения» и установите флажок «Вся автоматизация». Тем самым подключаем все часы и ресеты. Нажмите кнопку «Regenerate Layout» на панели инструментов Block Diagram, чтобы схема выглядела красиво.
Далее перейдите на вкладку «Редактор адресов». Нажмите кнопку «Назначить все» на панели инструментов. Делая это, мы назначаем адресные пространства различным интерфейсам AXI. Например, m_axi_dram0 и m_axi_dram1 получить доступ ко всему адресному пространству на плате Ultra96, включая память DDR и пространство регистров управления. Нам нужен только доступ к DDR, поэтому вы можете вручную исключить адресное пространство регистров, если знаете, что делаете.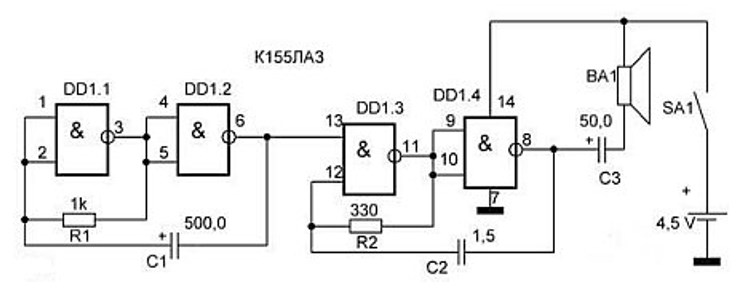
Вернувшись на вкладку «Блок-схема», нажмите кнопку «Проверить проект» (или F6). Вы должны увидеть сообщение об успешной проверке! Теперь вы можете закрыть дизайн блока, щелкнув x в правом верхнем углу.
Последним шагом является создание оболочки HDL для нашего проекта, которая свяжет все воедино и позволит осуществить синтез и реализацию. Щелкните правой кнопкой мыши элемент tensil_ultra96v2 на вкладке «Источники» и выберите «Создать HDL-оболочку». Оставьте выбранным «Разрешить Vivado управлять оболочкой и автообновлением». Подождите, пока дерево Sources полностью обновится, и щелкните правой кнопкой мыши на tensil_ultra96v2_wrapper . Выберите «Сделать верхним».
Теперь пришло время позволить Vivado выполнить синтез и реализацию и записать результирующий битовый поток. На боковой панели Flow Navigator нажмите «Создать битовый поток» и нажмите «ОК». Vivado начнет синтезировать наш дизайн Tensil — это может занять около 15 минут.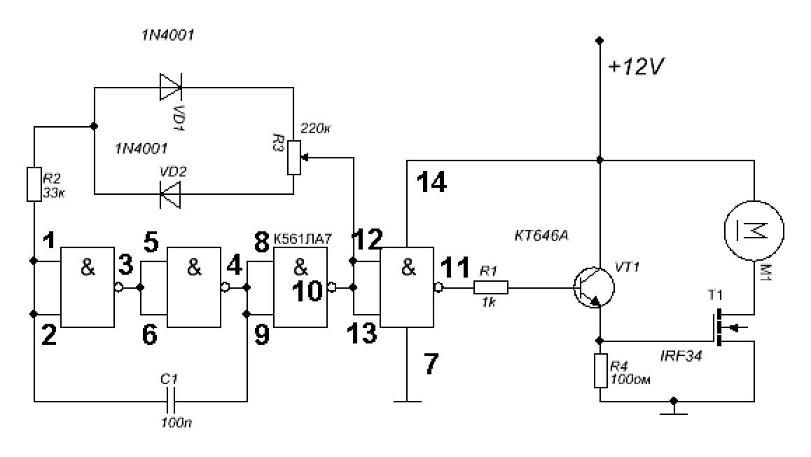 Когда закончите, вы сможете увидеть некоторые важные статистические данные в сводке проекта. Во-первых, посмотрите на использование, которое показывает, какой процент каждого ресурса FPGA использует наш проект. Обратите внимание, как мы максимально использовали ресурсы BRAM и DSP.
Когда закончите, вы сможете увидеть некоторые важные статистические данные в сводке проекта. Во-первых, посмотрите на использование, которое показывает, какой процент каждого ресурса FPGA использует наш проект. Обратите внимание, как мы максимально использовали ресурсы BRAM и DSP.
Второй параметр — время, которое говорит нам о том, сколько времени требуется сигналам для распространения в нашей программируемой логике (PL). Положительное значение «наихудшего отрицательного резерва» является хорошей новостью: наш дизайн соответствует ограничениям распространения для всех цепей на указанной тактовой частоте!
5. Компилировать модель ML для TCU
Вторая ветвь цепочки инструментов Tensil заключается в компиляции модели машинного обучения в двоичный файл Tensil, состоящий из инструкций TCU, которые выполняются аппаратным обеспечением TCU напрямую. В этом руководстве мы будем использовать ResNet20, обученную набору данных CIFAR. Модель включена в образ докера Tensil на странице 9. 0040 /demo/models/resnet20v2_cifar.onnx . Из контейнера докера Tensil выполните следующую команду.
0040 /demo/models/resnet20v2_cifar.onnx . Из контейнера докера Tensil выполните следующую команду.
растягивающая компиляция \
-a /demo/arch/ultra96v2.tarch \
-m /demo/models/resnet20v2_cifar.onnx \
-o "Идентификация: 0" \
-правда
Мы используем версию модели ONNX, но компилятор Tensil также поддерживает TensorFlow, что вы можете попробовать, скомпилировав ту же модель в форме замороженного графа TensorFlow по адресу /demo/models/resnet20v2_cifar.pb .
растягивающая компиляция \
-a /demo/arch/ultra96v2.tarch \
-m /demo/models/resnet20v2_cifar.pb \
-o "Идентификация" \
-правда
Полученные скомпилированные файлы перечислены в таблице ARTIFACTS . Манифест ( tmodel ) представляет собой простое текстовое описание скомпилированной модели в формате JSON. Программа Tensil ( tprog ) и данные о весе ( tdata ) являются двоичными файлами, которые будут использоваться TCU во время выполнения. Компилятор Tensil также печатает
Компилятор Tensil также печатает COMPILER SUMMARY с интересной статистикой как по архитектуре TCU, так и по модели.
-------------------------------------------------- ------------------------------------------------------------ ОБЗОР КОМПИЛЯТОРА -------------------------------------------------- ----------------------------------------------------------- Модель: resnet20v2_cifar_onnx_ultra96v2 Тип данных: FP16BP8 Размер массива: 16 Размер постоянной памяти (векторы/скаляры/биты): 2,097 152 33 554 432 21 Размер памяти Vars (векторы/скаляры/биты): 2 097 152 33 554 432 21 Размер локальной памяти (векторы/скаляры/биты): 20 480 327 680 15 Объем памяти аккумулятора (векторы/скаляры/биты): 4 096 65 536 12 Размер шага #0 (биты): 3 Размер шага №1 (бит): 3 Размер операнда #0 (бит): 24 Размер операнда №1 (бит): 24 Размер операнда № 2 (бит): 16 Размер инструкции (байт): 9Максимальное использование памяти Consts (векторы/скаляры): 35 743 571 888 Максимальное использование памяти Vars (векторы/скаляры): 13 312 212 992 Consts совокупное использование памяти (векторы/скаляры): 35 743 571 888 Совокупное использование памяти Vars (векторы/скаляры): 46 097 737 552 Количество слоев: 23 Общее количество инструкций: 102 741 Время компиляции (секунд): 30.066 Истинный скалярный размер const: 568 474 Утилизация констант (%): 97.210 Истинные MAC-адреса (M): 61,476 Эффективность MAC (%): 0,000 -------------------------------------------------- -----------------------------------------------------------
6. Выполнить с помощью PYNQ
Теперь пришло время собрать все вместе на макетной плате. Для этого нам сначала нужно настроить среду PYNQ. Этот процесс начинается с загрузки образа SD-карты для нашей платы разработки. На сайте документации PYNQ есть подробная инструкция по настройке подключения к плате. Вы должны иметь возможность открывать блокноты Jupyter и запускать некоторые примеры.
Существует одно предостережение, которое необходимо устранить после установки PYNQ. В образе PYNQ по умолчанию параметр размера области CMA ядра Linux (распределитель непрерывной памяти) составляет 128 МБ. Учитывая нашу архитектуру Tensil, размер CMA по умолчанию слишком мал. Чтобы решить эту проблему, вам нужно загрузить наше исправленное ядро, скопировать его в /boot и перезагрузить плату. Обратите внимание, что пропатченное ядро создано для PYNQ 2.7 и не будет работать с другими версиями. Чтобы пропатчить ядро, выполните следующие команды:
Обратите внимание, что пропатченное ядро создано для PYNQ 2.7 и не будет работать с другими версиями. Чтобы пропатчить ядро, выполните следующие команды:
wget https://s3.us-west-1.amazonaws.com/downloads.tensil.ai/pynq/2.7/ultra96v2/image.ub scp image.ub [email protected]: ssh [email protected] sudo cp /boot/image.ub /boot/image.ub.backup sudo cp image.ub /boot/ rm image.ub судо перезагрузка
Теперь, когда PYNQ установлен и работает, следующим шагом будет scp Драйвер Tensil для PYNQ. Начните с клонирования репозитория Tensil GitHub на свою рабочую станцию, а затем скопируйте drivers/tcu_pynq в /home/xilinx/tcu_pynq 9.0041 на вашу доску.
клон git [email protected]:tensil-ai/tensil.git scp -r тенсил/драйверы/tcu_pynq [email protected]:
Нам также нужно scp битовый поток и артефакты компилятора.
Далее мы скопируем битовый поток, который содержит конфигурацию FPGA, полученную в результате синтеза и реализации Vivado. PYNQ также требуется файл аппаратной передачи, в котором описываются компоненты FPGA, доступные для хоста, такие как DMA. Поместите оба файла в
PYNQ также требуется файл аппаратной передачи, в котором описываются компоненты FPGA, доступные для хоста, такие как DMA. Поместите оба файла в /home/xilinx на макетной плате. Предполагая, что вы находитесь в каталоге проекта Vivado, выполните следующие команды, чтобы скопировать файлы.
scp tensil-ultra96v2.runs/impl_1/tensil_ultra96v2_wrapper.bit [email protected]:tensil_ultra96v2.bit scp tensil-ultra96v2.gen/sources_1/bd/tensil_ultra96v2/hw_handoff/tensil_ultra96v2.hwh [email protected]:
Обратите внимание, что мы переименовали битовый поток, чтобы он соответствовал имени файла аппаратного переключения.
Теперь скопируйте .tmodel , .tprog 9Артефакты 0041 и .tdata , созданные компилятором для /home/xilinx на плате.
SCP resnet20v2_cifar_onnx_ultra96v2.t* [email protected]:
Последнее, что нужно для запуска нашей модели ResNet, — это набор данных CIFAR.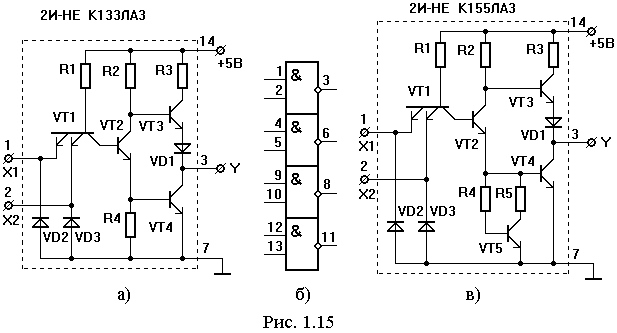 Вы можете получить его из Kaggle или выполнить приведенные ниже команды (поскольку нам нужен только тестовый пакет, мы удаляем обучающие пакеты, чтобы уменьшить размер файла). Поместите эти файлы в папку
Вы можете получить его из Kaggle или выполнить приведенные ниже команды (поскольку нам нужен только тестовый пакет, мы удаляем обучающие пакеты, чтобы уменьшить размер файла). Поместите эти файлы в папку /home/xilinx/cifar-10-batches-py/ на макетной плате.
wget http://www.cs.toronto.edu/~kriz/cifar-10-python.tar.gz смола xfvz cifar-10-python.tar.gz rm cifar-10-batches-py/data_batch_* scp -r cifar-10-batches-py [email protected]:
Наконец-то мы готовы запустить ноутбук PYNQ Jupyter и запустить модель ResNet на TCU.
Ноутбук Jupyter
Сначала импортируем драйвер Tensil PYNQ и другие необходимые утилиты.
система импорта
sys.path.append('/home/xilinx')
# Требуется для запуска логического вывода на TCU
время импорта
импортировать numpy как np
импортировать pyq
из наложения импорта pynq
из tcu_pynq.driver импортировать драйвер
из tcu_pynq.architecture импортирует ультра96
# Нужен для распаковки и отображения данных изображения
%matplotlib встроенный
импортировать matplotlib.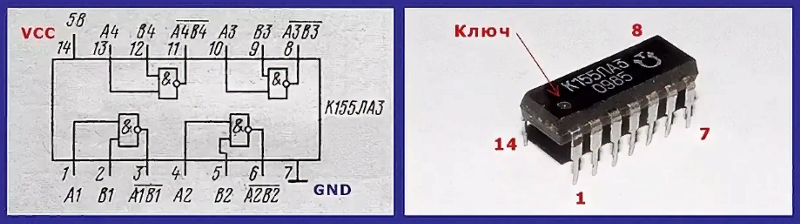 pyplot как plt
импортный рассол
pyplot как plt
импортный рассол
Теперь инициализируйте наложение PYNQ из потока битов и создайте экземпляр драйвера Tensil, используя архитектуру TCU и конфигурацию DMA наложения. Обратите внимание, что мы передаем объект axi_dma_0 из оверлея — имя соответствует блоку DMA в дизайне Vivado.
оверлей = оверлей('/home/xilinx/tensil_ultra96v2.bit')
tcu = Драйвер (ultra96, overlay.axi_dma_0)
Драйвер Tensil PYNQ включает определение архитектуры Ultra96. Вот отрывок из Architecture.py : вы можете видеть, что он соответствует архитектуре, которую мы использовали ранее.
ультра96 = Архитектура(
data_type = DataType.FP16BP8,
размер_массива=16,
драм0_глубина=2097152,
драм1_глубина=2097152,
локальная_глубина=20480,
глубина_аккумулятора=4096,
simd_registers_depth=1,
шаг0_глубина=8,
шаг1_глубина=8,
)
Далее загрузим изображения CIFAR из test_batch .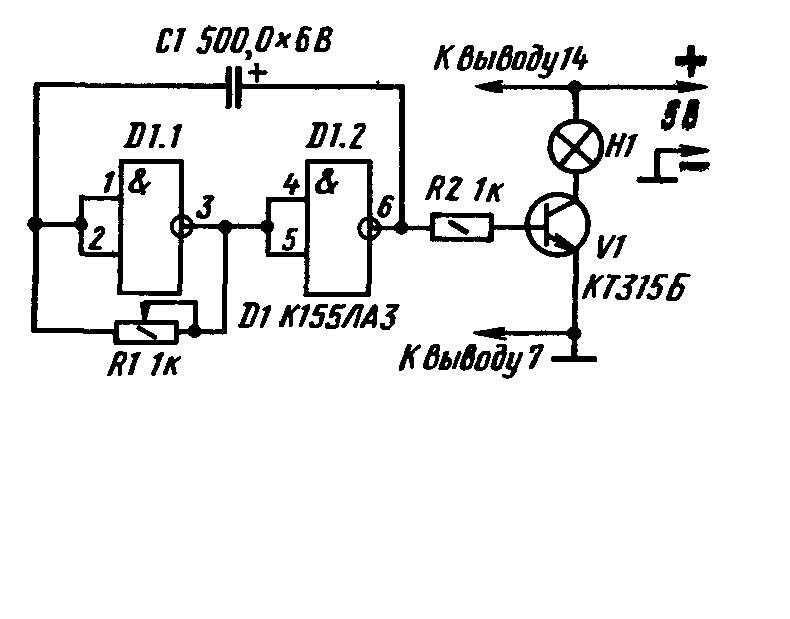
деф unpickle (файл):
с открытым (файл, 'rb') как fo:
d = pickle.load(fo, encoding='bytes')
вернуть д
cifar = unpickle('/home/xilinx/cifar-10-batches-py/test_batch')
данные = cifar[b'data']
метки = cifar[b'labels']
данные = данные [10:20]
метки = метки[10:20]
data_norm = data.astype('float32') / 255
data_mean = np.mean (data_norm, ось = 0)
data_norm -= данные_среднее
cifar_meta = unpickle('/home/xilinx/cifar-10-batches-py/batches.meta')
label_names = [b.decode() для b в cifar_meta[b'label_names']]
определение show_img (данные, n):
plt.imshow (np.transpose (данные [n]. reshape ((3, 32, 32)), оси = [1, 2, 0]))
def get_img (данные, n):
img = np.transpose (data_norm [n]. reshape ((3, 32, 32)), оси = [1, 2, 0])
img = np.pad (img, [(0, 0), (0, 0), (0, tcu.arch.array_size - 3)], 'константа', Constant_values = 0)
вернуть img.reshape((-1, tcu.arch.array_size))
def get_label (метки, label_names, n):
label_idx = метки[n]
имя = label_names[label_idx]
возврат (label_idx, имя)
Для проверки извлеките одно из изображений.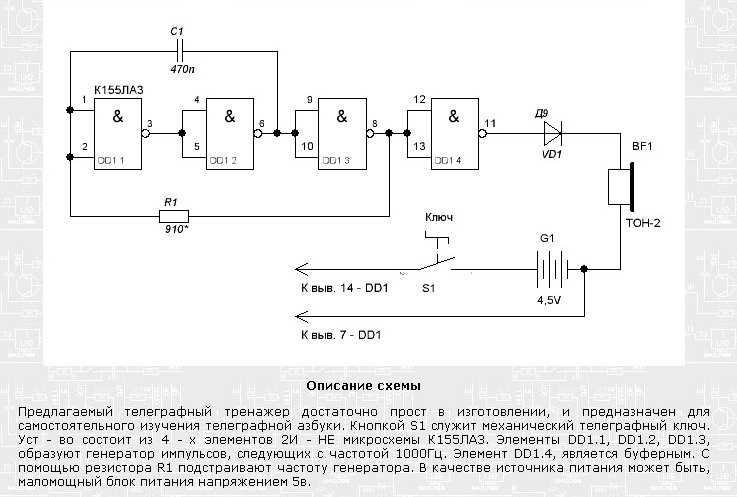
н = 9 img = get_img (данные, n) label_idx, label = get_label(labels, label_names, n) show_img (данные, п)
Вы должны увидеть изображение.
Затем загрузите в драйвер манифест модели tmodel . Манифест сообщает драйверу, где найти два других двоичных файла (программа и данные о весе).
tcu.load_model('/home/xilinx/resnet20v2_cifar_onnx_ultra96v2.tmodel')
Наконец, запустите модель и распечатайте результаты! Звонок на tcu.run(inputs) — вот где происходит волшебство. Мы преобразуем результирующий вектор классификации ResNet в метки CIFAR. Обратите внимание, что если вы используете модель ONNX, вход и выход имеют имена x:0 и Identity:0 соответственно. Для модели TensorFlow они называются x и Identity .
вводов = {'x:0': изображение}
начало = время.время()
выходы = tcu.run (входы)
конец = время. время()
print("Вывод выполнен в {:.4}s".format(конец - начало))
Распечатать()
классы = выходы['Идентификация:0'][:10]
result_idx = np.argmax (классы)
результат = label_names[result_idx]
print("Вывод активаций:")
печать (классы)
Распечатать()
print("Результат: {} (idx = {})".format(result, result_idx))
print("Фактическое: {} (idx = {})".format(label, label_idx))
время()
print("Вывод выполнен в {:.4}s".format(конец - начало))
Распечатать()
классы = выходы['Идентификация:0'][:10]
result_idx = np.argmax (классы)
результат = label_names[result_idx]
print("Вывод активаций:")
печать (классы)
Распечатать()
print("Результат: {} (idx = {})".format(result, result_idx))
print("Фактическое: {} (idx = {})".format(label, label_idx))
Вот ожидаемый результат:
Вывод за 0,03043 с Выходные активации: [-13,59375 -12,25 -7,90625 -6,21484375 -8,25 -12,24609375 15,0390625 -15,10546875 -10,71875 -9,1796875 ] Результат: лягушка (idx = 6) Фактически: лягушка (idx = 6)
Поздравляем! Вы запустили модель машинного обучения на собственном ускорителе машинного обучения, созданном на собственной рабочей станции! Только представьте, что вы можете с ним сделать…
Подведение итогов
В этом руководстве мы использовали Tensil, чтобы показать, как запускать модели машинного обучения (ML) на FPGA. Мы прошли ряд шагов, чтобы добраться сюда, включая установку Tensil, выбор архитектуры, создание дизайна RTL, синтез дизайна, компиляцию модели ML и, наконец, выполнение модели с использованием PYNQ.